
基于LDA 模型对大学生就业信息的主题挖掘
2024-06-26 11:25:06唐勇桑丽丽
电脑知识与技术 2024年13期
关键词:大学生就业
唐勇 桑丽丽


摘要:文章使用Python语言基于LDA模型对大学生就业信息进行主题分析。首先,使用Requests库和BeautifulSoup库对国家大学生就业服务平台中的就业信息进行采集,并使用pandas库对信息进行清洗和整理。然后,使用gensim库对大学生就业信息进行LDA建模,得出4个主题,即:就业帮扶及培训、企业招聘、考公考编和“三支一扶”政策。文章对这些主题进行了可视化处理,并分析了各个主题的内容。最后,按照信息发布的年份对就业信息文档分组,分析了各年份大学生就业信息主题强度的变化趋势。
关键词:主题分析;LDA模型;大学生就业
中图分类号:TP311.52 文献标识码:A
文章编号:1009-3044(2024)13-0084-04 开放科学(资源服务)标识码(OSID) :
0 引言
近年来,随着高校毕业生人数的增加和国内就业形势的变化,大学生就业问题日益凸显,引发社会各界的广泛关注。为了有效解决大学生就业问题,国家各部委和各级地方政府均出台了一系列的大学生就业帮扶政策信息,高校不断提升毕业生就业的服务水平,推出了大量的就业指导信息,企业和事业单位也积极投入到促进大学生就业工作中,发布了大量岗位招聘信息。
上述大学生就业信息通常是由各级政府和企业事业单位通过各种媒体平台零散发布的。那么,这些就业信息主要聚焦在哪些主题呢?各个主题的特征、针对性及变化趋势又是什么?这还需要进行具体的分析处理。本文通过Python爬虫程序对大学生就业信息进行收集整理,然后基于LDA模型分析大学生就业信息涉及的主题数及主题特征,并将主题模型可视化,最后按照时间顺序分析主题的演化过程,从而为完善和改进大学生就业帮扶政策提供建议。
1 LDA 模型介绍
LDA(Latent Dirichlet Allocation) 模型是一种无监督的机器学习模型,用于在大量文档中发现潜在的文档主题,被广泛应用于文档的自动化分析中。在LDA 模型中,一篇文档被认为是由文档主题矩阵和主题词语矩阵共同决定的。这两个矩阵的元素均服从二项分布,即:在文档主题矩阵中第m行代表语料库中的第m篇文档由k个主题构成,这些主题服从参数为θm的二项分布;而在主题词语矩阵中第k行代表主题集合中的第k 个主题由n 个单词构成,这些单词服从参数为φk 的二项分布。而二项分布θm 和φk 分别服从参数为α和β的迪利克雷分布。
因此,在LDA模型中生成文档的过程是:1) 根据参数为α的迪利克雷分布产生作为文档主题分布的参数θm,根据参数为β的迪利克雷分布产生作为主题单词分布的参数φk。2) 按照参数θm 的二项分布随机生成一个话题zmn。3) 最后按照参数为φzmn 的二项分布随机生成单词wmn。从上述LDA模型生成文档的过程中可以得出主题的单词分布,它能够刻画语料库中文档的潜在主题特征,如果结合文档产生的时间顺序,则可以进一步得出各个主题在不同时间段的特征词演变过程,从而能够分析出文档的主题动态演变过程。
LDA模型在文档主题分析时一方面忽略了文档产生的时间因素,它将不同时期的词语重要性同等对待;另一方面,LDA模型忽略了词语之间的关联性。因此,许多研究者针对LDA模型的不足进行了改进和优化,例如:苏婧琼等人对比了LDA模型和TF-IDF模型在文档关键词提取方面的各自特点,认为TF-IDF 模型更能够反映文档关键词的重要性[1]。潘越和高雪芬将TF-IDF模型和LDA模型相结合应用于微博的主题聚类分析:先用TF-IDF模型提取出每个文档的关键词,然后再用LDA模型结合起来进行主题分析[2]。彭俊利等人则进一步将TF-IDF 模型、LDA 模型和Word2Vec模型三者相结合,这种算法先采用TF-IDF模型提取出文档的关键词,然后采用LDA模型进行主题分析,最后将每个主题下的词汇采用Word2Vec模型进行向量化表示[3]。此种方法由于采用Word2Vec 模型,可以在一定程度上弥补LDA主题中词汇缺少上下文关联的不足。朱茂然等人则使用LDA模型计算了语料库中不同时间片段上的主题词汇分布,然后对不同时间段上的主题计算相似度,从而获得主题内容的演化过程[4]。海骏林峰等人将深度学习中有关自然语言预训练模型BERT与LDA模型结合,有效弥补了LDA模型在主题提取时忽略文本语义关联的问题[5]。但是,深度学习框架下的BERT模型需要基于大规模标注语料库和大规模计算,这并不适合于本文所要研究的大学生就业信息文本分析。
2 数据的来源、采集和清洗
就业信息数据源的选择关系到后期数据分析的正确性。目前,国内有众多平台发布大学生就业信息,既有前程无忧、中华英才网、智联招聘等求职网站,也有各级地方政府的人力资源网站。其中,国家大学生就业服务平台是由教育部学生服务与素质发展中心运营的专门服务于高校毕业生及用人单位的公共就业服务平台,是有关大学生就业信息的权威发布平台,采集该平台上的就业数据信息更加真实可靠,有利于后期的数据分析。因此,本文以国家大学生就业服务平台中的就业资讯作为数据源。
本文使用Python语言采集国家大学生就业服务平台2019 年到2024 年之间发布的就业资讯信息。Python语言的Requests库和BeautifulSoup库可以对网页内容进行获取和解析。首先分析出就业信息的网页地址模板为https://www.ncss.cn/ncss/jydt/jy/?start={},设置start的值在一个初始值为0,终止值为2220,步长为30的列表中循环,拼接成就业信息列表页的地址集合。然后,使用Requests库的get方法获取75个就业列表页面,每个页面30条就业信息;接着使用BeautifulSoup库解析每个列表页面的就业标题、发布时间、就业内容,总计2 250条记录。为了便于后期的数据清洗和处理分析,本文使用csv库的writer对象将上述标题、时间和内容信息分成三列存储到csv格式的文件中。
在完成就业信息的采集之后,需要对信息开展进一步的清洗。本文使用pandas库的DataFrame对象读取csv文件,然后通过DataFrame对象的dropna()方法去除掉就业信息内容为空的记录,最终保留了2 188 条大学生就业信息。接着采用jieba分词工具对就业信息内容进行分词,在分词的过程中使用了百度的中文停用词库,去除了就业内容中无实际含义的虚词、助词、形容词和标点符号,还要去除所有字符长度小于2的单字词,最后对jieba分词器的每个分词结果,判断其Unicode编码是否在u4e00到u9fff范围内可以提取出所有的中文分词。通过以上数据清洗过程产生最终的文档词汇列表作为LDA模型训练的语料库。
3 LDA 模型的实现
使用Python语言实现LDA模型可以借助gensim 库,gensim全称Generate Similarity,是一款开源的自然语言处理库,可以从多个文档中抽取潜在的主题。gensim库在生成LDA模型之前需要从多个文档中提取出词语构成词典,然后针对每个文档统计每个词语的权重。具体实现过程如下:
首先,导入gensim库中的corpora包,并调用cor?pora包的Dictionary类可以提取出所有文档中的词汇,形成语料库的词典,即:dictionary = corpora.Dictionary(words)。
然后,对于语料库中每个文档均调用Dictionary 类的doc2bow方法,返回的列表元素是每个词语在文档中出现的次数,即:corpus_bow = [dictionary.doc2bow(text) for text in words]。然而此种处理方式忽略了词语在整个语料库中的重要性,因此需要进一步应用TF-IDF模型。
接着,导入gensim库的models包,通过调用mod?els包的TfidfModel类可以将每个词汇的TF-IDF权重考虑进来,即:corpus_data = models.TfidfModel(cor?pus_bow)。这样处理后语料库中每个文档均转换为列表数据类型,每个列表元素是由该文档的单词编号和单词权重构成的元组。
最后,调用models包的LdaModel方法就可以生成LDA 模型,即:LDAModel(corpus_data, num_topics=6,id2word=dictionary, passes=20)。该方法的传入参数中,corpus_data是之前产生的语料库,dictionary是词典,passes表示对语料库迭代训练的次数,num_topics 表示需要的主题数。其中主题数num_topics需要预先确定。一般可以通过主题困惑度或主题一致性指标值来选择合适的主题数。本文使用主题一致性指标来判断合适的主题数,一致性指标值越高则选择的主题数量越合理。通过数据对比发现:主题一致性不仅受到主题个数的影响,还会受到语料库中词语数的影响。本文分别计算了不同主题数和词语数情况下的主题一致性曲线,如图1所示。可以发现选择词语数为1 200且主题数为4时的主题一致水平最高。
4 主题可视化及分析
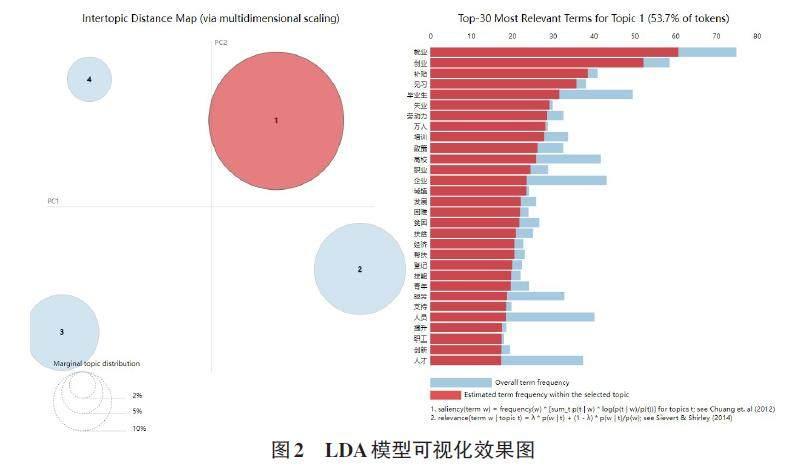
在LDA模型计算完成之后,可以借助pyLDAvis 库对主题模型的实现结果进行可视化分析。pyLDA?vis利用D3.js可视化模板将主题模型的结果制作成可交互的页面。图2是当词语数为1 200,主题数为4时的大学生就业信息可视化页面,此时四个主题没有任何重叠部分,说明主题建模效果良好。
通过LDA模型的get_topic_terms方法可以获得特定主题下相关度最高的词语。本文获取到大学生就业信息的4个主题下最相关的词汇,如表1所示。
通过各主题的特征词汇可以看出:主题1是与大学生就业帮扶和就业培训有关的内容,主题2是与大学生求职和企业用人招聘相关的内容,主题3是与大学生参加公务员考试和事业编制考试相关的内容,主题4是与大学生“三支一扶”(即:支农、支教、支医和扶贫)政策相关的内容。因此2019年到2024 年的大学生就业信息可以分为四个主题,即:就业帮扶及培训、企业招聘、公务员及事业单位考试、三支一扶。从各个主题的整体数量来看,主题1就业帮扶及培训相关的信息发布最多,而主题4三支一扶相关的信息发布最少,主题2企业招聘的相关信息略高于主题3考公考编。
为了进一步考查上述4个主题的动态发展变化,本文将每个文档按照发布的时间进行分类,得到按年划分的文档编号集合docs_id,然后使用LDA 模型的get_docu?ment_topics 方法可以获得每个文档在各个主题下的得分,最后按照年份分组并计算每个年份中各主题的得分平均值。图2 展示了2019年到2024年大学生就业信息的主题强度变化趋势,从图中可以发现主题4三支一扶的信息发布强度最低,也最平稳。主题1就业帮扶及培训的信息发布强度也呈现稳定趋势,而主题2企业招聘和主题3考公考编的信息发布强度均呈现波浪式发展态势。并且主题2的发布强度与主题3的发布强度还呈现互补的状态:在2019 年到2020 年期间由于受到疫情影响,企业招聘信息发布强度下降,此时考公考编信息发布强度上升;在2021 年到2022年期间国内经济逐渐从疫情影响中恢复,企业招聘信息发布趋势上升,而考公考编信息发布强度下降;在2022年到2024年期间国内经济发展放缓,同时大学生毕业人数激增,企业招聘信息的发布强度下降,而考公考编信息的发布强度开始上升。
5 总结
本文通过Python语言对国家大学生就业服务平台上2019年到2024年4月份的就业信息进行采集、清洗和整理,获得有效的大学生就业信息2188条。对这些就业信息文档使用gensim库的LDA模型进行主题识别和主题一致性的计算后,发现当设置词语数为1 200、主题数为4时的主题一致性最高,主题可视化效果也最好。因此,本文得到了有关大学生就业信息的四个主题,即:就业帮扶及培训、企业招聘、公务员及事业单位考试和三支一扶。最后,本文对大学生就业信息按照发布年份分组,获得每个年份下主题信息的发布强度曲线,分析出了各个主题信息的动态变化。本文在分析主题信息的动态变化时,受到文档语料库规模较小的限制,因此假定了每个年份的主题数目不变。在文档语料库规模较大的情况下,可以考虑将文档按年代分组后,使用LDA模型计算每个年份下文档的主题数和主题,然后分析各年份下的主题动态演变趋势。
参考文献:
[1] 苏婧琼,苏艳琼. 基于LDA和TF-IDF的关键词提取算法研究[J]. 长江信息通信,2024,37(1):78-80.
[2] 潘越,高雪芬. 大学数学精品慕课课程质量影响因素研究:基于评论文本挖掘的视角[J]. 浙江理工大学学报(社会科学版),2024(2):1-9.
[3] 彭俊利,王少泫,陆正球,等. 基于LDATF-IDF和Word2Vec文档表示[J]. 浙江纺织服装职业技术学院学报,2023,22(2):91-96.
[4] 朱茂然,王奕磊,高松,等. 基于LDA模型的主题演化分析:以情报学文献为例[J]. 北京工业大学学报,2018,44(7):1047-1053.
[5] 海骏林峰,严素梅,陈荣,等. 基于LDA-BERT相似性测度模型的文本主题演化研究[J]. 图书馆工作与研究,2024(1):72-79.
【通联编辑:谢媛媛】
基金项目:常州纺织服装职业技术学院应用技术类课题(项目编号:CFK201807) ;常州纺织服装职业技术学院教师企业实践锻炼项目(项目编号:2024)
猜你喜欢
商业经济(2016年10期)2016-12-16 12:06:59
考试周刊(2016年94期)2016-12-12 13:50:16
亚太教育(2016年31期)2016-12-12 07:57:50
青年时代(2016年28期)2016-12-08 17:44:44
青年时代(2016年28期)2016-12-08 17:43:06
新教育时代·教师版(2016年23期)2016-12-06 06:43:40
东方教育(2016年17期)2016-11-23 09:42:03
数学学习与研究(2016年19期)2016-11-22 11:42:54
文教资料(2016年20期)2016-11-07 12:02:37
知音励志·社科版(2016年8期)2016-11-05 02:34:08
