
AI赋能的生物医学研究
2024-06-16 15:52温砚中韩樾夏孙剑飞
科学 2024年3期
温砚中 韩樾夏 孙剑飞
生物医学是综合生命科学、生物学和医学等多个领域的前沿交叉科学,致力于运用工程技术手段探索和解决生命科学与医学相关问题,继而推动人类生命健康的发展。在生物医学研究中,科研工作者往往需要对复杂且多样的生物医学数据进行解读和分析,从中提取有价值的信息以理解复杂的生物医学问题,进而促进科学发现或推动临床诊疗的进步。作为生物医学领域的知识载体,这些数据或包含了大量疾病、药物、蛋白质、基因等多层次的生物医学关联规律,或蕴含着助力科学探索的潜能,掌握这些信息对生物医学相关研究向前发展至关重要。然而,随着生物科学技术以及计算机技术的发展,大量的生物医学数据快速产生并积累,如PB到EB级别的基因组学、蛋白质组学等生命科学组学数据,磁共振成像、CT成像等医学影像数据,收录超3600万篇文献的MEDLINE生物医学文献数据库等,生物医学进入了大数据时代。随着生物医学大数据的日益扩张,如何高效利用和挖掘这些多样化数据以驱动临床诊疗和科学实践成为生物医学研究的方向之一。
生物医学研究发展面临的问题
生物医学研究致力于洞察生命科学规律,促进精准医学发展。在推动临床诊疗和科学发现的发展中,预测和分析通常扮演着重要的角色。科学家一方面需要通过知悉领域数据来预测前沿趋势或锚定突破方向;另一方面需要采用高效的技术方法分析数据以支撑科学结论或决策。随着生物医学进入大数据时代,科学家对数据的高效利用愈发关键,故此可以将生物医学研究发展面临的问题归为基于生物医学大数据的高效预测和高效分析。
高效预测
预测可以理解为通过对已有的生物医学大数据进行充分“查阅”并“归纳”,总结出当前尚未被发现或被关注的信息,如潜在的药物靶点、潜在生物学信号通路、新型化合物结构等。预测重在基于现有的数据挖掘出新的有价值的科研线索。早在1986年,芝加哥大学教授斯旺森(Swanson)就曾基于生物医学文献数据预测出镁元素缺乏和偏头痛之间存在潜在关联,进而提出假说并由实验验证。传统的预测方法大多依赖于人工投入,科研人员需要先广泛搜集目标数据,然后手动分析和总结数据中有价值的信息,最后归纳得出预测性结论。但当下是生物医学大数据时代,传统方法不仅会消耗科研人员大量的时间精力,而且难以适应迅速增长的数据量以及不断涌现的复杂数据。因此需要更加高效的新方法来帮助预测任务的实现。

高效分析
分析通常指对生理信号、医学图像等具有表征意义的生物医学数据进行特征识别,从而揭示数据所反映的一系列生物医学现象。如临床医学中通过对肺部CT成像进行仔细观察和分析来确定患者肺部健康与否,从而给出诊断结论。传统的类似医学图像分析任务主要基于长期医学或科研实践中积累的专业经验和经典案例,在实际分析中已经是成熟且可靠的方法。但随着数据采集技术的不断升级,传统的人工分析方法在面临大量的数据处理任务时可能遇到效率低下的困境。因此,自动化且高质量的分析方法显得尤为必要,以期节省科研人员的时间精力,加速生物医学研究进程。
AI赋能生物医学的时代来临
近十多年以来,人工智能技术(a r t i f icial intelligence, AI)得到迅猛发展。在AI技术的加持下,计算机能够高效处理和分析大量的生物医学数据。通过机器学习、深度学习等人工智能技术,计算机可以自动学习和总结数据中蕴含的规律和知识,训练出AI模型用于高效预测和分析工作,进而代替人工完成复杂任务或前瞻性预测,辅助临床诊疗和科学实验的推进。经过多年的沉淀,AI已经深入影响到生物医学领域。从模型的角度看,AI模型经历了机器学习(machine learning, ML),深度学习(deep learning, DL),预训练模型(pretrained language model, PLM)和大模型(large language model, LLM)4个阶段[1]。

机器学习
机器学习是实现人工智能的一种方法,主要基于统计学和计算机科学,可以通过构建数学模型和算法使计算机对大量生物医学数据进行自动学习,不断迭代训练来优化其用于预测或决策的性能。由于传统机器学习方法大多依赖于标注数据,因此根据数据是否被标注,机器学习可以分为有监督学习、无监督学习和半监督学习。
有监督学习是指使用有明确标签的数据来训练模型学习数据中的规律和模式。例如可以根据过往病人的饮食习惯、血糖、血脂等记录以及是否患有糖尿病的标签,训练AI学会“根据病人记录判断其是否会发作糖尿病”。有监督学习的目标是让计算机基于带有标签的输入输出对,学习一个从输入到输出的映射关系,使其能够在未知数据中更好地进行预测或分类。常见的有监督学习算法包括决策树、朴素贝叶斯、支持向量机等。
无监督学习主要针对未标注数据学习其潜在规律和模式。不同于有监督学习,无监督学习不需要依赖已知的数据标签,而是通过算法来自行发现数据的内在结构和特征。例如在面对大量的基因数据时,可以使用无监督学习让计算机自动将功能相似的基因聚集在一起,帮助科学家理解基因的生物学功能而无须对基因功能预先标注。因此,无监督学习的目标是学习数据内在的结构和模式,以适应对未知数据的判断。常见的无监督学习算法包括聚类、主成分分析等。
半监督学习是有监督学习和无监督学习相结合的方法,旨在使用少量的标注数据和大量的未标注数据进行学习。其核心思想在于,首先使用小部分的标注数据基于有监督学习训练模型学习输入到输出的映射关系,然后使用大量的未标注数据去调优模型,提高模型的泛化能力。半监督学习一定程度上避免了数据和资源的浪费,同时也解决了有监督学习下的模型泛化能力不强和无监督学习下的模型不精确等问题。常见的半监督学习算法包括转导支持向量机、生成模型算法、自训练算法等。
深度学习
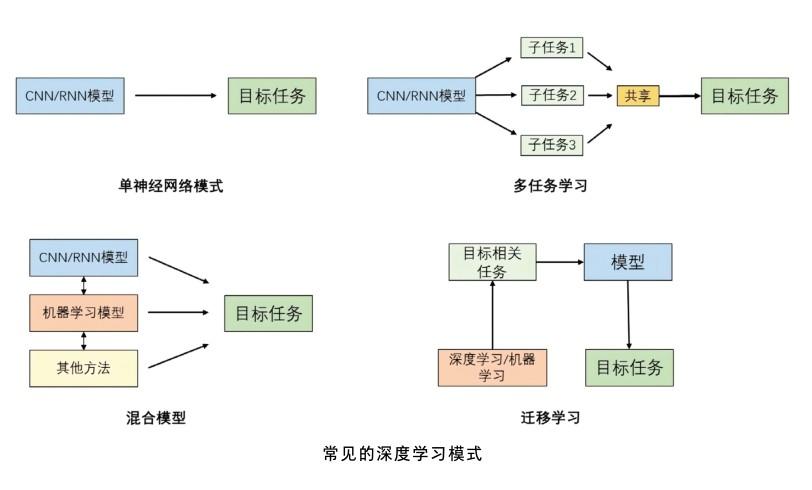
深度学习是机器学习的一种技术,主要用到了人工神经网络(artificial neural network, ANN)的新手段。传统机器学习方法一般需要人工构造特征,而通过多层次的神经网络模型,深度学习可以自动地从大量的数据中提取特征并学习隐藏在数据中的复杂模式,尤其可以节省人工构造生物医学数据特征的过程。根据不同的方法和策略,深度学习包括单神经网络、多任务学习、混合模型、迁移学习等多种模式。
单神经网络模式是指在数据建模时仅使用一种神经网络模型。常见的神经网络包括卷积神经网络(convolutional neural network, CNN)和循环神经网络(recurrent neural network, RNN)。CNN主要由输入层、嵌入层、卷积层、池化层、全连接层和输出层等构件组成,其核心思想在于利用多层次卷积操作来处理数据。类似人脑在面对视觉信息时对不同特征的识别,卷积操作是层层递进,由低向高的过程,最后实现对数据特征的提取,如识别图像。CNN在生物医学中常被用于医学图像分析处理,如图像分类、目标检测等。RNN更擅长处理序列型数据。在对序列数据建模时,RNN引入了隐藏状态设置来建立前后数据之间的依赖关系,因而可以有效利用长距离之前的信息,达到“记忆”的效果。这使得RNN能够随着时间推移捕捉数据中的长期依赖关系,可用于处理生物医学中的时序数据,如心电图、脑电图等,辅助疾病状态的识别和预测。
多任务学习采用了归纳学习的思想。在面对某一任务可以分解为多项子任务的场景时,可以训练模型同时适应多个子任务,模型在子任务之间通过“共享经验”来整合学习成果,例如训练AI自动从生物医学文本中识别基因、蛋白质、疾病。首先在3个对应不同概念的数据集上训练AI分别识别基因、蛋白质、疾病,通过在3个任务间共享特征来使模型达到“经验共享”的效果,从而实现模型对3种概念的同时识别。通过共享特征的学习,多任务学习模式可以充分利用多个数据集,有助于提升模型的泛化能力并减少数据和计算资源的消耗。
混合模型是指对于同一任务使用多种模型共同参与,旨在充分利用不同模型对同一任务的不同优势,从而构建性能更强的模型。如在基于医学图像的临床诊断中,可以将深度学习和传统机器学习模型相结合。首先基于CNN分析医学图像并提取特征,然后运用传统的机器学习算法(如支持向量机)根据医学图像的特征进行疾病分类,实现自动诊断。
迁移学习是一种将一个领域或任务中学到的知识或模式应用在另一个相关领域以解决目标问题的方法[2]。其核心思想在于模型学习到的特征或模式具有泛用性,可以跨任务或跨领域使用。迁移学习通常需要在源域数据中(如大量的生物医学文本)对模型进行预训练,然后将其转移至目标任务场景(如生物医学关系抽取任务)进行微调。微调旨在使用小场景中的少量数据更新源模型的参数,使其更好地适应目标任务。在复杂的生物医学研究中,迁移学习的使用可以极大地节省研究人员从头至尾训练新模型的时间精力。
预训练模型与大模型
预训练模型是迁移学习应用的经典代表,也是更为高效的解决方案。预训练模型是指在大规模未被标记的数据上进行训练的语言模型。预训练过程中,模型能够自动学习数据中的上下文信息、结构特征以及丰富的知识表示。通过将预训练中捕获的知识储存在巨大的参数中,针对特定任务场景进行微调,这些被储存的知识可以使各种下游任务受益。当下生物医学领域较为流行的预训练模型包括BioBERT、MedBERT、BioGPT、PubMedGPT等。生物医学预训练模型能够使计算机更好地理解生物医学文本,在将文本映射为向量表示的同时能够保留其生物医学语义,为生物医学领域的命名实体识别、关系抽取等自然语言处理任务提供了有力的基础。
预训练模型的使用极大地减少了对特定任务的训练数据需求。对于特定任务,使用相对较少的标注数据对预训练模型进行微调即可使模型适应具体任务,一定程度上也缓解了生物医学领域标记数据缺失问题,减少了数据构建成本。
大模型则是“知识储备”更大的预训练模型。与传统预训练模型相比,大模型使用的训练数据更多、训练方法更优,模型的参数量更大,可处理的任务更加复杂。2023年,以ChatGPT为代表的人工智能大语言模型(large language model, LLM)在各行各业的测试中取得了全新的突破,展现出了大模型作为新一代人工智能载体的潜力。
大模型最先在内容生成和对话方面表现出潜力。如ChatGPT这样的大模型其训练数据涵盖了多个领域,几乎可以回答或解决各种常规问题。在经过庞大且丰富的数据预训练后,大模型具备了强大的自然语言理解能力和学习能力,能够以对话的形式按照给定指令执行任务。如输入一段文本让其提取生物医学关系。由于训练语料的开放性,大模型几乎可以执行各种任务,但对于专业性极强的领域(如生物医学),通用大模型可能效果不足。为了应对生物医学领域的任务(如生物医学数据自动标注),一方面可以通过提示工程的手段,向大模型提示若干生物医学数据标注示例(如从一段生物医学文本中识别疾病、基因等实体),让大模型领会生物医学数据标注的“任务要领”,以此来适应目标任务,完成大模型的领域迁移应用;另一方面可以基于生物医学领域的语料数据训练一个生物医学大模型来适应领域任务,如基于生物医学文献训练的大模型PMC-LLaMA[3]。前者可以通过设计优质的提示来提升模型表现,后者一般需要投入较大成本才能实现,对数据质量和硬件都有一定的要求。
大模型背后丰富的训练数据使其具有庞大的“知识储备”。但大模型在回答问题时,答案很大程度上取决于训练所使用的数据。对于训练数据之外的问题,模型虽然能够根据“已经掌握的知识”给出答案,但答案可能并不可靠。因此,在面对快速更新的生物医学问题时,大模型需要被“投喂”新生物医学知识。微调便是一种向模型补充新知识的方法,但大模型参数量巨大,微调成本一般较高。
大模型的又一优势在于能根据给定的上下文信息进行学习,并结合问题生成相应的解释,因此可以通过引入外部知识作为新知识补充。可实时更新的外部知识库(如生物医学文献数据库等)可以用作上下文相关信息来优化模型表现。这种方式下,大模型首先会根据问题特点在知识库中进行相关知识检索,通过对相关知识和目标问题进行分析,从而生成更好的回答[4]。故此,大模型结合外部知识库的模式在应对知识更新较快的生物医学场景时具有极大的潜能。
AI在生物医学研究中的应用
不断迭代发展的AI展现出了强大的自动学习和推理能力。对于学科复杂的生物医学领域,AI的应用极大地减轻了科学家处理海量生物医学数据的负担,越来越多的研究团队基于AI技术对数据进行分析利用,如较为成熟的组学数据分析、医学图像分析、文献挖掘等。
AI应用于组学数据分析
随着高通量基因测序技术的不断进步,基因测序产生的大量组学数据需要分析。组学数据分析对疾病分类、药物作用预测、基因表达过程预测等研究突破至关重要。AI技术的应用为高效的组学数据分析提供了有力支撑。
在AI技术的帮助下,科学家可以根据基因转录组学数据推断药物-靶标之间的相互作用。研究者整理了药物相关的基因表达数据库,基于含有2000个组成单元的DNN模型进行训练,并对数据进行了约200倍的降维。经过训练后的DNN模型能够识别出患者样本间的差异,进而预测药物-靶标的作用差异,展现了AI在基于基因组数据预测药物靶标作用中的潜力[5]。
除了基因组数据,蛋白质功能和结构也是科学家关注的方向之一,基于蛋白质序列预测蛋白质功能和结构对推动生物学发展具有关键意义。在此背景下,DeepMind基于大规模蛋白质序列和结构数据训练了蛋白质结构预测模型AlphaFold2。在无参照结构的情况下,AlphaFold2模型能够准确预测蛋白质结构,并在第14次蛋白质结构预测关键评估(CASP14)中取得了优异的成绩。
AI应用于生物医学文献挖掘
生物医学文献挖掘旨在基于海量文献获取有用信息指导科学研究。现今可以通过AI技术从海量生物医学文献中自动识别、提取潜在的科研线索来辅助科研实践,如经典的潜在药物发现研究等。
药物发现旨在识别潜在的治疗疾病的新药物。SemaTyP是一项基于知识图谱和机器学习方法发现候选药物的工作[6]。该工作首先使用关系抽取工具从生物医学文献中提取生物医学关系三元组构建知识图谱(SemKG),通过对知识图谱中“药物—靶点—疾病”的路径信息进行建模,训练AI模型预测药物、靶点、疾病之间的关系。结果表明,SemaTyP成功预测出了疾病对应的潜在药物和相应靶点。已知睾酮和ap22408可用于治疗骨质疏松症,而在SemaTyP的预测结果中,这两种药物分别位列第一和第三。此外,SemaTyP还预测出了尚未发现的药物靶点,例如阿司匹林可能通过作用于淋巴细胞来治疗心血管疾病;特立兰卡可能通过作用于肌动蛋白来治疗心律失常等,预测结论均对后续药物靶点研究具有启发意义。
AI应用于医学图像分析
组学数据分析和文献挖掘分析对生物医学科学研究具有指导意义。而在临床医学中,医学图像则是临床诊断和疾病治疗的重要依据,同时医学图像分析也是AI在生物医学领域的重要应用之一。常见的医学图像包括X射线、磁共振成像、超声成像等,这些图像直观地反映了人体内部结构、组织和病理变化状态等。AI技术的应用促进了对医学图像的自动分析,极大地提高了诊断效率。
以黄斑为中心的视网膜眼底图像可用于筛查潜在的威胁视力的疾病,包括糖尿病视网膜病变和青光眼等。为了辅助临床自动筛选异常的眼底视网膜图像,研究者基于深度学习技术开发了AI模型。通过对10万多张图像超30万个读数和外部数据集的出血、硬性渗出物、黄斑裂孔等12个指标进行测试,并与眼科专业的检查结果进行对比,AI模型成功实现了对黄斑中心视网膜眼底图像的准确分类,推动了临床视网膜眼底图像的自动筛查应用[7]。
除了自动分析医学图像辅助诊断,为了应对精准医疗的需求,AI还可基于影像信息预测疾病可能病程、指导诊疗过程。研究人员基于14 036张手部X光影像,使用深度学习技术开发了一个手部X光片骨龄预测模型[8]。在200例测试集样本中,该AI模型的预测结果与放射科专家预测结果平均差值为0岁,平均绝对误差为0.50岁,均方根差为0.63岁,表现出了在预测骨龄应用中与专家水平相当的性能。
展 望
当前,新一代人工智能技术,特别是以大模型为核心的新方法,正在以更加智能的方式推进生物医学研究。这些技术在自动诊断、医学问答、药物研发等领域展现出巨大潜力。然而,AI技术的应用不仅为生物医学研究带来机遇,同时也引入了新的挑战。
从数据角度看,AI技术在处理和分析海量数据方面具有优势,而AI的成功应用往往依赖于高质量数据。在生物医学领域,数据具有专业性强、多样且复杂的特点。因此,高质量数据的获取需要多方努力。在数据收集方面,应研发或升级数据采集工具以提高数据的可靠性;在数据标注方面,需加强标注人员的专业知识培训和标注工具的精准度;对于多源数据整合,需要持续开发有效的整合和标准化策略,以提升AI性能。
AI模型的可解释性对生物医学决策至关重要。虽然先进的AI算法在处理生物医学问题中展现出高准确性和强预测能力,但其黑盒运作机制使AI模型在解释方面存在不足。未来,通过增强AI模型决策过程的可视化,可以帮助科研人员理解和信任AI;AI研究人员和生物医学科学家还可通过双向深入参与,以确保AI技术与科学应用的紧密耦合。此外,研发更加透明和可解释的AI模型,以进一步增强AI的可信度也尤为必要。目前,可解释AI的相关研究正逐渐开展,随着研究的不断深入,生物医学领域的AI可解释时代终会到来。
[1]罗锦钊, 孙玉龙, 钱增志, 等. 人工智能大模型综述及展望. 无线电工程, 2023, 53(11): 2461-2472.
[2]Pan S J, Yang Q. A survey on transfer learning. IEEE Transactions on Knowledge and Data Engineering, 2009, 22(10): 1345-1359.
[3]Wu C, Zhang X, Zhang Y, et al. Pmc-llama: further finetuning llama on medical papers. arXiv preprint arXiv: 2304. 2023, 14454.
[4]Gao Y, Xiong Y, Gao X, et al. Retrieval-augmented generation for large language models: A Survey. arXiv preprint arXiv: 2312. 2023, 10997.
[5]Xie L, He S, Song X, et al. Deep learning-based transcriptome data classification for drug-target interaction prediction. BMC Genomics. 2018, 19: 93-102.
[6]Sang S, Yang Z, Wang L, et al. SemaTyP: a knowledge graph based literature mining method for drug discovery. BMC Bioinformatics, 2018, 19: 1-11.
[7]Son J, Shin J Y, Kim H D, et al. Development and validation of deep learning models for screening multiple abnormal findings in retinal fundus images. Ophthalmology, 2020, 127(1): 85-94.
[8]Larson D B, Chen M C, Lungren M P, et al. Performance of a deeplearning neural network model in assessing skeletal maturity on pediatric hand radiographs. Radiology, 2018, 287(1): 313-322.
关键词:人工智能 生物医学大数据 自动分析 预测 ■
猜你喜欢
黄河之声(2022年10期)2022-09-27
西安航空学院学报(2022年2期)2022-07-04
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
商界(2019年12期)2019-01-03
疯狂英语·初中天地(2018年6期)2018-11-24
IT经理世界(2018年20期)2018-10-24
小康(2017年16期)2017-06-07
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
