
基于注意力机制和多级校正的单目室内场景深度估计
2024-06-03 11:15:28刘鹏丁爱华窦新宇
现代信息科技 2024年5期
关键词:注意力机制
刘鹏 丁爱华 窦新宇
收稿日期:2023-07-31
基金项目:唐山市市级科技计划项目(22130205H)
DOI:10.19850/j.cnki.2096-4706.2024.05.023
摘 要:场景的深度估计在三维视觉领域有着广泛的应用。针对单目室内场景深度估计精度低、细粒度信息预测能力差等问题,提出一种基于注意力机制和多级校正的单目深度估计网络。该网络首先采用混合自注意力Transformer和卷积神经网络的双分支模块提取彩色图像的多分辨率特征,然后利用基于空间域注意力机制的模块对提取的多分辨率特征进行渐进融合,最后通过多级校正的方式处理融合后的特征,并渐进地估计出不同分辨率的深度图像。实验结果表明,与同类方法相比,所提出的网络可有效提高深度图像细粒度信息的预测能力,网络的多个评价指标均有不同幅度的提升。
关键词:单目深度估计;Transformer;注意力机制;多级校正
中图分类号:TP391 文献标识码:A 文章编号:2096-4706(2024)05-0106-05
Depth Estimation of Monocular Indoor Scenes Based on Attention Mechanism and Multi-level Correction
LIU Peng, DING Aihua, DOU Xinyu
(Intelligence and Information Engineering College, Tangshan University, Tangshan 063000, China)
Abstract: The depth estimation of scenes has a wide range of applications in the field of 3D vision. A monocular depth estimation network based on Attention Mechanism and multi-level correction is proposed to address the issues of low accuracy and poor prediction ability of fine-grained information in monocular indoor scene depth estimation. The network first uses a dual branch module with a self attention Transformer and a convolutional neural network to extract multi-resolution features of color images. Then, a module based on spatial domain Attention Mechanism is used to gradually fuse the extracted multi-resolution features. Finally, the fused features are processed through multi-level correction, and depth images with different resolutions are gradually estimated. The experimental results show that compared with similar methods, the proposed network can effectively improve the predictive ability of fine-grained information in depth images, and multiple evaluation indicators of the network have been improved to varying degrees.
Keywords: monocular depth estimation; Transformer; Attention Mechanism; multi-level correction
0 引 言
单目深度估计以单目RGB图像为输入,估计出图像描述的场景对象到拍摄相机的距离信息,即深度信息。获取的深度信息在室内场景的地图导航、目标检测、三维重建等任务中有着广泛的应用。但单目深度估计缺少诸如运动、立体视觉关系等可靠的深度线索,本质上是一个不适定问题,因此一直都是计算机视觉领域的难点课题。
目前主流的单目深度估计均采用基于深度学习的数据驱动方法,借助深度学习模型强大的特征学习和特征表示能力,从大量RGB图像到深度图像的映射过程中提取深度线索。Eigen等[1]首次应用卷积神经网络(Convolutional Neural Network, CNN)完成单目深度估计任务,此后,基于CNN的单目深度估计方法不断呈现[2-11]。例如,Zheng等[2]通过自定义的特征多尺度上卷积操作将编码器不同分辨率的层次化特征进行有效整合,实现编码器特征从粗到精处理的映射;Chen等[3]用一种自适应密集特征聚合模块融合多尺度特征,实现场景深度图像结构信息的有效推断;Liu等[5]使用跳跃连接将CNN不同阶段的相同分辨率特征进行有效融合,以提高深度图像的估计精度;Huynh等[7]引入非局部共平面性约束和非局部注意机制来提高深度图像中平面结构区域的估计效果。
鉴于Transformer模型优秀的全局建模能力,研究人员开始将各种视觉Transformer模型应用于单目深度估计任务[12-15]。例如,Bhat等[12]用一种基于Transformer模型的全局统计分析方法细化全卷积网络模型的输出,提高了深度图像的整体估计效果。Ranftl等[13]提出一種通用的密集预测Transformer模型,在语义分割和单目深度估计方面均取得不错的效果。文献[14,15]设计的单目深度估计网络,均采用了Transformer模型实现编码器和CNN实现解码器的设计架构。
为了进一步提高单目深度估计网络的预测精度,本文对文献[14,15]使用的Transformer编码器-CNN解码器基础框架进行优化和改进,提出一种基于注意力机制和多级校正的单目深度估计网络。网编码器部分将Transformer模型和CNN有效结合,捕获场景全局上下文信息的同时,增强对细节特征的处理能力。解码器部分采用金字塔结构的特征处理方式,利用空间域注意力机制实现特征的渐进融合,利用多级校正的方式逐步恢复深度图像,以提高对深度图像细粒度信息的预测精度。
1 本文方法
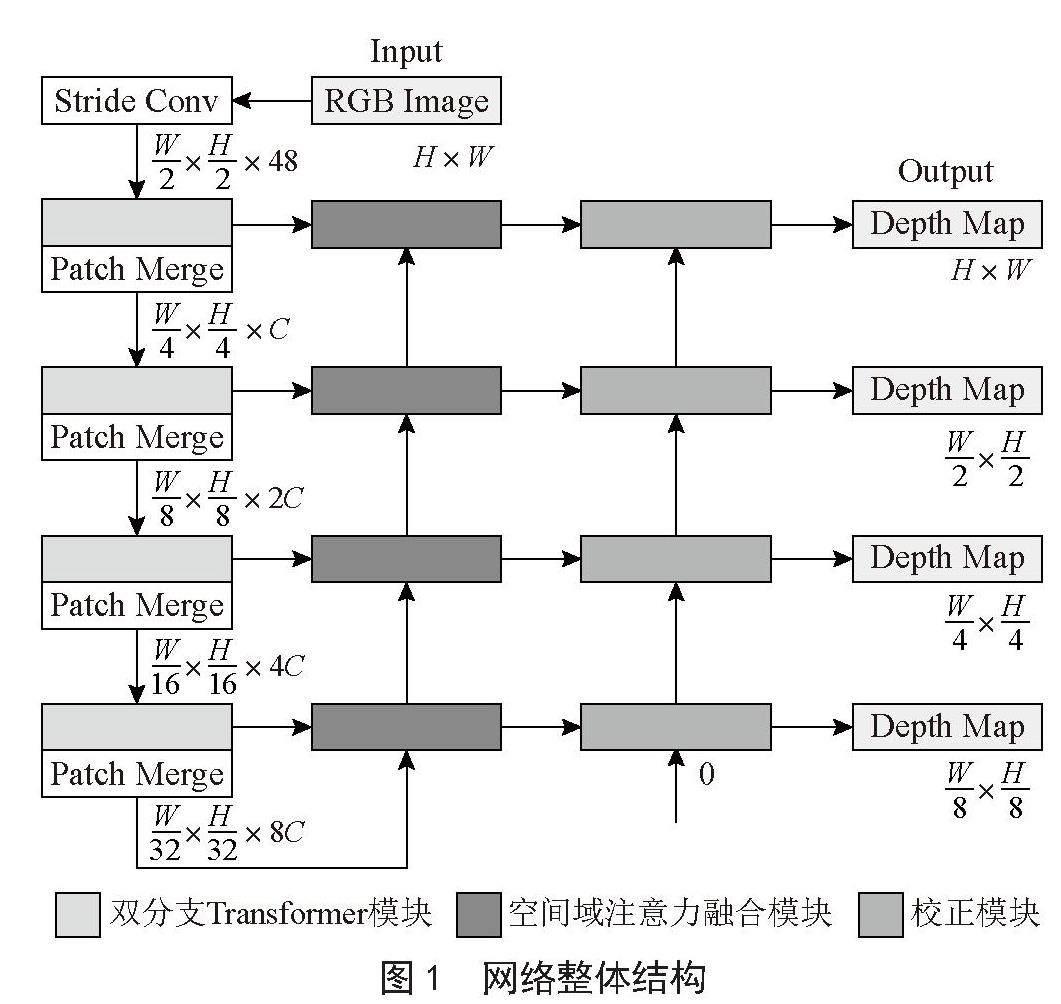
1.1 网络整体结构
本文提出的单目深度估计网络结构如图1所示。对于输入分辨率为H×W的RGB图像,首先,利用与ResNet [16]相同的跨步卷积进行浅层特征提取和特征分块,产生维度为H/2×W/2×48的特征。然后,通过设计的双分支Transformer模块进行进一步的特征提取,同时通过Patch Merge操作进行特征降维。经过四步的特征提取和特征降维,有效提取出RGB图像的多分辨率特征,对应特征的维度分别为H/4×W/4×C、H/8×W/8×2C、H/16×W/16×4C、H/32×W/32×8C,其中的参数C设置为96。
图1 网络整体结构
接着,几个设计的空间域注意力融合模块和校正模块均以自上而下的层次金字塔模式协同工作。空间域注意力融合模块对上述四组特征进行渐进融合,校正模块对融合后特征进行校正的同时,实现深度图像的渐进估计。估计出的深度图像分辨率分别为H/8×W/8、H/4×W/4、H/2×W/2、H×W。
1.2 子功能模块结构
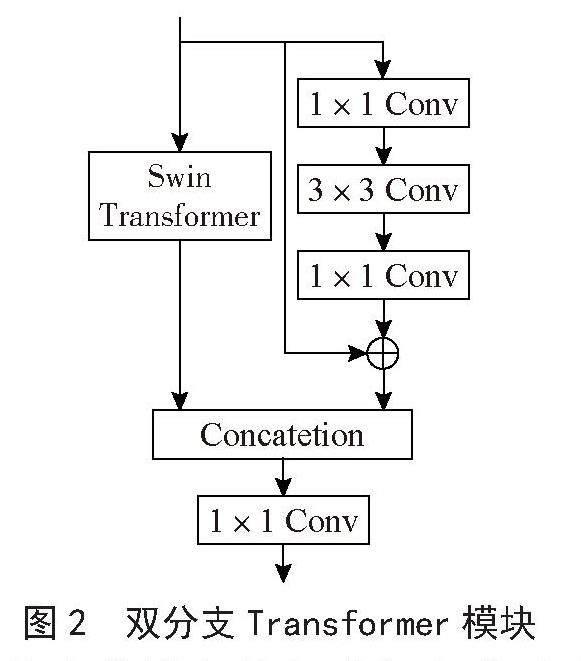
对RGB图像进行多分辨率特征提取时,本文设计了一种双分支Transformer模块,结构如图2所示。考慮到Transformer模型和CNN特征处理时的不同优势,该模块采用了并行混合Transformer和CNN的设计方式,利用CNN提取局部细节信息,利用Transformer捕获全局上下文信息。Transformer分支使用Swin-Transformer(S-T)[17]结构。S-T通过滑动窗口和分层表示的结构设计,进一步提高了Transformer模型的计算效率。卷积分支使用残差卷积结构,对应的Bottleneck由具有相同信道大小的1×1卷积、3×3卷积和1×1卷积串联组成。通过Concatenation和1×1卷积的组合实现两个分支输出特征的融合,以同时聚合全局和局部特征表示。
图2 双分支Transformer模块
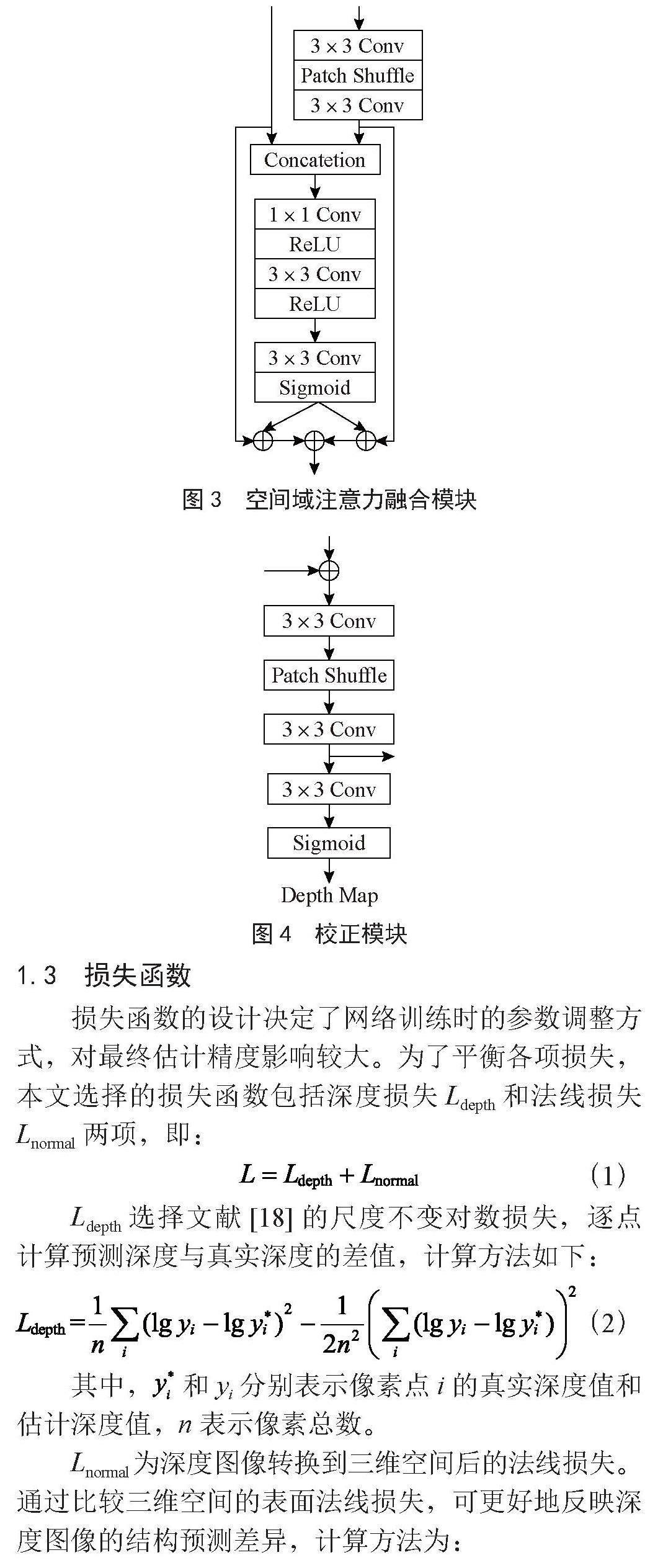
对提取的多分辨率特征进行渐进融合时,为了提高细粒度特征信息的处理能力,本文设计了一种空间域注意力融合模块,结构如图3所示。首先,使用3×3卷积+ Patch Shuffle + 3×3卷积的操作实现低分辨率特征的上采样。然后,通过Concatenation实现与高分辨率特征的合并,并对合并后特征通过1×1卷积+ ReLU激活函数和3×3卷积+ ReLU激活函数的两步操作实现特征的提取。接着,通过3×3卷积和Sigmoid函数的组合产生两个空间域二维注意力图。最后,将这两个注意力图分别与高分辨率特征和上采样后的低分辨率特征相乘,实现对特征的细化处理。
本文通过设计的校正模块实现融合后特征到深度图像的映射,这种映射关系的建立使得融合后特征的指向性更强,从而达到校正特征的作用。同时,深度图像的渐进预测也有利于对深度图像细粒度信息的预测。校正模块结构如图4所示,首先,当前分辨率的校正模块输出特征与融合后特征进行按元素求和。然后,经过3×3卷积+ Patch Shuffle + 3×3卷积的组合实现特征的上采样,得到下一分辨率的校正特征。最后,校正特征通过3×3卷积和Sigmoid函数的组合实现深度图像的预测。本文将初始分辨率的校正特征设置为0。
图3 空间域注意力融合模块
图4 校正模块
1.3 损失函数
损失函数的设计决定了网络训练时的参数调整方式,对最终估计精度影响较大。为了平衡各项损失,本文选择的损失函数包括深度损失Ldepth和法线损失Lnormal两项,即:
(1)
Ldepth选择文献[18]的尺度不变对数损失,逐点计算预测深度与真实深度的差值,计算方法如下:
(2)
其中, 和yi分别表示像素点i的真实深度值和估计深度值,n表示像素总数。
Lnormal为深度图像转换到三维空间后的法线损失。通过比较三维空间的表面法线损失,可更好地反映深度图像的结构预测差异,计算方法为:
(3)
其中, 和ni分别表示像素点i的真实表面法线值和估计表面法线值,表面法线的计算按照参考文献[19]提供的方法。
2 实验分析
2.1 实验设置
本文选取室内场景数据集NYU Depth V2 [20]进行模型的训练和测试。
对于NYU Depth V2数据集,按照通用的分类方法,选择249个场景,约5万组图像对模型进行训练;选择215个场景,654组图像对模型进行测试。深度图像和RGB图像均居中剪切成608×456像素,以去除深度值偏差较大的边缘区域。训练数据集的增强操作参照文献[18]中的通用做法。
网络模型的搭建基于PyTorch深度学习开发框架。训练时,使用Adam优化器不断调整网络参数,基本学习率设置为0.000 1,并且每5个周期将其降低10%,参数β1 = 0.9,β2 = 0.999,并使用0.000 1的衰减率。训练参数Batch设置为16,Epoch设置为30。
选择单目深度估计任务常用的性能指标进行定量评价,各评价指标和对应算式为:
1)均方根误差(RMSE):
2)绝对相对差(Abs Rel):
3)均方对数误差(Log10):
4)阈值内准确度δi,即相对误差在1.25k以内的像素比例,其中:
2.2 与现有方法的对比
表1显示了本文方法与几种先进的单目深度估计方法的性能指标比较结果,其中,↑表示指标的数值越大越好,↓表示指标的数值越小越好。
从表1可以看出,本文方法的各项性能指标均优于其他方法。相比于AdaBins[12],误差指标Abs Rel降低了5.8%,精度指标δ1提升了1.3%。表1也给出了模型参数和运算速度FPS的对比结果,可以看出,本文所提出的网络在深度估计效果、模型参数、运算速度上实现了很好的平衡。
表1 NYU Depth V2数据集深度估计性能指标对比
方法 误差/%↓ 准确度/%↑ FPS↑ 模型
参数↓
Abs Rel Log10 RMSE δ1 δ2 δ3
DORN[4] 11.5 5.1 50.9 82.8 96.5 99.2 — —
BTS[18] 11.0 4.7 39.2 88.5 97.8 99.4 24.5 47.0M
DAV[7] 10.8 — 41.2 88.2 98.0 99.6 — 25.0M
DPT[13] 11.0 4.5 35.7 90.4 98.8 99.6 24.3 123.0M
VNL[6] 10.8 4.8 41.6 87.5 97.6 99.4 53.6 90.4M
文獻[14] 10.5 4.4 35.8 90.5 98.5 99.6 62.0 45.0M
AdaBins[12] 10.3 4.4 36.4 90.3 98.4 99.7 19.9 78.0M
本文方法 9.7 4.1 35.1 91.5 99.2 99.7 44.3 68.2M
图5展示了部分测试数据集深度估计的可视化结果。可以看出,本文方法对桌椅、家居的细节深度边界的预测效果更好。从图5第一行和第五行的深度估计结果也可以看出,本文方法预测的深度变化更加接近深度真值的变化。因此,定量和定性的对比结果表明,本文方法进一步提高了单目深度估计的精度,对深度图像细粒度信息的预测效果更佳。
图5 NYU Depth V2数据集可视化结果对比
2.3 消融实验
在数据集NYU Depth V2上进行了一系列消融性实验,以验证各子功能模块设计的有效性,结果如表2所示。
为了验证设计的双分支Transform模块提取RGB图像特征的有效性,用单分支S-T模块进行了替换。由表2的第一行和第四行可以看出,混合S-T和残差卷积的双分支Transform结构的各项误差性能指标均优于单分支S-T。
为了验证特征融合模块设计的有效性,对低分辨率特征上采样后,采用了典型的跳跃连接的融合方式进行了替换,结果如表2的第二行所示。显然,本文设计的空间域注意力模块特征融合的效果优于局部融合方式。
此外,对多级校正的效果进行了分析。对比只在融合特征的最高分辨率处进行一次校正并预测深度的方式(表2的第三行),多级校正的方式可以获得更准确的估计结果。
表2 消融实验性能指标对比
方法 误差/%↓ 准确度/%↑
Abs Rel Log10 RMSE δ1 δ2 δ3
单分支S-T 10.2 4.4 36.4 90.8 99.0 99.7
局部融合 10.5 4.6 35.8 90.6 98.9 99.6
一次校正 11.0 4.7 39.2 90.5 98.7 99.6
本文方法 09.7 4.1 35.1 91.5 99.2 99.7
3 结 论
本文提出了一种基于注意力机制和多级校正的单目深度估计网络。网络将自注意力S-T模型和残差卷积有效结合,用于RGB图像的特征提取;设计空间域注意力融合模块,用于特征的渐进融合;利用设计的校正模块校正融合后特征,实现深度图像的渐进输出。室内场景公开数据集上的实验结果表明,相较于现有的单目深度估计方法,本文网络能取得更好的估计效果。另外,本文也做了一系列对比试验验证网络子模块设计的有效性。下一步研究工作将考虑把本文的深度估计网络应用与室内场景的单目视觉SLAM系统。
参考文献:
[1] EIGEN D,PUHRSCH C,FERGUS R. Depth map prediction from a single image using a multi-scale deep network [C]//Proceedings of the 28th International Conference on Neural Information Processing Systems(NIPS).Montreal:MIT Press,2014:2,2366-2374.
[2] ZHANG Z Y,XU C,YANG J,et al. Deep hierarchical guidance and regularization learning for end-to-end depth estimation [J].Pattern Recognition,2018,83:430-442.
[3] CHEN X T,CHEN X J,ZHA Z J. Structure aware residual pyramid network for monocular depth estimation [C]//Proceedings of the 28th International Joint Conference on Artificial Intelligence(IJCAI).Macao:AAAI Press,2019:694-700.
[4] FU H,GONG M M,WANG C H,et al. Deep Ordinal Regression Network for Monocular Depth Estimation [C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City:IEEE,2018:2002-2011.
[5] LIU J,LI Q,CAO R,et al. A contextual conditional random field network for monocular depth estimation [J/OL].Image and Vision Computing,2020,98:103922[2023-06-30].https://doi.org/10.1016/j.imavis.2020.103922.
[6] YIN W,LIU Y F,SHEN C H,et al. Enforcing Geometric Constraints of Virtual Normal for Depth Prediction [C]//2019 IEEE/CVF International Conference on Computer Vision(ICCV).Seoul:IEEE,2019:5683-5692.
[7] HUYNH L,NGUYEN-HA P,MATAS J,et al. Guiding Monocular Depth Estimation Using Depth-Attention Volume [C]//2020 Proceedings of the European Conference on Computer Vision(ECCV).Glasgow:Springer,Cham,2020:581-597.
[8] LIU P,ZHANG Z H,MENG Z Z,et al. Monocular depth estimation with joint attention feature distillation and wavelet-based loss function [J].Sensors,2021,21(1):54-75.
[9] WANG J R,ZHANG G,YU M,et al. Attention-Based Dense Decoding Network for Monocular Depth Estimation [J].IEEE Access,2020,8:85802-85812.
[10] RANFTL R,LASINGER K,HAFNER D,et al. Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-Shot Cross-Dataset Transfer [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2022,44(3):1623-1637.
[11] WANG Q L,WU B G,ZHU P F,et al. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks [C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR).Seattle:IEEE,2020:11531-11539.
[12] BHAT S F,ALHASHIM I,WONKA P. AdaBins: Depth Estimation Using Adaptive Bins [C]//2021 Proceedings of the IEEE/CVF International Conference on Computer Vision(CVPR).Nashville:IEEE,2021:4008-4017.
[13] RANFTL R,BOCHKOVSKIY A,KOLTUN V. Vision Transformers for Dense Prediction [C]//2021 Proceedings of the IEEE/CVF International Conference on Computer Vision(CVPR).Montreal:IEEE,2021:12159-12168.
[14] 吳冰源,王永雄. 面向全局特征Transformer架构的单目深度估计 [J/OL].控制工程,2023:1-7[2023-06-30].https://
doi.org/10.14107/j.cnki.kzgc.20220364.
[15] ZHANG C,XU K,MA Y X,et al. GFI-Net: Global Feature Interaction Network for Monocular Depth Estimation [J/OL].Entropy,2023,25(3):421[2023-06-30].https://doi.org/10.3390/e25030421.
[16] HE K M,ZHANG X Y,REN S Q,et al. Deep Residual Learning for Image Recognition [C]//2016 Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Las Vegas:IEEE,2016:770-778.
[17] LIU Z,LIN Y T,CAO Y,et al. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows [C]//2021 IEEE/CVF International Conference on Computer Vision(ICCV).Montreal:IEEE,2021:9992-10002.
[18] LEE J H,HAN M K,KO D W,et al. From Big to Small: Multi-Scale Local Planar Guidance for Monocular Depth Estimation [J/OL].arXiv:1907.10326 [cs.CV].[2023-06-25].https://arxiv.org/abs/1907.10326v5.
[19] PATIL V,SAKARIDIS C,LINIGER A,et al. P3Depth: Monocular Depth Estimation with a Piecewise Planarity Prior [C]//2022 Proceedings of the IEEE/CVF International Conference on Computer Vision(CVPR).New Orleans:IEEE,2022:1600-1611.
[20] SLBERMAN N,HOIEM D,KOHLI D,et al. Indoor segmentation and support inference from RGBD images [C]//Proceedings of the 12th European conference on Computer Vision.Adobe:Springer-Verlag,2012:746-760.
作者簡介:刘鹏(1982—),男,汉族,辽宁沈阳人,讲师,硕士,研究方向:深度学习、计算机视觉;丁爱华(1978—),女,汉族,江苏南通人,教授,硕士,研究方向:机器视觉、深度学习;窦新宇(1983—),男,汉族,河北唐山人,副教授,博士,研究方向:机器学习、图像处理。
猜你喜欢
计算机应用(2019年3期)2019-07-31 12:14:01
无线互联科技(2019年9期)2019-07-29 00:41:36
无线互联科技(2019年9期)2019-07-29 00:41:36
智能计算机与应用(2019年3期)2019-07-01 02:35:55
智能计算机与应用(2019年3期)2019-07-01 02:35:55
智能计算机与应用(2019年3期)2019-07-01 02:35:55
电子技术与软件工程(2019年5期)2019-06-20 10:31:23
软件导刊(2019年1期)2019-06-07 15:08:13
数字技术与应用(2019年2期)2019-05-14 08:25:10
现代电子技术(2018年8期)2018-04-13 06:36:32
