
多特征融合的中文实体关系抽取研究
2019-07-29 00:41孙康康
无线互联科技 2019年9期
关键词:注意力机制
孙康康
摘 要:词性等特征在句子中扮演着重要的角色,往往能揭示命名实体之间的关系,而当前的实体关系抽取任务大多仅基于词向量进行,忽视了词性等对实体关系抽取任务有益的特征。因此,文章采用了一种多特征融合的方式进行中文实体关系抽取模型的训练,在以词向量作为输入单元的前提下融合了句子中词语的词性、距离实体对的位置、实体标注相关特征,并以双向长短期记忆网络结合注意力机制的模型进行了中文实体关系抽取的实验,实验结果表明,基于多特征融合的训练方式提升了中文实体关系抽取的效果。
关键词:实体关系抽取;多特征;双向长短期记忆网络;注意力机制
实体关系抽取(Entity Relation Extraction,ERE)的主要任务是识别并抽取实体对间存在的语义关系,本文进行的实体关系抽取工作是为了从文本数据中提取实体间的语义关系作为知识表示的一部分。当前国内外主流的实体关系抽取大多采用机器学习的方法,根据其对标注语料库规模的不同需求,分为有监督学习、弱监督学习和无监督学习等方法[1]。弱监督方法中常以远程监督的方式进行实体关系抽取,是在基于现有知识库中存在领域知识的前提下进行的,而现有知识库并不能完全涵盖某些领域的实体关系。此外,基于无监督的实体关系抽取技术目前识别效率较低,难以投入实际应用。
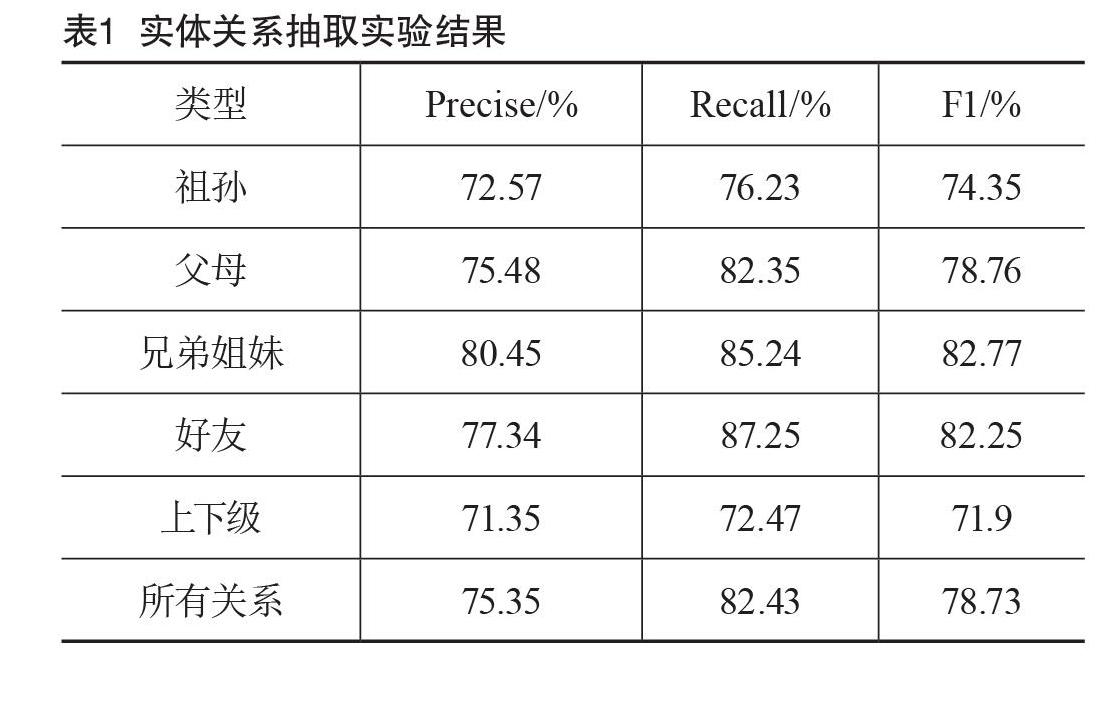
为此,本文采用了基于有监督学习方法的BiLSTM-Attention模型,并以人物关系抽取为例进行实体关系抽取的实验,其中,针对模型注意力不足的问题,提出了一种多特征融合的改进措施。此外,在实验之初,本文定义了5种人物之间的关系,分别为祖孙、父母、兄弟姐妹、好友和上下级。
1 数据预处理
本文采用了中国科学院软件研究所的刘焕勇[2]及Guan[3]在Github上发布的人物关系语料库,将训练语料的处理主要分为两部分。
(1)采用分词工具,通过哈尔滨工业大学语言技术平台(Language Technology Platform,LTP)对训练语料进行分词处理,为了保证分词的准确性,将语料库中的实体添加到分词工具的字典中,并采用word2vec对分词后的语料数據进行分布式词向量的训练,训练模型采用Skip-Gram,词向量的维度为100维。
(2)采用神经语言程序学(Neuro-Linguistic Programming,NLP)工具(哈工大LTP)对训练语料进行词性标注,获得语料库中各语句的词性标注序列;计算语料库中各词与实体对的相对位置,生成各语句的位置标签序列;将语料库中的实体进行标注,获得各语句的实体标签序列。分别对以上序列进行Word embedding操作,由于以上序列的相关特征较少,因此,采用随机初始化的方式,序列维度均为10,其中,相对位置标注序列可以分为距离实体1和实体2的相对位置,在此分别对其进行向量随机初始化。
2 多特征融合
使用词性标注工具对句子中的词语进行词性分析,获得该句子对应的词性标注序列;对句子中各词距离实体对的相对位置进行标注,以及对实体的标注,获得该句子的位置标注序列和实体标注序列。将以上标注序列分别采用随机初始化向量的操作得到各序列的向量化表示,然后与句子中各词的向量表示进行拼接,通过融合句子的词性特征、位置特征及命名实体特征,增强句子中对关系抽取的有益成分,具体做法如下。
以分词后的语句“母亲 章含之 是 对洪晃 影响 最大 的 一个人 。”为例,该语句中命名实体为“章含之”和“洪晃”,其中语句中各词对应的词性标注序列POS为:
语句中各词距离实体1和实体2的相对位置标注序列RP1和RP2分别为:
语句中各词对应的实体标注序列NER为:
语句各词对应的分布式向量Wi表示如下:
最终经融合后语句中各词的向量表示为:
3 实验结果及分析
本文采用了BiLSTM-Attention模型对人物关系进行抽取。首先,进行参数调优实验,分别选择对模型性能有影响的batch_size、优化器、隐藏层节点数及学习速率进行实验。经过参数调优,最终确定的模型参数为batch_size:32,优化器Adam,隐藏层节点数200,学习速率0.001。
通过对参数的选择实验,模型最终在测试集上取得了78.5%的F1值,实验结果如表1所示。
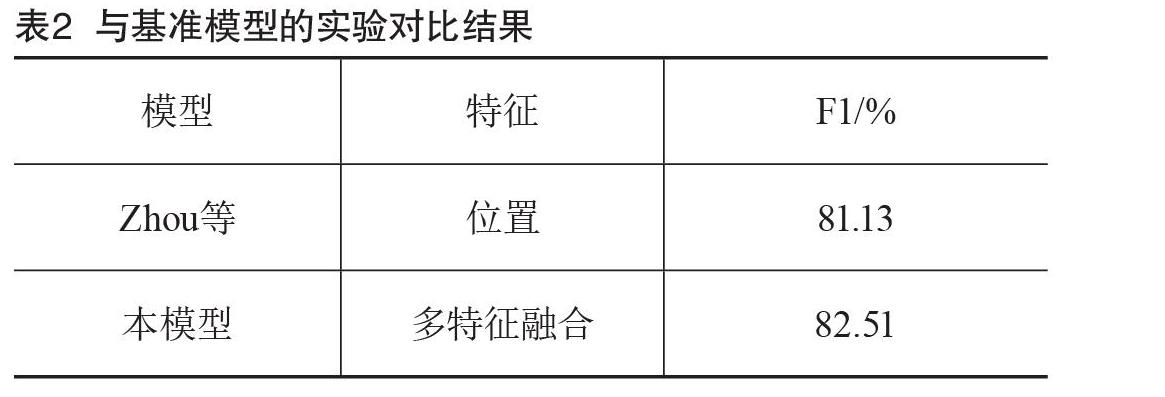
为了验证多特征融合的有效性,本文选择与2016年Zhou等[4]提出的基准模型进行对比,对比结果如表2所示。该文同样采用了双向长短期记忆网络(Long Short-Term Memory,LSTM)结合注意力机制的模型进行实体关系抽取,但并未采用任何词性及实体标注的信息,在采用与该论文相同数据集的情况下,本模型的F1值比其高出1.38%。
4 结语
本文选择了BiLSTM-Attention模型对人物关系进行抽取,针对BiLSTM-Attention模型中注意力层不足的问题,提出了多特征融合的改进措施,并针对改进措施进行了模型对比分析,验证了多特征融合的有效性。
[参考文献]
[1]胡亚楠,舒佳根,钱龙华,等.基于机器翻译的跨语言关系抽取[J].中文信息学报,2013(5):191-197.
[2]LIU H Y.Person relation knowledge graph[EB/OL].(2018-12-15)[2019-05-13].https//github.com/liuhuanyong/person relation knowledge graph.
[3]GUAN W.Small-Chinese-Corpus[EB/OL].(2017-09-13)[2019-05-13].https//github.com/crownpku/Small-Chinese-Corpus/tree/master/relation_multiple_chi.
[4]ZHOU P,SHI W,TIAN J,et al.Attention-based bidirectional long short-term memory networks for relation classification[C].Shanghai:Meeting of the Association for Computational Linguistics,2016.
Abstract:Features such as part of speech play an important role in sentences, and often reveal the relationship between named entities. The current task of extracting entity relationships is mostly based on word vectors, ignoring the characteristics of part-of-speech and other useful tasks for extracting entities. Therefore, this paper adopts a multi-feature fusion method to train Chinese entity relationship extraction model. Under the premise of word vector as input unit, the word part of the sentence, the position of the distance entity pair and the entity labeling related feature are combined. The experiment of Chinese entity relationship extraction is carried out by using the bi-long short-term memory network combined with the attention mechanism model. The experimental results show that the training method based on multi-feature fusion improves the effect of Chinese entity relationship extraction.
Key words:entity relationship extraction; multi-feature; bi-long short-term memory network; attention mechanism
猜你喜欢
计算机应用(2019年4期)2019-08-01
计算机应用(2019年3期)2019-07-31
智能计算机与应用(2019年3期)2019-07-01
智能计算机与应用(2019年3期)2019-07-01
智能计算机与应用(2019年3期)2019-07-01
现代电子技术(2018年8期)2018-04-13
智能计算机与应用(2017年5期)2017-11-08
