
基于注意力机制的改进CLSM检索式匹配问答方法
2019-08-01 01:54于重重曹帅潘博张青川徐世璇
计算机应用 2019年4期
关键词:注意力机制
于重重 曹帅 潘博 张青川 徐世璇


摘 要:针对检索式匹配问答模型对中文语料适应性弱和句子语义信息被忽略的问题,提出一种基于卷积神经网络潜在语义模型(CLSM)的中文文本语义匹配模型。首先,在传统CLSM基础上进行改进,去掉单词和字母的N元模型层,以增强模型对中文语料的适应性;其次,采用注意力机制算法,针对输入的中文词向量信息建立实体关注层模型,以加强句中核心词的权重信息;最后,通过卷积神经网络(CNN)有效地捕获输入句子上下文结构方面信息,并通过池化层对获取的语义信息进行降维。基于医疗问答对数据集,将改进模型与传统语义模型、传统翻译模型、深度神经网络模型进行对比,实验结果显示所提模型在归一化折现累积增益(NDCG)方面有4~10个百分点的提升,优于对比模型。
关键词:潜在语义模型;注意力机制;检索式匹配问答
中图分类号:TP391
文献标志码:A
文章编号:1001-9081(2019)04-0972-05
Abstract: Focusing on the problem that the Retrieval Matching Question and Answer (RMQA) model has weak adaptability to Chinese corpus and the neglection of semantic information of the sentence, a Chinese text semantic matching model based on Convolutional neural network Latent Semantic Model (CLSM) was proposed. Firstly, the word-N-gram layer and letter-N-gram layer of CLSM were removed to enhance the adaptability of the model to Chinese corpus. Secondly, with the focus on vector information of input Chinese words, an entity attention layer model was established based on the attention mechanism algorithm to strengthen the weight information of the core words in sentence. Finally, Convolutional Neural Network (CNN) was used to capture the input sentence context structure information effectively and the pool layer was used to reduce the dimension of semantic information. In the experiments based on a medical question and answer dataset, compared with the traditional semantic models, traditional translation models and deep neural network models, the proposed model has 4-10 percentage points improvement in Normalized Discount Cumulative Gain (NDCG).
Key words: Convolutional Latent Semantic Model (CLSM); attention mechanism; Retrieval Matching Question and Answer (RMQA)
0 引言
检索式匹配问答系统的研究伴随搜索引擎技术的发展不断推进。1999年,随着文本信息检索会议中自动问答任务(Text REtrieval Conference (Question & Answering track), TREC(QA))[1]的发起,检索式匹配问答系统迎来了真正的研究进展。TREC(QA)的任务是给定特定Web数据集,从中找到能够回答问题的答案。这类方法是以检索和答案抽取为核心的问答过程,具体过程包括问题分析、篇章检索和答案抽取[2]。
根据答案抽取方法的不同,现有的检索式匹配问答系统可以分为两类[3]:第一类是基于模式匹配和统计文本信息抽取的问答方法。该方法需要人工线下设定好各类问题答案的模式,需要构建大量的问答模式,代价高。第二类是利用神经网络模型对文本作语义表示后进行语义匹配的方法。2013年Huang等[4]针对搜索引擎中问答之间的语义匹配问题,提出了基于多层感知器的深度语义表示模型(Deep Structured Semantic Model, DSSM)。在DSSM中,输入层是基于文本的词袋向量,该模型忽略了文本中的词法、句法和语法信息,将其仅仅看作词的多种组合,这样就无法捕捉句子的上下文信息。基于此,2014年Shen等[5]对DSSM作出改进,提出了一种基于卷积神经网络的隐语义模型(Convolutional Latent Semantic Model, CLSM)。该模型将文本的语义信息加入到检索问答过程中,有效地提高了检索式问答模型的精确度。2016年CLSM得到了广泛应用,如用它来捕捉目标语言在局部上下文或者全局上下文中的含义[6],也有人用它来构建推荐系统[7]。
CLSM是基于英文文本作出的改进:其中字母N元组合模型主要是针对大量不同的英文单词,从中提取出多种字母组合,对其进行特征提取。然而中文汉字的个数远远超过了英文字母的个数,汉字的组合数更是远远超过了英文字母的组合数,因此通过原始CLSM很难对中文文本进行语义特征提取。本文结合中文语料的特点,提出了一种基于注意力机制的改进CLSM检索式匹配问答模型,该模型一方面解决了由于中文汉字远远多于英文字母而导致的文本特征难提取问题;另一方面加入了基于命名實体的注意力机制,能有效提高匹配问答结果的准确率。
1 CLSM
如图1所示,CLSM主要是将一个潜在语义空间中任意长度的词语序列所包含的语义信息映射成一个低维向量。
图1中:90k表示在不包含下划线和标点符号的情况下;字母的N元模型层维度是90k;卷积层以及池化层的维度均为300;最终输出语义信息的维度是128。
CLSM主要由五个部分构成:
1)单词的N元模型层。此部分的作用是通过一个自定义大小的滑动窗口将输入的文本序列划分为多个固定长度的单词组合。
2)字母的N元模型层。此部分的作用是将第1)步中的单词组合转换为由字母组合的向量表示。Wf是转移矩阵。对于单词N元模型层中的第t个N元单词组合,其对应的N元字母组合表示为:
3)卷积层。该层通过自定义大小的滑动窗口将基于每个单词的N元字母特征lt转换为其在上下文中的特征向量ht。
4)最大池化层。通过最大池化将单词在上下文中的特征向量ht转化为一个固定长度的句子级特征向量v。
5)語义层。为输入的单词序列提取高级特征语义向量y。
CLSM是基于英文文本提出的语义特征提取模型,其单词N元模型层和字母N元模型层都是为了提取英文文本中的特征信息,然而中文文本中汉字的组合数量远远超过了英文字母的组合数量,因此通过N元模型不能有效提取其重要特征。基于此,本文对CLSM进行了改进。
2 基于CLSM的改进模型
在CLSM中,CNN网络扮演了极其重要的作用,对文本序列进行字母N元组合卷积。由于本文处理的是中文语料,其汉字组合总数远多于字母组合总数,因此需要将中文语料进行分词,将英文字母组合替换成中文词组,用中文词组作为文本序列基本单元。
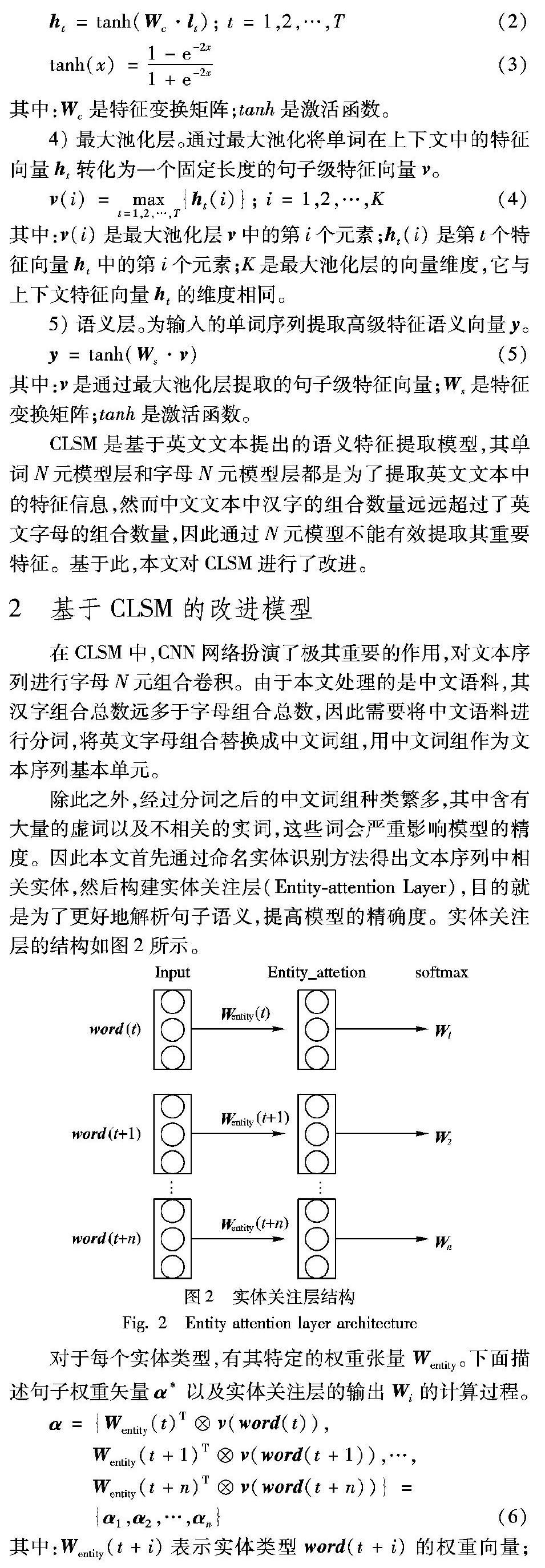
除此之外,经过分词之后的中文词组种类繁多,其中含有大量的虚词以及不相关的实词,这些词会严重影响模型的精度。因此本文首先通过命名实体识别方法得出文本序列中相关实体,然后构建实体关注层(Entity-attention Layer),目的就是为了更好地解析句子语义,提高模型的精确度。实体关注层的结构如图2所示。
将Wi输入CNN之后,模型训练与CLSM相同。下面给出数据结构的形式化定义:
定义1 实体类型所对应的权重向量Wentity(t+i)定义为一个和输入词向量v(word(t+i))维度相同的向量。
定义2 实体关注层的输出Wi指的是输入词向量矩阵Vx经过实体关注层后的输出矩阵,包含句子本身的信息及其权重信息。
定义3 表示层的输出y即为最终的语义输出,其大小定义为128维。
步骤3 构建CLSM表示层。该层的输入为步骤2中计算获得的突出命名实体信息的矩阵Wi,通过与win=1×3进行卷积运算之后得到初步得到语义信息ht,最终输出为y=tanh(Ws·max(ht))。
步骤4 最后借助语义匹配模型,通过计算向量余弦相似度来获得问答对匹配度sim(ysrc, ytgt),其中ysrc代表问题的语义信息, ytgt代表回答的语义信息。
模型结构如图3所示。依据经验,本文将词向量的维度设为300;卷积层和最大池化层的维度分别设置为300和128;学习效率初始值为0.01;卷积层的Filter的大小设为1×3,这样既包含了上下文信息,也去除了冗余信息。其输出是可变长度序列,长度与输入序列的长度成比例。 在输入序列的开始和结尾分别添加一个特殊的“填充”单词〈s〉,目的是形成词组序列中任何位置的单词的完整窗口。
3 实验与结果分析
3.1 实验数据和评测指标
本文采用寻医问药网站上大规模的在线问答对数据作为训练评估模型的数据集。问答对数据经过分词和标签替换等预处理后输入模型。问答对有47万对。数据分为三个部分:训练集40万对、验证集4万对、测试集3万对。每个问答对中问句和答句的平均长度分别为25词和50词。问答对数据形式如表1所示。实体代表的是医学领域的核心词汇,比如疾病、症状的名称等。如表2所示。
神经网络的初始权重通过随机初始化获取。模型采用基于小批量随机梯度下降的方法进行训练,每个最小批次包括1024个训练样本。实验使用双重交叉验证方法。模型的评估都是通过NDCG(Normalized Discounted Cumulative Gain)方法[9]来衡量的。NDCG常用于作为对排序结果的评价指标,当通过模型得出某些元素的顺序时,便可以通过NDCG来测评这个排序结果的准确度,其计算公式如下:
其中:NDCG@K表示前K个位置累计得到的效益;lb (i+1)表示第i个位置上答案的影响因子的倒数;r(l)表示第l个答案的相关度等级,如3表示非常相关,2表示较相关,1表示相关,0表示无关,-1表示垃圾文件。
NDCG其实是由DCG的值计算得出的,由式(10)可看出,分子为模型计算出的Ranking的DCG值,分母为理想情况下的DCG值。
3.2 实验设计
本文设计了三组对比实验:1)与传统语义模型的对比实验。为了验证本文模型的优越性,设计了在实验数据集与模型参数均相同的情况下,本文模型与两组传统潜在语义模型的对比实验。潜在语义模型只能以监督学习方式或非监督学习方式在文档中学习,其中双语主题模型(Bilingual Topic Model, BLTM)[10]是监督学习,而概率潜在语义分析模型(Probabilistic Latent Semantic Analysis, PLSA)[11]和文档主题生成模型(Latent Dirichlet allocation, LDA)[12]是非监督学习。实验结果如表3所示。
2)與传统翻译模型的对比实验。目前,很多学者将问答对看成源语言和目标语言,通过用翻译模型计算二者的短语与短语之间的对齐关系来建立简单的问答匹配模型。因此,为了验证本文的改进模型较传统翻译模型的优越性,设计了一个基于短语的翻译模型(Phrase-based Translation Model, PTM)[13]和一个基于词的翻译模型(Word-based Translation Model, WTM)[14]的对比实验,PTM旨在直接模拟多词短语中的上下文信息。而WTM实质上是PTM的一个特例。实验结果如表4所示。
3)与深度神经网络模型的对比实验。为了验证改进之后模型的准确性,设计了基于深度神经网络模型的对比实验。本文模型是检索式问答模型,也就是说从众多候选答案中通过某种方法筛选出最符合要求的答案,理论上可以看作是对候选答案进行分类,因此加入一定数量的负样本可以增强和验证模型的检索匹配的能力。在进行与深度神将网络模型的对比实验之前,本文按照以往的经验分别将负样本数设置为0~100,发现负样本数为50时训练效果最好,其次是4。因此,分别将J(代表负样本数量)设置为50和4进行了对比实验。实验结果如表5所示。
3.3 结果分析
1)与传统语义模型的对比实验。从表3可看出,CLSM+entity_attention模型明显优于传统的潜在语义模型:在NDCG@1方面较PLSA提升了11个百分点,在NDCG@3方面较LDA提升了12个百分点,与BLTM相比,模型的平均精度提高了10个百分点。PLSA和LDA均采用了词袋(bag of words)的方法将每一篇文档视为一个词频向量,从而将文本信息转化为了易于建模的数字信息,导致词与词之间的顺序信息丢失,这不仅简化了问题的复杂性,也降低了模型的精度。本文提出的改进模型中通过卷积神经层恰当地解决了这一问题。
2)与传统翻译模型的对比实验。从表4可看出,在检索式问答场景下,PTM优于WTM;而CLSM+entity_attention模型与PTM和WTM相比,均有一定幅度的提升。近几年来,在统计机器翻译领域,基于短语的翻译模型的性能优于基于词的翻译模型;但对于句子中非连续的固定搭配等问题仍然没有得到有效的解决。本文通过自定义大小的滑动窗口来抽取句子中基于词的上下文信息,然后通过最大池化层进行信息筛选,从而提升了模型的优越性。
3)与深度神经网络模型的对比实验。从表5可看出:CLSM+entity_attention模型较CLSM在NDCG方面有4个百分点的提升,说明实体关注层对模型的精确度提高具有极其重要的作用。在负样本数量J的设置方面,分别进行了三组对比实验:DSSM、CLSM以及CLSM+entity_attention,J=50时三者各自的NDCG@1和NDCG@2比J=4时均有一定幅度的提升,因此本文将J设置为50。
综上所述,CLSM+entity_attention能够通过实体关注层加强核心词的信息,同时利用卷积神经网络有效地捕获语义匹配有用的上下文结构方面信息,从而提升检索式匹配问答的准确率。
4 结语
CLSM的新型深度学习架构主要由CNN的卷积结构支撑,一般通过卷积层来提取句子级别的特征,通过最大池化层来提取N-gram级别的局部上下文特征。本文在此基础上进行调整,加入了基于实体类型的关注层,同时与几种最先进的语义模型进行比较,发现在大规模真实问答数据集上,改进的CLSM检索式匹配问答模型可进一步提高模型对句子的语义理解能力,在NDCG方面有4%以上的提升。不过该模型仍然存在不足,即用于训练模型的中文语料句子复杂度是不同的,本文主要针对简单句进行了实验,因此未来的工作将在原有基础上加入基于知识图谱的推理式方法,以提高模型应用的广泛性。
参考文献(References)
[1] AHN D D, JIJKOUN V, MISHNE G A, et al. Using Wikipedia at the TREC QA track[EB/OL]. [2018-05-10]. http://staff.science.uva.nl/~mdr/Publications/Files/uams-trec-2004-final-qa.pdf.
[2] 汤庸, 林鹭贤, 罗烨敏, 等. 基于自动问答系统的信息检索技术研究进展[J]. 计算机应用, 2008, 28(11): 2745-2748. (TANG Y, LIN L X, LUO Y M, et al. Survey on information retrieval system based on question answering system[J]. Journal of Computer Applications, 2008, 28(11): 2745-2748.)
[3] GAO J F, HE X D, YIH W T, et al. Learning continuous phrase representations for translation modeling [EB/OL]. [2018-05-10]. http://www.aclweb.org/anthology/P14-1066.
[4] HUANG P S, HE X D, GAO J F, et al. Learning deep structured semantic models for Web search using clickthrough data[C]// CIKM 2013: Proceedings of the 22nd ACM International Conference on Information & Knowledge Management. New York: ACM, 2013: 2333-2338.
[5] SHEN Y, HE X D, GAO J F, et al. A latent semantic model with convolutional-pooling structure for information retrieval[C]// CIKM 2014: Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management, New York: ACM, 2014: 101-110.
[6] HE X, GAO J, DENG L, et al. Convolutional latent semantic models and their applications: US 9477654B2[P]. 2015-10-01.
[7] GAO J, PANTEL P, GAMON M, et al. Modeling interestingness with deep neural networks[EB/OL]. [2018-05-10]. http://www.aclweb.org/anthology/D14-1002.
[8] BELLOS C C, PAPADOPOULOS A, ROSSO R, et al. Identification of COPD patients health status using an intelligent system in the CHRONIOUS wearable platform[J]. IEEE Journal of Biomedical and Health Informatics, 2014, 18(3): 731-738.
[9] BUSA-FEKETE R, SZARVAS G, LTETHO T, et al. An apple-to-apple comparison of Learning-to-rank algorithms in terms of normalized discounted cumulative gain[C]// ECAI 2012: Proceedings of the 20th European Conference on Artificial Intelligence. Montpellier, France: IOS Press, 2012:16.
[10] GAO J F, TOUTANOVA K, YIH W T. Clickthrough-based latent semantic models for Web search[C]// SIGIR 2011: Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2011: 675-684.
[11] 徐佳俊, 楊飏, 姚天昉, 等. 基于LDA模型的论坛热点话题识别和追踪[J]. 中文信息学报, 2016, 30(1): 43-49. (XU J J, YANG Y, YAO T F, et al. LDA based hot topic detection and tracking for the forum[J]. Journal of Chinese Information Processing, 2016, 30(1): 43-49.)
[12] LU Z D, LI H. A deep architecture for matching short texts[EB/OL]. [2018-05-10]. http://papers.nips.cc/paper/5019-a-deep-architecture-for-matching-short-texts.pdf.
[13] GAO J, HE X, NIE J Y. Clickthrough-based translation models for Web search: from word models to phrase models[C]// CIKM 2010: Proceedings of the 19th ACM International Conference on Information and Knowledge Management. New York: ACM, 2010: 1139-1148.
[14] 刘红光, 魏小敏. Bag of Words算法框架的研究[J]. 舰船电子工程, 2011, 31(9): 125-128. (LIU H G, WEI X M. Research on frame of bag of words algorithm[J]. Ship Electronic Engineering, 2011, 31(9): 125-128.)
猜你喜欢
计算机应用(2019年3期)2019-07-31
无线互联科技(2019年9期)2019-07-29
无线互联科技(2019年9期)2019-07-29
智能计算机与应用(2019年3期)2019-07-01
智能计算机与应用(2019年3期)2019-07-01
智能计算机与应用(2019年3期)2019-07-01
电子技术与软件工程(2019年5期)2019-06-20
软件导刊(2019年1期)2019-06-07
数字技术与应用(2019年2期)2019-05-14
现代电子技术(2018年8期)2018-04-13
