
基于孪生网络和双向最大边界排序损失的行人再识别
2019-08-01 01:54:12祁子梁曲寒冰赵传虎董良李博昭王长生
计算机应用 2019年4期
关键词:卷积神经网络
祁子梁 曲寒冰 赵传虎 董良 李博昭 王长生


摘 要:针对在实际场景中存在的不同行人图像之间比相同行人图像之间更相似所造成的行人再识别准确率较低的问题,提出一种基于孪生网络并结合识别损失和双向最大边界排序损失的行人再识别方法。首先,对在超大数据集上预训练过的神经网络模型进行结构改造,主要是对最后的全连接层进行改造,使模型可以在行人再识别数据集上进行识别判断;其次,联合识别损失和排序损失监督网络在训练集上的训练,并通过正样本对的相似度值减去负样本对的相似度值大于预定阈值这一判定条件,来使得负例图像对之间的距离大于正例图像对之间的距离;最后,使用训练好的神经网络模型在测试集上测试,提取特征并比对特征之间的余弦相似度。在公开数据集Market-1501、CUHK03和DukeMTMC-reID上进行的实验结果表明,所提方法分别取得了89.4%、86.7%、77.2%的rank-1识别率,高于其他典型的行人再识别方法,并且该方法在基准网络结构下最高达到了10.04%的rank-1识别率提升。
关键词: 行人再识别;孪生网络;双向最大边界;排序损失;卷积神经网络
中图分类号:TP391.4
文献标志码:A
文章编号:1001-9081(2019)04-0977-07
Abstract: Focusing on the low accuracy of person re-identification caused by that the similarity between different pedestrians images is more than that between the same pedestrians images in reality, a person re-identification method based on Siamese network combined with identification loss and bidirectional max margin ranking loss was proposed. Firstly, a neural network model which was pre-trained on a huge dataset, especially its final full-connected layer was structurally modified so that it can output correct results on the person re-identification dataset. Secondly, training of the network on the training set was supervised by the combination of identification loss and ranking loss. And according to that the difference between the similarity of the positive and negative sample pairs is greater than the predetermined value, the distance between negative sample pair was made to be larger than that of positive sample pair. Finally, a trained neural network model was used to test on the test set, extracting features and comparing the cosine similarity between the features. Experimental result on the open datasets Market-1501, CUHK03 and DukeMTMC-reID show that rank-1 recognition rates of the proposed method reach 89.4%, 86.7%, and 77.2% respectively, which are higher than those of other classical methods. Moreover, the proposed method can achieve a rank-1 rate improvement of up to 10.04% under baseline network structure.
Key words: person re-identification; Siamese network; bidirectional max margin; ranking loss; Convolutional Neural Network (CNN)
0 引言
行人再識别的目的是识别出跨摄像头、跨场景下的行人是否为同一个人,可以帮助进行进一步的查询跟踪,其应用领域广泛,如视频监控、城市监管、刑事安防等[1]。近年来,行人再识别技术引起了人们的广泛关注,虽然取得了大量的研究成果,但是行人再识别的研究依然存在着诸多挑战。例如:1)由于摄像机一般架设在较高位置,距离行人目标较远,所采集的图像内行人细节特征不明显,导致再识别精度不高;2)行人处于非合作状态,造成拍摄视角更加多样;3)即使视角相同,但由于服装或姿势的变化,导致不同行人的图像可能比相同行人的图像更加相似。
行人再识别的研究方法大体可以分为无监督学习方法和有监督学习方法两种,当前大部分行人再识别技术采用的是有监督学习方法。基于有监督学习的行人再识别方法可以概括为三大类:基于特征提取的方法、基于度量学习的方法和基于深度学习的方法。其中,早期的行人再识别方法主要为特征提取和度量学习两种,并且这些早期方法只关注其中的某一种,没有把这两个过程进行很好的结合,而深度学习则提供了较好的端到端解决方法。
特征提取通过提取具有分辨力和鲁棒性的行人特征来解决行人再识别问题,这里的特征是指通过研究者对研究对象观察研究后,人工选择并提取的特征,常用的特征如文献[2-3]中采用的颜色特征、纹理特征,以及多種特征的组合。
但是通过人工提取的特征大部分只能适应特定情况下拍摄的图像,对于未考虑到的情况无法很好地适用,并且设计特征需要较高的经验水平。当前,随着行人再识别研究的进行,人工特征研究对识别率的提升变得越来越小。
鉴于在特征研究中存在的问题和困难,度量学习的方法被应用于行人再识别问题,例如,XQDA(Cross-view Quadratic Discriminant Analysis)算法[3]、KISSME(Keep It Simple and Straightforward MEtric)算法[4]、最大边界近邻(Large Margin Nearest Neighbor, LMNN)算法[5]。该类方法的主要思想是通过学习一个映射矩阵,将特征从原始特征空间映射到另一个具有高区分度的特征空间,使得在原始特征空间难区分甚至不可分的特征变得容易区分。这种方法在一定程度上降低了对特征的要求,提高了识别算法的鲁棒性,但是这些特征提取和度量学习相互独立的处理方法还是不能达到令人满意的效果,在拍摄条件和环境差异较大时无法取得良好的效果。
随着计算机硬件的发展、计算能力的不断提升,以及大规模数据集的出现,深度学习开始应用于包括计算机视觉领域在内的各个领域,并取得了优异表现[6]。自从在2012年的ImageNet竞赛中获胜,深度学习吸引了许多的研究者。随着其发展,LeNet5、AlexNet、VGGNet、GoogLeNet、ResNet等优秀的卷积神经网络(Convolutional Neural Network, CNN)模型不断被提出,网络的结构越来越深,网络性能也不断提升。
由于深度学习在计算机视觉领域展现出了优越的性能,以及非深度学习方法的局限性,深度学习方法开始被用于行人再识别课题的研究。其中一些深度学习的研究方法可以看作从分类的角度来解决行人再识别的问题,如文献[7-8]方法,这些方法通过softmax函数连接交叉熵损失来判断某个行人的ID,依此来确定某一幅图像是否属于某一个人;还有一些方法从排序的角度来考虑这个问题,如文献[9-10],这类方法的出发点就是类内距离应该比类间距离更近,与被检索图像属于同一类别的行人图像排在前面。
针对不同行人图像之间比相同行人图像之间更相似所造成的行人再识别准确率较低的问题,
本文从排序角度进行分析,利用深度学习的方法来解决行人再识别问题。
本文方法是一种有监督学习方法,实质上就是通过更有效的损失函数来对具有较深结构的网络进行监督训练,从而得到更好的网络权重,之后通过提取更具分辨力和鲁棒性的深度特征来解决行人再识别问题。
本文网络结构与文献[11]中的网络结构相似,但其网络结构为一个较浅的8层的CNN结构,且未经过预训练,而本文采用了网络结构更复杂、效果更好的预训练过的CNN结构来处理图像对,这使得所提取的特征可以对图像进行更好的表达。虽然本文方法在操作上与文献[9]比较相似,但其仅仅使用了平方损失,而本文使用了更好的损失函数(排序损失)来监督网络的学习,其优势在于可以使得正样本之间的距离小于负样本之间的距离。同时,与文献[9]不同之处还在于本文方法中正负样本的比例是固定的,这样可以降低正负样本的数量不平衡所造成的影响,从而得到较高识别率。
1 网络结构
1.1 整体网络结构
本文的整体网络结构是在孪生网络(Siamese网络)结构的基础上进行的改进,所提出的网络主要包括两个判别力很强的CNN模型,并且融合了softmax损失和双向最大边界排序损失(本文简称为排序损失),网络结构如图1所示。图1中输入图像序列是一个四元图像组,并且这些输入图像需要调整大小来适应网络输入尺寸,CNN模型可以是任何一个基准网络结构,或者是一个重新设计定义的网络结构。为了得到更好的结果和提高训练效率,并对所提出的联合损失的有效性进行验证,本文采用已经在ImageNet数据集上预训练过的VGGNet-16、GoogLeNet、ResNet-50基准网络作为CNN模型进行实验。
以ResNet-50为例,首先,为了使本文模型能够在行人数据集上进行训练和预测,需要去掉原始ResNet-50中与最后的池化层相连的全连接(Fully Connected, FC)层和结果预测层;然后,在ResNet-50后添加用于防止过拟合的Dropout层和用于预测的1×1×2048×N维的全连接层,其中2048是特征维数,N是数据集的实例个数;最后,通过连接softmax损失层,得到识别损失,并且使用该网络最后池化层的输出作为图像特征来对输入图像进行表示,图像特征会用于测试阶段。
本文所提出的网络结构不仅利用到了结构和参数非常优秀的预训练模型,同时也可以通过孪生网络结构很方便地将softmax损失和排序损失结合在一起。下面分别对构建整体网络结构所用到的技术进行介绍。
1.2 基准网络结构
本文中孪生网络的两个分支结构采用在ImageNet竞赛的大规模数据集上预训练过的网络模型作为基准网络结构(baseline network),该数据集有10万左右的图片,包括各种类别的对象1000类。使用预训练过的模型有以下优点:1)由于预训练数据集包含对象类别较多,图片数量很大,因此使用预训练模型的初始权重相对人为设置更加合理,在训练时有利于快速找到最优解;2)由于参数量巨大,重新对复杂网络模型进行训练需要很多的计算资源和时间,不必要的重复训练会造成很大的浪费;3)这些预训练模型的性能已经通过大量研究者的实验验证,性能有所保障。表1对当前常用的经典基准网络结构的特点进行简单总结。
表1中的层数计算的是网络中包含可变参数的层的数量,比如卷积层和全连接层,那些参数固定或不包含可变参数的层未计算进去,其中参数可变与否是针对训练阶段而言的。另外,尽管表1中的网络结构都有相当多不同的版本和各种结构上的改进,但考虑到训练的效率和实验验证效果,本文只采用了表格中所展示的基准结构进行实验,其中包括VGGNet-16[12]、GoogLeNet[13]和ResNet-50[14]。
1.3 孪生网络
孪生网络通常用来度量两个输入样本之间的相似性(两个输入样本为同类,即输入都是图像或者都是文本),判断输入样本是否为相同标签。同时,对应孪生网络的还有伪孪生网络(pseudo-Siamese network,两种输入样本可以是不同类型的,比如一个是图像另一个是文本),用来判别输入样本是否匹配。两类网络的基本结构如图2所示。
图2中孪生网络的两个分支使用相同的结构并且权重W共享,输入无论从类型还是数量上也都是相同的,而伪孪生网络则可以使用不同的结构(比如一个为VGGNet,另一个为GoogLeNet),且权重不共享,输入也不相同。对于本文来讲更加适合使用Siamese网络结构的依据如下:1)行人再识别问题中输入的都是行人图像,即输入的是相同类型的数据;2)在训练过程中利用到两幅图像是否为相同行人这一已知信息;3)充分利用每幅图像自身所包含的各种信息(颜色和形状等)。Siamese网络通过把输入图像映射到特征空间中,从而在特征空间中用度量函数对比图像特征的相似度。通常度量函数可以表示为:
通过训练找到合适的W,使得当X1和X2属于相同类别时DW较小,当类别不同时DW较大。
可以看到,当输入为相同类别图像对时,即输入图像属于相同行人,则只需要在训练时最小化DW即可。DW可以是欧氏距离、余弦距离或其他度量方法。
2 目标函数
2.1 双向最大边界排序损失
通常用于两个特征向量之间距离度量的是欧氏距离,但对于行人再识别问题来说,仅仅使用欧氏距离无法区分那些外观非常相似的不同行人的图像。因此,本文使用余弦相似度来度量特征向量的相似度,即通过两个向量之间的夹角来判断图像是否属于同一行人。余弦相似度可以表示为:
其中:m是最大损失边界,它的大小影响训练中收敛的速度和效率;D(*,*)为式(2)所示的余弦相似度分数,图像的相似度越大则这个分数会越高。由式(3)~(4)可知正样本对之间的相似度大于负样本对之间的相似度,排序损失函数的作用就是在训练中约束这种关系。因此在式(5)中,当正样本对的相似性分数减去负样本对的相似性分数大于m时,即符合判定条件,损失为0。
本文截取了ResNet-50网络中某一非线性层(res4fx)的结果来可视化输出其特征图,分别对使用了双向最大边界损失的本文方法,文献[9]方法(使用了欧氏距离)和基准网络ResNet-50(仅使用了识别损失)的效果进行展示,其中原始图像来自Market-1501数据集,结果如图3所示。
由图3可看出:1)相对于文献[9]方法,本文方法训练出的网络对于图像中行人信息的表达更加准确,对于一些背景的处理效果更好;2)相对于基准网络ResNet-50,本文方法对于行人和背景之间的差异性表现更好,即图像中行人的信息得到了更高的响应值(对应特征图中采用深色进行表示)。
2.2 目标函数
受文献[9]的启发,本文最后的目标函数同时利用识别损失和排序损失。通过两个较深的基准网络结构提取两幅图像的特征,然后衔接FC层和softmax损失层产生每一类的概率和识别损失,其中softmax损失定义为:
代表该样本在真实标签位置i上的值;分母是对该样本在所有标签位置上的值进行求和。
softmax损失可以充分利用图像类别信息,但是只使用该损失函数无法有效地对那些相似的不同类别图像进行训练。因此,为了学习到一个判别力好的特征,并且在特征空间中具有相同类标签的特征向量之间比具有不同类标签的特征向量距离更近,本文把两种损失函数结合,得到最终的目标函数为:
其中:Lobject代表整个网络计算得到的损失;Lsoftmax1和Lsoftmax2为网络中两个分支的softmax损失;Lrank为双向最大边界排序损失; μ是用来权衡两种损失之间的影响,当μ=0时,只有softmax损失函数产生作用,并且本文在实验验证中得到 μ=0.5可以取得较好的实验结果。
通過式(7)对两种损失的结合,不仅充分利用了图像的类别信息,也使得相同类的特征向量之间比不同类的特征向量之间距离更近,从而降低了由于不同行人的图像非常相似导致误判的可能性。并且相对于只使用一种损失的方法, 本文方法充分利用了所有的已知信息去训练,因此可以达到较好的效果。
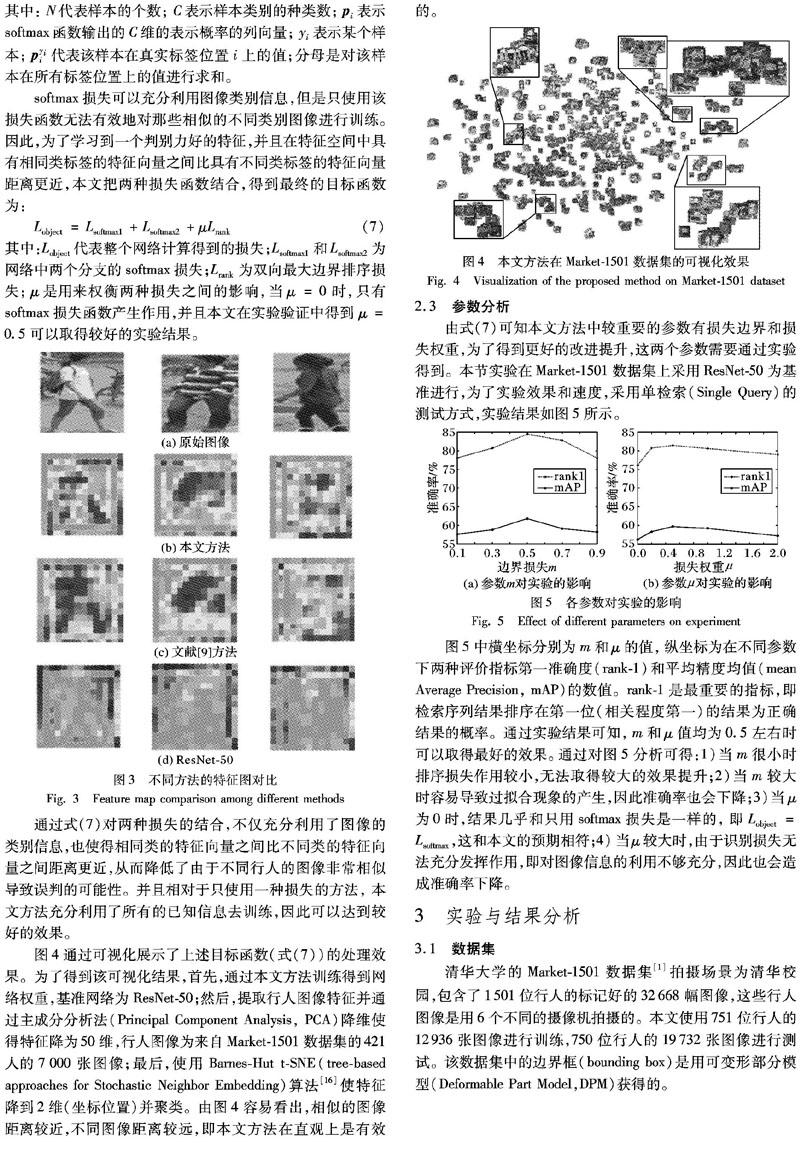
图4通过可视化展示了上述目标函数(式(7))的处理效果。为了得到该可视化结果,首先,通过本文方法训练得到网络权重,基准网络为ResNet-50;然后,提取行人图像特征并通过主成分分析法(Principal Component Analysis, PCA)降维使得特征降为50维,行人图像为来自Market-1501数据集的421人的7000张图像;最后,使用Barnes-Hut t-SNE(tree-based approaches for Stochastic Neighbor Embedding)算法[16]使特征降到2维(坐标位置)并聚类。由图4容易看出,相似的图像距离较近,不同图像距离较远,即本文方法在直观上是有效的。
2.3 参数分析
由式(7)可知本文方法中较重要的参数有损失边界和损失权重,为了得到更好的改进提升,这两个参数需要通过实验得到。本节实验在Market-1501数据集上采用ResNet-50为基准进行,为了实验效果和速度,采用单检索(Single Query)的测试方式,实验结果如图5所示。
图5中横坐标分别为m和μ的值,纵坐标为在不同参数下两种评价指标第一准确度(rank-1)和平均精度均值(mean Average Precision, mAP)的数值。rank-1是最重要的指标,即检索序列结果排序在第一位(相关程度第一)的结果为正确结果的概率。
通过实验结果可知,m和μ值均为0.5左右时可以取得最好的效果。通过对图5分析可得:1)当m很小时排序损失作用较小,无法取得较大的效果提升;2)当m较大时容易导致过拟合现象的产生,因此准确率也会下降;3)当μ为0时,结果几乎和只用softmax损失是一样的,即Lobject=Lsoftmax,这和本文的预期相符;4)当μ较大时,由于识别损失无法充分发挥作用,即对图像信息的利用不够充分,因此也会造成准确率下降。
3 实验与结果分析
3.1 数据集
清华大学的Market-1501数据集[1]拍摄场景为清华校园,包含了1501位行人的标记好的32668幅图像,这些行人图像是用6个不同的摄像机拍摄的。本文使用751位行人的12936张图像进行训练,750位行人的19732张图像进行测试。该数据集中的边界框(bounding box)是用可变形部分模型(Deformable Part Model,DPM)获得的。
香港中文大学的CUHK03数据集[17]包含1467位行人的14097幅图像,这些图像拍摄于两个摄像头,每个摄像头下每个行人平均有4.8幅图像。该数据集同时具有人工标记和DPM算法检测的边界框,为了更接近实际应用场景,本文使用DPM检测到的边界数据进行实验。
DukeMTMC-reID数据集[10]是行人跟踪数据集DukeMTMC的一个子集。DukeMTMC数据集由杜克大学学者在文献[18]中提出,包含8个不同视角的85min高分辨率视频。DukeMTMC-reID数据集的图片截取自DukeMTMC的视频,它的结构类似于Market-1501数据集,包含702位行人,其中16522张为训练图片,17661张图像用于测试,2228张作为查询图像。
3.2 评价准则和实验设置
为了验证本文方法的有效性,本文采用3种基准网络(VGGNet、GoogLeNet和ResNet-50)和3个公开的行人再识别数据集(Market-1501、CUHK03和DukeMTMC-reID)进行实验。使用Matconvnet深度学习框架进行算法实现,实验环境为Ubuntu 16.04,Matlab 2016a,NVIDIA Tesla P100显卡。
本文使用随机梯度下降(Stochastic Gradient Descent, SGD)算法对网络进行训练,训练中采用批训练的方式,批尺寸(mini-batch size)设置为10,训练的动量因子固定为0.9,共训练40次,前20次学习率为0.1,其后10次为0.02,最后10次为0.01。
在训练阶段:首先,数据集中的原始行人图像被重置为256×256像素的大小,并且从该图像中裁剪出224×224大小的图像作为网络输入;然后,图像数据输入网络之中,经前向传播计算得到损失;最后,进行损失反向传播,并调整网络参数,其中排序损失边界和损失权重为0.5。
在测试阶段:由于本文网络中的两个分支权重共享,因此只使用其中一个进行特征提取即可。首先,对图像进行预处理;然后,通过训练过的网络进行特征提取,對应VGGNet-16、GoogLeNet和ResNet-50分别为4096维、1024维和2048维的深度特征;最后,计算对比所提特征的余弦距离得到余弦相似度获得最终结果。
本文在实验中主要采用两种评价指标,分别为累计匹配特征曲线(Cumulated Matching Characteristics curve, CMC)和平均精度均值(mAP)。累计匹配特征曲线从排序的角度对再识别问题进行评价,即把检索结果按照相关程度进行排序。当然,排序靠后的检索结果正确率也很重要,尽管排序靠后的检索结果相关程度不如在第一位的结果,但对于辅助人工识别具有重要意义。
平均精度均值则是把行人再识别当作图像检索问题来进行评价,该指标可以从整体上对算法进行评价。其中,精度均值(Average Precision, AP)计算公式为:
3.3 有效性验证
本文通过对行人再识别问题进行分析,提出并采用了性能更好的损失函数,因此在有效性实验部分本文分别采用VGGNet-16、GoogLeNet和ResNet-50作为基准网络,
通过在Market-1501数据集上比较本文方法和基准网络的CMC曲线来进行有效性验证,实验结果如图6所示。
由图6可知,与基准网络的结果相比本文方法取得了较大的提升,其中对VGGNet-16、GoogLeNet和ResNet-50三种基准网络在Market-1501数据集上rank-1的提升幅度分别为5.85%、8.94%和10.04%,并且通过对比在三种基准网络上的提升幅度也可以得出,当网络结构较深时本文方法可以达到更好的提升效果。
3.4 Market-1501数据集实验
本文在Market-1501数据集上采用了两种测试方法,即单检索(Single-Query)和多检索(Multi-Query)。单检索时被检索的图像为单帧行人图像,多检索时被检索的图像为多帧同一行人的图像的均值图像,其中多检索可以利用到更多的行人图像信息,但单检索更接近实际情况,实验结果如表2所示。
从表2可知,在Market-1501数据集上,本文方法在使用ResNet-50作为基准网络时分别在单检索和多检索条件下取得了84.5%和89.4%的rank-1准确率,67.4%和79.2%的mAP。
從实验结果数据可得,本文方法取得了最好的综合效果,并且,在多检索条件下采用多幅行人图像用于检索,有利于提高再识别准确率。
3.5 CUHK03数据集实验
在CUHK03数据集中分别在单摄像采集(single-shot)和多摄像采集(multi-shot)的条件下进行实验。单摄像采集条件下每个被检索图像在搜索集中只有一幅对应的正确图像,多摄像采集条件下则是使用来自其他摄像机的所有图像用于待检索,对应正确的行人图像不只一幅。其中多摄像采集的情况非常接近图像检索,并且可以在一定程度上降低随机采样对结果带来的影响,实验结果如表3所示。
从表3可知,本文方法在CUHK03数据集上使用ResNet-50作为基准网络,在单摄像采集(single-shot)条件下取得了82.9%的rank-1准确率和89.2%的mAP;在多摄像采集(multi-shot)条件下取得了86.7%的rank-1准确率和77.8%的mAP。表3中,在单摄像采集条件下,Siamese-reranking方法[8]取得了最好的rank-1结果,原因是其在训练网络并提取特征后采用了重排序技术,使得特征更相似的图像有更大的概率被排在前面,处理过程较为复杂;然而,本文仅仅通过改进网络和损失函数来提高深度特征对行人图像的表达能力,直接提升网络本身的性能,没有进行进一步的处理。
3.6 DukeMTMC-reID数据集实验
DukeMTMC-reID数据集的数据在结构上和Market-1501相似,由于该数据集提出较晚,因此本文只列出了在单检索(Single Query)时本文方法与其他一些方法的对比。从表4可知,在DukeMTMC-reID数据集上本文方法使用ResNet-50作为基准网络取得了77.2%的rank-1准确率和53.9%的mAP。表4中得到最好mAP的方法是BraidNet-CS+SRL算法[23],该方法比BraidNet-CS多了对负样本率进行自适应学习的步骤,使得参数的选择更加合理,但同时也需要更多的学习时间。
4 结语
本文通过提出一种基于孪生网络结合识别损失和双向最大边界排序损失的方法,解决了在实际中不同行人图像之间比相同行人图像之间更相似所造成的行人再识别准确率较低的问题,并且通过数据可视化手段展示了识别处理效果。尽管本文只使用了3种基准网络验证本文方法的有效性,但本文所提的排序损失和对应的网络结构可以适用于所有的基准CNN结构。同时,通过在三个公开数据集上与其他方法进行对比实验,本文方法取得了较好的综合性能。
本文方法存在的主要问题是:1)尽管没有通过实验数据对运行时间进行分析,但是由于使用了拥有大量参数的网络模型,并且所提出的损失函数在训练时计算较慢,因此训练时间相对较长;2)文中实验的参数并不是通过自适应学习得到的,而是通过在某一数据集上实验获得的,因此参数选择的合理性需要进行进一步的验证。
基于现有结论,本文认为未来可以沿以下几个方向开展进一步的研究工作:首先,对如何把本文方法应用于更大规模的再识别数据集进行研究,或者验证其在实际场景中的效果;其次,对损失函数计算的优化和对算法参数的选择上需要采用更合理的方法;最后,尽管本文方法是针对行人再识别提出的,但也可以对其应用到其他课题进行探索,如图像检索等。
参考文献(References)
[1] ZHENG L, SHEN L, TIAN L, et al. Scalable person re-identification: a benchmark[C]// ICCV 2015: Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE, 2015: 1116-1124.
[2] MATSUKAWA T, OKABE T, SUZUKI E, et al. Hierarchical Gaussian descriptor for person re-identification[C]// CVPR 2016: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2016: 1363-1372.
[3] LIAO S, HU Y, ZHU X, et al. Person re-identification by local maximal occurrence representation and metric learning[C]// CVPR 2015: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2015: 2197-2206.
[4] KOESTINGER M, HIRZER M, WOHLHART P, et al. Large scale metric learning from equivalence constraints[C]// CVPR 2012: Proceedings of the 2012 IEEE International Conference on Computer Vision. Washington, DC: IEEE Computer Society, 2012: 2288-2295.
猜你喜欢
电子技术与软件工程(2017年3期)2017-03-22 23:24:25
电脑知识与技术(2016年33期)2017-03-21 23:19:04
科技创新与应用(2017年5期)2017-03-16 09:48:22
电脑知识与技术(2016年30期)2017-03-06 20:14:45
科技创新与应用(2016年35期)2017-02-21 19:16:50
计算机应用(2016年12期)2017-01-13 20:26:21
软件导刊(2016年9期)2016-11-07 22:20:49
软件工程(2016年8期)2016-10-25 15:47:34
软件(2016年5期)2016-08-30 06:27:49
电脑知识与技术(2016年10期)2016-06-16 21:27:26
