
卷积神经网络中减少训练样本时间方法研究
2017-03-21 23:19范青
电脑知识与技术 2016年33期
范青


摘要:深度学习在人工智能尤其是在图像处理,图像分类方面的应用越来越广泛。其中卷积神经网络在其中具有重要地位。本文的主要目的为探究通过调整在网络中卷积过程所使用的滤波器大小,在保证分类结果准确率可接受情况下,尽量减少样本的训练时间,并总结出一套较为通用的滤波器大小设置规则。在文章中,通过对theano中基于lenet模型所构造的卷积神经网络的两层卷积层中的滤波器大小进行不同搭配的设置,测试数据集为广泛使用的mnist手写数字库以及cifar_10库,最后对比探究出适用于这两个数据集的减少训练时间的设置规律。
关键词:卷积神经网络;深度学习;图像处理;训练时间
中图分类号:TP18 文献标识码:A 文章编号:1009-3044(2016)33-0167-04
如今在机器学习领域中,深度学习方法已经占据了相当重要的地位,通过模仿人腦学习方式构造模型,在图像、文本、语音处理方面取得了显著成果[1]。目前应用较为广泛的深度学习模型包含多层感知器模型(MLP)[2],卷积神经网络模型和限制性玻尔兹曼机模型等[4]。多层感知器[2]网络结构的神经节点一般分层排列,主要由输入层,输出层和一些隐层组成,同层之间的神经元节点无连接,相邻的两层神经元进行全连接,前一层的神经元的输出作为后一层神经元的输入,但本身此种算法存在着一些问题,那就是它的学习速度非常慢,其中一个原因就是由于层与层之间进行全连接,所以它所需要训练的参数的规模是非常大的,所以对其进行改进,产生了卷积神经网络模型。卷积神经网络模型在图像识别方面的应用十分广泛[5,8,9]。从它的结构上来看,层与层之间的神经元节点采用局部连接模式,而并非MLP的全连接模型,这样就降低了需要训练的参数的规模。而在它卷积层中,它的每一个滤波器作为卷积核重复作用于整个输入图像中,对其进行卷积,而得出的结果作为输入图像的特征图[6],这样就提取出了图像的局部特征。而由于每一个卷积滤波器共享相同的参数,这样也就大大降低了训练参数的时间成本。而本文,以卷积神经网络为研究对象,在其模型的基础上通过对其结构中卷积核也就是滤波器的大小进行调整并结合卷积核个数调整和gpu加速等已有的训练提速方法,达到降低训练时间并且对识别结果并无太大影响的目的。
1 卷积神经网络
卷积神经网络在MLP的基础上,已经对结构进行了优化,通过层与层之间的局部连接以及权值共享等方式对要训练的参数的进行了大幅减低。
1.1局部连接
BP神经网络中,神经元在本层中呈线性排列状态,层与层之间进行全连接,而在卷积神经网络中,为了减少每层之间的可训练参数数量,对连接方式进行了修改,相对于BP神经网络的全连接,卷积神经网络采取了局部连接的连接方式[7],也就是说按照某种关联因素,本层的神经元只会与上层的部分神经元进行连接。
2.2 权值共享
在CNN中,卷积层中的卷积核也就是滤波器,重复作用在输入图像上,对其进行卷积,最后的输出作为他的特征图,由于每个滤波器共享相同的参数,所以说他们的权重矩阵以及偏置项是相同的。
我们从上图看出,相同箭头连线的权值是共享的,这样在原有的局部连接的基础上我们又降低了每层需要训练的参数的数量。
2.3卷积过程
特征图是通过滤波器按照特定的步长,对输入图像进行滤波,也就是说我们用一个线性的卷积核对输入图像进行卷积然后附加一个偏置项,最后对神经元进行激活。如果我们设第k层的特征图记为[hk],权重矩阵记为[Wk],偏置项记为[bk],那么卷积过程的公式如下所示(双曲函数tanh作为神经元的激活函数):
2.4 最大池采样
通过了局部连接与权值共享等减少连接参数的方式卷积神经网络中还有另外一个重要的概念那就是最大池采样方法,它是一种非线性的采样方法。最大池采样法在对减少训练参数数量的作用体现在两个方面:
1 )它减小了来自m-1层的计算复杂度。
2 )池化的单元具有平移不变性,所以即使图像在滤波后有小的位移,经过池化的特征依然会保持不变。
3卷积神经网络整体构造以及减少训练时间的方法
3.1使用GPU加速
本次论文实验中,使用了theano库在python环境下实现卷积神经网络模型,在lenet手写数字识别模型上进行改进,由于theano库本身支持GPU加速,所以在训练速度上实现了大幅度的提高。
3.2 数据集的预处理
本次实验使用的两个数据集是mnist手写数字库以及cifar_10库
Mnist手写数字库具有60000张训练集以及10000张测试集,图片的像素都为28*28,而cifar_10库是一个用于普适物体识别的数据集,它由60000张32*32像素的RGB彩色图片构成,50000张图片组成训练集,10000张组成测试集。而对于cifar_10数据集来说,由于图片都是RGB的,所以我们在进行实验的时候,先把其转换为灰度图在进行存储。由于实验是在python环境下运行,theano函数库进行算法支持,所以我们把数据集进行处理,此处我们对使用的数据集进行了格式化。格式化的文件包括三个list,分别是训练数据,验证数据和测试数据。而list中每个元素都是由图像本身和它的相对应的标签组成的。以mnist数据集为例,我们包含train_set,valid_set,test_set三个list,每个list中包含两个元素,以训练集为例,第一个元素为一个784*60000的二维矩阵,第二个元素为一个包含60000个元素的列向量,第一个元素的每一行代表一张图片的每个像素,一共60000行,第二个元素就存储了对相应的标签。而我们取训练样本的10%作为验证样本,进行相同的格式化,而测试样本为没有经过训练的10000张图片。在以cifar_10数据集为实验对象时,把其进行灰度化后,进行相同的格式化处理方式。
3.3实验模型结构
本次实验是在python环境下基于theano函数库搭建好的lenet模型进行参数的调整,以达到在实验准确度可接受情况下减少训练时间的目的。
上图为实验中的基础模型举例说明实验过程,首先以mnist数据集为例,我们的输入图像为一个28*28像素的手写数字图像,在第一层中我们进行了卷积处理,四个滤波器在s1层中我们得到了四张特征图。在这里要特别的说明一下滤波器的大小问题,滤波器的大小可根据图像像素大小和卷积神经网络整体结构进行设置,举例说明,假如说我们的输入图像为28*28像素的图像,我们把第一层卷积层滤波器大小设置为5*5,也就是说我们用一个大小为5*5的局部滑动窗,以步长为一对整张图像进行滑动滤波,则滑动窗会有24个不同的位置,也就是说经过卷积处理后的C1层特征图的大小为24*24。此处的滤波器大小可进行调整,本论文希望通过对滤波器大小的调整,已达到减少训练时间的目的,并寻找调整的理论依据。C1层的特征图个数与卷积过程中滤波器数量相同。S1层是C1经过降采样处理后得到的,也就是说四個点经过降采样后变为一个点,我们使用的是最大池方法,所以取这四个点的最大值,也就是说S1层图像大小为12*12像素,具有4张特征图。而同理S1层经过卷积处理得到C2层,此时我们滤波器的大小和个数也可以自行设置,得到的C2层有6张特征图,C2到S2层进行降采样处理,最后面的层由于节点个数较少,我们就用MLP方法进行全连接。
3.4实验参数改进分析
由此可见,我们对滤波器的大小以及个数的改变,可以直接影响到卷积训练参数的个数,从而达到减少训练时间的目的。
从另一种角度来看,增大滤波器的大小,实际效果应该相似于缩小输入图像的像素大小,所以这样我们可以预测增大滤波器的大小会减少样本的训练时间,但是这样也可能会降低训练后的分类的准确率,而滤波器的大小是如何影响训练时间以及分类准确率的,我们通过对两种图片库的实验来进行分析。
4 实验结果与分析
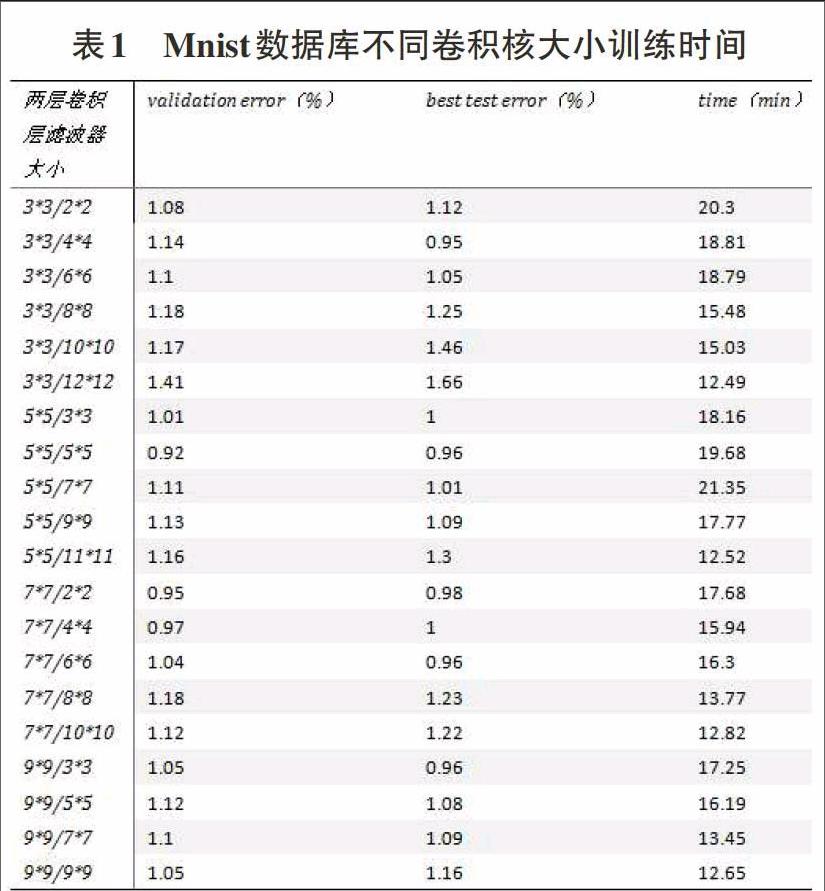
4.1以mnist手写数字数据集作为实验数据
我们知道卷积层可训练参数的数字与滤波器的大小和数字有关,所以我们通过对卷积层滤波器大小的变化来寻找较为普遍的可减少训练参数从而达到减少训练时间的目的。在实验记录中,我们表格纵列记录两层卷积层滤波器大小,横列分别为对已经过训练图像识别和对未经过训练的验证图像进行识别的错误率,最后记录每种滤波器大小搭配的使用时间。我们设定每次试验都进行100次重复训练,每次对权重矩阵进行优化。
此处我们记录两层滤波器大小之和作为横坐标,比较滤波器大小与实验之间的关系。两层滤波器大小相加后相同的元素我们把其对应时间做平均。
4.2以cifar_10数据集作为实验数据
同样是以100次循环训练进行测试,通过改变两层中滤波器的大小来寻找减少训练时间的设定。
此处以同样的方法,记录两层滤波器大小之和作为横坐标,比较滤波器大小与实验之间的关系。
4.3实验结果分析
从两组试验中,在不同的数据集下,我们得到了滤波器的大小与训练时间成反比的关系,而在减少了训练时间的同时确实增大了训练的错误率。
5 总结
通过实验结果分析表明,增大卷积层滤波器大小的方法,在此两种数据库的情况下,是有效减小训练时间的方式,而在不同的数据库对分类准确率的影响程度不同,mnist手写数字数据库中图像之间的相似度非常高,所以滤波器的增大对准确率产生的负面影响较小,而ifar_10数据集中图像之间的相似度较小,所以增大滤波器的大小对其分类结果的准确率的负面影响较大。
参考文献:
[1]LeCun Y, Bengio Y, Hinton G. Deep learning[J]. Nature, 2015, 521(7553): 436-444.
[2] Ruck D W, Rogers S K, Kabrisky M. Feature selection using a multilayer perceptron[J]. ]Journal of Neural Network Computing, 1990, 2(2): 40-48.
[3]LeCun Y, Bengio Y. Convolutional networks for images, speech, and time series[J]. The handbook of brain theory and neural networks, 1995, 3361(10): 1995.
[4] Larochelle H, Bengio Y. Classification using discriminative restricted Boltzmann machines[C]//Proceedings of the 25th international conference on Machine learning. ACM, 2008: 536-543.
[5]Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks[C]//Advances in neural information processing systems. 2012: 1097-1105.
[6] Zeiler M D, Fergus R. Visualizing and understanding convolutional networks[C]//European Conference on Computer Vision. Springer International Publishing, 2014: 818-833.
[7] Jarrett K, Kavukcuoglu K, Lecun Y. What is the best multi-stage architecture for object recognition?[C]//2009 IEEE 12th International Conference on Computer Vision. IEEE, 2009: 2146-2153.
[8] Ji S, Xu W, Yang M, et al. 3D convolutional neural networks for human action recognition[J]. IEEE transactions on pattern analysis and machine intelligence, 2013, 35(1): 221-231.
[9] Ciregan D, Meier U, Schmidhuber J. Multi-column deep neural networks for image classification[C]//Computer Vision and Pattern Recognition (CVPR), 2012 IEEE Conference on. IEEE, 2012: 3642-3649.
猜你喜欢
制造技术与机床(2018年12期)2018-12-23
电子制作(2018年18期)2018-11-14
计算机应用(2016年12期)2017-01-13
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
电气化铁道(2016年4期)2016-04-16
河南科技(2014年1期)2014-02-27
