
基于分布式爬虫的微博舆情监督与情感分析系统设计
2024-06-03 11:15:28何西远张岳张秉文
现代信息科技 2024年5期
何西远 张岳 张秉文
收稿日期:2023-07-27
DOI:10.19850/j.cnki.2096-4706.2024.05.024
摘 要:互联网的兴起使微博等自媒体平台成为网民表达意见的主要途径。同时,网络舆情的迅速传播使得网民舆论管理成为一个难题。针对传统方法在微博舆情管理上的局限性,文章设计一种基于分布式爬虫的微博舆情监测与情感分析系统,并借助情感分析和LDA主题提取技术,对热点事件进行分析,帮助政府和企业更好地把握舆情发展动态,捍卫其社会公信力。
关键词:网络舆情;分布式爬虫;情感分析;LDA主题提取
中图分类号:TP311.1 文献标识码:A 文章编号:2096-4706(2024)05-0111-05
Design of Sinaweibo Public Opinion Supervision and Sentiment Analysis System Based on Distributed Crawlers
HE Xiyuan, ZHANG Yue, ZHANG Bingwen
(School of Information Engineering, Shandong Youth University of Political Science, Ji'nan 250103, China)
Abstract: The rise of the Internet has made Sinaweibo and other We Media platforms the main way for netizens to express their opinions. At the same time, the rapid spread of Internet public opinion makes the public opinion management of netizens a difficult problem. Aiming at the limitations of traditional methods in Sinaweibo public opinion management, this paper designs a Sinaweibo public opinion monitoring and sentiment analysis system based on distributed crawler. It uses sentiment analysis and LDA topic extraction technology to analyze hot events, helping governments and enterprises better grasp the development dynamics of public opinion and defend their social credibility.
Keywords: Internet public opinion; distributed crawler; sentiment analysis; LDA topic extraction
0 引 言
近年來,微博作为中国最受欢迎的社交平台之一,已成为人们信息交流的主要途径。微博每天都发布上亿条信息,海量信息中蕴藏着巨大的价值。通过分析,可以有效了解网民们对热点事件的态度,并对舆情发展动态进行有效监控。了解社情民意、调整政策、回应社会关切对于政府和企业具有重要意义。
传统的舆情分析方法主要采用人工方法或机器学习进行。然而,在网络时代下,这些方法已经难以满足快速处理分析的需求。一方面,微博对用户IP的访问次数进行限制,导致数据获取困难。另一方面,微博所涵盖的数据规模巨大,其半结构化和非结构化数据类型使得数据处理存储困难。
分布式爬虫技术可以有效解决传统的舆情分析方法在应用中存在的局限。分布式爬虫技术可以充分利用分布式系统的优势,实现大规模数据的快速抓取和高效处理,为舆情分析提供更为全面准确的数据支持。情感分析和主题提取是常用的舆情分析方法[1]。情感分析技术能够展现网民对社会热点的情感态度,而主题提取则可以在大量的舆情信息中识别出舆情热点。为了弥补传统舆情分析方法的缺陷,本文从数据采集、处理、存储、文本挖掘和可视化展示五个方面设计了一个基于分布式爬虫技术的舆情监测和分析系统,用于挖掘舆情事件的热点和情感倾向,帮助政府和企业引导舆情。
1 架构设计
为了满足网络舆情发展的特点和舆情管理的相关需求,微博的舆情分析系统应该具备以下主要功能:采集微博热度舆情事件、定时采集热点事件、以监控事件发展动态以及筛选舆情数据。为此,本系统通过微博热搜榜上的热搜关键词获取数据。
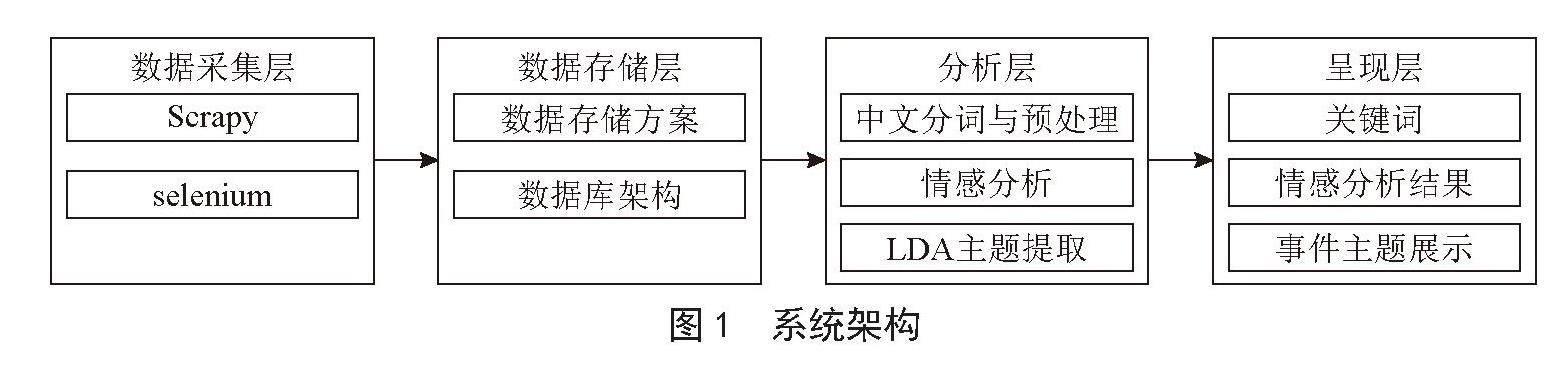
根据上述需求,本系统的架构设计包括数据采集、数据存储、数据分析和数据呈现四个方面。系统架构图如图1所示。
1.1 数据采集层
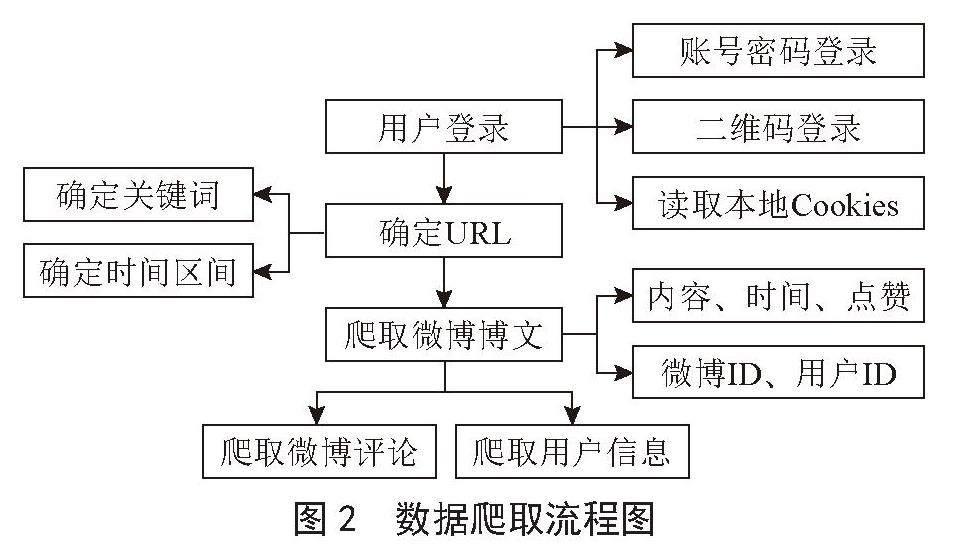
由于微博采取了一系列的反爬机制,数据的获取变得十分困难。采用BeautifulSoup和Request进行数据爬取时,在爬取时间和获取数据量方面的效果并不理想。因此,本文主要使用两个爬虫来获取数据,分别是基于Scrapy框架的分布式爬虫和基于多线程爬虫,这可以大大提升爬取效率。具体过程如图2所示。
图2 数据爬取流程图
1.1.1 基于Scrapy框架的分布式爬虫
Scrapy框架是一种开放源码的、以Python为基础的、可以快速有效地从大规模网页中获得有关信息的工具。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试[2]。该框架方便扩展并且易于开发。
微博平台每天涌现出数量惊人的博文,而一个社会热点所涉及的博文数量往往更是庞大且海量。为了满足舆情分析的需求,单个主机远远不够,因此需要采用分布式设计。文章向每一台主机共享一个Scrapy队列,调度程序在每一台主机上获得一个请求以进行爬行。这种设计使得爬虫程序能够在多台主机上运行,从而大幅提高其爬取效率[3]。
在Scrapy框架下,爬虫的分布式采集方式是通过设定关键词,获得一个或几条连续的微博搜索结果,并将结果写入文件或数据库。微博关键词检索是一种检索博文中含有指定关键词的微博的方法,允许用户指定搜索的时段。例如,设定“围棋”为关键词,爬取在9月到10月期间所有包含该关键词的微博。爬虫程序将对该时间段内的微博内容进行筛选爬取。获取的内容涵盖了微博用户ID、微博ID、博文内容、发布位置、点赞数和评论数等信息。
1.1.2 多线程爬虫
为了更有效地执行多线程爬虫,本文采用了Python的Thread库。多线程爬虫通常使用分布式爬虫获取微博用户ID和微博ID对URL进行地址定位,以确定所要访问的内容。然后,根据预设的线程数量将任务平均分配到各个线程中,以抓取微博下的二级评论信息和发布微博的用户信息。
根据微博网页的类型,该系统使用Python的lxml类库和re类库实现Web页面的分析。lxml库是Python中用于解析HTML和XML文档的高效工具。这个类库能够对文本进行快速的分析和抽取。使用re库可以快速灵活地抽取所需要的信息,并且轻松处理网页数据。为了提高数据价值,该系统在获取微博评论、用户ID和评论时间的同时,将根据用户ID进入评论者主页,以获取评论者的个人信息。
1.1.3 爬虫优化
在进行微博数据获取时,经常会面临反爬虫机制的限制和障碍。微博的反爬机制主要包括登录验证、IP限制、Cookie池和数据加密。这些机制为数据获取增加了难度。本文将采用以下方法来提高程序性能。
1)在Scrapy框架中,可以通过自定义中间件和扩展等方式,结合Selenium来实现请求的模拟登录。这样可以避免被反爬机制识别为机器登录,同时实现爬取到微博登录后才能浏览的数据。使用Selenium还可以自由切换IP和User-Agent等参数,从而提高爬取的成功率,降低IP被禁的风险。
2)设置代理IP池。用户频繁对网页进行访问可能会导致IP被封。虽然本文采用了多线程爬虫来提高效率,但其也存在被封IP的风险。因此,该系统设置了一个稳定的代理IP池,一旦发现IP被封,即及时更换。保持系统的稳定运行。
1.2 数据存储层
微博数据往往呈现出无结构的形式[4]。微博是一种随性而发的文本内容,可以包含文本、图片、视频、表情等不同的内容形式,并可能出现错别字、缩写、网络用语等非标准的文本和语言表达。因此,传统的关系型数据库很难满足存储微博数据的要求。Mongodb是一种非关系型数据库,能够存储非结构化的数据,因此成为处理微博数据的理想方案。此外,它还具有高性能、高可靠性、可扩展性和灵活性,能够快速存储和处理大量的微博数据。
1.3 分析层
1.3.1 文本预处理
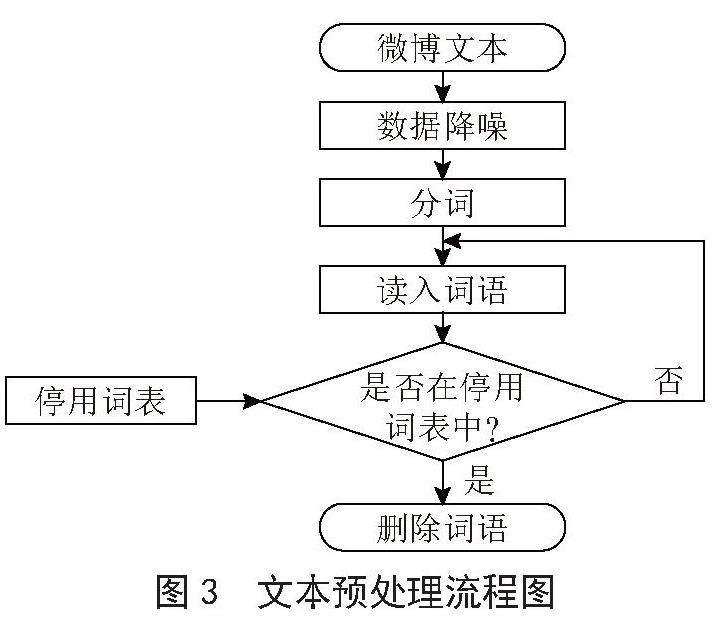
为达到更好的文本分析效果,对于微博文本进行预处理时,需要运用噪声消除、停用词去除、文本分割等技术。在Numpy库的基础上,利用Pandas工具对数据进行预处理,以解决数据不完整、冗余和脏数据等问题。在分词过程中,将中文分词多个单词,这些单词在语义上是完整的。与英文不同的是,中文没有明显的分词界限。因此,在中文中进行分词是一件非常困难的事情。为了解决这个问题,该系统使用了jieba库,这是一款强大而灵活的中文分词工具,能够精确地进行分词操作。通过对微博评论进行文本分词,利用停用词表删除无实际意义的停用词,这样提升了程序的运行速度和效率,并为文本分析做准备。文本预处理流程如图3所示。
1.3.2 情感分析
文本情感分析,又称倾向性分析,是对具有主观情感色彩的文本进行分析、处理、归纳和预测的过程[5]。本文采用了一种基于贝叶斯的文本分类方法,该方法具有计算复杂度低等优点。在对评论文本进行TF-IDF处理的基础上,对其进行矢量表达,并对其进行情绪分类,将其分为两个类别。为提高模型准确度,本文爬取了十几万条微博博文和评论数据,涵盖军事、娱乐、音乐、美食等领域。然后,进行模型的训练。根据训练好的模型得出情感得分,得分越高情感越积极,越低则越消极。通过对某一舆情事件的情感值进行汇总统计,可以很直观地看出公众对该事件的态度。算法流程如图4所示。
图3 文本预处理流程图
1.3.3 基于LDA主题提取
LDA是由Blei等[6]提出的一种基于Dirichlet分布的概率话题模型,它包含了文档、主题和词项3个层次。LDA广泛应用于无监督训练中[7-10],因为它可以有效地训练且不需要带标签的训练数据。
按照LDA模型,文档生成过程如图5所示。
图5 LDA算法模型
首先,根据参数α的Dirichlet分布中采样来产生一个文档相应话题的多项式分布θ;其次,根据题目的多项式分布θ中采樣,以产生文档i第j个词的题目z;然后,根据参数β的Dirichlet分布中采样,得到相应于主题z的特征性词汇的多项式分布u;最后,根据单词的多项式分布u对单词进行抽样,最终产生单词w。
在此基础上,提出了一种基于LDA的网络舆情话题抽取方法。该系统先对采集到的舆情事件文档进行降噪和分词处理,得到以词汇为单位的语料集合。然后,对文本中的每一个词进行随机的主题划分。其次,利用Gibbs抽样方法,根据词频和词频分布对各词频进行加权,对词频进行赋值。这一过程一直持续到文件、主题和词汇的分配趋于一致为止。本文在20个主题中选取排名前5的主题来反映该舆情事件的主要热点和趋势,这样的分析方法可以帮助用户更好地了解事件的关键信息,进一步揭示其背后的本质。
1.4 呈现层
本文旨在通过绘制图表的形式,以使用户能够直观地了解事件舆情的发展趋势。词云图将微博博文的热点呈现出来,用户可以通过词云图快速了解热点事件的信息。为绘制词云图,在微博数据预处理过程中,本文进行了降噪、去停、分词等操作,得到关键词。WordCloud库是一个基于Python的开源词云生成库,可以方便地生成美观、高度自定义的词云图。该库的功能包括将给定的文本转化为词频分布,然后根据词频绘制出具有艺术效果的词云图像。其提供了丰富的参数和方法,使用户能够轻松实现对词云图的个性化定制。
情感分析的结果和主题展示的呈现通过Echarts库实现。Echarts提供了Python的接口PyEcharts,为Python用户提供了更加方便的操作和使用方式。Echarts图形类型广泛,交互能力强,兼容性好,为用户提供了个性化的样式设计。
Django是一种以Python为基础、带有模板标记的网络框架,可以加快开发速度。此外,支持自定义前端设计,轻松实现图表和页面间的兼容。另外,Django还提供了大量的第三方插件和类库,这些类库能够提供给用户更好的互动体验。
2 实验及结果评估
本文以“唐山打人”事件为关键词,爬取了2022年7月1日到9月30日的近2万条微博博文和评论数据,并对该事件进行情感分析和主题提取,以揭示事件的舆情变化趋势和公眾关注的热点。
2.1 统计事件的情感比例
根据情感分析结果,对微博评论进行正向、负向和中向三种类型的研究,并对舆情评论中各类情感进行统计。利用Echarts绘制动态图表,以更直观地展示公众对该热点事件的情感态度。根据图6,可以了解各类数据的分布情况。在获取的数据中,消极信息占据了76.7%的比例,这反映了网民对该事件的不满、担忧或批评。而通过图7,可以具体地了解三类情感在舆情评论中的占比情况。
图6 事件整体数据概览
图7 情感分析占比
2.2 主题排行
根据LDA主题模型的结果,从20个主题中选出排名前5的主题词,以更好地反映舆情事件的关注点和热点。另外,使用Pandas库对热点词进行了统计,得到了其在微博博文中出现的次数,图8可以明确反映出各主题词的出现频率。根据图8可知,唐山和暴力是出现频率较高的主题词,反映了公众对于“唐山打人”事件的关注点和态度。
图8 主题词排名
2.3 绘制舆情地图
根据采集到的微博评论的IP地址,将各评论所在地的省份进行分类汇总,并通过Echarts库生成地域分布图,可以直观地展示各省对该舆情事件的关注度和态度。通过舆情地图,可以发现该热点事件引起了公众的广泛关注,进一步传播和扩散,各省份之间的态度和情感也存在一定的差异和分歧。
2.4 词云图
微博数据文本预处理后,使用WordCloud库绘制了词云图,更好地突显热点词。通过观察词云图,用户可直观地了解整个舆情事件中关键词的出现频率和重要性,从而进一步了解事件的主要热点和趋势。具体效果如图9所示。
图9 词云图
3 结 论
随着网络舆情形势的不断复杂化,准确掌握舆情发展趋势显得尤为紧迫。本文设计了一种利用情感分析和主题提取的舆情监测与分析系统。该系统采用分布式爬虫和多线程爬虫相结合的形式采集微博数据并进行文本预处理、情感分析、LDA主题模型提取等步骤,实现微博舆情的自动化监测和分析。同时,通过数据可视化技术,以图表和词云图的形式呈现结果,用户可直观地了解舆情事件的关键信息和趋势。在实际应用中,该系统展现了高效性、准确性和自动化的特点,具有广泛的实用性和应用价值。针对不同的舆情事件,可以通过该系统进行自动化监测和分析,可以帮助政府和公司及时了解公众声音,把握舆情发展的动态,做出更好的决策。与此同时,该系统抓取数据的速度、情感分析模型和主题提取模型的准确性、用户的交互性等有待提高。相信在未来的研究中,可以进一步完善和提高该系统的精度和实用性,为更好地服务社会提供更可靠的技术支撑。
参考文献:
[1] 叶艳,吴鹏,周知,等.基于LDA-BiLSTM模型的在线医疗服务质量识别研究 [J].情报理论与实践,2022,45(8):178-183+168.
[2] 姚云飞,杜洪波,梁建辉.基于SpringMVC框架毕业设计管理系统设计 [J].软件,2018,39(1):91-93.
[3] 周毅,李威,何金,等.基于Scrapy框架的分布式网络爬虫系统设计与实现 [J].现代信息科技,2021,5(19):43-46.
[4] 刘子谦,王志强.基于爬虫和文本处理的微博舆情分析系统 [J].北京电子科技学院学报,2020,28(3):31-39.
[5] 孙强,李建华,李生红.基于Python的文本分类系统开发研究 [J].计算机应用与软件,2011:28(3):13-14.
[6] BLEI D M,NG A Y,JORDAN M I. Latent Dirichlet alloction [J].Journal of Machine Learning Research,2003,3:993-1022.
[7] 邰悦,葛斌,李慧宗.基于改进LDA的细粒度主题建模方法研究 [J].佳木斯大学学报:自然科学版,2022,40(5):1-4.
[8] 张东鑫,张敏.图情领域LDA主题模型应用研究进展述评 [J].图书情报知识,2022,39(6):143-157.
[9] 杨文忠,丁甜甜,康鹏,等.基于舆情新闻的中文关键词抽取综述 [J].计算机工程,2023,49(3):1-17.
[10] 高万林,张港红,李桢,等.关于农业信息化与农村信息化关系的探讨 [J].中国农学通报,2011,27(1):466-470.
作者简介:何西远(2002—),男,汉族,山东济宁人,本科在读,研究方向:大数据、人工智能。
猜你喜欢
电脑知识与技术(2017年3期)2017-03-27 14:05:09
智能计算机与应用(2017年1期)2017-03-23 13:24:04
物联网技术(2016年11期)2017-01-12 19:41:22
电子技术与软件工程(2016年22期)2016-12-26 21:36:42
预测(2016年5期)2016-12-26 17:16:57
新媒体研究(2016年19期)2016-11-18 19:34:10
大学教育(2016年11期)2016-11-16 20:34:04
中国市场(2016年38期)2016-11-15 23:42:46
经营者(2016年12期)2016-10-21 07:51:37
今传媒(2016年9期)2016-10-15 22:02:52
