
基于Vision Transformer的小麦病害图像识别算法
2024-05-22 00:28白玉鹏冯毅琨李国厚赵明富周浩宇侯志松
中国农机化学报 2024年2期
白玉鹏 冯毅琨 李国厚 赵明富 周浩宇 侯志松

摘要:小麦白粉病、赤霉病和锈病是危害小麦产量的三大病害。为提高小麦病害图像的识别准确率,构建一种基于Vision Transformer的小麦病害图像识别算法。首先,通过田间拍摄的方式收集包含小麦白粉病、赤霉病和锈病3种病害在内的小麦病害图像,并对原始图像进行预处理,建立小麦病害图像识别数据集;然后,基于改进的Vision Transformer构建小麦病害图像识别算法,分析不同迁移学习方式和数据增强对模型识别效果的影响。试验可知,全参数迁移学习和数据增强能明显提高Vision Transformer模型的收敛速度和识别精度。最后,在相同时间条件下,对比Vision Transformer、AlexNet和VGG16算法在相同数据集上的表现。试验结果表明,Vision Transformer模型对3种小麦病害图像的平均识别准确率为96.81%,相较于AlexNet和VGG16模型识别准确率分别提高6.68%和4.94%。
关键词:小麦病害;Vision Transformer;迁移学习;图像识别;数据增强
中图分类号:TP18: S512.1
文献标识码:A
文章编号:20955553 (2024) 02026708
收稿日期:2022年5月12日 修回日期:2022年7月22日
基金项目:国家自然科学基金(11871196);河南省科技攻關项目(232102111125)
第一作者:白玉鹏,男,1996年生,河南驻马店人,硕士研究生;研究方向为图像处理与农业信息化。Email: yupengbai@126.com
通讯作者:侯志松,男,1979年生,河南安阳人,硕士,副教授;研究方向为智能信息处理与最优化算法。Email: houzhs@126.com
Algorithm of wheat disease image identification based on Vision Transformer
Bai Yupeng1, Feng Yikun2, Li Guohou1, Zhao Mingfu1, Zhou Haoyu3, Hou Zhisong1, 4
(1. School of Information Engineering, Henan Institute of Science and Technology, Xinxiang, 453000, China;
2. School of Software and Applied Science and Technology, Zhengzhou University, Zhengzhou, 450000, China;
3. School of Food Science, Henan Institute of Science and Technology, Xinxiang, 453000, China;
4. School of Computer Science and Technology, Xidian University, Xian, 710000, China)
Abstract:
Wheat powdery mildew, head blight, and rust are the three major diseases that harm wheat yield. In order to improve the recognition accuracy of wheat disease images, a wheat disease image recognition algorithm based on Vision Transformer was proposed. Firstly, the images of wheat diseases, including wheat powdery mildew, scab, and rust, were collected by field shooting, and the original images were preprocessed to establish the wheat disease image recognition data set. Then, the wheat disease image recognition algorithm was constructed based on the improved Vision Transformer, analyzing the influence of different transfer learning methods and data enhancement on the model identification effect. The experiments showed that full parameter transfer learning and data enhancement could significantly improve the convergence speed and identification accuracy of the Vision Transformer model. Finally, the performance of Vision Transformer, AlexNet and VGG 16 algorithms on the same dataset was compared under the same time condition. The experimental results showed that the average recognition accuracy of the Vision Transformer model for the three wheat disease images was 96.81%, which was 6.68% and 4.94% higher than that of AlexNet and VGG 16 models, respectively.
Keywords:
wheat disease; Vision Transformer; transfer learning; image recognition; data augmentation
0 引言
农作物病害是农业生产中严重的生物灾害,我国平均每年农作物病害爆发的耕种面积高达3.5×109 km2,给我国农业生产带来了难以估计的经济损失[1]。小麦作为我国重要的粮食作物,遭受病害后将导致产量和质量急剧下降,严重影响我国粮食安全[2]。小麦发病初期及时对病害诊断并进行精准防治,能够最大限度地减少经济损失,提高小麦产量。传统的农作物病害识别方法主要依赖于农业专家的经验和人工检测,这种方法效率低下、耗时耗力,且难以覆盖大面积的农田,已不能够满足当前环境下对病害快速准确诊断的需求。
随着深度学习技术的不断发展,利用计算机视觉对农作物病害进行快速识别与诊断逐渐成为取代传统人工诊断作物病害的一种重要方法[3]。深度学习技术可分为传统的机器学习算法和深度学习算法两大类。传统的机器学习算法主要包括支持向量机(Support Vector Machine, SVM)[4]、K近邻算法(Knearest Neighbor, KNN)、决策树(Decision Tree, DT)、K均值聚类算法等。国内外学者对此展开了广泛的研究,Wang等[5]用KNN算法对小麦霉变程度进行分析,取得了较好的识别效果;Feng等[6]利用支持向量機(SVM)和逻辑回归(LR)算法,结合光谱成像技术用于水稻病害检测,识别准确率达93%。然而,传统的机器学习算法在处理农作物病害识别问题时,往往受到过拟合、数据不平衡和鲁棒性差等问题的影响,导致识别效果不尽如人意。近年来,深度学习算法凭借其强大的特征表达能力和无需人工提取特征的优点,在计算机视觉领域中逐渐占据了主导地位,其中在图像识别方面应用广泛且实践效果最好的应属卷积神经网络(CNN)[7]。许多学者将AlexNet[8]、VGGNet[9]、GoogleNet[10]等经典的CNN模型用于作物病害识别,取得了较好的识别效果。与此同时,随着计算机算力的提升,涌现出越来越多的基于深度学习的作物病害识别模型,模型识别精度也在不断地提高[1113]。尽管卷积神经网络(CNN)在农作物病害识别领域取得了显著的成果,但其在处理大规模图像数据时,仍然面临着计算复杂度高、训练时间长等问题[14]。卷积操作缺乏对图像本身的全局理解,无法建立特征之间的依赖关系,不能充分地利用上下文信息。此外,卷积的权重是固定的,并不能动态地适应输入的变化[15]。因此,研究人员尝试将自然语言处理领域中的Transformer模型迁移到计算机视觉任务。相比卷积神经网络,Transformer的自注意力机制不受局部相互作用的限制,既能挖掘长距离的依赖关系又能并行计算,可以根据不同的任务目标学习最合适的归纳偏置[16]。其中,Dosovitskiy等[17]将原始的Transformer模型应用于图像分类任务,提出了一种完全基于自注意力机制结构的ViT(Vision Transformer)模型,在诸多视觉任务中取得了良好的效果。
本文基于Vision Transformer模型,采用迁移学习的方法对采集到的4种小麦图像(白粉病、赤霉病、锈病、健康)进行识别和分类,构建基于Vision Transformer的农作物病害识别模型,对模型进行优化;探究迁移学习和数据增强对ViT模型性能的影响;通过与其他深度学习模型,如AlexNet、VGG16进行对比试验,比较Vision Transformer模型相较于传统卷积神经网络在小麦病害识别任务中差异,为实际生产中小麦病害的精准识别提供理论依据。
1 材料和方法
1.1 构建小麦病害数据集
利用Scrapy[18]爬虫框架从百度、Google和Yahoo三个网站收集感染赤霉病、白粉病、锈病的小麦图像和健康小麦图像。由于爬取的小麦病害图像大多数质量不高,信息比较杂乱且重复图片较多,人工先选出图片分辨率大小在1 920像素×1 080像素以上、病害特征明显的4 000张无重复高清图片作为原始图像。然后,将采集到的原始图像随机裁剪成像素大小为900×900、600×600和300×300,从中筛选出每种小麦图像2 000张,共计8 000张图片。最后,将图像尺寸统一调整为224像素×224像素,构建小麦病害数据集WDD(Wheat Disease Dataset, WDD),图1为数据集部分图片。
(a) 白粉病
(b) 赤霉病
(c) 锈病
(d) 健康
本文数据集已公开至GitHub(https://github.com/houzhs/wdid)。
1.2 Vision Transformer算法
1.2.1 Vision Transformer
Transformer是Google在2017年提出的一种自然语言处理(Natural Language Processing,NLP)经典模型[19]。Transformer模型采用了自注意力机制,这种机制使得模型能够在处理图像时全局理解图像,建立特征之间的依赖关系,并充分利用上下文信息使得模型可以并行化训练。2018年发布的Image Transformer模型将Transformer应用于图像分类任务,但该模型依然采用了卷积操作,并未充分发挥Transformer的自注意力机制优势[20]。直到2020年,Dosovitskiy等提出了ViT(Vision Transformer)模型,首次将原始的Transformer模型应用于图像分类任务。ViT模型为了将图像转化成Transformer结构可以处理的序列数据,引入了图像块(patch)的概念。通过线性投影变换和位置编码,将图像块转化为序列数据,输入到Transformer中,同时在输入的序列数据之前添加一个分类标志位(class),以更好地表示全局信息。Transformer中的每一层,自注意力机制能够捕捉图像特征之间的依赖关系,并利用上下文信息进行全局理解。将Transformer的输出经过全连接层和Softmax层,得到图像的分类结果。此外,ViT模型通常在大型数据集上预训练,进而针对较小的下游任务进行微调。Vision Transformer模型的整体框架如图2所示。
Vision Transformer有“ViTBase”“ViTLarge”和“ViTHuge”三个版本,分别具有不同编码器的层数、隐藏层特征大小、全连接层节点个数、多头自注意力头数以及不同的参数规模和性能。Vision Transformer模型不同版本之间的差异如表1所示。
Vision Transformer模型算法流程如下:(1)给定一张图片X∈R3n×3n,分割该图片为9个patch,分别为x1,…,x9∈Rn2;将分割后的9个patch拉平,得出x1,…,x9∈Rn2。(2)利用矩阵W∈Rl×n2将拉平后的向量xi∈Rn2,i∈{1,…,9}经过线性变换得到图像编码向量zi∈Rl,i∈{1,…,9},具体的计算如式(1)所示。(3)将图像编码向量zi,i∈{1,…,9}和类别编码向量z0分别与对应的位置编码进行加和得到输入编码向量,如式(2)所示。(4)将输入编码向量输入到Vision Transformer Encoder中得到对应的输出oi∈Rl,i∈{1,…,9}。(5)将类别编码向量o0输入全连接神经网络中MLP中得到类别预测向量y^∈Rc,并与真实类别向量y∈Rc计算交叉熵损失,得到损失值loss,利用优化算法更新模型的权重参数。
zi=W·xi,i∈{1,…,9}
(1)
zi+pi∈Rl,i∈{1,…,9}
(2)
1.2.2 模型搭建
本文采用参数量相对较小的ViTBase模型,该模型编码器的层数为12,隐藏层维度大小为768,多头自注意力层使用的自注意力头的数量为12,其基本结构如图3所示。ViTBase模型输入的RGB图像为224像素×224像素,图像首先会被一个特殊的卷积层切割为196个像素大小为16×16的图像块(patch),卷积层的卷积核大小为16×16,步长为16;然后在图像块(patch)上加入类别标签和位置信息,输入到Transformer Encoder层中进行全局特征的学习,并采用残差结构和Dropout层来消除网络堆叠带来的梯度消失、爆炸和网络退化等问题;最后将训练好的类别标签进行切片处理作为模型的输出,输入到Softmax层根据提取的特征对小麦病害图像进行识别。
1.2.3 算法优化
为了提高模型的性能,在不改变ViT模型输入图像尺寸的基础上,对Patch Embedding层进行结构优化,首先对原始图像进行一次下采样和上采样提取局部特征,然后将提取的特征图输入到ViT模型中进行全局特征的学习,改进前后的Patch Embedding层结构如图4所示。同时为了降低模型的参数量,在尽可能不损失模型性能的前提下将MLP Block层中第一个全连接层输出向量的维度由原来的3 072降为1 536,修改后MLP Block层的参数量降低了50%。
(a) 修改前结构
(b) 修改后结构
2 模型训练
2.1 参数设置
从小麦病害数据集中随机选取80%的图片作为训练集,10%的图片作为验证集,剩余10%的图片作为测试集,用于模型的训练及测试。模型训练时,初始学习率(Learning rate)设置为0.000 1,批训练样本数(Batch size)设置为16;迭代次数(Epoch)设置为200,每次迭代前随机打乱训练集;优化器选择随机梯度下降(Stochastic Gradient Descent, SGD)算法[21]。
2.2 模型評价指标
采用平均识别准确率Accuracy对模型进行评价。
Accuracy=1ns∑nsi=1niini×100%
(3)
式中:
ns——样本类别数量,本文中为4;
ni——第i类样本数量;
nii——第i类样本预测正确的数量。
本文取模型200次迭代中验证集平均识别准确率最高的模型作为最佳模型,并将其应用于测试集进行性能评估。
2.3 试验环境
试验使用PyCharm2021.3.3开发环境和Pytorch深度学习框架,操作系统为Ubuntu18.04.2 LTS,处理器为英特尔Xeon E5-2640,服务器搭载2块Nvidia Tesla K40C图形处理器,单片GPU内存为12 GB。
3 结果与分析
3.1 迁移学习对模型性能的影响
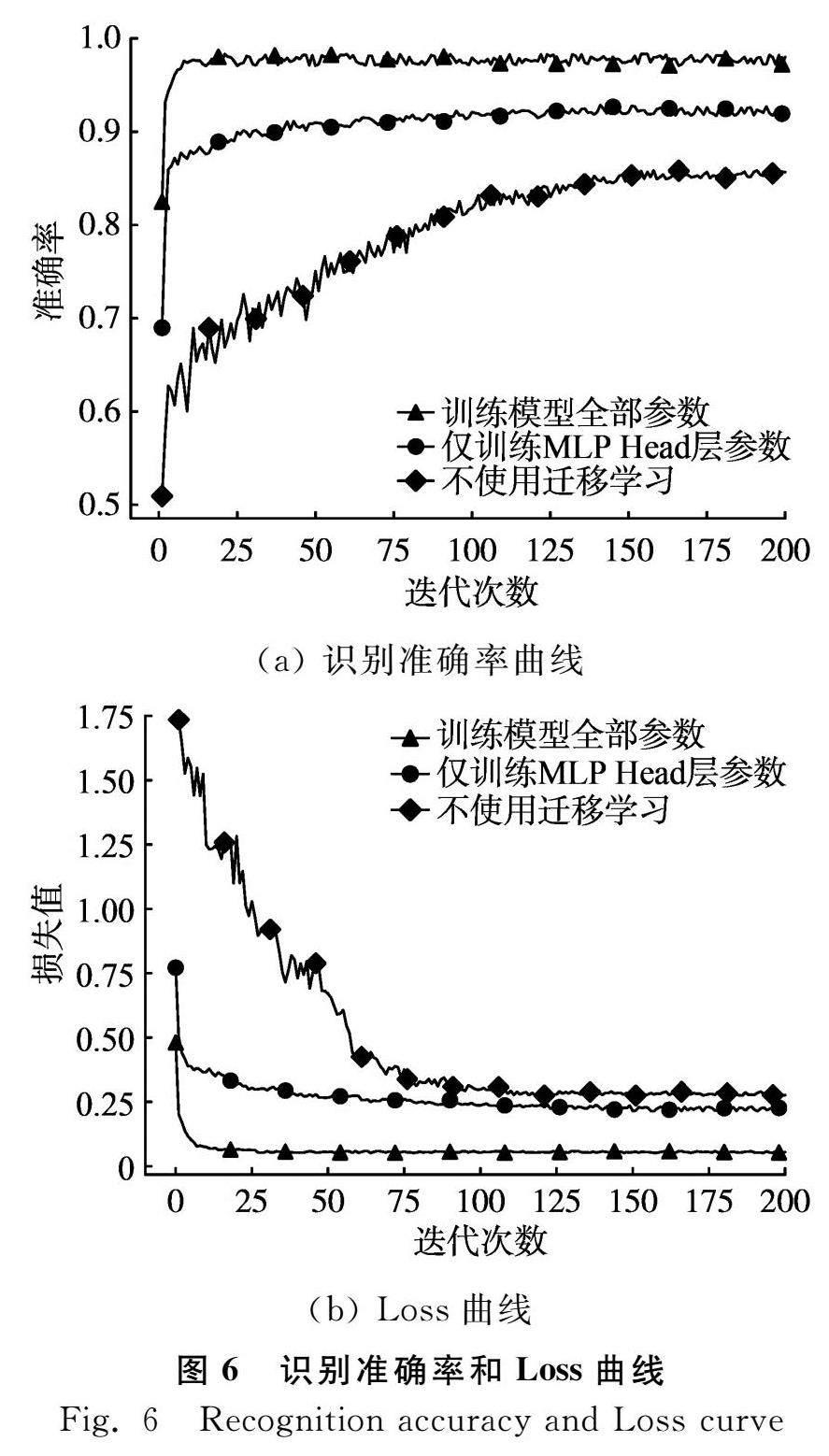
利用迁移学习的思想,将在ImageNet-21k上训练好的ViTBase模型权重迁移到本次试验中,迁移学习过程如图5所示。本文采用训练模型所有参数和仅训练模型分类器(MLP Head层)参数两种迁移学习方式对小麦病害数据集WDD进行特征学习,探讨迁移学习对模型性能的影响。不同迁移学习方式下ViT模型在训练集上的识别准确率和Loss曲线如图6所示。
(a) 识别准确率曲线
(b) Loss曲线
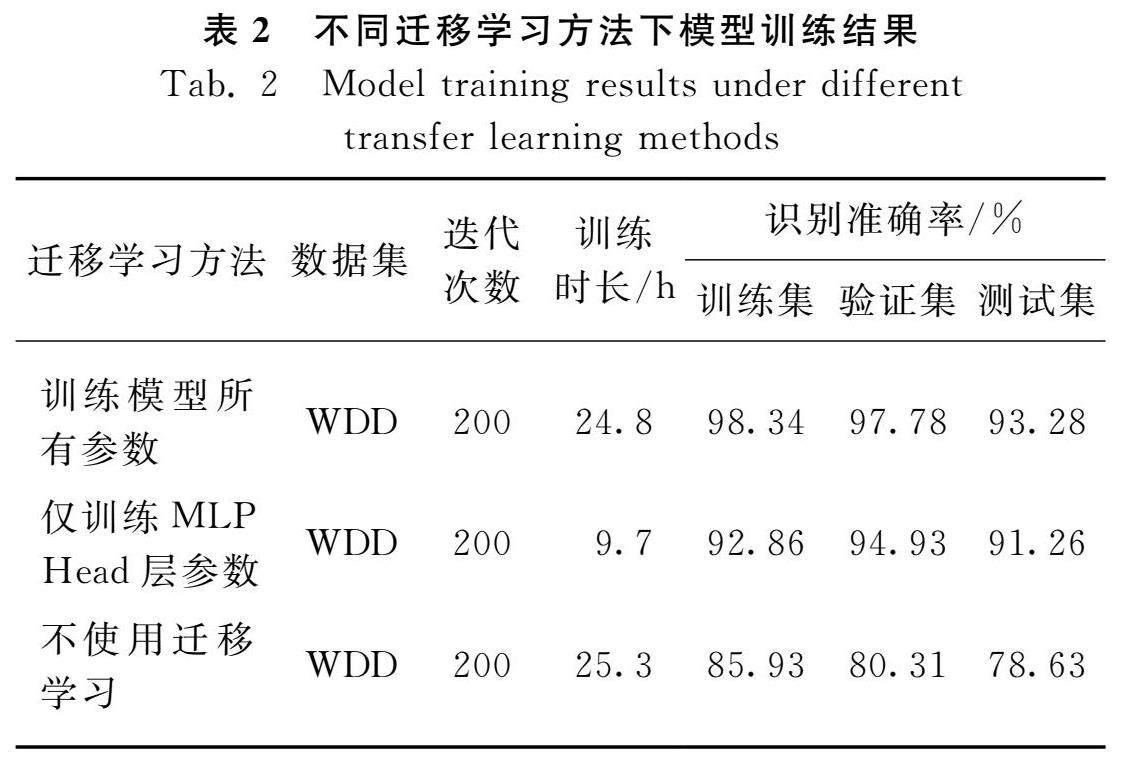
由表2可知,与不使用迁移学习相比,无论采用何种迁移学习方法对模型进行训练,ViT模型在训练集、验证集和测试集上的识别准确率均有明显提升。其中,采用训练模型所有参数的迁移学习方法,模型在测试集上的最高识别准确率为93.28%;采用仅训练模型分类器参数的迁移学习方法,模型在测试集上的最高识别准确率为91.26%;而不使用迁移学习进行模型训练时,模型在测试集上的最高识别准确率仅为78.63%。通过观察图6中不同迁移学习方法下训练集上模型识别准确率和Loss曲线可以看出,采用训练模型所有参数的迁移学习式模型收敛速度最快。
综上可知,在基于Vision Transformer进行小麦病害识别任务中,使用迁移学习能够显著提升模型识别准确率,使模型快速收敛,其中采用训练模型所有参数的迁移学习方法效果最好。
3.2 数据增强对模型性能的影响
由于田间小麦病害识别准确率会受到背景环境、拍摄角度等多种因素的影响,而本文所构建的小麦病害数据集样本量较小,不能充分模拟田间复杂的环境,这也可能是导致试验3.1节中的模型在测试集上的识别准确率明显低于训练集和验证集的原因之一。因此,本试验采用水平翻转、随机角度旋转和对比度增强3种数据增强的方式对原始数据集进行扩充,探讨样本量大小对模型性能的影响,如图7所示。扩充后的小麦病害数据集命名为LWDD(Large Wheat Disease Dataset, LWDD),其中包含32 000张小麦病害图像。根据试验3.1节结果可知,采用训练模型所有参数的迁移学习方法在小麦病害识别任务上的训练效果较好。因此,本次试验同样采用这种迁移学习的方式分别在WDD和LWDD数据集上进行ViT模型训练,试验结果如表3所示。
(a) 原图
(b) 水平翻转
(c) 随机角度旋转
(d) 对比度增强
由表3可知,相同的试验条件下,通过对比数据增强前后ViT模型在训练集和测试集上的识别准确率,可以发现,数据集扩充后,模型在训练集、验证集和测试集上的各项识别精度分别提高了1.12%、2.19%和3.67%。同时,从图8可以看出,模型在样本量较大的数据集上进行训练时,模型收敛更快,并且模型在验证集上的识别准确率波动的幅度更小,说明在大数据集上训练时模型更稳定,模型的泛化能力更强。
综上所述,通过增加数据集的样本量,能够有效地提高ViT模型性能,解决因田间复杂的环境、拍摄角度等因素造成模型在测试集上表现不佳的问题,提高模型的泛化能力。后续可以进一步对数据集进行扩充,以提升模型性能。
3.3 不同模型识别精度对比
通过对比本文构建的ViT模型和AlexNet、VGG16两种经典CNN模型在数据增强后小麦病害数据集LWDD上的训练结果,探究适合小麦病害识别的深度学习算法。模型训练过程中,对3种算法模型均采用训练模型所有参数的迁移学习方式进行训练,各模型在训练集上识别准确率曲线如图9所示。
由图9可知,相同的试验条件下,3个网络模型中ViT模型在训练集上表现最好,ViT模型在训练集上识别准确率明显高于AlexNet和VGG16,并且ViT模型的收敛速度最快。通过观察表4中的数据可以发现,ViT模型在测试集上的平均识别准确率达到了96.81%,比AlexNet和VGG16分別高出6.68%和4.94%。同时,由表5可以看出,ViT模型对3种小麦病害均取得了较高的识别准确率,其中对小麦赤霉病的识别准确率最高。
图10是不同模型在测试集上的混淆矩阵对比,混淆矩阵中X轴和Y轴对应着健康、白粉病、锈病和赤霉病4种小麦图像类别标签。其中,X轴代表图像的真实标签,Y轴代表网络的预测标签,当预测标签与真实标签一一对应时,图中颜色越深,证明网络识别相应标签的效果越好。利用混淆矩阵可以明显看出模型预测结果和实际结果之间的误差。结果表明,ViT模型在小麦病害识别任务中有更好的识别效果。通过分析以上性能指标,可以发现在小麦病害识别任务中,相较于传统的卷积神经网络模型,Vision Transformer模型在识别准确率和收敛速度方面优势明显。
(a) ViT
(b) AlexNet
(c) VGG16
4 结论
小麦白粉病、赤霉病和锈病是我国小麦生产上的三大主要病害,本文通过采集这3种小麦病害图片,构建了小麦病害识别数据集,并基于Vision Transformer和迁移学习对小麦病害图像识别算法展开研究。本研究共设置了3组试验,其中采用全参数迁移学习和数据增强训练Vision Transformer模型识别效果最好。通过对各组试验数据进行分析,得出以下结论。
1) 将在ImageNet-21k上训练好的模型权重迁移到Vision Transformer模型上,能够显著地提升模型的识别准确率。训练过程中使用不同的迁移学习方法对模型性能的提升有所差异,其中使用训练模型全部参数的迁移学习方法取得的识别效果最佳;而采用仅训练分类器参数的迁移学习方法对模型进行训练,虽然在识别准确率上略低于训练模型全部参数的迁移学习方法,但是训练时间得以大幅缩短;不使用迁移学习的训练效果最差。
2) Vision Transformer模型在数据增强后的数据集上取得的训练效果更好,模型的泛化能力也更强。在小麦病害图像识别任务中,扩大数据集的样本量能够有效提高模型的识别准确率。考虑到田间复杂环境和拍摄角度等因素可能会对模型识别精度造成影响,本文通过水平翻转、随机角度旋转等数据增强的方式对原始数据集进行扩充,模型在扩充后的数据集上取得了非常好的训练效果,在测试集上的识别准确率也由原来的93.28%提高到了96.81%。
3) 在小麦病害识别任务中,相较于传统的卷积神经网络模型,本文采用的基于Vision Transformer和迁移学习的小麦病害图像识别算法的识别准确率更高,在实际应用中更能满足对作物病害精准、快速诊断的需求。
本文构建的基于Vision Transformer的小麦病害图像识别算法,虽然在小麦病害识别任务中取得了良好的识别效果,但是Vision Transformer模型参数量较大,训练时对硬件要求较高,下一步工作需要对模型进行压缩和优化,在保证模型识别准确率的同时,尽可能地降低模型的参数量,提高模型的泛化能力。
参 考 文 献
[1]姜玉英, 刘万才, 黄冲, 等. 2020年全国农作物重大病虫害发生趋势预报[J]. 中国植保导刊, 2020, 40(2): 37-39, 53.
[2]史雪岩, 李红宝, 王海光, 等. 我国小麦病虫草害防治农药减施增效技术研究进展[J]. 中国农业大学学报, 2022, 27(3): 53-62.
Shi Xueyan, Li Hongbao, Wang Haiguang, et al. Progresses of pesticide reduction techniques in wheat production and the synergistic effects on the prevention and control of wheat pests [J]. Journal of China Agricultural University, 2022, 27(3): 53-62.
[3]周长建, 宋佳, 向文胜. 基于人工智能的作物病害识别研究进展[J]. 植物保护学报, 2022, 49(1): 316-324.
Zhou Changjian, Song Jia, Xiang Wensheng.Research progresses in artificial intelligencebased crop disease identification [J]. Journal of Plant Protection, 2022, 49(1): 316-324.
[4]秦丰, 刘东霞, 孙炳达, 等. 基于深度学习和支持向量机的4种苜蓿叶部病害图像识别[J]. 中国农业大学学报, 2017, 22(7): 123-133.
Qin Feng, Liu Dongxia, Sun Bingda, et al. Image recognition of four different alfalfa leaf diseases based on deep learning and support vector machine [J]. Journal of China Agricultural University, 2017, 22(7): 123-133.
[5]Wang J, Jiang H, Chen Q. Highprecision recognition of wheat mildew degree based on colorimetric sensor technique combined with multivariate analysis [J]. Microchemical Journal, 2021, 168: 106468.
[6]Feng L, Wu B, Zhu S, et al. Investigation on data fusion of multisource spectral data for rice leaf diseases identification using machine learning methods [J]. Frontiers in Plant Science, 2020, 11: 577063.
[7]周惠汝, 吳波明. 深度学习在作物病害图像识别方面应用的研究进展[J]. 中国农业科技导报, 2021, 23(5): 61-68.
Zhou Huiru, Wu Boming. Advances in research on deep learning for crop disease image recognition [J]. Journal of Agricultural Science and Technology, 2021, 23(5): 61-68.
[8]Chen H C, Widodo A M, Wisnujati A, et al. AlexNet convolutional neural network for disease detection and classification of tomato leaf [J]. Electronics, 2022, 11(6): 951.
[9]Chen J, Chen J, Zhang D, et al. Using deep transfer learning for imagebased plant disease identification [J]. Computers and Electronics in Agriculture, 2020, 173: 105393.
[10]Li Y, Wang H, Dang L M, et al. Crop pest recognition in natural scenes using convolutional neural networks [J]. Computers and Electronics in Agriculture, 2020, 169: 105174.
[11]Rangarajan A K, Purushothaman R, Ramesh A. Tomato crop disease classification using pretrained deep learning algorithm [J]. Procedia Computer Science, 2018, 133: 1040-1047.
[12]侯志松, 冀金泉, 李国厚, 等. 集成学习与迁移学习的作物病害图像识别算法[J]. 中国科技论文, 2021, 16(7): 708-714.
Hou Zhisong, Ji Jinquan, Li Guohou, et al. Crop disease image recognition algorithm based on ensemble learning and transfer learning [J]. China Sciencepaper, 2021, 16(7): 708-714.
[13]周宏威, 沈恒宇, 袁新佩, 等. 基于遷移学习的苹果树叶片病虫害识别方法研究[J]. 中国农机化学报, 2021, 42(11): 151-158.
Zhou Hongwei, Shen Hengyu, Yuan Xinpei, et al. Research on identification method of apple leaf diseases based on transfer learning [J]. Journal of Chinese Agricultural Mechanization, 2021, 42(11): 151-158.
[14]张珂, 冯晓晗, 郭玉荣, 等. 图像分类的深度卷积神经网络模型综述[J]. 中国图象图形学报, 2021, 26(10): 2305-2325.
Zhang Ke, Feng Xiaohan, Guo Yurong, et al. Overview of deep convolutional neural networks for image classification [J]. Journal of Image and Graphics, 2021, 26(10): 2305-2325.
[15]刘文婷, 卢新明. 基于计算机视觉的Transformer研究进展[J]. 计算机工程与应用, 2022, 58(6): 1-16.
Liu Wenting, Lu Xinming. Research progress of Transformer based on computer vision [J]. Computer Engineering and Applications, 2022, 58(6): 1-16.
[16]Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need [J]. Advances in Neural Information Processing Systems, 2017, 30.
[17]Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16×16 words: Transformers for image recognition at scale [J]. arXiv preprint arXiv: 2010.11929, 2020.
[18]Ma X, Yan M. Design and implementation of craweper based on Scrapy [C]. Journal of Physics: Conference Series. IOP Publishing, 2021, 2033(1): 012204.
[19]张重生, 陈杰, 纵瑞星, 等. 基于Transformer的低质场景字符检测算法[J]. 北京邮电大学学报, 2022, 45(2): 124-130.
Zhang Chongsheng, Chen Jie, Zong Ruixing, et al. Transformer based scene character detection over low quality images [J]. Journal of Beijing University of Posts and Telecommunications, 2022, 45(2): 124-130.
[20]Parmar N, Vaswani A, Uszkoreit J, et al. Image transformer [C]. International Conference on Machine Learning. PMLR, 2018: 4055-4064.
[21]Barani F, Savadi A, Yazdi H S. Convergence behavior of diffusion stochastic gradient descent algorithm [J]. Signal Processing, 2021, 183: 108014.
猜你喜欢
电子制作(2019年16期)2019-09-27
中国交通信息化(2019年4期)2019-07-13
电子制作(2018年19期)2018-11-14
电子制作(2018年14期)2018-08-21
电脑知识与技术(2017年32期)2017-12-15
现代交际(2017年18期)2017-09-11
振动工程学报(2017年1期)2017-04-21
电子测试(2017年23期)2017-04-04
物联网技术(2015年9期)2015-09-22
现代电子技术(2015年14期)2015-07-22
