
基于联邦学习的个性化推荐系统研究*
2024-05-11 12:02林宁,张亮
科技创新与生产力 2024年4期
林 宁,张 亮
(1.泰州机电高等职业技术学校,江苏 泰州 225300;2.南京师范大学泰州学院,江苏 泰州 225300)
1 研究背景
随着计算机技术的飞速发展,海量的信息存在于各种商业网站和信息分发应用中,信息过载现象严重阻碍了每个人的正常生活。科技的发展给人们生活带来便捷的同时,信息过载、数据冗余等问题也令人头疼。用户的选择越来越多,想要选择到适合自己的事物就变得困难。为了解决此问题,越来越多的人开始关注用户个性化推荐系统。该系统利用用户与各种事物的历史交互数据以及事物之间各特征属性,构建个性化的用户推荐模型,对用户未来可能感兴趣的内容进行精准预测,在众多的数据信息中自动筛选出用户感兴趣的信息及商家。基于联邦学习的用户推荐系统越来越受到广泛的关注。具体来说,推荐系统包括3 个方面的内容,即用户喜好、项目属性、用户与事物的交互数据(如时间、空间数等附加信息)[1]。推荐系统开发者通过向用户推荐匹配的商品来增加销售量,或者为目标用户提供匹配的娱乐内容来增加契合度,进而提高广告的曝光率、点击量等,从而最终为商家提高营业额[2]。随着各种数据保护条例和隐私保护法规的颁布,以及个人用户对隐私数据的保护,人们逐渐意识到隐私数据的保护是非常有必要的。然而传统的机器算法是有缺陷的,如在用户上传数据信息时,很难直接建立起一个有效的模型来保护用户的数据隐私安全。鉴于此,谷歌(Google)公司提出了基于联邦学习技术来建立用户隐私保护机制。
近年来,随着分布式学习和边缘计算技术的快速发展,互联网生态逐渐向移动化和开放化发展,使得用户终端能够存储相当多的原始数据[3]。在传统的集中式推荐系统中,系统首先需要收集到足够多的数据并建立数据关系,构建用户推荐系统,那么在真实情况下,平台能保护好用户的隐私数据吗?用户的隐私数据会不会另作他用?数据安全问题已经成为人们关注的热点之一。
有研究学者提出联邦学习算法可以解决用户隐私数据泄露的问题,而且算法正逐渐受到人们的广泛关注。联邦学习的个性化推荐系统是通过挖掘联合分布在各个设备上的数据集,但又不共享各设备上的原始数据,通过交换模型参数或中间结果的方式,构建基于虚拟全局的用户数据模型,建立分布式机器学习训练模型。一些学者将联邦学习应用到推荐算法中,在模型训练的整个过程中,用户的原始交互数据不用上传到平台,而是通过模型参数或者中间结果进行数据分析和挖掘,构建一套保护用户隐私数据的机器学习模型。联邦学习的推荐系统不要求用户上传原始数据到平台,这大大降低数据泄露的可能性。因此,基于联邦学习模式的推荐算法来解决用户隐私问题,越来越受到人们的广泛关注[4]。目前国内对基于联邦学习的个性化推荐系统研究缺少系统的归纳总结。本研究首先对推荐系统、联邦学习及联邦推荐系统进行概述。
2 推荐系统介绍
2.1 传统推荐算法
1992 年,Xerox 公司最早采用协同过滤算法来解决资讯过载问题。后期在新闻的筛选中,帮助阅读者筛选感兴趣的新闻,例如亚马逊网络书店和Facebook 的广告就非常有名。他们也是采用传统的协同过滤算法,为用户提供其可能感兴趣的书籍或广告。传统的推荐模型基于信息直接筛选分析而成,协同过滤算法先对相似喜好的用户进行数据挖掘,建立用户群,再对这些相似用户进行动态分析,形成对该目标用户的某一信息的喜好程度精准预测[5]。根据协同过滤算法的学习模式不同,可以分为基于领域(物品)的推荐系统和基于模型的推荐系统[6]。其中,基于领域的推荐系统是推荐用户之前喜欢物品的相似物品,通过物品的属性特征计算物品与之前物品的相似度,然后进行推荐[7];而基于模型的推荐系统是给用户推荐一个新的物品,通过对其喜好程度进行量化,结合机器学习算法来针对不同用户计算物品的向量进行训练,建立用户推荐模型来精准预测用户对于新事物的喜好得分,最后采用训练好的模型为用户提供个性化推荐[8]。
2.2 基于深度学习的推荐算法
深度学习技术在计算机网络技术领域已经受到普遍的应用,其强大的拟合能力和高度的非线性表示能力在推荐系统算法领域得到相当高的关注。深度学习是根据用户信息特征进行深层次挖掘,然后经过大量的数据来学习有效的特征表示及复杂的映射,最后建立起有效的数据模型[9]。近几年,记录多分支的浅层神经网络模型得到了广泛运用,但是基于深度学习的数据模型在推荐系统中的应用还处于初级阶段,深度学习技术对领域本身并无特殊要求,在未来多个潜在领域会有广泛的应用。
2.3 基于隐私保护的推荐算法
基于用户隐私数据保护的推荐算法不胜枚举,但是在保护用户隐私的前提下进行精准推荐是人们探讨的热点话题。一方面要保护用户的隐私数据,另一方面又要根据用户的个人信息和交互记录进行推荐,同时还要防护来自不同方面的攻击威胁。传统的推荐系统建立在各数据参与方完全信任的情况下,然而现实中却存在着数据信息泄露的隐患。这种隐患藏匿于平台与用户之间、用户与用户之间、平台与平台之间。在理想的推荐场景中,用户是充分信任平台的,用户将自己的个人信息完全提供给平台使用,然而平台方可能存在对用户信息泄露或滥用等行为。因此,人们的关注热点是能确保用户隐私信息不泄露的推荐系统。另外,在一些特殊场景中,比如分享推荐,用户与用户之间会进行信息的交换,而一些潜在的恶意用户会窃取其他用户的隐私信息,那么用户数据的安全性就会受到威胁。在平台与平台之间也可能会共享用户的交互记录,然而平台之间也并非完全可信,跨平台之间的信息泄露也时有发生。传统的隐私保护推荐系统,采用密码学或者模糊化方法对隐私数据进行保护[10];而近期隐私保护推荐系统的相关工作多以联邦学习为主,并整合加密算法和模糊化算法以更好地保护用户数据隐私安全。
3 基于联邦学习的推荐系统
3.1 联邦学习
在2016 年,Google 公司就提出过联邦学习的框架结构,其本质上是联合分布在各个设备上的数据集,又不共享各设备上的原始数据,建立分布式的学习框架,在保护各方的隐私数据的前提下,共同训练一个共享的数据模型[11]。另外,联邦学习对数据的集中存储不做要求,各参与方对己方数据有绝对的掌控权。联邦学习可以分为模型架构、联邦化、优化和隐私保护等4 个方法。其中,联邦学习的模型架构主要有两种,即中心化联邦架构和去中心化联邦架构,其中,中心化联邦架构即客户端/服务器架构模式,企业是中心服务器,主要是控制协调全局模型;去中心化联邦架构主要采用的是对等模式,针对联合多家数据单薄的困境企业进行模型训练。另外,不同模型的联邦化也是学者研究的重点,包括机器学习、元学习、深度学习、强化学习和迁移学习等方面。联邦学习的模型优化主要包括模型压缩、沟通策略、激励机制和客户抽样策略等方面。另外,同态加密、差分隐私、局部差分隐私等策略均为用户数据隐私保护技术的研究热点内容。
3.2 联邦推荐系统
用户个性化推荐系统是根据用户与某物品的交互数据以及物品特有的属性特点,找出用户潜在的兴趣偏好并建立模型,精准预测后进行用户推荐。一方面,目前主流的推荐模型首先需要收集用户的交互信息并将数据信息上传到平台,然后训练出一个推荐模型,最后生成对每个用户的推荐结果。当用户隐私数据被上传的时候就有可能存在信息泄露的风险[12]。另一方面,由于个人用户担心数据信息的泄露,往往不愿意上传自己的原始数据,这也会导致集中训练模型缺乏数据的问题,最终训练的推荐模型预测性能较差。
而联邦推荐系统是一种分布式机器学习系统,有效保护用户隐私信息,它将集中式的学习框架分布到联邦学习范式的场景中,为用户提供精准的信息推荐。鉴于此,在保护用户隐私数据的同时,还要提高推荐模型的预测性能。联邦推荐系统是联邦学习领域的一个重要应用场景。当前,联邦推荐系统的研究方向主要在架构设计、系统联邦化和隐私保护技术的应用等方面,见图1。
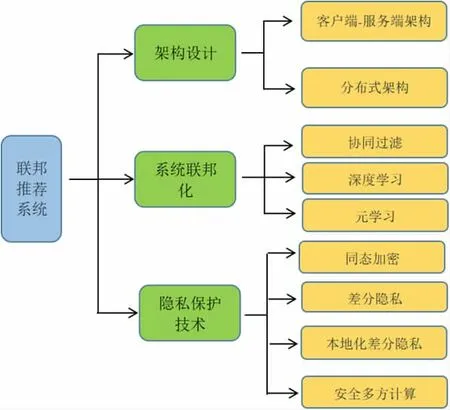
图1 联邦推荐系统的研究方向
3.3 联邦推荐系统的流程与分类
联邦学习的推荐系统是不需要直接访问各方的具体数据,而是通过协调训练的方式进行推荐模型的搭建,最终形成的推荐系统。该系统在保护个人隐私的前提下,具有良好的推荐效果,相比传统的推荐模型来说更有优势[13]。联邦推荐系统的流程具体见图2,其中需要注意:一是每个参与服务器需要从中心服务器中下载所有物品的特征矩阵,而非原始数据;二是每个参与服务器均需要在本地进行信息的整合和筛选,去除不相关的数据信息;三是每个参与服务器在本地计算全部物品特征矩阵和个人用户特征矩阵,及时更新本地个人用户特征和物品特征;四是每个客户端都需要将更新之后的物品特征按照安全协议的要求上传到中心服务器;五是中心服务器再通过联邦平均求解的方式对全部物品特征矩阵进行重新计算,并反馈给每个服务器用于新一轮的计算[14]。

图2 联邦推荐系统的流程
联邦推荐系统可以跟据不同商品的应用场景分为横向联邦推荐系统、纵向联邦推荐系统、联邦强化推荐系统和联邦迁移推荐系统[15]。其中,横向联邦推荐系统研究的是物品相同但用户不同的情况,同时在保护用户隐私的情况下,进行用户行为信息的共享;纵向联邦系统研究的是用户相同但物品不同的情况;联邦强化推荐系统研究的是用户及时反馈的数据情况,提升推荐的及时性;联邦迁移推荐系统研究的则是物品相同但用户重叠、数据不足的问题。
3.4 联邦推荐系统的应用现状
当前,联邦推荐系统的应用尚处于探索阶段,但得到各领域广泛的关注,包括电商、社交软件、在线视频、在线广告等领域。通过对新闻事件的数据分析,搜索系统NewsMiner 数据库的相关数据。据查,联邦学习技术的行业应用最早是在2018 年,应用在金融、IT 和通信领域,后来被逐渐扩展到智慧城市、教育、汽车、金融等多个行业领域。一是联邦学习技术在金融业的应用,仍处于研究阶段。推进联邦学习在金融业应用的参与主体主要是科技公司(如百度、腾讯、京东等)、互联网金融机构(如微众银行、蚂蚁金服等)、少数传统商业银行(如江苏银行、浦发银行、中国建设银行等)。二是联邦学习在医疗业的应用,目前仍处于探索阶段,需要得到科技公司和国内外权威科研机构、高校、医疗机构的支持与帮助。国际性科技期刊Nature(《自然》)曾发表过关于联邦学习技术在医疗领域应用的文章,联邦学习技术在医疗应用领域也有强大的潜力。新冠疫情以来,越来越多的研究者支持通过联邦学习技术以及来自各地区各医疗机构的数据来开发模型。三是联邦学习在电信业的应用,电信业是联邦学习技术的最早应用领域,解决移动设备数据训练问题。如今,联邦学习技术已经从最初的电信业已经逐渐辐射到客户体验和精准营销、网络通信和卫星网络等。
4 基于联邦学习的个性化推荐系统未来将面对的挑战
基于联邦学习的个性化推荐系统可以保护用户的数据隐私安全,但面向未来,基于联邦学习的个性化推荐系统在理论研究和实践应用方面还将面临严峻挑战,包括以下4 个方面。
1)联邦推荐系统的冷启动挑战。当新事物和新用户在进行数据挖掘和分析时,会出现数据量不足的问题。相比而言,传统的集中式推荐系统有强大的数据信息量作支撑。而联邦推荐系统下的冷启动问题更为严峻,联邦学习的推荐系统如何在数据资源不足的情况下构建有效的模型去解决数据稀疏问题,即是联邦推荐系统面临的冷启动挑战。
2)联邦推荐系统的异质性挑战。联邦推荐系统中由于用户为真实的个体,以及用户设备数量和型号各异,导致异质性问题更为严重。因此,在联邦学习框架下细粒度的建模数据异质性以及模型异质性也成为目前推荐系统领域的主要挑战。
3)联邦推荐系统的实时性挑战。实时性挑战主要体现在联邦推荐模型的更新周期和更新效率上。联邦推荐系统还需要进一步研究用户与服务端的数据信息的传输延时等问题;提高联邦推荐模型的更新效率和更新频率,进一步完成推荐系统的用户体验,也是非常关键的问题。
4)参与机制不够完善。在联邦个性化推荐系统中,需要参与各方提供数据并共同完成推荐模型。各方参与商在推荐模型中的获利不同,需要全面地评估各参与方的贡献能力,完善定价策略,合理分配各方的利益。截至目前,仍然没有建立起各方都认同的贡献评价策略,这将为联邦推荐系统的应用带来巨大的挑战。
猜你喜欢
小学生学习指导(低年级)(2022年5期)2022-05-31
疯狂英语·初中天地(2021年11期)2021-02-16
家庭影院技术(2020年10期)2020-12-14
家庭影院技术(2019年7期)2019-08-27
少年漫画(艺术创想)(2019年2期)2019-06-06
商用汽车(2016年11期)2016-12-19
商用汽车(2016年6期)2016-06-29
商用汽车(2016年4期)2016-05-09
小天使·一年级语数英综合(2015年8期)2015-07-06
创业家(2015年5期)2015-02-27
