
多层级信息增强异构图的篇章级话题分割模型
2024-05-11 03:33张洋宁尤泽顺
计算机工程与应用 2024年9期
张洋宁,朱 静,董 瑞,尤泽顺,王 震
1.新疆农业大学计算机与信息工程学院,乌鲁木齐 830052
2.中国科学院新疆理化技术研究所,乌鲁木齐 830011
3.中国科学院大学,北京 100049
随着信息时代的到来,网络上的数据呈爆炸式增长,用户如何获取感兴趣的信息,减轻信息负载成为研究热点。目前,话题分割是一种有效的提取信息方法,它可以揭露文本的潜在结构,增强文本可读性,并为信息检索[1]、文本摘要[2]、话题检测[3]等下游任务提供基础。
话题分割定义为按照话题相关的原则将一篇较长的文本划分为语义段落序列,使得各个语义段落内部具有最大的话题相关性,而语义段落之间具有最小的话题相关性。现有的话题分割方法分为两类,无监督和有监督方法。传统的无监督方法利用向量相似度来判断话题是否发生变化[4]。有监督方法[5]将篇章中每个句子进行一次二分类任务,判断其是否为分割边界。然而现有话题分割仍存在一些问题,以表1为例,句子2和3语义关联性小,仅靠句子语义信息无法判定是否属于同一话题,但是它们分别依靠关键词“Record”和“release”与句子1存在关联,因此三句话属于同一话题“发行”。而句子4“WWE选集在商业上取得了成功”虽然与句子1也存在共现词“WWE”“Anthology”,但是这两个词汇在文章出现频率过高,并且与上一话题没有其他关键词信息,话题语义从发行过渡到反响,因此关键词信息是对该处进行分割的关键。

表1 部分节选内容Table 1 Partial excerpts
从上面分析,为进一步提高话题分割效果,目前话题分割任务主要存在以下挑战:(1)如何提取句子的语义特征,句子中存在复杂的语义关系,加大了句子语义特征提取的难度,挖掘句子语义信息是话题分割任务的基础。(2)如何聚合多层次信息来提高篇章内容建模能力,篇章中存在多种层级单元(段落、语句、单词),具有不同级别粒度的信息,有助于建模并分割篇章话题,但层级与粒度的差异增加了建模难度。(3)如何构建上下文信息交互来加强文本单元全局特征表示,在不同语境上下文中,文本单元的语义特征存在很大差异。
本文提出了多层级信息增强异构图的篇章级话题分割模型(a discourse-level topic segmentation model with multi-level information enhanced heterogeneous graphs network,MHG-TS)。针对挑战(1),模型使用预训练语言模型进行句子语义特征提取,利用大规模语料训练的外部知识和Transformer提取的语义关系增强句子语义信息表达;针对挑战(2),模型引入关键词信息来加强层次信息,通过不同粒度的语义节点充当句子节点之间的中介,拓展了图中的节点与边的类型,构建了句子节点间的远距离跨句信息交互,增强了全局语义信息建模能力;针对挑战(3),模型利用图的非欧几里得结构来表示篇章中的非序列关系,基于图注意力机制在不同层级中的节点间消息传递,有侧重的聚合节点信息,融合一阶邻域、关键词和高阶邻域等层级信息弥补句子在上下文中的全局信息交互不足的缺陷。实验表明本文提出模型MHG-TS在多个基准数据集上实现了最佳性能。
1 相关工作
早期话题分割任务通过观测词汇变化来判别话题变化,例如相邻片段的词共现、线索词、词的转移与变换等。1997年,Hearst[6]提出TextTiling模型用于话题分割任务,该模型利用词频统计构建句子块特征向量,比较向量余弦相似度判断话题变化。该方法构建的特征向量稀疏,只考虑了表层的词统计信息,未考虑语义以及文本单元之间依赖等潜在信息。2003年,Dennis等人[7]使用潜在语义分析(latent semantic analysis,LSA)对词频统计向量进行奇异值分解,使用前k个最大奇异值计算出k维特征向量来近似代替原向量。2012年,Riedl等人[8]使用潜在狄利克雷分配(latent Dirichlet allocations,LDA)主题模型得到句子中单词的主题ID,将原先方法中的单词向量空间降维到主题向量空间,根据主题向量计算相似度来判定话题是否变化。上述两种方法虽然通过特征降维得到了较为密集的向量表示,但是仍未考虑到文本单元之间的信息交互问题。
后来随着深度学习的发展,国内外很多研究学者将深度学习方法运用到话题分割任务。例如,2017 年Wang 等人[9]使用卷积神经网络(convolutional neural network,CNN)提取文本特征,但CNN提取特征为局部特征,全局信息交互能力不强。2018年Li等人[10]提出使用门控循环网络(gated recurrent unit,GRU)结合指针网络进行话题分割;同年Koshorek等人[5]提出使用两层双向长短期记忆(bidirectional long short-term memory,Bi-LSTM)进行话题分割;2020年,Barrow等人[11]提出将话题分割和话题分类两个任务进行联合学习提升分割效果。上述方法虽然考虑到了文本单元之间的交互问题,但基本是利用循环神经网络(recurrent neural network,RNN)按序列顺序捕获特征信息,忽略了单元之间的语法结构等非序列关系。Shi等人[12]将输入单词序列转换成树形结构,通过Tree-LSTM和池化获得句子向量,该方法使用树形结构构建词之间的非序列关系,但模型本质还是基于LSTM 模型,时间空间复杂度较高,文本单元交互能力存在欠缺。Somasundaran[13]提出使用两部分Transformer 来进行话题分割,第一部分将输入单词向量转换为句子向量表示,第二部分得到加入上下文信息的句子表示,该方法能够同时考虑单词级和句子级文本单元间的非序列关系,但是未考虑篇章中的层次信息。
近年来,随着BERT(bidirectional encoder representation from Transformers)[14]的提出,出现了许多以BERT为基础的话题分割模型。2020 年Lukasik 等人[15]使用BERT+Bi-LSTM 进行话题分割,使用BERT 的[CLS]向量作为句子语义表示,然后将向量放入负责捕获句子序列关系的Bi-LSTM中进行分割判定。该方法在单词级文本单元考虑了结构信息,取得了不错的效果提升,但是句子级文本单元仍只能提取到序列信息,在上下文信息建模上存在缺陷。
受到上述研究工作的启发,研究人员意识到利用图的非欧几里得结构模拟文本单元之间非序列关系的效果更佳。2019 年,Yao 等人[16]提出TextGCN(text graph convolutional network)模型应用于文本分类任务,该模型使用语料中的文章和单词作为节点构建异构图,节点初始化特征为独热(one-hot)编码,使用逐点互信息(point-wise mutual information,PMI)作为单词节点之间的边权值,使用词频-逆文本频率指数(term frequencyinverse document frequency,TF-IDF)作为单词与文章节点之间边的权重,通过图卷积网络(graph convolutional networks,GCN)进行迭代,最终取出文章节点的特征作为向量表示进行文本分类,该模型证明图结构应用于文本语义信息挖掘的有效性,但模型将整个语料构建成图,而GCN是full-batch更新(全图更新),节点较多和图较大时全图更新计算慢且内存占用大。2021 年,Lin 等人[17]使用BERT 等预训练语言模型初始化图中文档节点的表示。该方法加强了TextGCN 中使用独热编码而损失的文本语义特征。为解决TextGCN 计算速度的问题,DSG-SEG 模型[18]使用句子节点替代文章节点建立异构图,并使用门控图神经网络(gated graph neural network,GGNN)迭代获取具有全局信息的句子编码,但GGNN会在全部节点上多次运行递归函数,需要将全部节点的中间状态存储下来。
2 MHG-TS模型结构
为了解决句子的语义特征提取不足、忽略篇章中的层次信息和上下文信息交互等问题,本文提出了一个融合图注意机制的话题分割模型MHG-TS,如图1 所示,模型包括三个模块:(1)图初始化模块,分为节点特征初始化和边权值的构造编码,节点特征初始化使用预训练模型初始化节点表示,边权值的构造编码根据节点之间关系进行边初始化编码;(2)图聚合模块,分为一阶邻域层级,关键词层级,高阶邻域层级,基于图注意力机制完成层级中的消息传递聚合;(3)分割边界预测模块,将是否为边界视为二分类任务,概率大的标签为预测结果。
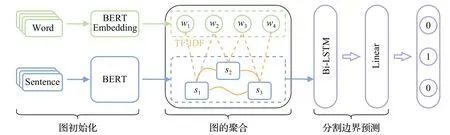
图1 MHG-TS模型流程Fig.1 MHG-TS model process
2.1 图初始化模块
构建一张图G={V,E},节点集V可以定义为V=Vw∪Vs,其中Vw=w1,w2,…,wm表示文档的m个不重复的单词,Vs={s1,s2,…,sn}对应于文档中的n个句子;E代表节点之间所有边的集合,表示为E=Eii∪Eij,Eii为句子节点之间的边,Eij为单词节点与句子节点之间的边。图的初始化包括节点特征的初始化和边的构建编码两部分。
2.1.1 节点特征初始化
由于该模型将篇章中的句子以及单词作为节点,因此需要初始化这两种节点。W∈Rm×d和S∈Rn×d分别表示单词和句子节点的输入特征矩阵,Rm表示为m个单词节点,Rn表示为n个句子节点,d为节点特征的维度,图中得到的节点特征矩阵表示为X=W∪S,X的前m行存放单词节点,从m+1 行开始存放n个句子节点,如式(1)所示:
(1)句子向量表示使用预训练语言模型中每一层的[CLS]向量相加,该方法不仅考虑了预训练语言模型深层提取到的语义信息,更能结合表层提取到的局部短语结构等信息,丰富了句子向量的表达。
(2)单词嵌入向量引入预训练语言模型的词嵌入层进行嵌入,为单词嵌入带来经过大规模语料训练的更准确语义信息。
2.1.2 边权值的构造编码
在图结构中,边的构建对于节点间的信息传递有一定的影响。考虑到节点并非篇章级别,为挖掘篇章中的文本结构和上下文等信息,本模型设置三种类型的边:句子节点之间的边,单词节点与句子节点之间的边,句子节点的自环边。两个节点i和j之间的边的权重定义为:
(1)句子节点之间的边,考虑到句子节点初始化是句子级别,经过预训练模型并未考虑到篇章级的上下文语境等信息,所以将篇章中所有句子节点连接在一起,使用图注意力机制计算节点间的相关性进行信息传递。
(2)关键词节点与句子节点之间的边,为了进一步增强单词节点与句子节点之间的关系重要性信息,本文对句子节点与其包含的所有单词节点之间初始化了一条权重为TF-IDF 值的边。TF-IDF 值[19]的计算公式如(3)~(6)所示:
其中,n表示该单词节点在当前句子中出现的次数,D表示篇章中句子总个数,Di表示包含指定词的句子个数,将TFw与IDFw相乘得到初始的TF-IDF值,再进行欧几里得范数归一化得到最后的TF-IDF值。
(3)句子节点的自环边,为了防止网络在迭代传递信息的过程中,过分关注聚合到的邻居节点信息,而忽略自身节点信息,故在所有句子节点增设自环边。
2.2 图聚合模块
2.2.1 一阶邻域层级的消息聚合
经过图的初始化后,构造出的图G中具有节点特征矩阵Xi和邻接矩阵Aij,隶属于同一话题的句子存在潜在的语义联系,模型首先在句子节点之间利用图注意力机制GAT传递信息获取初步的全局特征表示。计算过程如下所示:
其中,Wa、Wq、Wk、Wv是可训练的权重参数矩阵,αij是si和sj即句子i和句子j之间的注意力权重,σ为非线性激活函数,为全面表示句子节点信息,将多头注意力学到的特征进行拼接作为最后节点特征的表示ui:
在句子节点得到初步全局信息之后引入Transformer中的前馈网络(feed forward network,FFN),通过线性变换加强模型提取更深层次特征的能力。
如图2所示,句子节点聚合一阶邻域内的句子节点信息,从而获得具有全局信息的篇章级的句子表示,计算过程如下所示:
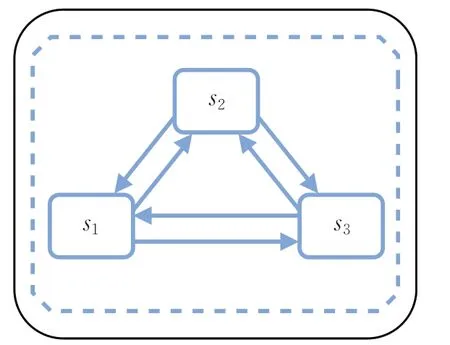
图2 句子节点特征更新过程Fig.2 Updating process of sentence node features
2.2.2 关键词层级的消息聚合
图初始化在关键词节点与句子节点之间的边引入了TF-IDF 值作为初始化边权重eij,因此将等式(7)改为(12),得到新的GATsw:
其次通过引入句子内的关键词特征信息,丰富句子节点特征的层次信息,使用GATsw和FFN 层实现一阶邻域内关键词节点信息向句子节点的聚合,计算过程如下所示:
2.2.3 高阶邻域层级的消息聚合
如图3 所示,为加强间接相邻的跨句信息交互,实现高阶邻域节点间的信息传递,本方法以关键词节点为中介,使聚合关键词层级信息的句子节点反向传递信息给单词节点得到新的单词节点表示Mw,再迭代更新句子节点表示Ms,每次迭代都包含一次上述更新过程。n次迭代过程可表示为:
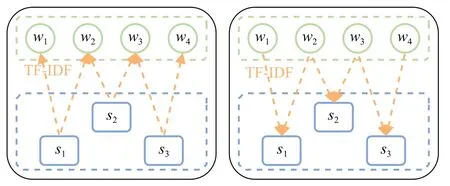
图3 句子节点与单词节点间的特征更新过程Fig.3 Feature update process between sentence nodes and word nodes
2.3 分割边界预测模块
通过上述过程,模型得到了篇章中的句子向量序列(m1,m2,…,mi,…,mn),由于上述图模型更关注跨句之间的联系,为了加强句子之间的序列关系,本文将该句子向量序列放入Bi-LSTM[20]中,得到隐藏层的向量序列表示(h1,h2,…,hi,…,hn),如下所示:
然后将上述向量序列表示经过全连接层分类器,再使用softmax输出一个(0,1)的概率分布,作为每个句子作为分割边界的概率,同Omri Koshorek提出模型一样,对于包含n个句子的篇章,通过降低前n-1 个句子的损失来训练模型,为解决分割点与非分割点的样本不平衡造成数据的长尾问题,本文使用Polyloss 损失函数[21],如式(16)、(17)所示:
其中,Pt为模型对目标分类的预测概率。
3 实验及结果分析
实验中为验证本文提出模型的有效性,模型在英文数据集中使用一个较大规模的训练集进行训练,在6个数据集上进行测试,中文数据集使用一个进行训练测试,有关数据集的部分信息如表2所示。

表2 有关数据集的部分信息Table 2 Some information about datasets
3.1 数据集及评价指标
3.1.1 数据集
实验选择话题分割领域常用的7 个数据集:WIKI-727K、SECTION、CHOI、ELEMENTS、CITIES、WIKI-50、Weibo等。其中WIKI-727K作为训练语料,从它的训练集、验证集、测试集中分别抽取8000、1 000、1 000 条数据,组成新的包含10 000 条数据的WIKI-10K,使用WIKI-10K中的8 000条数据作为训练集,训练出的模型在除中文数据集Weibo外的几个数据集上进行测试:
WIKI-10K(Koshorek 等人[5])测试集由WIKI-727K测试集中随机抽取的1 000条数据组成。
SECTION(Arnold 等人[22])数据集由38 000 个英文和德文维基百科文档组成,本实验使用其中英文语料,包含21 376 个英文文档,数据集主要包含疾病和城市等,本文使用7∶1∶2比例划分该数据集,最终得到4 142个数据作为测试集对模型进行测试。
Weibo(Zhang 等人[23])数据集包括20 000 个中文文档,由微博上爬取微博新闻拼接而成,按16∶4∶5的比例划分数据集,4 000条作为测试集。
CHOI(Choi[24])数据集由920 个人工生成的文档组成,每个文档都是布朗语料库中10个随机段落的拼接。
ELEMENTS(Chen 等人[25])数据集包含118 篇从维基百科抽取的文档,主要内容包括周期表中化学元素的作用、发生率以及同位素等。
CITIES(Chen 等人[25])数据集是作者从英文维基百科抽取的100 篇文档,主要内容包括城市的历史、文化和人口统计信息等。
WIKI-50(Koshorek等人[5])数据集是由作者从WIKI-727k数据集中随机抽样取得的50个测试文档。
7个数据集中除前3个进行了数据集划分使用测试集测试,其余数据集皆使用全部数据对模型进行测试。
3.1.2 评价指标
本实验使用Pk[26]、WindowDiff(WD)[27]、B(boun-dary similarity)[28]等三个指标来评估模型的性能。具体计算如下所示:
由Pk和WD公式定义可知,值越小代表真实分割和预测分割的差异越小,模型的性能越好;由B的定义可知,B的值为1减去每个边界对的不正确性除以边界对的总数,故B的值越大,模型性能越好。
3.2 实验设置
3.2.1 基线模型
为验证本文提出模型在话题分割任务上的有效性以及融合多层级信息捕获篇章全局信息的能力,本文设置实验将模型与多种句向量嵌入模型进行对比。
表3说明了本次实验所涉及的模型:
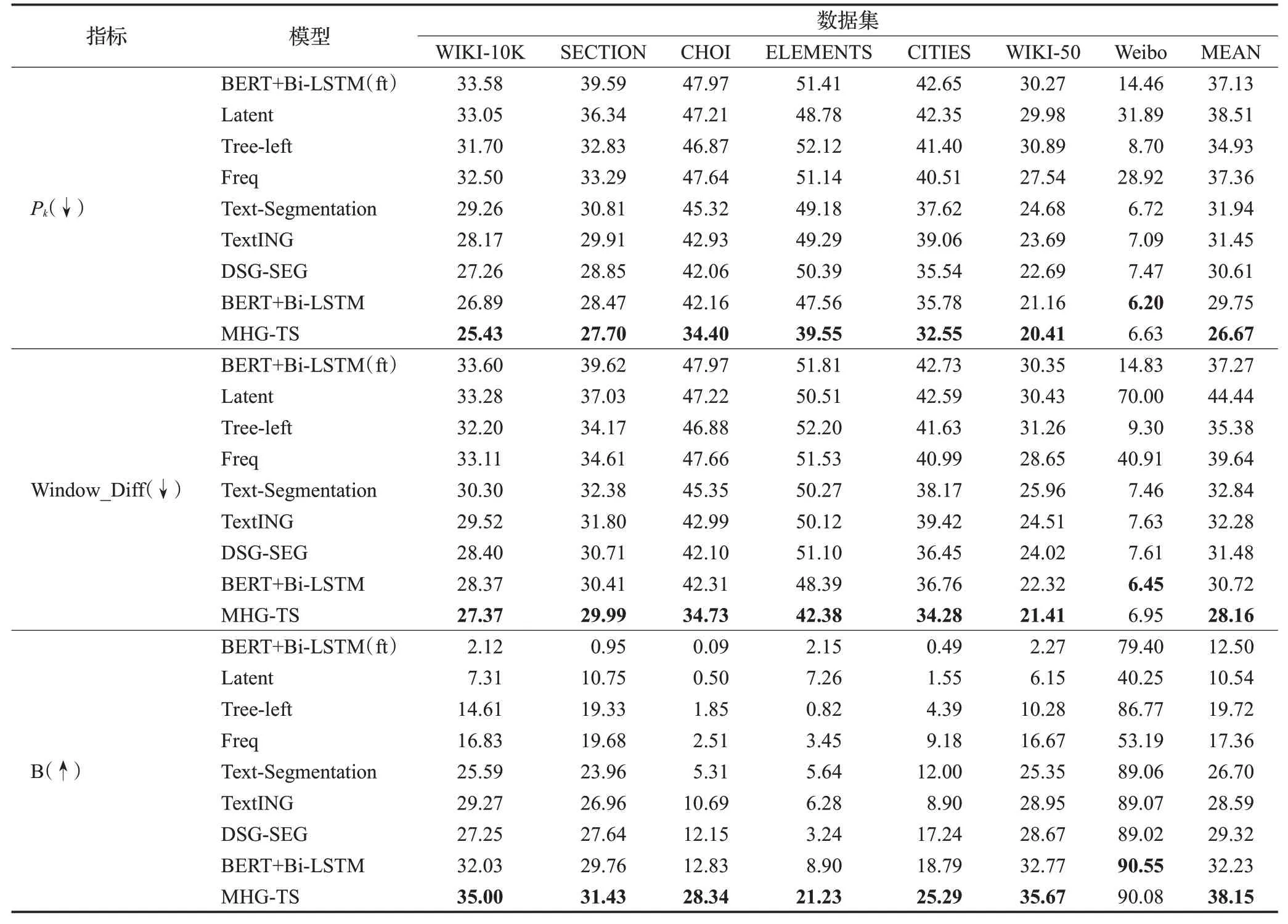
表3 模型的测试效果指标Table 3 Test effect indicators of models 单位:%
Latent 方法根据n个句子中出现的m个单词构成n×m维的词频矩阵,其次使用奇异值分解,选择前300个最大奇异值计算出300 维特征向量来近似代替原矩阵,再将特征向量放入分割点预测层;
Tree-left方法模型首先使用静态词向量将每个单词进行初始化,再将单词序列放入Tree-LSTM 模型中,通过注意力池化得到300维的句子向量表示,最后将向量表示放入分割点预测层,本方法使用左平衡树结构;
Freq代表词频方法,取10 000个高频单词和两个特殊标识符
Text-Segmentation 模型[5],首先使用静态预训练词向量初始化单词序列,再通过双层Bi-LSTM 模型和最大池化输出512维的句子向量表示,最后进行分割点预测;
TextING 模型[18]使用篇章中的单词构建图网络,使用词嵌入模型进行初始化,通过GGNN网络迭代更新单词节点,然后通过读出函数(readout function)融合所有单词节点得到句子的向量表示,最终进行分割预测;
BERT+Bi-LSTM 模型[15]将句子输入BERT,使用768 维[CLS]字符向量代表句子向量,再通过256 维Bi-LSTM预测分割点;
DSG-SEG 模型[18]首先将篇章构建成图,使用静态预训练词向量初始化词节以及和最大池化词向量的方式初始化句子节点,再使用GGNN网络进行迭代得到句子的向量表达,接着将得到的句子向量进行分割点预测。
3.2.2 实验参数
初始化模型:Tree-left、Text-Segmentation、TextING、DSG-SEG 四个模型分别使用300 维的中英文词向量模型Google News Word2Vec、SGNS Weibo;BERT+Bi-LSTM(ft)、BERT+Bi-LSTM、MHG-TS使用的中英文预训练语言模型为BERT-base-uncased、wobert-Chinese-base。
MHG-TS模型参数:高阶邻域信息迭代模块的迭代次数设为1,GAT层维度为512,注意力个数为8,Bi-LSTM隐藏层维度为128。
训练与预测参数:batch-size 设置为8,优化器选择Adam[29],初始化学习率设置为2.5E-4,损失函数Polyloss中的超参数α和γ分别为0.4(中文0.25)和2。若模型指标在验证集超过5 轮未提升,训练结束。同Text-Segmentation 模型一样,模型验证过程中会优化一个阈值,在预测阶段,当句子预测概率超过该阈值,句子预测标签为1,反之为0。
实验设备:24 GB 显存的NVIDIA GeForce RTX 3090。
3.3 实验结果
表3 显示了MHG-TS 与其他基线模型在多个数据集上的测试效果,实验结果表明:
(1)MHG-TS 模型在多个数据集取得了最好的结果,在三个指标上分别比最优基线模型的实验结果平均值提高了3.08%、2.56%、5.92%,证明了模型的稳定性;由于多个数据集的数据分布不同,证明了MHG-TS模型的鲁棒性。
(2)从提升效果来看,CHOI、ELEMENTS、CITIES三个数据集提升最多,从数据集信息可知,这三个数据集的话题转换次数最多,分割点密集,上下文交互信息复杂。证明MHG-TS 模型引入的层次信息加强句子联系,以及通过图注意力机制有侧重的相关语义信息聚合,有助于提取到更适合话题分割任务的语义特征。
(3)在中文数据集Weibo未取得最优的原因可能是中文分词过程中专有名词未被保留,导致关键词提取不够准确,该问题同样出现在使用图网络的TextlNG、DSG-SEG模型中。
(4)在所有模型中,TextlNG、DSG-SEG、BERT+Bi-LSTM和MHG-TS取得了较好的结果,表明了图网络所构建的非序列关系以及预训练模型注入的先验知识对话题分割任务的有效性。
3.4 实验分析
3.4.1 消融实验分析
为了研究异构图中不同层级信息:句子节点一阶邻域的层级信息;以及关键词节点层级信息和句子节点高阶邻域的层级信息,对模型性能的影响,故设置如下消融实验:
(1)模型不包含关键词层级信息和高阶邻域层级信息,仅保留句子节点一阶邻域中的信息传递(记作w/o word)。
(2)模型去除句子节点之间的一阶邻域层级信息,使用单词与句子之间的迭代传递信息,只通过中介节点构建跨句关系(记作w/o sentence)。
表4显示了消融实验的结果,实验表明:
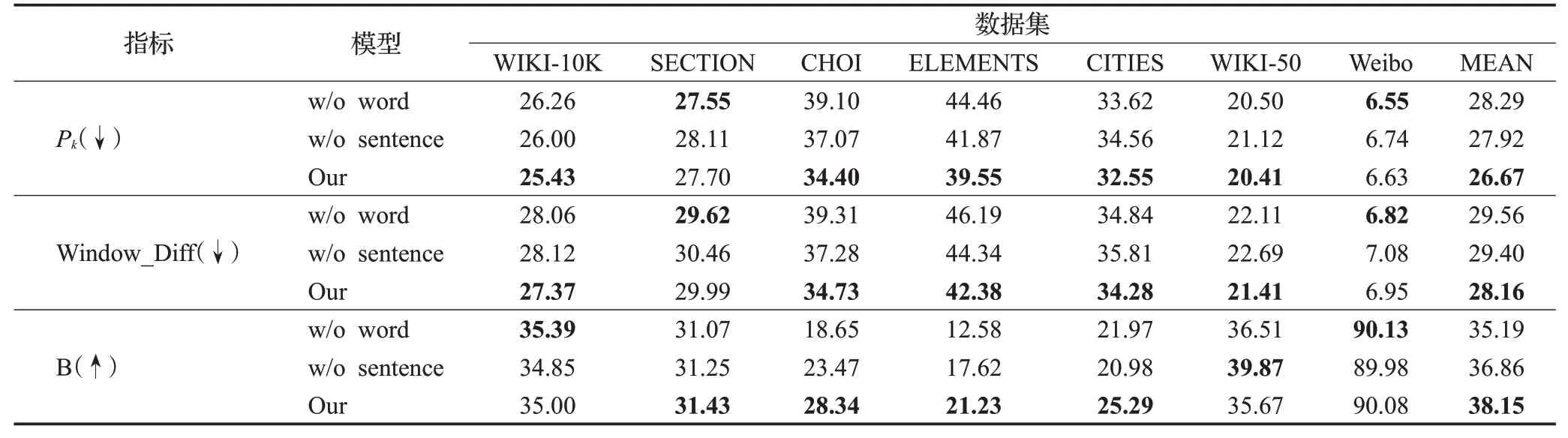
表4 消融实验结果Table 4 Results of ablation test 单位:%
(1)不使用单词与句子节点之间的信息传递的w/o word模型,在所有数据集上,三个指标性能分别比原模型平均下降了1.62%、1.4%、2.96%。这一结果表明,在模型中引入附加层次信息,通过将附加节点作为媒介聚合高阶邻域层级信息的有效性。
(2)没有使用句子节点之间图注意力的w/o sentence模型,在所有数据集上的性能出现了下降,三个指标性能分别平均下降了1.25%、1.24%、1.29%,证明使用句子节点一阶邻域中图注意机制可以提取到对话题分割任务有效的语义信息。
(3)从指标变化分析,SECTION 这个数据集上Pk值出现不稳定的消融效果,可能的原因是,句子之间共现词过多,导致引入词节点间接信息交换出现不稳定。Weibo数据集在w/o word模型上性能提升,原因可能是中文数据集中有太多专有名词或生僻词,导致分词过程引入了数据噪音,对模型产生影响。
(4)三个模型在CHOI、ELEMENTS 两个数据集上差距最大,w/o sentence模型强于w/o word模型证明了利用关键词节点增强层次信息和高阶邻域信息在话题转变较多数据集中的有效性。
3.4.2 不同句向量初始化分析
表5 展示了使用三种预训练语言模型常用句向量表示方法的实验结果,以验证预训练语言模型不同句向量表示方法对后续分割效果的影响。三种表示方法分别为使用BERT所有层的[CLS]字符向量相加(记为All-CLS)、仅使用最后一层[CLS]字符向量(记为Last-CLS)、第一层与最后一层隐藏向量平均池化(记为First+Last)

表5 不同句向量表示的实验结果Table 5 Experimental results expressed by different sentence vectors 单位:%
表5 结果说明,本文模型在上述数据集中All-CLS作为句子向量表示要优于Last-CLS 和First+Last 方法,其原因可能为:引入不同层的向量信息可以丰富句子向量表达,融合了深层的语义信息和表层的短语结构和句法信息。
3.4.3 样例分析
该样例出自WIKI-10K 测试集,介绍了一个名叫Amguri的地方,包含六个话题片段:0~2、3~6、7~13、14~17、18~19、20~21,分别为地理、人口统计、教育、文化、政治和健康。如表6 所示,分别为真实分割结果以及DSG-SEG、BERT-Bi-LSTM和MHG-TS模型分割结果。

表6 样例分析结果Table 6 Sample analysis results
从分割结果可以看出,只有MHG-TS模型预测到了17、19这两个分割点。这两处分割点话题段落较短,话题转移频率较高,证明了MHG-TS模型应对话题分割任务的有效性。
BERT+Bi-LSTM和MHG-TS模型都错误地在第9句话分割的可能原因是:7~9和10~13虽然都是在讲Amguri的教育,但是话题主语从Amguri转移到Rameswar Dutta高中,序列关系上出现了话题的递进。
MHG-TS 和DSG-SEG 模型将第12 句话预测为分割点的可能原因是10~12句着重描写了Rameswar Dutta高中的由来,Dutta关键词出现频繁,模型受到关键词语信息的影响,进而导致分割错误。
由上所述,MHG-TS模型取得更好的分割结果,成功结合了不同粒度文本单元的信息,适用于话题分割任务。
4 结束语
本文针对现阶段模型对句子的语义特征提取不足、忽略篇章中的层次信息和上下文信息交互等问题,提出一个话题分割模型MHG-TS,该模型首先使用预训练语言模型初始化图中关键词与句子节点表示,再通过图注意力网络进行图中句子节点一阶邻域层级的信息传递,初步得到具有全局信息的句子节点表示;再通过引入更细粒度的文本单元构建关键词层级,注入外部知识;利用关键词节点充当中介,帮助模型建立更复杂的句子间关系,将信息传递推广到高阶邻域以加强局部句子节点间的信息交互;最后使用Bi-LSTM 网络提取序列关系进行分割边界预测。在七个数据集上的对比实验结果证明了MHG-TS模型在话题分割任务中的有效性,并验证了多层级信息增强全局语义信息提取的合理性。
在接下来的研究中,将探索中文语料中关键词节点的抽取和句子节点的信息挖掘,同时根据节点之间的潜在语义联系,对节点之间的边进行筛选,保证模型性能的同时,降低模型计算复杂度。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
航天工业管理(2020年9期)2020-12-28
军事运筹与系统工程(2020年1期)2020-09-11
开放教育研究(2020年2期)2020-03-31
现代语文(2016年21期)2016-05-25
高中生学习·高三版(2016年9期)2016-05-14
系统工程与电子技术(2016年2期)2016-04-16
新高考·高二数学(2015年11期)2015-12-23
大连民族大学学报(2015年2期)2015-02-27
