
FA-SORT:轻量化的多车辆跟踪算法
2024-05-11 03:33欧阳博朱勇建杨礼康王本源
计算机工程与应用 2024年9期
欧阳博,朱勇建,杨礼康,王本源
1.浙江科技学院机械与能源工程学院,杭州 310023
2.上海应用技术大学计算机科学与信息工程学院,上海 401800
3.宁波敏捷信息科技有限公司,浙江 宁波 315300
随着无人机技术的快速发展,无人机因其灵活、紧凑、轻便等优点,广泛应用于智能视频监控、目标识别、医学诊断、视觉导航和空间监控等领域[1]。
多车辆跟踪(multi-vehicle tracking,MVT)是无人机重要应用场景之一。MVT是对视频中多个车辆目标进行检测和定位,并赋予身份识别号(identification,ID),再通过数据关联方法来维持车辆各自的ID 号,实现轨迹追踪的连续性。目前大多数的多目标跟踪方法都采用先检测后跟踪(tracking by detection,TBD)范式[2],该范式实施步骤:首先通过检测算法获取当前帧目标检测框消息(包括目标位置信息、类别、置信度得分),再使用现有的预测方法对当前帧目标位置进行估计或者使用特征提取方法(如重识别[3-4]、REID(re-identification)、Transformer[5]等网络模型将检测框内的外观特征处理成低维向量)获得当前帧目标外观特征向量,最后将目标位置的估计值或外观特征向量与下一帧目标检测框进行IOU 匹配或外观特征匹配,若前后帧判定为同一目标,则赋予相同的ID,维持目标轨迹的连续性,实现多目标追踪任务。
针对TBD 范式的研究,Bewley等人[6]提出SORT算法,利用卡尔曼滤波[7](Kalman filter,KF)对当前帧目标检测框的位置进行预测,然后与下一帧检测器获取的目标检测框进行IOU 匹配,再通过匈牙利算法[8]进行最优分配,实现多目标跟踪。但该算法未考虑目标被遮挡情况,导致ID 频繁切换。DeepSORT[9]算法将外观特征匹配引入到数据关联中,用以解决SORT算法所存在的问题。当目标被遮挡时,通过保存目标遮挡前的外观特征信息,用以保留该目标的ID,当目标遮挡结束后,可以利用遮挡前、后的外观特征信息进行匹配,从而有效地解决了目标因遮挡发生ID切换的问题。Wang等人[10]提出JDE 算法和Zhang 等人[11]提出FairMOT 算法都是在一个网络模型中同时训练目标检测模型和外观特征模型,通过“一阶段式”方法共享大部分计算量来减少推理时间。但这种“一阶段式”跟踪算法的精度往往低于“两阶段式”。StrongSORT[12]算法分析了“一阶段式”联合跟踪器精度低的主要原因是不同组件(目标检测、运动特征、外观特征模型等)之间的竞争和用于联合训练这些组件的数据集是有限的,故仍然使用“两阶段式”模型,并对DeepSORT算法的各个组件进行改进,提出了无外观链接模型(AFLink)和高斯平滑插值算法(GSI)两种即插即用的模块,用于提高轨迹关联的连续性。Aharon等人[13]提出BOT-SORT算法,分析了无人机在高空飞行时会出现抖动导致KF 预测目标位置不准确的问题,从而影响前后帧IOU 匹配关联,提出使用相机运动补偿(GMC)校正图像用于解决该问题,并使用IOU+ReID融合机制解决因拥挤和遮挡导致检测框得分低而不被关联匹配的问题。上述的方法基本都采用外观匹配方式来解决目标遮挡问题,但引入外观特征模型会影响跟踪的实时性,于是Zhang 等人[14]提出ByteTrack 跟踪算法,将检测置信度得分低的目标进行二次关联匹配用于解决目标遮挡问题。Cao等人[15]提出OC-SORT算法,通过改进卡尔曼滤波和以观测值为主要的跟踪信息方法来改善目标遮挡和非线性运动导致目标ID 切换的问题。Li等人[16]提出BVTracker,分析了在鸟瞰视角下,目标外观彼此相似,缺乏足够的外观特征信息,因此使用联合目标检测和REID 模型的方法可能无法满足跟踪需求。因此,提出了一种基于长短期记忆递归神经网络[17](long short term memory,LSTM)和自注意力网络用于轨迹预测的混合模型。
综上所述,使用无人机对复杂场景下的多车辆跟踪主要存在以下三点问题:(1)由于高空飞行,无人机图像中的车辆目标像素点少,常规的检测方法对小目标检测效果差,从而导致后续的跟踪性能差。(2)在自然场景中,车辆运行是非线性的,如超车、等红绿灯、变道等情况,导致车辆目标前后帧IOU 匹配困难,影响跟踪精度。以及车辆因遮挡发生非线性运动,使用传统KF 对目标位置估计不准确。(3)无人机在高空下为鸟瞰视角,对于同一类型的车辆,外观彼此相似,使用外观特征匹配的方式处理车辆拥挤或遮挡情况时表现不佳。
因此,针对上述问题,本文采用“tracking by detection”两阶段式跟踪策略,提出FA-SORT轻量化跟踪模型,并将改进的YOLOv8[18]检测算法应用在该模型当中。针对上述MVT存在的问题1,本文在原YOLOv8检测模型中添加BiFormer[19]稀疏动态注意力模块用来增强图像上下文信息的联系,提高对车辆小目标特征提取的能力。与Transformer 相比,BiFormer 在保持良好的性能情况下,大大降低了计算复杂度。并且使用CARAFE[20]模块替换原上采样,保持原始特征图的细节和边缘纹理信息,减少上采样过程中小目标特征丢失的问题。从而提升对小目标的检测能力。针对上述MVT 存在的问题2 和3,本文基于SORT 跟踪模型提出了三点改进策略,(1)使用改进的KF解决车辆因遮挡发生非线性运动导致预测车辆位置不准确的问题。(2)通过添加速度方向一致性匹配解决车辆因非线性运动导致目标的检测值与KF 预测值IOU 匹配困难的问题,从而增强数据关联匹配。(3)使用检测值匹配方式替换外观匹配[3,21]解决无人机鸟瞰视角下车辆拥挤或遮挡导致跟踪失败的问题,从而减少车辆身份ID的切换次数,提高跟踪的准确性和跟踪的速度。
1 改进YOLOv8检测算法
1.1 YOLOv8原理
YOLO系列在目标检测方面具有速度快、检测精度高和适用性广等优势,被广泛应用于实际生产和生活的各种场景当中,YOLOv8[18]是目前YOLO 系列中最先进的一阶段目标检测算法,该模型是在YOLOv5基础上添加了新的改进方法,使得检测精度得到有效的提升。该算法框架主要由输入端(Input)、骨干模块(Backbone)、颈部模块(Neck)和头部模块(Head)这四部分组成。与YOLOv5相比,主要的改进思路如下:
(1)Backbone 模块:骨干网络依旧采用YOLOv5 的骨干网络结构,不过将原来的C3 模块替换成梯度流更为丰富的C2f 模块,不仅模块更加轻盈化,而且增强了特征的融合能力。
(2)Neck模块:颈部模块结构也是采用YOLOv5的颈部网络结构,同时也将C3模块替换成C2f模块,并且删除了PAN-FPN上采样阶段中的卷积模块。
(3)损失函数:YOLOv8 采用Anchor-Free 思想,因此,只使用分类损失BCE Loss和回归损失CIOU Loss+DFL(distribution focal loss)。
(4)样本的分配策略:YOLOv8 采用Task-Aligned Assigner[22]正负样本动态匹配方式替换原本以IOU匹配或者单边比例的分配方式。
1.2 YOLOv8模型改进策略
1.2.1 BiFormer模块
Transformer凭借自注意力机制(self-attention)的优势,能够捕捉图像上下文特征信息,被广泛应用在目标检测模型中[23],用以解决图像中小目标检测效果差的问题。但传统的Transformer 模型参数量大,如果直接对特征图全局范围内操作的话,会导致计算成本高,增大内存占用,影响图像检测速度,并且会因处理特征图中非目标区域而浪费大量的时间。针对该问题,不少研究者在Transformer中引入稀疏注意力,即每个查询(query)只关注小部分键值(key-value)对,而不是全部。例如将注意力操作限制在特征图中的局部窗口[24]、轴向条纹[25]或扩张窗口内[26],而非全局,称这一类方法为手工制作的稀疏模式。还有一类方法为自适应稀疏模式,例如Chen等人[27]提出一种可变形patch模块(DePatch),以数据驱动的方式将图像自适应地分割成具有不同位置(position)和大小(scale)的patch,打破常规的固定patch分割方式。Xia 等人[28]提出一种可变形的自注意力(deformable attention transformer,DAT)模块,以数据依赖的方式选择自注意中的键值对的位置,使得自注意力模块能够专注于感兴趣区域,并捕捉到更多的信息特征。但这类方法还是将与内容无关的稀疏性引入到注意力机制当中。
综合上述分析,为了提高对小目标特征提取能力,本文在YOLOv8 网络模型中引入了基于Transformer 变体的BiFormer动态稀疏注意力模块,该模型提出了一种双层路由注意力机制(bi-level routing attention,BRA)用以缓解多头自注意力(multi-head self-attention,MHSA)的可扩展性问题。BiFormer模块遵循Vision Transformer架构设计,采用特征金字塔结构。图1(a)、(b)分别为BiFormer以及BiFormer Block的模型结构图。BiFormer是由多个BiFormer Block 模块构成的,而BRA 模块是BiFormer Block 核心模块。BRA 核心思想是对特征图的粗区域过滤掉不相关键值对,即通过构建和修剪区域级有向图,再通过区域的联合中应用细粒度的token-totoken注意力实现过滤操作。下面给出BRA模块的具体实施过程。
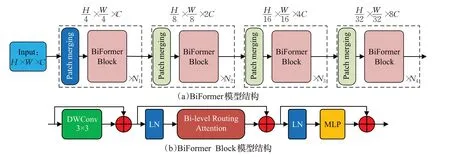
图1 BiFormer、BiFormer Block模型结构图Fig.1 BiFormer,BiFormer Block model structure diagram
图2 为BRA 模块结构图,假设输入一张图片,宽为W,高为H,通道数为C,用X∈RH×W×C表示,将输入的图片划分为S×S个区域,每个区域的特征为HW/S2,则X表示为,再通过线性投影获得:
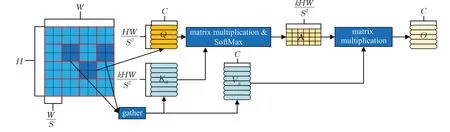
图2 BRA模块结构图Fig.2 BRA module structure diagram
式(1)中,Wq,Wk,Wv∈RC×C,分别为Q(query)、K(key)、V(value)的投影权重,。然后需要找到每个区域感兴趣的部分,即先计算Q、K在区域里的平均值Qr、Kr,再计算两者的区域间相关性矩阵:
然后只保留每个区域的前k(top-k)个连接来修剪相关性图。利用行列top-k算子获得索引矩阵:
再对聚集后的Kg,Vg使用注意力操作得到:
式中,LCE((V))为局部上下文增强项。因此,BRA模块不仅能够捕捉图像上下文特征信息,而且大大降低了计算复杂度。
本文将BiFormer中BRA模块引入到YOLOv8网络模型,如图3 所示,当输入图像通过SPPF 模块之后,此时的图像经过了32倍下采样,得到的特征图尺寸最小,因此,在该位置添加一个卷积模块和BRA 模块可以捕捉特征图的细微信息,增强图像上下文信息关联,提高对特征图中小目标特征提取的能力。
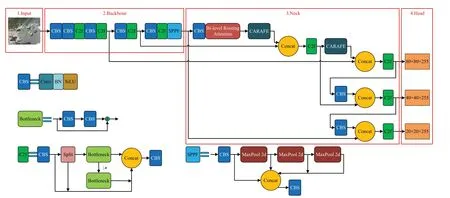
图3 改进YOLOv8模型结构图Fig.3 Improved YOLOv8 model structure
1.2.2 CARAFE模块
在YOLOv8算法中,上采样操作主要以常用的最近邻线性插值法为主,其作用是将特征图的分辨率放大,使得网络能够融合来自不同尺度的特征信息。但在处理密集的小目标场景时,仅使用了图像中最近邻的几个像素点的值与上采样核进行加权计算,而没有用到特征图的语义信息,这会导致图像中的细节和纹理信息丢失,使得插值结果显得过于平滑,无法准确还原原始数据的细节。
针对该问题,本文将YOLOv8 中最近邻线性插值法替换成轻量级上采样算子CARAFE[3](content-aware reassembly of features),CARAFE是一种基于内容感知的特征重组上采样方法,相比于线性插值上采样,通过对输入特征图进行分块处理,并利用卷积操作对每个分块进行特征重组。这种方式可以增强感知范围,使得上采样后的特征图能够融合更多的上下文信息,保持原始特征图的细节和边缘信息,从而提高上采样的质量和特征表达能力。CARAFE算子实现流程如图4所示,主要通过上采样核预测和特征重组这两个模块来完成的。当一张图像通过本文改进的YOLOv8模型中BRA模块之后,得到一个形状为H×W×C的特征图,再将该特征图输入至上采样算子CARAFE。使用CARAFE 算子实现上采样具体实施步骤如下:(1)首先将输入的特征图通道数C压缩至Cm,目的是减小后续步骤的计算量。(2)再使用的卷积层对通道数压缩后的特征图进行上采样核预测,得到一个形状为的上采样核,然后将其通道维度展开成宽、高维度,此时,得到的上采样核形状为σH×σW×,其中,σ为上采样倍率,为上采样的尺寸。最后对上采样核进行softmax 归一化,使其卷积核权重和为1。(3)在特征重组模块中将输出特征图的每一个位置映射回X,然后取出以之为中心点的kup×kup区域,将得到的区域与该点的上采样核作点积,相同位置的不同通道共享同一个上采样核,最后输出一个形状为σH×σW×C的特征图。
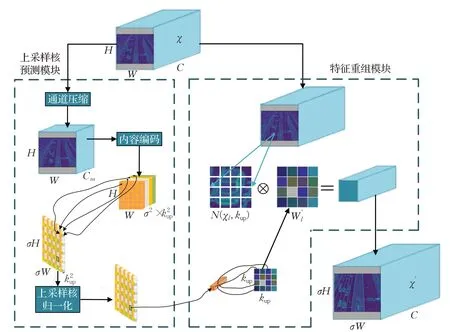
图4 CARAFE模型结构图Fig.4 CARAFE model structure
2 FA-SORT跟踪算法
针对序言中提出的无人机对复杂场景下的多车辆跟踪的三个问题,已经在第一章提出解决问题1 的方法,即通过改进的YOLOv8模型提高对车辆小目标检测能力。针对其他两个存在的问题,本文在SORT跟踪算法基础上提出了改进KF、添加速度方向一致性匹配和添加检测值匹配这三个改进策略,并将其命名为fast and accurate SORT,简称FA-SORT。改进KF用来解决车辆因遮挡导致常规的KF 估计位置不准的问题,添加速度方向一致性匹配用来解决车辆非线性运动导致前后帧IOU匹配困难的问题,添加检测值匹配用来替代外观匹配方法,解决无人机在高空鸟瞰视角下,对于同一类型的车辆,外观彼此相似,使用外观特征匹配的方式处理车辆拥挤或遮挡情况时表现不佳,并且还会影响车辆跟踪实时性的问题。
2.1 改进卡尔曼滤波
2.1.1 KF应用在多目标跟踪的局限性
卡尔曼滤波(KF)[7]是一种基于状态空间模型的最优估计算法,广泛应用于信号处理、控制系统、导航系统、机器人技术等领域。KF 在目标跟踪算法中可以分为预测和更新这两个阶段,在预测阶段,通过系统模型对当前状态目标的位置和速度进行预测,得到预测值;在更新阶段,利用检测值对KF预测值进行修正和更新,得到最终的状态估计值。
在目标跟踪算法中,通常使用KF 对上一帧匹配成功的状态估计值或目标被遮挡前匹配成功的状态估计值进行运动信息预测(如果是第一帧检测框,则将当前检测值进行KF预测)。KF预测阶段可以通过以下等式执行:
(1)KF噪声值初始化:在SORT[6]算法当中,KF状态X由7个变量组成,即,其中x、y为对象中心点坐标,s为对象边界框面积,r为对象高宽比(恒值),其他三个变量̇对应变量的速度,当状态X变量参与KF预测阶段和更新阶段时,需要选取KF 过程噪声Q和观测噪声R的值,SORT 算法是直接对Q、R值取常量,与状态X变量和检测值Z变量无关,但是,输入到KF的每一帧目标检测框和状态估计值的变量是时刻发生变化的,这会导致KF 产生的边界框大小与时间独立,无法自适应调整。针对SORT算法存在的问题,DeepSORT[9]算法则是将上述的KF 状态变量改成8 个,即,a为对象高宽比;h为对象高,其余变量不变。通过添加状态X的高(h)初始化Q、R的值,用以缓解该问题。
(2)状态对噪声的敏感:使用KF估计目标速度会存在噪声的敏感,尤其是使用无人机拍摄的高帧率视频进行目标跟踪时,会放大对噪声的敏感性;这会导致KF估计目标的速度时存在较大的方差。在KF 预测阶段时,因为噪音Qt的存在,使得KF 预测值存在误差。假设状态X的中心坐标位置x、y服从高斯分布,设x~因为是线性运动模型,两个时间步长t到t+Δt之间的估计速度为:
式中,xt、yt为状态X在t时刻x、y的位置;xt+Δt、yt+Δt为状态X在t+Δt时刻x、y的位置;Δt为时间步长(帧数差);Ẋ、Ẏ 为状态X中心点x、y方向的估计速度。根据高斯分布相加性质可知,状态X估计速度噪声为;Δt=1 时,噪声最大化。当车辆在视频中连续几帧发生位移时,其中心位置x、y方向移动仅为几个像素,但这也会导致估计速度有很大的误差。通常速度估计的方差可以是速度本身相同的幅度甚至更大。如果目标在被正常跟踪情况下,这不会产生很大的影响,因为在一帧时间差内,可以通过目标检测值来校正KF运动模型的估计值。但是目标被遮挡时,因为没有检测值参与KF更新阶段,在这段时间步长内会造成误差累积。
(3)位置误差的累计:当车辆在t时刻被遮挡,在连续T帧都没有检测值情况下,只能利用遮挡前一帧状态X进行KF 预测和更新,得到t+T时刻状态X中心点位置为:
结合已知状态X的中心位置和其速度噪声都服从高斯分布;根据高斯分布相加性质,可以计算出状态X位置噪声;因此,当没有检测值对KF运动模型修正的话,状态X的位置估计方差是时间差T的二次方,如果被遮挡时间越长,产生的位置误差就越大,这会造成KF估计不准确。
2.1.2 KF状态变量参数重定义
针对KF 噪声值初始化所存在的问题,本文将重新定义状态X的变量,如公式(13)所示,在DeepSORT 算法基础上,添加了状态X的宽(w),这样可以通过对状态X的宽和高两个变量来初始化过程噪声矩阵Q和观测噪声R的值,从而更好地自适应调整边界框大小。通过检测器获取的检测值如公式(14)所示,其中zx、zy为检测框的中心点坐标,zw、zh为宽和高,zs为置信度得分。公式(15)和(16)展示了通过状态X的宽和高来确定过程噪声矩阵Q的值和观测噪声R的值的计算过程。
式中,过程噪声因子σP设置为0.05,噪声因子σV设置为0.006 25;观测噪声因子σM设置为0.05。图5展示了多车辆跟踪边界框可视化的结果,分别对改进后的KF状态变量参数和原始广泛使用的KF 进行对比实验,为了增强对比性,用虚线框表示使用原始KF方法,与原始KF方法对比,本文改进的KF产生的边界框更接近于被跟踪车辆的外接矩形框,这也为后续的KF 预测与更新提供更准确的边界框位置信息。
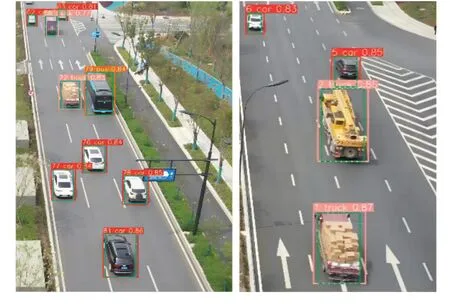
图5 多车辆跟踪边界框可视化Fig.5 Multi-vehicle tracking bounding box visualization
2.1.3 建立虚拟轨迹
针对状态对噪声的敏感和KF估计位置误差积累的问题,本实验将建立一个虚拟轨迹,图6可以看出,轨迹的起始点为目标被遮挡前一帧的位置Zt1,终点是目标遮挡后再次出现的位置Zt2,通过遮挡前、后的位置做一个平滑操作,建立线性插值函数。平滑KF参数,以获得更好的目标位置估计。建立的虚拟轨迹表示为:
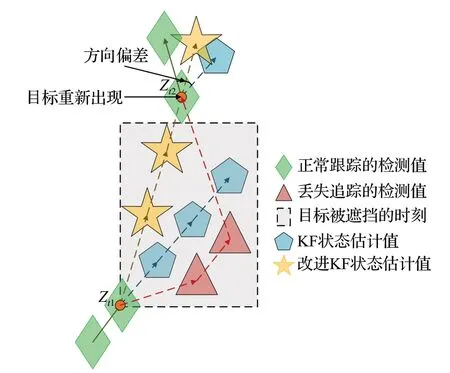
图6 使用KF与改进KF估计目标位置演示过程Fig.6 Estimating object position demonstration process using KF with improved KF
式中,t1为虚拟轨迹起始时刻,t2为虚拟轨迹终点时刻,Zt1为虚拟轨迹起始点,Zt2为虚拟轨迹终点。沿着这条虚拟轨迹,从t1时刻开始,通过KF预测与更新阶段之间反复交替检查KF 参数。在虚拟轨迹校正下,经KF模型获得的状态估计值所产生的误差将不再积累,KF新的更新阶段得到的状态估计值表示为:
如图6 所示,当目标在Zt1位置被遮挡并发生非线性运动时,KF 会基于Zt1进行线性估计,直到结束遮挡后再次出现的位置为Zt2,此时对Zt2进行KF 线性估计,得到状态估计值会因噪声的存在导致位置误差的积累。而本方法是利用遮挡前、后的目标位置,建立一条虚拟轨迹,通过建立的虚拟轨迹消除KF 使用过程中存在的噪声积累,从而有效解决目标因遮挡而导致KF模型估计位置偏差的问题。
2.2 速度方向一致性匹配
在进行车辆多目标跟踪时,默认被跟踪的车辆为线性运动,且具有速度方向一致性。然而,在现实生活中,因为存在状态噪声,车辆几乎是处于非线性运动状态,这会增加被跟踪的轨迹框与检测框进行IOU 匹配的困难,在短暂的时间间隔内,可以认为车辆运动近似为线性,但状态噪声会阻止利用速度方向一致性。此外,仅使用IOU进行前后帧匹配还会存在如图7所示的问题,该图展示了t帧目标检测框与t-1 帧轨迹框进行IOU匹配关联过程,当出现t-1 帧轨迹框ID-5分别与t帧的检测框at、bt的IOU值相同时,无法利用匈牙利算法[8]实现ID的分配。
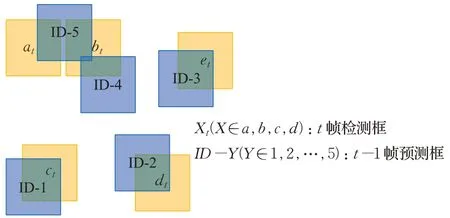
图7 轨迹框与检测框进行IOU匹配Fig.7 IOU-matched between trajectory boxes and detection boxes
针对上述问题,本文提出将速度方向一致性添加到轨迹关联成本矩阵当中,t帧时刻,假设有i个轨迹框和j个检测框,其关联成本矩阵为:
本文提出的速度方向一致性匹配过程如图8所示,t帧的检测框at和与之时间差为ΔT的检测框这两个中心点形成一条速度方向,t-1 帧的检测框at-1与也会构成一条速度方向,计算出的这两条速度方向一致性的相似值大于与其他检测框构成速度方向一致性的组合;其中t-1 帧检测框at-1参与了t-1 帧轨迹框ID-5的KF更新阶段。同理,t帧检测框bt、bt-1在时间差ΔT上分别与构成两条速度方向,计算该两条速度方向一致性的相似值最大,其中t-1 帧检测框bt-1参与了t-1 帧轨迹框ID-4 的KF 更新阶段。这样可以将轨迹框ID-5分配给at,轨迹框ID-4分配给bt。通过该方法可以进一步增强多目标跟踪数据关联匹配。
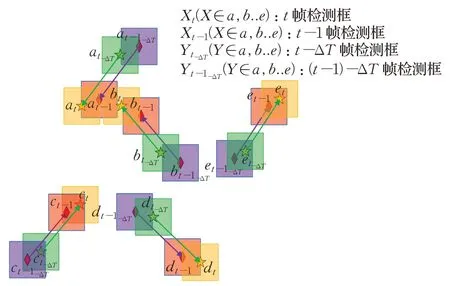
图8 历史检测框与当前检测框进行速度方向一致性匹配Fig.8 Velocity direction consistency matching between historical and current detection boxes
2.3 检测值匹配
车辆在运行过程中经常会遇到车身部分被遮挡和完全被遮挡的情况,当车身被部分遮挡时,通过目标检测模型得到的检测框置信度得分偏低,容易被后续的跟踪模型给筛选掉,导致无法进行后续的跟踪,给目标跟踪带来检测的缺失和轨迹不连续的影响。图9(a)便出现了上述情况,当检测框置信度高于阈值(阈值参考DeepSORT,设置为0.45),目标可以被正常跟踪,并赋予ID、车辆类别和置信度值;但是图中出现有两辆白色汽车因部分车身被路标指示牌和后面的卡车、公交车遮挡而未被检测出,在图中用圆圈标识出来;而这两辆白色汽车真实存在,如果直接忽略的话,会影响多目标跟踪的效果。
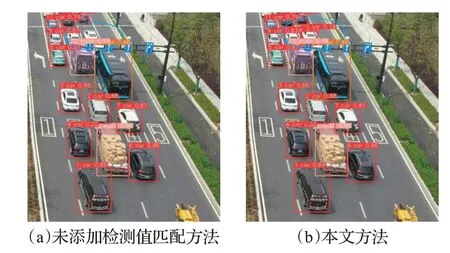
图9 添加检测值匹配前后多车辆跟踪实验对比结果Fig.9 Comparison results of multi-vehicle tracking experiments before and after adding detection value matching
对于车辆完全被遮挡的情况,常见的跟踪算法采用REID[3-4]方法,即外观匹配方法进行前后帧的特征信息匹配,保证轨迹的连续性。然而在图9 中,图像中的车辆所包含的像素点少,可获得的外观特征信息少,而且在公交车和卡车前面的两辆白色汽车,其外观特征相似,使用外观匹配处理目标遮挡情况所带来的效果不明显,而且在目标跟踪算法中添加外观匹配会带来很大的计算时间成本,影响跟踪的实时性。
(1)低置信度检测值匹配。针对车身部分被遮挡情况,导致低置信度得分被筛选掉的问题,本文将考虑每个检测框,对于检测框置信度大于0.1 的目标都认为是待定的跟踪对象,并通过目标跟踪数据关联匹配的方法来区分低置信度检测框是检测对象还是背景;具体做法是:首先将置信度大于0.45的高分检测框优先与上一帧轨迹框进行第一次关联匹配;再将第一次关联匹配中未匹配的轨迹框与置信度在0.1至0.45区间的低分检测框进行第二次关联匹配。图9(b)中可以看出对低置信度的目标能够实现检测与跟踪,从而减少漏检率,提高轨迹跟踪完整性。
(2)历史检测值匹配。针对车辆被完全遮挡的情况,本文将采取类似于REID的方法实现数据关联匹配,当车辆被正常检测时,检测框的位置服从高斯分布,可以将车辆被遮挡前最后一次出现的检测框的位置作为均值,其方差将随着遮挡时间的增加而增加。在合理的遮挡时间差,可以将第二次关联匹配中未匹配成功的轨迹框与遮挡前最后一次出现的检测框进行IOU 关联匹配,实现第三次关联匹配来解决车辆遮挡的问题。虽然该方式只适合于车辆被短暂遮挡的情况,但是在DeepSORT 算法当中,为了避免跟踪速度过低,只保留最新的100帧的历史检测值的外观信息用于外观匹配,并且设置了连续30 帧轨迹框未成功匹配的话,则删除轨迹信息。DeepSORT 所设计的这些方法也是用于处理短时期目标遮挡的问题。因此,本文采用的历史检测值匹配的方式也是在合理的遮挡时间范围之内。
综上研究,图10 展示了本文提出的FA-SORT 具体实施过程,将改进的KF 和添加速度方向一致性匹配应用在第一次匹配关联,其中为距离t时刻时间差ΔT的检测框,为t-1 时刻检测框速度方向信息,Last_boxes 为目标遮挡前最后一次出现的检测框。将检测值匹配应用在第二次和第三次匹配关联,其中,第二次匹配关联是将低置信度检测框与第一次未匹配成功的轨迹框进行匹配关联,而第三次匹配关联主要是利用历史检测值,即遮挡前的检测值与轨迹框进行IOU匹配,解决车辆被短暂遮挡时,导致车辆目标ID切换的问题。
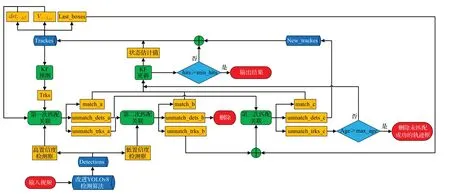
图10 FA-SORT跟踪算法流程图Fig.10 FA-SORT tracking algorithm flow chart
3 实验结果与分析
为了验证改进的YOLOv8算法和FA-SORT跟踪算法的有效性,分别将它们与最先进的算法模型进行比较,设计的实验和数据集均在本章中描述。所有实验均在Ubuntu18.04系统平台上完成。使用的处理器型号为Intel®CoreTMi9-10850K CPU@3.60 GHz;使用的显卡型号为NVIDIA GeForce RTX 3060 Ti。
3.1 实施细节
(1)数据集。实验数据集类型对象主要是无人机视角下高速公路和城市道路上最常见的汽车(car)、卡车(truck)、公交车(bus)、货车(van)四种类型,本实验数据集主要由UA-DETRAC 数据集[29]、UAVDT 数据集[30]和本团队采集的数据集这三部分构成。其中本团队数据集是通过无人机在30 m 至120 m 不同高度下拍摄约30个视频,并筛选出约8 000 多张带标注的图片,图11 为本团队采集的部分车辆数据集图片。

图11 实验部分车辆数据集图片Fig.11 Images of experimental part of vehicle dataset
本实验数据集筛选了部分公共数据集和本团队标注的数据集,共组成23 986张带标注信息的图片。将数据集按8∶2划分训练集和验证集。在筛选数据集时,尽可能选择在不同场景下的夜晚、阴雨天等复杂环境的图片,筛选出的图片尽可能包含分辨率低的车辆;以使训练出的模型具有足够的鲁棒性和泛化能力,其结果更能反应真实情况。如图12所示为本实验训练集和验证集中四类车型类别标签框数量分布情况。
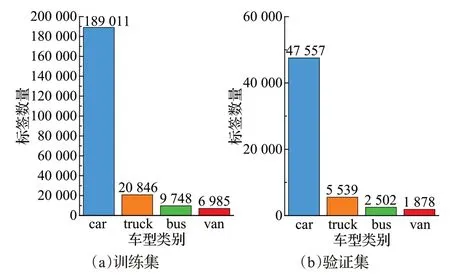
图12 训练集和验证集车型类别标签框数量分布图Fig.12 Distribution of number of labels boxes of car categories in training and validation sets
(2)模型参数设置及训练。为实验具有公平性和对比性,检测模型训练不使用预训练权重。IOU阈值默认为0.7,epoch 训练设置为100,Batch Size 为16,学习率设置为0.01,衰减率为0.937,优化器使用SGD。
(3)评价指标。检测模型训练后的泛化能力需要通过合适的评价指标来进行衡量,目标检测常用的评价指标为精确率(precision)、召回率(recall)、mAP0.5 和mAP0.5:0.95。此外,本实验选取UAVDT数据集中8个视频作为验证集用于评估多目标跟踪算法性能,该车辆数据集用来评价无人机视角下车辆多目标跟踪的性能是具有权威性。常用的多目标跟踪(MOT)评价[31]有:HOTA[32]为高阶跟踪精度。用于衡量检测精度和跟踪性能。MOTA用于评估多目标跟踪的准确度,MOTP用于评估多目标跟踪精确度,IDF1 用于衡量ID 识别准确度和召回率,IDs 用于评估目标ID 切换次数,FPS 表示每秒处理的帧数。这些评价指标能够从不同方面衡量跟踪算法的优劣。
3.2 消融实验
3.2.1 本文改进的YOLOv8组件消融
为了检验本文添加的BiFormer模型和CARAFE模型对YOLOv8模型的检测性能是有提升的,以YOLOv8模型为基线,分别对这两个组件进行消融实验,结果如表1 所示,当添加BiFormer 模型时,精确率(P)提升了0.65%,mAP@0.5:0.95提升了1.36%。添加CARAFE模型时,召回率(R)提升了0.67%。本文的检测算法是融合了这两个模型,与YOLOv8 模型相比,在目标检测性能方面是有提升的。在检测速度方面,因参数量增加了1.1×106,导致FPS有所下降,但仍然达到39.2 FPS,不影响无人机视角下目标车辆检测的实时性。

表1 本文检测算法消融实验结果对比Table 1 Comparison results of ablation experiments with proposed detection algorithm
为了验证不同改进策略的YOLOv8 检测算法对小目标检测的有效性,使用上述的四种消融实验模型对无人机在不同高空场景下进行实时的车辆检测。图13(a)是使用YOLOv8 检测效果,可以看出,在远处的车辆因分辨率低未被检测出来,而通过添加的BiFormer、CARAFE 以及本文检测算法都能将远处的车辆精确地检测出来。图14(a)是无人机在120 m高空下使用YOLOv8检测效果,其中有三处区域的车辆未能够检测出,当添加BiFormer 或CARAFE 后,这三处区域的部分车辆可以被检测出,而其余未能检测出的车辆均能够被本文提出的算法给检测出。这证明了本文检测算法所提出的不同改进策略对车辆小目标检测是有效果的。

图13 不同改进策略在100 m高空下多车辆检测效果Fig.13 Effectiveness of different improvement strategies for multi-vehicle detection under 100 m altitude

图14 不同改进策略在120 m高空下多车辆检测效果Fig.14 Effectiveness of different improvement strategies for multi-vehicle detection under 120 m altitude
3.2.2 FA-SORT组件消融
在本文第2 章中,重点讨论FA-SORT 三个改进策略。以SORT算法为基线,比较FA-SORT中每一个改进策略对表2中UAVDT数据集的验证集的影响。当对原始卡尔曼滤波(KF)进行了改进时,MOTA 和IDF1 的指标都得到了明显的提升,这主要得益于改进的KF 能够很好地处理车辆非线性运动的情况,使得车辆位置估计更准确。在改进KF策略基础上添加速度方向一致性匹配时,增强了目标跟踪的数据关联,提高了多目标跟踪的准确度。当添加检测值匹配策略时,MOTA指标提升了1.45%,这说明了能够恢复跟踪丢失的车辆,稳定其身份ID,从而准确地跟踪目标。

表2 FA-SORT消融实验结果对比Table 2 Comparison of FA-SORT ablation experiment results单位:%
此外,本实验还尝试在FA-SORT模块添加REID外观特征匹配,通过表3 验证外观匹配对FA-SORT 的影响。从实验结果可以看出,添加REID对IDF1是有提升的,但是FPS大大降低,无法达到实时性。

表3 REID对FA-SORT的影响Table 3 Influence of REID on FA-SORT
3.2.3 FA-SORT参数消融
在第2章讨论得知,ΔT=1 时,噪声最大化;假设在线性运动情况下,ΔT取值越大,对噪声具有更好的鲁棒性。但过大的ΔT值将会阻碍物体运动近似为线性。因此,通过表4研究ΔT的变化对数据关联性能的影响,从表4可以看出,ΔT=5 时,HOTA和IDF1的指标最高。确定好ΔT取值之后,需要研究添加速度方向一致性在关联成本矩阵中的占比,从表5可以看出,α=0.5时,性能表现最优。
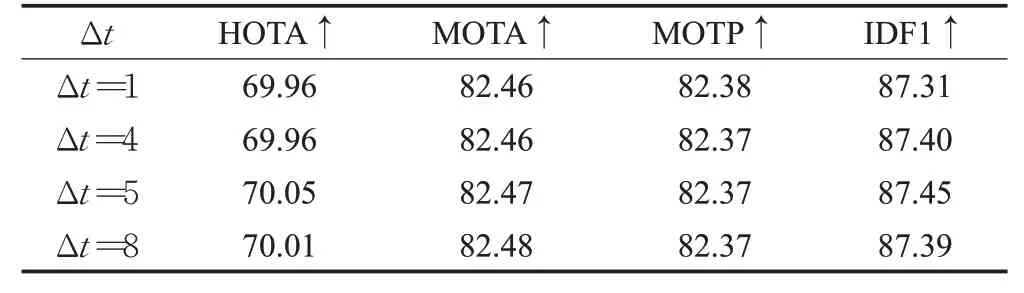
表4 ΔT 选择对速度方向一致性匹配的影响Table 4 Influence of choice of ΔT for velocity-direction consistency matching 单位:%
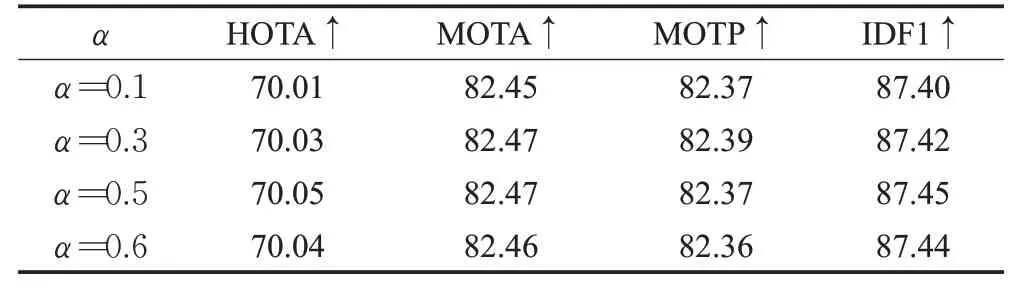
表5 α 选择对速度方向一致性匹配的影响Table 5 Influence of choice of α for velocity-direction consistency matching 单位:%
3.3 对比实验
3.3.1 车辆检测算法对比实验
本实验使用收集的车辆数据集的验证集来测试目标检测算法的性能,主要与SSD、Faster R-CNN、YOLO系列等常见的目标检测算法进行比较。结果如表6 所示,其中shufflenetv2[33]、mobilenetv3[34]是基于YOLOv5框架改进的轻盈网络,结果表明,YOLOv8 与现有的检测算法相比,各项评价指标表现突出,这也是本文采用YOLOv8 作为算法改进的主要原因。而本文提出的检测算法在车辆数据集上的精确率、召回率、mAP0.5以及mAP0.5:0.95都高于现有的检测算法,尤其mAP0.5:0.95相比较于原YOLOv8,提升1.91%。故本文改进的检测算法能够为后续的多车辆跟踪提供良好的检测性能。
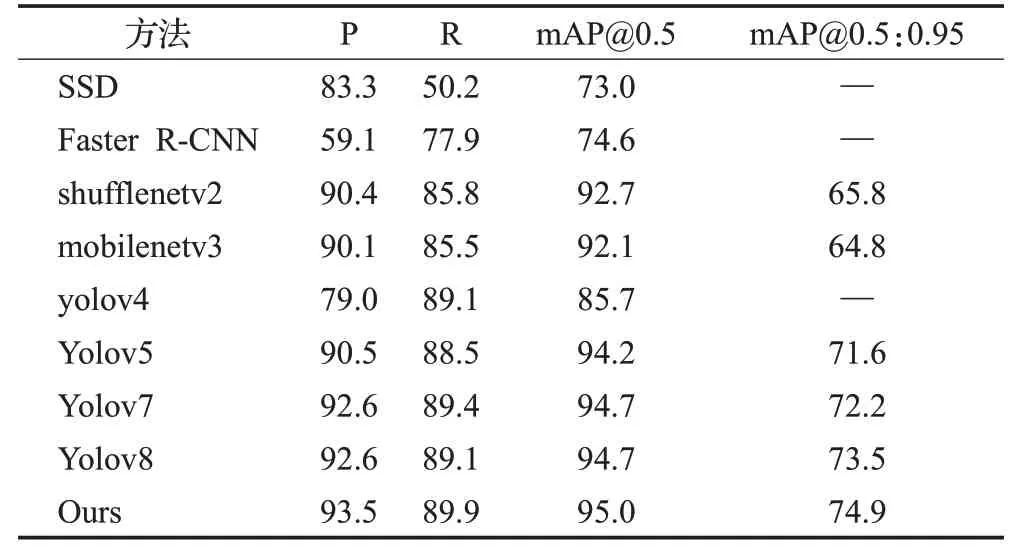
表6 目标检测算法比较Table 6 Comparison of object detection algorithms单位:%
3.3.2 车辆跟踪算法对比实验
为了验证本研究中提出的多目标跟踪算法FASORT 的有效性,使用UAVDT 数据集的验证集将FASORT与其他先进的跟踪器比较,为了实验公平,统一使用改进的YOLOv8作为检测器。实验结果表7所示,它们在实验过程中FPS普遍都低,无法达到实时性。而本研究所提出的方法在保证实时性的情况下,能够获得更好的HOTA 值和IDF1 值,在图15 中,在UAVDT 验证集上,将提出的FA-SORT 与其他的跟踪器比较HOTA-跟踪速度和IDF1-跟踪速度。图15(a)中,x轴为跟踪速度,y轴为HOTA。图15(b)中,x轴为跟踪速度,y轴为IDF1。可以直观地看出本文的跟踪算法在实验中,HOTA值和IDF1值高于其他跟踪算法,其中HOTA值更是所有跟踪算法中首个达到70%。
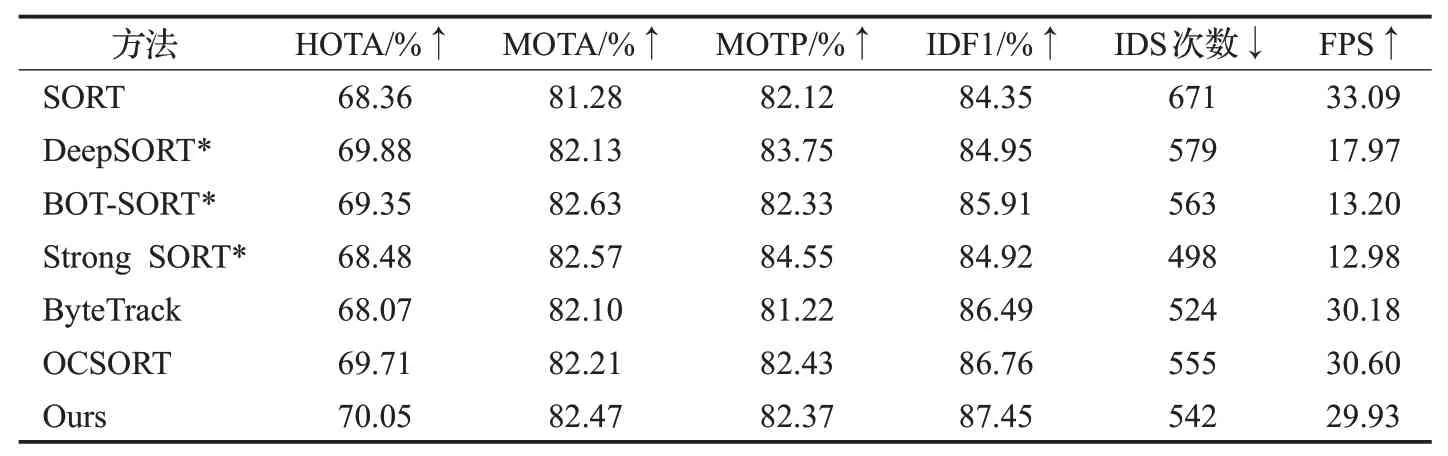
表7 多目标跟踪算法对比实验Table 7 Comparative experiments of multi-objective tracking algorithms
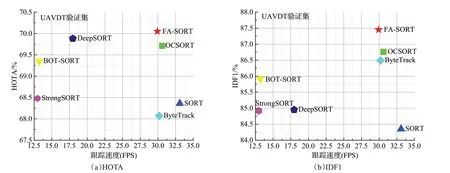
图15 不同跟踪算法在UAVDT数据集上评价指标对比Fig.15 Comparison of evaluation metrics of different tracking algorithms on UAVDT dataset
HOTA 值高说明FA-SORT 能够准确地检测到目标和稳定的跟踪目标,即能够在目标出现遮挡、或非线性运动情况下保持跟踪的连续性,保持目标轨迹的连贯性。IDF1值高说明能够准确地为每个目标分配唯一的标识符,即目标ID;并且能够成功追踪大部分目标。具有较高的召回率。值得一提的是,在不采用外观匹配方式的跟踪方法当中,FA-SORT方法表现最优。
4 结束语
本文对无人机平台下的多车辆的检测和跟踪算法进行了优化。针对视频中车辆分辨率小、检测精度低的问题,使用改进YOLOv8检测算法提高对小目标检测的性能。针对目标遮挡和目标遮挡后使用卡尔曼滤波器预测存在位置误差积累的问题,提出了快速、准确的FA-SORT跟踪器。最后,在多车辆实验数据集上进行了检测和跟踪算法的实验验证,改进的YOLOv8算法能够更准确地识别小目标车辆,而FA-SORT 也优于现有的跟踪算法,能够很好地处理目标车辆出现严重的遮挡和非线性运动的情况,还能够满足在线跟踪和实时性的要求。然而,在未来工作中仍然需要有很大的改进。比如可以考虑将行人目标融入到所提出的跟踪的对象当中,这需要寻求更加合适的跟踪算法,用以快速、准确地跟踪行人和车辆。
猜你喜欢
当代医药论丛(2022年22期)2022-12-07
北京航空航天大学学报(2022年8期)2022-08-31
阅读(快乐英语高年级)(2022年6期)2022-06-17
家庭影院技术(2021年10期)2021-11-20
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
中国兽医杂志(2019年2期)2019-06-25
现代装饰(2018年5期)2018-05-26
首都食品与医药(2017年22期)2017-10-25
紫禁城(2017年6期)2017-08-07
