
基于双通道Transformer的地铁站台异物检测
2024-04-23 10:03:26刘瑞康刘伟铭段梦飞谢玮戴愿
计算机工程 2024年4期
刘瑞康,刘伟铭,段梦飞,谢玮,戴愿
(华南理工大学土木与交通学院,广东 广州 510640)
0 引言
全自动驾驶地铁列车具有安全风险小、运营效率高、运营成本低等优势,已经成为城市轨道交通的发展趋势。国内主要城市已将全自动运行系统纳入建设规划,经过多年的发展,全自动运行系统已经成为我国城市轨道交通建设的主流制式选择。据中国城市轨道交通协会统计,截至2021年底,中国内地共计有北京、上海、天津、重庆、广州、深圳、武汉、成都、苏州、宁波、南宁、济南、太原、芜湖14市开通了全自动运行系统线路,线路共计23条,已形成了554 km的全自动运行线路规模。
站台屏蔽门与列车门是连接站台与列车的唯一通道,是地铁运输系统的风险点和管控核心区域,直接影响地铁在站时间、运输效率和安全。据统计,上海地铁10号线(全自动驾驶线路)安全事故30%来自乘客、24.82%来自列车门、10.64%来自站台屏蔽门、12.74%来自站台门与列车门及间隙夹人与夹物,可见列车门与站台门处是影响全自动驾驶系统运营安全的重要因素。因此,在无人驾驶运行环境下,乘降作业监督是最重要的安全功能之一。
目前国内外关于地铁站台异物检测的研究较少。传统的地铁风险空间异物检测方式主要有4种:人工瞭望灯带技术;基于激光扫描的方法;基于红外光幕的方法;基于激光探测的方法。人工瞭望灯带技术[1]依靠司机观测屏蔽门尾端立柱外明亮灯带的完整度来判断是否新增异物。然而,由于视力和疲劳的限制,人工方式容易产生漏检,尤其是小尺寸异物。基于激光扫描的方法[2]和基于红外光幕的方法[3]分别依赖点探测器和区域探测器,根据发射器和接收器间光幕的完整性进行异物辨别。这2种方式易受到灰尘、悬浮粒、昆虫、环境内折射/反射光等干扰,常常产生虚报和误报。基于激光探测的方法[4]聚光效果好且能远距离检测,但列车行驶产生的振动可能会使激光偏离对应的接收器,造成无效检测。
自2012年KRIZHEVSKY等[5]提出AlexNet以来,卷积神经网络(CNN)在近十年里主导了计算机视觉,并取得了许多成就,基于图像的地铁异常检测方法逐渐被研究人员所采纳。孔德龙等[6]利用深度残差神经网络自动检测地铁站台门与列车门间的异物。ZHENG等[7]提出一种顺序可更新异常检测网络来解决轨道中异物入侵的问题。近年来,视觉Transformer(ViT)完全依靠自注意力来捕获长程的全局关系,并取得了辉煌的成功。在短时间内,涌现出许多基于Transformer的改进模型,并取得了比CNN更高的精度。由于CNN通过堆叠更多的卷积层来扩大感受野,因此它只能对像素的局部依赖进行建模。考虑到全局依赖在视觉任务中扮演着不可或缺的作用,Transformer能够在任意图像块之间构建长程依赖的优势将被引入到本文算法中。
然而,基于Transformer的异常检测方法仍然面临着以下挑战:
1)图像块尺度受限。受内存资源限制,DOSOVITSKIY等[8]提出的纯ViT网络仅接收粗粒度图像块(16×16像素)作为模型输入以缩短数据序列的长度。然而,网络中生成的低分辨率特征图对小尺度的异常目标学习能力不足,表现出较低的检测性能。细粒度的图像块输入能够具备较强的局部特征提取能力,但对计算资源的要求较高。因此,即使不同尺度的图像块能带来更丰富的语义特征,现有的Transformer模型仍难以同时兼容多尺度的图像块输入。
2)注意力机制的计算量过大。Transformer中多头自注意力(MHSA)模块的计算量和空间复杂度与图像块数量(图像块尺寸越小,划分的数量越多)是呈二次相关的,如何轻量化自注意力机制并维持Transformer全局信息交互的优势尤为重要。
为增强Transformer对图像局部细节信息的感知能力,本文提出一种双通道Transformer来引入不同尺度的图像块作为输入并完成特征映射变换,优化Transformer在全局和局部特征上的表征性能。同时,受SENet的启发,提出通道交叉注意力机制来实现Transformer网络中不同尺度图像块输出特征间的交互。此外,将级联卷积模块嵌入MHSA模块中以缩短输入序列长度并学习到强大的上下文信息,极大地减少了模型的计算成本并促使DualFormer模型灵活地学习多尺度和高分辨率特征。
1 相关工作
1.1 卷积神经网络检测算法
在深度学习中,CNN已经成为目标检测的经典框架,其代表性算法主要包括单阶段检测器(如SSD[9]、YOLOX[10]、RetinaNet[11]、TOOD[12])和两阶段检测器(如Faster R-CNN[13]、Mask R-CNN[14]、Cascade R-CNN[15]、Sparse R-CNN[16])。两阶段检测网络通常包括候选区域的生成及分类2个步骤。Faster R-CNN[13]是两阶段检测网络的里程碑,其首先利用区域候选方法在输入图像中映射出目标候选区域,然后识别不同候选目标实现密集预测。Cascade R-CNN[15]基于多阈值交并比(IoU)检测子网络的级联结构,避免了单个模块检测网络设置阈值时的矛盾,显著提升了模型准确率。Sparse R-CNN[16]抛弃了对密集候选框的依赖,省略了基于非极大值抑制(NMS)算法的后处理过程,通过一种纯稀疏的方式提升了检测速度。单阶段检测网络则无需生成区域候选的阶段,而是直接预测目标的类别和位置坐标。YOLO[17]将图像划分为多个网格,可以一次性输出所有检测到的目标信息。然而,YOLO对小目标的检测性能有所不足。为了缓解该问题,SSD[9]在多个尺度的特征图上分别检测不同尺寸的目标,在减小计算复杂度的同时,实现了与Faster R-CNN相当的准确性。此外,RetinaNet[11]提出了一个新的分类损失Focal Loss,解决了训练过程中正负样本不均衡的问题,VarifocalNet[18]则提出了Varifocal Loss来优化密集目标检测任务。TOOD[12]设计了一种新颖的任务对齐头部(T-Head),对现有单阶段检测器分类与定位中存在的非对齐问题进行平衡,进一步提高了算法的准确性。
相比之下,单阶段网络速度更快,而双阶段网络精度更具优势。卷积神经网络的共性在于需要堆叠更深的网络层来获取更大的感受野,提升全局上下文信息的提取性能。本文的关注点更倾向于具有长程特征提取优势的Transformer网络。
1.2 Transformer检测算法
随着图像分类网络ViT[8]和目标检测网络DETR[19]的提出,研究人员对它们的变体进行了广泛的研究。ViT先将图像划分为无重叠、固定大小的图像块,并将图像块拉平为一维向量进行线性投影实现特征提取。在骨干网络设计中,针对ViT局部信息容易受损的问题,Swin Transformer[20]利用局部注意力思想和位移窗口多头注意力机制(SW-MSA)来实现局部与全局特征的交互,在多个视觉任务上达到了较好的结果。DeiT[21]通过知识蒸馏的方式来减少训练ViT[8]所需的计算资源。此外,CvT[22]将Transformer模块中每个自注意块之前的线性投影替换为卷积投影,在引入CNN中固有的移动、缩放和失真不变性等优势的同时,保持了Transformer中动态关注和全局上下文的特性。DETR[19]模型是目标检测领域的又一里程碑,它利用Transformer解码器将目标检测看作一个目标集的预测问题,成功消除了NMS等繁琐的后处理过程。Deformerble DETR[23]提出了一种可变形注意机制,缓解了DETR收敛缓慢和特征分辨率有限的问题。然而,这些算法在多尺度密集预测任务上表现并不理想。因此,一些学者模仿了CNN的架构,为Transformer构建类似的多尺度金字塔特征层以适应密集预测的需求,如PVT[24]、P2T[25]等。此外,为了实现模型的轻量化,在MHSA模块中引入池化操作来缩减Value和Key的长度,减少模型内存占用。
1.3 地铁异物检测
深度学习的巨大成功使得其在地铁异物检测中受到青睐。刘伟铭等[26]提出了一种结合语义分割和背景参考的前景检测方法,通过背景差分的方式检测地铁中存在的异物。LIU等[27]利用生成对抗网络将异常图片重新生成为正常图片,利用输入与输出图片间的差异来定位异常。然而,这些基于图像像素差异或特征差异的方法只能判断异物的存在,无法进一步辨识异物类别。由于不同类型异物危害等级有所区别,因此地铁工作人员的应对措施具有很大差异。例如:小型或柔软异物对列车运行的安全威胁小,风险等级低,通常不会延误列车的正常发车;夹人事件则对应最高的危险等级,须立即停车并实施应急方案。DAI等[28]改进了CNN算法来检测地铁风险空间中的异物,证明了基于深度学习的目标检测算法在该任务中的潜力。然而,所提方法的检测精度还有待提升。本文结合Transformer和CNN的优势来提升算法检测精度,并进一步缓解Transformer参数量大的问题。
2 DualFormer网络模型
DualFormer整体架构如图1所示(彩色效果见《计算机工程》官网HTML版本,下同),主要包括3个部分:基于双通道策略的Transformer(作为骨干网络);基于通道交叉注意力的多尺度特征聚合;基于特征金字塔网络(FPN)[29]的异常目标检测。
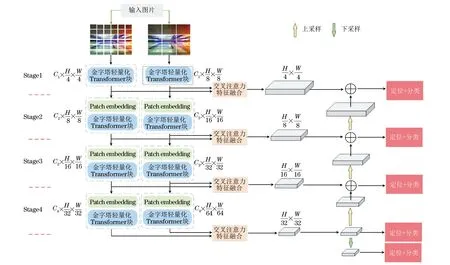
图1 DualFormer网络架构Fig.1 The architecture of DualFormer network
首先将输入图片划分成2种不同尺寸的图像块(Patch),并将这些具有不同尺寸的图像块分别放入2个不同的Transformer网络分支中进行特征提取。骨干网络包括4个阶段(Stage),对每个阶段中2个分支网络的输出利用通道交叉注意力机制进行交互,使得提取到的特征能够在特征通道上深层次融合,避免局部信息的损失。然后,将聚合后的4个特征输入FPN构造5个不同尺度的特征图进行目标定位和分类。
2.1 基于双通道Transformer的骨干网络
ViT将图像划分为多个图像块以使它们转换为序列。图像块的大小及数量影响着算法的速度和精度:较小的图像块具有较高的精度,但导致更高的耗时;较大的图像块具有较低的耗时,但检测精度欠佳。此外,自注意力机制虽然能够有效地建立图像块之间的远程依赖关系,但大图像块在训练过程中容易忽略其自身内部的结构特征和细节信息。因此,本文提出一种双通道Transformer骨干网络,利用不同的网络通道提取2种不同尺度图像块的上下文信息,并设计一种金字塔轻量化Transformer块来减少模型的计算参数,实现精度与速度的平衡。
以图像I∈3×H×W作为输入,双通道Transformer首先将其分割成尺寸为的大图像块和尺寸为的小图像块。定义4×4×3或8×8×3的图像块为一个元素,每个元素具有48维。与PVT[24]相似,将这些平铺的图像块输入到一个Patch embedding模块,该模块包括一个线性投影层,然后添加一个可学习的位置编码以保证图像块的相对位置信息不被丢失。Patch embedding首先将输入特征维度从48维扩展到C1维,然后对2.2节中引入的金字塔轻量化Transformer块进行堆叠。如图1所示,整个骨干网络可分为4个阶段,其特征维度分别为{C1,C2,C3,C4}。在每2个阶段之间,上一阶段输出特征中每个2×2图像块组合将被拼接起来,并通过深度可分离卷积[30]将特征维度从4×Ci维投影到Ci+1维(i∈{1,3})。2个Transformer分支中4个阶段的尺度分别变为和在这4个不同阶段中,每个分支将分别产生4个特征表示,包括粗粒度特征{b1,b2,b3,b4}和细粒度特征{s1,s2,s3,s4}。
2.2 金字塔轻量化Transformer块
ViT的计算成本和内存消耗即使对于普通大小的输入图像也相对较高。本文设计的双通道网络同样受到该问题的困扰。为此,将级联卷积引入多头自注意力层,提出一种金字塔轻量化Transformer块。它能够减少Transformer的计算与内存消耗,促进双通道网络灵活地学习多尺度和高分辨率的特征。
传统Transformer中的构建块通常由一个MHSA层和一个前馈网络(FFN)组成。如图2(a)所示,本文提出的金字塔轻量化Transformer块在传统的MHSA层中引入了级联卷积。输入首先通过基于级联卷积的MHSA层(命名为CC-MHSA),输出通过残差连接方式[31]与输入进行相加,然后再经过一个线性归一化层(LayerNorm)[32]进行处理。FFN的作用在于特征投影。接着,再次经过残差连接和一个线性归一化层来得到输出特征。
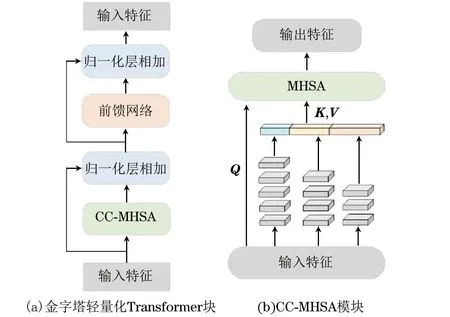
图2 金字塔轻量化Transformer块Fig.2 Pyramid lightweight Transformer block
CC-MHSA层如图2(b)所示。首先,输入X的形状将被重塑为二维形式以便于卷积进行处理。然后,在重塑后的X上分别应用不同数量的级联小卷积层(卷积核大小为3×3,步长为2)来生成多尺度金字塔特征,例如:
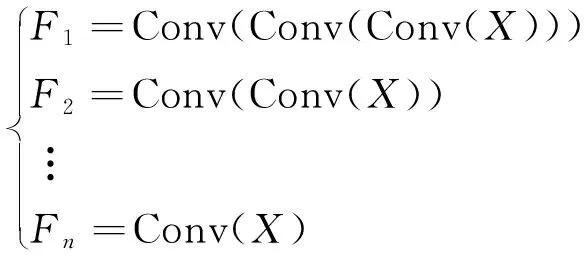
(1)

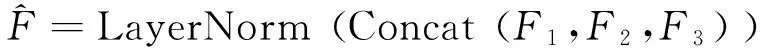
(2)
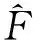
与传统MHSA中Q(query) 、K(key) 、V(value) 的值不同,本文对CC-MHSA中的Q、K、V进行了转变:
(Q,K,V)={Xwq,Xwk,Xwv}→
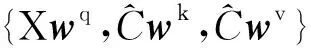
(3)
其中:wq、wk、wv分别表示Q、K、V的权重矩阵。自注意力计算公式如下:

(4)
其中:dk为K的通道维数。由于K和V的长度远小于X,因此CC-MHSA的计算量远小于传统的MHSA,具有更小的参数量和更低的内存占用。此外,由于K和V包含高度抽象的多尺度语义信息,因此CC-MHSA具有更强的特征表达能力,有助于提升检测精度。
2.3 基于通道交叉注意力的特征聚合
从骨干网络中获得双尺度输出特征后,关键问题在于如何有效地聚合它们来形成多尺度特征表示。最直接的方式是对粗粒度特征和细粒度特征直接拼接,然后利用一个卷积实现特征融合。然而,这种简单的方式无法充分利用不同尺度特征间的长程和短程依赖关系。因此,本文提出一种新的通道交叉注意力模块,利用通道注意力机制实现多尺度特征间的有效融合。
受到SENet的启发,本文将不同尺度特征图上的空间和通道信息聚合得到交互特征。不同的是,SENet是一种自注意力机制,它通过建模特征图自身通道之间的相互依赖关系来提高重要特征在网络中的占比,而本文提出的通道交叉注意力模块则考虑了不同尺度特征通道之间的权重关系,通过交叉训练促进不同尺度全局特征间的交互。如图3所示,所提出的通道交叉注意力模块可以整合来自不同尺度的2个分支的特征。具体来说,对于同一阶段的2个分支的输出{si,bi},i∈(1,4),小尺度图像块分支的输出Si形状重塑为C×h1×w1,大尺度互补分支的输出bi被重塑为C×h2×w2,其中,C代表特征通道数,h和w代表各阶段输出特征图的大小。首先,通过使用全局平均池化层分别将细粒度特征Si和粗粒度特征bi内的全局空间信息压缩到一个通道描述符中,这个通道描述符具有全局的感受野。随后,依次通过全连接层、ReLU层和Sigmoid激活层来显式地建模特征通道之间的相关性。第1个全连接层用于特征降维(降维比率为16),第2个全连接层用于特征升维(恢复为原始通道维数)。处理后的全局特征分别表示为gglobal(bi)和gglobal(si)。接着,对特征图gglobal(bi)和gglobal(si)进行缩放,使得gglobal(bi)与Si的特征图尺寸保持一致,gglobal(si)与bi的特征图尺寸保持一致。最后,将全局通道特征与输入特征进行交叉融合,即gglobal(si)×bi,gglobal(bi)×si。通过交叉注意力融合方式,细粒度特征可以从大尺度图像块分支获得粗粒度信息,粗粒度特征也同样可以从小尺度图像块分支获得细粒度信息。更重要的是,不同尺度的特征之间存在着间接的相互作用,可以有效地保持图像块周围的局部连续性,避免Transformer网络中局部细节信息的丢失。
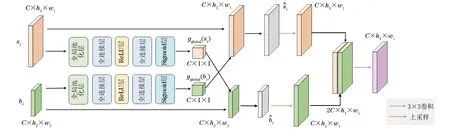
图3 通道交叉注意力机制Fig.3 Channel cross-attention mechanism
2.4 基于FPN的目标检测与定位
如图1所示,融合后的4个特征图输入FPN构造5个不同尺度的特征进行目标定位和分类。FPN[29]因在处理多尺度变化问题和小目标检测方面的优越性被广泛使用在不同的检测器中,如Faster R-CNN[13]、Mask R-CNN[14]、RetinaNet[11]等。因此,本文直接引入FPN来高效地处理这4个融合后的高级语义特征,实现目标检测与定位。
简单来说,FPN利用2×双线性上采样的方式将小特征图放大到同上一个Stage的特征图一样的大小。同时,为了将高层语义特征和底层的精确定位能力结合,其利用类似于残差网络的侧向连接结构将上采样后的特征图和当前层特征图通过相加的方式进行融合。此外,利用一个3×3卷积对最底层特征进行又一次的下采样,增加一个尺度的特征以提升网络检测性能。
不同类别异常样本数量不均衡,这种不平衡现象容易导致模型训练难度剧增。为了优化检测模型,本文直接采用Focal Loss[11]函数来促进网络的平稳训练。分类损失函数表达式如下:
FL(pt)=-αt(1-pt)γlgpt
(5)
其中:pt是不同类别的分类概率;γ与αt都是大于0的固定值。从式(5)中可以看出,pt越大,权重值(1-pt)越小。因此,容易区分的类别对整体损失贡献小,难以区分的类别则对损失贡献大,这有利于诱导模型努力分辨难以训练的目标类别,提升精度。αt用于调节正例(Positive)目标和反例(Negative)目标的比例,与γ的取值相互影响。因此,本文设γ=2,α=0.25,调节损失函数对难识别样本和易识别样本的权重。
此外,定位损失函数表达式定义为L1 loss,用以回归预测框的准确位置:
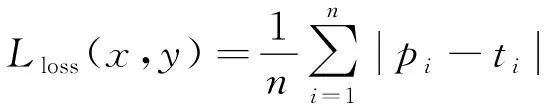
(6)
其中:pi和ti分别代表预测框和ground-truth中左上角和右下角坐标位置信息;n代表图片中目标的数量。
因此,检测模型的整体损失函数为:
LLoss=FL(pt)+Lloss(x,y)
(7)
2.5 双通道Transformer网络的变体
与其他风格的Transformer模型一样,本文的双通道Transformer网络包含几个具有不同参数的模型,它们共享相同的架构,但网络宽度和深度不同。在本文研究中,为了在精度和速度之间进行更好的权衡,设置了3种不同的检测模型:small,base,larger,具体的参数如表1所示。其中:图像输入尺寸为640×640像素(H×W),C1、C2、C3、C4为不同构建块内特征的通道数,N为不同阶段CC-MHSA设置的卷积数量。图像首先经过一个7×7卷积层实现特征采样,并将特征通道数调整为48,然后依次经过4个阶段进行处理。在后续实验中,将展示这些变体的性能。

表1 DualFormer网络的变体Table 1 Variations of DualFormer network
3 实验及分析
3.1 数据集及评估指标
由于地铁异物检测数据集匮乏,通过在地铁站中放置异物来收集和构建一个标准数据集(MAD)进行仿真测试,采集地点为广州某地铁站。地铁风险空间是指列车在站停靠期间,屏蔽门与列车之间、站台水平面至列车车门顶水平面之间、屏蔽门垂直面与列车垂直轮廓面之间所形成的立体区域,见图4蓝色区域。
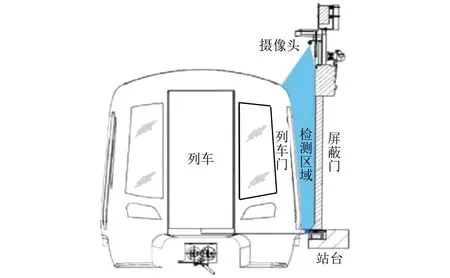
图4 地铁站台列车门与屏蔽门间风险空间结构图Fig.4 Risk spatial structure diagram between metro platform train door and screen door
异物是指列车离站前,风险空间新增的影响地铁设施、乘客安全和列车正常运营的人和物。本文收集了15种常见的不同类别物体来覆盖大多数异物实例。构建的MAD数据集包含5 854张图像,它们包含的类别有粗绳、细绳、假发、书包、塑料袋、盒子、单肩包、钱包、手机、水瓶、伞、人、纸板、其他异物和正常。“粗绳”和“细绳”代表不同大小的儿童防丢失牵引绳。出于安全考虑,用假发代替真人头发夹在门缝间。此外,“其他异物”代表了标记它们时无法识别的物体或其他罕见的异常物体,“正常”则表示没有异物。按照COCO[33]数据集的格式进行数据标注,并随机抽取20%的数据作为测试集,其余80%的数据作为训练数据集。采集的图片大小统一为640×480像素。MAD数据集中各类别异物的数量在表2中列出,MAD数据集的部分示例在图5中展示(红色框内包含异物)。

表2 MAD数据集中各类物体图片数量Table 2 Number of images of various objects in MAD dataset 单位:张

图5 MAD数据集图片样例Fig.5 Sample images in MAD dataset
实验采用目标检测评价指标,即平均精度均值(mAP)、每秒传输帧率(FPS)、每秒10亿次浮点运算数(GFLOPs)。平均精度(AP)计算可以定义为经过插值的查准率-查全率曲线与x轴包络的面积。FPS用于评价模型的检测速度,GFLOPs用于评估模型的复杂度。查准率P和查全率R的公式表示如下:
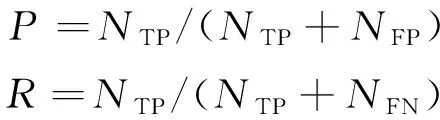
(8)
其中:NTP、NFP和NFN分别表示正确匹配的目标数、错误匹配的预测目标数和错误匹配的真实目标数。
基于PyTorch平台和MMDetection[34]开发工具,本文使用3个2080Ti GPU来进行模型训练,采用与文献[25]相似的训练技巧,并将AdamW设置为具有0.9动量和0.000 1权重衰减的优化算法。在MAD数据集上,初始学习率为0.000 1,batch size为16,模型的迭代次数为36次。
3.2 实验结果对比
将本文提出的DualFormer与其他先进的目标检测算法在MAD数据集上进行对比,包括基于CNN的算法和基于Transformer的算法。基于CNN的算法包括VarifocalNet[18]、RetinaNet[11]、YOLOX[10]、ConvNeXt[35]、Mask R-CNN[14]和TOOD[12],基于Transformer的算法包括PVT[24]、Swin Transformer[20]、P2T[25]和Deformable DETR[23]。
表3列出了对比实验结果。可以看出,总体上,DualFormer网络的性能优于现有的目标检测算法。表中展示了AP、AP50、AP75、APS、APM和APL指标的结果。APS、APM和APL分别表示文献[33]中定义的小、中和大目标的AP得分。与其他算法相比,DualFormer 的AP、AP50、AP75达到了最高值,证明了所提模型的有效性。此外,DualFormer在APS、APM和APL上相对排名第2的算法分别取得了2.7、0.6、0.5个百分点的增长,这验证了双通道网络在粗、细粒度特征聚合中的优势。

表3 MAD数据集上的对比实验结果Table 3 Comparative experimental results on MAD dataset
表3还给出了各模型时间和空间复杂度的比较。根据表1中不同变体的参数设置,可以在参数量和速度上进行权衡。从对比结果中可以看出,DualFormer-small在具有最小参数量(1.98×107)和GFLOPs(6.29×1010)的情况下获得了89.7%的检测精度(AP50),在时间和空间复杂度上优于其他对比算法。此外,随着参数量的增加,DualFormer-base和DualFormer-lager能够进一步提升检测精度(AP50)。图6中展示了部分DualFormer算法的检测结果。

图6 部分检测结果Fig.6 Partial test results
3.3 消融实验
在本节中,对DualFormer网络中不同组件和操作策略的作用和功效进行分析。以DualFormer-small为基线进行实验。
1)不同组件的性能分析。
如表4所示,设置5个实验组来验证双通道策略、CC-MHSA和通道注意力机制的优越性。实验组2和3将双通道策略分别替换为大尺度(8×8图像块)和小尺度(4×4图像块)的单通道特征提取方式,并保持其他组件不变。从表中可以看出,双通道策略的应用使得评价指标AP50明显提高。与单通道模型相比,在精度上分别带来了5.6和0.6个百分点的改进。实验组4验证了CC-MHSA和MHSA之间精度和速度的差异,这表明CC-MHSA可以对输入特征进行压缩并得到更强大的特征表示。实验组5将通道注意力机制替换为简单的融合机制,使得精度有0.4个百分点的下降。这验证了通道交叉注意力融合机制对粗、细粒度特征聚合的有效性。

表4 不同组件的消融实验结果Table 4 Ablation experimental results of different components
2)级联卷积数量。
为了验证级联卷积数量的重要性,以DualFormer-small为基线进行评估,结果如表5所示。可以看出,可以级联卷积的数量越多,输入序列的压缩比越大,模型的运算速度也越快。同时,本文提出的CC-MHSA中有3个并行卷积操作,每个卷积通路有不同大小的感受野(级联数量不同)。因此,压缩后的特征能具有不同强度的语义表达。从表中可以看出,当网络模型中4个不同阶段的CC-MHSA设置的卷积数量为{[5,4,3], [4,3,2], [3,2,1], [2,1,1]}时,算法能够达到最佳性能。由于网络4个阶段的特征有不同的尺度大小,因此不同阶段的卷积数量呈梯次递减的趋势。

表5 CC-MHSA中不同级联卷积数量的比较Table 5 Comparison of different cascade convolution quantity in CC-MHSA
3)压缩方式的选择。
最大池化、平均池化和级联卷积是3种典型的特征压缩方式。在表6的对比实验中,池化的步长与级联卷积的累积步长相同,以保持相同的下降采样率。相同的特征压缩比率对网络模型复杂度的影响较小,它们只影响模型参数量大小。相比池化操作,卷积操作将增加少量的参数计算。然而,级联卷积带来的精度提升明显优于另外2种选择。平均池化和最大池化仅仅对特征进行简单的抽样,而级联卷积可以高度概括输入特征,得到更强的语义表示。因此,本文将级联卷积作为最优选。
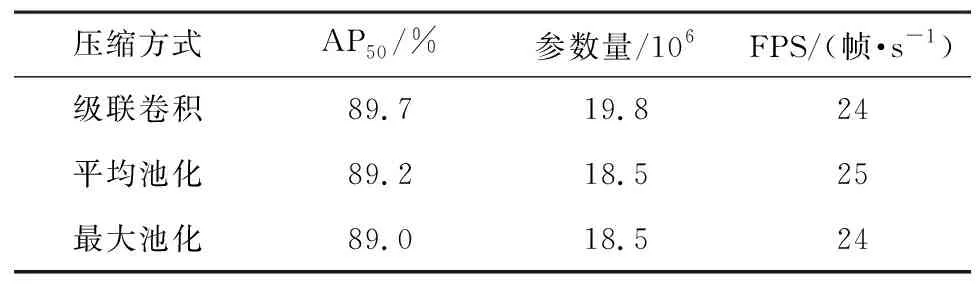
表6 不同特征压缩方式的比较Table 6 Comparison of different feature compression methods
4 结束语
本文提出了一种基于双通道Transformer、金字塔轻量化Transformer块和通道交叉注意力融合机制的DualFormer框架来检测地铁风险空间中的异物,及时为工作人员提供预警。双通道策略缓解了现有Transformer方法在输入图像块尺寸上的限制,引入了多尺度全局特征。通道交叉注意力融合机制使得不同尺度特征在通道中进行深层次的交互,促进了全局与局部信息的聚合。CC-MHSA利用级联小卷积缓解了Transformer计算和内存成本大的问题。此外,分别给出DualFormer的3种变体,实现了模型速度和精度之间较好的平衡。在MAD数据集上的大量实验证明了DualFormer的优越性。在mAP、FPS、GFLOPs和模型参数量等评估指标上,DualFormer模型均获得了最优性能。下一步工作将研究权重优化问题并探索模型量化等神经网络压缩方法,在尽可能减少精度损失的前提下轻量化网络模型,使其能够在边缘设备上进行部署。
猜你喜欢
中老年保健(2021年9期)2021-08-24 03:49:56
昆明医科大学学报(2021年4期)2021-07-23 01:21:56
昆明医科大学学报(2020年12期)2021-01-26 00:43:52
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
兽医导刊(2019年1期)2019-02-21 01:14:26
太空探索(2016年5期)2016-07-12 15:17:55
电子设计工程(2015年16期)2015-02-27 12:07:56
时代英语·高三(2014年5期)2014-08-26 17:01:17
教育与职业(2014年31期)2014-01-19 01:48:18
城市道桥与防洪(2013年8期)2013-03-11 15:18:23
