
基于虚拟网关的交通基础设施监测点位数据接入方法
2024-04-23 10:14:26黄亮邹鹏曹菁菁胡健颜泽锌黄小蝶
计算机工程 2024年4期
黄亮,邹鹏,曹菁菁,胡健,颜泽锌,黄小蝶
(1. 武汉理工大学水路交通控制全国重点实验室,湖北 武汉 430063;2. 武汉理工大学国家水运安全工程技术研究中心,湖北 武汉 430063;3. 武汉理工大学智能交通系统研究中心,湖北 武汉 430063;4. 武汉理工大学交通与物流工程学院,湖北 武汉 430063;5. 北京四维图新科技股份有限公司,北京 100093)
0 引言
2019年7月25日交通运输部印发《数字交通发展规划纲要》,目的是推动交通基础设施规划、设计、建造、养护、运行管理等全要素、全周期数字化。交通基础设施数字化通过汇集包括物联网 (IoT)[1-2]、地理信息系统(GIS)、建筑信息模型(BIM)[3]等在内的多种技术手段,对交通基础设施进行全方位的信息感知,从而实现对交通基础设施中各种信息的集成处理。其中,IoT点位监测数据在实时状态感知、结构健康监测、安全风险评估等方面具有重要价值[4-9]。文献[10]设计了一套改进型膨胀土边坡GNSS/多源实时监测技术,对监测数据进行实时采集、存储、处理和分析,进而实现对边坡的实时状态监测;文献[11]提出了一种基于组合载荷响应特征融合的桥梁结构智能损伤识别方法,利用点位监测数据实现了对桥梁损伤的识别和定位;文献[12]将航道监测信息作为客观评价指标,通过熵权模型进行科学赋值,实现了对引航安全风险的精准评估;文献[13]提出了一种以监测点当前变化量、累计变化量和变化率3个指标为基础的隧道风险数学模型和智能预警方法,该方法能够及时有效地进行风险预警。
监测数据在数字化应用中扮演着重要角色,然而,交通基础设施涵盖了道路、桥梁、隧道、轨道、航道等多种设施,涉及多种传感器,产生的监测数据存在数据结构、传输协议和采样频率各不相同的问题[14-15]。此外,交通基础设施数字化需要综合应用多种点位监测数据,这些数据往往又具有数量庞大、多源异构且实时性强的特点,给实时数据的快速接入带来了一系列挑战。
目前,主流的物联网监测数据接入方法主要包括基于Netty的数据接入[16-17]、基于Kafka的接入[18]、基于云平台的接入等[19]。在这些技术的基础上,国内外学者进行了多项与数据接入相关的研究。文献[20]提出了一种由Flink和Kafka集成的工业大数据平台,能够实现工业数据的接入、查询与预警,但是仍存在接入速度慢、接入数据类型少的问题。文献[21]基于Netty和Kafka开发了一个支持高并发、低延迟的数据接入平台,能够在万级连接下实现快速响应,但是其系统较为简单,整体性能不足以满足实际需求。尽管上述技术在某些情况下能够实现交通设施监测数据的部分接入,但是无法兼顾多源数据统一接入和高效大规模数据接入的要求,对超大规模全生命周期交通基础设施多源异构数据的实时接入以及存储能力较弱,这对未来构建交通基础设施全要素数字模型带来极大的挑战。
本文通过使用Netty高性能网络框架和Kafka消息队列[22-23],实现交通基础设施监测数据的高效大规模接入,并结合微服务的高可扩展性,设计一种微服务+Netty+Kafka架构的智能虚拟网关。针对交通基础设施数据大规模传输的特点,采用一种自定义的二进制报文编码格式,缩短数据报文所需的字节长度,提高网络传输效率,进一步使系统性能得到提升。最后,通过对系统接入速度、存储速度和溯源速度进行测试,以验证系统的数据接入性能。
1 交通设施监测数据接入需求分析
部分灯浮监测数据如表1所示,隧道围岩拱顶变形监测数据如表2所示。

表1 灯浮监测数据示例Table 1 Buoy light monitoring data sample
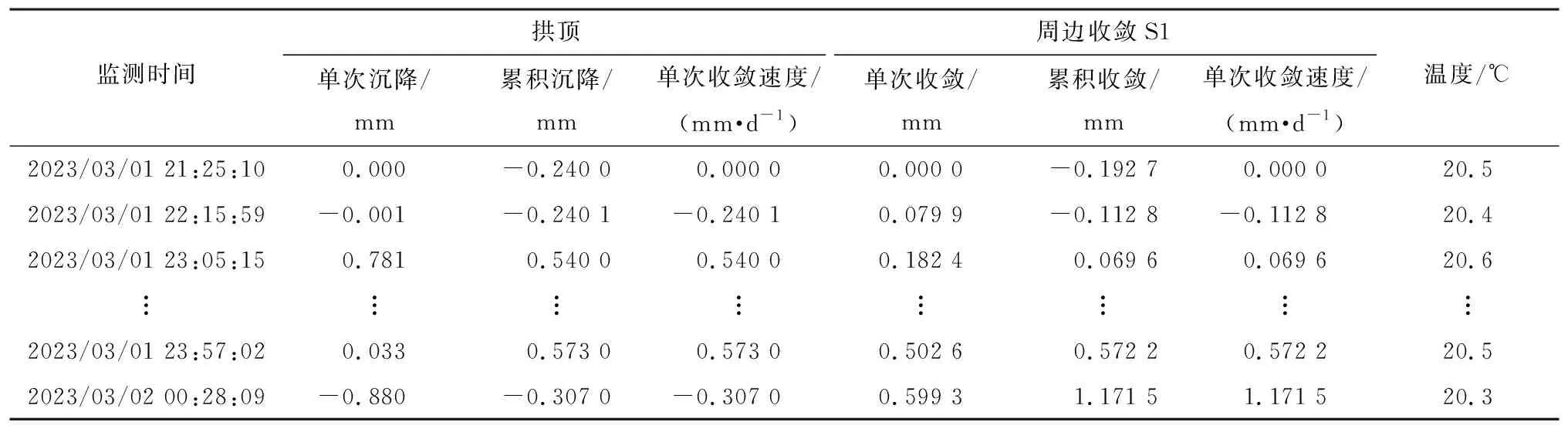
表2 隧道围岩变形监测数据示例Table 2 Tunnel surrounding rock deformation monitoring data sample
从表1和表2可以看出,交通基础设施监测数据涵盖位置、时间、电压、电流、沉降等多种信息,这些数据在格式、内容、精度和采样频率方面存在显著差异,呈现出明显的异构性。随着监测数据持续产生,数据会不断累积,数据中每个时间戳都记录了最新的监测信息,反映了设施的实时状态。因此,时效性和逐步累积性是交通基础设施监测数据的两大特征。上述数据特征对数据接入框架提出以下需求:
1)多源异构监测数据的统一接入需求。
数字交通基础设施感知设备的数据呈现多源性,这一多源性不仅体现在数据来自不同的采集系统,还在于数据源覆盖多个地域。当前主流数据传输系统采用了多种网络通信协议,如超文本传输协议(HTTP)、用户数据报协议(UDP)、传输控制协议(TCP)等[24]。因此,接入框架需要具备对各种数据来源接入请求的支持和处理多协议、多节点并发操作的能力。
2)数据接入效率高的需求。
交通基础设施监测设备种类繁多,它们不断产生庞大的数据量,并且数据持续上传到数据接入系统。这一巨大的数据体量如果不能及时处理,就会导致数据积压,可能会造成系统的阻塞。因此,需要高效、迅速地处理数据接入的请求。
3)数据接入规模大的需求。
交通基础设施数量庞大,产生的监测数据规模也相应增大。为了应对这种规模化的数据,数据接入系统需要具备同时处理大规模数据的能力。
2 基于虚拟网关的点位数据接入
2.1 虚拟网关架构
本文提出一个基于微服务+Netty+Kafka的智能虚拟网关架构。该架构整合了Netty框架,能够支持HTTP、TCP、UDP这3种协议,使得多源异构数据能够按照相应协议高效传入系统。传入的数据会被快速写入Kafka集群,并通过该集群分发至其他存储组件,以实现持久化存储。同时,微服务结合Kafka集群的使用,能够应对大规模数据的处理需求,实现系统的横向扩展能力。
本文交通基础设施数据接入智能虚拟网关的整体结构如图1所示,其涵盖了Web端网关配置界面、Nacos注册服务以及核心处理等多个关键模块。各个模块的核心功能分别如下:
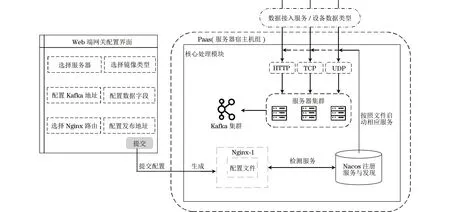
图1 交通基础设施数据接入智能虚拟网关结构Fig.1 Traffic infrastructure data access intelligent virtual gateway structure
1)Web端网关配置界面:配置服务器,选择Docker镜像包,配置Kafka地址、端口、主题,增/删/改数据字段,生成数据接收服务地址。
2)Nacos注册服务:注册服务,提供服务清单。
3)核心处理模块:读取配置,分配端口,拉取镜像,启动容器,监听Nacos注册,发现、修改Nginx配置,平滑重启Nginx,验证服务可用性。
2.2 虚拟网关配置
本文设计并开发一种智能虚拟网关平台[25],为用户提供一套可视化监测点位配置界面。通过智能网关配置界面,用户能够设定接入数据的类型、接入协议、字段名称、字段类型、字段说明等关键信息,这些配置信息规定了监测点位的配置方式。
在选择服务器和镜像后,系统会自动在对应服务器上拉取镜像,并根据配置的Kafka地址启动相应的后端服务,这些服务会发布数据发送接口,按照接口规范进行数据传输,实现与Kafka集群的接入。此外,系统可以根据网络情况针对性地对Kafka进行动态配置,充分利用网络本地特性,就近部署Kafka集群,能够有效减轻网络传输对系统性能的影响。为了满足服务的横向扩展,当单个集群网关达到性能瓶颈时,也可以通过搭建多集群的方式[26],同时启动多网关分配服务,设置一定的分配规则,比如:
1)基于hash的分配规则。根据客户端IP地址进行hash计算,将同一客户端的请求分配给相同的服务器;根据请求的URL信息进行hash计算,将相同URL的请求分配给相同服务器。
2)基于负载均衡的分配规则。将请求依次分配给不同的服务器,确保每台服务器都有机会处理请求,或将请求分配给当前连接数最少的服务器,以达到负载均衡。
3)基于权重的分配规则。为每台服务器分配一个权重,高权重的服务器获得更多的请求,这在服务器性能不同时比较适用。
4)基于地理位置的分配规则。根据客户端的地理位置信息,将请求分配给最近的服务器,降低网络延迟,提高访问速度。
图2是智能网关的数据接入配置页面,能够显示铁路、港航、公路、民航的不同交通基础设施感知设备类别,如信号设备、供电设备、RSU设备、路面监测设备、气象监测设备、摄像头、AIS设备、闸坝监测设备、机场风力传感器等,此外,还可以选择服务器、镜像名、Kafka地址、Nginx路由等。每个交通基础设施感知设备有默认的数据字段,根据实际需要可以通过配置页面进行删除、修改、增加,保存后就可以启动后台数据接收服务并生成数据接收接口,提供给数据发送方进行数据传输。
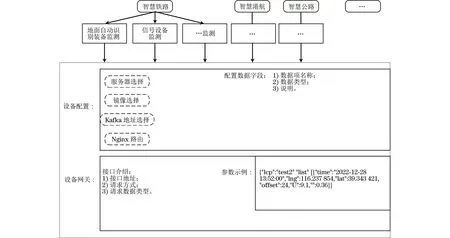
图2 虚拟网关数据接入配置页面Fig.2 Virtual gateway data access configuration page
2.3 多终端多协议数据接入
2.3.1 数据接入流程
数据接入流程如图3所示。系统的数据输入涵盖各类交通基础设施信息数据源,主要包括道路、铁路、航标等相关设施的点位监测数据。原始数据通过HTTP/TCP/UDP协议与网关集群相连接,从而启动数据接入过程。根据不同连接协议和数据包类型,网关将数据分发至相应的HTTP服务集群、TCP服务集群以及UDP服务集群,这些服务集群拥有可伸缩和可扩展的特性。通过标识(Topic),服务集群将经过处理的数据传输至Kafka数据总线,进而流入大数据存储系统进行有效的存储和管理。同时,数据也会被写入Redis集群,其中库名与Topic相匹配,而时间戳加上分区(PARTITION)则成为KEY,设置一定的超时时间以满足数据回溯的需求。

图3 数据接入流程Fig.3 Data access process
2.3.2 数据接入协议
虚拟网关支持HTTP、TCP、UDP这3种数据接入协议,对于每种协议下的数据格式做出相关定义,如下:
1)HTTP接入协议(传感器使用最多)。
HTTP是基于TCP协议的一种应用层传输协议,是一种使用最广泛的协议类型。HTTP接入需要解析数据实体,数据正文形式如表3所示。

表3 HTTP数据正文形式Table 3 HTTP data body format
数据示例如下:
目前,综合考虑性价比、可靠性和测速性能,基于传感器的测速方法仍是普通环境下测速应用的首选方法。由于测速传感器的精度与价格成正比,高精度、高性能测速传感器高昂的价格让普通用户望而却步。因此针对常规精度测速传感器,设计一种能保证高、中转速区测速精度,并能有效改善低速区测速精度的宽范围、实时滤波测速算法,对拓宽普通测速传感器的应用范围具有重要的工程意义。
{
"lcp": "topic1",
"list":[
{"time":"2023-07-11_10:48:54","lng":109.093,"lat":21.498,"U":15.5,"I":0,"temperature":2.0,"humidity":52,"motor_nums":3,"Light_Intensity":5.0},
{"time":"2023-07-11_11:00:53","lng":109.092,"lat":21.498,"U":15.7,"I":0,"temperature":1.8,"humidity":46,"motor_nums":3,"Light_Intensity":5.0},
...
]}
2)TCP接入协议(大规模数据接入)。
在TCP协议下以二进制形式封装数据报文,如图4所示,该报文采用big-endian字节顺序。

图4 TCP协议下的报文格式参考Fig.4 Message format reference under TCP protocol
(1)魔数:占用4个字节,固定为WHUT,用于在二进制数据流中区分数据报文。
(2)CRC32校验码:占用4个字节,对数据报文中的报文长度、命令ID以及协议报文字段3个部分的字节流求取CRC32校验码。
(3)报文长度:占用4个字节,包括命令ID以及协议报文字段的字节流长度。
(4)命令ID:占用4个字节,从1开始编号,用以标识报文所对应的平台业务。
(5)协议报文:占用可变字节长度,根据命令ID的不同,它所包含的字段也不一样,其中心跳报文命令ID取值为1,无协议报文。
(6)String类型:字符串长度,占用4个字节,字符串内容以“�”结束。
二进制数据流可以接收批量数据,它是多条报文的二进制数据累加,格式如图5所示。

图5 报文格式Fig.5 Message format
3)UDP接入协议。
UDP数据接入也是基于Netty框架,图6为UDP数据接入框架。此外,由于UDP是无连接的,即发送数据之前不需要建立连接,并且是面向报文的,没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低。UDP接入协议可以支持一对一、一对多、多对一和多对多的交互通信。UDP接入协议的逻辑通信信道是不可靠信道。UDP协议下的数据传输格式及含义如下:
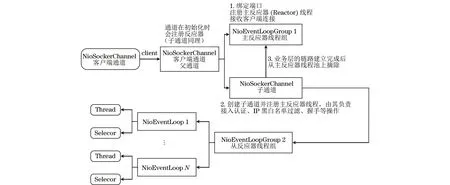
图6 UDP数据接入框架Fig.6 UDP data access frame
(1)源端口号:占用2个字节,指定发送端的端口号。
(2)目标端口号:占用2个字节,指定接收端的端口号。
(3)报文长度:占用2个字节,指定UDP报文的长度(以字节为单位),这个长度包括UDP报文头和UDP数据。
(4)校验和:占用2个字节,用于错误检测。
2.4 传输消息压缩和校验
为了降低数据在网络带宽上的占用,本文采用一种自定义的二进制报文编码格式。以表1的灯浮监测数据为例,用JSON格式传输,单条监测数据报文的大小为141 Byte,但在二进制编码格式下,每条监测数据报文的大小仅为54 Byte,节约了一半的网络带宽。这种优化提升了网络传输效率,显著减少了传输延迟,尤其对于大规模数据传输能够有效提高整体的传输性能。示例数据JSON格式如下:
{"time":"2023-07-11_10:48:54","lng":109.093,"lat":21.498,"U":15.5,"I":0,"temperature":2.0,"humidity":52,"motor_nums":3,"Light_Intensity":5.0}
转化为二进制后如下:
0111101100100010011101000110100101101101
01100101001000100011101000100010001100100011
00000011001000110011001011010011000000110111
00101101001100010…
由于TCP协议本身的机制问题,数据传输过程中可能会出现粘包现象。针对数据传输过程中出现的数据丢失情况,本文给出一种解决方案,如图7所示。
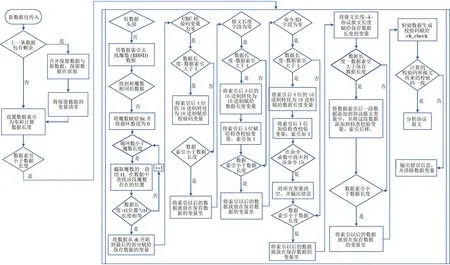
图7 粘包与半粘包验证流程Fig.7 Packet concatenation and half-packet verification process
新数据到达服务端时,首先检查前一次传输是否有未处理的数据:如果存在未处理数据,系统会将这些数据进行合并处理;如果没有未处理的数据,系统会检查新传输数据的长度,若数据长度为空,则系统不予处理,若数据长度不为空,则会进一步检验数据的头部信息。如果数据中存在头部信息,系统会进行CRC校验码验证,如果校验码存在,则系统检查数据长度,如果数据长度不为空,系统会检查数据的命令ID,若命令ID不在Netty预设的范围内,系统会进行相应的错误处理;若命令ID在Netty中存在,则系统生成校验码,并将其与报文携带的校验码进行比对。如果生成的校验码与报文中携带的校验码一致,系统将执行报文解析;若不一致,系统将清除数据,以避免错误数据对传输造成影响。
上述方案能够在数据传输过程中有效解决粘包和数据丢失等问题,确保数据的完整性和准确性。这一流程能够提高数据传输的可靠性,保障系统的正常运行。
3 实验验证与分析
3.1 实验环境
本文实验环境设置如表4、表5所示,使用14台应用服务器、2台数据库服务器和1台客户端,网络使用的腾讯公有云速率为100 Mb/s。

表4 应用和数据库服务器配置Table 4 Application and database server configuration

表5 客户端配置Table 5 Client configuration
3.2 性能效率测试
本文对具有亿级点位流数据的接入、存储和溯源分析能力进行测试,图8(a)为测试流程,图8(b)为数据传输实图。
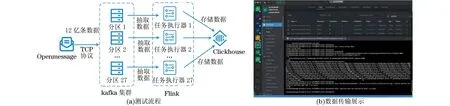
图8 测试流程和数据传输实图Fig.8 Testing process and real data transmission diagram
测试流程为:
1)启动分布式消息队列Kafka集群,设置集群资源、创建主题。
2)启动分布式数据模拟工具Openmessage生成点位流数据,通过TCP协议发送到Kafka集群中。每条消息对应一个点位在指定时刻产生的数据,Kafka缓存的数据为27个分区(PARTITION)。同时,统计点位流数据接入条数和时间。
采用4类数字交通基础设施感知设备数据作为测试数据进行模拟,每类数据各占25%,具体如下:
(1)智慧公路-隧道环境监测数据(TOPIC: tunnel_environment)描述如下:
{
"source_id": "qttl-a02-01", ∥来源设备或平台∥ID
"detection_time": "20230301230515", ∥监测∥时间
"luminance": 9.75, ∥隧道内的光亮度
"wind_speed": 5.0, ∥风速
"smoke_ density ": 1.02, ∥烟雾浓度
"tunnel_tempreture": 20.5 ∥隧道温度
}
(2)智慧铁路-轨道安全监测数据(TOPIC:railway_safe)描述如下:
{
"source_id": "YCBP-CX15", ∥来源设备或平∥台ID
"detection_time": "20231211123231", ∥监测∥时间
"track_structure_relative_displacement": 0.002 3, ∥轨道结构相对位移
"crack_and_seamwidth": 0.001, ∥裂缝及离∥缝宽度
"switch_crack": 0.012, ∥道岔裂纹
"temperature_humidity": 25.0 ∥湿温度
}
(3)智慧港航-航道运行监测气象数据(TOPIC: sea_lane_weather)描述如下:
{
"segment_code": "50400200", ∥航段编码
"collection_time": "20231015153000", ∥采集∥时间
"wind_speed_avg": 5.0, ∥平均风速
"temperature": 9.0, ∥气温
"humidity ": 0.65, ∥湿度
"atmospheric_pressure": 1.0 ∥气压
}
(4)智慧民航-风机监测数据(TOPIC: air_fan)描述如下:
{
"deviceno": "GN671188SK2", ∥设备编号
"location": "122.219 760,31.015 464", ∥设∥备位置
"acttime": "20230902123000", ∥记录时间
"status": 0 ∥运行状态
}
3)启动分布式实时数据处理引擎Flink,Flink按分区数启动同等数量的任务执行器(taskmanager)执行数据任务(job),taskmanager并行从Kafka中抽取数据写入分布式数据库Clickhouse。
4)将生成的12亿条点位流数据全部存储到分布式数据库Clickhouse中,并统计总时长。
3.2.1 数据接入和存储速度测试
以10 s为单位统计接入点位流数据量,多次统计后取平均值,由此计算数据接入速度。利用统计时长和存储量进行计算,得到存储速度。
统计每10 s的点位流数据接入量并取平均值,结果如表6所示。

表6 接入数据测试结果Table 6 Access data test results
经过计算,每10 s平均接入Kafka数据条数为122 911 898,即每亿条数据接入Kafka的时间为8.14 s,测试成功。存储速度测试结果如图9所示,每亿条数据的存储时间为9.75 s。
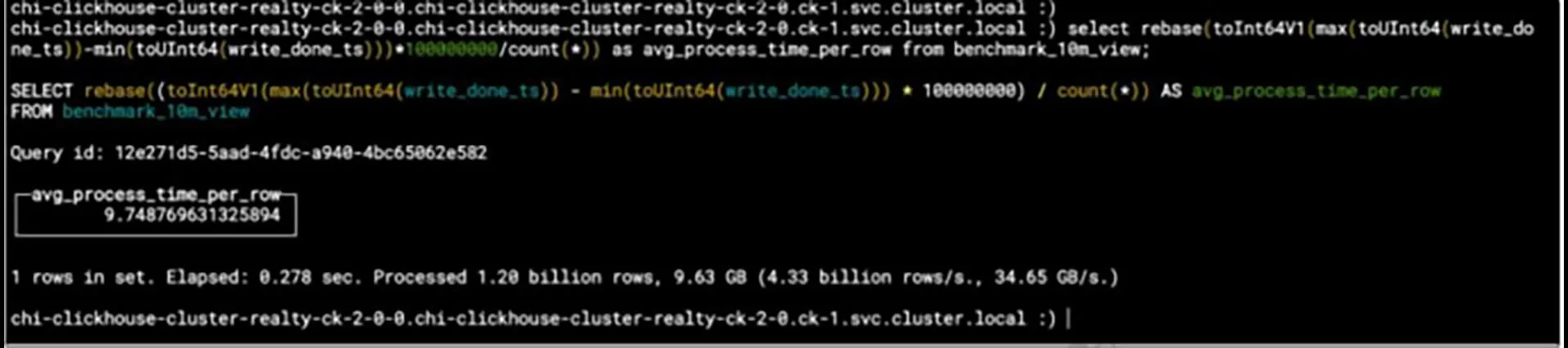
图9 数据存储测试结果Fig.9 Data storage test results
3.2.2 数据存储后溯源时间测试
溯源时间指溯源分析中从请求发起到获取分析结果的时间。测试中通过Clickhouse Client客户端工具连接到Clickhouse集群,分别执行测试用例中指点的溯源场景,如图10所示。本文进行多个不同场景的测试,最终统计全部结果的平均值,得到平均溯源时间为2.96 s。

图10 溯源场景4的执行结果Fig.10 Execution results of traceability scenario 4
3.3 对比分析
现阶段对于交通设施监测领域并未有数据接入相关的研究,本文参考其他领域的数据接入研究进行分析。
文献[20]中描述的平台架构在工业大数据处理中关注了查询效率、数据吞吐量和预警响应速度,记录了系统数据接入速率,达35万条/s。相对而言,本文所开发的系统专注于交通基础设施领域,对大规模数据接入的性能要求更为严格,其数据接入速率远超前述平台,达到了前者的数十倍。
此外,文献[20-21]中提到的数据接入方法采用物联网设备,通过网络通信接口直接与数据中心对象进行数据交换。这种直接接入方式虽然简便,但是会引起数据可靠性和系统兼容性的问题。与此不同,本文系统借鉴了文献[19]中的方法思想,实施封装与解析的标准接口,对数据对接过程的内部细节进行了抽象化处理,并采用数据包进行数据传输。基于这一架构,本文设计一种面向交通设施监测的虚拟网关,并通过一系列的协议适配和优化策略,增强数据接入的安全性、效率和兼容性,以满足不同应用场景的需求。
3.4 接入数据可视化展示
以北海港1号灯浮2020年9月14日的监测数据为例,监测数据中包括采集时间、经纬度、电压、电流、光强等级、工作环境温度等多项监测特征。这些数据可在地图上以灯浮点的形式呈现,点击这些标点可进入详细情况页面,如图11(a)所示。此外,还提供了历史查询功能,可查看最近一段时间内的监测数据变化曲线,如图11(b)所示。这样的设计有助于用户更直观地了解监测数据的变化趋势,并方便深入分析不同时间点的具体数据。
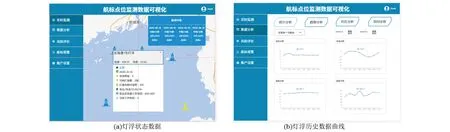
图11 灯浮监测数据可视化Fig.11 Buoy light monitoring data visualization
上述实验结果表明,本文所构建的虚拟网关平台可以满足多种物联网通信协议对交通基础设施监测数据的接入需求,平台具有快速性和高并发性,基于微服务的架构也使其具有高扩展性和高可用性。
4 结束语
针对当前超大规模交通基础设施监测数据实时接入以及存储能力较弱的问题,本文提出一种基于微服务+Netty+Kafka架构的交通基础设施点位监测数据接入虚拟网关系统。通过传输协议适配、传输消息压缩设计以及集群分配策略等一系列性能优化措施,提升系统的接入和存储效能,并确保系统的广泛适用性。在测试环境中,该系统实现了对多点位多协议的亿级交通基础设施数据的快速、统一接入与存储。相较于传统的直接接入方法,虚拟网关在安全性与兼容性方面均取得了显著改进,为交通基础设施监测数据接入领域提供了一种有效的解决方案。此外,该系统为未来交通基础设施的性能感知、状态在线评估、预警应急、智能养护决策等数字化应用提供了高效、可靠的数据接入理论支撑。下一步将围绕系统性能优化、具体数字化应用这2个方面展开研究。
猜你喜欢
销售与市场(营销版)(2021年10期)2021-11-21 20:15:03
成都信息工程大学学报(2020年5期)2020-07-29 08:50:22
销售与市场(营销版)(2019年6期)2019-06-21 01:16:38
铁道通信信号(2019年11期)2019-05-21 03:05:56
网络安全技术与应用(2017年9期)2017-09-20 09:54:28
移动通信(2015年18期)2015-08-24 07:45:08
太阳能(2015年7期)2015-04-12 06:49:50
振动工程学报(2015年1期)2015-03-01 01:15:42
全球定位系统(2015年4期)2015-02-28 12:38:12
电测与仪表(2014年3期)2014-04-04 09:08:32
