
基于知识注入提示学习的专利短语相似度计算
2024-04-23 10:14邓远飞李加伟蒋运承
计算机工程 2024年4期
邓远飞, 李加伟, 蒋运承, 2
(1. 华南师范大学计算机学院,广东 广州 510631;2. 华南师范大学人工智能学院,广东 佛山 528225)
0 引言
专利是知识产权的一种形式,对于管理信息和知识、研发活动以及减少研究周期和费用都有帮助[1-2]。专利的申请数量每年都在持续增长,需要高效的系统来管理如此庞大的数据。现有研究提供了许多方法来解决这个问题,如有效处理、分析、分类和存储专利数据的方法[3-4]。
最近几十年来,专利法和专利技术的创新实证研究受益于质量越来越高的专利数据集,这些数据集在国家、企业、团队和个人层面都被广泛应用。专利数据有多种用途,如作为知识输入的代理或专利价值的度量,也被用作创新代理的度量。由于专利数据量庞大,因此需要大量的人力成本来研究和搜索专利。目前,专利管理和搜索的方式主要是基于传统的数据库,即技术人员需要识别目标的关键字并进行搜索,然后从数据库中检索专利[5]。因此,为了有效地对专利文本进行语义相似度计算,需要设计一种准确的专利语义表示方法。
USPTO(United States Patent and Trademark Office)数据在专利分析、经济学、起诉和诉讼工具等领域频繁使用。大多研究中使用的专利分类系统是参照国际专利分类法(IPC)和联合专利分类(CPC)所建立的。目前,针对USPTO数据的专利相似度计算及检索相关研究,仅利用自然语言处理相关技术来实现[6]。
随着预训练语言模型(PLM)的不断发展,BERT[7]等具有动态语义表征能力的模板逐渐成为文本表示领域的通用模型,使得解决下游任务的策略从重新训练模型转变为根据任务调整其参数。然而,在预训练和微调的过程中,不同阶段的优化目标不同。于是,起源于生成式预训练Transformer(GPT)[8]并由模式探索训练(PET)[9]等发展而来的“提示学习”[10]新范式应运而生。值得注意的是,已有很多工作尝试将外部知识融入以BERT为代表的预训练语言模型中,但主要集中在常识领域知识[11]和开放领域知识[12]。清华大学曾通过外部知识图谱扩展标签映射的方法,即知识集成的提示调优(KPT)[13],在关系抽取、文本分类等任务中取得了较大的性能提升。此外,文献[14]研究表明,并不是所有的外部知识都能带来增益。目前,该领域主要面临2个挑战:1)如何有效地植入外部知识,解决专利短语信息不足的问题?2)如何充分利用专利短语中的标签信息,解决知识噪声和异构性问题?如果这些技术被有效地应用于专利检索、专利分类等任务,专利推荐、自动专利质量预测等应用在未来甚至可以实现。
针对专利短语相似度语义匹配问题,本文首先提出基于知识注入的提示学习方法并应用到专利短语相似度计算中;其次引入外部知识图谱Wikidata,提出基于实体影响度的邻域过滤机制,获取相关实体的邻域特征信息,通过外部信息源扩充标签与专利短语信息,提高分类准确度同时解决专利短语信息不足的问题;接着应用交叉熵损失函数来训练所提模型,将扩展标签词的分数映射到标签分数上。此外,本文设计一种有效的提示生成文本,并验证其在现有数据集上的有效性。
1 相关工作
1.1 专利相关工作
近年来,许多机器学习技术已应用于专利相关研究,主要集中在专利检索、专利分类和相似度计算中,提高了专利分析工作的效率[2]。文献[6]提出一种两阶段专利检索方法,通过考虑权利要求的结构,将检索到的文档重新排序,取前N个文档,这意味着权利要求在专利中具有重要意义。随后,文献[15]通过使用USPTO专利数据,利用一种引文分析方法来改进专利检索技术。文献[16]提出一种基于聚类的专利检索技术,通过使用IPC代码提供额外的数据,满足用户的信息需求。
另一方面,尽管专利具有半结构化的性质,但是大多数现有的关于专利分类的研究工作都侧重于文本信息。如今,深度学习方法(如卷积神经网络)在图像处理、语音识别等领域取得了巨大进展,但尚未应用于专利分类任务。文献[17]提出了一种基于卷积神经网络和词向量嵌入的深度学习算法DeepPatent并用于专利分类。PatentBERT专注于微调预先训练的 BERT 模型,该模型仅使用专利的第一项权利要求,并在CPC子类级别的656个标签上取得了显著的成果。Patent2Vec[18]在专利分类工作中使用标签的文档学习专利的低维表示,从多视图的角度执行专利分类任务。
1.2 提示学习
经过微调的PLM[19]在各种自然语言处理任务中取得了巨大的成功。PLM可学习关于语言的语法[20]、语义[21]和结构[22]信息,在智能问答[23]、文本分类[24]和机器翻译[25]等领域广泛应用。然而,PLM仍然阻碍下游任务对预训练知识的充分利用。为此,受GPT-3[26]的启发,提示学习方法应运而生,其将下游任务转换为一些形式化目标并取得了优异的性能[17]。
提示学习[27-28]是最近出现的模型训练方法,最初由人工设计模板。文献[29]提出的PET借助自然语言构成的模板,使用BERT的掩码语言模型来进行预测。但是,PET方法的局限性在于需要人工选择模板,而且PET的准确率严重依赖模板的质量。文献[30]提出前缀调优(Prefix-tuning),其放弃模板由自然语言构成这一常规要求,使用连续空间内的向量作为模板。GPT-3、 ChatGPT[26]相关研究表明,通过快提示调优和上下文学习,大规模语言模型可以在低数据状态下实现优异的性能。P-tuning[31]利用可训练的向量来自动构建提示文本模板,重点解决提示调优在小模型上效果不佳的问题。手工定义或自动搜索得到的标签词映射有主观性强、覆盖面小等缺点,KPT[12]通过外部知识库扩展描述器的提示调优,用于提高文本分类的准确率。同时,KPT也为在提示学习下引入外部知识提供了参考。
2 背景知识
2.1 专利短语相似度语义匹配数据
本文使用的专利短语相似度语义匹配数据集(PPSD)是一个人类专家评级的CPC上下文专利技术短语(术语)到短语匹配数据集。表1所示为专利短语相似度匹配数据集的一个示例,完整的数据集可以通过 Kaggle(https:∥www.kaggle.com/datasets/google/google-patent-phrase-similarity-dataset)公开获取。

表1 专利短语相似度语义匹配数据示例Table 1 Example of semantic matching data for patent phrases similarity
专利短语相似度语义匹配数据集包含近 50 000 个评级短语对,每个短语对都有一个 CPC 类作为上下文,分为训练集 (75%)、验证集 (5%) 和测试集 (20%)。数据集中存在成对的专利短语 (Anchor和Target),并对它们的相似度进行评分,分数从0(完全不相似) 到1(意思相同)。在数据集中,相似度(Score)表示2个专利短语(Anchor和Target) 在上下文(Context)中的相似度,其值在0~1范围内,增量为 0.25。本文使用第4.2节的方法得到最终的扩展标签词,如表2所示,具体描述如下:

表2 扩展标签词示例Table 2 Examples of extended label words
1)锚短语(Anchor):第1个专利短语。
2)目标短语(Target):第2个专利短语。
3)CPC分类(Context):上下文 CPC 分类,指出进行相似度评分的专利短语的主题分类。
4)相似度等级(Rating):相似度等级标签,来自一个或多个手工专家评级的组合。
5)相似度(Score):相似度评分,来自一个或多个手工专家评级的组合。
2.2 问题定义
本文使用余弦距离来计算2个专利短语的相似度,然后计算其与人工评分之间的相关系数结果,包括Pearson 相关系数(PCC)和Spearman相关系数(SRC)。
3 专利短语相似度计算方法
3.1 提示学习
提示调优通过自动编码器调整将分类任务形式化为一个掩码语言模型(MLM)问题。提示调优可用于文本分类任务,构建一个含有[MASK]的模板,然后让掩码语言模型去预测[MASK]位置的单词。因此,文本分类任务被转化为一个掩码语言建模问题。
假设M是一个在大规模语料库上预训练的语言模型。在文本分类任务中,输入序列x=(x0,x1,…,xn)被分类为类别标签y∈Y。具体来说,提示调优用模板包装输入序列,而模板是一段自然语言文本。例如,本文将x=“The similarity between patent ′faucet assembly′ and patent ′tap inputs′.”分类为“not related”(相似度标记为0)或 “exact”(相似度标记为1),可以封装成:
xp=[CLS]xis [MASK]
(1)
在专利短语相似度匹配任务中,本文使用xA=WordAnchor表示原始专利短语(Anchor),使用xT=WordTarget表示目标专利短语(Target),则xA和xT可划分到一个相同相似度等级的分类标签y∈Y中。由表1可以看出,在专利短语数据集中,相似度是一个离散值。因此,本文将专利短语相似度计算问题转化成专利短语分类问题来解决。使用xA和xT替代x,则式(1)可以转换成:
xp=[CLS]xAandxTis [MASK]
(2)
接着,预训练的语言模型M给出了词汇表中每个单词v被[MASK]词元(token)的概率,即PM([MASK]=v∈Vyxp)。在提示学习中,本文需要一个标签词映射(verbalizer),将[MASK]位置上对于词表中词汇的预测转化成分类标签。例如在{0: “not related”, 1: “exact”}这个映射下,预训练模型在[MASK]位置,对于“not related”或“exact”这个相似度程度标签词的预测概率值会被当成是对“0”或“1”这个标签的预测值。标签词映射器首先要定义词表中哪些词是合适[MASK]词元位置的标签词,其次要定义标签词概率如何转化为最终的类别概率。
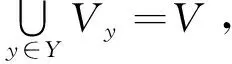
P(y∈Y|xp)=
f(PM([MASK]=v∈Vy|xp))
(3)
其中:f是一个函数,其将标签词的概率值转化为标签的概率值。
在上面的例子中,常规提示调优可以定义V1= {“exact”},V2= {“not related”},f为恒等函数,如果“exact”的概率大于“not related”,则本文将这个实例划分为“exact”标签。
提示学习的本质是设计一个比较契合上游预训练任务的模板,通过增加提示模板,将训练数据转成自然语言的形式,并在合适的位置 MASK。提示学习主要包括设计预训练语言模型、设计输入模板样式和设计标签样式及模型输出映射到标签(label)的方式3个步骤。本文提出知识注入的提示学习方法,利用外部知识来提高提示调优的语言表达能力,其模型框架如图1所示, 在本文方法中,通过扩展标签词及输入专利短语,达到注入外部知识的目的。

图1 本文模型框架Fig.1 The framework of the model in this paper
3.2 知识注入
基于上下文的掩码词预测过程并不是一对一的选择过程。因此,标签词映射中的标签词应该具备2个属性,即广泛的覆盖范围和较低的主观偏见。为此,本文使用外部知识来构建标签词映射,即通过Wikidata(https:∥www.wikidata.org)获取相关实体的信息。
对于每个专利短语中的实体,本文首先使用专利短语或者标签词称作为查询关键词,通过Wikidata获取相关实体的信息;然后使用相似度算法对专利短语和Wikidata实体进行匹配,以确定它们之间的关系;最后根据匹配结果将专利短语中的实体链接到Wikidata知识图谱中的相应实体上,实现实体的语义统一。

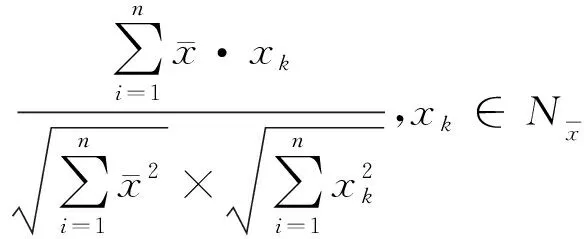
(4)
如果将专利短语实体的所有一阶邻居作为知识注入的提示学习模板,则工作量巨大。然而,仅针对相似度值进行过滤,则容易丢失专利短语实体间的潜在关系。因此,本文利用邻居实体的影响度对专利短语的邻域信息过滤进行干预筛选,得到其邻域信息,并作为知识注入模板的标签词:
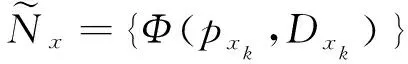
(5)
其中:Dxk为实体节点xk的度;Φ(·)为邻域节点的筛选函数。本文取邻居相似度值与邻居节点度的乘积的前m个最大值 (为了避免由于引入高阶邻居而带来的噪声影响,同时简化计算,设m=1)。
如图1所示,以提示生成的输入文本“[CLS] The similarity is exact between cocoa beans and free fatty acid in B01 [SEP] Coffee_bean Biochemistry”为例,目的是将专利短语对“cocoa beans” 和 “free fatty acid”归类到“exact”标签(即相似度为1)。对于专利短语“cocoa beans”,首先找到它的Wikidata实体“Cocoa_bean”;然后通过Wikidata实体间的关系构建其对应的一阶邻居图;接着采用node2vec图嵌入算法分别计算其与一阶邻居的相似度,如“Cocoa_bean”与一阶邻居“Coffee_bean”的相似度为0.72;随后逐个计算“Cocoa_bean”一阶邻居的度(“Coffee_bean” 一阶邻居的度为78);最后分别计算“Cocoa_bean”的一阶邻居相似度值与邻居节点度的乘积,将其降序排序,找出前m个最大的一阶邻居(设m=1,即获取到最终的外部知识图谱Wikidata中的实体“Coffee_bean”)。标签词“exact”与另一个专利短语“free fatty acid”也使用上述方法获取。
3.3 提示生成
本文构造有遮蔽的提示文本,其中,xA和xT表示专利短语,rA和rT分别为专利短语xA和xT的相关词,Context为CPC分类,[MASK]为预测的分类,[CLS]和[SEP]为预训练模型中的分隔符。考虑到不同提示生成的文本对最终结果的影响不同,本文构造如下T1~T7提示生成的输入文本:
T1=[CLS][MASK][SEP]xA[SEP]xT
T2=[CLS] The similarity is [MASK] betweenxAandxT
T3=[CLS] The similarity is [MASK] betweenxAandxTin Context
T4=[CLS] The similarity is [MASK] betweenxAandxT[SEP]rArT
T5=[CLS] The similarity is [MASK] betweenxAandxTin Context [SEP]rArT
T6=[CLS] The similarity is [MASK] betweenxAandxT[SEP]rArT
T7=[CLS]rArT[SEP] The similarity is [MASK] betweenxAandxTin Context
提示文本生成是基于提示学习机制构造融合专利领域知识的提示文本。添加提示文本不仅有利于模型获得上下文的语义联系,而且能够显著提升下游的任务效果,充分利用预训练语言模型可以从海量的语料中学习到通用的语言表示。
3.4 分类
本文采取对每个类所有标签词的概率值取平均的方法,定义标签词和类别的映射关系,得到最终类别y对应的预测概率:

(6)
3.5 损失函数
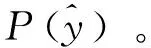

(7)

4 实验验证
4.1 实验设置
在实验过程中,本文模型和对比基线都是通过 Python 来实现,使用工具包OpenPrompt(https:∥github.com/thunlp/OpenPrompt)实现基于知识注入的专利短语相似度分类方法。Our(T5) 是本文提出的基于知识注入提示学习的专利短语相似度计算方法。使用性能最好的提示文本T5与基线方法进行比较。
4.2 对比方法
为了证明本文方法的有效性,将所提方法与经典方法及最近出现的方法进行比较,对比方法具体如下:
1)Word2Vec[33]从大量文本预料中以无监督方式学习语义知识,用于学习文本中的单词表示。本文使用 tensorflow_hub工具包加载英语维基百科语料版的Word2Vec预训练文本嵌入向量。
2)GloVe[34]构造一个单词共现矩阵,然后最小化词向量之间的欧几里得距离的平方来学习词向量。本文通过加载预训练好的“Wikipedia2014 + Gigaword(glove.6B.zip)”词向量实现GloVe。
3)FastText[35]基于用实数向量表示文本中单词的思想,使用神经网络学习从单词到向量的映射。本文加载预训练好的“wiki-news-300d-1M.vec”词向量获取每个专利短语的FastText向量表示。
4)BERT[7]和PatentBERT。BERT是一个基于Transformer的模型,使用一个大型的无监督语言建模数据集来学习一个句子的表示,这个句子中单词的顺序是不变的。对于BERT,本文使用BERT-large 模型。为了进行比较,本文在与 BERT-large 相同大小的专利数据上进行训练后得到 PatentBERT 模型。
5)Sentence-BERT[36]使用深度学习模型来预测句子中的下一个单词。本文使用“sentence-transformers”工具包加载“all-mpnet-base-v2”实现Sentence-BERT。
6)P-tuning[31]利用可训练的向量来自动构建提示文本模板,使用BiLSTM对模板中的初始化向量进行表征,增加嵌入向量之间的相关性。
7)KPT[12]通过外部知识库扩展描述器的提示调优,用于提高文本分类的准确率。
8)Patent2Vec[18]用于专利分类,使用图嵌入来生成低维表示,通过视图增强模块和基于注意力的多视图融合方法来丰富和对齐不同视图的信息。
4.3 评估指标
在语义相似性计算任务中,给定一个数据集,可以通过计算预测得分与人工评分之间的相关系数来评价模型性能。有2种常用的相关系数,即PCC和SRC,前者用来衡量2个变量之间的关系强度,后者偏向于相关度的评价。
除此之外,本文还使用文本分类评估指标进行比较,其中包括准确率(RAccuracy)、精确率(RPrecision)、召回率(RRecall)和 F1值,它们的结果包括4个部分,即真正例(NTP)、假正例(NTN)、真负例(NFP)和假负例(NFN),则对应的RAccuracy、RPrecision、RRecall和 F1 值的计算公式分别为:
4.4 实验结果
表3所示为对比方法在专利短语相似度匹配数据集PPSD上的PCC和SRC性能表现。从表3可以看出:静态预训练模型 Word2Vec、GloVe 和FastText性能表现不佳,考虑到数据集结构 (如许多具有不同含义的匹配专利术语)的影响,实验结果符合预期;PatentBERT模型显著优于常规的 BERT 模型,这意味着通用预训练模型对于专利中发现的专利术语而言效果不佳。

表3 不同语义相似度计算方法在PPSD上的性能表现Table 3 Performance of different semantic similarity calculation methods on PPSD
然而,本文从PatentBERT和 Sentence-BERT模型中得到了一个较好的结果,因为已经针对用于短语相似性匹配数据的预训练进行了微调。 KPT和本文方法都是基于提示学习进行微调的提示调优方法,表3显示,本文专利短语相似度计算方法(Our(T5))性能优于KPT,也比所有的对比基线方法更优,这验证了将知识图谱中蕴含的知识引入提示学习中的数据增强方式具有有效性。
4.5 实验分析
4.5.1 提示文本的影响
表4所示为使用不同提示文本的 PCC、SRC、准确率、精确率、召回率、 F1 值的实验结果,最优结果加粗标注。表4显示,提示文本T1~T7的 PCC波动比较明显,在T5上取得了最好的PCC性能。从式(6)可知,T5考虑了上下文 Context特征信息和相关词 relatedWord 特征信息,说明本文计算方法具有有效性,同样的结论也可从T5在SRC上的性能表现得出。

表4 不同提示文本的实验结果Table 4 Experimental results of different prompt texts
从表4可以看出:T1~T7的准确率波动较小,在T4和T5上取得了较好的准确率,可知本文方法对正样本的查准效果更好;T1~T7的精确率波动也较小,在T5上取得了最佳值,反映了本文方法分类结果准确率稳定,也说明整体分类效果较好;召回率是正确预测专利短语分类数与数据集PPSD中该类别实际包括专利数的比值,在T1~T7上表现相当稳定,说明本文方法对正样本的查全效果较好;F1值是精确率和召回率的调和平均数,综合平衡了精确率和召回率,在T1~T7上的表现波动更小,说明本文计算方法的整体分类效果较好。
图2所示为不同提示文本在验证集上的损失值变化情况(彩色效果见《计算机工程》官网HTML版)。从图2可以看出,在 Epoch为5之前,不同提示文本的验证集损失值波动较大,但是随后就稳定下来,说明模型泛化效果较好,也进一步说明了其有效性。
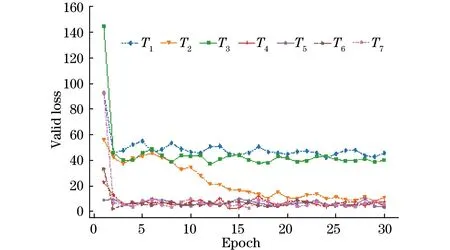
图2 不同提示文本在验证集上的损失值变化情况Fig.2 Changes in loss values of different prompt texts on the validation set
4.5.2 消融实验分析
从式(6)的提示文本T1~T7中选出提示文本T1、T2、T4和T5进行消融实验分析。从表5的实验结果可以看出,在提示阶段,不同的提示文本对应的 PCC和 SRC不同且相差较大,提示文本的长度、上下文 Context和相关词的选择均会影响最终的实验结果,且提示文本中不同特征信息交换位置时也在一定程度上影响了拼接后的语义,导致 PCC和 SRC较低。因此,寻求合适的提示文本是提示学习能否取得较好性能的关键。

表5 考虑不同特征信息时提示文本的PCC和SRC性能表现Table 5 PCC and SRC performance of prompt text considering different feature information
对于提示文本T1、T2、T4和T5,在提示文本中输入的合理信息越多,其性能越优,该结果也能验证本文基于知识注入提示学习的专利短语相似度计算方法的有效性。
对比提示文本T1和T2可以看出,T2的 PCC 和 SRC 性能表现都优于T1,说明T2的提示文本设置比T1更加合理,也说明了上下文 Context(CPC分类)的有效性。对比T4和T5可知,缺失 CPC 分类特征信息对T4的PCC和SRC性能影响更大,也进一步验证了上下文Context的重要性。
对比提示文本T1和T4,T4的PCC和SRC表现优于T1,说明T4的提示文本设置比T1更加合理,也说明了相关词 relatedWord 特征信息的有效性。对比T2和T4可知,T4的PCC和SRC性能更佳,说明考虑相关词 relatedWord 特征信息比考虑上下文信息更加有效,也验证了相关词筛选方法的有效性。相比T2,T5的PCC和SRC性能大幅提升,说明了相关词 relatedWord特征信息的有效性,也验证了相关词选择方法的合理性。
从表5还可以看出,不同提示文本之间的PCC和SRC性能表现差距较大。相比T1,T5的PCC和SRC性能大幅提升,说明上下文Context信息和相关词relatedWord特征信息具有有效性,进一步验证了本文计算方法的合理性。
5 结束语
专利是迈向知识型社会的重要资源,开发高效的系统来管理海量专利数据非常重要。为了解决专利短语信息不足的问题,本文利用专利短语中的相似度标签信息,提出一种基于知识注入的提示学习方法。实验结果验证了该方法的有效性。随着人工神经网络技术的不断发展,基于数据驱动的预训练和提示学习技术变得更加有效,但是人类的知识也在不断更新,如在不同时间阶段三元组知识(苹果,CEO,乔布斯)会更新为(苹果,CEO,库克)。因此,更新预训练语言模型中的参数空间知识将是下一步的研究方向。
猜你喜欢
水运工程(2022年7期)2022-07-29
传感器世界(2019年4期)2019-06-26
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
公民与法治(2016年10期)2016-05-17
海峡姐妹(2016年2期)2016-02-27
计算机工程(2015年8期)2015-07-03
求学·理科版(2015年6期)2015-06-18
化学分析计量(2013年1期)2013-03-11
轴承(2010年2期)2010-04-04
