
基于并行多注意力的语音增强网络
2024-04-23 10:03张池王忠姜添豪谢康民
计算机工程 2024年4期
张池,王忠,姜添豪,谢康民
(1.四川大学电气工程学院,四川 成都 610065;2.国网浙江省电力有限公司温州供电公司,浙江 温州 325029)
0 引言
语音增强旨在利用信号处理算法提高语音的质量和可懂度[1],被广泛应用于语音系统的前端[2]。传统语音增强方法包含谱减法[3]、维纳滤波[4]、基于最小均方估计[5]、子空间算法[6]等,这些方法的基本思路是将语音信号和声学干扰相分离,在语音短时平稳及噪声信号与语音信号独立且平稳的前提下可以实现语音增强,但是面对非平稳噪声时处理性能会降低。
基于深度学习的语音增强方法对于非平稳噪声有很好的处理能力。深度神经网络(DNN)[7]、卷积神经网络(CNN)[8-9]、循环神经网络(RNN)[10]和生成式对抗网络(GAN)[11-13]在语音增强领域具有较好的应用效果。根据语音增强方式的不同,神经网络的处理方式可划分为映射和掩蔽2种。基于映射方式,神经网络模型学习从带干扰语音特征到干净语音特征的映射,实现语音增强。文献[11]基于GAN的语音增强并使用生成器直接将时域带干扰语音信号映射到干净语音信号。文献[9]基于卷积神经网络并使用频域特征实现带干扰语音信号到干净语音信号的映射。掩蔽方式多应用于使用语音频谱特征的神经网络模型。神经网络模型根据输入的语音频谱特征生成相对应的掩模,将生成的掩模和输入的谱特征相乘或相加得到增强后的谱特征,将谱特征还原到时域得到增强语音[2]。掩蔽算法包括理想二元掩蔽(IBM)[14]、理想比率掩蔽(IRM)[15]和复比率掩蔽(CRM)[16],其中,前两者只针对语音幅度谱进行运算,忽略相位信息,后者基于复数计算规则,实现对于幅度信息以及相位信息的掩模计算。文献[8]使用复比率掩蔽结合卷积神经网络以及循环神经网络的变体长短时记忆(LSTM)网络实现了深度复卷积递归神经网络(DCCRN)。另外,还有一些研究使用生成式对抗网络的判别器实现对于语音评价指标的学习。文献[12]利用判别器学习评价指标函数,使其可以预测音频质量,解决了评价指标不可微分的问题,并使增强后的语音具有更高的语音感知质量和可懂度。
Transformer[17]由于具有可并行及处理长时间依赖能力的特点,因此基于Transformer的语音增强[18-20]可对语音进行全局信息建模,增强语音处理性能。Transformer的自注意力机制在语音增强领域的成功应用也引起了学者们的广泛关注,文献[18,21-22]在语音增强网络中引入通道注意力机制和局部注意力机制[23]进一步提升语音增强性能。
为了提取语音频谱的局部信息和全局信息,更好地捕捉语音信号的频谱结构,实现针对低信噪比以及陌生环境的语音增强,本文提出基于并行多注意力机制和编解码结构的时频域语音增强网络(PMAN),自注意力机制采用改进的Conformer[24]结构,用于提取语音序列的全局信息以及局部信息,局部块注意力(LPA)机制基于二维(2D)窗口注意力机制实现,可聚焦语音频谱信息的二维分布结构。PMAN结合通道注意力结构,实现不同通道之间的信息通信,采用并行Conformer模块同时处理语音序列的全局信息和局部信息,并行输入下一个层级的Conformer结构,更好地聚合序列部分的全局和局部信息,使用门控线性前馈网络(GLUFFN)作为Conformer模块的前馈网络(FFN),提升对于输入的特征提取效率。
1 基于并行多注意力的语音增强
1.1 网络模型
为利用语音频谱域的局部信息、全局信息和二维结构信息,提出结合Conformer自注意力机制和局部块注意力机制的语音增强网络。网络模型整体结构如图1所示,包含编码器、并行Conformer模块、掩模解码器和复数解码器。首先,信号经过短时傅里叶变换(STFT)得到语音复数频谱并计算得到语音幅度谱,将幅度谱和复数频谱在通道维度进行拼接,输入编码器使用卷积模块进行语音频域信息提取,输出语音频域信息的高维表示;接着,将编码器的输出输入并行Conformer模块进行注意力机制的处理,提取语音频域全局、局部及二维结构信息;然后,通过掩模解码器输出语音的幅度谱掩模,用于后续乘法增强运算;最后,通过复数解码器直接映射得到语音增强后的复数频谱,加和模块使用掩模解码器和复数解码器的输出计算复数频谱,再经过逆短时傅里叶变换(ISTFT)得到增强后的语音时域信号。

图1 网络模型整体结构Fig.1 Overall structure of network model
1.1.1 编码器
给定含有干扰的语音信号x∈B×L,其中,B和L分别代表输入语音的批量大小和数据长度。对x的复数频谱X通过幂律压缩[25]进行特征增强,如式(1)所示:

(1)
其中:Y、|X|、|Y|、θX、Yr、Yi分别代表幂律压缩后的复数频谱、原始的振幅、幂律压缩后的振幅、相位、幂律压缩后的实部、幂律压缩后的虚部;c为压缩系数,取值为0~1;幂律压缩后的振幅、实部和虚部在通道维度进行叠加Yin={|Y|,Yr,Yi}∈B×3×T×F输入编码器。
图2展示了编码器结构,包含1×1卷积核的二维卷积层、密集扩张卷积模块和包含1×3卷积核的二维卷积层。密集扩张卷积模块包含4个扩张卷积层,卷积的扩张系数为{1,2,4,8}。输入Yin首先通过卷积层得到语音频谱的高维度表示Y′∈B×C×T×F,其中,C代表卷积层的输出通道数;然后经过密集扩张卷积模块,使用不断增大的感受野及密集连接进行不同分辨率信息的聚合;最后通过后续的包含1×3卷积核的二维卷积层将频率维度减半以降低运算量,经过实例归一化和非线性层,编码器的输出为其中,T和分别代表编码器输出的矩阵时间维度和频率维度。

图2 编码器结构Fig.2 Structure of encoder
与一般的密集扩张卷积模块相比,本文使用的密集扩张卷积模块在卷积层之后添加局部块注意力层进行语音频谱二维结构特征的捕捉。图3展示了语音频谱图和卷积层输出的特征图(彩色效果见《计算机工程》官网HTML版,下同)。图3(a)语音频谱图虚线框中有规则条纹反映的是语音的谐波结构。图3(b)和图3(c)是卷积层不同通道输出的特征图,虚线框中的部分特征图具有和语音频谱图相似的条纹样式。针对特征图和语音频谱图具有类似图形结构的特点,引入二维局部块注意力机制,实现对于特征结构的捕捉。

图3 语音特征Fig.3 Speech feature


图4 局部块注意力层结构Fig.4 Structure of local patch attention layer
1.1.2 并行Conformer模块
并行Conformer模块主体是并行的Conformer层结构,使用注意力特征融合(AFF)模块[27]将并行输出的注意力特征进行融合,AFF和后续的局部块注意力模块和通道注意力模块构成注意力加和模块,连接在并行Conformer层后实现特征融合并进行二维结构特征的提取。注意力加和模块的输出分两路到下一个阶段的并行Conformer层,再经过同样的注意力加和模块得到并行Conformer模块的输出。

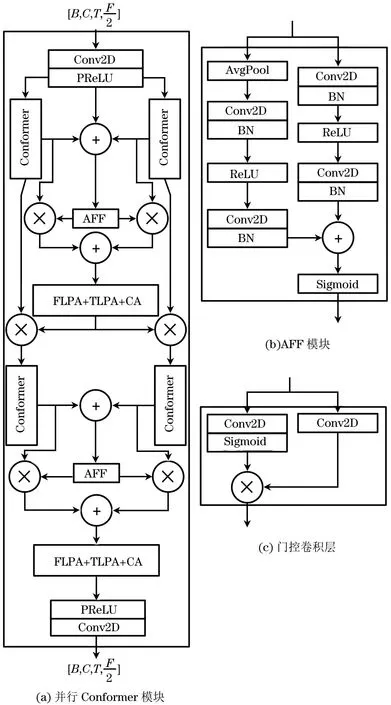
图5 并行Conformer模块结构Fig.5 Structure of parallel Conformer module


(2)

(3)
其中:δ代表ReLU激活函数。

Conformer层内部结构如图6(a)所示,2个GLUFFN中间夹入多头自注意力(MHSA)构成名为马卡龙网络[28]的结构。每个模块后面都有相应的层归一化(LN)和跳跃连接,用以缓解梯度消失,加速模型训练。整体的层输入和输出之间也具有跳跃连接,保证梯度传递。文献[29]证实了使用门控线性单元(GLU)的FFN具有较好的效果。图6(b)展示了GLUFFN结构,GLUFNN结构的系统函数如下:

图6 Conformer层结构Fig.6 Structure of Conformer layer
Hgluffn(x)=(Swish(xW)⊗(xV))W2
(4)

GLUFNN结构包含Dropout层用来优化梯度传输,使得训练更加稳定。Transformer结构擅长捕捉全局注意力,卷积模块能更有效地利用局部信息,两者结合能更好地进行局部和全局注意力的建模。图6(c)展示了DepthConv卷积模块结构,具有2个逐点卷积(PConv)、深度卷积(DConv)和Swish激活函数,其中GLU和批标准化(BN)用于优化梯度,辅助网络训练。
1.1.3 解码器
解码器包含掩模解码器和复数解码器2个模块。
掩模解码器具有类似于编码器的密集卷积扩张模块,不同之处在于:解码器的频率维度相比于编码器减半,包含4层扩张卷积模块,扩张系数为{1,2,4,8}。掩模解码器经过密集卷积扩张模块之后,输入子像素卷积层(SPConv)对频率维度进行上采样,恢复到原始大小。后续经过2个卷积层:第1个卷积层输出通道数与输入保持一致,卷积层的输出经过PReLU非线性激活函数得到语音振幅谱的掩码输出Y′m∈B×1×T×F,最后与输入的原始语音振幅谱|Y|进行点乘实现语音振幅谱的增强Ymag∈B×1×T×F,相比于掩模解码器模块,复数解码器模块去掉了最后的PReLU层;第2个卷积层的输出通道数设置为2,得到语音增强后的复数频谱Ycom∈B×2×T×F。

图7 解码器结构Fig.7 Structure of decoder
复数频谱的实部与虚部可表示如下:

(5)
复数解码器模块生成的增强后的语音复数频谱Ycom∈B×2×T×F,2个通道分别为语音复数频谱的实部B×1×T×F和虚部B×1×T×F。最终的语音增强的复数频谱可表示如下:

(6)
输出Yout经过逆短时傅里叶变换得到增强后的语音时域信号y∈B×L。
y=ISTFT(Yout)
(7)
1.2 损失函数
模型使用频域与时域联合损失函数。时域损失函数基于[y,xclean]计算,其中,y代表经过网络处理增强后的语音,xclean代表对应的干净语音时域信号。对信号使用STFT会存在一致性问题,计算公式为ISTFT(STFT(z))=z,其中z为时域信号。因此,基于文献[30]的设计,干净语音时域信号经过STFT以及ISTFT得到xclean,保证了增强语音与干净语音先经过同样的傅里叶变换处理过程,再进行损失函数的计算。频域损失函数包含2个部分:一部分是使用[Yout,Xclean_com],其中,Xclean_com代表干净语音信号的复数频谱,Yout代表增强后的语音信号复数频谱;另一部分是使用[|Yout|,|Xclean|],其中,|Yout|代表增强后的语音振幅谱,|Xclean|代表干净语音的振幅谱。损失函数计算如下:

(8)
时间域损失函数使用L1范数计算,其余的语音振幅谱以及语音复数频谱使用均方根误差(MSE)计算。
为了均衡各个损失函数的贡献,μ1、μ2和μ3作为权重系数,使用权重控制的方式得到最终的损失函数,如式(9)所示:
L=μ1Lmag+μ2Lcom+μ3Ltime
(9)
2 实验与结果分析
2.1 实验数据集
实验使用语音数据集VoiceBank+DEMAND[31],该数据集使用28个说话人进行训练,2个说话人进行测试。训练集包含11 572条干净语音数据,添加了10种噪声,其中,8种来自VoiceBank+DEMAND数据集,2种为人为噪声,信噪比混合等级为0、5 dB、10 dB、15 dB。测试集包含824条干净语音数据,添加了5种来自VoiceBank+DEMAND数据集的噪声,均未在训练集噪声中出现,信噪比混合等级为2.5 dB、7.5 dB、12.5 dB、17.5 dB。
为测试模型的泛化能力,使用NOIZEUS[32]数据集。该数据集具有30条语音数据,混合有不同信噪比下的8种不同真实世界噪声,信噪比混合等级为0、5 dB、10 dB、15 dB。
2.2 实验环境及参数设置
实验环境使用Linux Ubuntu 20.04操作系统,GPU显卡Tesla T4、显存16 GB、CUDA 11.8、PyTorch 2.0.0和Python 3.8的软件环境。
实验使用的VoiceBank+DEMAND数据均采用16 kHz的采样率。训练集语音数据切片长度为2 s,测试集的语音保持原始长度不变。STFT变换采用长度为512的汉明窗口,长度为256的位移,重叠率为50%,生成257个频率段。
网络模型采用AdamW参数优化器进行训练。初始学习率设置为0.001,根据训练批次进行学习率减半更新。一共训练100个批次,批次大小设置为3。损失函数的权重设置为μ1=0.7、μ2=0.3、μ3=0.2。
2.3 评价指标
采用主客观多种语音评价指标:1)主观评价指标,信号失真测度(CSIG)[33]、噪声失真测度(CBAK)[33]和综合质量测度(COVL)[33],三者的数值范围为1~5;2)客观评价指标,客观语音质量评价(PESQ)[34]、短时客观可懂度(STOI)[35]和分段信噪比(SSNR)[36],其中,PESQ的数值范围为-0.5~4.5,使用宽带PESQ,符合ITU-T P.862.2规范,STOI的数值范围为0~1,SNR与主观质量相关性较低,因此使用基于帧的SSNR作为语音质量的衡量标准[36]。以上6种语音评价指标的数值越大,语音质量越高。
2.4 结果分析
2.4.1 模型对比实验
为评估本文提出模型PMAN的增强性能,与经典模型及近几年的主流模型进行比较。选取的深度学习模型包括语音增强生成式对抗网络(SEGAN)[11]、用于语音增强的基于生成式对抗网络的黑箱度量分数优化(MetricGAN)[12]、相位和谐波感知的语音增强网络(PHASEN)[37]、基于频率递推的单耳语音增强特征表示(FRCRN)[21]、时域波形的语音增强(DEMUCS)[10]、基于两阶段变换器的时域语音增强神经网络(TSTNN)[19]、用于噪声消除的多视角注意力网络(MANNER)[18],其中,SEGAN[11]和MetricGAN[12]均采用GAN结构,后者使用指标鉴别器,引导网络直接学习语音的评价指标,PHASEN[37]和FRCRN[21]两者进行基于频域特征的语音增强,前者使用卷积层实现注意力计算,后者使用LSTM网络变体(FSMN)进行语音的长序列建模,相比于原始的LSTM,FSMN参数更少,并且性能有所提升[21],DEMUCS[10]使用LSTM网络进行语音长序列建模,TSTNN[19]和MANNER[18]均采用Transformer[17]网络结构对于语音进行全局特征和局部特征的提取,前者通过双阶段的Transformer网络提取语音的局部和全局上下文信息,后者构建了多视图注意力模块,包含全局注意力、局部注意力和通道注意力。
PMAN与经典以及主流模型的实验结果如表1所示,其中最优指标值用加粗字体标示,下同。由表1可以看出:1)PMAN在PESQ、CBAK、COVL、SSNR和STOI评价指标上取得了最好的结果,相比于MANNER网络分别超出0.07、0.19、0.07、0.29 dB和0.01,CSIG评价指标也具有可比性,仅相差0.03,这主要是因为MANNER使用多种注意力机制,直接对时域波形进行处理,PMAN虽然在CSIG上稍差,但是得益于基于频域特征增强的方式以及使用的并行Conformer结构,在其他评价指标上均有较大的提升,并且模型参数量降低了1个数量级;2)与使用FSMN作为自注意力机制并含有多注意力机制的FRCRN相比,PMAN得益于中间层网络的并行设计以及Conformer网络所提升的性能,在所有指标上均有提升;3)与使用Transformer自注意力机制的TSTNN相比,PMAN网络使用频域的特征处理以及并行Conformer模块,最终评价指标有较大提升;4)本文的轻量模型PMAN1使用32通道的卷积层,参数量下降到0.36×106,具有较优的性能;5)本文PMAN2的中间层使用单个并行Conformer模块,达到的效果也优于一些经典和主流的语音增强网络模型。

表1 模型实验结果对比Table 1 Comparison of model experiment results
图8展示了干净和含噪语音以及经过不同模型增强后的语音时域以及频谱图。由图8的语音时域波形以及语音的频谱图可以看出:与PMAN和FRCRN相比,MANNER和TSTNN对于噪声的处理力度更大;与FRCRN相比,PMAN对于噪声处理力度更大,增强后的部分更接近于干净语音,对于语音的低频部分恢复得更加彻底,高频部分更好地保留了语音的有用信号,且对于有用信号的增幅更大。

图8 语音频谱图Fig.8 Speech spectrogram
2.4.2 消融实验
为了验证PMAN各个模块结构的有效性,进行消融实验,具体为采用串行的注意力机制结构(Serial Model)、去掉LPA模块(No LPA)、使用常规的FFN层替换GLUFFN层(No GLUFFN)、去掉Conformer层(No Conf),从而分别验证并行结构的优势、LPA模块的作用、GLUFFN层的作用和Conformer层的作用。表2展示了消融实验结果。

表2 消融实验结果Table 2 Results of ablation experiment
由表2可得知:串行的网络结构的PESQ以及SSNR指标相比于PMAN有一定的差距,说明了并行结构对于语音增强有提升作用;去掉包含编码器、中间层和解码器的LPA模块得到的各个指标相比于PMAN有所下降;将GLU结构替换为两层的全连接网络指标也有所下降,说明了使用GLUFFN的PMAN具有更好的性能。综上,PMAN所使用的结构均在模型中起到了相应的作用。
2.4.3 泛化能力实验
为了探索模型对于语音增强的泛化能力,使用模型对NOIZEUS语音数据集进行增强,对于训练完成的模型,NOIZEUS语音数据的说话人和噪声均是未知的。
结合表3和图9可以看出:PMAN在除了STOI指标以外的PESQ等语音指标上相比于对比模型具有一定的优势,仅在STOI指标上稍微弱于FRCRN,但在PESQ等指标上相比于FRCRN也有较大幅度的提升,说明了PMAN对于未知的含噪语音的处理能力优于对比模型。可见,PMAN在不经过再训练的情况下,能有效针对陌生环境以及说话人干扰进行语音增强,具有较好的泛化能力。

表3 泛化能力对比数据Table 3 Comparison data of generalization ability

图9 泛化能力对比曲线Fig.9 Comparison curve of generalization ability
3 结束语
本文构建结合并行Conformer与多注意力机制的PMAN模型,同时处理语音经过傅里叶变换之后得到的振幅谱和复数谱,通过后续加权计算的方式利用语音的相位信息规避了相位的直接计算,使用并行的Conformer结构更好地进行局部信息和全局信息的整合,并利用LPA结构捕捉语音图谱的二维结构特征。在VoiceBank+DEMAND数据集上的实验结果表明,相比于经典及主流模型,PMAN模型取得了较好的增强效果。下一步将对含有噪声、混响等干扰下的语音进行增强研究。
猜你喜欢
小学生必读(低年级版)(2021年10期)2022-01-18
中学生数理化(高中版.高考数学)(2021年11期)2021-12-21
中学生数理化(高中版.高二数学)(2021年4期)2021-07-20
中学生数理化(高中版.高二数学)(2021年4期)2021-07-20
空间科学学报(2021年6期)2021-03-09
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
新世纪智能(数学备考)(2020年12期)2020-03-29
家庭影院技术(2019年8期)2019-12-04
测控技术(2018年7期)2018-12-09
