
基于事件演化图的多标记事件预测模型
2024-04-23 10:14:34王华珍许泽孙悦丘斌陈坚邱强斌
计算机工程 2024年4期
王华珍,许泽,孙悦,丘斌,陈坚,邱强斌
(1. 华侨大学计算机科学与技术学院, 福建 厦门 361021; 2. 华侨大学厦门市计算机视觉与模式识别重点实验室, 福建 厦门 361021; 3. 智业软件股份有限公司, 福建 厦门 361008)
0 引言
事件预测是指基于给定已经发生的一系列事件来预测后续可能发生的事件[1],而多标记事件是指同时发生的多种类型的事件,多标记事件预测就是基于已经发生的事件来预测候选事件是多标记事件的情况。多标记事件预测在医学、金融、环境等许多领域都有应用。如在医学领域中,一个病人的诊断可能涉及到多种疾病;在金融领域中,股票市场预测需要同时考虑多个相关指标。
事件预测的方法随着计算机技术的不断发展而完善。基于统计方法和机器学习方法是目前主要的两大类方法。早期的事件预测大多采用基于统计的方法,常用的包括回归分析、时间序列分析、贝叶斯分析等。如点互信息(PMI)模型[2]根据两个事件在训练集中出现的频率来反映这两个事件之间的关联程度,以此来进行后续事件的预测。Bigram方法[3]则通过分析文本中相邻的两个事件出现的频率和概率,建立一个基于Bigram的事件预测模型,从而预测文本中未来发生的事件。这类方法在特定场景中的性能优异且准确率较高,但其是在训练集中通过统计事件发生的概率来进行后续事件预测,无法预测出训练集中没出现的事件,因此鲁棒性较差,且事件之间潜在关联难以学习,导致效率较低。
随着机器学习和深度学习的发展,事件预测领域也涌现出许多新的预测方法,总体来说可以分为三类[4-6]:基于事件对的方法,基于事件链的方法和基于事件演化图的方法。基于事件对的方法是通过分析事件对中前事件与后事件的相关性,从而来提高在候选事件中匹配出正确事件的准确性,常见的基于事件对的方法有Word2Vec[7]和EventComp[8]等。基于事件对的方法在预测时以已知事件和后续事件的相关性作为预测依据,忽略了多个事件间可能存在联系。基于事件链的方法通过学习事件链中事件之间的时序信息,充分捕获事件之间的序列特征进行后续事件预测。常见的基于事件链的方法有PairLSTM[9]和SAM-Net[10]等。基于事件链的方法同样也忽略了事件之间复杂的相关性。基于事件演化图的方法可以有效地解决这个问题。目前基于事件演化图的方法研究较少,文献[11]提出事件演化图的概念,他们认为隐藏在事件演化图中的反映事件之间的动态发展规律和演化模式是有一种非常有价值的知识,可以利用其来提升事件下游任务的性能和效率。
近年来,随着图神经网络的研究逐渐兴起,研究人员基于图神经网络进行事件预测,解决了如何根据事件间的联系来预测后续事件问题。传统的神经网络更适用于在欧几里德空间中的数据,而图神经网络则能作用在图数据结构上,通过图嵌入方法来进行图表征学习,扩展了深度学习对于非欧几里得数据的处理能力[12]。图数据中蕴含着非常丰富的关系类型的信息,而图神经网络在对图中的节点之间的关联性进行模型化处理上具有很强的优势,这使得它在很多相关的研究中都有很大的突破。使用图神经网络进行事件的预测,同样可以提高预测结果的准确率和效率[13]。而对于多标记事件,利用多标记学习中问题转换思想,将多标记问题转化为单标记问题,并结合现有事件预测方法,实现对多标记事件的预测。
事件预测越来越受到学界和业界的关注,大量研究致力于事件预测的开发和应用。但已有的相关研究分析不够细致和深入,忽略普遍存在的多标记事件情境。为解决以上问题,本文提出了基于事件演化图的多标记事件预测模型(MLEP)。利用门控图神经网络(GGNN)框架,并结合多标记学习中问题转换思想,将多标记问题转化为单标记问题,构建多标记事件预测模型,以实现多标记事件的预测。
1 相关工作
多标记事件预测问题可在现有事件预测技术的基础上利用多标记学习的思想来解决。下文分别介绍事件预测技术和多标记学习技术。
1.1 事件预测技术
事件预测是事件研究的下游任务,现有研究大多都是在已经抽取出的事件基础上挖掘事件之间在时间维度、因果维度上的联系,从外部语料中获取先验知识和事件演变规律来支撑推理和预测。事件预测方法可根据对数据的组织和利用方式分为以下3类[14]:
1)基于关联规则的方法。基于关联规则是数据挖掘领域比较经典的预测方法之一。它通常由两个步骤组成:首先学习前兆和目标事件之间的关联;然后利用所学的关联预测未来事件,其中未来事件前兆是通过挖掘历史数据中的关联或逻辑模式来提取的。基于关联规则的方法在特定场景中性能优异,但缺乏普遍适用性,且规则的构建往往需要大量的人力和时间,效率较低,所以难以在实际应用中普及。
2)基于因果的方法。使用特定的预定义的因果关系模式将事件根据因果关系转换成特定的结构,以此来推断未来的事件。这种方法的步骤如下:从给定文本中抽取出目标事件;根据因果规律定义事件间的因果关系;根据因果关系预测出后续事件。文献[15]通过挖掘医疗因果关系构建因果知识图来实现预测,为医疗诊断提供了一定的辅助作用。在实际应用中,因果关系有时定义比较模糊而难以确定,关系抽取相对困难,而且这种方法只关注特定事件之间的因果关系,没有发现一般的因果关系模式。因此,在这方面深入的研究相对较少。
3)基于序列预测的方法,即通过分析事件发生的时序关系规律来预测后续可能发生的事件。序列预测主要探索如何预测序列的下一个元素及其所代表的事件。序列预测方法主要分为两种类型,其中第一种需要人为定义关键属性,而更现代化的方法可以基于深度学习方法学习序列的隐含表征以直接预测未来事件。基于序列的方法成为事件预测领域应用比较广的一种方法,尤其是在具有顺承关系和演化特性的事件中。近年来,已有很多通过对序列事件建模的方法来进行事件预测的研究,如文献[16]通过构建一个长程时序模块学习事件链中的序列信息,实现了后续脚本事件的序列预测。
以上事件预测研究鲜有关注到在各领域普遍存在的多标记事件情境。目前多标记事件预测仍处于快速发展阶段,但针对多标记事件预测的研究还很贫乏。
1.2 多标记学习技术
多标记学习(MLL)是针对现实世界中普遍存在的多义性对象而提出的一种机器学习技术[17]。传统学习模型的样本一般具有明确且单一的标记,但在现实世界中的对象标记往往都是不明确的,会表现出多义性[18]。关于多标记学习问题的求解策略,现有的方法根据标记之间的相关性可以分为三类[19-20]:一阶策略,二阶策略和高阶策略,而这些策略根据算法求解思路的不同也可以分为算法改进和问题转化两种算法。
算法改进,顾名思义就是改进现有的单标记算法,从而使算法能够解决多标记领域的问题。如何考虑多标记空间中的不同标记间的联系和相关性,以提高预测的性能是算法改进的一个关键问题。通过改进现有的单标记学习算法能够解决多标记学习问题,具体算法包括增强文本[17]、多标记k近邻[21]和排名支持向量机[22]等。问题转化则不需要对算法进行修改,是在处理过程中将复杂的多标记问题转化为单标记问题,得以使用现有的方法解决,问题转化的关键问题是对标记空间中重叠标记的处理,其主要方法包括BR(Binary Relevance)[23]和LP(Label Powerset)[24]等。与算法改进方法相比,问题转化更加灵活,因为在问题转化后可以应用任何现成的单标记学习方法解决,所以具有强大的适用性[25]。因此,问题转化是目前研究多标记使用较多的方法,本文也将采用这种方法来研究多标记事件预测问题。
以多标记分类为例,给出多标记问题的形式化定义。用L表示一个多标记数据集合,即L={lj|j=1,2,…,m},其中,m表示类别标记的数量。D表示训练集,D={(xi,Yi)|i=1,2,…,n},其中,n和xi分别为样本数量和第i个样本的特征属性,Yi∈L代表样本i的标记集合。多标记数据集示例如表1所示,数据集共有4个样本,每个样本包含1个或多个标记。
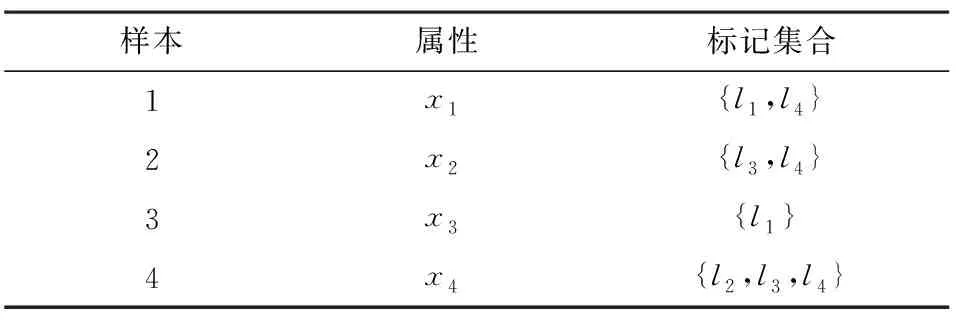
表1 多标记数据集Table 1 Multi-label dataset
BR是一种典型的问题转换型方法,主要思想是用多个二分类问题代表一个多标记问题来实现问题转换。它将对每一种标记进行预测看作为单独的二分类问题来处理,因此共有m个二分类器。与此同时,数据集被变换为m个数据集。以第j个数据集为例,包含标记lj则赋予lj,不包含标记lj则赋予lj。在采用BR方法进行分类时,最终预测结果用m个二分类器得到组合结果代表。用BR方法对数据集L进行数据转换,结果如表2所示。
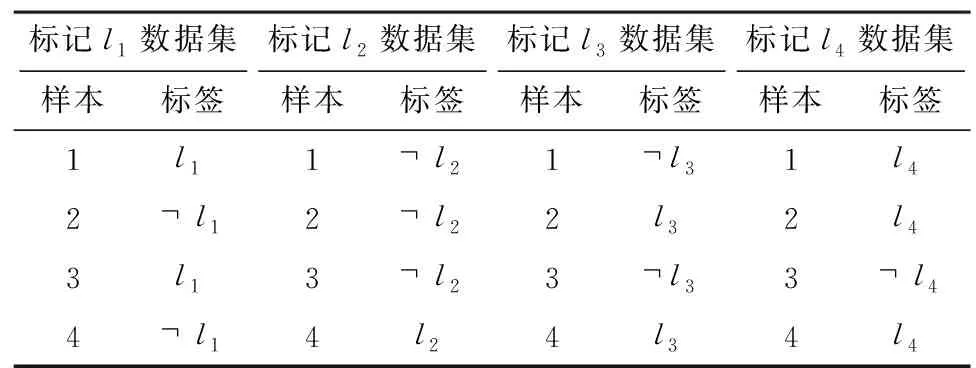
表2 使用BR方法对数据集进行数据转换的结果Table 2 Result of data transformation on the dataset using the BR method
LP也是一种问题转换型方法,它用一个多标签分类器来代替多个标签组合,实现了多标记到单标记的转化。这个组合标签表示所有可能的标签组合,每个组合都被视为一个单独的分类类别。LP方法用多种标记组合对数据集中的标记通过组合的方式进行重新排列,以单标记的组合标签来代替多标记标签,LP方法对数据集进行转换后的结果如表3所示。LP方法实现了对标记的组合进行编码,能简单地将多标记问题转换成组合标记形式的单标记问题,然后采用已有的单标记算法进行解决,具有广泛的适用性。因此,本文也将采用LP问题转换方法,使用组合标签的方式来研究多标记事件预测问题。

表3 使用LR方法对数据集进行数据转换的结果Table 3 Result of data transformation on the dataset using the LR method
2 MLEP模型框架及关键技术
2.1 模型框架
事件预测任务是指根据已知发生的事件来预测出后续可能发生的事件。本文提出一种基于事件演化图的多标记事件预测模型(MLEP),该模型具有以下优势:1)将实体描述、实体类型以及关系路径信息融入到事件表示中以提升事件的表示效果;2)针对多标记事件预测的研究,提出基于事件演化图的多标记事件预测研究的新模式。MLEP模型框架如图1所示。

图1 MLEP模型框架Fig.1 Framework of MLEP model
MLEP模型输入为多个原始已知事件组成的事件图以及候选事件集合,进而根据每个候选后续事件与已知事件之间的相关性得分选取最优的候选事件作为预测结果。具体为:首先利用事件表示学习方法获取所有事件的向量表示,并基于多标记学习问题转换的思想,将多标记标签转换成单标记标签表示,对多标记事件进行编码;然后采用门控图神经网络的框架,并基于事件演化的模式构建多标记事件预测模型,实现多标记事件的预测;最后对预测结果进行解码,输出对应的多标记事件。
2.2 事件演化图的构建
事件演化图可以揭示事件发展的规律,且事件演化图中边的权重可以用于获取事件之间的关联信息以指导事件预测[26],因此基于事件演化图来构建事件预测模型,可以大幅提高预测的准确性。
事件演化图是由有顺承关系的事件和事件链构建的具有演化规律的图结构,根据事件链中事件节点及事件间关系在数据集中出现的频率进一步配置事件间关系的权重。具体来说,由S={s1,s2,…,si,…,sn}表示一组事件链,si是S中任意一个元素,si中可能包含多标记事件,可以将其表示为{e1,l1,e2,l2,…,(eg,lg,eg+1,lg+1,…,ek),…,lm-1,em},其中,ei表示事件链中的事件,li表示事件间的关系,(eg,lg,eg+1,lg+1,…,ek)表示同时发生的多标记事件集合。事件演化图可以表示为G={E,Q},其中,E={e1,e2,…,eP}为节点集,Q为边的集合。图中每一条有向边lij表示为lij:ei→ej(lij∈Q)。lij需要赋予一个权值w(ei,ej),权值是通过事件节点及事件间关系在数据集中出现的频率计算出来的,其公式如下:
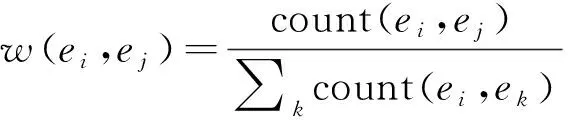
(1)
其中:count(ei,ej)表示(ei,ej)关系在训练集中的频率。构建的事件演化图示例如图2所示。
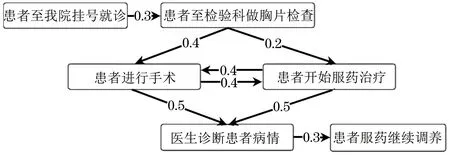
图2 事件演化图示例Fig.2 Example of event evolution graph
2.3 MLEP模型的算法原理
MLEP模型算法由3个步骤组成:1)事件编码,用来获取已知事件和候选事件的向量表示,以此作为门控图神经网络输入;2)门控图神经网络,用于建模事件之间的时序预测并不断更新演化图中事件的表示;3)后续事件预测,即通过已知事件和候选事件之间的相似度,选出合适的事件作为预测结果。
2.3.1 事件编码
对于事件编码,通过将实体类型、实体描述等实体属性和事件间关系路径融合到事件中表示,以提高事件表示学习的能力及推理性能。这种方法模型定义为融合实体属性和关系路径的事件表示学习模型(EARP),具体为:使用加权层次编码[27]嵌入实体类型;引入BERT(Bidirectional Encoder Representations from Transformers)模型[28],对实体描述的完整语义进行表示;通过路径资源约束算法[29]对关系路径进行向量表示。本文通过EARP表示学习方法获取所有事件的向量表示,以提高事件预测的效率。
对于多标记事件,需要利用第1.2节中多标记学习问题转换的LR方法对其进行编码,即基于多标记学习问题转换的思想,将多标记标签转换成单标记标签表示,对多标记事件进行编码。将构建好的事件演化图G中的事件定义为{e1,e2,…,en},其中n为事件数量。而对于G中同时发生的多个事件{e1,e2,…,em}的事件转换成一个融合事件ey。ey对应的向量表示vey的计算公式为:
vey=f(w1ve1+w2ve2+…+wmvem)
(2)
其中:{w2,w2,…,wm}为权重参数,即采用加权融合编码的方式对多标记事件进行编码。
以m=3为例来说明事件编码规律。3个事件定义为e1、e2、e3,按它们同时发生与否和同时发生的个数可以得出共有8种候选事件组合,对应的融合事件编码标记如表4所示。

表4 候选组合事件编码表Table 4 Candidate combination event code table
将事件演化图中头事件实体对应的多个同时发生的尾事件实体按式(2)获取组合向量表示,获得多标记尾事件实体向量,赋予头事件实体与多标记尾事件实体之间为顺承关系,更新关系权重,获得多标记事件融合编码后的事件演化图,作为门控图神经网络的输入。
2.3.2 门控图神经网络
门控图神经网络(GGNN)适用于对已知事件和候选事件之间的交互建模,因此采用它对多标记事件演化图进行训练获得多标记事件预测模型。如何在一个大规模事件知识图谱上训练GGNN模型,是模型的一个挑战。本文参照文献[30]的方法对图划分子图,以子图作为一条数据,从而能使GGNN用来训练大规模数据。
对于GGNN,它输入的对象为:事件的表示向量矩阵h(0)和图的邻接矩阵A,其中h(0)={ve1,ve2,…,ven,vec1,vec2,…,veck},其包含初始已知事件和后续候选事件向量,A∈(n+k)×(n+k)是对应子图的邻接矩阵。邻接矩阵A决定子图中的节点如何相互作用,其数值A[i,j]可以表示为:
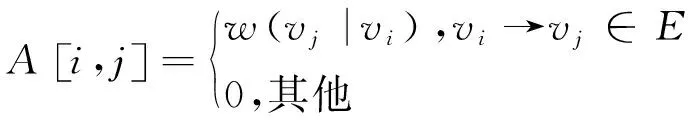
(3)
接下来将h(0)和A输入到GGNN中,GGNN的基本递归式为:
a(t)=ATh(t-1)+b
(4)
z(t)=σ(Wza(t)+Uzh(t-1))
(5)
r(t)=σ(Wra(t)+Urh(t-1))
(6)
c(t)=tanh (Wa(t)+U(r(t)⊙h(t-1)))
(7)
h(t)=(1-z(t))⊙h(t-1)+z(t)⊙c(t)
(8)
其中:式(4)是节点间传递信息;式(5)~ 式(8)类似于GRU的更新[31],每次都会更新节点的状态;σ为Logistic-Sigmoid函数;a(t)是来自边的激活;⊙是逻辑同或运算符;z(t)和r(t)分别为更新门和复位门,GGNN按一定固定的数量根据公式所述循环传播;输出h(t)作为已知事件和候选事件更新后的表示。
2.3.3 后续事件预测
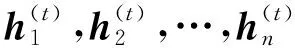
在模型中,打分函数g有多种选择,一般为相似度计算量,常见的打分函数有曼哈顿相似性、余弦相似性、点相似性以及欧几里得相似性。本文采用欧几里得相似性作为打分函数,即求两个向量的欧几里得距离,计算公式为:

(9)
另外使用注意力机制[32]来处理已知事件,因为不同的已知事件可能具有不同的权重来选择正确的后续事件。使用注意神经网络根据后续候选事件计算每个已知事件的相对重要性:
(10)
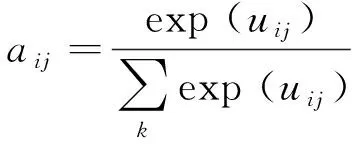
(11)
然后通过下式计算相关性得分:
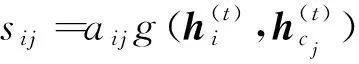
(12)
模型的正确输出代表输入中的组合事件向量是正确的。模型的输出向量是一种融合事件向量,通过解码可获得其真实的多事件集合。解码器的输入是后续组合事件表示向量vey,输出为多标记事件编码序列y,根据表4可反推出发生的事件组合。
2.4 模型训练
MLEP模型训练目标如式(13)所示,该模型使用边界损失函数作为目标函数。

(13)
其中:k是候选事件的数量;N是事件链的数量;y是正确后续事件的标签;sIj是第I个事件链与第j个后续的候选事件之间的得分;λ是L2正则项的惩罚因子;θ是模型参数的集合。
3 实验
3.1 数据集
本文所使用的数据集是由公开数据集PatientEG预处理而来的。PatientEG数据集[33]由华东理工大学和上海曙光医院联合构建,数据来源于191 598个真实病历记录,其中事件共有Diagnosis-Event、Hospitalization-Event、Drug-Event、Assay-Event和Surgery-Event 5种类型,事件之间按顺承关系排列,是较好的事件链数据源。数据集预处理具体过程为:首先对数据集中事件链进行清洗,保留只存在after和concurrent关系的事件,对于concurrent连接的多标记事件,采用重新编码的方式,以一个新的事件存入,按不同的事件链将数据存入文件中;然后对事件进行编码获取事件的向量表示,对于多标记事件,采用本文第2.3.1节的方式编码;最后基于获取的事件链构建事件演化图,构建方法参照本文第2.2节。
构建好事件演化图后,对其划分子图制作模型的每条数据,子图的集合即可作为MLEP模型的数据集。预处理后的数据集共包括108 701个样本,通过随机方法按6∶2∶2的比例将数据集分为训练集、测试集和验证集。表5为数据集的数据统计。

表5 数据集的数据统计Table 5 Data statistics of datasets 单位:个
3.2 实验设置
3.2.1 参数设置
在模型训练过程中,具体参数设置为:损失计算使用边界损失函数进行,λ是L2正则的惩罚因子,设为0.000 001;γ是边界值,设为0.015。超参数通过在验证集上的实验来调整,具体为:GGNN网络的层数设为2层,丢弃率为0.4,学习率设为0.000 1,初始词嵌入的向量维度设为128,在运行过程中使用早停训练方法和RMS优化算法。
3.2.2 对比模型
为了全面评估提出的MLEP模型,本文选用经典的基于统计的预测模型(如PMI Predictor和Bigram Predictor)、基于事件对的预测模型(如Word2Vec Predictor和EventComp Predictor)和基于事件链的预测模型(如PairLSTM和SAM-Net)作为对比模型。各模型具体介绍如下:
1)PMI Predictor[2]:通过计算互信息,对后续事件建立共现模型进行预测,是一种基于统计共现的事件预测方法。
2)Bigram Predictor[3]:以二元条件概率作为两事件相关性评分,是一种基于统计共现的事件预测方法。
3)Word2Vec Predictor[7]:依靠Skip-gram模型对事件进行映射,以余弦相似性作为两事件相关性评分,是一种基于事件对的事件预测方法。
4)EventComp Predictor[8]:利用Siamese网络学习事件的特征表示,再根据事件对之间的得分预测事件,是一种基于事件对的事件预测方法。
5)PairLSTM[9]:一种基于事件链的事件预测方法,该方法通过向双向LSTM输入事件初始表示向量,获得隐藏层状态,以此来表示事件,然后联合上下文序列信息以及事件对信息,计算出候选后续事件和事件上下文相关性评分。
6)SAM-Net[10]:一种基于事件链的事件预测方法,该方法主要利用注意力机制和LSTM来对事件链中的事件进行表示,其中LSTM是实现对事件链序列的建模,注意力机制实现对事件的表示,最后通过对两部分融合训练预测出后续事件。
3.3 实验结果与分析
本文利用准确率作为评价实验结果的好坏,各个模型在对应数据集上的结果如表6所示,对比如图3所示。
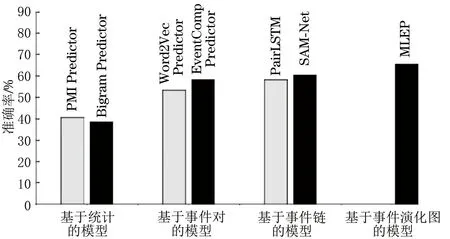
图3 不同模型的准确率对比Fig.3 Accuracy comparison of different models

表6 不同模型的准确率Table 6 Accuracy of different models %
根据表6和图3的实验结果得到如下结论:
1)本文提出的MLEP模型要优于基于统计的模型、基于事件对的模型和基于事件链的模型,可以表明MLEP模型可以实现对多标记事件的预测,且性能要优于其他基线模型。
2)基于统计的模型效果最差,因为该模型仅以事件出现的频率来计算相关性得分,如果出现训练中没有的事件则无法计算得分,所以具有很大的局限性。基于事件对的模型表现也不理想,因为模型只考虑相邻事件间的关系,而没有关注到非相邻事件可能存在的时序信息和其他复杂的关系。基于事件链的模型表现较好,因为其充分利用和学习了序列的时序信息,根据序列的特征来进行后续事件预测,但由于没有考虑各个事件之间的联系,没有利用事件之间的发展规律和演化模式,因此效果不如基于事件演化图的模型。
3)MLEP模型取得了较好的效果,证明了事件演化图能捕获事件之间的发展规律和演化模式,基于事件演化图的预测模式能充分学习到图中各事件之间的连接关系,其预测性能要优于基于统计、基于事件对和基于事件链的模式。
从时间复杂度来看:基于统计学的预测模型为O(p),p为事件的数量;基于事件对的预测模型为O(v),v为输入向量的维度;基于事件链的预测模型为O(4Th2+4Tnh),其中,n为输入特征维度,T为输入序列的长度,h为隐状态的维度,则4Th2表示输入门、遗忘门、输出门和候选记忆单元的计算,4Tnh表示输入输出门和记忆单元的计算;本文提出的基于事件演化图的MLEP模型为O(|e|×F×F′+(Tnd(T+d2+kd))),其中,F×F′为权重矩阵W的表示,|e|为图顶点数量。从对比结果可以发现,基于统计学的预测模型和基于事件对的预测模型属于轻量级的模型,时间复杂度较低,基于事件链的预测模型和本文的MLEP模型都属于深度学习模型,复杂度较高,可通过高算力设备来支持算法的运行。
3.4 消融实验
为验证MLEP模型中各模块的有效性,本文还进行了消融实验,分析事件表示模块对模型的作用。消融实验使用的模型介绍如表7所示。
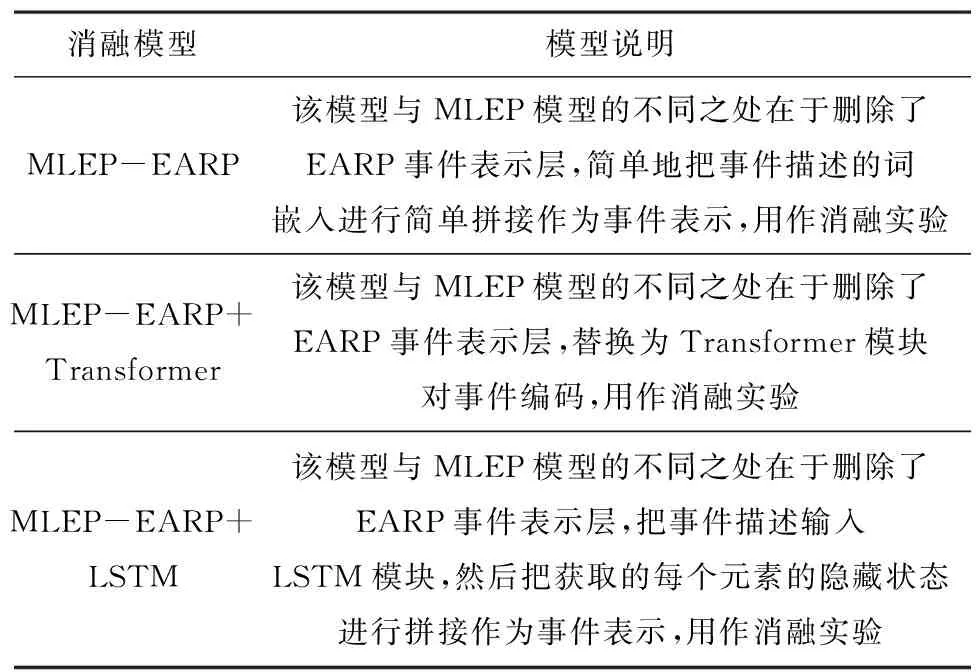
表7 消融实验模型介绍Table 7 Introduction of ablation experimental model
消融实验结果如图4所示,由图4可知:1)MLEP模型结果优于MLEP-EARP模型,准确率提高了6.65%,这表明EARP事件表示方法相比于简单地把事件描述词嵌入拼接表示事件效果要好,更好的事件表示可以提高事件预测的效率,也证明了EARP事件表示学习方法可以提高事件知识图谱表达能力和推理性能;2)MLEP模型结果优于两个消融模型MLEP-EARP+LSTM和MLEP-EARP+Transformer,这表明在MLEP模型中EARP事件表示学习层对事件的表示较于LSTM和Transformer有更好的效果,EARP模块提升了MLEP模型的性能,也证明了考虑更多的融合信息的表示学习方法可以更好地提高事件表示学习效果。
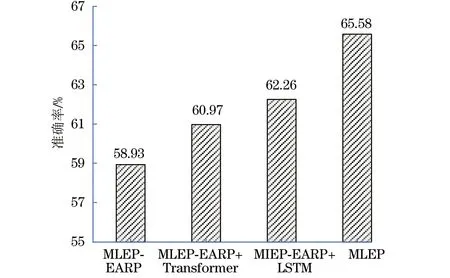
图4 消融实验结果Fig.4 Ablation experiment results
4 结束语
本文提出一种基于事件演化图的多标记事件预测模型(MLEP)。该模型以门控图神经网络为框架,并结合多标记学习中问题转换思想,将多标记问题转化为单标记问题,构建多标记事件预测模型,实现对多标记事件的预测。在真实数据集上的实验结果表明,MLEP模型可以有效地预测出多标记事件,且性能优于现有的主流模型,并通过消融实验证明了更好的事件表示学习方法对事件具有更好的表示效果,能较好地提升MLEP模型性能。本文通过事件演化的模式对多标记事件预测,能反映事件之间的动态发展和逻辑关系,使事件预测更具有可解释性。本文模型是在基于事件演化的模式下实现多标记事件预测,没有考虑事件链级别之间的联系,下一步将以融合信息更多的知识图谱或事件图谱为研究载体,以提升事件预测的准确率。
猜你喜欢
黄河之声(2022年10期)2022-09-27 13:59:46
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
中学生数理化·八年级物理人教版(2017年11期)2017-04-18 11:22:51
意林原创版(2016年10期)2016-11-25 10:28:30
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
Coco薇(2016年2期)2016-03-22 02:42:52
新高考·高二数学(2015年11期)2015-12-23 18:17:44
