
基于Carla仿真平台的YOLOv5多目标检测研究
2024-04-03 12:06:08尹誉翔
黑龙江科学 2024年6期
尹誉翔
(兰州交通大学交通运输学院,兰州 730070)
0 引言
随着自动驾驶技术[1]的快速发展,如何能够准确检测包括各类车辆、行人等在内的环境目标已成为自动驾驶系统面临的关键问题。实时性和检测准确率是衡量目标检测算法优劣的两大关键指标。作为当下主流的目标检测算法之一,YOLOv5通过多尺度特征融合[2]方法实现了检测速度快与检测精度高的良好平衡。模拟平台的出现为目标检测算法的开发与验证提供了新思路。如Carla模拟环境[3]可通过配置各类交通工具、行人模型等元素构建细致的交通场景,生成包含复杂目标的图像数据,为评估目标检测算法性能提供了可靠的平台支持。本研究构建了Carla模拟环境,通过配置各种静态和动态目标元素收集包含多类别车辆、行人及动物的视觉数据,采用主流的YOLOv5目标检测算法,训练模型对这些目标进行识别与定位,考察模型在模拟生成的复杂场景[4]中的泛化能力,通过增强模型训练的数据量和场景的多样性提高模型的鲁棒性。整个研究遵循严谨的实验设计方法,从多个角度全面考察YOLOv5在模拟平台上的检测性能,研究成果可为后续进行目标检测算法优化提供有价值的借鉴。未来的研究将更侧重于提高模型在复杂环境中的检测稳定性,将在仿真环境中获得的模型更好地迁移到实际的自动驾驶应用中。
1 研究框架
1.1 YOLOv5目标检测算法
YOLOv5是一种基于深度学习的单阶段目标检测算法,由Ultralytics Lab团队在2020年开源,对之前的YOLOv4版本[5]进行优化升级。YOLOv5最大的特点是端到端实现目标检测,无需生成候选框,直接在特征图上完成分类与框回归,从而实现检测速度快且准确率高的平衡。相比YOLOv4继续使用Darknet53作为特征提取骨干网络,YOLOv5采用了参数量更少、特征提取能力更强的CSPDarknet,有效减小了模型大小,提升了检测效率。在网络头部使用FPN(特征金字塔网络)模块进行多尺度特征的提取和融合,而YOLOv4中默认使用的是PANet结构,FPN增强了模型对各种尺度目标的适应性。在预测模块,YOLOv5沿用了YOLOv3中的设计思路,即在不同尺度的特征图上同时预测目标类别和位置信息。在训练过程中,YOLOv5使用各式数据增强技术[6],如CutMix、Mosaic等,增强了模型对场景和目标变化的鲁棒性。YOLOv5采用了兼具分类损失、置信度损失及框回归损失的复合损失函数,使模型收敛更加平稳。综合来看,YOLOv5在速度和准确度方面都超过了之前的版本,在公开数据集上的MAP指标可达45%左右,保持了实时检测的能力要求。由于其性能高效稳定,已得到了广泛应用,如在工业质检[7]及学术研究等领域。图1为YOLOv5的网络结构。

图1 YOLOv5的网络结构Fig.1 Network structure of YOLOv5
1.2 Carla模拟环境
Carla是一款开源自动驾驶仿真系统[8],用于自动驾驶算法的开发、训练及验证。Carla最大的特点是可以生成细致逼真的城市交通环境,场景中包含复杂的道路交通网络、各类建筑、丰富的天气效果及时间环境等因素,既具有真实感又可编程可控制虚拟环境。Carla提供了灵活开放的编程接口,允许用户通过Python或C++两种语言进行交互,如读取车载虚拟传感器数据及控制虚拟车辆运动等。Carla的主要功能是提供灵活的传感器配置选项,可模拟生成类似相机、激光雷达、IMU、GPS在内的多种传感器数据;支持丰富的环境效果,如时序的日夜光照变化、多种天气条件的模拟;包含复杂的交通流模块,可模拟车辆、行人和自行车的运动行为;开放式的地图自定义功能,用户可根据需要生成交通网络;智能Agent API基于强化学习方法使训练智能体成为可能。综上所述,Carla提供了一个功能全面且可定制的仿真环境生成平台,可大幅提升自动驾驶算法研究的效率。图2为Carla模拟环境概念图,通过Unreal Engine实现了逼真的3D场景渲染和复杂的交通流模拟,提供了开放的编程接口,使其成为自动驾驶算法研究的强大工具。

图2 Carla模拟环境概念图Fig.2 Concept map of Carla simulation environment
2 系统搭建与数据集
2.1 Carla环境搭建
Carla作为一个开源的自动驾驶仿真平台,提供了构建虚拟交通环境的工具和丰富的接口功能。为了在该平台上进行自动驾驶算法的开发与评估,需正确配置和搭建Carla的软硬件运行环境。图3为Carla的系统架构及各核心模块,包括运动规划、控制、感知等部分及连接环境和算法接口,支持开发闭环的自动驾驶仿真系统。具体的搭建流程为根据Carla发布的系统配置要求,在Window系统下安装指定版本的Python解释器、CUDA工具包、英伟达显卡驱动等相关软硬件。Carla对运行环境有较高要求,需严格参考指南选择合适的配置。从GitHub上克隆或下载Carla的最新源代码,获取包含城市资源和python接口的完整代码库。Carla作为开源项目在GitHub上进行维护更新。使用Makefile或CMake等方法编译Carla源代码。编译过程会自动下载城市地图资源并检查相关依赖库的可用性。在UnityEditor中打开编译好的Carla项目,运行并播放场景即可进入高保真的三维虚拟城市环境中。运行Carla提供的示例Python或C++脚本,验证Carla是否被正确安装和配置,所有的接口功能正常工作。通过配置质量水平、分辨率比例等参数以平衡视觉效果和仿真的运行流畅度。根据项目需要编写Python或C++代码,利用Carla提供的丰富接口连接感知模块、控制模块及评估工具等,构建闭环的仿真实验系统。
2.2 数据收集与标注
搭建好Carla仿真环境后,利用该平台生成用于模型训练和验证的数据集。需根据实验要求设计虚拟传感器,定义场景元素,通过控制API采集包含不同目标的图像数据。在Carla中配置虚拟摄像头采集数据的设置,可以看到摄像头的位置和角度拍摄到了场景中的多类目标,包括行人、车辆等元素。对采集的数据进行整理,使用标注工具完成目标的框选注释。这一部分详述了在Carla平台上收集和标注图像数据集的关键过程。基于Carla模拟环境收集图像数据集的一般流程如下:①定义场景与传感器配置。根据实验需求设定所需的场景元素,如车辆、行人、交通信号和道路条件等,配置所需的摄像头等虚拟传感器参数。②播放模拟场景生成数据。启动Carla服务器,加载定义好的场景,通过编程控制相机进行数据采集。这一过程可通过手动操作完成,也可编写自动化的脚本程序实现。③导出记录的原始数据。Carla支持图片或视频格式,批量导出虚拟传感器采集到的图像、点云等数据。需对这些原始数据进行整理,方便后续处理。④对导出的数据进行标注。采用标注软件手动标注感兴趣的目标,如行人、车辆等,生成含标注的图像数据集。⑤数据清洗与增强。删除错误数据,校验并修正标注框,采用旋转、扰动等操作对数据集进行增广。⑥划分训练集和测试集。按比例将增强后的最终数据集分为训练和测试用途。
3 实验环境
模型搭建和训练是基于Pytorch深度学习框架进行的。为实现高效的并行计算,调用了NVIDIA的GPU设备及CUDA并行计算架构。借助GPU强大的并行处理能力及CUDA和CuDNN等加速库的优化,模型训练速度显著提升。具体环境配置见表1。表1给出了主要软硬件信息,包括GPU型号、CUDA和CuDNN版本等。充分利用高性能的计算环境,有助于高效训练出性能优异的目标检测模型。

表1 实验运行环境
4 YOLOv5检测模型的构建与分析
4.1 网络训练
输入图像被 resize 到 640x640 像素,这个尺寸经过多项试验验证可在检测速度和效果之间取得最佳平衡。标注数据集按照通常的比例划分为 80% 训练数据和 20% 验证数据,前者可使模型获得充分学习,后者可评估模型泛化能力。考虑到检测任务的特点,模型选用随机梯度下降(SGD)算法进行优化,初始学习率为 0.01,采用分段常量衰减策略,即每 10 个epoch时降低10倍,以便模型快速接近局部最优解。作为优化目标的损失函数采用 YOLOv5 预定义的包含分类、置信度及边框回归三项的综合损失,全面兼顾各个性能指标。根据GPU的计算能力将训练时的批大小(batch size)设置为8或16,在充分利用并行资源的同时避免过大的计算开销。总的训练周期设置为100~300 个epoch,取决于具体的数据集规模,周期数越多模型效果越好,但需要平衡计算时间成本。应用随机裁剪、翻转等多种图像增强手段,进一步提高模型泛化性。
4.2 训练过程及结果分析
为评估构建的YOLOv5模型检测效果,使用单块RTX3050 GPU对模型进行训练,参考4.1设置超参数。训练过程分为3个阶段:①模型初始化阶段。随机初始化网络参数,配置SGD优化算法和分段衰减学习率策略,引导模型训练方向。②由于参数较为随机,损失函数值开始较高,在训练迭代过程中随着训练批数增加,模型参数持续更新优化,损失函数值明显下降。但可能遭遇梯度消失等难题,需调整优化策略以维持损失下降速度。③模型收敛阶段。损失函数值趋于平稳,训练可以终止。从表2可以看出,随着训练轮次的增加,YOLOv5模型在训练集和验证集上的损失均持续下降,在200轮后趋于稳定,验证集损失无明显变化,说明模型已收敛。测试了模型在验证集上的检测性能。YOLOv5在Carla数据集上最终取得了88%以上的mAP,达到了较优的检测效果。说明构建的模型可有效完成对Carla场景中的目标检测,后续工作将在更复杂场景中进一步评估模型的泛化能力。
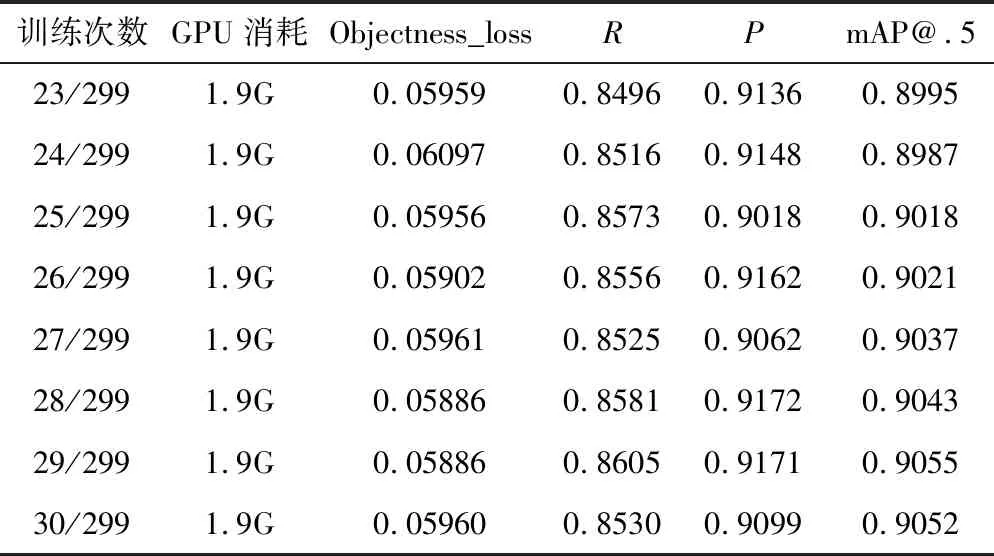
表2 算法结果
5 结论与展望
针对自动驾驶场景中的目标检测任务,探索了一种基于仿真的检测系统设计方案,在Carla平台构建仿真环境,采集多传感器数据样本。该平台可灵活配置场景,高效获取标注数据集,通过标注数据训练YOLOv5检测模型评估结果显示,基于仿真数据训练的模型可达到较优的检测性能,验证了仿真技术的有效性,为后续迁移学习应用奠定了基础。研究还提出并验证了从仿真场景构建到模型训练及评估端到端的检测系统设计流程,为仿真与实际需求的融合提供了范例。仿真与真实场景可能存在差异,需要多方面评估模型的泛化能力,继续增强仿真场景的多样性,提高模型的鲁棒性。未来可深入研究不同迁移学习技术,弥补仿真与现实的差距。探索目标检测领域中仿真技术的新应用为多源异构建模等方向奠定了基础,为集成仿真与实际应用需求提供范例,对自动驾驶领域具有启发意义。但该研究仍存在限制与可改进之处,如仅构建了有限的仿真场景,未来需继续丰富场景模式,提高仿真环境的逼真度。模型当前仅在仿真平台上评估,离实际应用还有一定差距,未来需在真实场景中部署模型,评估其检测性能,研究不同的迁移学习技术以弥补仿真与实际的鸿沟。当前研究侧重目标检测任务,未来可将更多视觉子任务如语义分割、运动预测等集成到系统中,构建端到端的视觉场景理解框架。
猜你喜欢
中老年保健(2021年12期)2021-08-24 03:30:40
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09 08:43:00
学生天地(2020年5期)2020-08-25 09:09:08
中国生殖健康(2020年6期)2020-02-01 06:28:50
中国生殖健康(2019年11期)2019-01-07 01:28:02
电子测试(2018年10期)2018-06-26 05:53:36
汽车博览(2016年9期)2016-10-18 13:05:41
高中生学习·高二版(2015年12期)2016-01-05 13:08:35
交通建设与管理(2015年15期)2015-03-20 15:19:15
中学英语之友·上(2008年2期)2008-04-01 01:19:30
