
复合多尺度注意熵在旋转机械多工况损伤识别中的应用*
2024-03-26 05:54卞其翀叶丹茜
机电工程 2024年3期
张 伟,卞其翀,叶丹茜
(1.山西师范大学 数学与计算机科学学院,山西 临汾 041004;2.长治职业技术学院 信息工程系,山西 长治 046000;3.福州外语外贸学院 经管学院,福建 福州 350200;4.台州科技职业学院 机电与模具工程学院,浙江 台州 318020)
0 引 言
旋转机械是各类工程设备中的应用较为广泛的一种机械装置。它通过部件的旋转来向外输出动力或者传递载荷。由于负载和转速经常发生变化,使得旋转机械易产生振动,发生突变,长期运行会造成设备发生故障。在旋转机械发生故障后,如何对其进行准确地识别是亟需解决的工程实际难点[1]。
由于摩擦、阻尼、冲击等非线性因素的影响,旋转机械振动信号呈现非线性和非平稳性[2]。近来年,基于信息熵概念,大量非线性损伤信号复杂度测量工具被开发出来,并应用于损伤识别中,如样本熵、多尺度熵、注意熵等[3]。姜保军等人[4]提出了样本熵,对齿轮箱振动信号进行了损伤特征分析,结果表明样本熵作为损伤特征指标是有效的;但样本熵只是提取了信号的单个尺度的特征,这些特征无法全面反映齿轮箱的损伤特性。为全面表征机械系统的复杂性,张龙等人[5]将多尺度熵指标应用于轴承的故障特征提取环节,有效提高了特征的质量,进行了轴承损伤的准确分辨;但该算法容易受到时间序列中突变点的影响。为提高分析精度,减小误差,代俊习等人[6]采用复合粗粒化方式对多尺度熵进行了改进,提出了复合多尺度熵(composite multi-scale sample entropy,CMSE),并将其用于提取滚动轴承的损伤特征,识别结果表明该指标可以有效诊断不同故障;但CMSE的特征提取时间长,效率不高。
针对CMSE存在的缺陷,董治麟等人[7]提出了复合多尺度排列熵(composite multi-scale permutation entropy,CMPE),将其用于提取滚动轴承的损伤特征,实验结果验证了该方法的优越性;但CMPE忽略了信号的幅值信息,降低了特征的质量。ZHENG Jin-de等人[8]提出了基于复合多尺度模糊熵(composite multi-scale fuzzy entropy,CMFE)的滚动轴承故障诊断方法,进行了滚动轴承故障的准确判断;但CMFE的分析效率比较低。为了提高分析效率并且确保足够的精度,郑近德等人[9]将复合多尺度散布熵(composite multi-scale dispersion entropy,CMDE)用于滚动轴承的故障诊断,完成了故障特征快速、有效地提取任务;但CMDE未考虑信号中的波动性。为此,GAN Xiong等人[10]提出了复合多尺度波动散布熵(composite multi-scale fluctuation dispersion entropy,CMFDE),进一步考虑信号的波动性对复杂度的贡献,更加充分地提取了滚动轴承的故障特征;但CMFDE进行分析前需要设置嵌入维数、类别数量、时间延迟3个固有参数,且3个参数对算法的性能有较大影响[11]。为此,YAN Xiao-an等人[12]采用粒子群算法对散布熵的嵌入维数、类别数量和时间延迟进行优化,并将参数优化后的散布熵用于提取滚动轴承的故障特征,准确识别了轴承的不同故障;但是参数优化涉及到大量的迭代运算,降低了计算效率。
针对传统熵值特征提取方法受参数影响较大的缺陷,YANG Jia-wei等人[13]提出了一种更加高效的测量时间序列动态特性的非线性动力学方法,称之为注意熵。与传统熵值方法关注于时间序列中所有样本点的频率分布不同,注意熵只关心时间序列各个峰值点间隔的频率分布状态。因此,注意熵完全基于数据自身驱动,具有参数设置少、分析效率高和对数据长度鲁棒性强等优点;但注意熵未开展信号的多尺度分析。随后,陈飞等人[14]提出了多尺度注意熵(multi-scale attention entropy,MATE),将其用于水电机组的故障诊断,取得了较好的故障识别结果;但MATE的粗粒化方式存在缺陷,忽略了大量有效信息。
针对上述缺陷,笔者采用复合粗粒化方式对注意熵进行改进,提出复合多尺度注意熵(CMATE),在实现信号多尺度分析的基础上进一步提高分析的精度;随后,结合随机森林(RF)分类模型,提出一种基于CMATE和RF的旋转机械损伤识别方法;采用千鹏齿轮箱故障数据集、东南大学旋转机械数据集和离心泵数据集构造多种工况的损伤样本,对该损伤识别方法的有效性进行实验和验证,并与其他多种方法进行对比。
1 算法理论
1.1 复合多尺度注意熵
多尺度注意熵(MATE)定义为不同时间尺度的注意熵,从不同的时间尺度来表征信号的动态特征,避免了单一尺度注意熵的缺点,其可以提取信号更深层次的模式信息。
MATE的理论可以描述如下:

(1)
式中:τ为尺度因子,为正整数;τ=1时,粗粒分量为原始信号;τ>1时,原始信号被粗粒处理后分割为多个长度为[N/τ]的粗粒化序列。
2)计算各尺度因子下粗粒分量的注意熵,则MATE定义为:
MATE(X,τ)=ATE(y(τ))
(2)
MATE避免了单一尺度注意熵测量信号复杂性时难以获得准确结论的缺点。然而在MATE的定义中,基于粗粒化方式进行的多尺度计算严重依赖于分析数据的长度,每个粗粒分量的长度等于原信号的长度除以尺度因子。因而熵值的误差会随着尺度因子的增加而逐渐变大,同样对于短信号的分析结果也不甚理想[15]。
以尺度因子τ为2为例,MATE粗粒化过程的示意图如图1所示。
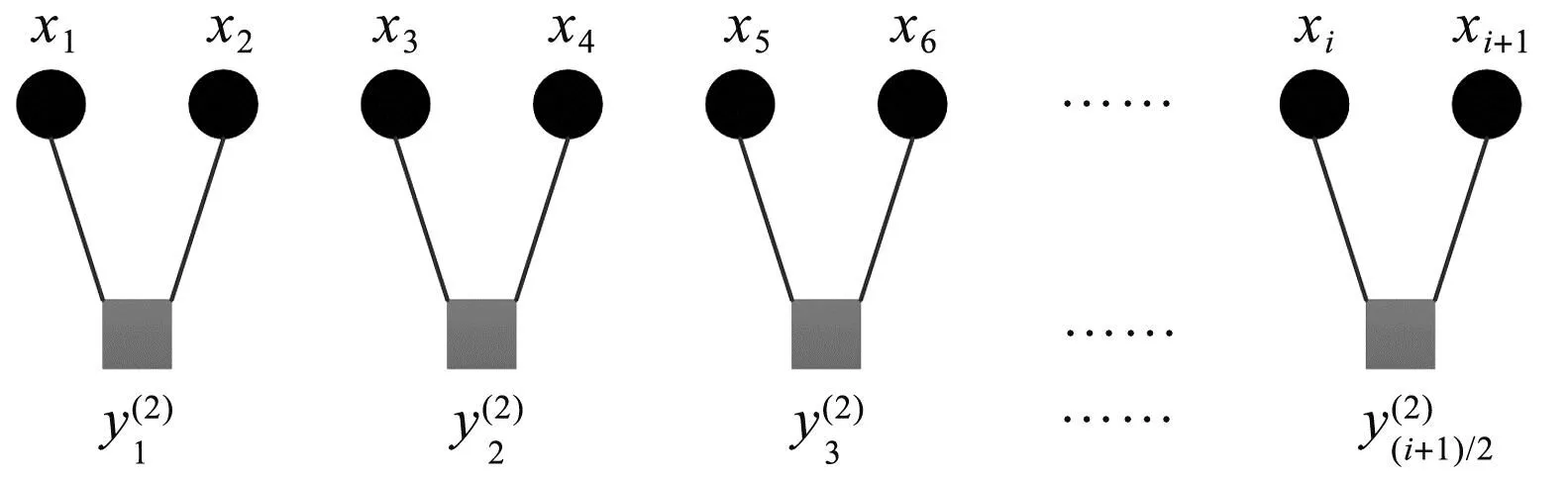
图1 尺度因子为2时的粗粒化
从图1可以发现:当尺度因子为2时,粗粒化处理后得到的序列依次序两两平均,只考量了x1和x2之间的相对关系,而未考量x2和x3之间的相对关系,这无疑会丢失部分有效信息,进而无法准确刻画时间序列的动态特性。
为了避免MATE的缺陷,笔者提出了复合多尺度注意熵(CMATE)方法进行代替。针对粗粒化过程中由于粗粒分量的长度逐渐变短而导致偏差增大的问题,采用相同尺度因子下的不同粗粒分量的注意熵的均值作为该尺度因子下的注意熵值。
CMATE的理论如下:

(3)

(4)
CMATE综合考量了同一尺度下全部粗粒分量的注意熵信息,相对性和独立性考量得更加全面,因此,其分析结果优于MATE。
以尺度因子为2为例,复合粗粒化过程如图2所示。

图2 尺度因子为2时的复合粗粒化
与MATE类似,CMATE表征了信号在不同尺度因子下的动态特性和不规则度。
若一个信号的熵值在大多数尺度上都比另外一个信号的熵值大,则可以给出前者比后者复杂的结论;反之,若一个信号的熵值随着尺度因子的增加而单调递减,则表明该序列的结构相对简单,在频谱上高频部分的信息量较少,只在较小的尺度上包含较多的模式信息。
1.2 CMATE与MATE对比分析
1.2.1 数据长度分析
CMATE由于其特殊的复杂度测量方式,仅需要设置数据长度N和尺度因子τ两个参数,尺度因子一般取τ≥20。笔者设置为τ=30,以充分提取信号的多尺度信息。数据长度对复杂度的测量结果具有一定的影响。但广泛的研究证明,若数据长度N≥1 024,则此时复杂度的测量结果几乎不受影响[16]。
为了验证CMATE和MATE两者对数据长度的敏感性,分别对不同长度的高斯白噪声(white Gaussian noise,WGN)和1/f噪声进行分析。
笔者分别采用CMATE和MATE对长度为N=1 024,2 048,4 096,6 144,8 192和10 240的WGN和1/f噪声进行分析,如图3所示。

图3 不同长度的WGN和1/f噪声的CMATE和MATE曲线
由图3可以发现:WGN和1/f噪声的CMATE相对比较稳定,不同数据长度的熵值波动较小,熵值曲线基本重合;而WGN和1/f噪声的MATE曲线随着尺度因子的增加而出现较大的波动,这表明随着尺度因子的增加,CMATE能够获得优于MATE的熵值测量结果。
其次,当数据长度N大于2 048时,两个信号不同数据长度的CMATE和MATE曲线基本没有明显的差异,这说明数据长度对算法的性能影响较小。
再者,WGN的MATE曲线随着尺度因子的增加而减小,这证明WGN所含有的模式信息较少,结构简单;而1/f噪声的CMATE曲线随着尺度因子的增加而逐渐趋于平稳,且在大多数尺度上1/f噪声的熵值大于WGN的熵值,证明1/f噪声含有的模式信息比WGN复杂。
1.2.2 算法稳定性分析
根据上面的分析,笔者选择N=2 048进行后续的分析计算。
为了进一步证明CMATE在测量信号复杂性时具有相对显著的稳定性,笔者对10组N=2 048的WGN和1/f噪声进行了变异系数计算,如图4所示。

图4 WGN和1/f噪声的CMATE和MATE的变异系数
由图4可以发现:除尺度因子1外,两种噪声的CMATE的变异系数均小于MATE的变异系数,而变异系数反映了数据的稳定性,因此CMATE在测量时间序列的复杂性方面具有显著的稳定性。
1.3 随机森林分类模型
随机森林是BREIMAN L[17]于2001年开发的一种分类识别模型,利用Bagging技术训练多个决策树集成得到随机森林。基于Bagging算法,RF同时引入了样本和特征两个方面随机属性选择。RF进行分类的思想是随机选择一些特征属性来构造一个决策树,不断重复这个过程来建立多个决策树,并根据决策树的投票结果来实现样本的分类目的[18]。
随机森林算法的实现原理归纳如下:
1)构造每棵决策树的训练样本。RF通过Bootstrap方法重采样,从初始训练样本中有放回无权重地抽出T个训练子集,每一个子集对应一个决策树。未被抽取的数据称为袋外数据,袋外数据用于评价分类模型的精度,且对异常样本有一定的抗干扰性能,进而能够避免RF中的决策树出现局部最优解,提高模型的精度;

3)特征α将节点分割为2个分支,接着从余下的特征中搜索分类结果最优的特征,最后决策树依据不纯度最小准则充分生长,且不做剪枝处理,直至决策树的属性生长至叶子节点或完全被使用;
4)通过构造的决策树集合对测试样本进行投票评价,分类的标签取决于所有决策树的综合分类结果。
2 基于CMATE和RF的旋转机械损伤识别
2.1 损伤识别流程
根据前面的分析,在取数据长度为N=2 048时,CMATE的分析效果优于MATE,具有相对较好的稳定性。为此,结合CMATE和RF分类器,笔者提出了一种旋转机械多工况的损伤识别模型。
该损伤识别模型的具体实施流程如下:
1)利用振动传感器采集旋转机械在不同转速、不同负载下多种损伤类型的振动信号,并分割成长度为N=2 048的多组样本;
2)利用CMATE提取振动信号的熵值,获得特征样本;
3)将特征样本输入至RF分类器,进行训练和分类,依据决策树的投票结果完成样本的损伤识别,
4)采用多种特征提取方法与其进行对比,验证该模型的优越性。
2.2 实验分析
2.2.1 旋转机械实验
旋转机械实验数据采集于DDS故障诊断实验平台,如图5所示。

图5 DDS故障诊断综合实验平台
该平台由驱动电机、两级行星齿轮箱、平行齿轮箱、磁粉制动器和控制系统组成[19]。振动传感器PCB 608A11布置在行星齿轮箱径向输入端,信号的采样频率为5 120 Hz。
实验模拟了行星齿轮箱在不同转速和负载下的9种情况,包括1种健康状态(healthy,HEA),4类滚动轴承故障:内圈故障(inner race fault,IRF)、外圈故障(outer race fault,ORF)、滚动体故障(ball fault,BF)和复合磨损故障(composite wearing fault,CWF),和4类齿轮故障:切齿故障(chipped tooth fault,CTF)、缺齿故障(missing tooth fault,MTF)、齿根裂纹故障(root chipped fault,RCF)和表面磨损故障(surface wearing fault,SWF),详细信息参考WANG Huan等人[20]的研究。
每种数据选择50组样本,每个样本的长度为2 048,随机选择25组样本作为训练样本,剩余25组样本作为测试样本。样本的波形如图6所示。

图6 旋转机械振动信号波形
首先,计算所有样本的CMATE值,如图7所示。
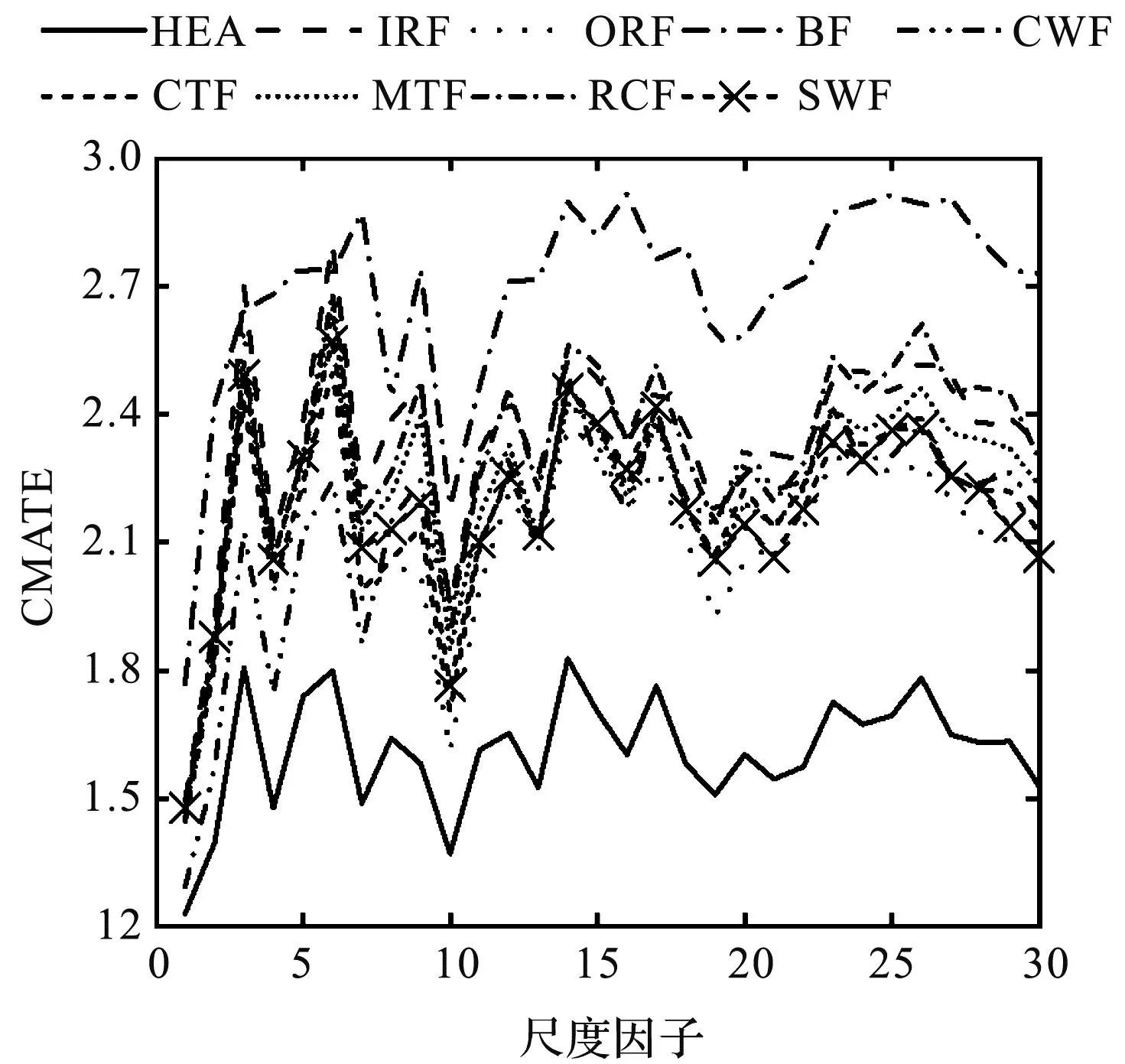
图7 旋转机械振动信号样本的CMATE曲线
由图7可以发现:不同样本的熵值曲线存在比较大的差异,特别是HEA和BF样本,HEA样本的熵值曲线在所有样本的下方,而BF样本在大部分尺度上都处于所有样本的上方,这表明HEA样本的复杂性较低,而BF样本的复杂性较高。这是因为,HEA样本是完全健康的,其振动信号中谐波分量少,信号比较规则,因此复杂性低;而滚动体故障时,滚动体沿着轴和自身旋转,谐波含量和幅值大,相应具有较大的复杂性。
因此,图7中的熵值曲线能够较好地反映不同样本故障类型的复杂性关系,具有较强的物理意义,可以作为表征旋转机械故障属性的指标。
笔者在采用CMATE提取完所有样本的故障特征后,利用RF分类器进行了故障的识别,如图8所示。
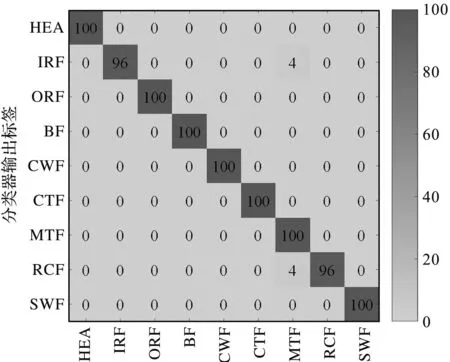
图8 CMATE-RF模型的混淆矩阵
由图8可以发现:该方法在进行故障识别时仅出现了2个被错误分类的样本,分别是IRF和RCF样本,其他样本都被完全准确地识别出来,总的分类准确率达到了99.11%,这表明了该模型可以有效地用于多工况的旋转机械损伤识别,能够同时识别齿轮箱和滚动轴承的不同损伤。
随后,为验证CMATE方法的优越性,笔者从准确率和特征提取效率两个方面进行考虑,分别采用精细复合多尺度熵(refined composite multi-scale sample entropy,RCMSE)、复合多尺度模糊熵(refined com-posite multi-scale fuzzy entropy,RCMFE)、精细复合多尺度排列熵(refined composite multi-scale permutation entropy,RCMPE)、精细复合多尺度散布熵(refined composite multi-scale dispersion entropy,RCMDE)、精细复合多尺度波动散布熵(refined composite multi-scale fluctuation dispersion entropy,RCMFDE)和多尺度注意熵(MATE)进行故障特征提取,并通过RF进行故障识别。其中的尺度因子设置为τ=30,时间延迟t=1。
不同方法的参数设置如表1所示。

表1 对比方法的参数设置
为了综合评估上述不同方法的特征提取性能,笔者统计了单次分类最高准确率、10次分类的平均准确率以及方差、特征提取时间,结果如表2所示。
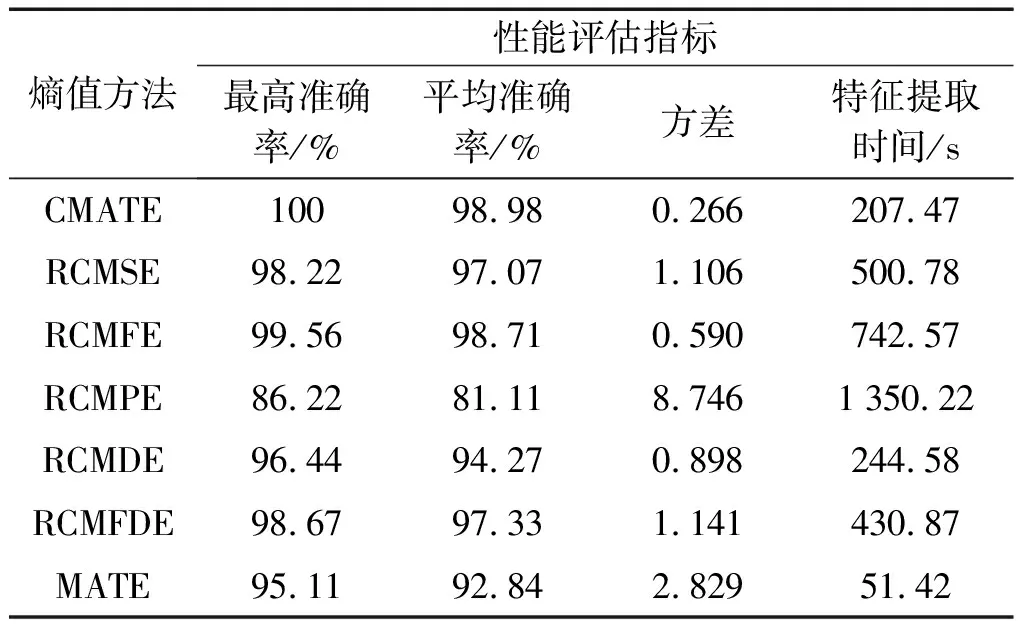
表2 各方法的特征提取性能对比
由表2可以发现:除了特征提取时间高于MATE方法外,CMATE方法其他各个指标都优于另外5种方法,这证明了以该指标进行故障特征提取的优越性。
随后,为了进一步验证CMATE方法在小样本识别中的有效性,笔者将上述方法得到的前30个特征依次输入RF分类器中进行故障识别,结果如图9所示。
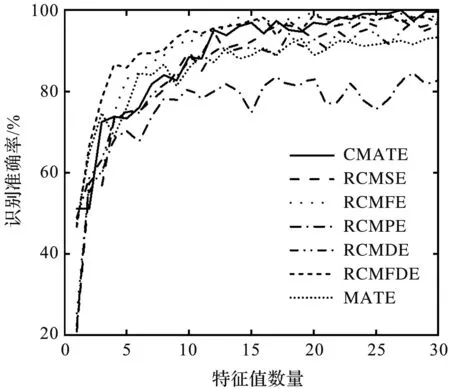
图9 基于不同数量特征的识别准确率对比
由图9可以发现:随着特征数量的增加,每种方法的准确率都有明显的提高,但当特征数量超过20个以后,准确率没有明显的增加,存在明显波动。这主要是因为特征数量越多,冗余的特征也越多,这样不仅对分类的贡献较小,而且可能降低分类的精度。而CMATE方法在特征数量为27时则达到了100%的分类精度,其他方法均未得到100%的分类准确率,且CMATE的效率非常高。
综合来看该方法适用于小样本的快速识别。
最后,为了验证CMATE方法的抗噪性,笔者选择表2中平均准确率最高的5种方法对不同信噪比的信号进行分析。通过向振动信号中加入0 dB、1 dB、2 dB和3 dB 4种不同信噪比的噪声来模拟实际环境下噪声对特征提取的影响。
不同信噪比下的损伤识别结果如表3所示。
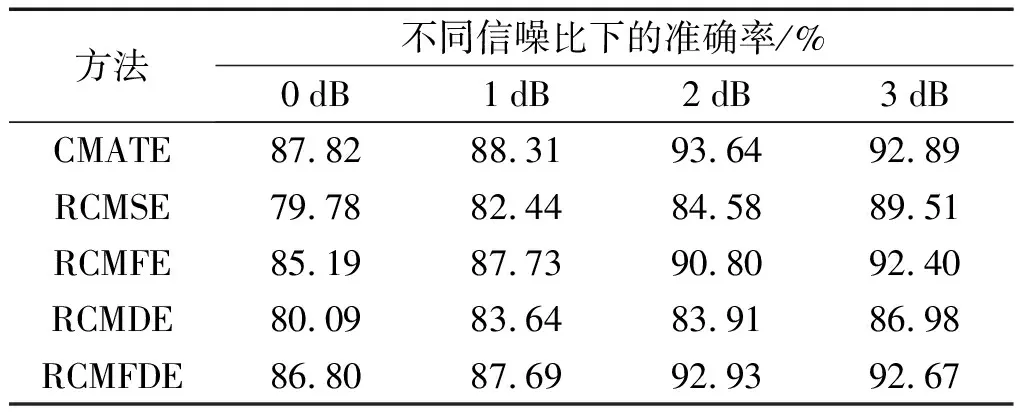
表3 不同信噪比下的损伤识别结果
由表3可以发现:在信噪比为0 dB和2 dB时,CMATE方法的准确率明显高于其他4种方法,这证明了该方法的特征提取性能优异。当信噪比为0 dB时,CMATE方法的准确率也达到了85%以上,而当信噪比为2 dB时,准确率达到了93%以上,证明该方法具有较好的噪声鲁棒性。总之,CMATE方法在特征提取性能和噪声鲁棒性方面优于其他4种方法。
为了进一步验证CMATE方法在小样本识别中的有效性,笔者对不同训练样本下该方法的诊断表现进行实验。
对于实际状态下的故障识别问题,通常缺乏训练样本,训练样本的数量通常比较少,因此,笔者考虑将每个状态的训练样本的数量减小为5、10、15和20。
不同训练样本下7种方法的识别准确率如表4所示。
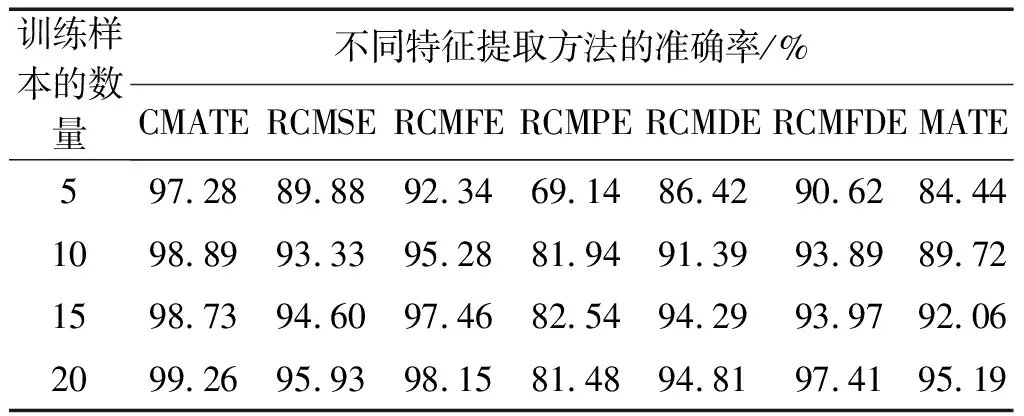
表4 不同训练样本数量下的准确率
从表4可以发现:在不同数量的训练样本下,CMATE方法的准确率都高于其他6种方法。同时随着训练样本数量的增加,识别准确率也随之增加,这是因为增加训练样本的数量能够更好地训练分类模型,使得模型的泛化性更好。
总之,根据实验结果,CMATE方法适用于小样本的分类识别问题,且优于其他方法。
2.2.2 齿轮箱实验
笔者使用QPZZ-II机械故障模拟实验平台模拟4种不同转速—负载电流工况下的5种行星齿轮箱故障。
行星齿轮箱故障实验平台如图10所示[21]。

图10 齿轮箱损伤模拟装置
齿轮箱的状态包括:大齿轮断齿故障(tooth breaking fault,TF)、大齿轮点蚀故障(pitting fault,PF)、小齿轮磨损故障(wearing fault,WF)、大齿轮点蚀与小齿轮磨损复合故障(PWF)和正常状态(HEA),采样频率为5.12 kHz,每种状态的数据共收集了53 248个样本点,数据采集的转速为1 500 r/min和880 r/min。
为了评估CMATE方法能够用于不同工况下的损伤识别,在转速为880 r/min时,利用磁粉扭力器调整3种负载电流,分别是0.05 A,0.10 A和0.20 A。因此2种不同的转速共构造了4种负载数据。
实验样本的详细信息如表5所示。

表5 实验样本的详细信息
转速为1 500 r/min下5种工况样本数据的振动信号波形如图11所示。

图11 不同状态下的振动信号波形
因为振动信号所包含的样本点较少,为了最大化利用数据,笔者采用滑动采样的方式进行样本的构造。其中,滑动窗口的大小为N=2 048,步长为s=1 024,每种状态的样本构造50个。
笔者计算4种工况的每个振动信号样本的CMATE,如图12所示。

图12 齿轮箱振动信号样本的CMATE曲线
由图12可以发现:不同样本的熵值曲线具有比较好的区分度,总体上具有相似的趋势,证明CMATE能够很好地区分不同负载转速下的损伤,具有强大的特征提取能力。
随后,笔者将CMATE损伤特征输入至RF分类器进行训练和识别。
测试样本的识别结果如图13所示。

图13 CMATE-RF的分类结果
由图13可以发现:CMATE-RF损伤识别方法的损伤识别准确率为99.80%,仅有1个样本被错误地识别了,这再一次证明了CMATE具有强大的特征提取性能,能够从多个工况的齿轮箱振动信号中提取出高质量的故障特征。同时CMATE-RF分类模型能够准确地识别齿轮箱的故障类型和不同负载,具有极强的应用潜力。
随后,笔者利用6种方法进行对比,将其用于提取齿轮箱振动信号的故障特征,并进行RF分类识别。各方法的特征提取性能结果如表6所示。

表6 各方法的特征提取性能对比
由表6可以发现:在最高准确率方面,RCMSE、RCMFE和RCMFDE方法均为100%,而CMATE方法为99.40%,虽然CMATE低于这3种方法,但依然具有很强的性能;在平均准确率方面,RCMFE最高,达到了99.64%,其次是RCMFDE方法,为99.60%,接着是CMATE方法,为98.92%。
同样,CMATE方法的方差也仅略微大于RCMFE和RCMFDE方法,这表明3种方法都能够稳定地识别齿轮箱的多工况损伤;在特征提取时间方面,MATE方法的效率最高,仅需要43.97 s即可以完成20种工况的特征提取,但其准确率仅为81.48%;而CMATE方法的特征提取时间为552.78 s,小于除MATE的其他5种方法。
因此,CMATE方法具有非常高的效率,更适合于实际应用问题。
随后,为了进一步验证CMATE方法在小样本识别中的有效性,笔者将上述方法得到的前30个特征依次输入RF分类器中进行故障识别,结果如图14所示。

图14 基于不同数量特征的识别准确率对比
由图14可以发现:除了RCMPE、RCMDE和MATE方法外,其他4种方法在特征值数量达到20个以后,识别准确率均能够达到非常高的数值,证明4种方法均可以有效地用于齿轮箱的故障识别。
最后,为了验证CMATE-RF方法的抗噪性,笔者在振动信号中加入0 dB、1 dB、2 dB和3 dB 4种不同信噪比的噪声,以此来模拟实际环境下噪声对特征提取的影响。
不同信噪比下的CMATE-RF损伤识别结果如表7所示。

表7 不同信噪比下的CMATE-RF损伤识别结果
由表7可以发现:随着工况的增加,CMATE-RF方法对噪声的鲁棒性有所降低,但当信噪比达到2 dB时,该方法的准确率依然能够达到82.08%的平均准确率。在实际应用中,可以减少单次识别的工况,以增加识别效率和精度。
为进一步考察CMATE方法在小样本识别中的有效性,笔者将不同数量的训练样本输入至RF分类器中进行故障识别。
不同数量训练样本的识别结果如表8所示。
由表8可以发现:在输入不同数量的训练样本时,CMATE方法均能取得不错的故障识别结果,证明CMATE方法适用于小样本的分类问题。RCMFE方法也取得了不错的故障识别结果,准确率在97%以上,但该方法的特征提取时间较长,不适合实时故障诊断。
2.2.3 离心泵实验
为了进一步验证CMATE-RF故障诊断方法的通用性,笔者利用离心泵实验平台进行实验。
实验平台如图15所示。

图15 离心泵实验平台
离心泵的转速为4 380 r/min,电源的电压为230 V,电动机的功率为373 W,离心泵的流量为1.61 L/s。离心泵中叶轮的直径为118.88 mm,由3个叶片组成。
实验平台中包含2个滚动轴承,靠近叶轮端的轴承为试验轴承,其参数如表9所示。

表9 试验轴承的参数
笔者采集了离心泵健康(normal,Nor)、离心泵叶轮破损(borken,Bor)、离心泵叶轮堵塞(blockage,Blo)、离心泵轴承内圈破损(inner race fault,IF)、离心泵轴承外圈破损(outer race fault,OF)时的振动信号和声音信号,采集频率为70 000 Hz。
不同损伤部件如图16所示。

图16 离心泵的损伤部件
为了进一步突出CMATE-RF方法的有效性,笔者采用声音信号进行特征提取。通常振动信号与零部件的故障相关性较强,由于声辐射的衰减而导致声音信号中的故障信息出现了损失,因此声音信号的信噪比通常比较小。
笔者通过长度为2 048的窗口截取声音信号样本,每种状态的样本构造50组,其中25组进行训练,25组进行测试。
笔者利用CMATE提取离心泵声音信号的故障特征,并将故障特征输入至RF分类器进行故障识别,结果如图17所示。

图17 CMATE-RF模型的混淆矩阵
从图17可以发现:CMATE-RF方法的准确率为100%,证明了该方法可以有效识别离心泵的故障类型。
随后,为了验证CMATE方法的优越性,笔者利用6种方法进行对比,将其用于提取齿轮箱振动信号的故障特征,并进行RF分类识别,结果如表10所示。

表10 各方法的特征提取性能对比
由表10可发现:CMATE方法的平均识别准确率最高,为99.12%,高于其他方法,这证明了CMATE方法在特征提取过程中的有效性。CMATE方法的特征提取时间仅为107.49 s,小于除MATE方法外的其他方法,这证明了CMATE在特征提取过程中的高效。CMATE的准确率方差为0.78,仅大于RCMDE方法,而小于其他方法,证明了CMATE具有极好的稳定性,能够稳定地识别故障。
随后,为了进一步验证CMATE方法在小样本识别中的有效性,笔者将上述方法得到的前30个特征依次输入RF分类器中进行故障识别,结果如图18所示。

图18 基于不同数量特征的识别准确率对比
从图18可以发现:在特征数量达到3个以上时,CMATE的识别准确率高于其他方法,且达到了90%以上,这证明CMATE仅需要较少的特征即可以准确地诊断离心泵的故障。
最后,为了验证CMATE方法的抗噪性,笔者向声音信号中添加不同强度的噪声,并进行CMATE特征提取。
不同信噪比下该方法的诊断结果如表11所示。

表11 不同信噪比下的CMATE-RF损伤识别结果
从表11以发现:随着信号信噪比的增加,识别准确率也随之增加,这与理论相符。当信噪比达到1 dB时,CMATE方法的识别准确率达到了83.2%,证明了CMATE具有比较强的噪声鲁棒性。
最后,笔者对不同数量的训练样本下的故障识别问题进行了研究,结果如表12所示。
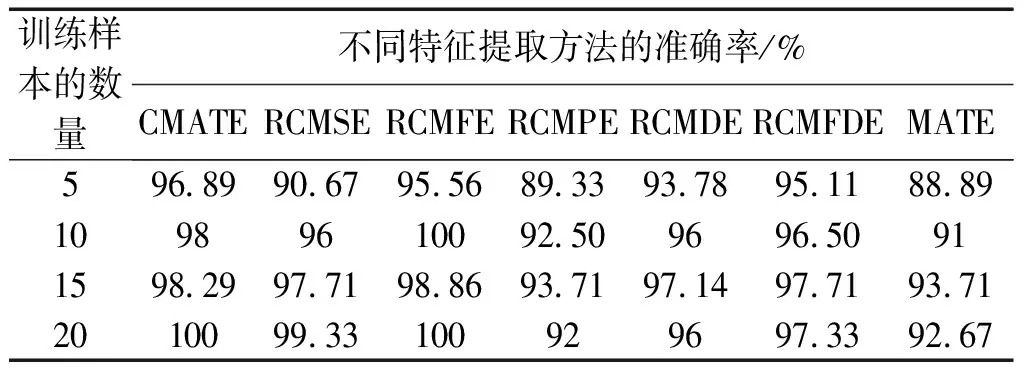
表12 不同训练样本数量下的准确率
由表12可知:CMATE方法输入在不同数量的训练样本时,均能取得不错的识别结果,证明了该方法具有较为良好的性能;RCMFE方法的性能也较好,但特征提取时间较长,综合性能弱于CMATE方法。
3 结束语
针对旋转机械的故障识别精度低和抗噪性不佳的问题,笔者提出了一种基于复合多尺度注意熵和随机森林的故障识别方法,并利用3种旋转机械数据集进行了实验分析和研究。
研究结论如下:
1)白噪和1/f噪声的仿真分析结果表明,CMATE对数据长度的敏感性较MATE弱,熵值的波动性小,变异系数的结果验证了CMATE在稳定性方面优于MATE;
2)在特征提取效率和识别准确率方面,基于CMATE和RF的旋转机械故障识别方法优于其他对比方法,更适合于小样本的故障识别;
3)CMATE-RF方法的噪声鲁棒性较强,在信噪比为2 dB时,识别准确率分别达到了93%、82%和83.2%以上,具有一定的应用潜力。
虽然该方法取得了不错的故障识别结果,但特征的数量较多,降低了特征提取效率。因此,在后续的研究工作中,笔者将对特征的数量进行优化。
猜你喜欢
山东冶金(2022年3期)2022-07-19
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
电子制作(2018年19期)2018-11-14
制造技术与机床(2017年4期)2017-06-22
自动化学报(2017年11期)2017-04-04
太空探索(2016年5期)2016-07-12
风能(2016年12期)2016-02-25
噪声与振动控制(2015年4期)2015-01-01
时代英语·高三(2014年5期)2014-08-26
振动、测试与诊断(2014年4期)2014-03-01
