
基于规则生成医案及Transformer算法构建中医方药推荐模型❋
2024-03-26 13:50练志润张家蔚杨保林
中国中医基础医学杂志 2024年3期
练志润,张家蔚,杨保林△
(1.广东省中西医结合医院,广东佛山 528200;2.北京中医药大学东直门医院,北京 100007)
中医辨证论治是一个复杂的思维过程,临床信息与中药处方之间存在复杂的映射关系。当前计算机模拟中医辨证主要通过基于规则的专家系统、数理统计、机器学习、深度学习等方法实现,然而上述方法皆存在一定局限性。例如专家系统虽逻辑清晰、具有可解释性,但难以处理规则过多、推理链过长导致的矛盾推理及循环推理的问题,且人类难以准确地穷举所有相关规则;数理统计拟合能力不足,难以有效模拟中医辨证非线性复杂映射关系;机器学习、深度学习虽具有较强的拟合能力,但依赖大样本数据,且深度学习亦存在可解释性不足的问题[1-3]。
由于方药推荐系统涉及医疗领域,对模型的准确率、可解释性要求高,同时规范、全面且经过疗效评定的临床数据集获取难度大,以单一模式进行建模难以满足需求,因此有学者建议尝试“经验模型+机器学习”模式,即将中医知识、中医经验以规则的形式表达,同时结合机器学习进行建模[3-5],使模型兼具强拟合能力、高准确性、可解释性,减少大数据依赖。基于此,笔者提出一种可利用人类中医知识、经验的深度学习模型来实现中医方药推荐模型的构建。
1 方法
本模型分为规则生成医案模型及Transformer模型两部分。大体思路为根据特定的规则生成医案数据(包括方证及方药等)代替真实世界的医案数据,联合基于编码器-解码器架构的深度学习模型Transformer实现模拟方证到方药之间的非线性复杂映射[6]。模型工作流程如图1。为了方便讨论,本文将称该模型为“望庐模型”,取自“横看成岭侧成峰”的一体多象的哲学体会。源码请参考: https://github.com/TioRean/TCMmodel。

图1 望庐模型工作流程图
1.1 实验数据
本研究使用《伤寒论》中的方剂进行模型测评,纳入方剂包括:桂枝汤、桂枝加葛根汤、桂枝加附子汤、桂枝加厚朴杏子汤、桂枝新加汤、桂枝加附子汤、桂枝甘草汤、葛根汤、葛根加半夏汤、麻黄汤、大青龙汤、小青龙汤、麻杏石甘汤、柴胡桂枝汤、小柴胡汤、柴胡加龙骨牡蛎汤、柴胡加芒硝汤、大柴胡汤、柴胡桂枝干姜汤、调胃承气汤、小承气汤、大承气汤、白虎加人参汤、甘草附子汤、去桂加白术汤、桂枝附子汤、附子汤、四逆汤、真武汤、苓桂术甘汤;小柴胡汤、小青龙汤、真武汤的加减法亦纳入其中。根据《伤寒论》原文、上海科学技术出版社的《伤寒论讲义》、科学出版社的《方剂学》,同时参考历代伤寒医家的注解及医案,将上述方剂的适应证改写成特定格式的方证规则共105条,录入格式参考表1。

表1 中医方证规则录入表(部分)
1.2 规则生成医案模型
1.2.1 规则生成医案模型的构建背景 在本模型中,方证规则是指由包括中医文献、临床经验总结、临床研究等临床资料归纳而来的方药适应证条目。相比临床中相互独立的医案数据,规则可更完整地拟合人脑的中医模型。规则含有庞大的信息量,以桂枝汤为例,《伤寒论》条文所拟定的规则为“头痛,发热,汗出,恶风,桂枝汤主之”,在该规则的指导下桂枝汤可运用于多种情况,见表2。假设构成某方证的规则存在n个元素,若不考虑元素间的不合理组合,该规则在现实中可存在2n-1种对应的可能。实际临床中若想高质量收集如此庞大的数据存在困难度大、成本高的问题,且很可能因数据收集不完整导致模型过拟合。因此笔者结合中医方证固有的规律,构建模型实现规则生成医案数据代替真实世界的临床数据用以方药推荐模型训练。

表2 桂枝汤适应证枚举表
1.2.2 规则生成医案模型的规则组成要素
规则生成医案模型中的规则由必选元素库(源码中称compulsory)、备选元素库(源码中称optional)、舌脉元素库、中药元素库组成。其中必选元素库中的所有元素必然存在于每一个生成的医案中;备选元素库中的元素或存在或不存在于某一个特定的医案中,备选元素库有多个(本模型中预设为8个)。必选元素库中的元素代表着某方证成立的必要条件;某一个备选元素库中的所有元素往往存在某种共同属性(方证、病机等),而多个备选元素库便于表达多病机的复杂中医方证规则。舌脉元素库包含舌象、脉象两部分,舌象包括舌质、苔厚度、苔色、苔湿润度、苔质共5个维度的内容,脉象包括脉率、脉律、脉位、脉体、脉力、脉流利度、脉紧张度共8个维度的内容。中药元素库代表在该条规则下所生成的所有医案对应的单个中药处方。具体规则录入格式参见表1。
1.2.3 规则生成医案模型的运作流程
医案数据生成过程中共有三级组合:第一级组合中,备选元素库进行库内元素组合(combination,特指数学概念中的“组合”);第二级组合中,不同的备选元素库按笛卡尔积(Cartesian product)的形式进行库间组合,舌脉元素库不同维度间亦进行笛卡尔积式组合;第三级组合中,经组合的备选元素分别与必选元素、舌脉元素、中药元素进行拼接(源码中称montage)组成多个完整的中医医案,拼接方式有笛卡尔积和一一对应组合(源码中称overlap)两种,见图2。
1.2.4 规则生成医案模型的细节解释
1.2.4.1 附属元素的表达 临床医案中存在拥有附属关系的元素,例如“头胀痛”“头刺痛”“头搏动样疼痛”皆附属于“头痛”,笔者将附属关系中的子元素称为附属元素(源码中称accessory),这些附属元素对中医辨证论治有时起到重要作用。为了在模型中表达出附属关系,规定若某个拥有附属关系的子元素一旦出现,其父元素必然出现,否则所生成的该条医案将被删除。
1.2.4.2 药物元素的剂量数据存储 为了使模型拥有表现药物剂量的能力,本模型的每个药物元素同时具有名称及剂量两种属性,代表着一个单位剂量的某种药物,每味药单位剂量所对应的数值可人为设定;若某个规则中需要多个单位剂量的某味药物,可同时用“药物”“药物+”“药物++”的形式表示。
1.2.4.3 药物元素的位置顺序问题 Transformer模型在解码过程中是参考前面已有的预测结果来预测后面的序列[6]。考虑到中医存在“君臣佐使”的中药配伍理论,君药对辨证论治全局具有决定性意义[7],而佐使药不具有该特征,为了让模型在方证-方药的映射过程中尽可能抓住关键信息,在规则书写时建议将药物元素按重要程度依次排序。为了增强模型对特定方剂的识别能力,建议将方剂中的药物元素按固定顺序排列。
1.3 Transformer模型
1.3.1 Transformer模型架构简介 Transformer采用了编码器-解码器结构[8],由N个编码器及N个解码器组成,见图3。每个编码器都包含多头自注意力模块、前馈神经网络模块,每个解码器都包含多头自注意力模块、多头注意力模块、前馈神经网络模块,编码器及解码器的所有子模块都进行残差连接[9]及归一化[10]操作。输入序列及目标序列都会经过嵌入层(Embedding)映射为计算机可训练的低维稠密向量,然后经过位置编码层(Positional Encoding)使模型识别序列顺序[11]。输出部分,使用线性变换及softmax将解码器的输出转为预测未来输出序列符号(token)的概率向量。望庐模型基本沿用了Transformer的结构,仅针对中医辨证论治的特点进行微调。
(1)

图4 注意力公式示意图
(2)
(3)
(4)
1.3.3 自注意力机制 自注意力机制是注意力机制的特殊形式。在自注意力公式中,Q、K、V来自共同序列X,X通过可训练权重WQ、WK、WV分别映射为Q、K、V,此后的计算过程与注意力公式一致。自注意力机制可分别单独对输入序列或目标序列进行内部元素关系的特征提取[6,13]。在望庐模型中,编码器通过自注意力机制实现了方证内部的信息特征抽取;解码器通过自注意力机制实现了方药内部的信息特征抽取,然后通过注意力机制得到方证特征与方药特征间的联系完成映射。
1.3.4 规则生成医案数据背景下自注意力机制的特殊性
1.3.4.1 词属性及词向量人为可控 自注意力机制原本用于自然语言处理,通过计算句子中单词与其上下文间的联系(相似度)来捕获单词之间的语义特征,单词语义以词向量的形式表达,相似的词语拥有相近的词向量[13-15],无法人为设定。与自然语言处理不同的是,规则生成的医案数据来源于元素规律组合,同个规则下的元素之间必然拥有彼此相似的上下文,见表1、图2,因而会获得彼此相似的词向量。规则制定时需将指向共同属性(方证、病机等)的诸多元素写在同一个规则之下,故具有共同属性的元素最终可获得相似的词向量,见图5、图6。这些赋予给元素的属性在拟定规则时人为可控,故获取的词向量亦可部分人为控制,增加了模型的可解释性及准确性。

图5 词向量三维主成分分析图(与恶寒距离最近的元素)

图6 词向量三维主成分分析图(与口苦距离最近的元素)
1.3.4.2 自注意力机制可模拟中医辨证的过程 自注意力机制对方证内部信息进行特征抽取时,由注意力公式(1)(2)可知,具有相同属性的元素间由于彼此具有相似的词向量,故相似度高,可获得更高的注意力分数及权重。以小柴胡汤证为例,方证中“往来寒热”“胸胁苦满”“口苦”“目眩”等元素会彼此给予更多的注意力,而对于与小柴胡汤证关系较远的元素,上述方证会给予较少的注意力。自注意力机制实际上是对具有共同属性(方证、病机)的元素进行提取归纳,故可模拟方证识别、病机归纳的过程。自注意力机制对方药内部信息进行特征抽取时同理,实际上完成了对方药内部结构的认识。
2 结果
通过规则生成医案模型产生不重复的医案共1 212 795例,随机选择5 000例作为测试集,剩余的90%作为训练集,10%作为验证集。在拥有5 000例医案的测试集中,预测方药与目标方药(即定义规则时人为给定的正确方药)完全相同的医案有4 983例,不完全相同的医案共17例,见表3。按总准确率=预测方药与目标方药重合的总个数/目标方药的总个数计算,总准确率为99.90%。在预测方药与目标方药不完全相同的医案中,模型将葛根汤预测为麻黄汤,将真武汤预测为真武汤去白芍加干姜,将小青龙汤预测为小青龙汤去麻黄加杏仁,上述两者互换的情况亦存在。

表3 模型测试集预测结果(部分)
3 讨论
3.1 模型对方证、病机的识别能力
根据实验结果可知,望庐模型成功鉴别了桂枝类方、麻黄类方、柴胡类方、大黄类方、石膏类方、附子类方、苓桂类方,上述类方分别对应营卫不和、风寒袭表、少阳郁热、阳明腑实、阳明郁热、元阳虚损、水饮内停的中医病机。即使预测方药与规则指定的方药不同,预测方药亦符合中医理论及方证对应原则。以上说明望庐模型可模拟预设的中医方证规则,具备方证识别及病机区分能力。模型成功识别了具有复杂病机的柴胡桂枝干姜汤证、柴胡加龙骨牡蛎汤证,正确使用了小青龙汤、小柴胡汤诸多加减法,说明模型可掌握多病机复杂疾病的辨证论治。另一方面,理论及实践层面皆表明,望庐模型不存在以往基于规则推理的中医专家系统的矛盾推理、循环推理问题。
3.2 模型对方剂的组织能力
由实验结果可知,模型预测结果都是在一定规则约束下的合理方剂,方药组成皆为人类所能识别,暂未发现凭空捏造的、不合理的方药组成。模型可正确使用小青龙汤、小柴胡汤、真武汤的复杂加减法,说明模型对所开具的处方具有加减化裁能力。模型拥有根据规则合理调整药物剂量的能力,例如小柴胡汤治疗发热时,模型给出的柴胡剂量为30 g,无发热时,模型将柴胡剂量减为15 g。
3.3 数据收集成本及模型学习效率
望庐模型的数据来源于规则,数据收集成本主要集中在规则制定上。规则制定有赖于临床经验总结,而经验一旦被证实是临床有效的即可在短时间内编写成规则,继而形成模型训练数据。相比于以往基于深度学习的中医模型,望庐模型无需倚赖真实世界的海量数据,因此极大降低了数据收集成本,提高了模型迭代效率。
3.4 模型的可解释性
机器学习模型的可解释性是指人类能够理解模型决策原因的程度[16]。方药推荐模型涉及医疗领域,若模型不具有可解释性可直接导致人类对模型决策结果的不信任。望庐模型具有可解释性,理由如下:其一,望庐模型融合了规则模型及深度学习模型两者的特点,规则模型本身具有可解释性,规则被书写后可查、可监督、可修改;其二,本模型训练数据来源于规则生成,本身具有规律性,有别于来源于真实世界的零散、无序、有误的数据,模型通过对规律的拟合,实现输入输出(即方证方药)两端的数据严格符合人类预期;其三,通过设置规则可部分人为地控制方证方药元素的属性及词向量结果。
3.5 模型设计的核心中医理念
方证相应是本模型设计的核心理念。方证是方的主治、用方的临床证据,是中医临床实践的物质基础,历代医家每每强调“有是证用是方”[17]。方证识别是基于现象的直觉思维,不讲究逻辑推理、因果关系,具有浓郁的东方哲学色彩[18]。中医理论的价值是为现实世界中本无直接联系的方证及方药建立理论联系,但存在为了理论逻辑自洽而脱离临床的可能。故本模型使用端到端的深度学习模型Transformer实现方证到方药的映射,而非规则推理,且中间不人为另设中医理论相关参数,而是让模型直接在方证方药特征之间寻找二者的联系,以此模拟方证相应的诊疗模式。方证到方药映射的中间过程类似于人类通过中医理法为方证及方药建立联系的过程,见图7。
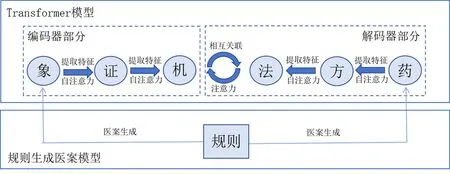
图7 辨证论治原理与模型原理对照示意图
3.6 模型的局限性及展望
本模型在实验过程中未使用真实医案进行测评,相关工作有待进一步完善。本模型虽在拟合方证规则上具有高准确率,但并不等同于在真实世界的临床中可获得同等的高准确率,理由在于真实世界的临床信息往往存在噪声,一旦模型错估了噪声的权重则会导致错误的结果。故减少噪声对模型的影响、增加模型泛化能力成为下一步的工作重点。具体方法可能包括:训练模型时模拟真实的临床在规则生成的医案中适当增加噪声,基于真实世界的临床医案、经验编写方证规则,使用正则化技术增加模型泛化能力等。
猜你喜欢
中国民间疗法(2021年18期)2021-11-02
中国民间疗法(2021年6期)2021-06-09
法律方法(2021年4期)2021-03-16
基层中医药(2020年1期)2020-07-27
基层中医药(2018年9期)2018-11-09
文教资料(2018年30期)2018-01-15
传播力研究(2017年5期)2017-03-28
中国宪法年刊(2016年0期)2016-05-20
云南中医学院学报(2015年3期)2015-07-31
中医研究(2014年11期)2014-03-11
