
基于UNet3+生成对抗网络的视频异常检测
2024-03-21 01:48陈景霞林文涛龙旻翔张鹏伟
计算机工程与设计 2024年3期
陈景霞,林文涛,龙旻翔,张鹏伟
(陕西科技大学 电子信息与人工智能学院,陕西 西安 710021)
0 引 言
传统视频异常检测[1]采用手工特征提取方法,虽然检测效果较好,但是计算成本高。与传统方法相比,基于深度学习的视频异常检测方法具有更好的准确性、鲁棒性和运行速度[2]。
为了缓解视频中正异常事件不均衡[3],以及有监督训练所需视频标注工作量过大等问题,目前大部分研究集中在弱监督[4]、半监督[5]和无监督[6]方向进行。在训练模型时只采用正常行为的视频数据,旨在学习正常情况下的行为变化以及缓解样本事件不平衡的问题。在测试时如果出现与正常行为不符的事件,则生成的数据会与原测试数据产生较大误差,由此判断产生异常。
基于生成对抗网络和自编码器结构的检测方法不断被提出[2],通过提取视频帧空间特征或时间特征学习视频中的行为变化。
本文就不同场景下多尺度特征提取不完全等问题,提出两种生成对抗网络方法。一种是将UNet3+[7]嵌入生成对抗网络中学习全局信息,捕获简单场景下更深层次小尺度特征信息(简称U3P2)。另一种是将UNet++[8]引入生成对抗网络,学习复杂场景下大尺度特征信息(简称UP3)。
1 相关工作
现阶段的视频异常检测研究主要采用深度学习方法,并以视频帧重构和未来帧预测两类方法为主。
基于重构的视频异常检测通过训练正常视频数据来获得正常数据的分布表示[9],而异常行为出现时会有不同的分布,带来较大的重构误差。Gong等[10]为了减轻重构异常的漏检问题,引入内存模块,提出内存增强自编码器模型(MemAE)。Chu等[11]结合时空特征,提出了一种使用稀疏编码和深度学习表示的检测方法。Ganokratanaa等[12]提出深度残差时空转换网络(DR-STN),提高了生成器合成的图像质量。Wang等[13]引入基于边缘的潜在损失,迫使产生更大的重建误差,加强正异常帧的差距。
在基于预测的视频异常检测方面,Liu等[14]提出将分割模型UNet(U-shaped network)用于视频异常检测方法,通过生成对抗网络(generative adversarial networks,GANs)和其获取语义信息的能力预测未来帧进行异常判别,并采用光流模型学习帧的运动变化,取得较好的检测结果。Dong等[15]提出双鉴别器生成对抗网络(CT-D2GAN)进行异常检测,同样基于UNet分割模型生成异常帧。Li等[16]提出一种基于注意力的多实例框架和帧预测框架,在预测框架内引入内存寻址模型。Chang等[17]提出一种带有时空分离的卷积自动编码器结构,采用RGB差值模拟光流运动,并在空间重构最后一帧。
上述基于生成对抗网络的研究[14-17]均采用UNet分割模型作为其网络的生成器模型,虽然这些方法取得一定成果,但依然存在模型检测效果低、场景适用性不高、多尺度特征提取不完全等问题。此外,基础的UNet无法学习长距离依赖性[18],存在不能有效捕捉目标对象中多尺度特征等问题。
UNet3+[7]和UNet++[8]均是针对多尺度特征提取且具有高性能的图像分割模型。本文也是受分割模型在视频异常检测应用[14]的启发,将两种性能较优且能缓解上述问题的图像分割模型应用于生成对抗网络中进行视频异常检测。
2 方 法
本文根据视频中内容的拍摄角度分为近景和远景,其中近景主要是人物行为及背景距离拍摄设备较近的场景,归属于简单场景;远景是距离拍摄设备较远的场景,如监控视频等,归属于复杂场景。
针对不同场景下,使用简单的卷积自编码器网络特征提取能力有限[19],为此本文提出两种异常检测方法。其检测整体流程如图1所示。

图1 异常检测结构
首先,叠加融合并归一化连续的视频帧,再通过编码器对输入数据提取小尺度特征。然后在简单场景下,解码器对编码特征通过反卷积进行上采样,使用U3P2网络中的全尺度跳跃连接融合不同层次的特征图,通过添加的双卷积更全面地提取视频帧的空间特征,在提升检测效果的同时也减少了模型的参数量。在复杂场景下,使用UP3网络并在其密集跳跃连接中引入更多的卷积来提取更加丰富的语义特征,从而提升模型对大尺度特征的提取能力。另外,所提两种方法均采用光流模型来更好地提取视频帧间运动信息。最后通过生成对抗网络获得预测帧,并计算预测帧与真实帧的差值,进而判断视频中的异常情况。
2.1 基于UNet3+的视频异常检测方法
针对现有方法在远景视频中小尺度行为特征提取不准确、参数量大的问题,本文提出基于UNet3+的视频异常检测方法(U3P2),在提高检测效果的同时,降低模型的参数量。
2.1.1 生成模块
U3P2框架主要结构如图2所示。本文采用改进的UNet3+[7]作为网络生成器,整体采用四层自编码器结构并将3×3大小的64个卷积核的卷积块作为第一层。

图2 U3P2方法结构
下采样阶段,每层输入将经过双卷积、LeakyRelu激活函数,提取各个层次特征数据。上采样阶段,由于双线性插值方法会丢掉部分特征信息,为了更好还原特征图,解码器部分采用反卷积的方式对拼接后特征进行上采样操作,公式计算如下
(1)

为了捕获更多细粒度和粗粒度的语义信息,采用全尺度跳跃连接方式,将上采样过程中每个卷积层的卷积核个数固定,使其与第一层卷积核数量相同,从而每一层能融合来自低、同、高层次的特征图。在拼接全尺度特征图时,使用连续的双卷积以及LeakyRelu激活函数作为连接时的卷积块,以此提高对特征的提取能力,其计算公式如下
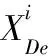

(2)

2.1.2 U3P2

当生成器的编码层采用M特征数,编码器N层时,其中UNet3+模型参数量计算如下


(3)
式中:DF代表卷积核大小,d(·) 代表节点深度。

(4)
式中:G代表生成器,[I1,…It-1]代表连续的视频帧。
最后采用全卷积网络鉴别器,通过卷积感受野判断每个区域,最后根据加权结果判断预测帧是否与原图接近。由判别器判别真假,以预测帧和真实帧的差值作为异常分数。
2.2 基于UNet++的视频异常检测方法
针对现有方法在近景视频中大尺度行为特征提取不准确、准确度不高等问题,本文提出基于UNet++的视频异常检测方法(UP3)。
UP3框架主要结构如图3所示。本文使用改进的UNet++[8]作为近景视频检测网络的生成器模型。模型整体采用五层结构,并引入密集的跳跃连接,在跳跃连接路径中使用双卷积卷积块,其卷积的输入来自同层前一个或多个卷积层的输出和下一层低密度卷积的输出相融合,以此减少编码器和解码器子网络的特征图之间的语义差距,通过抓取不同层次的特征,来捕获更大感受野的区域特征,获得更加丰富的语义信息。
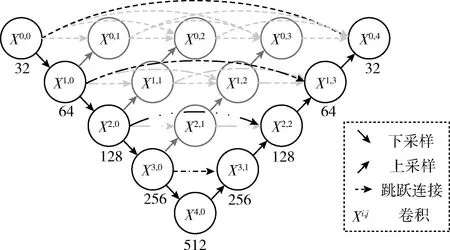
图3 UP3方法生成器结构
在解码器阶段也采用反卷积对特征图进行上采样,每个卷积结点的计算公式如下
(5)
式中:i代表沿编码器下采样层索引,j代表沿跳跃连接的密集卷积层,Xi,j表示当前节点,C(·) 代表卷积以及激活函数计算,[·]代表级联层,U(·) 代表上采样层。
其输入与上节相同,选取连续t-1帧在通道维度上融合叠加,再输入改进的生成器模型预测下一帧。采用相同的损失函数学习外观特征,并送到光流模型和全卷积网络判别器中,结合足够的对抗迭代以及损失约束,让模型在时空维度上提取更多特征信息,学习正常行为的变化。
其中模型的参数计算如下
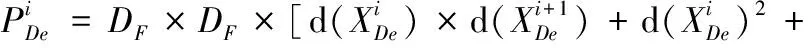

(6)
式中:DF代表卷积核大小,d(·) 代表节点深度。
2.3 损失约束
为了加强对抗网络对视频帧的预测能力,引入4种损失约束[14]。
2.3.1 强度损失
(7)

2.3.2 梯度损失
为了更好保证预测帧的清晰度,引入梯度损失Lgd,其定义如下


(8)
式中:i,j代表视频帧的空间索引。
2.3.3 光流损失
为了加强学习运动信息,本文引入运动损失约束,在时间上对其约束,其损失函数表示如下
(9)
2.3.4 对抗损失约束
生成对抗网络已被证明在视频生成中的可行性[2]。通常网络包含一个生成器G和一个判别器D,本文将采用UNet3+或UNet++作为生成器G,使用全卷积网络作为判别器D。
训练生成网络目的是为了使生成器G学习正常事件行为特征,从而输出与正常事件真实帧更加接近的预测帧,具体表示如下
(10)
(11)
2.3.5 目标损失函数
结合前几节提到强度损失、梯度损失、光流损失以及对抗损失,最终目标损失函数如下所示


(12)
式中:λint、λgd、λol和λadv为各个损失部分的权重参数。
2.4 异常评判标准
假设异常事件是不可预测,因此在训练时均采用正常数据训练,预测帧的结果也只会更加接近真实帧,将预测帧与真实帧间的差异作为异常分数的判断。当出现真实异常情况时,预测帧和真实帧必会产生差异,若差异较小,则视为正常情况。峰值信噪比(peak signal to noise ratio,PSNR)是一种评估图像质量的有效方法[14],表达为
(13)
式中:在t帧时的PSNR值越高表示其预测帧生成质量越好,更加接近真实帧,代表行为正常,反之异常。同时每个视频的所有帧的PSNR也将归一化到[0,1],具体计算每帧分数的公式如下
(14)
最终根据S(t) 结果判断预测帧是否异常。
3 实验结果及分析
3.1 数据集
为了有效开展实验,本文提出的两种模型使用TensorFlow框架和NVIDIA GeForce GTX3090 GPU,在两个公开数据集[18]CUHK Avenue和UCSD Pedestrian 2(Ped2)进行实验验证。数据集具体内容如下:
(1)CUHK Avenue数据集:包含16个训练视频和21个测试视频,场景是校园大道且每帧为RGB图像,每帧的尺寸为640×360,采取固定角度录制的监控视频,其中存在行人跑错方向、快速的奔跑、物品散落等47个异常事件。
(2)UCSD Ped2数据集:包含16个训练视频和12个测试视频,场景是行人与摄像头拍摄方向平行的区域,每帧的尺寸为360×240,其中存在骑自行车、玩滑板、汽车等12个异常事件。
以上两个数据集在训练时均采用只包含正常事件的训练视频,在测试时会存在异常事件的测试视频,异常数据部分展示如图4所示。

图4 异常数据部分展示
3.2 评价指标
为了方便实验对比,本文与Liu等[14]采用相同的评价指标AUC,作为视频异常检测的评价指标。
AUC(area under curve)是接收者操作特征曲线(receiver operating characteristic curve,ROC)下的面积。视频异常检测标准方式一般分为帧级和视频级,本次实验在帧级进行操作,根据AUC指标评估模型对异常检测效果的好坏,当ROC曲线面积越大时,则AUC分数越高,模型检测效果越好。
3.3 实验结果分析
本文采用连续5帧作为网络输入,输入每帧大小固定256×256。其中连续的前4帧用于预测最后一帧。方法均使用光流模型学习在时间维度的运动特征,并引入不同损失约束使其学习外观特征,最终以预测帧和真实帧的差值计算异常分数。
3.3.1 不同算法性能对比
为了验证本文模型的有效性,将与现有的视频异常检测研究在帧级的AUC指标进行对比,方法分为基于重构和基于预测两种,具体对比结果见表1,模型的参数量对比见表2。本文提出的UP3在Avenue数据集上AUC达到了85.8%,U3P2在Ped2数据集上AUC达到96.0%。所提方法分别是两种数据集的最优结果,验证了本文提出的视频异常检测方法的有效性以及两种图像分割模型的可应用性。
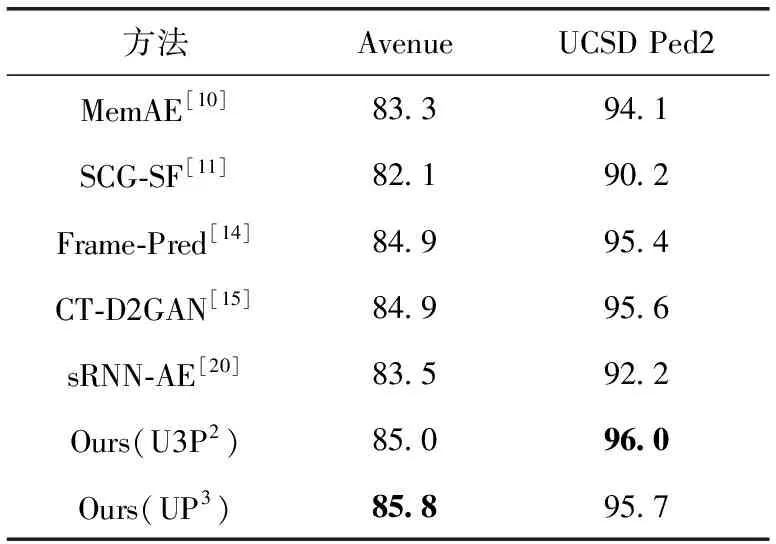
表1 帧级检测性能比较AUC/%

表2 计算成本对比
U3P2在Avenue数据集的检测效果虽低于UP3模型方法,但在Ped2数据集上取得最好结果,较于基准方法[14]提升0.6%,较于方法UP3提升0.3%。结合表2,方法U3P2在提升异常检测效果的同时,也带来了更少参数量,并与其它算法的性能保持持平甚至优于其它算法,降低了视频异常检测模型的复杂度。Ped2数据集是更接近现实监控的黑白视频,视频中的行为特征较为细小。通过全尺度跳跃连接结构,将不同尺度的特征图进行拼接,能更有效获取视频帧中多尺度特征的语义信息,该方法更适用在远景监控的场景下。在Avenue数据集中效果与近年其它方法相差不多,其原因可能是,方法还未能将多个局部信息联系,对大尺度行为特征提取欠缺,由于该数据集中人物行为变化较大,因此对人物行为检测效果略低一些。
UP3在Avenue数据集检测效果较于基准方法[14]提升0.9%,取得最优结果。UP3采用深度卷积以及密集跳跃连接提取特征信息,针对近景视频中的人物行为特征,该方法相比U3P2能关注较大的感受野区域特征信息,较好检测视频中存在的大尺度行为特征,却也存在大量参数的使用。对于远景数据检测效果略低的原因,可能是UP3未能处理更小感受野的局部信息。
MemAE[10]虽然用记忆模块存储正常行为特征,但没有考虑时间维度的行为变化,当记忆模块空间设置越大时,也会带来更多的参数量。SCG-SF[11]虽然考虑到时空特征信息,但对视频中的多尺度特征提取能力不足,检测结果相比其它几种方法略低。CT-D2GAN[15]方法采用双鉴别器生成对抗网络,效果就基线方法相比,提升并不明显,说明网络的叠加使用并不能提升特征的提取,而本文所提方法能更有效提取多尺度特征,提高检测能力。
相比于重构的模型[10,11,20],基于预测的模型[14,15]检测效果更好。说明本文的预测模型可以有效提取连续视频帧的时空特征信息,也证实UNet++和UNet3+图像分割模型在视频异常检测领域的适用性。
3.3.2 结果可视化
为了更好验证模型的有效性,将U3P2模型预测结果可视化展示,如图5所示。

图5 预测结果可视化
在正常行为中,预测帧与真实帧接近;出现异常时,将生成较为模糊的异常行为,如图5左下角的自行车为生成的模糊异常行为。
本文所提模型在训练时实时计算并记录了每个预测帧的PNSR值。当图像生成质量越高时,PSNR值越大,反之越小。在视频异常检测领域根据PSNR值的变化可以更加直观判断模型检测的效果,在U3P2模型实验的PSNR值结果展示如图6所示。

图6 PSNR值结果可视化
选取Ped2数据集中第二个测试片段作为PSNR值变化分析。从图中看到正常行为的PSNR值变化不大,仅在[0,1]范围发生波动,而在后几帧中PSNR值快速下降,是由于出现训练中突然未出现的骑自行车现象,该现象被判定为异常,后几帧的值趋于低值稳定是因为在后面的片段中一直存在骑自行车的行为,即一直存在异常行为。由此也证实了本文所提方法确实能有效分辨视频片段中的正常行为和异常行为。
3.3.3 验证实验
为了确定网络层数的不同对视频异常检测效果的影响,就本文提出的两种方法,分别以四层结构和五层结构且采用相同的参数在Ped2数据集上进行实验对比。最终帧级AUC(%)结果以及参数量在表3和表4中展示,损失函数对模型的影响在表5展示。
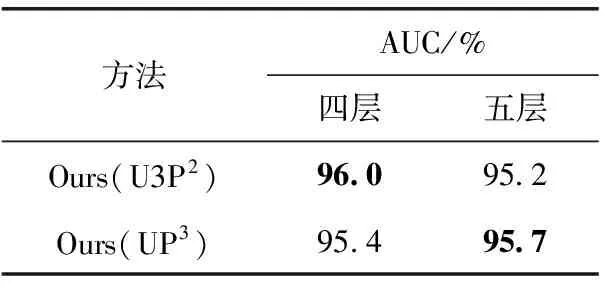
表3 不同层数对结果的影响
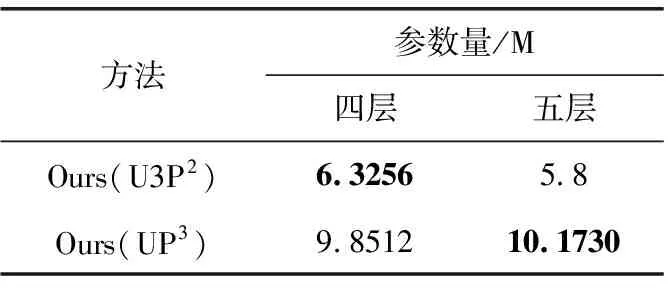
表4 不同层数对参数量的影响

表5 不同损失函数在Ped2数据集中的AUC值
其中,四层网络均采用特征数为64、128、256和512的结构,而五层网络均采用特征数为32、64、128、256和512的结构。通过表3和表4发现四层U3P2的结果优于五层的结果,其原因在于四层时使用的参数量更多;五层的UP3的结果优于四层的结果,也表明在参数量多的情况下预测效果更好。而U3P2在四层时的参数多,源于其全尺度跳跃连接结构,其上采样的每层卷积核数量与下采样第一层卷积核数量相同。当采用四层结构且第一层数量为64,则上采样的每一层特征数为64×4,而五层设置第一层数量为32,则上采样的每一层特征数为32×5,五层的特征数低于四层,因此该模型在四层时效果更好;针对不同层数的UP3的预测方法,由于减少一层32特征数的卷积层,只带来少量参数减少,因此不同层数的检测结果接近。
表5显示4种损失约束对方法U3P2在Ped2数据集上的影响。表中结果显示,光流损失引入后达到96.0%,较未引入时提高至少1%,说明光流能有效提升方法在时间维度的特征提取能力。随着损失约束的添加,AUC值明显提升,因此验证了加入不同的损失约束会影响方法的检测性能,引入更多的约束条件可能会提升AUC。
4 结束语
针对现有研究方法存在不同场景下多尺度特征提取不完全等问题,本文提出两种方法。
U3P2能够在少量参数的情况下提取更多的空间特征信息。结合光流以及其它损失函数能在时空维度准确提取特征。在Avenue数据集检测结果达到85.0%,在Ped2数据集检测结果达到96.0%,适用在简单场景中检测小尺度行为特征。
UP3采用深度卷积和密集跳跃连接,关注更大范围的感受野,能更好提取视频帧复杂语义特征信息。在Avenue数据集检测结果达到85.8%,在Ped2数据集检测结果达到95.7%,适用于检测更加复杂场景下的异常情况。
未来的视频异常检测研究主要从优化算法的时空特征提取能力、减少模型的参数量、关联前后景的行为变化3个方面展开。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
数学小灵通·3-4年级(2021年5期)2021-07-16
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
电子制作(2019年11期)2019-07-04
今日农业(2019年15期)2019-01-03
北京航空航天大学学报(2018年1期)2018-04-20
太空探索(2016年5期)2016-07-12
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
时代英语·高三(2014年5期)2014-08-26
