
基于SDL-LightGBM集成学习的软件缺陷预测模型
2024-03-21 01:48谢华祥高建华黄子杰
计算机工程与设计 2024年3期
谢华祥,高建华+,黄子杰
(1.上海师范大学 计算机科学与技术系,上海 200234;2.华东理工大学 计算机科学与工程系,上海 200237)
0 引 言
软件缺陷预测利用项目中已有的缺陷信息建立缺陷预测模型,并预测项目中可能出现缺陷的代码,以减少开发人员检查出错代码的时间和软件开发成本。相关研究[1]指出大型系统的维护工作占用软件开发总成本的90%。软件缺陷预测技术可以根据软件的信息提取特征,使用分类器算法建立预测模型来确定软件具体模块是否包含缺陷。
在模型的使用方面,Erturk等[2]使用SVM(support vector machine)算法对NASA数据集建立缺陷预测模型,并取得不错效果。Feidu等[3]使用多种机器学习算法和基于LM(language model)的神经网络算法建立缺陷预测模型,实验结果显示基于LM的神经网络取得最高预测精度。
上述软件缺陷预测研究大多使用单个分类器,而单个分类器存在预测准确率不高,泛化能力弱等问题,相比单个分类器,集成学习具有更好的分类准确性和效率[4]。如陈丽琼等[5]使用XGBoost集成学习算法建立即时软件缺陷预测模型。
然而针对典型Boosting算法的不足,Ke等[6]提出了LightGBM算法,大量实验结果表明LightGBM算法在性能和效率方面优于传统机器学习算法和其它集成学习算法。
在特征选择方面,实验数据特征间的多重共线性和大量无关特征会导致“维度灾难”,增加预测模型的复杂度和训练时间[7],并可能导致模型过拟合[8]。合理的特征选择可以有效地实现特征降维[9]。
相比分类器的默认超参数,不同超参数组合对应模型性能有较大不同[14],超参数优化主要有网格搜索、随机搜索以及贝叶斯优化。Shen等[10]比较各种优化算法,发现DE算法优化结果最好。
在可解释方面,LIME是Ribeiro等[11]提出的局部替代模型。该模型使用可解释的机器学习模型(即线性回归、决策树等)局部模拟黑盒模型的预测。因此,可以使用局部代理模型来解释单个实例。
基于以上研究,本文提出一种基于SDL-LightGBM集成学习的软件缺陷预测模型。
1 相关工作
1.1 LightGBM算法
集成学习是组合多个基分类器来建立一个强分类器,即使每个基分类器是弱分类器,通过集成学习后也能建立一个强分类器。它能有效避免传统分类器的过拟合问题,同时能获得更强的泛化能力。由Ke等[6]提出的LightGBM算法是集成学习的一种,主要使用基于梯度的单边采样(gradient-based one-side sampling,GOSS)和互斥特征捆绑(exclusive feature bundling,EFB)这两种方法弥补Boosting算法的不足[6]。
GOSS是从减少样本的角度出发,排除大部分权重小的样本,仅用剩下的样本计算信息增益,它是一种在减少数据和保证精度上平衡的算法。而高纬度数据中很多特征是互斥的,特征很少同时出现非0值。EFB的思想就是把这些特征捆绑在一起形成一个新的特征,以减少特征数量,提高训练速度。因此本文选择LightGBM算法构建基础模型。
1.2 特征选择
原始特征集可能存在无关特征和特征间的多重共线问题[5]。而LightGBM的特征重要性算法可以有效剔除无关特征。处理特征间的多重共线问题,本文选择Spearman[13]定义的Spearman秩相关系数,定义如式(1)
(1)
式中:xi,yi分别是两个特征按大小(或优劣)排位的等级,n是样本大小,ρ代表Spearman秩相关系数。ρ越大,代表两个特征之间共线性越强。
如艾成豪等[12]通过ReliefF+XGBoost+Pearson相关系数混合特征选择,融合所有特征的权重,删除融合权值较低的特征得到特征子集,有效地降低了模型的运行时间。
1.3 模型超参数优化
相比分类器的默认超参数,不同超参数组合对应模型性能有较大不同[14]。Shen等[10]通过4个优化算法优化6个常用的机器学习分类器,使用AUC值作为模型性能度量,实验发现模型超参数优化可以显著提高代码异味检测的性能,差分进化(DE)算法可以比其它3种优化器获得更好的性能。因此本文使用DE算法优化LightGBM的超参数。
1.4 模型可解释相关研究
现有的软件缺陷预测重点关注模型的预测能力,忽略了模型的可解释性。大多数分类器都属于黑盒模型,其预测的结果无法使人信服。LIME解释模型的原理通过简单模型来解释复杂模型。对样本数据变换得到一个新的数据集,用这个新数据集训练一个简单模型,即一个容易解释的模型。假设f是一个黑箱模型,x是一个需要解释的实例,LIME的损失函数如式(2)
E(x)=argminLg?G(f,g,πx)+Ω(g)
(2)
式中:L反应黑箱模型(复杂模型)f与简单模型g之间预测结果相似程度,G表示简单模型g的算法集,π表示定义在实例x周围采样时的域范围,Ω(g) 表示可解释模型g的模型复杂性,本文采用LIME对模型进行解释性分析。
2 SDL-LightGBM设计流程
机器学习算法可以有效地建立软件缺陷预测模型。然而相关工作存在特征冗余、分类器选择和模型解释的不足[3],对此,本文提出一种基于SDL-LightGBM集成学习的软件缺陷预测模型,方法流程如图1所示。

图1 本文方法流程
2.1 建立特征集
实验的特征集主要有两类特征组合,一类为传统结构度量,另一类由Fowler等[16]定义的代码异味。
2.1.1 结构度量
产品度量测量源代码内在特征,如代码行数、复杂度等。本文在传统结构度量的基础上[16]利用CK[17]软件测量36个结构度量新特征。通过类关键字匹配对两个数据集进行融合,供后面特征选择组合。具体特征描述分别见表1与表2。

表1 传统结构度量

表2 CK测量的36个结构度量
2.1.2 代码异味
本文采用由Fontana等[18]定义的代码异味强度指数(Intensity)量化代码异味。通过JCodeOdor[18]工具检测6种类型的代码异味并计算得到一个Intensity值。6种代码异味分别是:
(1)God Class:实现不同职责和集中大部分系统处理的大型类。对程序理解、软件可维护性有负面影响。
(2)Data Class:单纯用作数据存储的类,该类仅有一些字段(fields),以及读写这些字段的函数。
(3)Brain Method:实现多个函数的过大方法。
(4)Shotgun Surgery:一个类遇到某种变化,其它类需要被动作出修改。
(5)Dispersed Coupling:类与其它类具有太多耦合关系。
(6)Message Chains:过长的方法调用。
2.1.3 混合特征选择
本文为了更细化研究软件结构度量,使用CK[17]软件测量36个结构度量新特征,加上27个传统结构度量和JCodeOdor[18]工具计算得到的一个代码异味强度指数Intensity值共提取64个特征,并利用类名作为匹配键对其合并。然而合并后特征间的高度共线性和大量无关特征会导致“维度灾难”,增加预测模型的复杂度和训练时间。对此本文采用LightGBM特征重要性和Spearman[13]算法对特征选择与组合,并确定特征子集。通过实验比较得到LightGBM重要性阈值为30时,不会降低模型的预测能力。根据Nucci等[19]的建议,当设置Spearman的相关度ρ的阈值为0.8,即当ρ大于0.8时认为两个特征具有强相关,这时保留对模型贡献最大的特征。Spearman+LightGBM混合特征选择算法具体流程如算法1所示:
算法1:混合特征选择算法
输入:合并后的数据集
输出:特征子集
(1)使用LightGBM计算每个特征对预测结果的重要性权重向量W,并按照从大到小进行排序
W=[ω1(x),ω2(x),…,ωn(x)]
(2)设置重要性阈值30,去除重要性低于阈值的特征,得到第一次选择的特征子集X1
X1=[x1,x2,…,xn]
(3)使用Spearman测量特征子集X1两两特征间的相关系数ρ,得到相关系数矩阵P
(4)设置相关性阈值为0.8,当两两特征阈值大于0.8时认为其具有高度相关,保留重要性最高的一个特征。依次去除高度相关特征,最后得到特征子集X2
X2=[x1,x2,…,xn]
经过Spearman+LightGBM混合特征选择后,从高度冗余的64个特征中选择15个组合成结构度量子集,去除大量无关特征和高度共线特征,进而实现降低模型复杂度。
2.2 模型优化
机器学习模型中有各种参数需要调整,这些参数可分为模型参数和模型超参数。模型参数是模型内部通过自动学习而得出的配置变量,如神经网络中的权重,逻辑回归中的系数等。模型超参数则需要从外部配置,模型训练之前需要手动设置的参数。如随机森林树的深度、神经网络中迭代次数等。不同超参数设置会有不同的模型性能。本文对LightGBM的5个关键超参数进行优化其具体描述见表3。

表3 本文优化的LightGBM超参数
本文使用DE算法优化LightGBM的超参数,优化方法如算法2所示:
算法2:DE优化LightGBM超参数
输入:数据集和LightGBM分类器
输出:优化后的一组超参数
/*将数据集划分为训练集和测试集*/
xtrain,xtest,ytrain,ytest←D
/*1. 10折交叉验证*/
/*2. DE种群初始化*/
Xi(0)=(xi,1(0),xi,2(0),…,xi,n(0))
/*3.开始迭代*/
Hi(g)=Xp1(g)+F·(Xp2(g))-Xp3(g)
/*4.从种群中随机选择3个个体产生变异,F是缩放因子取0.5*/
if rand(0,1)≤CRorj=jrand
Uj,i(g)=Hj,i(g)
Otherwise
Uj,i(g)=Xj,i(g)
/*5.在变异操作后,对第g代种群 {Xi(g)} 及其变异中间体 {Hi(g)} 进行个体间交叉操作*/
iff(Ui(g))≤f(Xi(g))
Xi(g+1)=Ui(g)
Otherwise
Xi(g+1)=Xi(g)
/*6.DE算法采用贪婪算法来选择下一代的个体*/
Endfor
/*7.迭代结束,输出最优超参数组合*/
3 实验分析
为了验证基于SDL-LightGBM集成学习的软件缺陷预测模型的有效性,本文主要回答以下4个问题:
Q1:Spearman+LightGBM混合特征选择算法是否有效?
Q2:使用DE算法优化模型超参数是否能提高模型预测性能?
Q3:本文所提出的SDL-LightGBM方法与其它文献相比是否具有优势?
Q4:使用LIME分析什么特征对结果影响最大?
3.1 实验数据集
实验使用的数据集[16]包括12个开源系统的35个版本。表4给出了数据集的详细信息,包括系统名称、系统版本数量、系统类的数量(最小-最大)、系统代码千行数量(最小-最大)和缺陷类的百分比(最小-最大)

表4 实验项目
3.2 十折交叉验证
为了更好评估模型的性能,实验采用10折交叉验证策略,将数据集随机划分10个大小相等的数据子集,一个作为测试集,其余9个作为训练集,重复10次,使每个子集都恰好一次作为测试集,最后结果取10次操作的平均值。
3.3 评价指标
(1)F1值:在分类预测中,常用精确度(Precision)和召回率(Recall)这两者的调和平均作为评价指标即F值(F-Score),如式(3)
(3)
当α取1时,就是常见的F1值,如式(4)
(4)
precision和recall的定义如式(5)、式(6)
(5)
(6)
其中,TP、FP和FN的含义见表5。

表5 TP、TN、FP、FN概念
(2)AUC值:AUC值是ROC曲线下的面积,而ROC曲线的横轴是FPRate,纵轴是TPRate。当两者相等时,其表示的含义是对于正类和负类的预测概率为1的概率相等,
即TPRate=FPRate=0.5,此时ROC下的面积即AUC值为0.5,分类器没有任何区分能力。而一个好的分类器要求TPRate>>FPRate。而理想的情况为TPRate=1,FPRate=0。此时ROC下的面积即AUC值最大,分类器性能最好。
3.4 实验结果分析
Q1:为了验证本文Spearman+LightGBM混合特征选择方法的有效性,本文分别使用选择前和选择后的特征数据集建立预测模型。首先利用LightGBM的特征重要性importance对64个特征进行排序。importance越高,说明特征对预测结果越重要。排序结果见表6。

表6 特征重要度排序
importance大于30的特征有17个,大于10的特征有37个,因此本文对importance阈值为0、10和30分别进行筛选比较,结果见表7。

表7 阈值筛选性能比较
根据实验比较结果可以看出,当importance阈值设置为30时,能最大程度降低特征维度从而降低模型复杂度且不会影响模型的预测性能。因此利用LightGBM筛选结果保留importance大于30的17个特征,分别是intensity、scattering、fi-changes、ce、ostrand、UWQty、loc、cbo、AMQty、cboM、VBQty、amc、rfc、FAN-OUT、acpd、TMQty和cam。
考虑到特征间可能具有多重共线性,本文利用Spearman秩相关系数计算17个特征间的相关系数ρ。根据Nucci等[19]的建议,当设置ρ的阈值为0.8,即当ρ大于0.8时认为两个特征具有强相关,这时保留对模型贡献最大的特征,剔除特征loc和cam。
经过Spearman+LightGBM混合特征选择后的特征子集共15个特征,分别是intensity、scattering、fi-changes、ce、ostrand、UWQty、cbo、AMQty、cboM、VBQty、amc、rfc、FAN-OUT、acpd和TMQty。
特征选择前后对模型的影响比较结果见表8,特征选择后的模型F1值提高0.5%,AUC值提高0.4%,模型预测性能得到提高。特征选择前的模型模型训练时间为30.36 s,特征选择后的模型训练时间为21.12 s,模型训练时间缩短43.6%。因此,本文使用的混合特征选择能有效提高模型预测性能和降低模型复杂度从而缩短模型训练时间,验证该方法的有效性。
Q2:根据Shen等[10]的建议,使用DE算法优化LightGBM的重要超参数。DE算法的初始种群数量和算法迭代次数的取值会影响DE算法的性能,因此对种群数量取值[10,100],迭代次数取值[10,500],以AUC值作为优化目标函数返回值分别进行实验,结果如图2、图3所示。

图3 迭代次数比较
从图2、图3可以看出当种群大小和迭代次数分别设为20和100时DE算法可获得最佳性能。通过DE算法优化得到一组最优的LightGBM超参数组合,即[n_estimators:164,max_depth:178,num_leaves:63,min_child_sample:42,learning_rate:0.16]。通过表9可以看出,超参数调优后F1值提高0.98%,AUC值提高0.92%。因此可验证通过DE算法优化LightGBM超参数可提高模型预测精度。

表9 超参数优化前后性能对比
Q3:为了验证本文所提方法SDL-LightGBM的有效性,与近年同类论文进行对比。Palomba等[16]使用逻辑回归建立软件缺陷预测模型。Pritam等[20]使用多层感知机建立软件缺陷预测模型。对比实验将在相同项目数据集下进行,确保实验具有可比性。从表10可以看出,本文所提出的方法SDL-LightGBM相比文献[16]在F1值提高12.28%,在AUC值上提高18.63%,相比文献[20]在F1值上提高5.67%,在AUC值上提高4.22%。因此可证本文所提方法SDL-LightGBM的有效性。
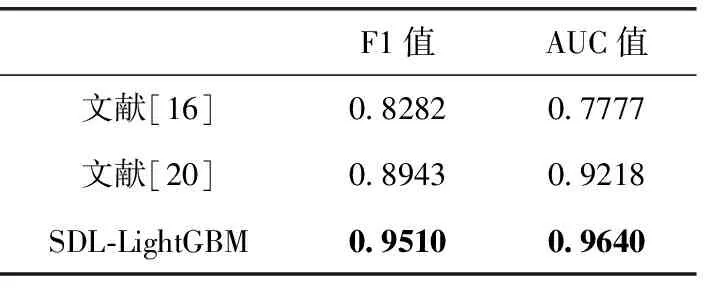
表10 缺陷预测方法对比
Q4:图4给出全部数据特征对模型输出结果的贡献度,可见在全局情况下,代码异味强度指数intensity对模型贡献度最高,这符合软件工程实际情况,即代码异味越严重越有可能出现缺陷。

图4 全局特征对模型贡献度
然而每条实例数据都有各自特点,具体问题要具体分析,因此不能用全局解释的结果来分析单个实例数据。因此本文采用LIME解释模型的单个实例。本文选择一条带缺陷的实例数据使用LIME解释,如图5所示,这条实例预测为有缺陷倾向的3个最重要的因素为 {fi-changes>61.00}{scattering>30.0}{intensity>1.05},对缺陷有影响的贡献依次是0.19,0.19,0.11。而在全局解释中intensity对模型贡献度最高。这进一步说明全局解释结果不能解释单个实例。LIME能计算单个实例数据中每个特征对模型影响的重要性和取值范围,这能够给测试人员分析具体缺陷类提供条件。

图5 LIME解释局部实例
4 有效性威胁
本文有效性威胁分析主要从3个方面讨论,分别为建立有效性威胁、结论有效性威胁和外部有效性威胁。
建立有效性威胁主要与结构度量和代码异味的测量有关。本文通过CK[17]测量结构度量,依靠JCodeOdor[18]测量代码异味强度指数。为了验证结构度量和代码异味强度指数的有效性,采用Spearman秩相关性去除多重共线性影响,得到的15个特征相互之间的共线性均低于0.8,表明它们之间的相关性较弱。因此,本文模型建立不受特征之间的多重共线性的威胁。
结论有效性威胁主要与评价指标有关,精确率含义是在所有被预测为正的样本中实际为正的样本的概率,召回率含义是在实际为正的样本中被预测为正样本的概率。前者偏向查准率,后者偏向查全率。为了综合两者优点,本文采用F1值,同时考虑查准率和查全率,是两者达到一个平衡。而为了评价模型的好坏,即模型的区分能力,本文引入了ROC曲线下的面积AUC值。AUC值可以更全面的衡量一个模型的好坏。因此,本文结论不受评价指标的有效性威胁。
外部有效性威胁主要涉及到结果的泛化性。根据Palo-mba等[16]的建议,删除缺陷比例高于75%的7个系统,保证数据的健壮性。同一种方法在不同的应用领域程序的缺陷预测中可能有不同的表现[22],因此本文分析了来自不同应用领域、具有不同特征(大小、类数等)的12个软件系统的35个版本,从而提供本文数据的可靠性。
5 结束语
本文提出基于SDL-LightGBM集成学习的软件缺陷预测模型,为了避免特征冗余和多重共线的影响,根据Spearman+LightGBM混合特征选择建立特征子集,避免无关特征和特征间的多种共线影响。采用集成学习算法LightGBM作为基础分类器。为了进一步提升分类器预测性能,利用DE算法优化LightGBM的重要超参数,得到一组最佳超参数组合。最后对模型实例进行解释,方便测试人员分析缺陷类。实验结果表明,本文提出的方法SDL-LightGBM与其它模型相比取得了更好的预测性能,F1值平均提高8.97%,AUC值平均提高11.42%。通过混合特征选择后,模型训练时间缩短43.6%。同时使用LIME解释复杂的黑盒模型,生成可解释的特征重要性可视图,进而帮助测试人员更好理解软件缺陷预测模型。
未来的工作包括:①使用基于抽象语法树的神经网络(abstract syntax tree neural network,ASTNN)[21]的深度学习方法捕捉代码的上下文信息,并建构分类器;②进一步考虑其它特征对软件缺陷的影响;③探究本文方法在实际应用场景中的效度。
猜你喜欢
数学小灵通·3-4年级(2024年2期)2024-05-15
数学年刊A辑(中文版)(2022年4期)2022-02-16
黑龙江工业学院学报(综合版)(2020年6期)2020-08-11
数学年刊A辑(中文版)(2019年3期)2019-10-08
成都信息工程大学学报(2018年3期)2018-08-29
电子元器件与信息技术(2017年4期)2017-03-08
电子制作(2017年23期)2017-02-02
中国学术期刊文摘(2016年1期)2016-02-13
西北工业大学学报(2015年4期)2016-01-19
电脑与电信(2014年10期)2014-03-13
