
基于评论文本和融入专业度评分的跨域混合推荐
2024-03-21 01:48陈昊峰刘学军王步美
计算机工程与设计 2024年3期
陈昊峰,刘学军+,王步美
(1.南京工业大学 计算机科学与技术学院,江苏 南京211816;2.江苏省特种设备安全监督检验研究院 直属分院安全评价室,江苏 南京 210002)
0 引 言
为深入挖掘用户的历史行为信息从而捕获用户的兴趣偏好,推荐系统应运而生。推荐系统根据分析用户过去的行为记录和属性等相关信息,以此来预测用户未来的兴趣偏好,并基于这些预测结果以个性化的方式为用户提供所需要的商品项目[1]。
传统的推荐系统方法使用协同过滤推荐算法(collaborative filtering recommendation algorithm,CF[2]),该算法主要根据用户的历史交互进行推荐,然而对于那些交互信息较少的用户,推荐的效果就会受到影响。
现有的跨域推荐研究主要是通过相关的源域作为辅助信息,利用跨域评级矩阵来实现知识的迁移,当用户的交互信息不足时往往会导致评级矩阵产生稀疏性问题,因此相关研究人员考虑把用户的评论信息作为知识进行转移,评论信息可以丰富用户和项目的建模,不但可以反应用户对项目的爱好程度,而且还能提高推荐的可解释性。但是当用户对一个项目的评论较少容易产生评论稀疏性问题。
针对上述问题,提出了一种基于评论文本和融入专业度评分的跨域混合推荐方法(hybrid cross-domain recommendation based on comment text and rating recommendation,CTR-HCDR)。该方法通过不同领域用户的评论来连接多个用户的内在特征,能够提取用户和项目评论文本中的方面特征信息,并通过注意力机制识别和加权全局跨域方面相关性进行用户偏好估计。同时利用评论文本中的评分信息,引入基于评分的跨域推荐方法,对聚类用户对聚类项目的评分做出了改进,融入用户专业度来细化每个用户的评分,使得专业度高的用户对项目评分具有更大的权重,从而提高推荐效果。
1 相关工作
1.1 基于评分的跨域推荐方法
按照域中的不同信息可以将跨域推荐方法分为基于评分的跨域推荐方法和基于评论的跨域推荐方法。早期的Ajit等[3]提出了CMF模型,通过分解多个评分矩阵来进行跨域关系学习,当评级矩阵存在过于稀疏的现象时,则会影响推荐的效果。于是Ling等[4]提出将共享的评级传播到一个集群级别中,通过将观察到的评级传播到粗矩阵中未观察到的评级来降低评级矩阵的稀疏性。Xue等[5]创新性地提出CBT方法,通过聚类分析用户和项目的特征来提取内在特征,并采用”CodeBook”结构存储压缩后的评分模式信息,进而实现目标域的迁移。而Li等[6]则提出了三元桥迁移学习策略,首先借助矩阵分解提取用户与项目共享的评分模式及其潜在因子,并构建邻接图来表示其内在关系。最后,将共享评分模式、邻接图及潜在因子形成的“三元桥”进行迁移学习,显著增强了正向迁移效果。
1.2 基于评论文本的跨域推荐方法
为了捕捉用户交互中重要信息,研究人员通过评论信息进一步挖掘用户交互的兴趣偏好。Fu等[7]提出了RC-DMF,利用降噪堆叠自动编码器aSDAE用于用户和项目的表示,并融合了项目的评论信息,实现了冷启动用户推荐的SOTA性能指标。Lu等[8]使用注意力机制的GRU模型,对评论信息进行建模,得到用户和项目的特征向量,提取了跨域全局特征。LesKovec等[9]提出HFT模型,结合了评论信息和评分数据,将用户和项目的评论文本作为输入,结合用户评论和项目评论中的隐因子,但是HFT模型很难保留评论文本中的词序信息,从而忽略上下文信息。Zhao等[10]提出了一个通过方面特征转移网络的跨域推荐模型CATN,从评论文本中提取用户和项目的方面特征,并利用辅助用户来进一步增强用户表示,但是当评论信息稀疏时,会导致评论稀疏性问题。
2 基于评论文本和融入专业度评分的跨域混合推荐方法
本节先给出问题的定义,然后介绍了基于评论文本和融入专业度评分的跨域混合推荐方法,再详细介绍了基于用户评论文本的跨域推荐和融入专业度评分跨域推荐的具体过程,最后通过加权混合推荐实现该方法。
2.1 问题的定义
首先使用DS和Dt来表示源域和目标域,源域DS和目标域Dt都应包括用户、项目以及用户对项目的交互行为,该交互行为包括评分活动以及评论内容。重叠用户定义为在源域和目标域中均呈现出历史交互行为的用户群体,而冷启动用户特指在源域内具有历史交互记录,但在目标域内尚无此类行为的用户群体。针对给定的冷启动用户,通过整合其在源域的评论信息和评分数据,来实现跨域混合推荐的精准预测。
2.2 基于评论文本的跨域推荐方法
本小节借鉴CATN中的推荐方法,基于评论文本的跨域推荐整体结构如图1所示。它由两部分组成:方面特征抽取和跨域方面特征推荐预测。在源域中,Du用于表示用户的评论文档,Di表示项目的评论文档,目标域中也有用户和项目的评论文档,而重叠用户则有两份用户文档,分别来自不同的域。

图1 基于评论文本的跨域推荐模型
模型训练使用一个跨域偏好匹配流程如图2所示。为了将源域中的知识迁移到目标域,利用重叠用户的评论文档在源域和目标域交替训练,从而优化相关参数。该训练流程如下:①通过目标域中的项目评论信息与源域用户的评论信息,优化目标域内用户评分预测的模型参数;②通过源域中的项目评论信息和目标域用户的评论信息,对源域的用户评分预测模型参数进行优化。

图2 跨域偏好匹配流程
2.2.1 方面特征抽取
方面特征的抽取过程如下,由于源域和目标域中对文本方面特征抽取的过程相同,所以以项目文档Dt为例。
文本卷积(text convolution):首先给定一个项目文档Di=[w1,w2,…,wl],l表示文档长度。在使用文档之前,需要将文档中的内容转换为结构化的向量表示。利用Google News中预先训练好的单词嵌入来获得项目文档中每个单词对应的词向量,并将其映射到嵌入表示Ei中,其中Ei=[e1,e2,…,el],e∈Rd,d表示单词嵌入的维度。为了捕捉每个单词的上下文,卷积操作的激活函数采用ReLU,使用卷积滤波器应用在矩阵Ei提取单词的上下文特征,并构建一个项目特征矩阵Ci=[C1,i,C2,i,…,Cl,i],其中Cj,i∈Rn表示该项目文档下第j个单词的上下文特征向量。
门控机制(gate control):由于单词的上下文特征具有多个语义方面,采用门控机制捕捉各特征与不同语义层面之间的关联。对于第m个方面,第j个单词的方面特征gm,j,i定义如式(1)所示
(1)

Gm,i=[gm,1,i,gm,2,i,…,gm,l,i]
(2)
Gi=[G1,i,G2,i,…,GM,i]
(3)
其中,Gm,i是项目i的第m个方面特征,由所有单词的第m个方面特征构成。
方面特征注意力(aspect attention):由于评论来自不同的领域,因此项目的评论文档会体现出不同的方面。例如,音乐领域的评论注重于曲风和演唱者,而图书领域则侧重于情节和作者。因此,使用两个全局方面特征表示矩阵Vs和Vt用于查询源域和目标域的方面特征的抽取。于是可以从Gm,i中推导出第m个方面特征的表示am,i,其推导方式如式(4)和式(5)
(4)
(5)
其中,Bm,j,i表示第m个方面特征对第j个单词的重要性,Vm,t表示查询第m个方面特征的抽取。因此,从项目评论文本Di中得到M个方面特征的表示,构建方面特征矩阵Ai=[a1,i,a2,i,…,aM,i]。同理按照同样的步骤可以从用户评论文本Du中构建方面特征矩阵Au=[a1,u,a2,u,…,aM,u]。值得注意的是:用户和项目评论文本的方面特征提取参数在两个学习流中是共享的,尽管这些参数来自不同领域。
2.2.2 跨域方面特征推荐预测
现在有了用户和项目的抽象方面特征矩阵Au和Ai。由于每个领域中的方面有不同的重要性,例如电影领域中的演员和电影时长两个方面特征,前者的重要性往往是大于后者。因此,模型的推荐预测不能简单的对Au和Ai两个方面特征进行聚合。为了在每个领域中突出重要的方面特征,利用前面提到的全局方面特征表示矩阵Vs和Vt来构建全局跨域方面特征相关矩阵S,具体表示为式(6)
(6)
式中:S∈RM×M,W∈Rk×k是一个近似预测的可学习矩阵,LeakyReLU是一个激活函数。在得到全局跨域方面特征相关矩阵S后,可以用S(x,y) 反映来自源域第x个方面特征对目标域第y个方面特征偏好转移的重要性。
再计算方面特征矩阵Au和Ai之间每个方面特征的语义匹配矩阵Su,i,表示为式(7)
(7)
式中:Au和Ai是用户和项目的方面特征矩阵,W和式(6)一样,是一个可学习矩阵。在得到语义匹配矩阵Su,i后,可以用Su,i(x,y) 表示方面特征x和方面特征y之间的匹配程度。

(8)
(9)
其中,M表示方面数,S是全局跨域方面特征相关矩阵,Su,i是语义匹配矩阵,bu和bi是用户偏差和项目偏差。
2.3 融入专业度评分的跨域推荐方法
2.3.1 用户专业度
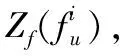
(10)
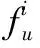
(11)

2.3.2 推荐步骤
(1)首先通过用户评分信息建立联合评分矩阵R。
(2)对联合评分矩阵R进行矩阵分解,分解矩阵后得到用户潜在因子P和项目潜在因子Q。
(3)使用k-means聚类方法对潜在因子P和Q进行聚类。
(4)在计算簇用户对簇项目评分形成跨域粗矩阵前,引入用户专业度,利用式(11)来计算每个簇用户的权重au,其计算公式为式(12)
(12)
式中:N表示该簇中用户数量,Zf(fu) 表示簇用户专业度。
(5)引入专业度权重计算簇用户对簇项目的评分,如式(13)
(13)

(6)在计算集群级别的评分后,可以得到跨域粗矩阵RC,其定义为式(14)
(14)

(15)

(16)
(17)


R*=tR′+(1-t)RC′
(18)
(19)
其中,t∈[0,1]是一个调优参数,随着实验不断进行调整。
2.4 混合跨域推荐
(20)

模型训练中的损失函数定义如式(21)
(21)
式中:*表示源域或目标域,O表示训练集合中包含的元素,λ表示正则化的系数,Θ是训练的参数。
3 实 验
在本节中,首先描述了实验中使用到的数据集,再介绍数据预处理的相关操作和评价指标,然后将CTR-HCDR跨域推荐方法与其它方法进行比较分析。
3.1 数据集和数据预处理
本实验选择在亚马逊审查数据集上进行模型推荐预测的性能评估,在最大的类别中,选择图书、电影和音乐作为3个领域,用户评分的数值为1到5之间的整数。表1给出了实验数据集的详细数据记录。

表1 实验数据集
本实验构建了3个跨域场景,选择图书、电影、音乐3个类别作为3个领域。3个跨域场景分别为“图书->电影”、“电影->音乐”和“图书->音乐”。在“图书->电影”这一跨域场景中,图书域表示源域,电影域表示目标域,冷启动用户表示为在图书域中有过历史交互行为但是在电影域中没有交互行为的用户,在该跨域场景中,推荐的任务是推荐预测冷启动用户在电影域中可能感兴趣的电影,从而进行推荐。针对重叠用户,采用随机抽样策略,选择其中50%的用户作为冷启动用户群体,推荐模型在训练过程中将忽略这些用户在目标域内的交互行为记录。接着对这部分冷启动用户进一步划分:随机抽取30%作为测试集,20%作为验证集。余下50%的重叠用户则构成了模型训练数据集。为了模拟不同比例的重叠用户对推荐准确性的影响,用不同比例的n∈{100%,50%,10%} 来构建训练集,表2报告了3个跨域场景的具体信息以及在不同比例下的重叠用户信息。

表2 跨域推荐场景统计数据
首先对用户和项目的评论文档进行预处理,主要包括:①对各个领域中的评论信息进行数据清洗,剔除所有未曾获得用户评论的数据条目。为了确保数据的有效性,删除交互记录不足15次的用户以及交互次数低于40次的项目;②删除已经停用的单词和高频词(比如出现频率大于0.5的单词);③通过tf-idf的分数挑选前20 000个单词作为词汇表并删除其它单词。
3.2 评价指标
在评价模型性能过程中,选取均方误差(mean square error,MSE)作为性能度量指标,MSE通过量化实际评分与预测评分之间的差异程度,以此衡量推荐系统的准确性,它在许多相关性能评价的工作中被广泛采用,其计算公式如式(22)
(22)

3.3 基线方法及实验设置
实验与以下几种基线方法进行对比实验。
CMF:一种传统的跨域评分推荐方法,利用辅助域中的用户对项目评分信息预测冷启动用户在目标域中评分。
CCBMF:在CMF的基础上,通过加入粗矩阵集群级别建议来聚合未观察到的评分信息,来减少原始评分矩阵的稀疏性。
TARMF:一种改进基于评论的推荐算法,提出了用注意力机制的GRU网络学习用户和项目的特征表示,提高了模型的可解释性。
RC-DMF:一种集成了评论信息与内容特征的跨域推荐模型。该模型创新性地运用了降噪堆叠自动编码器(aSDAE),旨在通过深度学习增强用户和项目的特征表达,并采用多层感知器(MLP)机制,以实现从源域到目标域的映射构建。
EMCDR[11]:通过mapping函数来解决交叉域推荐问题,提出了跨域推荐模型应遵循三步优化:知识获取、知识映射、知识推荐。
ANR[12]:一种前沿的基于评论的单域推荐算法,其通过在目标域中对用户-项目匹配对进行精细化方面特征匹配来训练模型,并运用源域中的评论数据来提升匹配精度,提高推荐的准确性。
针对所有基线方法所涉及的超参数配置,采用网格搜索技术进行调整优化。为了确保实验结果的稳定性,所有基线方法均经过至少5次以上的独立运行与验证。
在实验设置中,采用50个卷积滤波器应用在嵌入表示矩阵上获得上下文特征向量,并将批处理大小设定为256,同时确定滑动窗口大小为3。为了增强模型的泛化能力,训练阶段运用了dropout策略随机忽略小部分的方面特征表示,将dropout的保留率设为0.8,CTR-HCDR模型训练的学习率设为0.001。
3.4 实验结果及分析
本实验在“图书->电影,电影->音乐和图书->音乐”3种跨域场景下进行,实验结果显示了所有对比模型的MSE性能比较,如表3所示。

表3 所有模型在3种跨域场景下的MSE比较
根据表3数据可得,CTR-HCDR方法在3种不同的场景中均优于其它基线方法,特别是在“图书->电影”的跨域推荐场景下,CTR-HCDR的MSE为1.042,比最好的EMCDR模型提高9.25%,在其它两个场景中也同样优于其它对比模型,这表明在评论推荐基础上引入具有专业度的评分推荐能够提高推荐的准确性。同时,随着n值的下降,用于训练的重叠用户数量也随之减少,CTR-HCDR依然保持较好的推荐效果,这说明在评分矩阵中加入粗矩阵能够缓解数据稀疏性问题。实验结果表明,CTR-HCDR方法将评论和评分推荐结合进行混合跨域推荐,不仅能够提高预测的准确性,而且能够有效解决冷启动问题。
在所有对比模型中,CMF在所有评估的表现最差,这是因为CMF仅仅通过联合评分矩阵分解来学习用户表示。CCBMF加入粗矩阵缓解原始评分矩阵稀疏性问题,使其优于CMF模型。TARMF通过优化矩阵分解和基于注意力机制的GRU网络,联合学习评论和评分中的用户项目信息从而得到了不错的推荐效果。RC-DMF模型虽然通过整合评论数据和内容特征实现了良好的推荐,但其依赖自动编码器aSDAE以原始评分向量作为输入。当处理维度接近10万级别的数据集时,模型所需的训练参数规模可达数百万级别,这显著增加了模型收敛的复杂度。而EMCDR是针对两个领域来设计的,当模型扩展到多个领域时就需要找更多组合的mapping函数来确定域和域之间的关系。ANR利用评论数据,通过设计一个注意力机制来学习方面特征表达,考虑到了项目对应方面特征的重要性,最终取得较好的实验结果,说明评论信息和方面特征对推荐具有一定重要性。
实验研究了调优参数t在“图书->电影”场景下,对融入专业度评分的跨域推荐方法MSE性能的影响,如图3所示。
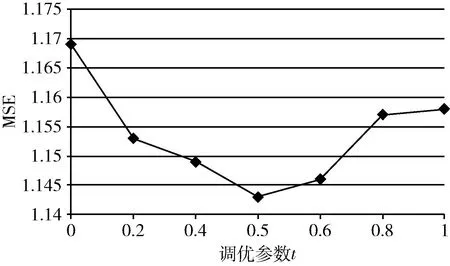
图3 调优参数t在“图书->电影”中MSE性能
图3表明,当调优参数t取0.5时,该方法的推荐效果最好,这是因为在原始评分矩阵上加入集群级别的建议能够有效降低评分矩阵的稀疏性。因此,选择50%的预测评分矩阵R′和50%的集群级预测评分矩阵RC′进行线性积分得到最终预测评分矩阵R*。
最后,分别在3种跨域场景中研究不同调整参数a对模型CTR-HCDR的MSE性能影响,图4显示不同调整参数a在不同场景的MSE性能,从图中可以发现当a=0时,模型主要依赖跨域评分推荐,这说明忽略评论信息的推荐模型,推荐的效果不理想,当a=0.4时,CTR-HCDR模型获得最好的推荐分数,这表明结合评论信息和评分数据能够更好挖掘用户的兴趣偏好。当a为0.2和0.6时,CTR-HCDR的性能略有变化。当a=1时,模型只基于评论信息进行推荐,这意味着只使用评论信息进行跨域推荐是不够的。

图4 不同调整参数a在3种场景的性能
4 结束语
为缓解数据稀疏性问题,提出了一种基于评论文本和融入专业度评分的跨域混合推荐方法,简称CTR-HCDR。该方法不仅利用评论信息实现用户偏好从源域到目标域的有效迁移,而且结合评分信息进行混合推荐,通过生成一个跨域粗矩阵来避免评级矩阵中的数据稀疏性问题,引入专业度细化了评分推荐中不同用户对不同项目进行评分的重要性从而提高推荐效果。通过实验与其它方法进行对比分析,本文提出的CTR-HCDR优于其它方法,一定程度上缓解了冷启动和数据稀疏性问题,具有良好的推荐效果。
猜你喜欢
计算机技术与发展(2024年3期)2024-03-25
系统仿真技术(2022年4期)2023-01-17
北京航空航天大学学报(2022年8期)2022-08-31
读报参考(2022年1期)2022-04-25
科学家(2021年24期)2021-04-25
计算机技术与发展(2020年11期)2020-12-04
中央民族大学学报(自然科学版)(2016年3期)2016-06-27
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
