
基于联邦学习的多技术融合数据交易方法
2024-03-21 08:15:38刘少杰文斌王泽旭
计算机工程 2024年3期
刘少杰,文斌∗,王泽旭
(1.海南师范大学数据科学与智慧教育教育部重点实验室,海南 海口 571158;2.海南师范大学信息科学技术学院,海南 海口 571158;3.中山大学软件工程学院,广东 珠海 519082)
0 引言
数据保护的约束使得数据被限制在不同企业和组织之间,形成了众多“数据孤岛”,难以发挥其蕴含的重要价值,而传统的数据交易方式往往存在数据所有权混乱以及缺乏透明性等问题[1]。联邦学习(FL)的模型训练机制有效地实现了“数据不出门,可用不可见”,在打破“数据孤岛”的同时满足了数据隐私和安全性规约[2],使得数据被合规交易和共享成为可能。联邦学习对未来人工智能等技术的发展和数据安全保护有着重要的推动作用,但缺乏奖励分配机制、存在恶意攻击、网络通信开销大等问题对联邦学习应用于数据交易场景有着显著的影响[3]。因此,对联邦学习框架的设计和完善成为学术界和工业界亟待解决的热点问题,其研究需求也应运而生。
当联邦学习实际应用在数据交易场景中时,需要模型聚合服务端与各个数据供给方训练端间进行不间断的模型权重数据同步,这带来了巨大的通信开销[4-6],并随着数据供给方的数量和迭代次数增加而陡增,不适用于多方参与的复杂数据交易场景。此外,联邦学习中缺少用于数据供给方贡献度评估的方法,存在各方利益分配策略不明确、缺少有效的激励机制的问题[7-8]。同时,利益分配数据依赖中心化的存储或任务需求的发布者,缺少透明性和可信性,从而降低了参与方的积极性[9]。
数据交易场景中仅仅依靠联邦学习技术将面临众多的挑战,为此,本文提出一种基于联邦学习的多技术融合数据交易方法(MTFDT)。该方法能够在缩短通信时间损耗和增强激励机制可靠性的同时,使得交易过程数据可溯源和不可篡改,提高服务质量。本文主要贡献总结如下:
1)以可信执行环境(TEE)技术为依托,结合沙普利值提出一种用于数据供给方贡献评估的有效机制,解决模型评价数据集来源问题,使得数据交易过程中贡献度量和利益分配更加公平。
2)将树型网络拓扑结构应用于联邦学习模型数据同步过程,提出一种并行化模型权重参数同步算法,降低训练过程中的通信开销,从而提高可扩展性,使得联邦学习可应用于包含更多参与方的复杂数据交易或共享场景。
3)引入联盟链技术并通过设计智能合约进行贡献数据和训练数据存储,利用其不可篡改和去中心化特性保证过程数据的安全性,使得数据交易过程透明、可信任。同时,结合星际文件系统(IPFS)实现模型数据存储,避免大数据上链造成存储和通信负担,提高数据交易效率。
1 相关工作
数据安全保护政策、法律法规的颁布和实施使得隐私计算成为了当下研究的热点,联邦学习作为隐私计算中的代表性方案也受到了广泛的关注,但对于联邦学习应用于数据交易场景中的利益分配机制、模型训练效率和安全性等方面的研究仍处于初期阶段。文献[10]针对传统联邦学习存在的激励机制不明确和依赖于单点服务器的问题,创新性地将区块链技术引入到联邦学习过程中,以区块链网络代替中央节点,加入了相应的验证和奖励机制,并对加入区块链所带来的延迟问题和分叉现象进行了优化。虽然该方法一定程度解决了现存的部分问题,但其基于挖矿的奖励分配策略和模型同步方案也极大地提高了训练成本。为了进一步优化奖励策略并提高可靠性,文献[11]提出一种基于反复竞争思想的利益分配方案,并通过以太坊进行实现。该方案以投票的方式来体现前轮各参与方对模型优化的贡献,同时参与者各自选择前轮较优的k个模型权重进行聚合作为新一轮的本地模型初始状态。该方案虽然使得利益的分配变得具体化,但增加了参与方的计算和通信成本。文献[12]提出一种带有训练评价指标的联邦学习激励机制模块,通过对提交模型进行测试并与初始状态对比来反映参与方的贡献度,一定程度上提高了数据交易中利益分配的合理性,但其评估方法仅考虑模型相对初始状态的提升,并未考虑模型为全局模型聚合带来的整体效益。文献[13]在增加模型评价指标的基础上进一步引入沙普利值以从整体上度量参与方模型的贡献度,提高报酬分配的公平性。然而,文献[12-13]均缺少对于模型评价过程中所使用数据集来源的研究和分析。文献[14]对模型评估所需要的数据集来源问题进行了讨论,提出一种新的联邦学习算法Fed-PCA,以达到在没有测试数据集的情况下完成贡献度评估的目的。
对于联邦学习应用于数据交易场景时的通信成本,文献[15]提出一种基于群体划分的策略,通过将所有参与者进行群体划分逐步完成模型聚合,但该策略增加了训练过程的复杂度。为解决这一问题,文献[16]提出一种具有委员会共识的联邦学习框架,通过动态地选举委员会成员作为模型的验证方和评价方,达到k倍交叉验证的效果,同时也避免了全部节点都参与验证带来的通信开销。然而,该方案为了故障验证和回退,将模型数据存储在区块链中,降低了链节点交易同步的效率,不利于实际的应用。为了提高联邦学习过程的效率,文献[17]将许可链融入框架中,在避免依靠公链造成资源浪费的同时,利用差分隐私来进一步提高训练中数据的安全性,但未能考虑区块链在大型数据存储中的不适用性。优化网络拓扑结构是提高联邦学习通信效率的有效方式[18],分散的节点部署往往比星型拓扑具有更好的效果[19]。文献[20]引入边缘聚合服务器来缓解星型拓扑结构中央聚合服务器的带宽压力。文献[21]使用Gossip 协议来并行分段传输权重参数,从而提高训练节点间模型权重数据的同步效率,但为了保证聚合效果,增加了整体的通信次数且训练效果不够稳定。目前,较多研究工作的框架设计缺乏对于存储成本的考虑,不具备较高的可行性。
MTFDT 与现有方法的综合对比如表1 所示。

表1 MTFDT 与现有方法的综合对比Table 1 Comprehensive comparison among MTFDT and existing methods
2 多技术融合的数据交易方法
数据交易流程中利益分配的公平性、合理性将直接影响数据需求方和数据供应方参与数据交易或共享服务的积极性。本文以联邦学习技术作为服务基础,结合联盟链、星际文件系统和可信执行环境等多种技术,构建MTFDT 框架。
2.1 整体介绍
MTFDT 整体工作流程如图1 所示。其中:假设所有参与数据交易任务的数据供给方为P,Pi为第i个供给方,n为参与数据交易任务的供给方总数;每个供给方Pi拥有本地数据集Di;数据需求方为R,其发布的数据交易任务为E;第r轮全局模型为Gr;供给方本地训练得到的模型为。

图1 MTFDT 工作流程Fig.1 Workflow of MTFDT
在数据交易过程中,数据需求方根据自身的需求构建联邦学习任务请求,任务请求包括模型结构、评估指标和目标以及预算信息,该任务请求通过数据需求方调用服务接口的方式发送到区块链中并由数据交易服务智能合约处理;随后数据供给方查询链上数据交易任务,并结合本地数据集属性提交选择参与训练任务的请求;之后数据需求方确定参与联邦学习任务的数据供给方,通过可信执行环境密钥协商方式收集数据供给方测试数据集(用于贡献量化评估和利益分配计算);模型聚合服务器根据数据参与方信息构建树型拓扑交互节点树,并并行同步分发联邦学习模型数据,进入联邦学习训练阶段;模型聚合服务器收集数据供给方训练结果,并进行贡献量化评估,利用联盟链完成奖励分配和过程模型等数据存储。
2.2 利益分配策略模块设计
利益分配策略的公平公正是促进数据交易可持续进行的重要基础和维护参与方利益的保障,但目前缺少对于数据交易过程中所使用效果评价数据集来源的研究。为此,本文在MTFDT 中基于可信执行环境和沙普利值设计一种新的贡献度量化与利益分配机制,具体工作流程如图2 所示。

图2 MTFDT 中贡献评估与利益分配流程Fig.2 Contribution evaluation and benefit distribution process in MTFDT
在数据交易任务训练前,参与任务的数据供给方Pi与模型聚合服务器的可信安全区中的程序进行远程认证并完成密钥协商[25],得到加密密钥Ki,Pi将本地测试数据使用Ki进行加密得到测试数据密文,并将发送给模型聚合服务器存储;当Pi在本地完成计算后,将新的梯度信息发送给模型聚合服务器中非可信区域运行的模型梯度收集服务;收集服务发起可信服务调用,并完成所有的梯度信息传输;可信安全区中的贡献计算服务通过排列聚合得到当前轮的聚合模型集合,同时使用协商密钥Ki解密测试数据,并使用测试数据与数据需求方数据交易任务中预设的评估方法完成模型效用评估;在得到聚合模型集合评估结果后,使用沙普利值对数据供给方Pi的贡献值进行计算[26]。
在现有的使用联邦学习进行数据交易的研究中,多以数据供给方训练所得新模型的评价指标值f相对初始模型fg的提升作为效用评估Q的主要依据[12],计算过程如式(1)所示:
然而该方式在数据规模不均衡的情况下,利益分配存在不公平的可能性。当以准确率作为评价指标时:1)数据供给方训练数据集的增大与其训练所得模型准确度的提升不成等比例关系,反之亦然;2)数据供给方训练数据集的增大与其训练模型所耗费的资源即代价成等比例关系,反之亦然。由此可知,在使用联邦学习进行数据交易的过程中,单纯基于评价指标相对初始模型的提升来进行效用评估继而完成贡献度计算的方式并不完全合理,在数据集质量相当的情况下,使用更多数据进行训练的参与方并不能获得等比例的收益。由于在训练过程中,数据供给方用于训练的数据量是不可知的,因此训练成本难以得到可信且有效的计算。
综上,本文所提出的模型训练效用评价方法在考虑相对初始模型提升的前提下,综合考虑了模型在所有新模型中的综合水平,计算方式如式(2)所示:
其中:a为奖惩调节系数,按式(3)动态调整和分别为当前轮所有聚合模型评价指标的均值、最大值和最小值。
当数据供给方训练得到的新模型性能低于全局平均模型时,将受到惩罚,反之则获得奖励,奖惩调节系数则能够在模型训练后期性能提升较小时放大差异,使得提供较多数据集的供给方能够得到更高的评估。
由于联邦学习过程具有新模型由所有本地模型聚合得到的特性,因此通常会存在以下情况,即第r轮训练得到的所有本地模型效果都比当前轮初始模型差,但其聚合所得到的新模型效果优于初始模型。在这种情况下,传统的贡献计算方法将不再适用,缺失了对本地模型在聚合时对全局模型效果提升所起作用的评估。由此,本文引入沙普利值来计算本地模型在全局模型聚合时所做的贡献,从而提高利益分配的可靠性。
数据供给方Pi在某轮次训练中的贡献值计算方式如下:
其中:S为参与数据交易任务供给方集合P在当前轮产生的聚合模型集合的任意子集;PPi为不包含Pi训练所得到模型的聚合子集。在交易任务完成后,数据供给方Pi获得的收益计算公式如下:
其中:C为达到目标精度进行的训练总次数;B为数据需求方发布交易任务时的预算总额。
2.3 模型同步模块设计
联邦学习中的通信网络拓扑结构通常是星型结构,即存在一个中心模型聚合服务器和成百上千个训练端(数据供给方),如图3 所示。对于同步联邦学习,模型聚合服务器需要等待所有的训练端返回新一轮的模型更新参数,并聚合得到新的全局模型权重,之后将新的全局模型权重一次性分发给所有的训练端[27]。模型权重参数文件分发将为服务端带来巨大的带宽压力。同时,由于大多数数据交易中所要训练的神经网络模型往往拥有巨大的参数量,模型同步带来了较高的通信成本[28],因此也限制了训练端节点的数量,降低了可拓展性。

图3 星型拓扑结构联邦学习模型数据同步Fig.3 Data synchronization of federated learning model with star topology structure
假设模型权重文件大小为msize,各个节点带宽为d,参与训练的节点数量为n,2 个节点间建立通信的时间损耗为l1,则星型拓扑结构下联邦学习每轮模型同步所需要的时间Tstar为:
为了减缓模型分发给模型聚合服务端所带来的带宽压力,降低同步时间对联邦学习训练造成的影响,进而提高数据交易效率,本文在MTFDT 中设计一种新的权重数据同步算法。该算法通过切割权重文件和构建交互节点树的方式实现参数数据并行传输,其中模型聚合服务端与训练端关联关系如图4所示。
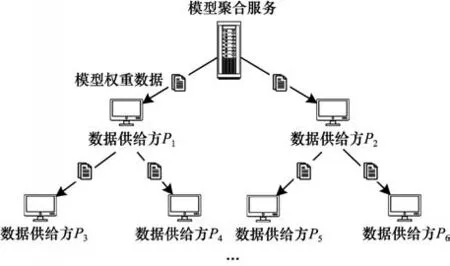
图4 树型拓扑结构联邦学习模型数据同步Fig.4 Data synchronization of federated learning model with tree topology structure
2.3.1 算法流程
模型同步模块的算法流程具体如下:
步骤1模型聚合服务端P0将第r轮模型参数权重文件Gr切割为均等的k份并计算整体权重文件哈希值hr和所有子文件哈希值集合
步骤2聚合服务端选择当前迭代轮次的训练节点集合Pr,Pr={P1,P2,…,Pn},利用n个训练节点信息和聚合服务端信息构建多叉树Tr,Tr={P0,P1,…,Pn},其中,将P0作为多叉树的根节点。
步骤3将Tr、hr和Hr合并得到第r轮次迭代配置信息cr,其中,cr={hr,Tr,Hr},并将cr发送给集合P中所有训练节点。
步骤4聚合服务端按序将k份模型权重子文件根据Tr中的结构信息发送给其子节点,子节点在收到文件wi后立即向后续子节点发送并同时接收父节点发送的下一份模型权重子文件wi+1。
步骤5重复步骤4,计算各个子文件哈希值与cr中对应子文件哈希值进行对比,若不相同或父节点无响应,则根据cr向其他祖父节点请求,直至所有训练端接收到全部正确的权重文件集合
步骤6所有训练端合并子文件集合得到新一轮的模型权重参数文件,模型同步结束。
同步过程中节点间文件传输流如图5所示。在t时刻,根节点向第1 层训练节点发送权重模型子文件w1,在2t时刻,第1 层训练节点在接收根节点发送的子文件w2的同时向第2 层节点发送子文件w1,从而实现模型参数文件同步的并行数据传输,极大地提高了效率,降低了时间消耗。
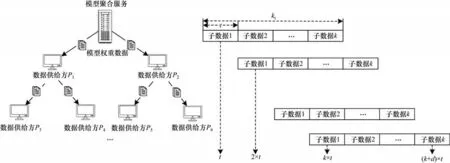
图5 树型拓扑结构联邦学习模型同步过程Fig.5 Synchronization process of federated learning model with tree topology structure
2.3.2 算法复杂度分析
假设模型权重文件切割后得到的子文件个数为k,构建的节点树T中非叶子节点出度为o,迭代配置文件分发所需时间为l2,则所提出的联邦学习模型权重同步算法完成每轮权重参数分发所需要的时间Ttree为:
通过分析式(6)和式(7)可知,星型拓扑结构下传输伴随节点数的增加,联邦训练过程中的模型同步时间消耗也将呈线性增加。由于节点间建立链接的时间l1和发送迭代配置数据所需的时间l2占比很小,因此本文所提出的同步方法伴随训练端数量的增多同步所需的时间将以对数的形式增加,更加适用于大规模的联邦学习数据交易场景。此外,所提出的方法对于模型聚合端的带宽要求更低。
2.4 交易过程数据存储模块设计
区块链通过点对点传输和共识算法等技术来实现分布式账本,具有去中心化、不可篡改、记录可追溯等特点,适用于金融、溯源等多种应用场景。在数据交易过程中,参与方之间互不信任,为了保证数据交易过程中利益分配数据和模型数据的可信性和存储的安全性,本文在MTFDT 中设计一种基于区块链与IPFS 相结合的交易过程数据存储机制。
2.4.1 利益分配与追责溯源智能合约
依据数据交易服务的需求对合约功能进行抽取,划分为权限层、数据层、服务层等3 个部分,如图6 所示。其中,权限层通过地址映射来实现账户的权限约束,从而达到数据交易服务访问的细粒度控制。
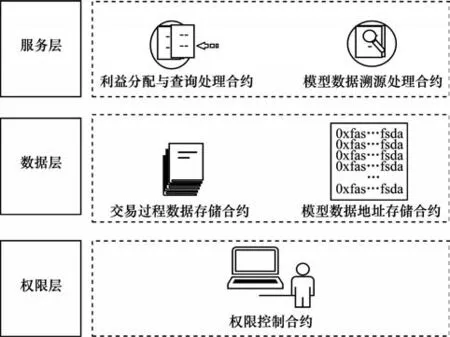
图6 数据交易场景智能合约设计Fig.6 Smart contracts design for data transaction scenario
通过将数据存储与数据操作进行分离的方法来提高合约的可拓展性和易维护性,在顶层服务需求发生变化时,只需要对服务层中的功能函数进行新增或修改,从而避免了对底层数据的影响。为了满足数据交易利益分配计算和模型数据溯源需求,智能合约中的主要函数设计如表2 所示。
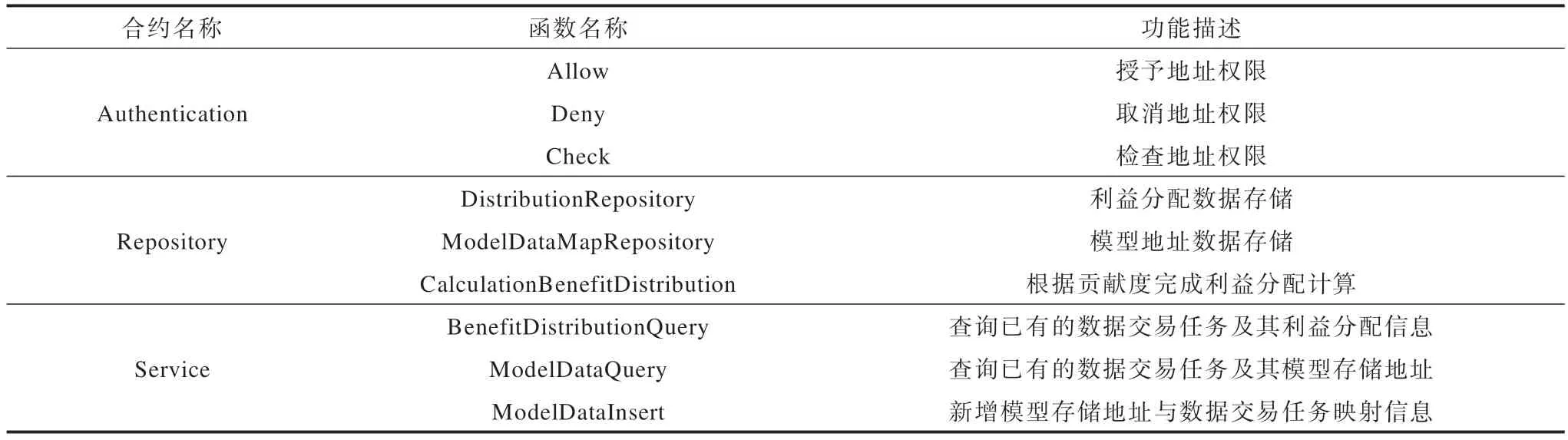
表2 智能合约函数设计Table 2 Smart contract function design
2.4.2 数据存储设计
区块链中交易的大小是影响系统运行效率的一个重要因素。数据交易场景中往往包含了大量的模型权重信息,具有较大的数据量,若将其全部存储于链中,将会对系统的运行效率造成影响,从而降低数据交易服务质量。为了缓解数据量对区块链网络的压力,本文在MTFDT 中进行数据存储机制优化,如图7 所示。
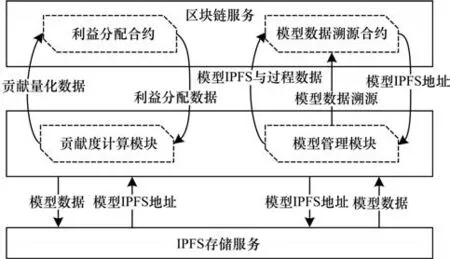
图7 数据存储设计Fig.7 Data storage design
在数据交易过程中,交易服务模块在收集数据供给方发送的最新模型数据后,将模型数据通过IPFS 接口完成上传,之后通过调用区块链智能合约把返回的地址信息与对应的数据供给方信息以及所属的数据交易任务信息一同存储于链上;在数据交易任务模型训练过程结束后,数据需求方向数据交易服务模块发送模型申请请求,在链上完成地址信息查询后通过IPFS 接口完成下载。基于该存储机制,在引入区块链技术提高数据交易过程去中心化和保证数据交易过程模型数据可溯源的同时,避免较高的服务成本,提高可拓展性和效率。
2.5 方案复杂度分析
MTFDT 数据交易方案相比直接使用传统的联邦学习进行数据交易整合了多个模块,因而增加一定的复杂度。为了能够更好地说明方案设计中对复杂度的考量以及额外计算量的必要性,对其分析如下:1)利益分配策略模块中为了实现对数据供给方贡献度的精确计算,增加了评估过程,其时间消耗与数据交易任务参与方数量正相关;2)模型同步模块在维护拓扑关系过程中带来了一定的复杂度,但整体时间消耗低于原有数据同步方法;3)数据存储模块中引入了区块链服务,相比直接使用数据库进行数据存储增加了复杂度,在设计上进一步引入了分布式存储来进行优化。综上,MTFDT 方案的整体计算量相对可控,能够以较低的复杂度增加来提高数据交易的安全性和可靠性。
3 实验设计与性能评估
本文基于CIFAR-10 公开数据集进行了仿真实验,并通过调整变量参数对所提方案中利益分配合理性以及模型同步效率进行对比分析。
3.1 利益分配策略效果评估
为了更好地证明本文所提激励机制的公平性和有效性,基于CIFAR-10 数据集使用卷积神经网络(CNN)模型进行了实验验证。使用3个数据供给方节点(命名为A、B、C)参与数据交易过程,将数据集进行等比例划分,各个节点的数据之间符合独立同分布。模型训练效果评估及贡献度占比如表3、表4所示。
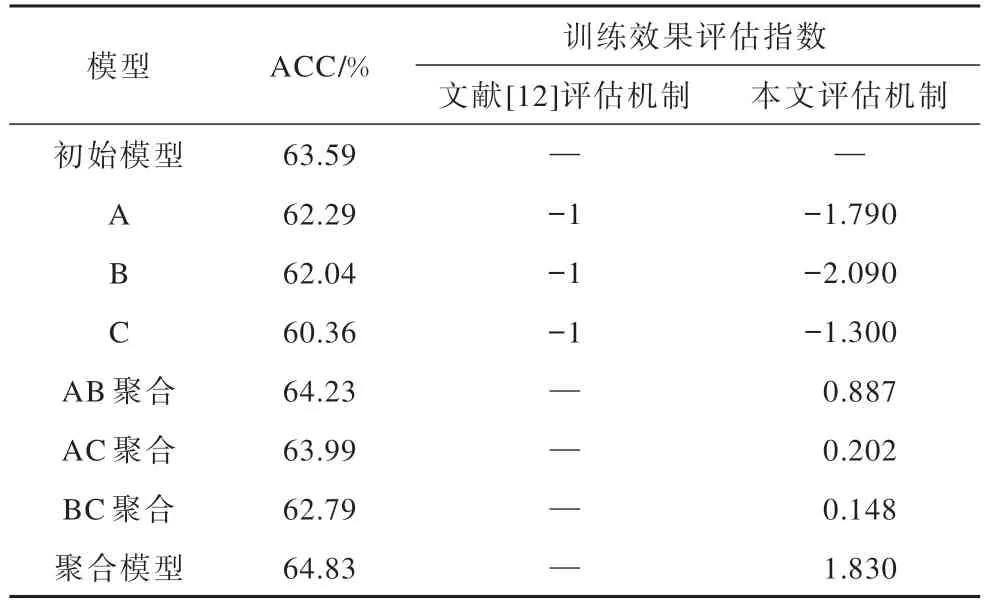
表3 模型训练效果评估对比Table 3 Evaluation and comparison of model training effects

表4 模型训练贡献度对比Table 4 Comparison of model training contribution %
表3 列出了某轮数据交易过程中的联邦学习训练数据,该模型训练中以准确率(ACC)作为评估依据。根据该轮数据分别使用文献[12]所提出的评估机制和本文所提出的训练效果评估机制进行计算,并进一步得到贡献度数据,如表4 所示。从结果中能够看出,文献[12]评估机制并不能适用于该情况,而本文MTFDT 中的模型训练效果评估机制由于综合考虑了模型在聚合过程中所做出的贡献,从而能够有效地对训练效果进行评估,提高了数据交易中利益分配的可靠性。
为了进一步分析本文所提出利益分配策略的有效性,使用多个模型和公开数据集进行仿真评估,实验结果如表5 所示。可以看出,在独立同分布且数据集等比例划分的情况下,本文所提出的评估机制贡献评估结果更加符合实际情况。
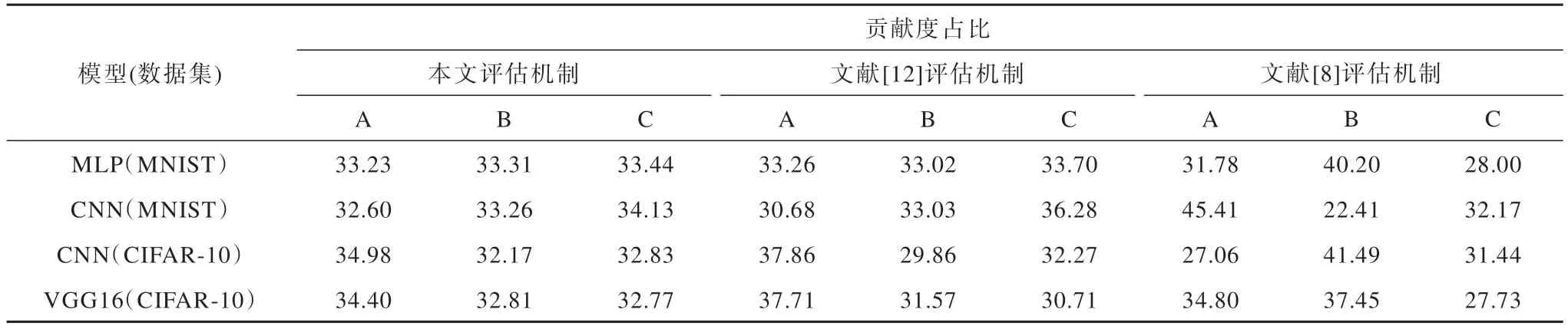
表5 多场景下数据交易贡献度计算综合对比Table 5 Comprehensive comparison of data transaction contribution calculation in multiple scenarios %
为了分析所提出的评估机制在数据集规模不均衡时的表现,进一步验证其应用于数据交易过程中利益分配的公平性。将数据集分别按照1∶1∶1、5∶3∶2和7∶2∶1 进行划分,各个节点的数据之间符合独立同分布。在不同比例数据划分情况下,模型训练达到收敛时各节点的贡献度计算结果如图8 所示。可以看出,贡献度占比与数据集规模比例相近,说明本文所提出的贡献度量方法能够保证收益与成本成比例变化,更好地激励供给方使用更多的数据参与到数据交易过程中。实验结果验证了本文所提激励机制的可行性。

图8 不同规模数据集分布下贡献度占比结果Fig.8 Contribution ratio results under different size dataset distributions
3.2 模型数据同步性能对比
基于CIFAR-10 数据集,使用VGG16 模型对星型拓扑结构模型同步与本文所提出的模型同步方案进行效率对比,其实验中涉及的参数设置如表6所示。

表6 实验参数设置Table 6 Experimental parameter settings
在表6 的设置下对比不同参与方数量下模型同步所消耗的时间情况,实验结果如图9 所示。可以看出,随着参与方节点数量的增多,模型同步过程所消耗的时间也在增加。在相同情况下,本文所提出方案相比星型拓扑结构数据同步时间消耗最多减少了34%,并随着节点数量的增加效果更为显著。

图9 不同节点数目条件下模型同步时间消耗对比Fig.9 Comparison of model synchronization time consumption under different number of nodes
为了进一步分析方案的有效性,通过调整聚合服务端带宽大小对比不同方案模型同步时间消耗情况,实验结果如图10 所示。可以看出,随着带宽变小,同步时间逐步增加,但本文所提出的模型同步方案相对星型拓扑的增加趋势更加缓和,在同等情况下,时间消耗最大减少了36%。由此可以证明,本文所提方案对参与数据交易节点的带宽要求更低,实验结果与理论分析一致。
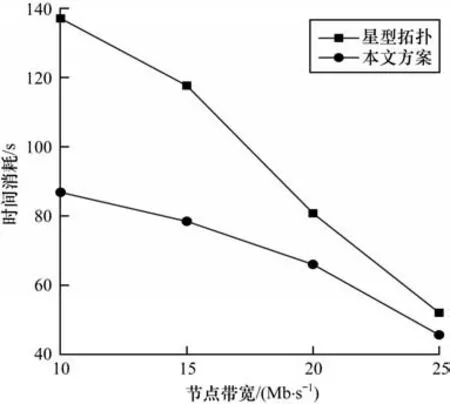
图10 不同带宽条件下模型同步时间消耗对比Fig.10 Comparison of model synchronization time consumption under different bandwidth conditions
上文通过5 组实验对所提出的MTFDT 数据交易方法中的贡献计算和模型同步效果进行了评估,实验结果表明,MTFDT 能够满足数据交易场景的综合需求。
4 结束语
针对联邦学习在数据交易和共享场景应用中存在的利益分配、同步开销和中心化问题,本文深入剖析其关键流程和机理,提出一种多技术融合的数据交易方法,有效地增强了数据交易过程中参与方贡献评估的公平性,减少了模型同步过程时间消耗,并结合区块链和星际文件系统等技术提高了可靠性和安全性。最后,通过设计对比仿真实验验证了所提方案在数据交易场景中的有效性。未来工作中将进一步探索异步联邦学习场景下的模型同步方法和适用于非独立同分布数据集的激励机制。
猜你喜欢
统计与决策(2023年13期)2023-07-21 08:49:28
——基于供需双方的进化博弈
乡村科技(2022年1期)2022-04-11 11:58:18
家庭影院技术(2020年10期)2020-12-14 07:54:16
看世界·学术下半月(2020年7期)2020-09-10 09:06:08
商情(2020年2期)2020-02-14 05:53:18
今日财富(2019年30期)2019-11-16 11:02:46
家庭影院技术(2019年7期)2019-08-27 02:42:06
职工法律天地·下半月(2016年9期)2016-11-30 10:23:53
新作文(小学中高年级版)(2015年10期)2015-12-22 02:28:50
俄罗斯问题研究(2013年1期)2013-03-11 15:43:59
