
融合词性语义扩展信息的事件检测模型
2024-03-21 08:15:38严海宁余正涛黄于欣宋燃杨溪
计算机工程 2024年3期
严海宁,余正涛*,黄于欣,宋燃,杨溪
(1.昆明理工大学信息工程与自动化学院,云南 昆明 650504;2.昆明理工大学云南省人工智能重点实验室,云南 昆明 650504)
0 引言
事件检测(ED)是事件抽取的关键步骤,目标是在给定句子中识别事件触发词并将其分类为预定义的事件类型。触发词是最能清楚表达事件核心含义的词,通常是一个名词或者动词[1]。事件检测作为自然语言处理领域的一项重要任务,被广泛应用于知识图谱[2]、自动内容抽取[3]等下游任务。
事件检测任务依赖于识别出的触发词进行事件类型分类[4-5]。现有多数数据中触发词的标注严重不平衡,使模型过度拟合密集标注的触发词数据,而稀疏标记的触发词数据往往得不到有效训练,导致触发词为稀疏标记或未出现过的词时模型性能不佳。
在以下句子S1、S2 中有下划线的词语表示触发词:
S1:EU will release 20 million euros in emergency humanitarian aid to Iraq.
S2:EU will disburse 20 million euros in emergency humanitarian aid to Iraq.
可以看出,在句子S1 中,密集标注触发词数据“release”被模型正确识别后,句子被分类为正确的事件类型“Transaction:Transfer-Money”,而在将句子S2 中密集标注触发词“release”替换为稀疏标记的同义触发词“disburse”后,不改变句子原本表达的含义,模型却不能识别出正确的事件类型。
针对以上问题,现有研究认为生成更多的训练实例是一种解决方案。一些方法通过引导扩展出更多的训练实例[6-8],另一些方法使用更多数据进行远程监督[9-11]。但是这些方法要么生成同质的语料库,要么受制于低覆盖率的知识库,导致数据本身分布不均,训练的模型存在内置偏差[12],且在稀疏标记数据上性能仍然较差。笔者认为主要原因为稀疏标注数据的触发词难以识别,导致其事件类型不能被正确分类。为此,需要对词粒度扩展信息进行探索,在不增加训练实例的条件下,缩小候选触发词的范围,并对候选触发词进行语义扩展,从而提升触发词识别能力。同时,融合不同粒度的语义信息,增强语义表征的鲁棒性,以缓解标记数据稀疏的情况。
本文提出一种融合词性语义扩展信息的事件检测模型(FESPOS-ED)。首先,通过词性筛选模块寻找特定词性的词,确定候选触发词的位置。无论是稀疏标记还是未见过的触发词,都会以极大概率包含在特定词性中,因此能更好地识别候选触发词且不受触发词样本数量的限制。然后,对候选触发词位置进行语义扩展,挖掘候选触发词上下文丰富的词粒度语义信息。最后,融合句子粒度语义信息,增强语义表征的鲁棒性,进一步提升事件检测准确性。
本文主要贡献如下:
1)建立一种融合词性语义扩展信息的事件检测模型,结合词粒度语义扩展信息及句子粒度语义信息,提升语义表征的鲁棒性,从而缓解稀疏标记数据带来的不良影响。
2)利用词性语义扩展方法,在缩小候选触发词范围的同时扩展候选触发词在当前语境下的语义信息,能更好地识别候选触发词且不受触发词样本数量的限制。
3)在实验数据集上的F1 值相较于基线模型有明显的提升。
1 相关工作
在早期研究中,事件检测任务被视作基于触发词的分类问题,重点在于收集全局统计特征作为知识来源或决策基础[13-14]。随着深度学习的发展,许多研究利用深度神经网络来学习输入序列的上下文表征信息。在将文本上下文信息嵌入低维空间后,再利用这些特征识别触发词和事件类型。根据上下文信息的不同,可以分为结构化上下文信息和非结构化上下文信息。引入结构化上下文信息通常是指引入事件参数信息[15-16],利用结构化文本描述事件信息。引入非结构化上下文信息通常是使用卷积 神经网 络(CNN)[17-18]、图卷积 神经网 络(GCN)[19-21]、预训练语言模型[10,22-23]等方法捕捉事件信息。
在针对不平衡数据标注的研究中,通常主要有两类平衡思路:一类是从数据方面进行平衡;另一类是从分类损失上进行平衡。在数据方面的平衡策略中,研究者们利用半监督或弱监督的方法自动扩充训练实例。文献[6]依靠复杂的预定义规则从并行的新闻流中引导产生更多训练实例。文献[7]采用WordNet 和基于规则的方法来生成没有事件类型标签的开放域数据。文献[10]利用远程监督方法,基于触发器的潜在实例发现策略和对抗性训练方法来协同获得更加多样化和准确的训练数据。文献[11]利用远程监督从知识库中现有的结构化事件知识中生成大规模数据。在分类损失方面的平衡策略中,研究者们也进行了大量研究。文献[21]提出一个带有解耦分类重新平衡机制的语法增强型GCN 框架,根据样本数量模拟负幂律分布重新调整分类器权重。文献[24]提出的损失通过鼓励少数类别拥有更大的边际来扩展现有的软边际损失。文献[25]利用贝叶斯不确定性估计计算样本和类别的不确定性来度量最大边距,以缓解类别不平衡造成的影响。
2 融合词性语义扩展信息的事件检测模型
针对标记数据不平衡导致稀疏标记数据不能得到有效训练的问题,构建一种融合词性语义扩展信息的事件检测模型,结构如图1 所示(彩色效果见《计算机工程》官网HTML 版),主要分为句子粒度语义编码、词粒度语义扩展、词粒度-句子粒度语义融合3 个模块。
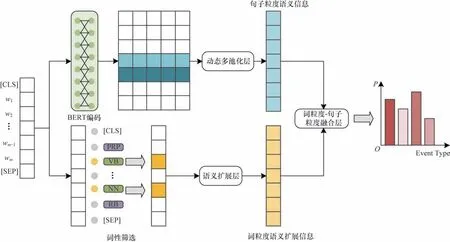
图1 融合词性语义扩展信息的事件检测框架Fig.1 Framework of event detection integrating part of speech semantic extension information
2.1 句子粒度语义编码
首先,利用Word Price Model 标记化获得输入文本序列中token 和位置嵌入的总和,这一做法可以确保为任意字符序列生成确定性的切分,具体计算过程如下:
其中:Sw表示输入文本序列;m表示文本序列中包含的单词数量;St表示输入序列中token 序列;n表示序列中包含的token 数量。
然后,将文本序列Sw输入BERT,进一步编码得到隐藏状态,具体表示如下:
其中:ht=(h1,h2,…,hn-1,hn)表示文本序列中每个token 对应的隐状态;表示BERT 中的可学习参数。
接着,分别提取每个token 对应隐藏状态左右两端的上下文特征信息,并利用动态多池化保留每个token 左右两部分的最大值。与传统的最大池化相比,动态多池化可以在不丢失最大池化值的情况下保留更多有价值的信息[9],具体计算过程如下:
其中:[;]表示拼接 操作;max(∙)表示最大池化操 作;E1表示第j个token 左边部分上下文信息特征;E2表示第j个token 右边部分上下文信息特征;Es表示句子粒度语义特征。
2.2 词粒度语义扩展
2.2.1 词性筛选
利用词性标注工具Stanford CoreNLP 对输入序列进行筛选,得到满足词性的词语位置,具体表示如下:
其中:SSet,p表示词性集,具体包括动词词性和名词词性;表示第i个单词 的词性;LLoc,i为0 表示该 位置的词语不满足词性;LLoc,i为1 表示该位置的词语满足词性,即候选触发词位置。
2.2.2 语义扩展
在得到候选触发词位置后,为了扩展候选触发词在当前语境下的语义信息,受到完形填空任务[26]的启发,使用掩码预训练语言模型对每个候选触发词位置进行覆盖。
首先,在输入文本序列中加入占位符,每次只对一个满足词性的候选触发词位置进行覆盖,具体计算过程如下:
然后,利用掩码预训练语言模型对带有占位符[MASK]的文本序列Smask进行预测,具体表示如下:
其中:Hmask表示带有占位符的文本序列Smask的隐藏状态;Pmask表示预测单词的概率分布。这里模型得到的预测单词表征是固定的,不会跟随模型一起进行训练。如果预测单词表征是动态的,那么每一次训练得到的词粒度语义特征都会出现变化,当遇到一些未被训练的输入序列时仍会使用之前产生的表征,这样可能会导致错误的识别。
最后,取Top-k预测单词的表征作为词粒度语义扩展特征,具体表示如下:
其中:Largestk(∙)返回候选词中最大的k个元素,k是超参数;K=(Κ1,K2,…,Kk)表示Top-k预测单词的表征;Ew表示词粒度语义扩展特征。
2.3 词粒度-句子粒度语义融合
在得到句子粒度语义特征Es和词粒度语义特征Ew后将其进行融合,得到最终鲁棒的语义表征,具体计算过程如下:
其中:[;]表示拼 接操作;MLP(∙)表示多 层感知 机;代表多层感知机中的可学习参数;E表示最终鲁棒的语义表征。
将最终的融合语义特征经过Softmax 操作得到最终的事件类型概率分布,并根据分布概率判断输入序列的事件类型,具体计算过程如下:
其中:P表示预测事件类型概率分布;L 表示损失函数;qi是真实标签的One-hot 编码。
3 实验与结果分析
3.1 数据集
在实验中采用ACE2005[1]和KBP2015[27]语料库作为数据集来评估所提模型。ACE2005 数据集是事件检测任务广泛使用的一个基准数据集,其中包括来自不同领域的文档集合,例如文本新闻、广播对话、博客等。该数据集包含599 个文档并定义了34 种事件类型,同时提供对应的事件触发词、事件参数和事件类型注释。为避免数据预处理对模型性能产生较大影响,采用与已有研究[17,22,28]相同的方式分割数据,训练集、验证集和测试集的文件数量分别为529、30 和40。KBP2015 数据集 是来自2015 年文本分析会议(TAC)的Nugget 事件检测的评估数据。该数据集包含360 个文档,定义了39 种事件类型。采用与官方[27]相同的数据分割方式,训练集和测试集分别包括158 个文档和202 个文档,并将训练集的一个子集作为验证集,约占训练集的20%。
以ACE2005 数据集为例,该数据集中数据标注情况存在不平衡现象,统计情况具体如图2 所示。位于头部的“Conflict:Attack”事件类型的触发词数量远大于位于尾部的事件类型总和,其中尤为显著的是数量排名最后5 类事件类型中的触发词数量仅为个位数。
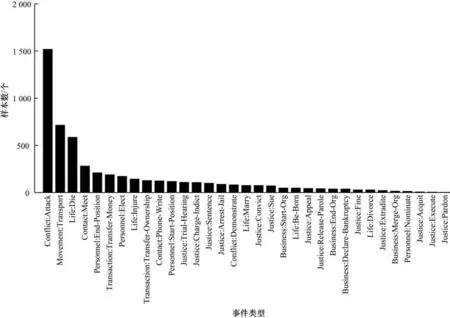
图2 ACE2005 中事件类型样本大小分布Fig.2 Sample size distribution of event type in the ACE2005 dataset
触发词是句子中最能清楚表达事件核心含义的词,通常是一个名词或动词[1]。以ACE2005 数据集为例,对数据集中的触发词词性进行统计,具体结果如图3 所示,主要包括单数名词形式(NN)、复数名词形式(NNS)等名词词性,过去分词(VBN)、动词过去式(VBD)、动词基本形式(VB)、动名词和现在分词(VBG)等动词词性以及形容词(JJ)词性。由统计结果可以看出,触发词中名词和动词约占总数的92%。因此,对动词或名词词性的特定位置进行语义扩展可以缩小候选触发词范围,并且不受数据集中样本数量的影响。

图3 ACE2005 数据集触发词词性统计Fig.3 Statistics of ACE2005 dataset trigger part of speech
3.2 参数设置
所提模型实现基于PyTorch 框架,利用两个NVIDIA 3080Ti-12 GB GPU 进行训练。在实验中采用Adam 作为优化器,参数设置如表1 所示。
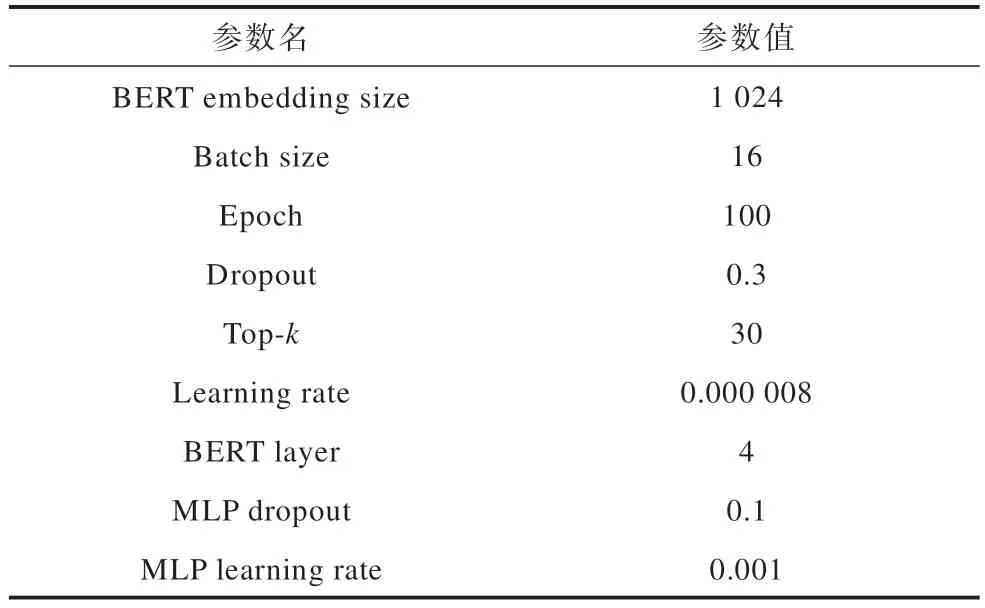
表1 实验参数设置Table 1 Experimental parameter setting
如上文所述,所提模型分为句子粒度语义编码、词粒度语义扩展、词粒度-句子粒度语义融合3 个模块,只有词粒度语义扩展模块中的参数不参与更新,不具有梯度,其余模块参数均具有梯度。词粒度语义扩展模块参数不具有梯度的原因为:词粒度语义扩展信息旨在扩展符合当前输入序列上下文语义信息的词粒度信息表征,而不能受到其他输入序列表征的干扰,否则会与当前语境产生偏差,导致错误的识别。
3.3 评价指标
实验选取事件检测研究中常用的3 个评价指标:
1)准确率(P)表示正确预测的事件在总预测的事件中的比例。
2)召回率(R)表示正确预测的事件在所有事件中的比例。
3)F1 值(F1)根据准确率和召回率计算得来,计算公式为F1=2RP/(R+P)。
3.4 基线模型
为了充分验证所提模型的性能,选取上述3 种评价指标将近年来主流的事件检测模型与FESPOSED 进行比较。对比模型具体如下:
1)DMCNN[17]模型:在事件检测任务中引入动态多池化层作为特征提取器,该特征提取器更加关注事件触发词与事件要素信息,从而保留更重要的信息。
2)JRNN[29]模型:为了避免管道模型中的误差传播问题,采用双向RNN 来学习更加丰富的句子表示,同时也考虑了事件触发词与事件要素信息之间的联系。
3)dbRNN[30]模型:在使用RNN 方法的同时应用树结构与序列结构来提高事件检测模型的性能,丰富了每个token 的信息表示。
4)GCN-ED[31]模型:采用基于依赖树的卷积神经网络模型来改进事件检测,并且提出一种新颖的基于实体提及的卷积向量聚合方法。
5)JMEE[19]模型:引入依存句法树方法并使用基于注意力机制的卷积神经网络对图信息进行建模,从而解决事件触发词歧义的问题并提升事件检测效果。
6)EE-GCN[32]模型:通过融 合句法 结构和类型依赖标签并且以上下文相关的方式更新关系表示来改进卷积神经网络模型。
7)GatedGCN[20]模型:采 用BERT 进行编码,并利用门控机制根据候选触发词的信息过滤图卷积神经网络模型中的噪声信息。
8)Adv-DMBERT[10]模型:采用一种对抗训练机制,不仅可以从候选集中提取实例信息,而且可以提高事件检测模型在嘈杂环境中的性能。
9)EKD[12]模型:引入开放域触发知识,为未见过/稀疏标记的触发词提供额外的语义支持,并改进触发识别性能。
10)SEGCN-DCR[21]模型:采用一种带有解耦分类重新平衡机制的语法增强型卷积神经网络,提升在数据分布不均衡的情况下事件检测模型的性能。
3.5 对比实验
为了充分验证所提模型的性能,利用上述基线在相同的实验条件下进行对比。在ACE2005 数据集上的实验结果如表2 所示,其中:★表示扩充训练实例的模型;▼表示基于循环神经网络的模型;△表示基于图神经网络的模型;※表示引入动态多池化层的模型;加粗数据表示最优指标值,下同。

表2 ACE2005 数据集上的实验结果Table 2 Experimental results on the ACE2005 dataset %
在ACE2005 数据集上的实验结果表明,所提模型在触发词识别任务中的性能有明显提升,且在事件检测任务上的性能优于其他对比模型,召回率和F1 值都有所提升,尤其是对比先进的SEGCNDCR[24]模型,召回率和F1 值分别提升了2.2 和1.2 个百分点。这充分说明了所提模型在事件检测任务上的有效性和先进性。在ACE2005 数据集上,EKD[12]模型的触发词分类准确率最高,这是因为其引入了丰富的开放域触发词知识并利用师生模型减少注释中的内在偏差,但召回率较低。由表2 实验结果可以看出:
1)与扩充 训练实 例的模 型Adv-DMBERT[10]和EKD[12]相比,所提模型在F1 值上均有所提升,分别提升了4.9 和0.9 个百分点。这可能是因为它们生成的语料库都是同质的,仍然存在内置偏差,并且在一定程度上受限于知识库的低覆盖情况,而所提模型不扩充句子级训练实例,在词粒度上进行语义扩展,避免了引入噪声干扰模型训练,且可以挖掘候选触发词上下文中的丰富语义。
2)与基于 循环神 经网络 的模型JRNN[29]、dbRNN[30]相比,所提模型性能更加优越,在F1 值上分别提升了10.2 和7.6 个百分点。这可能是因为循环神经网络无法解决句子长距离依赖问题,而所提模型同时利用词粒度和句子粒度语义信息有效地避免了此问题。
3)与基于 图神经 网络的模型GCN-ED[31]、JMEE[19]、EE-GCN[32]、GatedGCN[20]、SEGCN-DCR[21]相比,所提模型性能均有所提升,在F1 值上分别提高了6.4、5.8、1.9、1.9、1.2 个百分点。这可能是因为GCN 在卷积时对所有邻居赋予同等的重要性,不能根据节点重要性分配不同的权重,并且GCN 将特征编码为高阶向量,会引入过多额外参数,而所提模型着重对符合触发词词性的候选触发词进行语义扩展,关注特定位置符合语境的上下文信息预测,且没有引入过多参数。
4)与引入 动态多 池化层 的模型DMCNN[17]和Adv-DMBERT[10]相比,所提模型在F1 值上分别提升了10.4 和4.9 个百分点。这可能是因为引入动态多池化层的模型仅关注句子粒度语义信息,没有重视与触发词相关的词粒度语义扩展信息。
综上所述,所提模型仅在词粒度上进行语义扩展,利用词性筛选缩小候选触发词范围并扩展特定位置的语义信息,不仅考虑了候选触发词信息,而且还充分考虑了候选触发词与当前语境的关联关系,同时融合词粒度语义扩展信息和句子粒度语义信息增强了分类能力,因此性能优于对比模型。
为了进一步验证所提模型的有效性,在KBP2015数据集上进行实验,实验结果如表3 所示。在KBP2015 数据集上的实验结果表明,所提模型在触发词识别与触发词分类任务上的性能都有不同程度的提升,其中在触发词识别任务上,准确率、召回率和F1 值分别达到了83.5%、65.3%和73.3%,在触发词分类任务上准确率、召回率和F1 值分别达到了77.8%、59.6% 和67.5%。TAC Top[27]是在TAC KBP2015 事件检测中获得排名第1 的结果,与之相比,所提模型也表现出优异的性能。
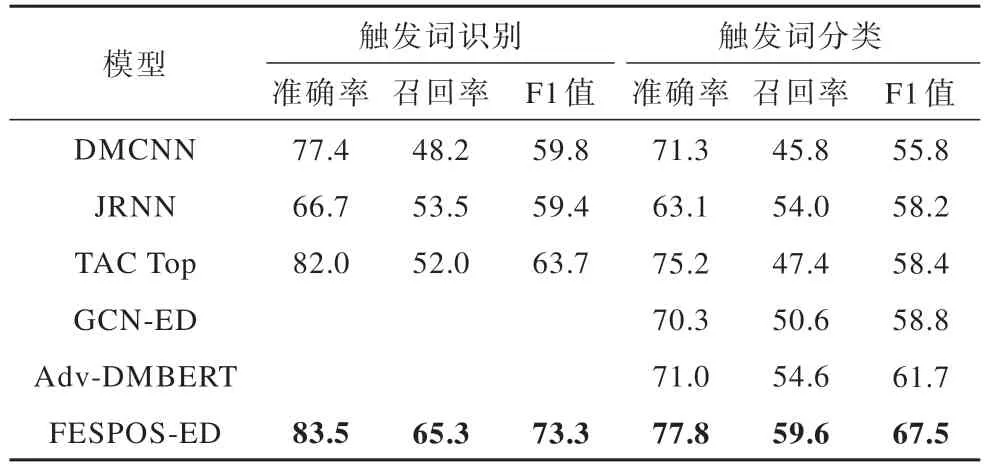
表3 KBP2015 数据集实验结果Table 3 Experimental results on the KBP2015 dataset %
3.6 稀疏标记数据实验
当数据标记不平衡时,模型在稀疏标记数据上的表现无法通过整体性能进行衡量。在实验中根据训练数据的分布拆分测试集,对ACE2005 数据集中数量小于10 条数据的类别进行测试,并与对比模型在相同实验条件下进行比较。实验结果如表4 所示。
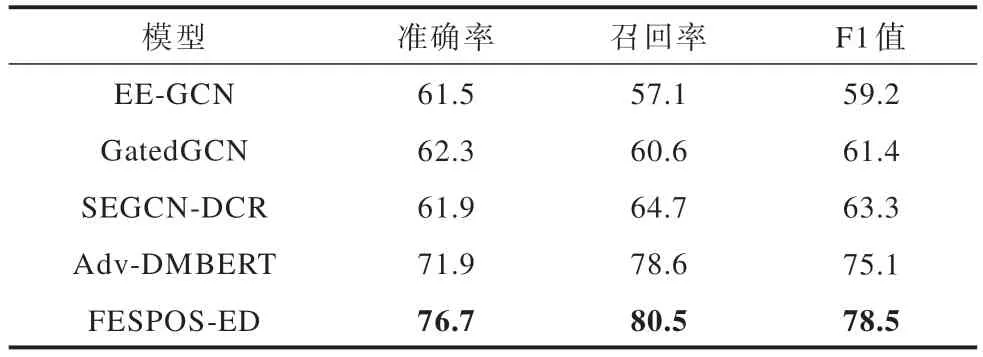
表4 稀疏标记数据实验结果Table 4 Experimental results of sparse labeled data %
由表4 可知,随着实验数据的减少,所提模型的性能会显著下降,但是在稀疏标记数据上所提模型在各项指标上均有所改善,与扩充训练实例的模型Adv-DMBERT[10]和在分类损失上进行平衡的模型SEGCN-DCR[21]相比,在3 个指标上均有不同程度的提升,在F1 值上分别提高了3.4 和15.2 个百分点。所提模型在召回率上的改善最为显著的可能原因为词性筛选机制可以缩小候选触发词范围,在这些候选触发词中极大概率包含真正的触发词,从而使更多稀疏标记的触发词被模型识别,并且扩充候选触发词语义信息,挖掘触发词上下文中蕴含的丰富语义信息进行训练,进而提升事件类型的分类性能。实验结果表明,所提模型能够缓解稀疏标记数据得不到有效训练对模型性能造成的不良影响。
3.7 消融实验
为了进一步探究模型中各个子网络的具体作用及其对最终结果的影响,进行消融实验。在实验中使用ACE2005 数据集,具体结果如表5 所示。
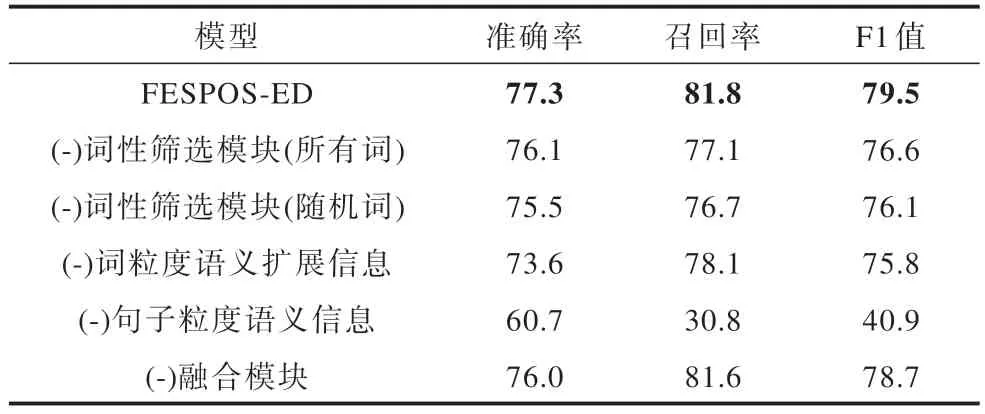
表5 ACE2005 数据集消融实验结果Table 5 Ablation experimental results on the ACE2005 dataset %
1)对词性筛选模块的消融
(-)词性筛选模块(所有词)表示消除词性筛选模块,对输入序列的每个词进行语义扩展;(-)词性筛选模块(随机词)表示消除词性筛选模块,对输入序列进行随机语义扩展。
实验结果表明,在消除词性筛选模块后,模型性能受到影响,原因为无论是对整个输入序列进行语义扩展,还是对输入序列进行随机语义扩展,均有可能引入与触发词无关的噪声,从而降低模型性能。
2)对语义信息模块的消融
(-)词粒度语义扩展信息表示消除词粒度语义扩展信息模块,仅使用句子粒度语义信息进行事件检测;(-)句子粒度语义信息表示消除句子粒度语义信息,仅使用词粒度语义扩展信息进行事件检测。
实验结果表明,所提模型在F1 值上有不同程度的下降,分别降低了3.7 和38.6 个百分点,这表明在所提模型中句子粒度语义信息和词粒度语义扩展信息都是不可或缺的。词粒度语义扩展信息能够提供候选触发词的语义扩展信息,句子粒度语义信息能够提供输入序列的上下文信息,两种粒度的语义信息融合生成鲁棒的语义表征对事件检测更加有效。
3)对融合模块的消融
(-)融合模块表示消除融合模块,仅将词粒度语义扩展信息和句子粒度语义信息进行拼接。
实验结果表明,拼接操作缺少句子粒度语义信息和词粒度语义扩展信息的交互过程,不能有效融合两种语义信息。
3.8 实例分析
为了更好地验证所提模型性能,本节从ACE2005 数据集中挑选了若干条数据。在第1 组数据中,为了验证所提模型的鲁棒性,将2 条数据中的触发词换为同义的未见过的触发词进行测试。第2 组数据来源于ACE2005 数据集中的稀疏标记数据,为了验证所提模型的有效性,对2 条稀疏标记数据进行测试。由表6 可以看出:

表6 ACE2005 数据集实例分析Table 6 Case analysis of the ACE2005 dataset
在第1 组数据中,a 句的原始触发词是“Bankrupt”,将其替换为数据集中未见过的同义词“Insolvent”;b 句的原始触发词是“fallen”,将其替换为未见过的同义词“deceased”。由于触发词在极大概率上是动词或名词,所提模型利用词性筛选缩小候选触发词范围,在未见过的触发词识别及分类上有天然的优势,并且无论是什么触发词都有极大概率包括在特定词性内,因此在未见过的样本测试中依旧能够正确识别,说明了所提模型具有良好的泛化性。
在第2 组数据中,c 句对应的触发词是“fined”,事件类型为“Justice:Fine”,该类型在数据集中仅有5 条样本;d 句对应的触发词是“amnesty”,事件类型为“Justice:Pardon”,该类型在数据集中仅有1 条样本,所提模型能够正确识别触发词和事件类型。实验结果表明,所提模型在稀疏标记数据中不仅能够利用特定词性的词粒度语义扩展信息正确识别触发词,而且能有效利用输入序列的词粒度-句子粒度语义信息正确识别事件类型,充分说明了所提模型的有效性和先进性。
4 结束语
针对数据标注不平衡导致稀疏标记数据得不到有效训练的问题,本文提出融合词性语义扩展信息的事件检测模型。通过词性语义扩展,缩小候选触发词范围的同时挖掘候选触发词的上下文中的丰富语义,并融合句子粒度语义信息进行识别和分类,避免训练受到样本数量的限制,缓解了稀疏标记数据带来的影响。实验结果表明,所提模型在ACE2005和KBP2015 数据集上均具有良好性能,在稀疏标记数据上也取得了具有竞争性的结果。在未来工作中,将对无触发词的事件检测任务进行探索和研究。
猜你喜欢
小猕猴智力画刊(2022年9期)2022-11-04 02:31:42
粉末冶金技术(2021年3期)2021-07-28 06:26:16
南京大学学报(自然科学版)(2021年1期)2021-01-30 14:01:04
开放教育研究(2020年2期)2020-03-31 01:54:14
小哥白尼(趣味科学)(2019年6期)2019-10-10 01:01:50
系统工程与电子技术(2016年12期)2016-12-24 07:19:14
发明与创新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
现代语文(2016年21期)2016-05-25 13:13:44
大连民族大学学报(2015年2期)2015-02-27 08:28:11
