
基于深度学习的自然场景文本检测综述
2024-03-21 08:15:38连哲殷雁君云飞智敏
计算机工程 2024年3期
连哲,殷雁君,云飞,智敏
(内蒙古师范大学计算机科学技术学院,内蒙古 呼和浩特 010022)
0 引言
文字作为人类语言的书面形式,是人类获取信息和传递信息的重要载体。在自然场景中拍摄的以文字为内容的图像,被称为自然场景文本图像或场景文本图像,在自然场景中出现的大量文字信息对于描述和理解场景内容具有积极作用。自然场景文本检测作为场景内容分析的基础研究,旨在定位输入图像中文本内容的位置,广泛地应用于图像搜索[1]、机器翻译[2]、机器人导航[3]、多媒体检索[4]、工业自动化[5]等场景理解任务。本文立足于深度学习背景下的自然场景文本检测技术,梳理概括目前文本检测的主流方法,着重阐述和讨论目前主流方法存在的优缺点及仿真实验结果和环境设置。
1 基于深度学习的自然场景文本检测
近年来,随着深度学习技术的发展,基于深度学习的场景文本检测方法逐渐成为主流。基于深度学习的自然场景文本检测方法大致可以分为基于检测框的文本检测方法、基于分割的文本检测方法、基于检测框和分割的混合文本检测方法和其他文本检测方法。
1.1 基于检测框的文本检测方法
基于检测框的文本检测方法主要通过检测包围框对自然图像中文本所在区域进行限定。文献[6]提出的目标检测模型(Faster R-CNN)在目标检测领域取得了很好的结果,继而给文本检测领域带来了巨大的突破。基于检测框的文本检测方法根据检测框粒度的不同,分为基于文本区域建议的方法和基于文本组件建议的方法。
1.1.1 基于文本区域建议的文本检测方法
受到目标检测算法的启发,许多研究人员将基于深度学习模型的目标检测方法用到文本检测中,通过选择性搜索算法[7]生成多个文本候选区域,通过筛选文本候选框并微调候选框位置以及大小,将候选区域分为文本区域和非文本区域。
文献[8]提出一种基于文本倾斜角信息的旋转区域建议网络(RRPN),其中旋转感兴趣区域(RRoI)池化层为文本区域分类器设计特征图提供了一个任意方向的方案,解决了文本检测中检测区域具有旋转角度的问题。RRPN 候选框方向是通过旋转角度参数控制,对旋转候选框的边框进行回归,增强了对于倾斜文本的检测效果,但是RRPN 不能检测弯曲文本,且RRoI 通过最大池化方式将旋转区域转换为固定大小区域,存在RoI 与提取特征之间未对准的问题。为解决该问题,文献[9]提出一种使用点代替锚的无锚区域建议网络(AF-RPN)来代替Faster R-CNN 中传统的区域建议网络(RPN),摆脱了传统复杂的候选框设计,在水平和多方向的文本检测任务中均有很高的召回率,然而使用点代替锚会出现检测框未完全围住文本区域的情况。
针对长文本和任意方向文本的问题,研究人员也进行了大量研究。文献[10]提出旋转敏感回归探测器(RRD),调整了单步多框目标检测器(SSD)[11]的锚定比,以适应非规则形状的宽高比变化,主要解决了有方向的检测框回归问题。通常地,图像文本检测方法中文本分类和边界矩形框(BBox)坐标回归两个任务共享同一特征,采用同一特征解决两个不同任务,在一定程度上会导致系统性能下降。RRD 是用两个不同设计的网络分支来分别提取用于文本分类和BBox 坐标回归的任务特征,不仅减少了旋转敏感特征对分类的影响,同时也减少了旋转不变特征对回归的影响,从而对长文本的检测更加准确,但是对于字符间距较大的文本行存在无法检测整个边界且不能处理弯曲文本的问题。文献[12]同样基于SSD 模型提出TextBoxes++网络以检测任意方向的文本区域,通过四边形或倾斜的矩形框来表示图片中的文本区域,将卷积核大小由3×3 改为3×5的长卷积核来更好地提取文本特征信息,TextBoxes++网络结构复杂,需要长时间对模型进行训练,且因低层特征表达能力较弱,对小尺度文本检测的准确率低。
1.1.2 基于文本组件建议的文本检测方法
当前基于文本区域建议的文本检测方法大多是由目标检测算法改进而来,但是目标检测中所检测的目标一般是较大的物体。在文本检测时,因为自然场景中文本、尺寸和宽高比不同,而且存在文本行弯曲的情况,所以候选框的尺寸大小很难完全接近文本,并且对候选框位置进行微调的方法同样很难达到预期结果。
基于文本组件建议的方法是将文本区域看作很多个连续文本组件,其中文本组件是字符或文本的一部分。文本组件建议的方法通过检测文本组件区域,将文本组件连接成文本区域,实现文本检测任务。
文献[13]提出的DeepText 首次将目标检测算法成功应用于自然场景文本检测,基于GoogleNet 中Inception 模块的理念设计Inception RPN,通过并行使用不同尺度的卷积核和池化操作来提取多尺度的特征信息,以该方式生成的候选框能捕捉文本区域的形状、纹理、上下文等特征,但是DeepText 主要针对英文文本进行训练和设计,且网络性能在很大程度上依赖于大规模训练数据集,如果训练数据集不充分或不具代表性,则可能导致模型的泛化能力不佳。
文献[14]提出连接文本建议网络(CTPN),采用垂直锚检测水平方向文本,并且网络中加入了双向长短期记忆(LSTM)网络[15]来学习文字序列特征,有利于获得检测框和置信度,但是CTPN 加入了LSTM 后,在训练阶段容易导致梯度爆炸,并且没有很好地对多方向文本进行处理。为此,文献[16]在特定环境下改进了SSD 算法,提出SegLink 多方向文本检测方法,检测含有单词或文本行的局部区域,将局部区域连接组成完整的文本检测框,实验结果表明该方法可以检测多方向和任意长度的文本,但是存在单词或文本行阈值α和β需要人工设置的缺陷,且无法检测间隔很远或形变的文本。
从多方向文本检测的角度出发,文献[17]提出深度关系推理图(DRRG)网络,该网络基于卷积神经网络(CNN)的文本组件建议网络预测文本组件的几何属性,利用局部图建立不同文本组件之间的连接,并最终采用图卷积网络进行文本组件深度关系推理,实现文本组件聚合。DRRG 网络抛弃了锚的思想,无需预先考虑文本框的大小,使用了新的文本组件连接方式,真正实现了对任意形状文本的预测,但是该网络检测结果过度依赖文本组件建议网络所建议的单个词检测框。
基于检测框的文本检测方法的机制、适用场景、优势和局限性如表1 所示,实验条件和检测结果对比如表2 所示。

表1 基于检测框的文本检测方法的机制、适用场景、优势和局限性Table 1 Mechanisms,applicable scenarios,advantages,and limitations of text detection methods based on detection boxes
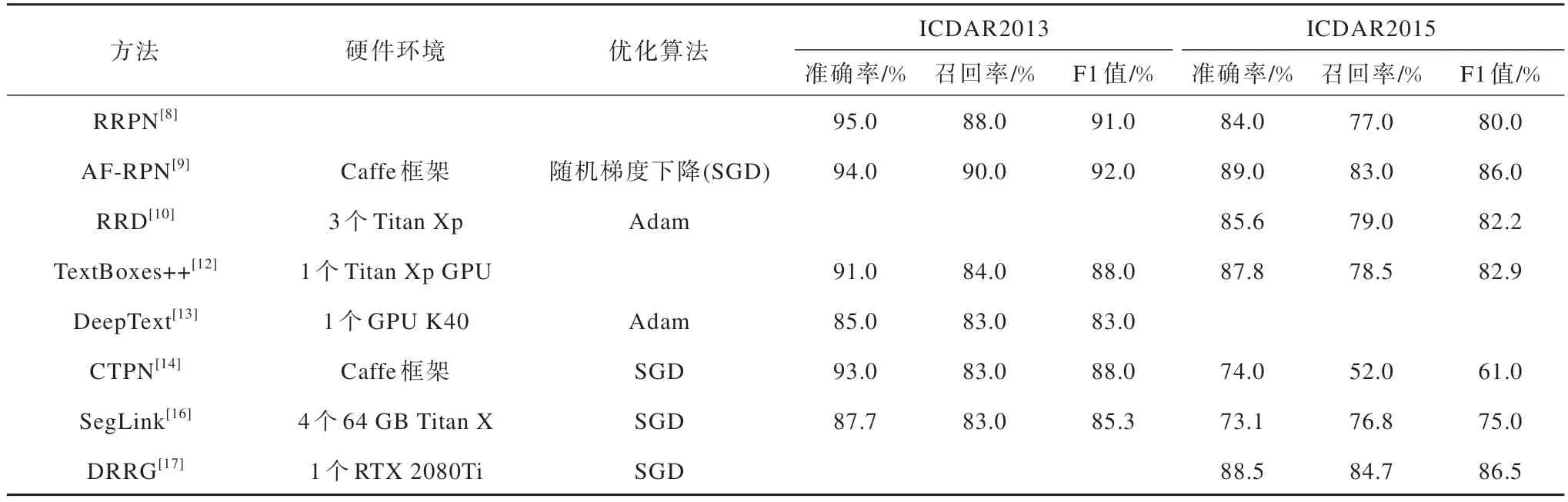
表2 基于检测框的文本检测方法的仿真实验结果Table 2 Simulation experimental results of text detection methods based on detection boxes
1.2 基于分割的文本检测方法
该方法主要借鉴了经典的语义分割算法的思路,例如全卷积网络(FCN)、FPN[18]和全卷积实例感知(FCIS)[19]等。基于分割的自然场景文本检测方法利用深度卷积和上采样进行特征提取和多级特征融合,通过对图像中每个像素分类来判断每个像素点是否属于文本区域,达到精准文本区域分割的目的。
文献[20]提出端到端的高效和准确的场景文本(EAST)检测网络,该网络利用FCN 和NMS[21]舍弃了中间不必要的步骤,有效减少了检测时间,可以预测任何形状的矩形,但是该网络的局限性在于检测器处理文本实例的大小和网络的感受野成正比,限制了网络预测长文本的能力,同时该网络在一定程度上对垂直文本实例存在预测遗漏或预测准确率不高的问题。文献[22]是在EAST 网络的基础上提出一种基于实例分割的自然场景文本检测算法(PixelLink),与EAST 网络技术的差异在于:EAST网络基于检测框回归和图像分割,而PixelLink 只使用图像分割。因为文本检测需要更为精确的定位,只采用图像分割不能准确地定位距离较近的文本实例,所以PixelLink 还采用了Link 的思想,不仅预测像素是否为文本,并且预测文本的像素之间是否可以进行连接组成一个文本框。然而,PixelLink 网络在针对不同数据集进行预测时需要调整Pixel 和Link 两个阈值,并且设置的后处理方法有所不同,使模型检测过程较为复杂。
后处理是基于分割的文本检测方法的关键阶段,但是后处理阶段一般很耗时。文献[23]基于可微二值化(DB)后处理机制提出DBNet。传统的基于语义分割算法后处理通过一个固定的阈值对特征图进行二值化操作,而DBNet 添加了一个可学习的阈值映射,通过图片特征学习像素阈值,这样便无须计算二值化图,减少了时间消耗,提高了网络性能。但是,DBNet 网络只关注预测文本区域的准确性,无视其他非文本区域类别的差异,导致学习到的特征较为分散。
DBNet 一经提出便引起众多研究人员的关注,并在其基础上进行改进,以实现更好的检测性能。文献[24]引入残差校正分支(RCB)使得轻量级网络更准确地定位文本区域的位置,设计一种基于FPN的双分支注意力特征融合(TB-AFF)模块结合局部注意力和全局注意力,提高文本特征信息表示能力。由于引入了两个模块,因此模型复杂度提高,训练时间有所增加。TB-AFF 模块结构如图1 所示,其中,C4与C5表示网络后两层输出,X表示合成特征,L(X)表示三维注意力权重,通过两层深度可分离卷积得到,g(X)表示一维注意力权重,通过一层全局平均池化与两层深度可分离卷积得到,X'表示合成权重,P5表示最终输出特征。
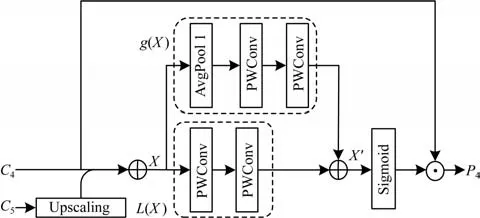
图1 TB-AFF 模块结构Fig.1 Structure of TB-AFF module
文献[25]引入多尺度池化(MP)模块,通过不同高宽比窗口的空间池化操作来获取场景文本图片中不同层次的上下文信息,利用双向特征融合(BiFF)结构改善网络的信息传播路径。由于池化窗口为正方形,因此无法很好地适应弯曲文本。MP 模块结构如图2 所示,其中,ConvBN 与ReLU 表示标准的卷积+归一化+激活函数操作,4 个不同的AvgPool 表示不同池化核的平均池化,Concat 表示级联。
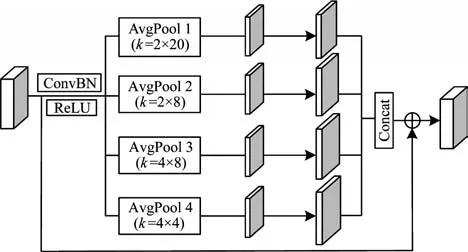
图2 MP 模块结构Fig.2 Structure of MP module
文献[26]在骨干网络中嵌入注意力机制,增强特征提取能力,引入深度多尺度特征融合(DMFF)模块充分挖掘并有效融合文本实例在不同尺度上的特征信息。由于特征提取过程中的信息丢失,因此DMFF 模块在文本实例与背景具有较强相似性时表现出较差的检测性能。DMFF 模块结构如图3 所示,其中,P2、P3、P4、P5分别表示骨干网络提取的4 层特征,f表示将4 层特征融合后的特征,F表示经过增强的用于最终检测任务的特征。
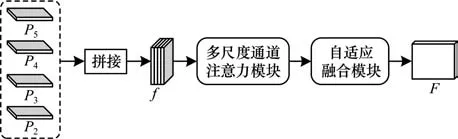
图3 DMFF 模块结构Fig.3 Structure of DMFF module
LIAO等[27]对DBNet 进行改进,提出DBNet++网络模型,设计自适应尺度融合(ASF)模块,将一个空间注意力模块集成到一个阶段性的注意力模块中,阶段注意力模块学习不同尺度特征图的权重,空间注意力模块学习跨空间维度的注意力,从而实现尺度鲁棒的特征融合。虽然DBNet++在多个基准测试上取得了最高精度,但还是很难处理文本中的文本的情况。
目前,研究人员提出可以对任意形状的文本图片进行文本检测的方法,但通常算法运行时间较长。基于算法运行时间和效率的考量,文献[28]提出一种高效准确的任意形状文本检测器(PAN),由特征金字塔增强模块(FPEM)和特征融合模块(FFM)构成,其中,FPEM 用于引入多级信息来指导分割,FFM 将不同深度的FPEM 特征融入最终分割特征,可学习的后处理方法应用在像素聚合(PA)模块,通过预测相似性向量对文本像素进行准确融合。实验结果表明,PAN 提升了文本检测效率,对长文本和密集文本检测效果较好,但是PAN 使用轻量级CNN 进行特征提取,导致所提取的特征感受野较小且表达能力较弱。
文献[29]使用自适应通道注意力(ACA)机制,通过局部跨通道交互获得更具代表性的文本特征,利用FPEM 融合低层和高层信息进一步增强不同尺度的特征,提出一种加权感知损失(WAL),通过调整文本实例的权重来增强鲁棒性。实验结果表明,该方法可对任意形状的文本实现检测,但是在复杂背景下容易将背景图案检测为文本。
分离相邻文本实例是一项很难的挑战。文献[30]提出一个二维渐进核,可满足自然场景中各种四边形文本和曲面文本检测任务的要求,设计定向池化模块,采用不同方向的集合来获取更多的文本信息,并设计基于分水岭算法的后处理方法。该方法能够鲁棒地检测出文本尺度变化较大的文本,但是在处理一些针对稀有训练数据的文本嵌入时存在困难。
基于分割的文本检测方法的机制、适用场景、优势和局限性如表3 所示,实验条件和检测结果对比如表4 所示。
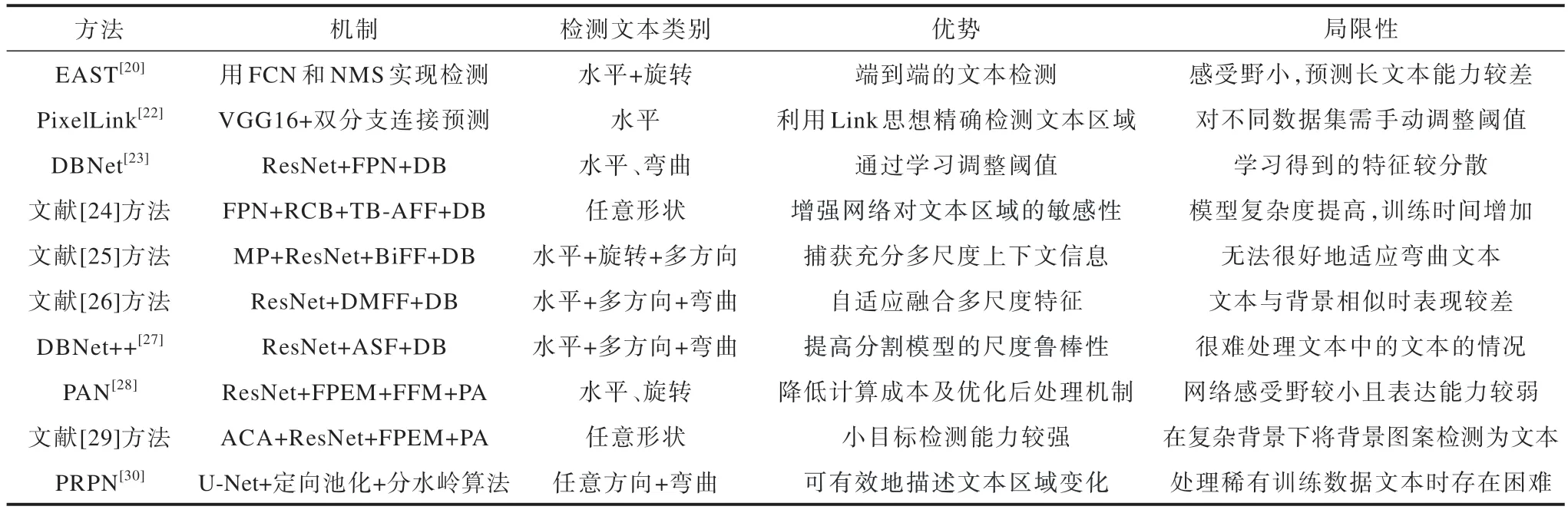
表3 基于分割的文本检测方法的机制、适用场景、优势和局限性Table 3 Mechanisms,applicable scenarios,advantages,and limitations of segmentation-based text detection methods

表4 基于分割的文本检测方法的仿真实验结果Table 4 Simulation experimental results of segmentation-based text detection methods
1.3 基于检测框和分割的混合文本检测方法
基于分割的文本检测方法适合不规则文本的检测,但对小文本区域的特征响应信号弱。基于检测框的方法能够弥补小文本捕获的缺陷,但是容易产生文本密集区域的锚点匹配困难的问题。针对上述问题,研究人员提出两者混合的文本检测方法。
文献[31]提出融合文本分割网络(FTSN),该网络在提取特征过程中结合了多级特征,是FPN 和FCIS 的组合。在FTSN 中,位置敏感模块用于提取文本分类特征和边框回归特征。文本分类特征主要包括像素属于文本还是非文本的特征以及属于检测框K2 块不同区域的特征。边框回归特征包含文本K2块不同区域的坐标位置特征。FTSN 模型利用语义分割和区域建议的文本检测的优点,同时进行检测和分割文本实例。然而,FTSN 模型生成四边形矩形框表示文本区域,在检测不规则文本时效果欠佳。文献[32]以FTSN 网络为基础提出IncepText网络,实质是将GoogleNet 网络中Inception 结构融入FTSN 网络。通过Inception 结构中设计的多个不同尺度卷积核来达到检测不同大小和高宽比文本的目的,同时使用可变形的RoI池化来代替RoI池化。因为引入了可变形的卷积核以及在池化操作中加入了方向参数,所以感受野能够对不规则的兴趣区域进行自适应,使得对不规则文本特征有很好的提取效果,提高了文本检测的性能,但是网络模块较多,训练时间较长。
文献[33]提出监督金字塔上下文网络(SPCNet),该网络采用文本上下文模块(TCM)提取全局上下文语义信息,对文本建议网络提取的文本矩形框进行再评分,以有效抑制文本建议网络生成的文本区域矩形框中存有背景区域的假阳性(FP)现象。同样地,通过抑制FP 现象提高性能的有ContourNet 网络[34],利用Adaptive-RPN 模块来提升建议质量,并且在分割阶段利用再评分机制来抑制FP,降低最终检测结果中出现的误检率。该方法在对比实验中并没有和SPCNet 这类基于Mask R-CNN的Two-stage 方法进行比较,但是在抑制假阳性阶段会产生较大计算量,影响训练速度。
多分支处理能获得较好的检测结果。文献[35]提出基于Faster R-CNN 模型的改进深度场景文本检测(DSTD)模型。该模型使用双分支对文本进行检测:第一分支是对文本进行像素分割预测,即区分自然场景图像中的文本像素与非文本像素,并且使用组件模块将文本像素点连接生成候选框;第二分支对字符候选框进行检测,输出一组用于候选的字符。最终两个分支所获得的输出结果进行融合,通过保留字符区域的候选框得到最终的检测结果。但是,DSTD网络使用双分支结构导致网络结构复杂,训练成本较高。文献[36]提出多方向场景文本(MOST)网络。该网络主要由文本/非文本分类分支、定位分支、位置敏感图预测分支构成。文本/非文本分类分支以像素级的方式区分文本和非文本区域。定位分支首先构建粗略的文本建议框,随后文本建议框经过文本特征对齐与文本/非文本分类分支生成的特征图进行融合,对粗略文本建议框进行细化。位置敏感图预测分支主要用于生成四通道的位置敏感图,并且将其与细化后文本建议框输入位置感知非极大值抑制(PANMS)模块,以融合所有网络预测得到的正检测框,最终得到文本实例区域。与标准NMS 相比,PANMS 能够花费更少的时间,产生更多的准确结果,但由于三分支并行处理,因此计算量较大。
文献[37]提出基于动态卷积的文本检测器(Dtext),该方法采用全卷积单阶段(FCOS)策略,可以动态地从多个特征中为每个文本实例生成独立的文本实例感知卷积参数,克服了固定卷积核集不能适应所有分辨率的问题,同时防止了由于实例的多尺度而导致的信息丢失,但是对于锐化字体和实例中的形状处理效果并不好。
基于检测框和分割的混合文本检测方法的机制、适用场景、优势和局限性如表5 所示,实验条件和检测结果对比如表6 所示。
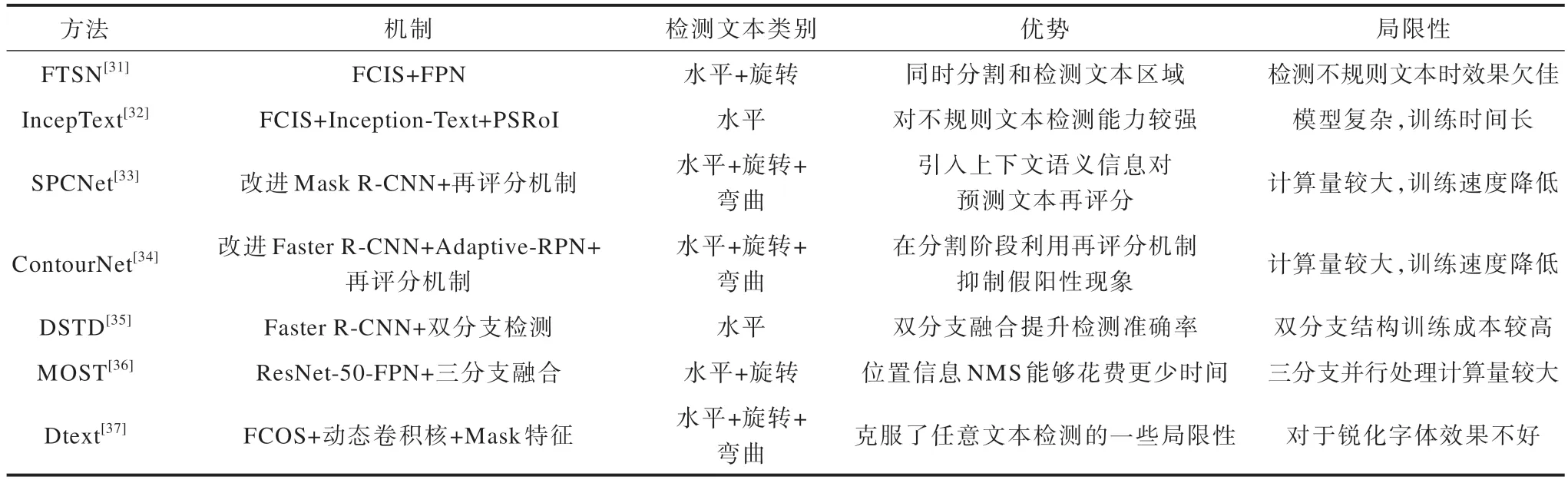
表5 基于检测框和分割的混合文本检测方法的机制、适用场景、优势和局限性Table 5 Mechanisms,applicable scenarios,advantages,and limitations of hybrid text detection methods based on detection boxes and segmentation
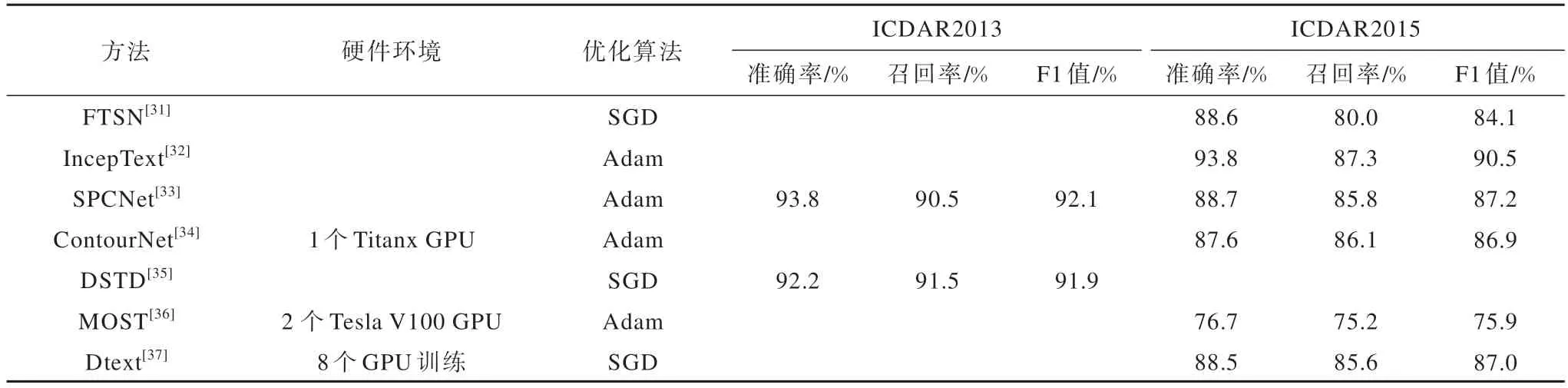
表6 基于检测框和分割的混合文本检测方法的仿真实验结果Table 6 Simulation experimental results of hybrid text detection methods based on detection boxes and segmentation
1.4 其他文本检测方法
现有字符级别的用于文本检测的样本库较少,且人工标注成本高,而基于深度学习的文本检测方法的性能在一定程度上取决于训练样本集的规模。针对目前字符级注释的文本数据集少的问题,文献[38]提出一种弱监督的训练框架(WordSup),构建字符检测器获得字符对应的输出坐标,利用文本结构分析部分获得词坐标,在弱监督训练模块中利用字符检测模型自动依据词坐标生成字符中心点掩码以更新词模型,但是WordSup 文本表示框是在矩形锚中形成的,容易受到摄像机视角变化引起的角色透视变形的影响,此外,还受主干结构的性能限制,即受锚数量和大小的限制。文献[39]提出一种基于弱监督框架的字符区域注意力文本(CRAFT)检测方法。该方法基于图形分割思想,但是与图形分割不同的是不进行图像的像素级分类,并且进行了回归处理,而且该方法基于字符区域得分和字符亲和力得分将字符连接成文本,其中,字符区域得分表示该像素是字符中心点的概率,字符亲和力得分表示该像素点是相邻字符中间空白区域中心的概率,根据这两个得分图将字符连接成文本,但是CRAFT 使用字符级边框生成字符区域得分和字符亲和力得分作为标签,对单词重叠区域检测能力较差。
文献[40]提出用于任意形状文本检测的自适应边界建议网络(TextBPN),可以对任意形状文本区域生成标准的边界而且不需进行后处理操作。该网络采用多层空洞卷积构建分类图、距离场、方向场和粗略的边界建议,并且由图卷积网络和循环神经网络构成编码-解码器,通过迭代方式使边界框逐渐贴合文本区域。然而,TextBPN 模型较为复杂,虽然去除了后处理操作,但是训练参数多,训练时间长。
一般的文本检测方法是基于像素级或者文本组件的方法,而以上方法会对噪声较为敏感,且依赖于复杂的后处理机制。对此,文献[41]提出渐进轮廓回归(PCR)网络,该网络首先构建水平文本候选框,在水平框上均匀选择N个点并将这N个点的位置和语义信息进行聚合产生旋转文本框,在旋转文本框上均匀选择N个点并逐渐将文本边界框回归为任意形状,实验结果表明该网络对任意形状文本的检测效率较高,但是最终检测结果受选择点数的影响较大。
针对多尺度文本检测问题,文献[42]提出门控多尺度输入特征(GMIF)融合方法,该方法从缩小的输入图像中以全局文本特征生成模块(GTFGB)生成局部特征,通过多路径模块(MPB)增加骨干网络感受野,随后通过门控循环单元将这些低分辨率局部特征转换为高分辨率的全局特征,能够检测所有较小文本实例的浅层骨干网架构,减轻了为文本实例选择最佳Mask 所需的后处理负担,但是后处理开销较大。
针对文本特征不清晰问题,文献[43]提出多尺度残差正交通道注意力网络(MS-ROCANet),该方法首先使用细节感知特征金字塔模块(DAFM)捕获更详细的信息,然后使用残差正交注意力模块(ROAM)和残差信道注意力模块(RCAB)组成的共享复合关注头(SCAH)在多尺度层次上增强文本特征区域,最后使用关键的全局上下文提取模块(GCM)捕获全局上下文信息,在得到分类图后使用NMS 得到最终检测文本框,由于模块较多,因此训练时间较长。
其他文本检测方法的机制、适用场景、优势和局限性如表7 所示,实验条件和检测结果对比如表8所示。

表7 其他文本检测方法的机制、适用场景、优势和局限性Table 7 Mechanisms,applicable scenarios,advantages,and limitations of other text detection methods
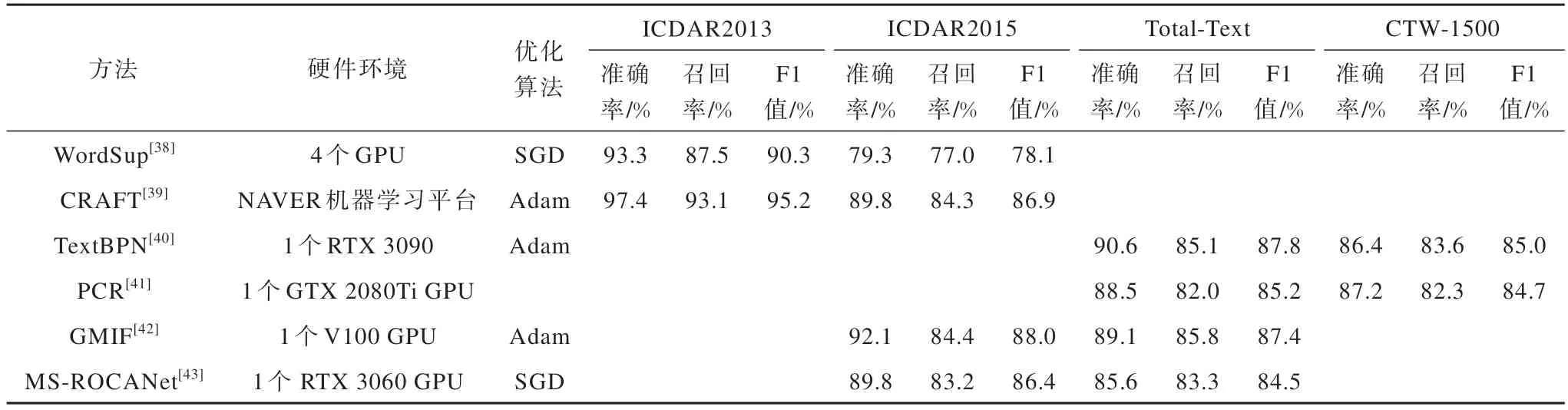
表8 其他文本检测方法的仿真实验结果Table 8 Simulation ecperimental results of other text detection methods
1.5 总结与分析
1.5.1 实用性分析
基于检测框的文本检测方法通常首先生成多个候选框,通过对候选框打分得到包含整个文本区域的候选框;然后通过边框回归方法,校正候选框使其拟合文本实例区域,但是使用该方法后候选框尺寸很难完全接近弯曲文本,导致多数目标检测算法在处理不规则文本时难以得到较好的效果,其中,基于文本组件建议的文本检测方法将检测文本区域划分为若干连续的文本组件,每个组件为文本区域的一部分,使用区域建议网络检测文本组件区域;最后将文本组件连接为文本检测区域,达到检测文本的目的。
基于检测框的文本检测方法在训练过程中对于候选框的预处理会导致检测速度较慢,为了使候选框能够更加贴合文本区域,基于分割的自然场景文本检测方法通过语义分割算法,采用深度卷积网络进行特征提取,通过双线性插值上采样方式融合语义特征,通过特定的后处理算法预测自然场景图像中每个像素是否为文本区域。由于获得了像素级别的标签预测,因此该类方法对任意形状文本检测表现出良好的鲁棒性,成了文本检测的主流方法。此外,该类方法的性能高度依赖于主干网络的特征处理方式,且通常需要复杂的后处理方法以增强像素点之间的关联性。大部分基于分割的方法对于文字重叠部分检测效果较差。
基于检测框和分割的混合文本检测方法结合了检测框和分割技术,旨在兼顾准确性和鲁棒性。该类方法的主要思想是使用检测框来粗略地定位文本区域。首先生成多个候选框进行筛选和去重,保留可能包含文本的框;然后使用语义分割方法对候选框进行像素级分割,从而得到精细的文本边界,将两类方法融合得到的分割结果进行后处理;最后得到文本检测区域。此类方法采用多分支结构,计算量较大,通常模型较为复杂。
其他文本检测方法针对特定问题提出解决方案。例如:通过弱监督解决了字符级注释的文本数据集少的问题;通过字符区域得分和字符亲和力精细定位小文本;通过多层空洞卷积与图卷积推理去除后处理过程;通过残差正交注意力增强不清晰文本。这些方法针对特定数据集能够取得很好的检测结果,但是泛化能力较弱。
表9 总结了上述自然场景文本检测方法的特性差异及适用场景。

表9 文本检测方法的特性差异及适用场景Table 9 Differences in characteristics and applicable scenarios of text detection methods
1.5.2 轻量化分析
基于检测框的文本检测方法通常使用简单而紧凑 的主干 网络结 构,例 如MobileNet[44]、EfficientNet[45]等,降低网络的复杂性和参数量,同时共享卷积特征,减少计算开销。但是,这类轻量化措施过于简易,仅能略微减少推理时间。
基于分割的文本检测方法轻量化效果较好。为了降低计算复杂度和内存消耗,基于分割的方法通常采用较小的感受野减少每个像素的计算量。后处理的轻量化策略对提高运行速度效果显著。例如:NMS 只对一组检测框排序和遍历,极大降低了计算复杂度;DB 将二值化过程纳入可训练的分割网络,有效提升推理速度。
基于检测框和分割的混合文本检测方法和其他文本检测方法实现轻量化的方式多样。例如:CRAFT 基于密集预测的Anchor-Free 检测方法,使用通道剪枝和结构剪枝的组合策略,以减少网络的参数和计算量;WordSup 引入字级别监督减少标注成本和模型复杂度,采用弱监督训练策略减少了模型训练的计算负担和时间成本;文献[46]通过知识蒸馏,最小化教师网络和学生网络的预测结果之间的差异,使学生网络学习到更丰富的信息,提高检测性能。
2 数据集设置
目前,常用的文本检测数据集有很多,其中文档分析与识别国际会议(ICDAR)比赛中使用的数据集较为典型。文本检测数据集随着文本检测要求的发展而发展,一开始线性文本数据集较多,后来渐渐出现了弯曲的文本数据集,目前出现了失真的文本数据集,即测试网络模型基于弱监督情况下的性能。本文整理了实验中常用的自然场景文本检测数据集,如表10 所示。
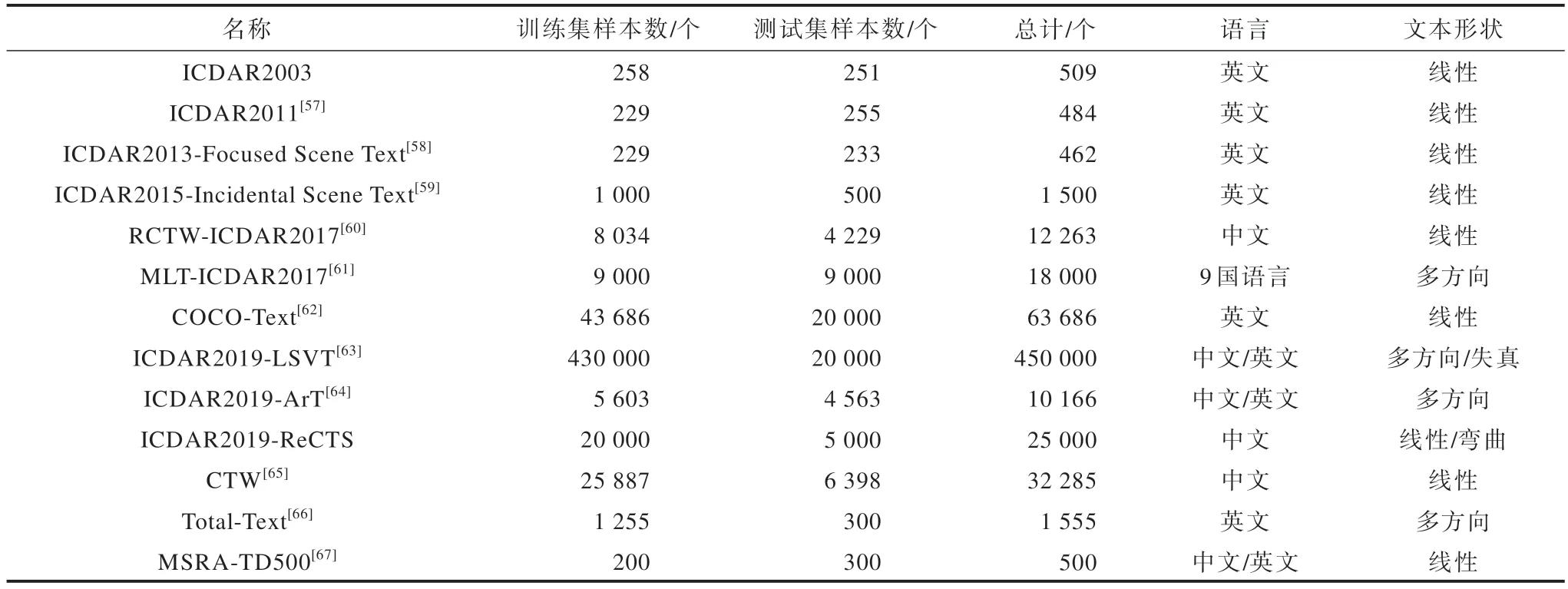
表10 常用的自然场景文本检测数据集Table 10 Common datasets for natural scene text detection
3 文本检测性能评估
目前,关于文本检测性能评价指标主要有准确率(P)、召回率(R)和F1 值(F1)。在通常情况下,召回率是指所有实际为正例的样本中被正确地预测为正例的样本数所占的比例,计算公式如式(1)所示。准确率是指预测为正例的样本中实际为正例的样本数所占的比例,计算公式如式(2)所示。F1 值是基于准确率和召回率的调和均值,计算公式如式(3)所示。
其中:NTruePositives表示被正确地预测为正例的样本数量;NGroundTruth表示数据集中实际为正例的样本数量;NRetrievedItems表示数据集中检索到的与NTruePositives相关的样本数量。
4 未来展望
目前,自然场景文本检测研究虽然取得了一定的进展,但是仍有一些问题需要解决和思考:
1)在自然场景图像文本分割时,因自然场景图像分辨率较高,在进行卷积时参数量和计算量较大,而且卷积核的感受野有限,很难捕捉到更多的上下文信息。针对上述问题,目前主流的解决方法是空洞卷积与注意力机制相结合的方法,其中,使用空洞卷积来加大感受野[58],使用注意力机制来构建时间、空间或时空两个维度的关系,快速捕获长距离依赖,从而获得更大的感受野。代表性的注意力机制有压缩和激 励网络(SENet)[59]、卷积块 注意力模块(CBAM)[60]、选择性内核网络(SKNet)[61]、高效通道注意力网络(ECA-Net)[62]等。谷歌在2017 年提出基于自注意力机制的模型(Transformer)[63],通过直接获取全局信息来避免感受野受限问题。目前,很多基于CNN 的文本检测任务将CNN 替换为Transformer 来提取图形文字特征,效果均有所改善。例如,文献[64]提出的用于语义分割的Transformer(SETR)网络将语义分割看作是序列到序列的预测任务来提供代替视角,虽然SETR 是针对目标检测提出的模型,但是也为自然场景文本检测提供了可以借鉴的思路。目前,众多的研究人员采用将注意力机制引入语义分割模型中增强语义信息的提取且得到了不错的效果。因此,将注意力机制应用到基于分割的文本检测领域有着广阔的前景。
2)任意形状文本检测较为困难。针对上述问题,研究人员进行了很多尝试,提出了TextBPN、DRRG 等模型。以上模型借鉴了基于图像语义分割任务的图模型(Graph-FCN)[65]。Graph-FCN 模型将图卷积引入语义分割任务,将图像语义分割中的像素分类问题转换为图节点分类问题,并且相关研究已证明通过图卷积的关系推理可以更好地检测任意形状的文本实例。但是,如何通过图片语义特征来构建节点图关系辅助自然场景文本检测任务仍是一个值得深入研究的课题。
3)字符级和像素级标注的公开数据集很少,且人工标记的方法耗时耗力。针对数据集规模较小的问题,通常使用数据增强的方法进行数据集扩容,但是会导致模型泛化能力较弱。弱监督学习和半监督学习在一定程度上解决了数据集少的问题。研究人员通过生成对抗网络(GAN)[66]和去噪扩散概率模型(DDPM)[67]生成的伪标签实现样本的多样性生成,以满足基于深度学习的文本分割模型对数据集规模的需求。文献[68-72]展示了近年来基于生成对抗网络和去噪扩散概率模型应用到语义分割和目标检测任务中所取得的成果。可见,已有越来越多的研究人员开始关注基于生成对抗网络和去噪扩散概率模型的文本分割技术的研究。
4)在复杂自然场景下的文本检测。由于公开数据集通常选择拍摄角度较好的图像,因此在此基础上多数文本检测模型都展现出良好的检测性能,但是自然场景中往往存在许多干扰因素,例如强烈的光照、遮挡等,对这类复杂场景文本:基于检测框的文本检测模型多数预先设置候选框,文本表现形式受限,检测时效果不佳;基于分割的文本检测方法将文本区域视为像素级别的分割任务,能够更准确地捕捉到文本的形状和边界。但是,由于复杂场景中文本的遮挡、重叠、模糊和小尺寸等情况,因此仍然存在误分割和漏分割现象,基于检测框和分割的混合文本检测方法在复杂场景中文本分割边界可能比较模糊或不规则,这会提高对边界处理算法的要求。目前,较普遍的解决措施是在模型训练阶段穿插环境较为复杂的样本,提高模型对复杂环境中文本检测的能力。因此,后续可以采用数据增强等技术来扩充数据集,从而进一步增强模型对不同环境的适应能力。
5 结束语
自然场景文本检测是计算机视觉领域的研究热点,越来越多的研究人员在国际计算机视觉大会、欧洲计算机视觉国际会议、IEEE 国际计算机视觉与模式识别会议、国际文档分析与识别国际会议等重要的国际性会议上展示了该领域最新的研究成果。本文对自然场景文本检测的相关研究进行阐述,对自然场景文本检测技术进行分类介绍和分析对比,归纳目前主流技术在主要公开数据集上的测试性能和实验条件,并对文本检测未来的发展趋势进行分析展望,指出未来可引入更强大的特征表示、增强学习和领域自适应等方法,提高算法鲁棒性和通用性。
猜你喜欢
光学精密工程(2022年13期)2022-08-02 08:53:30
计算机工程与应用(2022年1期)2022-01-22 07:46:48
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
计算机工程与科学(2021年4期)2021-05-11 01:59:36
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
电子制作(2019年11期)2019-07-04 00:34:38
当代陕西(2019年10期)2019-06-03 10:12:04
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
火力与指挥控制(2018年3期)2018-04-19 11:43:39
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
