
基于SwinT-YOLOX 模型的自动扶梯行人安全检测算法
2024-03-21 08:15侯颖杨林胡鑫贺顺宋婉莹赵谦
计算机工程 2024年3期
侯颖,杨林,胡鑫,贺顺,宋婉莹,赵谦
(1.西安科技大学通信与信息工程学院,陕西 西安 710054;2.西安科技大学西安市网络融合通信重点实验室,陕西 西安 710054)
0 引言
日常生活中自动扶梯是运送乘客十分常见的设施,在商场、地铁、机场、医院等公共场所被广泛使用。乘客摔倒事故是自动扶梯伤人事件中主要原因。传统自动扶梯日常管理消耗较多人力,但是遇到突发状况难以立即被发现,常常因无法及时按下“紧急停止按钮”终止扶梯运行,从而造成连续翻滚等重大人身伤害。因此,实现自动扶梯智能化监控管理势在必行,避免扶梯造成安全事故与损失,具有显著的经济效益和社会意义。
自动扶梯智能化监控管理系统,首先通过视频图像识别技术检测到行人摔倒行为,随后实时发出预警信息,并立即实施紧急停止命令,以确保乘客安全。扶梯行人摔倒检测技术是整个系统的关键核心,当今计算机视觉摔倒检测方法备受关注[1-4],其中基于深度学习的人体姿态摔倒检测算法[5-6]和YOLO 系列摔倒检测算法逐渐成为研究热点。CHEN等[7]采用OpenPose 算法提取人体骨骼关键点信息,并通过髋关节中心点下降速度、人体中心线与地面的倾斜角以及人体外接矩形宽高比3 个关键参数进行摔倒检测。基于视频序列的时间特征,LIN等[8]提出一种基于OpenPose 骨骼信息、长短期记忆和门控递归单元模型摔倒检测算法。卫少洁等[9]提出一种基于AlphaPose 骨骼关键点特征的长短期记忆神经网络人体摔倒检测算法。马敬奇等[10]采用AlphaPose 加速优化模型得到人体姿态骨骼点坐标信息,随后根据人体跌倒过程瞬时姿态变化特征和跌倒状态短时持续不变特征构建摔倒检测算法。RAZA等[11]采用YOLO DarkNet 网络框 架分别 对YOLOv1~YOLOv4 和Tiny-YOLOv4 这5 种方法进行实时摔倒检测,并优化模型将其部署在边缘设备实现有效实时检测。YIN等[12]提出网络模型优化的YOLOv4和YOLOv5深度学习摔倒检测算法。王晓雯等[13]提出一种融入卷积注意力机制模块和加权盒函数的改进YOLOv5 行人摔倒检测算法。
近两年自动扶梯行人摔倒检测算法开始获得关注。在自动 扶梯安 全系统 中,ZHAO等[14]采用YOLOv3 算法检测行人目标,OpenPose 提取人体姿态特征,最终利用人体关节特征检测算法识别危险姿态并报警。LIU等[15]通过视觉背景提取算法获得人体目标,并提取人体纵横比、有效面积比和质心加速度3 个特征信息,利用支持向量机分类算法判断跌倒事件。JIAO等[16]在YOLOv4 行人目标检测后采用改进的区域多目标姿态估计方法提取人体关节特征,再由安全估计模型检测摔倒行为。文献[17-18]所提算法均通过OpenPose 提取人体关键点特征信息,再利用特征检测算法或分类器检测摔倒行为。汪威等[19]采用改进的SlowFast 深度学习网络进行自动扶梯场景下的人体动作识别。
具有坡度的自动扶梯运行环境复杂,行人较多,局部遮挡情况频发,视频采集角度不断变化,人体姿态特征摔倒检测模型效果不佳,检测速度较慢。YOLO 系列目标检测算法采用端到端预测,具有速度 快、检测精度高、易于部 署等优点[20-24];Swin Transformer(SwinT)[25]算法是一种基于自注意力机制、并行化处理的深度神经网络,可以捕获全局上下文信息,获得更强的特征,在目标检测视觉应用中取得显著成果。
本文提出一种基于SwinT-YOLOX 网络模型的自动扶梯行人安全检测算法,利用局部窗口多头自注意力计算从而减少计算量,设计滑动窗口多头自注意力实现不同窗口间的信息传递,Neck 网络采用融合注意力机制的YOLOX Neck 网络结构,双向多尺度的特征重构融合,进一步提升特征图的多样性和表达能力。
1 改进的SwinT-YOLOX 目标检测算法
1.1 改进的网络结构
直接将常用的人体姿态摔倒检测方法应用到自动扶梯场景中,受周围环境复杂、行人较多、局部遮挡情况频发的影响,容易导致骨骼关键点特征丢失。此外,监控摄像头位置固定,具有坡度的动态移动扶梯在运行过程中行人目标采样图像的角度不断变化,人体姿态特征状态多样,造成摔倒检测估计模型适应性不强。因此,人体姿态估计摔倒检测算法检测精度降低。YOLO 系列不断引入创新性策略、优化结构、提高检测性能和速度,并支持移动终端和嵌入式设备部署应用。YOLOX 算法[24]采用解耦检测头结构、无锚点框机制、简单最优传输标签分配(SimOTA)等策略提升网络模型的检测精度。2017年谷歌提出的新型神经网络架构Transformer 推动计算机视觉领域取得丰硕成果,例如图像分类的iGPT 和ViT 系列算法、目标检测的DETR 系列算法和Swin Transformer 算 法,图像分割的SETR 和Segmenter 算法等[26-27]。LIU等[25]提出的SwinT 通用骨干网络是一种基于滑动窗口策略的多头自注意力分层结构Transformer 模型,以它为骨干网络的检测模型可以捕获全局上下文信息,扩大感受野并大幅减少计算量。
通过分析YOLOX 和SwinT 算法的创新策略,本文提出基于SwinT-YOLOX 网络模型的自动扶梯行人摔倒检测算法,改进行人摔倒检测算法的网络结构如图1 所示。其中骨干网络采用Swin Transformer模型,利用局部窗口多头自注意力计算以减少计算量,设计滑动窗口多头自注意力实现不同窗口间的信息传递,从而提高检测性能。Neck 网络采用融合注意力机制的YOLOX Neck 网络结构,双向多尺度的特征重构融合,进一步提升特征图的多样性和表达能力。此外,本文提出CBF 模块改进Neck 网络,采用漏斗修正线性单元(FReLU)视觉激活函数替代Sigmoid 线性单元(SiLU)激活函数,由此获得更优的特征检测性能。除了保留YOLOX Head 网络优秀策略以外,本文改进算法采用完全交并比(CIoU)损失函数代替YOLOX 的IoU 算法计算回归定位损失。根据网络模型深度和模块参数不同,SwinT 模型有Tiny、Small、Base、Larger 多种网络模型结构。
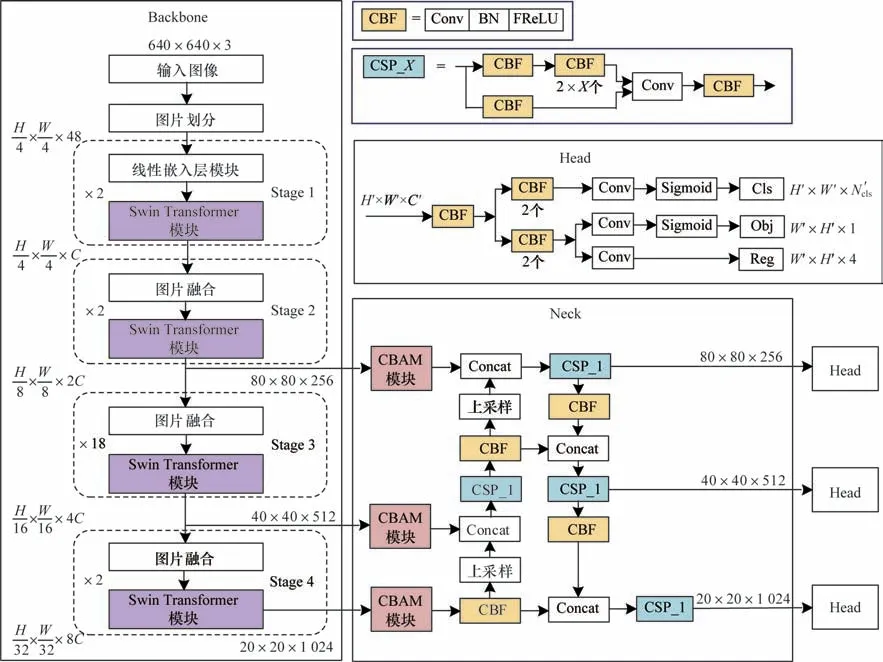
图1 改进SwinT-YOLOX 算法的网络结构Fig.1 Network structure of improved SwinT-YOLOX algorithm
1.2 Swin Transformer 骨干网络
SwinT-YOLOX 改进算法采用SwinT 骨干网络提取不同分辨率大小的3 组多尺度特征金字塔信息。
首先,640×640×3 的RGB 图像输入到图片划分模块进行不重叠分块和重组,将4×4 相邻像素构成1 个patch,并在通道方向展平为4×4×3=48 大小,整幅图像被划分成H/4×W/4×48 的patch 集合。
随后,分别通过4 个特征学习阶段获得不同分辨率下的特征信息,从而依次逐层扩大感受野。Stage 1 过程利用线性嵌入层模块通道维数据进行线性变换,将图像48 维度映射到给定的C维上,本文网络中取C=128。然后,通过2 个SwinT 模块进行注意力计算,从而提取(H/4×W/4×C)维特征信息。在Stage 2~Stage 4 过程中均采用图片融合模块进行下采样,将2×2 相邻patch 合并拼接后,使特征图宽高减半,维度扩展1 倍。随后,Stage 2 通过2 个、Stage 3通 过18 个、Stage 4 通 过2 个Swin Transformer 模 块,分别提取{H/8×W/8×2C}的浅层特征信息、{H/16×W/16×4C}的中层特征信息和{H/32×W/32×8C}的高层特征信息。
针对640×640×3 的输入图像,本文SwinT-YOLOX骨干网络将Stage 2~Stage 4 提取到 的80×80×256、40×40×512、20×20×1 024 这3 个尺度信息构成特征金字塔。
每个Stage 都包含成对的Swin Transformer 模块,主要由层正则化(LN)、窗口多头自注意力(W-MSA)、滑动窗口多头自注意力层(SW-MSA)和多层感知机(MLP)通过残差运算构成。LN 模块对同一样本的不同通道做归一化处理,从而保证数据特征分布的稳定性。传统的Transformer 多头自注意力机制全局计算量较大。为此,Swin Transformer 中的W-MSA 模块单独对每个窗口内部进行自注意力计算,能够有效减少计算量。SW-MSA 模块利用滑动窗口间的自注意力交互信息扩大特征感受野,提高检测性能。SwinT 模块各部分的具体输出计算式如式(1)所示:
Swin Transformer 模块结构如图2 所示。
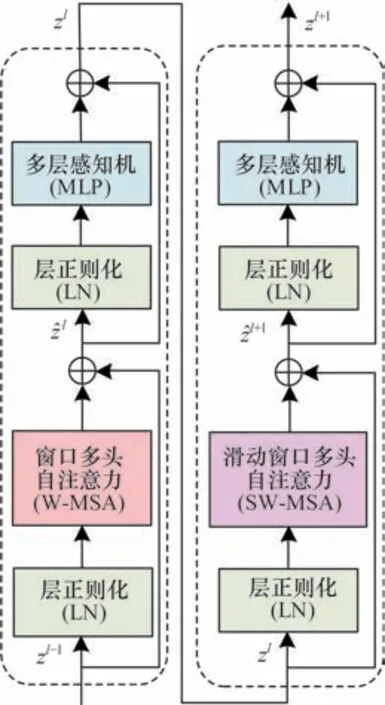
图2 Swin Transformer 模块结构Fig.2 Structure of Swin Transformer module
1.3 融合注意力机制的改进Neck 网络
SwinT-YOLOX 改进算法的Neck 网络采用融合卷积块注意力模块(CBAM)[28]的路径聚合特征金字塔网络(PAFPN)[29]结构,将3 个尺度的特征金字塔输入到Neck 网络中提取更有效的增强特征。Neck 结构设计如图1 所示。CBAM 模块由通道注意力模块(CAM)和空间注意力模块(SAM)串联而成,以增强特征图中有用信息的表征能力,并抑制背景特征,有效提高目标检测精度。本文Neck网络添加3 个CBAM 模块,分别接收来自SwinT骨干网络Stage 2、Stage 3 和Stage 4 阶段输出的80×80×256、40×40×512、20×20×1 024 3 个尺度特征图。CBAM 模块先将输入特征图F经过CAM 模块,完成加权处理后,再将CAM 输出特征图Mc(F)与其输入特征图F元素相乘得到的结果F′=F⊗Mc(F)进行SAM 模块处理,最终SAM 模块输出特征图Ms(F′)与其输入特征图F′元素相乘的结果就是获得的注意力优化特征图F″,其运算过程如式(2)所示:
CBAM 注意力机制结构如图3 所示。
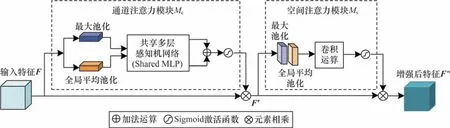
图3 CBAM 注意力机制结构Fig.3 Structure of CBAM attention mechanism
CAM 模块在特征图的空间维度上分别采用全局平均池化和最大池化2 种方法产生不同的空间上下文信息,再通过共享多层感知机网络(Shared MLP)对输出特征向量执行元素求和操作和Sigmoid激活函数计算,最终获得通道注意力权重向量。CAM 模块判别图像中重要目标区域,并增强其特征信息,抑制非重要区域特征响应。SAM 模块在通道维度上分别进行全局平均池化和最大池化处理,然后将产生2 种特征图拼接后的信息采用7×7×2 卷积操作和Sigmoid 激活函数计算,最终获得空间注意力权重矩阵。SAM 模块用于增强有用目标区域的位置特征信息。
图4 所示为本文SwinT-YOLOX 改进算法与YOLOX 算法的可视化热图结果(彩色效果见《计算机工程》官网HTML 版)。图4(b)和图4(c)所示的YOLOX 算法和不引入CBAM 的SwinT-YOLOX 高激活区(红色区域)覆盖面积明显较少。从图4(d)可以看出,本文所提的SwinT-YOLOX+CBAM 算法的高激活区域分布范围广且更集中,能够准确地覆盖摔倒行人躯体的大部分区域,融合空间信息和通道信息的CBAM 注意力机制可以让待检测目标特征获得更有效地增强,能够关注到大部分重要特征信息。为了进一步评估CBAM 模块的有效性,将CBAM 模块增强后输出的80×80×256、40×40×512、20×20×1 024 特征金字塔,Neck 网络采用PAFPN 方法进行双向多尺度的特征重构融合,进一步提升特征图的多样性和表达能力。PAFPN 双向融合机制分别由特征金字塔网络(FPN)和路径聚合网络(PAN)组成。在Neck 结构中先采用FPN 方法自上而下将深层特征图通过上采样与浅层特征图相融合,使大目标信息更明确;再利用PAN 方法自下而上将融合后的浅层特征图通过下采样与深层特征图相融合,使小目标信息更明确,最终获得80×80×256、40×40×512、20×20×1 024 3 组加强特征信息用于后续Head 网络预测。

图4 SwinT-YOLOX 与YOLOX 算法的可视化热图Fig.4 Visual heat map of SwinT-YOLOX and YOLOX algorithms
PAFPN 网络由CBF 和CSP_X基础组 件构成,本文改进算法在CBF 模块中采用FReLU 视觉激活函数替代YOLOX 算法CBS 模块里的SiLU 激活函数,其中CBF 模块由卷积层(Conv)、批量归一化层(BN)和FReLU 激活函数层组成。根据特征信息空间上下文相关性,在增加极少量内存开销的情况下,MA等[30]提出简单有效的FReLU 视觉激活函数,其性能在目标分类、检测、分割等领域明显优于ReLU、PReLU、SiLU 和Swish 等激活函数。FReLU 视觉激活函数表达式如下:
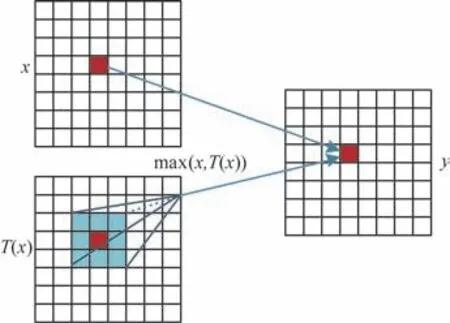
图5 FReLU 视觉激活函数示意图Fig.5 Schematic diagram of FReLU visual activation function
1.4 改进的Head 网络
除保留YOLOX Head 网络的解耦检测头、无锚点框机制、标签分配等策略以外,本文改进算法的Head 网络模型采用CBF 模块来替代YOLOX 算法的CBS 模块,即引入FReLU 视觉激活函数改进Head 结构进行预测。改进算法的总损失函数由分类预测损失、回归定位预测损失和置信度损失3 个部分构成,用于更新网络参数,并采用CIoU 损失函数代替YOLOX 的IoU 算法计算回归定位损失。整个Head网络预测过程:1)利用解耦检测头网络获得预测特征向量;2)采用无锚点框机制的SimOTA 标签分配策略挑选正样本预测框;3)计算损失函数确定检测目标。
1.4.1 基于FReLU 视觉激活函数的预测网络结构
针对特征金字塔的每个尺度信息,Head 预测网络分别采用3 个解耦检测头完成分类与回归检测任务,解耦检测头具有收敛速度快、精度高、兼容性好的优点。Head 预测网络输出支路特征整合结构如图6 所示。
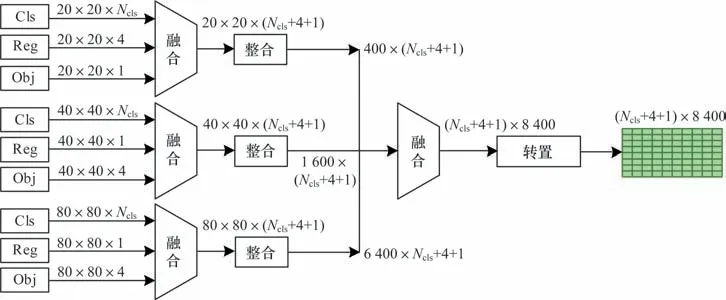
图6 Head 预测网络输出支路特征整合示意图Fig.6 Feature integration schematic diagram of Head prediction network output branch
整合步骤如下:
1)20×20×1 024 输入特征经过CBF 模块、Conv层和Sigmoid 函数组合的3 个支路,分别获得20×20×Ncls的Cls 分类预测向量、20×20×1 的Obj 置信度预测向量、20×20×4 的Reg 位置预测向量。随后,这3 个预测向量通过融合得到20×20×(Ncls+4+1)预测信息,即预测特征图上每个预测位置得到(Ncls+4+1)个参数,其中Ncls表示检测目标类别个数,4 表示目标边界框参数,1 表示置信度参数。
2)同理,40×40×512 输入特征分支融合后得到40×40×(Ncls+4+1)的预测信息,80×80×256 输入特征分支融合后得到80×80×(Ncls+4+1)的预测信息。
3)分别将3 组预测信息进行整合,再通过融合和转置操作获得(Ncls+4+1)×8 400 的二维预测特征信息,其中,8 400 为预测框数量,(Ncls+4+1)为每个预测框的(Cls,Reg,Obj)特征信息。
4)将融合后的特征信息输入到失真度评估系统中进行预测,从而获得检测结果。
1.4.2 损失函数
本文利用8 400 个被标注的预测框与真实目标框进行对比,采用SimOTA 标签分配策略通过初步和精细筛选挑选出合适的正样本预测框。首先,采用中心点判别或目标框判别方法对(Ncls+4+1)×8 400特征向量初步筛选部分正样本预测框;其次,将第i个真实目标框与第j个初筛正样本预测框对比,计算分类损失与定位回归损失的线性加权求和获得成本代价损失为权重系数,设置为3;最终,针对每个真实目标框,对其cij得分进行排序,成本最小的前k个预测框作为正样本,剩余预测框作为负样本。
当模型训练时,本文改进算法采用式(4)的总损失函数L更新网络参数,L由分类预测损失LCls、回归定位损失LReg和置信度损失LObj3 个部分组成。
其中:λ2为权重系数,设置为5。
本文改进算法采用CIoU 损失函数代替YOLOX的IoU 计算回归定位损失。IoU 的计算如式(5)所示。置信度损失和分类预测损失分别采用YOLOX 的二分类交叉熵损失函数(BCELoss)方法获得。通过SimOTA 标签分配的正样本预测框与真实框对比,采用式(6)的CIoU 损失函数计算得到回归定位损失LReg,采用式(7)的BCELoss 方法获 得分类预测损失LCls。
其中:B和Bgt分别表示预测框和真实框;b和bgt分别表示预测框和真实框的中心点;ρ(∙)表示2 个中心点之间的欧氏距离;c为预测框与真实框最小外接矩形的对角线距离;α为权重函数;ν用于测量长宽比的相似性;wgt和hgt为真实框的宽和高;w和h为预测框的宽和高;Npos为正样本个数;Oij∊{0,1}表示第i个预测目标框中是否存在第j类目标;Cij为预测类别;σ(∙)表示Sigmoid 函数。
利用所有正负样本预测框与真实框对比,采用式(8)的BCELoss 算法得到置信度损失LObj。
其中:N为正负样本总数;oi∊[0,1]表示预测目标框与真实 目标框 的IoU 值;ci为预测 置信度;σ(∙)表 示Sigmoid 函数。
2 自动扶梯行人摔倒智能监控系统
2.1 扶梯智能监控系统设计
自动扶梯行人摔倒事故通常发生在瞬息之间,传统的人员巡检式管理难以及时发现安全隐患,无法立刻按下扶梯紧急停止按钮,以至造成严重人身伤害。因此,本文设计1 个自动扶梯行人摔倒智能监控系统,其流程如图7 所示。
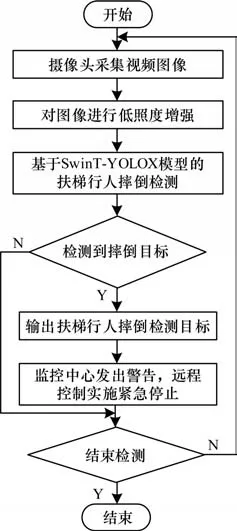
图7 扶梯智能监控系统流程Fig.7 Procedure of the escalator intelligent monitoring system
首先,通过扶梯监控摄像头采集设备获取当前视频图像;其次,针对室内环境照明强度不足问题,采用直方图均衡算法对低照度输入图像进行增强预处理;随后,采用本文提出的基于SwinT-YOLOX 网络模型的自动扶梯行人摔倒检测算法对当前采样视频帧进行摔倒事件检测;最终,如果检测到发生摔倒行为,立刻进行语音播报提示,监控平台实时向管理人员发送预警信息,并且监控中心对自动扶梯实施紧急缓停的远程控制。本文改进算法行人摔倒平均检测精度为95.92%,检测帧率为24.08 帧/s,能够快速、精准地检测到乘客摔倒事故的发生,及时采取安全应急措施,降低事故危害等级,保护行人安全。扶梯智能监控系统可以24 h 高效检测,显著减轻安全管理人员压力。
2.2 自建立数据集
本文通过视频采集设备自行构建扶梯行人摔倒检测数据库。在实际应用场景中由于运行的自动扶梯具有30°左右坡度,监控摄像头设备安装位置对检测结果会有重要影响。本文在扶梯上行口和下行口各安装1 台采样摄像头,分别采集不同视角的扶梯事故视频。摄像头安装位置及采集图像如图8 所示。摄像头安装示意图如图8(a)所示。通过模拟摔倒动作,在商场、医院、飞机场、火车站、地铁和露天扶梯等场所采集300 段视频序列,并从视频中提取8 600 张关键帧图像,其中行人正常情况图像有5 820 张,行人扶梯摔倒图像有2 780 张,图像尺度大小为720×1 280 像素。此外,为了进一步提高系统检测精度,通过网络收集,又添加3 500 张扶梯及非扶梯行人摔倒事故图像,从而建成总计12 100 张图像的数据集。
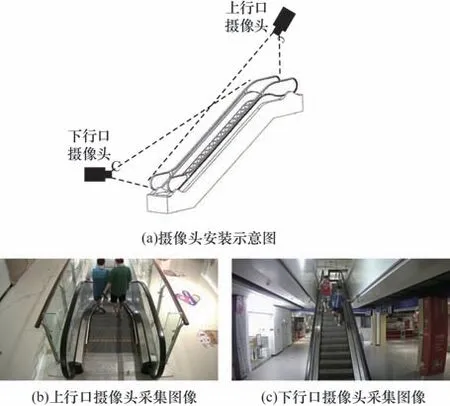
图8 摄像头安装位置及采集图像Fig.8 Camera installation position and acquisition images
低亮度图像直方图均衡增强预处理结果如图9所示。许多自动扶梯安装在商场、地铁、医院等室内环境,有些地方室内照明强度不足,无法获得清晰的扶梯运行图像,行人目标特征细节缺失,从而导致摔倒检测精度不高,如图9(a)所示。因此,本文采用快速有效的直方图均衡算法对低照度输入图像进行增强预处理,如图9(b)所示增强后的图像清晰度明显提升,从而获得更优的目标检测性能。

图9 低亮度图像直方图均衡增强预处理结果Fig.9 Preprocessing results of low histogram equalization enhancement for low-brightness image
此外,为了获得更丰富的训练数据集,本文改进算法采用Mosaic 和Mixup 2 种数据增强策略。Mosaic和Mixup数据增强方法处理结果如图10所示。

图10 Mosaic 和Mixup 数据增强方法处理结果Fig.10 Processing results of Mosaic and Mixup data enhancement methods
Mosaic 方法在数据库随机选取4 幅图片,对每张图片分别进行随机缩放、裁剪、排布等操作,并把4 幅图像拼接合成为1 幅新图片作为训练数据,如图10(e)所示。Mixup 方法从训练样本中随机抽取2 幅图片进行简单的加权求和,同时样本标签也进行对应加权求和,融合后形成新图片用于扩充训练数据,如图10(f)所示。
2.3 模型训练
当网络模型训练时,将输入图像大小统一调整为640×640×3,12 100 幅图像数据集被标注分成行人摔 倒(fall)和行人正常(normal)2 种类型,其 中normal 标签的数据有10 827 个,fall 标签的数据有9 865 个,训练集、验证集和测试集按照8∶1∶1 比例随机划分。模型采用冻结训练方式提高训练效率,加速收敛,其基础参数设置如表1 所示。
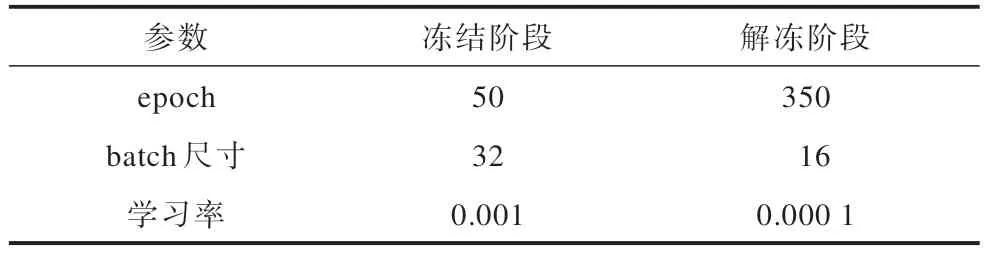
表1 SwinT-YOLOX 训练参数设置Table 1 Parameters setting of SwinT-YOLOX training
本文实验采用SGD 优化器,epoch 设为400,前50 个epoch 主干网络参数被冻结不进行更新,初始学习率设置为0.001,batch 大小为32;后350 个epoch 解冻训练阶段,将学习率设置为0.000 1,batch 大小设为16。此外,为提升模型检测能力,训练最后90 个epoch 关闭Mosaic 和Mixup 数据增强。
图11 所示为在训练过程中损失变化曲线和平均均值精度(mAP)的变化曲线。
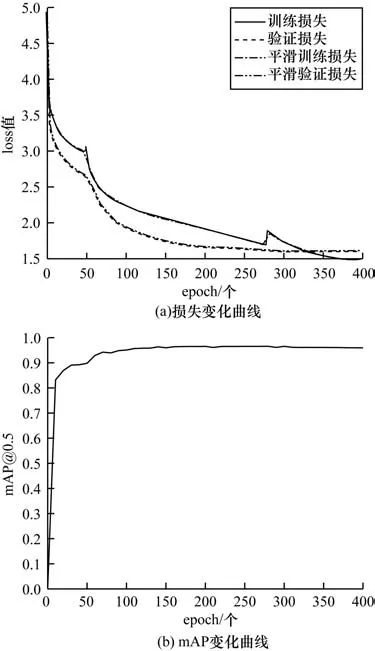
图11 SwinT-YOLOX 算法的损失和mAP 变化曲线Fig.11 Loss and mAP variation curves of SwinT-YOLOX algorithm
从图11(a)可以看出,训练初期前几个epoch 损失值快速下降,在第50 个epoch 附近达到局部最优解,解冻后350 次迭代,损失值缓慢下降逐渐收敛,最终训练集和验证集的loss 值分别收敛于1.48 和1.57,选取训练中最低loss 值的训练模型用来检测。从图11(b)可以看出,前50 个epoch 检测精度mAP迅速上升,epoch 达到100 以后mAP 逐渐趋于平稳,最终获得96.71% 的检测精度,相比YOLOX 算法mAP 提升了6.51%。
3 实验结果分析与讨论
3.1 实验环境与参数设置
本文算法实验硬件平台均在CPU 为Intel i9-10900X 3.70 GHz,GPU 为2 张NVIDIA GeForce RTX 3090,内存32 GB。计算机操作系统为Ubuntu 20.04,采用Python 3.8.13 编程语言在PyTorch 1.12.0、Anaconda 4.10.3、CUDA11.1、CUDNN 8.5.0深度学习框架上实现编程。在训练和测试阶段,输入图像尺寸大小被调整为640×640×3,12 100 幅数据集分成行人摔倒(fall)和非摔倒(normal)2 种类型,训练集、验证集和测试集按8∶1∶1 比例随机划分。
本文采用精确度(P)、召回率(R)、综合评价指标F1 值(F1)、平均精度(AP,计算中用AAP)和平均均值精度(mAP,计算中用mmAP)、帧率(FPS)来评估模型性能,10 亿次浮点运算数(GFLOPs)描述模型计算量,评估模型对硬件算力要求。P、R、F1的计算式如下:
其中:TTP表示样本真实是正例,预测结果是正例;FFP表示样本真实是负例,预测结果是正例;FFN表示样本真实是正例,预测结果是负例。
AP 指单个类别的平均精度,由P-R曲线与坐标轴围成的面积获得,其计算式如下:
mAP 指所有类别平均精度的均值,计算式如下:
其中:n表示样本类别总数;APi表示第i类样本的平均精度。
3.2 消融实验结果
为验证改进策略对检测性能的影响,本文对自建数据集进行大量的消融实验。消融实验结果如表2 所示,首先采用YOLOX 算法作为基准进行测试,当采用SwinT 替代骨干网络后,mAP@0.5 提升4.39 个百分点,Neck 网络融合CBAM 注意力机制的mAP@0.5 进一步提升1.14 个百分点,在Head 网络引入的CIoU 损失函数和FReLU 激活函数mAP@0.5 精度分别提升0.09 和0.89 个百分点。最终,本文改进的SwinT-YOLOX 算法可以获得96.71%的mAP@0.5 检测精度,相比YOLOX 算法提升6.51 个百分点。因此,SwinT 网络具有更强的特征提取能力,扶梯行人摔倒检测精度提升效果较为明显,其他改进策略也对检测性能提升具有明显贡献。

表2 改进策略的消融实验结果Table 2 Ablation experiment results of improved strategy %
根据网络模型深度和SwinT 模块参数不同,本文分别研究SwinT 骨干网络的SwinT_T(通道深度为96,每层模块倍数{2,2,6,2})、SwinT_S(通道深度为96,每层模块倍数{2,2,18,2})、SwinT_B(通道深度为128,每层模块倍数{2,2,18,2})、SwinT_L(通道深度为192,每层模块倍数{2,2,18,2})4 种不同模型对检测性能的影响。不同模型规模的检测效果如表3 所示。从表3 可以看出,4 种模型都具有较好的检测精度,mAP@0.5 精度均大于95%,且随着通道深度及SwinT 模块倍数的增加,检测精度会显著提升,模型大小和GFLOPs 数量也随之增加,综合权衡检测性能、内存及运行速率需求,本文改进算法SwinT 骨干网 络选择SwinT_B 模 型,Neck 和Head 网络结构选择YOLOX_S 模型。

表3 不同模型规模的检测效果Table 3 Detection effects among different model size
由于监控摄像头设备安装的位置及角度会影响自动扶梯行人图像的采样效果,因此本文研究由不同摄像头位置采集构建的3 种图像数据库对摔倒检测性能的影响,分别是只使用上行口摄像头采集的图像数据库、只使用下行口摄像头采集的图像数据库以及使用上行口+下行口摄像头采集的所有图像数据库。不同摄像头位置采集的图像数据库检测效果如表4 所示。

表4 不同摄像头位置采集的图像数据库检测效果Table 4 Detection effect of image database collected from different camera positions
从表4 可以看出,使用上行口+下行口摄像头采集的所有图像数据库能获得不同角度更丰富的行人特征信息,其扶梯行人摔倒检测精度最高,只使用上行口数据或下行口数据的检测精度分别降低1.18 和2.34 个百分点。因此,在模型训练时,采用上行口+下行口2 个摄像头采集自建数据库图像进行模型训练,以获得最佳的检测精度。
3.3 不同算法对比实验结果
表5 所示为在自建数据集上SwinT-YOLOX 改进算法 与AlphaPose[10]、OpenPose[7]、YOLOv5[20]、YOLOv6[21]、YOLOv7[22]、YOLOX[23]当前主 流行人摔倒检测算法的性能对比结果,其中YOLOX、YOLOv5、YOLOv6 采用Medium 模型。
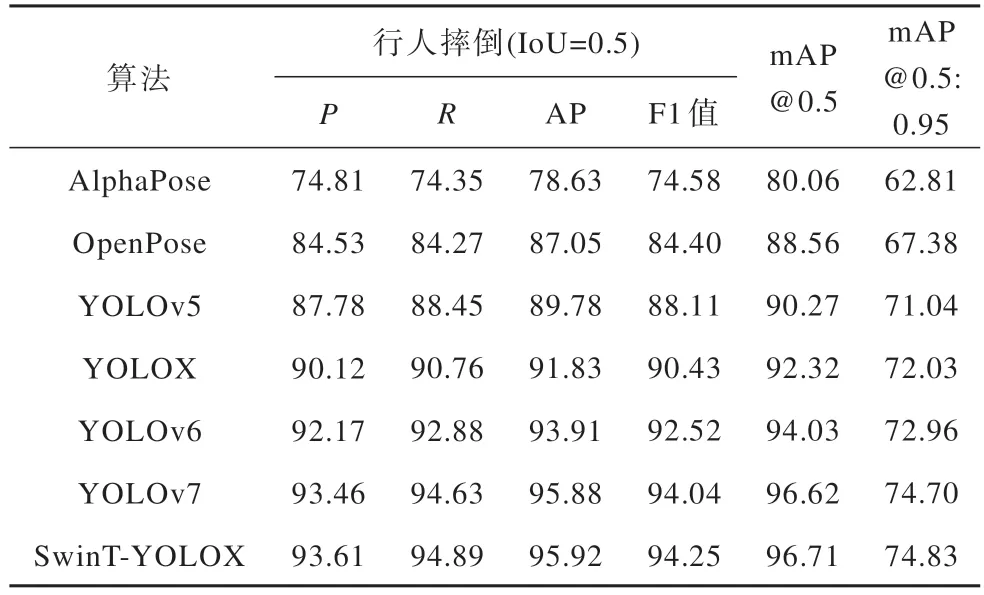
表5 不同算法在自建数据集上检测性能对比结果Table 5 Comparison results of detection performance among different algorithms on self-built datasets %
实验结果显示本文改进算法的mAP@0.5 检测精度达到96.71%,比AlphaPose、OpenPose 算法分别提 高 17.22% 和 8.43%,比 YOLOX、YOLOv5、YOLOv6 算法分别提高4.54%、6.66%、2.77%,检测精度略优于YOLOv7 算法。此外,本文SwinTYOLOX 算法行人摔倒检测分别获得93.61%的精确度、94.89% 的召回率,95.92% 的平均检测精度和94.25%的F1 值,明显优于其他检测算法。本文改进算法不仅检测性能明显提高,而且检测帧率为24.08 帧/s,具有较优的实时性。
3.4 可视化结果与分析
图12 所示为YOLOv5、YOLOv6、YOLOv7、YOLOX 和SwinT-YOLOX 这5 种算法 在自建数据集中扶梯行人摔倒检测的视觉定性对比结果。第1列表示上行口摄像头单行人摔倒检测结果,第2 列表示上行口摄像头多行人部分遮挡摔倒检测结果,第3 列表示下行口摄像头单行人摔倒检测结果,第4 列表示下行口摄像头多行人部分遮挡摔倒检测结果。从图12 可以看出,无论是上行口摄像头还是下行口摄像头检测,5 种算法对于单行人都能准确地检测到摔倒事故。在上行口摄像头采集的多行人扶梯摔倒事故图像中,2 位行人目标均比较小,并且摔倒行人部分身体被遮挡,YOLOv5 算法没有检测到后面的摔倒目标,其余4 种算法仍然能够准确地检测到小目标行人的摔倒事件。在下行口采集的多行人扶梯摔倒事故图像中,5 种算法均检测出摔倒事故,但是YOLOX 算法未检测出非摔倒行人。

图12 不同算法的扶梯行人摔倒检测结果对比Fig.12 Comparison of escalator pedestrian fall detection results using different algorithms
在实际扶梯行人摔倒事故中,图13 和图14 分别所示为图像与视频序列检测结果的视觉对比。从图13 可以看出,除了YOLOv5 有1 幅孩子摔倒图像没有检测出来以外,其余4 种算法均能较准确地检测出扶梯摔倒事故,其中本文改进算法的检测效果较好,预测置信度也普遍较高。从图14 可以看出,对于乘坐轮椅的行人,本文SwinT-YOLOX 改进算法能较准确地检测到摔倒事故,在视频最开始发生摔倒事故的第4 帧中YOLOv5 和YOLOX 算法没有检测到摔倒目标,并且YOLOv5、YOLOv6、YOLOv7 和YOLOX 这4 种算法在后续多个视频帧中也发生了漏检情况。

图13 在实际扶梯事故中行人摔倒检测结果图像视觉对比Fig.13 Image visual comparison of pedestrian fall detection results in actual escalator accidents

图14 在实际扶梯事故中行人摔倒检测结果视频帧视觉对比Fig.14 Visual comparison of video frames of pedestrian fall detection results in actual escalator accidents
4 结束语
本文提出基于SwinT-YOLOX 网络模型自动扶梯行人摔倒检测算法,能够快速、精准地检测到乘客摔倒事故发生,使得监控管理平台可以及时发出预警信息,并立即实施紧急停车命令,确保乘客安全。改进算法的骨干网络采用Swin Transformer 模型;Neck 网络采用融合CBAM 注意力机制的PAFPN 结构,同时利用FReLU 视觉激活函数改进网络模块以提高特征检测性能。实验结果表明,本文改进算法采用端到端预测,具有速度快、检测精度高、易于部署的优点,扶梯智能监控系统可以全天高效检测,显著减轻扶梯日常安全管理人员的工作。后续将对本文改进算法的模型进行优化,以及嵌入式设备硬件平台的开发部署,同时实现监控设备的视频采集与智能检测功能,最终达到与自动扶梯联动控制的目的,当乘客摔倒事故发生时能够更迅速地完成减速停机命令。
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
思维与智慧·上半月(2022年4期)2022-04-08
意林(2021年5期)2021-04-18
小聪仔(幼儿版)(2020年12期)2020-02-01
扬子江(2019年1期)2019-03-08
小天使·一年级语数英综合(2017年6期)2017-06-07
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
好孩子画报(2016年6期)2016-05-14
