
融合乌尔都语词性序列预测的汉乌神经机器翻译*
2024-03-19 11:10陈欢欢MuhammadNaeemUlHassan
计算机工程与科学 2024年3期
陈欢欢,王 剑,Muhammad Naeem Ul Hassan
(1.昆明理工大学信息工程与自动化学院,云南 昆明 650500; 2.昆明理工大学云南省人工智能重点实验室,云南 昆明 650500)
1 引言
随着信息技术的快速发展,机器翻译作为自然语言处理的重要组成部分得到了广泛的应用与发展。近年来,由于计算机计算能力的快速提升以及深度学习算法的提出,神经机器翻译NMT(Neural Machine Translation)取得了良好的结果,在大规模平行语料的基础上,能够有效地学习各种语言的特点。然而,乌尔都语和汉语在句法结构上存在较大的差异,乌尔都语属于印欧语系,其句子主干成分的语序基本均为主语-宾语-谓语SOV(Subject-Object-Verb)结构,其次乌尔都语的语序结构相对自由,如图1所示,部分词在句中的位置并不唯一,这些都影响着传统翻译方法的效果。

Figure 1 Example of Urdu: I can’t go图1 乌尔都语示例:我不能走
语言的差异性对机器翻译系统的性能有着不可忽略的影响,因此本文提出融合乌尔都语词性POS(Part of Speech)序列预测的神经机器翻译方法。首先,训练词性预测模型,使用Transformer在原语言的基础上预测目标语言的词性序列,以此学习乌尔都语的语序结构特征。然后,训练翻译模型,将词性序列预测模型的知识融入翻译模型中,基于统计方法构建乌尔都语词汇与词性标签关联矩阵,以词性序列预测结果指导翻译模型生成译文。
2 相关工作
机器翻译出现以来主要经历3个发展阶段:基于规则的翻译、统计机器翻译和神经机器翻译NMT。神经机器翻译完全使用神经网络来完成从源语言到目标语言的翻译过程,采用分布式语言表示,将翻译知识隐含在神经网络结构和参数中,对语言表示和翻译模型实现联合建模和学习,训练端到端神经机器翻译模型,完成源语言文本到目标语言文本的直接转换[1,2]。神经机器翻译以其独特的优势迅速成为主流的机器翻译方法,并在翻译技术上取得了巨大突破,翻译质量也不断得到改善和提升。
受限于乌尔都语相关语料资源稀少,汉乌语言翻译相关研究一直以来寥寥无几。从可查文献来看,Zakira等[3,4]曾将神经网络模型应用于汉乌语言翻译,分别使用OpenNMT和长短时记忆网络LSTM(Long Short-Term Memory)实现汉语到乌尔都语的翻译。然而,这些工作缺乏有针对性的创新,翻译效果欠佳。
作为参照,英乌双语之间的翻译研究已有不少的研究成果。高巍等[5,6]分别将Transformer和Bi-LSTM(Bidirectional Long Short-Term Memory)网络应用于乌英机器翻译。Jawaid等[7]考虑了乌尔都语和英语之间的语序差异,构建了基于短语的统计机器翻译,通过对源语言句子的句法分析树中的短语进行重新排序来提升翻译质量。Shahnawaz等[8]考虑英乌双语的语言特征不同,提出基于GIZA++( GIZA是SMT工具包EGYPT的一个组成部分,GIZA++是GIZA的扩展版本)、SRILM(SRI Language Modeling, SRI是一个独立的非盈利性研究组织)和Moses的英乌机器翻译系统模型,Moses采用最小翻译错误率训练模型,对因子翻译模型进行译码和训练,最终提升翻译效果。
神经机器翻译的优异效果使其逐渐成为主流的机器翻译方法。Zoph等[9]将长短时记忆网络LSTM应用于乌英机器翻译。Rai等[10]提出了一种基于卷积的端到端的英乌机器翻译模型,该模型降低了注意词映射的非线性,并在最终结果上优于Mixture Models[11]、OpenNMT[12]和Wiseman-Rush Models[13]等翻译模型。Shahnawaz等[14]提出了一种基于机器翻译实例推理CBR(Case-Based Reasoning)、翻译规则库模型和人工神经网络模型的乌英机器翻译模型,采用CBR方法选择合适的翻译规则,以便将输入的英文语句翻译成乌尔都语。由于翻译规则需要语言专家人为制定,该方法的实现需要较大的工作量且实现难度很大。因此,针对语言差异性规则改进的翻译方法仍需进一步探究。
本文提出融合乌尔都语词性序列预测的神经机器翻译方法,在传统机器翻译模型的基础上融合词性序列的预测结果,构成新的机器翻译模型框架,通过辅助模型学习乌尔都语词性序列特征来提升翻译效果。
3 模型构建
本文基于Transformer模型提出了融合乌尔都语词性序列预测的汉乌神经机器翻译模型,通过训练词性序列预测模型学习乌尔都语的词性序列特征,并将学习到的特征融入传统的机器翻译模型中,模型的整体框架如图2所示,输入为中文句子,输出为乌尔都语句子。

Figure 2 Chinese-Urdu translation model图2 汉乌翻译模型
3.1 Transformer模型
2017年,Vaswani等[15]提出了完全基于注意力(Attention)机制的Transformer模型,其总体结构仍是编码器-解码器的结构,但Transformer抛弃了序列计算,使得模型高并行化,显著提高了计算效率和模型性能。Transformer模型结构如图3所示,其中N表示层数。编码器分为自注意力层和前馈神经网络层。解码器除包含编码器结构中自注意力层和前馈神经网络层外,在自注意力层和前馈神经网络层间加入交叉注意力层(编码器-解码器注意力层),同时在自注意力层加入序列掩码。

Figure 3 Structure of Transformer model图3 Transformer模型结构
Transformer创新性地使用了自注意力机制,其定义如式(1)所示:
(1)
其中,Q、K和V是经由3个线性变换矩阵得到的向量表征,dk表示向量的维度。
模型使用了多头注意力来捕捉不同子空间下词之间的关联关系,多头注意力机制通过并行计算多个自注意力,从不同的表示子空间中学习不同的上下文信息,如式(2)和式(3)所示:
MultiHead(Q,K,V)=
Concat(head1,head2,…,headh,…,headH)
(2)
(3)
其中,headh(1≤h≤H)表示模型使用的第h个注意力头。
Transformer通过注意力机制学习句子中每个词之间的关联关系,有效地解决了长距离依赖的问题,并且Attention机制支持并行化计算,极大提高了计算效率,在翻译任务上取得了显著的效果。
3.2 词性序列预测模型


Figure 4 Example of Urdu word order: I sent him a letter图4 乌尔都语词序示例:我给他寄了一封信

汉乌双语语序结构存在差异,而这种差异性明显地表现在词性序列上,为提升翻译效果,本文将词性序列的差异性融入翻译过程中。本文考虑翻译过程中先对目标词的词性进行预测,再对目标词进行预测的方式。预测概率表达如式(4)所示:
P(yt)=P(ypos)×P(yt|ypos)
(4)
其中,ypos表示预测的词性标签,yt表示根据预先预测出的词性标签预测出的目标词,P(ypos)表示预测的词性概率,P(yt)表示预测出的目标词概率。
序列预测模型的输入和输出如图5所示,模型编码端输入源语句,解码端输入目标语和目标语对应的词性序列。编码端和解码端的词嵌入表达分别如式(5)和式(6)所示:
(5)
(6)

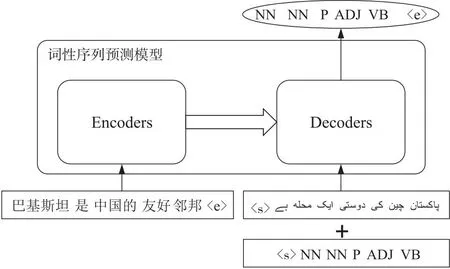
Figure 5 Prediction model of part of speech sequence图5 词性序列预测模型
模型预测时输入源语言序列和已知目标语言序列及对应词性信息,输出下一个目标词的词性预测。基于词性预测结果与翻译模型的词预测结果联合预测下一个目标词。再将预测的目标词同时输入翻译模型和词性预测模型的解码端继续预测下一个目标词,直至预测到结束标签‘〈e〉’,从而得到源语言对应的翻译语句。
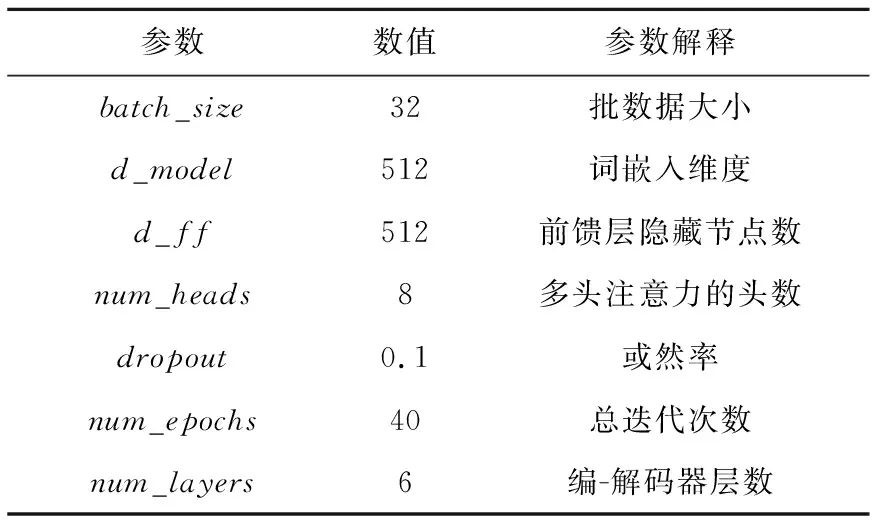
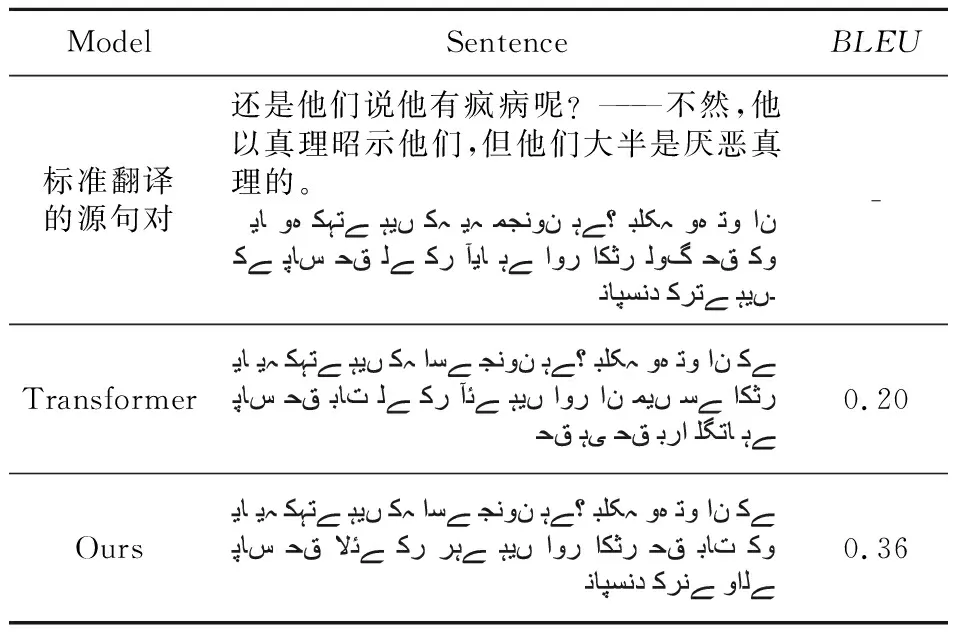
给定编码端输入序列x=(x1,x2,…,xn)和已生成的翻译序列y=(y1,y2,…,yn),解码端产生下一个词的词性标签概率P(Tt|y 翻译模型同样使用Transformer模型,参数设置与序列预测模型保持一致。 为将词性序列预测结果融入翻译模型中,本文利用统计方法构建词性标签-词表关联矩阵。基于乌尔都语带词性标签语料统计词典中每个词的词性,构建大小为vocab_size×postag_size的关联矩阵。矩阵中词与词性标签有关联关系的对应位置为1,反之为0,由此构建词性标签-词表关联矩阵。关联矩阵构建示例如图6所示,以稀疏的0-1矩阵表现乌尔都语词和词性标签的对应关系。 Figure 6 Construction of incidence matrix图6 关联矩阵构建 由关联矩阵将词性序列预测结果和翻译模型预测结果结合起来。设t时刻利用汉乌翻译模型解码端产生下一个词的预测概率为P(yt|y P(yt|y P(Tt|y (7) 其中,E表示关联矩阵,最后通过Softmax函数估计t时刻目标语单词的概率分布。 模型构建完成后,分别对词性序列预测模型和翻译模型进行训练。模型构建流程大致如图7所示。 Figure 7 Process of system图7 模型构建流程 本文实验使用总数据约72 000条汉乌平行语料,数据来源于古兰经以及Subtitles网站,训练集、验证集和测试集的划分如表1所示。 Table 1 Dataset partition表1 数据集划分 数据集的处理方面,本文使用了自然语言处理工具NLTK(Natural Language ToolKit)对中文文本进行切分,乌尔都语方面则仅以空格作为词的边界来对语料进行分词处理。对于双语语料设置了最长序列长度50,舍弃了过长平行句对。实验环境基于NVIDIA®GeForce RTXTM3060 GPU,Windows系统,Python版本为3.6.0,PyTorch版本为1.10.2。 此外本文使用Bushra Jawaid发布的乌尔都语词性标记器[16]来对本文实验数据中的乌尔都语部分进行词性标记,该标记器基于SVMTool训练,准确率达到87.74%,图8展示了部分数据的标记结果。 Figure 8 Examples of part of speech labels in Urdu language texts图8 乌尔都语文本词性标记示例 本文将融入乌尔都语词性序列预测的翻译模型与基准Transformer模型进行对比实验,参数设置如表2所示。 图9展示了本文模型和基准模型的损失变化,随着迭代次数Epoch的增加,损失值逐渐降低。由于加入了预测的词性信息,本文模型的损失在初始时便低于基准Transformer模型,随迭代次数增加,模型逐渐收敛,最终本文模型损失相较于基准模型低0.17左右,由此可以看出本文模型对于实验数据拥有较好的拟合度。 Table 2 Model parameters表2 模型参数 Figure 9 Curves of loss图9 损失变化曲线 本文实验中采用的评价指标为BLEU(BiLingual Evaluation Understudy)[17]值。BLEU值是用来衡量机器翻译文本与参考文本之间的相似程度的指标,本文通过BLEU值来衡量译文质量。实验中每迭代一次就对模型的翻译效果进行一次测试,在测试集上运行,根据输出的BLEU值检测翻译效果的变化,测试集大小为3 000条数据。表3展示了每迭代5次时测试的BLEU值。图10为BLEU值随Epoch的变化曲线。 从图10可以看出,与基准Transformer模型相比,本文提出的融入乌尔都语词性序列预测的翻译模型的BLEU值提高较为明显,在迭代40次时最优结果为0.34,相较于基准模型其BLEU值提升了0.13。这说明融入词性序列信息的翻译模型能够有效提升翻译效果。 Table 3 Change of BLEU scores表3 BLEU值变化 Figure 10 Curves of BLEU scores图10 BLEU值变化曲线 Table 4 Comparison of models表4 模型对比 巴基斯坦作为中国的友好邻邦和“一带一路”倡议的重要国家,开展汉乌语言机器翻译研究具有非常重要的现实意义。本文提出融合乌尔都语词性序列信息的汉乌神经机器翻译模型,将预测目标语言的词性序列信息融入翻译模型中,最终实验结果表明,本文方法的BLEU值相较于基准模型的有所提升。本文在汉乌语言神经机器翻译方面进行了开创性的研究,也为后续的改进打下了研究基础。现阶段由于语料库数据较少且数据来源单一,模型并不能充分学习语言知识,导致模型的泛化能力不够,因此,扩充语料是下一步工作的要点。另外,翻译模型和词性序列预测模型的融合可以进一步优化,有研究证明Transformer模型自底向上各层网络依次聚焦于词级-语法级-语义级的表示[18],那么词性序列预测模型是否对翻译模型的中低层表示具有指导意义是未来值得验证的探究点。3.3 融入词性序列预测信息的翻译模型

3.4 模型构建流程

4 实验与结果分析
4.1 实验环境


4.2 实验结果评估和分析




5 结束语
猜你喜欢
贵州师范学院学报(2022年12期)2023-01-16小雪花·成长指南(2022年1期)2022-04-09烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19长春师范大学学报(2017年8期)2017-09-03传媒评论(2017年3期)2017-06-13海外华文教育(2016年1期)2017-01-20湖北民族大学学报(自然科学版)(2016年3期)2016-11-29第二课堂(课外活动版)(2016年2期)2016-10-21当代教育理论与实践(2015年9期)2015-12-16民族古籍研究(2014年0期)2014-10-27
