
面向工业缺陷分类的交互式易混淆缺陷分离方法研究*
2024-03-19 11:10罗月童张延孔
计算机工程与科学 2024年3期
罗月童,李 超,周 波,张延孔
(合肥工业大学计算机与信息学院,安徽 合肥 230601)
1 引言
产品表面缺陷检测是工业生产的重要环节。人工检测具有工作量大、结果不稳定等问题[1]。得益于深度学习的优良性能,基于机器视觉的自动工业缺陷检测正在获得越来越广泛的应用。虽然基于深度学习的分类算法的性能已经非常高,但在实际应用中,基于深度学习的产品缺陷检测模型仍面临以下2个挑战:(1)存在易混淆缺陷,即2种或多种缺陷非常相似,影响分类精度;(2)对缺陷分类精度要求非常高。所以,虽然易混淆缺陷通常比较少,但会导致分类精度不能满足工业生产的要求,减少易混淆缺陷对分类精度的影响具有重要意义。
在工业产品上,虽然某些缺陷的成因不同使得处理方式也不同,但其视觉外观非常类似,这样基于机器视觉的分类方法难以区分这些缺陷。如图1所示,CMOS(Complementary Metal Oxide Semiconductor)产品表面的残胶和脏污2种缺陷,前者导致产品报废,后者只需要用酒精擦拭处理即可,但它们视觉外观非常相似,本文称这类缺陷为易混淆缺陷。易混淆缺陷通常处于不同类型缺陷的交叉地带,属于一种重叠数据[2]。重叠数据会让类别之间的特征边界变得模糊,导致分类模型难以学习到正确的分类边界,进而影响分类的准确性[3]。文献[4]提出调整支持向量机SVM(Support Vector Machine)以处理重叠数据;文献[5]专注于通过修改朴素贝叶斯算法来优化分类算法。目前缺少面向深度学习的重叠数据优化方法研究。
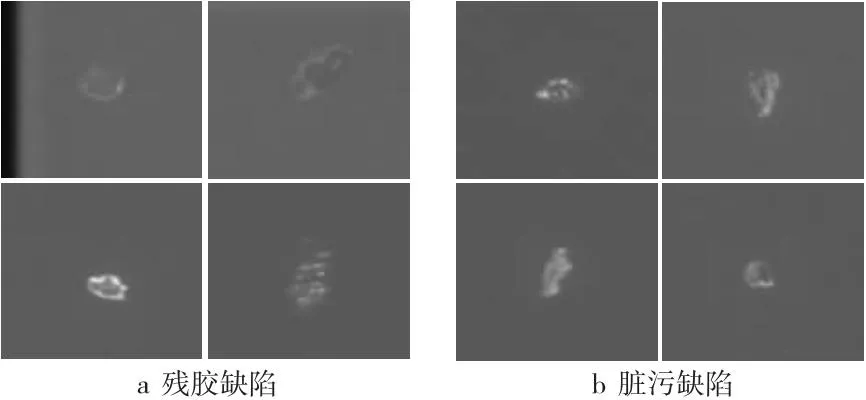
Figure 1 Examples of confusable defects on the surface of industrial products图1 工业产品表面易混淆缺陷实例
虽然应用更复杂的模型、准备更丰富的数据能在一定程度上减少易混淆数据的影响,但是,一方面代价较大,另一方面难以从根本上解决上述2个挑战。本文提出一种新的思路,将易混淆缺陷作为一个或多个被称为虚缺陷的新缺陷类型,让深度学习网络把易混淆缺陷分为虚缺陷,同时保证其他缺陷能够被准确分类。虽然易混淆缺陷没有被分开,仍需要进一步人工处理,但因为它们通常占比很少,所以额外处理的代价不大。
当前,生产实践中通常用如下2种方法处理易混淆缺陷:(1)手动挑选出易混淆缺陷,但工作量大且难度高;(2)通过算法辅助,将类别间分类错误的数据直接作为新的虚缺陷进行反复迭代,因为其处理流程固定,本文称之为固定算法。虽然方法2相对效率更高,但因为固定算法仅将分类错误数据当作易混淆缺陷,往往会遗漏潜在的易混淆缺陷,导致效果不佳。
可视分析将机器智能和人类的直觉、顿悟等智能相结合,在解决模糊问题上有巨大优势。已经有多位研究人员将可视分析用于优化训练数据,如文献[6]中提出了交互式可视分析工具Label- Inspect,以识别数据集中不可靠的标签实例;文献[7]提出了OoDAnalyzer,对数据集中的异常数据OoD(Out-of-Distribution)进行分析识别。因为易混淆缺陷并不存在明确的定义和标准,需要综合判断,所以本文设计并开发一套可视交互系统,帮助用户快速筛选易混淆缺陷、定义虚缺陷。虽然和文献[5,6]类似,本文也是从可视分析的视角研究训练数据的优化问题,但本文解决的是全新问题。
综上所述,本文的主要工作如下所示:
(1)提出了一种基于虚缺陷的易混淆缺陷处理方法,将少量易混淆缺陷划分为单独的虚类别,从而避免对大量其他缺陷产生影响,提高了分类模型在生产实践中的可用性。
(2)设计了一套交互式虚缺陷构建系统,即多视图关联可视分析系统,帮助用户快速挑选训练数据中的易混淆缺陷、设置虚缺陷的种类和观察模型的优化效果,进而实现基于虚缺陷的易混淆缺陷处理。
2 相关工作
本文采用可视分析方法处理训练数据中的易混淆缺陷,而且因为易混淆数据是一种重叠数据,所以将从重叠数据分类、面向深度学习的可视化2个方面介绍相关工作。
2.1 重叠数据分类
在分类问题中,常有不同类别样本重叠的现象[8],这一现象意味着不同类别的样本具有相似特征。这些有相似特征的样本所覆盖的区域被称为重叠区域[9]。有研究指出许多发生在类边界的分类错误的根本原因就是重叠数据的存在[10]。关于重叠数据的研究众多,比如文献[11]建议调整分类算法;文献[12]通过修改原始数据或者附加其他特征来减轻重叠数据的影响。
尽管这些方法在特定场景中有效果,但它们是针对特定的分类算法,所以应用于其他算法时缺少普适性,如针对SVM的改进不能应用于深度学习网络。与上述研究不同,本文从优化训练数据的角度出发解决易混淆缺陷数据问题,本文方法可以和任何训练类方法相结合,所以有更好的通用性。
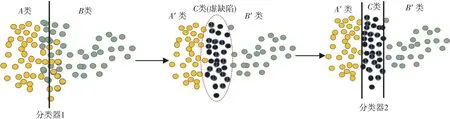
Figure 2 Process of confusable defects separation图2 易混淆缺陷分离的过程
2.2 面向深度学习的可视分析
近年来,可视分析方法被大量用于改进深度学习方法的性能[13],主要从异常数据、数据标签和数据隐私3个方面对数据质量进行改进。研究人员采用可视化技术将各类数据映射为图形元素,构造交互式分析环境,以支持用户识别、理解和处理异常。针对分类标签错误问题,Xiang等[14]设计了层次化 TSNE(T-distributed Stochastic Neighbor Embedding)方法,以查看图像数据集,结合自动纠正算法,迭代地对标签进行纠正。类似地,Bäuerle等[15]设计了基于矩阵和散点图的可视化方法,允许用户迭代地纠正错误标签和改进分类器性能。在众包模式中,错误标签往往集中在部分参与人的标注结果上。针对该问题,Park等[16]设计了一个可视分析系统,用于改善临床图像数据众包标注参与人的工作质量。
与上述面向深度学习的可视化方法类似,本文设计了一套虚缺陷划分可视化系统,帮助用户挑选易混淆缺陷、定义虚缺陷,从而实现基于虚缺陷的易混淆缺陷处理。
3 易混淆缺陷分离方法
3.1 易混淆缺陷分离原理
本文把易混淆缺陷从大量缺陷中分离出来,使得不同缺陷的样本之间有清晰边界,从而减少易混淆缺陷对分类精度的影响,具体做法如图2所示。因为本文通过优化缺陷数据训练集来提升分类器的性能,所以本文方法是分离缺陷数据训练集中的易混淆缺陷。如图2所示有2个缺陷类别A和B,首先使用当前分类器对训练集进行分类,提取分类错误缺陷并将它们作为初步易混淆缺陷;然后将易混淆缺陷更改类别标签为虚缺陷C,剩下的A′类和B′类之间有清晰边界;最后使用优化后的训练集重新训练分类网络。在新网络中,原始数据类别A类和B类数据之间的错误分类问题被成功弱化,从而提升了各自类别的精度。
3.2 易混淆缺陷分离过程
交互式易混淆缺陷的分离流程如图3 所示,整个过程分成以下3个步骤:
(1)分类网络训练和易混淆缺陷自动检测。首先将给定的数据集以及对应的类型标签作为训练集,通过卷积神经网络学习训练集中的缺陷特征并对训练集进行分类预测;然后将分类结果通过混淆矩阵进行展示。通过混淆矩阵,用户可以轻易地识别出分类错误点,而分类错误点也正是易混淆数据的一部分。最后从分类错误缺陷数据出发,进行易混淆缺陷探索,为分离易混淆缺陷做准备。
(2)交互式易混淆缺陷数据优化。首先用户选择需要待处理的混淆缺陷类别,通过错误分类样本来定位周围易混淆缺陷的区域。根据深度学习知识,虽然分布在错误分类周围的数据并没有错分成其他类别,但会有潜在分错的可能性,即潜在的易混淆缺陷数据。潜在的缺陷数据也需要从训练集中分离出来,使得非虚缺陷的部分能够满足分类精度高的要求。本文需要通过虚缺陷划分系统将该部分数据划分成虚缺陷,以达到从训练数据中分离出来的目的。
(3)虚缺陷类别设置。在完成以上2步后,用户已经对训练数据集中的易混淆缺陷数据完成检索,下一步可以为易混淆数据赋予虚缺陷类别标签,以便重新训练深度学习分类模型。一般而言,易混淆数据在空间中成簇分布,因此可以为每一个簇赋予一个新的虚缺陷类别标签。如果虚缺陷种类过多且每个类别中数据量过少,会导致深度学习分类网络很难学习虚缺陷类别的信息。为防止这一情况,本文充分考虑易混淆数据的总体特征相似性,设计了虚缺陷类别合并系统。用户可以将不同簇的虚缺陷类别数据合并为一个虚缺陷类别,从而减少虚缺陷的标签个数。
第2步和第3步的内容会在第4节进行详细描述。
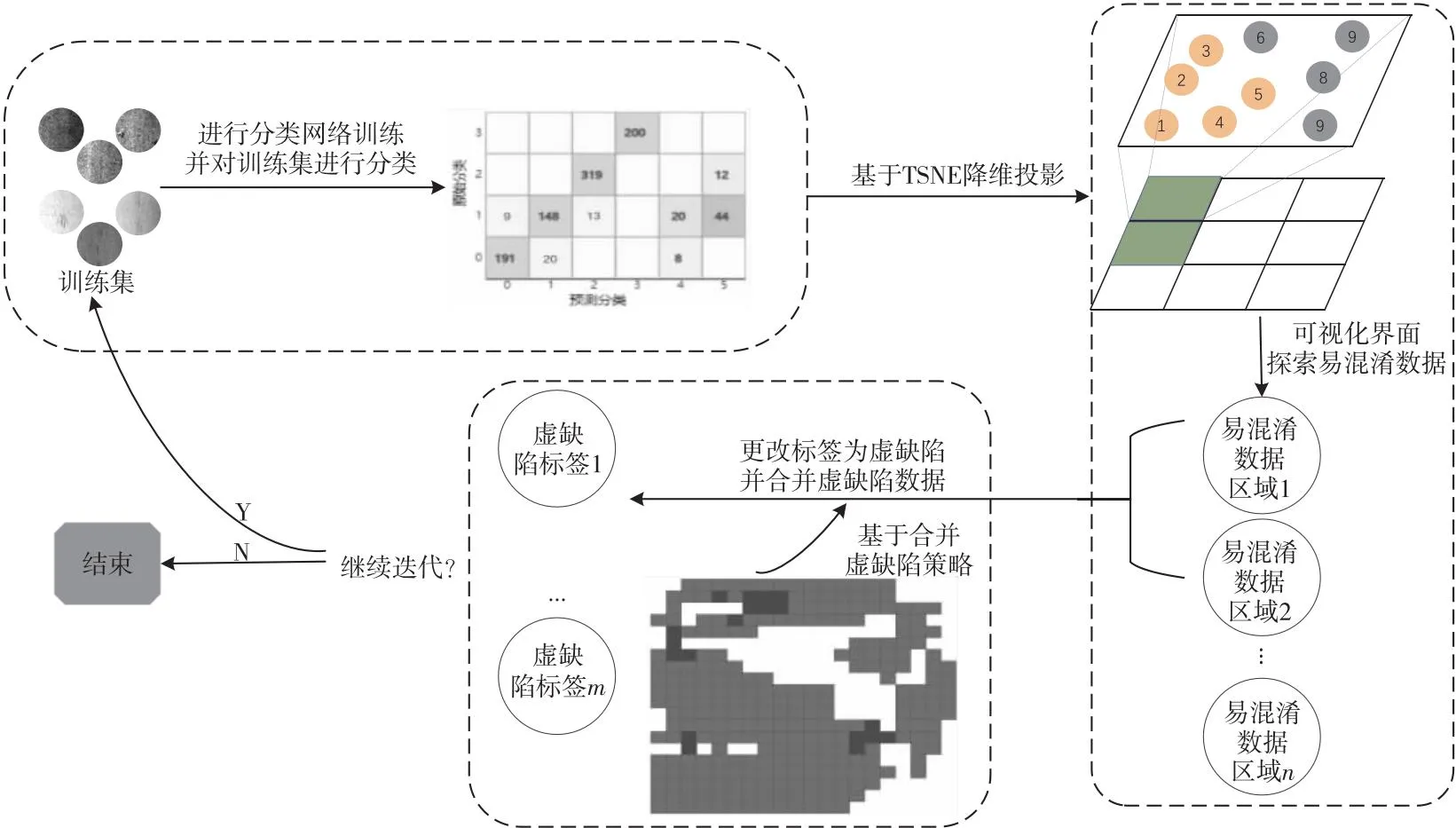
Figure 3 Process of interactive confusable defects separation图3 交互式易混淆缺陷分离过程
4 交互式虚缺陷划分系统
4.1 可视化需求分析
为支持3.2节所述的流程及与一线从业者的沟通,交互式易混淆缺陷分离系统需要完成的任务如下所示:
(1)分类结果的可视化呈现。本文需要消除指定缺陷之间的易混淆缺陷对分类结果的影响,故需要对每次处理后的数据集进行分类并可视化呈现分类结果,以便用户对当前数据集分类效果进行准确评估,进而判断是否需要继续在训练集上进行迭代。
(2)探索易混淆缺陷。在各种研究和实践项目中发现,易混淆缺陷不仅包括分类错误的数据,还可能包含和分类错误数据相似的数据,所以还需要呈现数据之间的相似性;此外,需要将虚缺陷样本与训练数据集中的正常样本进行比较,以了解虚缺陷样本与正常样本之间的相似性和差异性。为此,专家们需要将相似的图像放在一起,并且以紧凑的方式直观地显示出数据集中的每个图像,这样他们就可以更轻松地识别出易混淆缺陷。这一要求也与当前识别数据集偏差的常见做法一致。
(3)虚缺陷标签的分配。如果根据固定算法,将每2种缺陷之间产生的错误分类数据都作为一种虚缺陷,就会产生过多的虚缺陷。故本文采取合并易混淆缺陷的方式,以减少虚缺陷的类别标签个数。合并虚缺陷的目的包括:①减少产生的虚缺陷种类;②保证每种虚缺陷有足够的训练数据,以避免模型出现过拟合。虚缺陷标签的分配应当遵循易混淆缺陷数据点距离相近、特征相似的原则。
4.2 可视化视图
基于以上需求,本文设计虚缺陷划分系统,整体界面如图4所示。

Figure 4 Overview of the visualization system图4 可视化系统概览
4.2.1 混淆矩阵视图
混淆矩阵刻画当前分类网络的分类能力,每一列代表了预测分类,每一行代表正确类别。
混淆矩阵视图包含2个部分(如图5所示):左侧虚线框部分刻画被预测为真实缺陷类别数据的情况;右侧表示被预测为虚缺陷类别的数据分布情况。在左侧部分,左下到右上对角线上的方格(下文简称对角方格)表示正确分类的数据情况,非对角线上的方格(下文简称非对角方格)表示错误分类的数据情况。所有方格中,用灰度的深浅表示落入其中的样本多少,同时标注了样本数量。
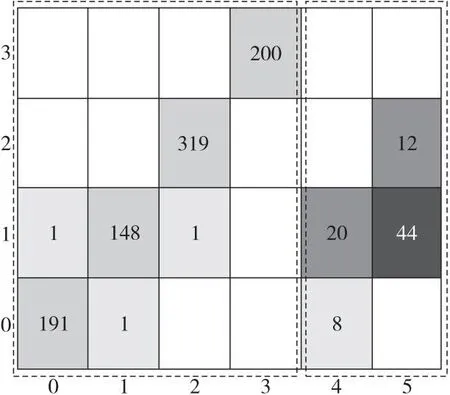
Figure 5 Confusion matrix图5 混淆矩阵
在混淆矩阵中,非对角方格表示有易混淆缺陷且没分离出来,需要进一步迭代;右侧方格表示被预测为虚缺陷的样本情况。如果非对角方格中的数较小,则可认为当前深度学习分类算法有较高的准确度,能达到实际场景需求;反之,则需要进一步划分虚缺陷类别标签,继续训练深度学习分类模型。
4.2.2 降维投影视图
为了便于探索易混淆缺陷样本,需要结合其他样本进行分析。本文采用TSNE降维技术将高维图像数据投影为二维平面的散点。TSNE是一种嵌入模型,能够将高维空间中的数据映射到低维空间,并保留数据集的局部特性,使得高维空间的数据分布特征可以在低维空间中呈现出来。
为了使系统更加高效地批量处理易混淆缺陷,本文采用如图6所示的基于密度的采样以DBS(Density-Based Sampling)构建层次结构,即在稀疏区域密集采样,在密集区域轻微采样。该采样方式在保持数据分布特征不变的情况下可以检索到更多的易混淆数据。之后,采取2D网格布局对投影采样后的数据进行进一步处理。每个网格含有多个数据,并且处于一个网格内的数据在位置关系上是最相近的,因此数据特征也最相近的。基于密度的采样与网格布局相结合的方法有助于用户批量选择易混淆缺陷,提高处理效率。
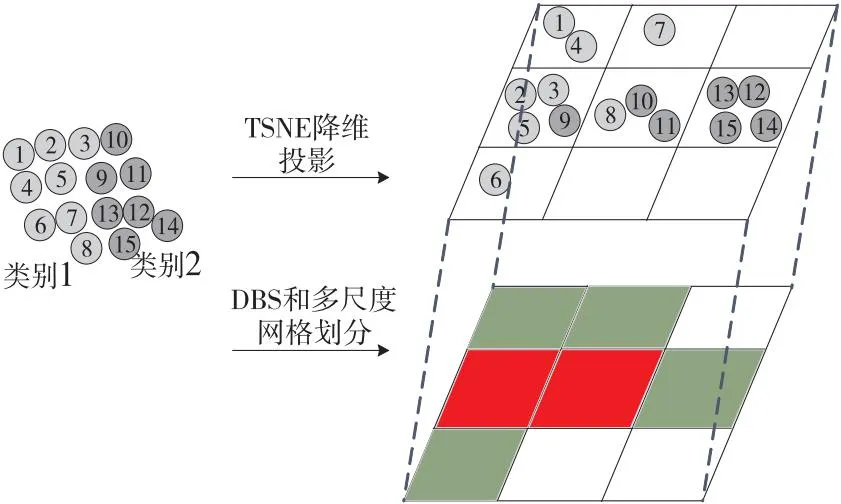
Figure 6 Dimensionality reduction projection、 DBS &multi-scale meshing图6 降维投影、DBS和多尺度网格划分
其中网格布局采用多尺度划分,用户通过动态调整网格尺度来控制网格的布局。用户通过详细视图观察,根据网格内数据的相似程度,来放大或者缩小网格尺度。选择适宜的网格大小,从而使得邻近的含有错误分类数据点的能够彼此相连,形成区域。
单个网格中可能包含零个、一个或多个数据,本文按下列原则对其进行颜色编码:
(1)绿色:网格内数据全部正确分类;
(2)红色:网格内含有错误分类的数据;
(3)黄色:网格内数据已经被划分为虚缺陷。
通过调整网格尺度交互地确定网格大小。当网格呈现为红色时,表示该网格内含有错误分类的点,网格内的数据包括错误分类数据以及距离相近的数据,其一起作为虚缺陷数据。对于指定类别之间的红色网格全部转换成黄色网格,即将该网格内数据类别标签修改成虚缺陷,达到将批量易混淆缺陷划分为虚缺陷的目的。
观察网格内的颜色,如果所产生的黄色网格呈现近似连通状态,表明该区域的虚缺陷数据在特征上也是相近的,此时可以将它们合并为一个虚缺陷类别,从而减少虚缺陷种类。
4.3 交互操作
在识别易混淆数据并划分成虚缺陷的过程中,需要进行添加新标签、过滤数据等一系列自定义操作。交互操作台在整体流程中起着连接作用,其优势是能够自定义用户的操作交互,过滤出待选的虚缺陷数据,并完成整体虚缺陷划分流程。交互操作台视图提供了一组过滤器(如图7所示):
(1)选择已有虚缺陷标签:为即将划分成虚缺陷的数据选择一个类别标签。
(2)增加已有虚缺陷标签:增加一个新的虚缺陷,并赋予一个新的类别标签。
(3)网格选择尺度:用于划分网格大小,动态规划网格内的数据样本的数量,便于选择合适数量的数据样本进行虚缺陷划分处理。
(4)置信度网格划分:用于将所有数据按照置信度的不同区分开来,来探索潜在易混淆缺陷。
(5)确认与训练:对于找到的虚缺陷进行确定,并标注为新的类别标签,但也会保存原有的类别标签,便于后期进行迭代回溯。
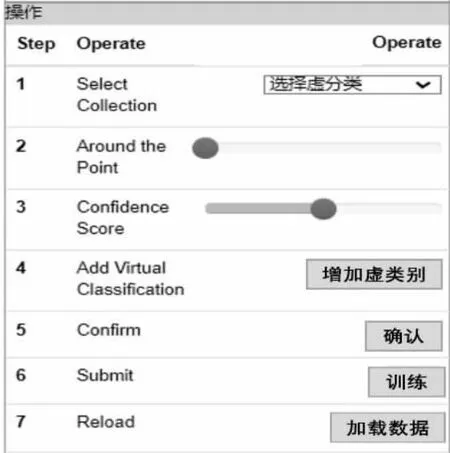
Figure 7 View of interactive console图7 交互操作台视图
虚缺陷划分系统通过如图8所示标准化交互流程,完成易混淆数据到虚缺陷的划分过程,具体步骤如下所示:
步骤1通过混淆矩阵找到感兴趣的类别中错误分类的数据点并在投影视图中进行展示。
步骤2通过交互操作台调整网格尺度,然后在投影图中选择红色网格内的数据作为虚缺陷的候选数据。
步骤3将候选数据点图像与展示错误分类区域内的数据图像进行对比,专家用户通过置信度和人为主观判断复查一遍,最终确定虚缺陷数据。
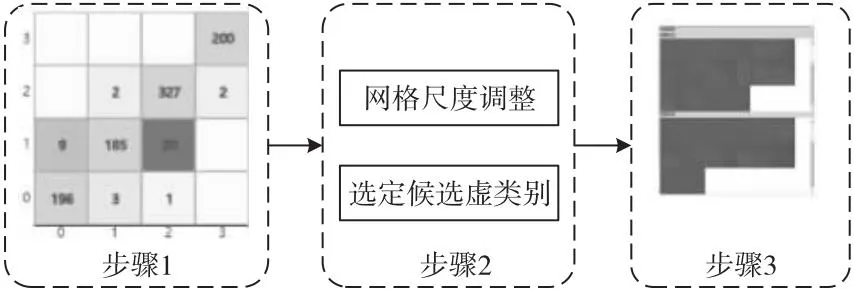
Figure 8 Interactive process图8 交互流程
5 实验与结果分析
本文使用生产实践中的常用方法——固定算法进行实验比较,以验证本文方法的有效性。
所有实验均在配备Intel®CoreTMi7-10700K CPU(3.80 GHz)和32 GB内存的台式计算机上进行。
5.1 缺陷数据集
5.1.1 数据集介绍
本文与领域专家合作,在产品表面缺陷分类任务中有效识别易混淆缺陷。训练数据集包含4个类别(如图9所示):脏污、残胶、划痕和崩边,分别包括200,214,331和200幅图像,所有数据均来自实际项目。
Figure 9 Four categories: Dirt,glue, scratches and edge breaking(from left to right)图9 4个类别:脏污、残胶、划痕和崩边(从左到右)
5.1.2 专家分析流程
将初始数据加载到虚缺陷划分系统后,领域专家通过观察混淆矩阵,根据混淆矩阵的颜色深浅以及矩阵上显示的数字,选择指定类别来消除易混淆数据对分类的影响。为了进行下一步分析,首先通过调整交互操作平台的网格尺度,来找到合适的网格大小,保证红色网格内有足够多的数据且同一框内的数据相似度接近,如图10所示。领域专家发现指定类别对应的错误分类数据集中在区域A中,如图11所示。划分好网格尺度后,领域专家发现区域A的红色数据位置相近且呈现连通状态。故本文合并虚缺陷标签为一个标签。然后领域专家对红色框内的数据通过详细视图进行最后一步对比确认,将错误分类的数据作为参照,修改标签为虚缺陷同时修改网格颜色为黄色。然后,领域专家继续处理区域B和区域C的数据,通过观察发现,红色网格位置较远,且区域B和区域C的数据是来自不同类别的错误分类数据。故本文将这2个区域的数据分别作为1个虚缺陷进行处理,操作步骤同上。
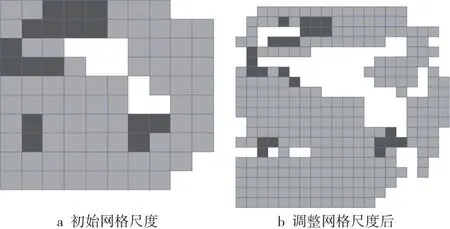
Figure 10 Adjusting grid scale图10 调整网格尺度
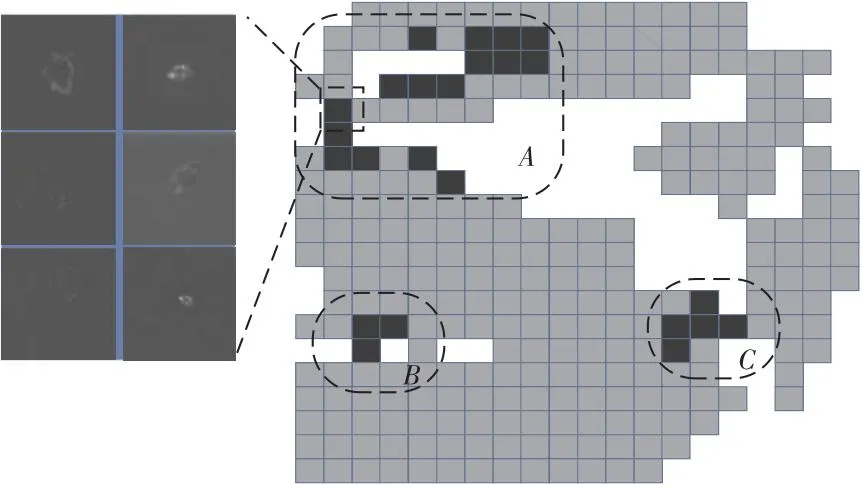
Figure 11 Data under dimension reduction projection图11 降维投影下的数据
基于新的训练集训练得到新的分类模型,该模型对数据的预测精度有一定的提升,如图12中的混淆矩阵非对角线数据的错误分类大幅度减少。这表明,原始类别的错误分类数量减少了,易混淆数据很大程度被隔离开来,验证了本文方法的可用性。
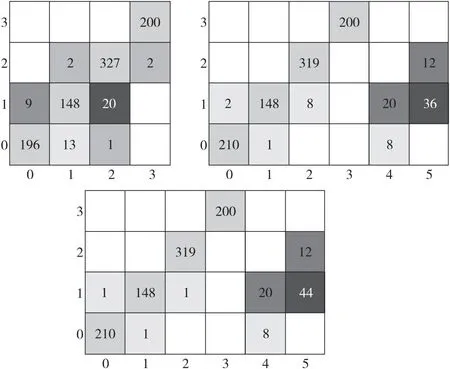
Figure 12 Iterative results display图12 迭代结果展示
5.2 虚缺陷分离方法与固定算法对比
目前,工业界普遍采用固定算法对易混淆缺陷进行处理。该方法通过将不同类别的错误分类数据作为易混淆缺陷,将其直接划分为虚缺陷,从而重新训练深度学习模型,实现从训练集中分离出易混淆缺陷的目标。本节将虚缺陷划分方法与固定算法进行对比实验。特别关注本文方法是否能够识别出更多的易混淆数据,以及是否能够通过合并标签达到减少虚缺陷种类的目的。为此,本文设计了以下评估指标:
(1)迭代次数:迭代的次数越少,表明所耗费的时间、人力、物力就越少。
(2)虚缺陷种类:新增加的类别标签个数。
(3)虚缺陷比例:识别出的易混淆数据转换成虚缺陷的总数占数据集的比例。
(4)识别精度:指被识别为真实类别的数据样本中有多少是识别准确的。
(5)平均精度:各个类别精度的平均值。
本文方法与固定算法的结果如表1所示。其中,初始分类为直接采用原始数据集训练得到的分类结果,本文结果经过了如图12所示的2轮迭代。
由表1可知,在初始分类结果当中,平均精度不高,存在类别之间错误分类的情况;划分虚缺陷后,分类精度得到大幅度提升,相比于初始类别和固定算法,精度分别提升了4.6%和1.9%。另外,虚缺陷划分方法相比于固定算法能够以更少的迭代次数识别出更多的易混淆缺陷,使用的虚缺陷种类更少。

Table 1 Performance comparison of fixed algorithm and virtual defect division method表1 固定算法和虚缺陷划分方法性能对比
数据集中的不同类别的缺陷识别精度提升效果如表2所示。由表 2可知,本文方法使脏污和残胶的错误分类大大减少,分类识别精度相比于初始分类的分别提升了13.1%和7.4%。这表明虚缺陷划分方法对提升指定类别的识别精度效果显著,大幅度减少了人工复检工作量,表明了本文方法的有效性。
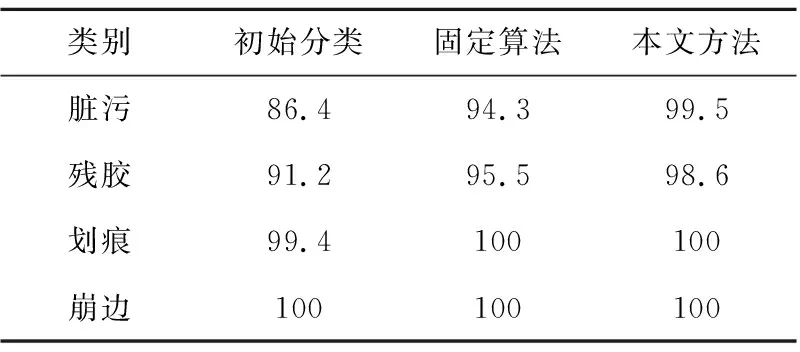
Table 2 Comparison of recognition precision for single category表2 单个类别识别精度对比 %
6 结束语
产品表面缺陷分类是深度学习在工业缺陷检测中的常见应用,但极少量的易混淆缺陷却影响了深度学习算法在缺陷分类任务中的可用性。本文通过分离易混淆缺陷的方法来降低其影响,并设计了一套分离虚缺陷的可视化解决方法,最后基于实际工业数据验证了本文方法的有效性。
但是,本文方法依然有较大的改进空间,如本文方法依赖混淆矩阵,如果缺陷类别较多,混淆矩阵会因过于庞大而难以处理。如何提高本文方法的可扩展性,以处理包含更多缺陷类别和更大规模的训练数据是后续需要进一步研究的问题。
猜你喜欢
小天使·一年级语数英综合(2022年2期)2022-03-30
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
公民与法治(2016年10期)2016-05-17
新校长(2016年8期)2016-01-10
计算机工程(2015年8期)2015-07-03
人生十六七(2015年29期)2015-02-28
商事法论集(2014年1期)2014-06-27
中国中医药现代远程教育(2014年16期)2014-03-01
短篇小说(2014年11期)2014-02-27
