
基于ALBERT-Seq2Seq-Attention模型的数字化档案多标签分类
2024-03-14 07:38王少阳成新民王瑞琴陈静雯费志高
湖州师范学院学报 2024年2期
王少阳,成新民,王瑞琴,陈静雯,周 阳,费志高
(湖州师范学院 信息工程学院,浙江 湖州 313000)
0 引 言
随着大数据时代和数字化社会的到来,档案数字化工作被提上日程.但随着社会数据、档案数量呈井喷式增长,人们难以从海量如山、五花八门的各级各类档案中快速获取目标档案,而且在对不计其数的档案进行手工分类等工作时,需要投入大量的人力物力,耗时较长.如何让档案管理人员对海量的数字化档案信息进行准确的分类,并快速找到需要的档案,是目前学界和业界比较关注的话题,也是档案管理领域面临的一项重大挑战.
针对传统的多标签分类没有考虑到多标签间的关联问题,本文提出一种新型的ALBERT-Seq2Seq-Attention模型方法,用于档案多标签分类,挖掘多标签之间的关联性.与传统的多标签文本分类输入的不同之处在于:本模型没有采用将标签转为由0和1组成的one-hot向量,而是采用类似字典的形式,通过标签的指针找到不同标签所对应的id,使其组合在一起,并将多标签当作一个序列整体输出,突出标签之间的关联性.ALBERT-Seq2Seq-Attention模型使用ALBERT预训练语言学习模型作为提取文本特征的工具,考虑文本上下文语义信息,采用Seq2Seq-Attention完成多标签的抽取,并进行分类.
1 ALBERT预训练语言模型
ALBERT轻量化网络模型的提出,是解决基于Transformer双向编码器表示的BERT[1](bidirectional encoder representations from transformers,BERT)预训练语言模型参数量巨大和训练时间过长的问题.ALBERT模型在实现参数数量减少为BERT的1/18的同时,还能使训练速度提高17倍,从而增加模型效果.ALBERT在BERT的基础上进行了以下改进:对Embedding进行因式分解操作,将词嵌入层输入的one-hot向量映射到低维空间进行降维,再经过一个高维度矩阵映射到隐藏层;采用跨层参数共享的方法降低内存占用率,并解决因网络深度增加而导致参数数量增加的问题;以改用语序预测(Sentenc Order Prediction,SOP)代替后文预测(Next Sentence Predict,NSP)作为训练任务,从而更有力地学习句子间的连贯性.
ALBERT小型中文预训练语言模型是通过大量中文语料库训练得到的.该模型训练超过125 000步,使用超过30 GB的中文语料库Albert_small_zh进行训练.中文语料库涵盖新闻、百科、互动社区等多种语境,学习文本内容累计超过100亿汉字[2].ABERT的词嵌入层是获得档案文本向量化序列特征表示的重要环节,词嵌入将档案文本映射为字向量,可以有效提取文本中的序列信息、位置信息和上下文语义关联.文本通过ALBRT的词嵌入层、编码层的词向量特征表示,将词汇的语义信息与上下文语义特征结合,从而在句子层面生成更加丰富和准确的语义特征向量.ALBERT模型框架见图1.

图1 ALBERT模型框架图
图1中,Ei为文本序列经过词嵌入后得到的向量表示;Ti为文本序列经过Transformer编码器处理后从文本序列中提取出来的具有丰富语义信息的特征向量,Trm为T模型内置的多层双向Transformer模块.ansformer模块结构见图2.
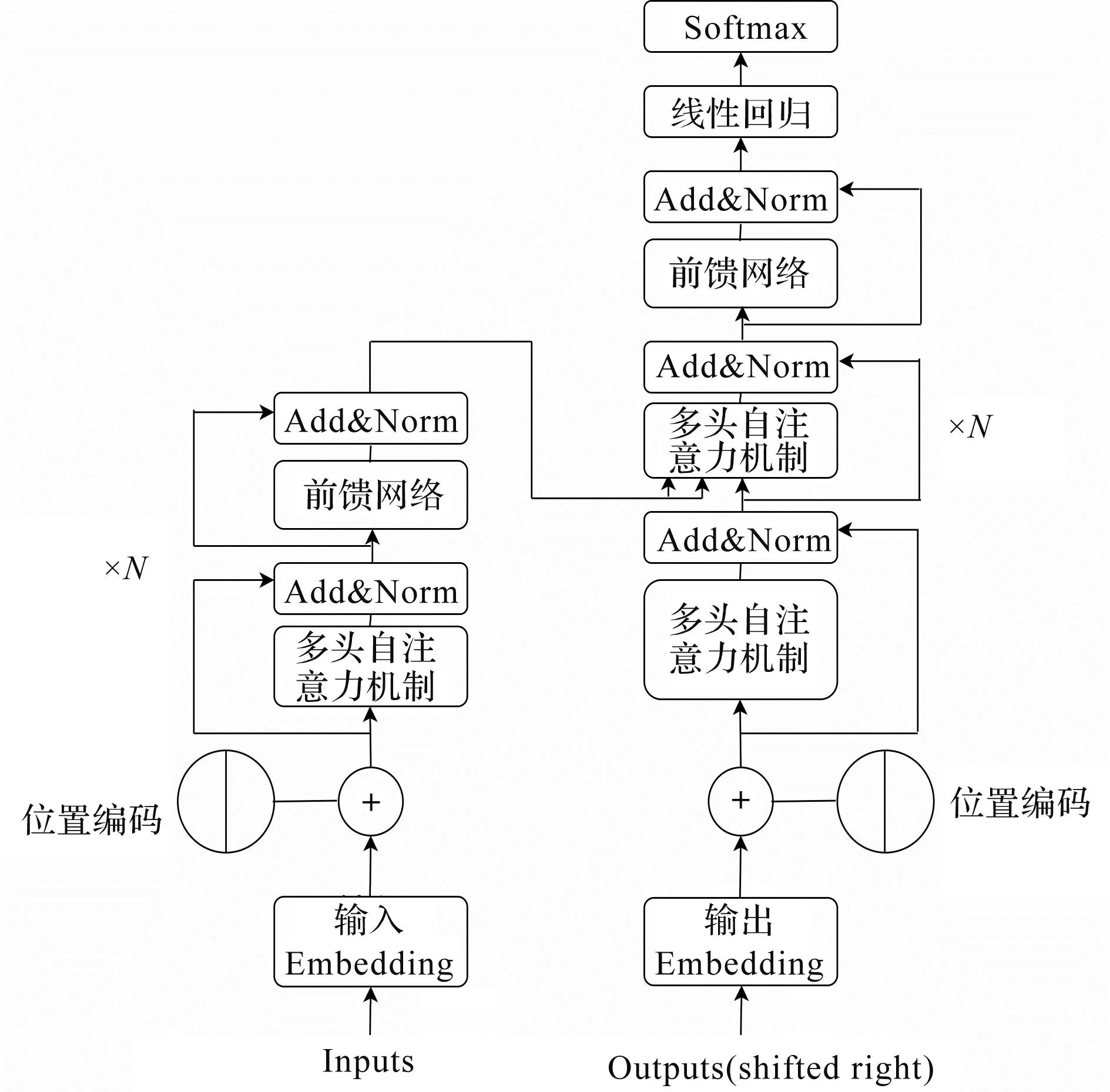
图2 Transformer模块结构图
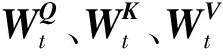
(1)
(2)
式(3)是将多头自注意力机制输出的词向量合并为矩阵,以作为前馈网络层的输入.
MultiHead(Q,K,V)=Concat(head1,head2,…,headh)Wo,
(3)
其中,Wo是附加权重矩阵,其作用是将拼接后的矩阵压缩成与序列长度相同的维度[5];dt为每个Q、K、V词向量的维度大小.通过使用多头注意力机制,ALBERT模型能够计算句子中每个字词与目标语句中所有字词间的相互关系.这种计算可以在句子层面进行,从而更全面地捕捉句子中各个部分间的关联关系,并通过这种相互关系调整每个字词在整个句子中的权重,从而获得新的向量表达,实现抽取文本序列词向量特征的目的.
2 Seq2Seq-Attention模型
Seq2Seq常用于处理序列到序列的问题,是一种编码器-解码器结构的网络[6].单独的Seq2Seq网络有一定的不足,如输入序列一旦过长,其有效信息被分配的权重便会降低,输入序列的全部信息就会被压缩到固定长度的上下文向量中,使得整个模型处理信息的能力受到限制和削弱[7].本文通过引入Attention机制,可以有效地解决序列过长导致信息压缩的问题.引入Attention机制的Seq2Seq网络模型见图3.
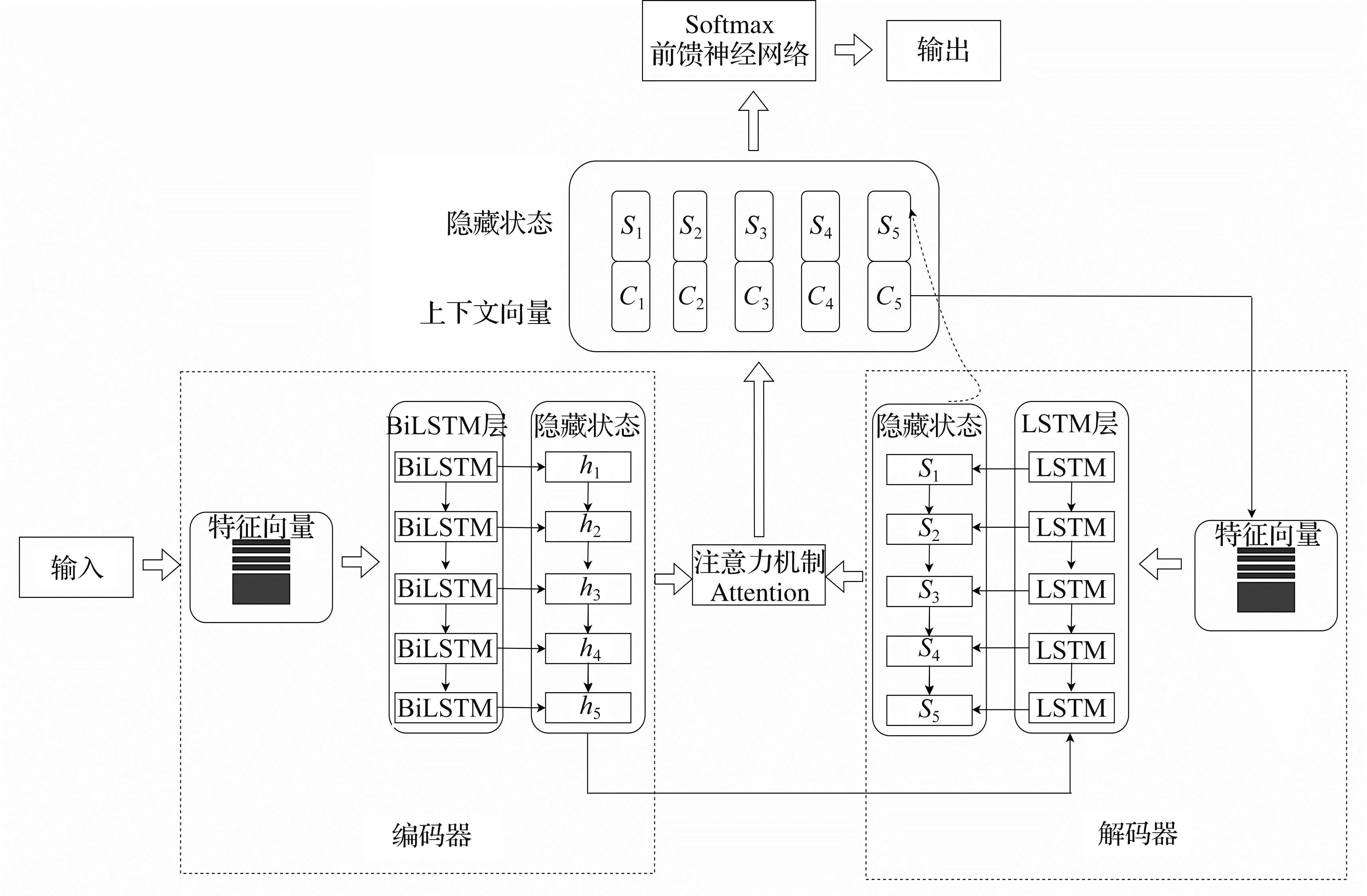
图3 Seq2Seq-Attention网络模型图
Seq2Seq-Attention模型的核心思想是通过动态生成上下文向量Ct,使Ct能够随着解码过程的动态变化,替代原有固定的上下文向量C,从而生成更加准确的序列[8],使得解码层每个时刻都拥有自己独特的上下文向量.这既避免了信息被压缩的问题,又能够使解码层在每个时间步选择自己最关注的编码层序列内容,而且使模型的解码器在解码的各个时刻有不同的侧重点,从而增强对文本特征的利用能力[9].
动态的上下文向量Ct的计算方式为:在t时刻进行解码时,解码器会计算编码器获取到的每个隐藏状态hj与当前解码时刻的相关性系数et,j.其计算公式为:
et,j=VT·tanh(Wst-1+Uhj),t,j=1,2,…,Ni,
(4)
其中,s为解码层隐藏状态,W、V和U为模型待训练参数.模型在训练过程中将对待训练参数进行不断调整.
对计算得到的相关性系数et,j进行归一化处理,得到编码器隐藏状态hj的权重系数at,j.其计算公式为:
(5)
归一化过程是将所有的相关性系数et,j除以它们的和,从而确保它们的总和为1.根据隐藏状态的权重at,j,实现对编码器隐藏状态的加权求和操作,最终得到动态上下文向量Ct.其计算公式为:
(6)
3 ALBERT-Seq2Seq-Attention模型的档案多标签分类
ALBERT-Seq2Seq-Attention模型应用于档案多标签分类的训练过程,包括两个主要步骤:第一步,通过使用ALBERT模型的多层双向Transformer编码器训练档案文本,提取语义特征;第二步,基于Seq2Seq-Attention模型,该模型主要由编码器和译码器组成.其中,编码器部分由多层BiLSTM构成;解码器部分由多层LSTM的局部注意力机制组成,并使用局部注意力机制突出临近标签间的相互影响力.ALBERT-Seq2Seq-Attention网络模型见图4.
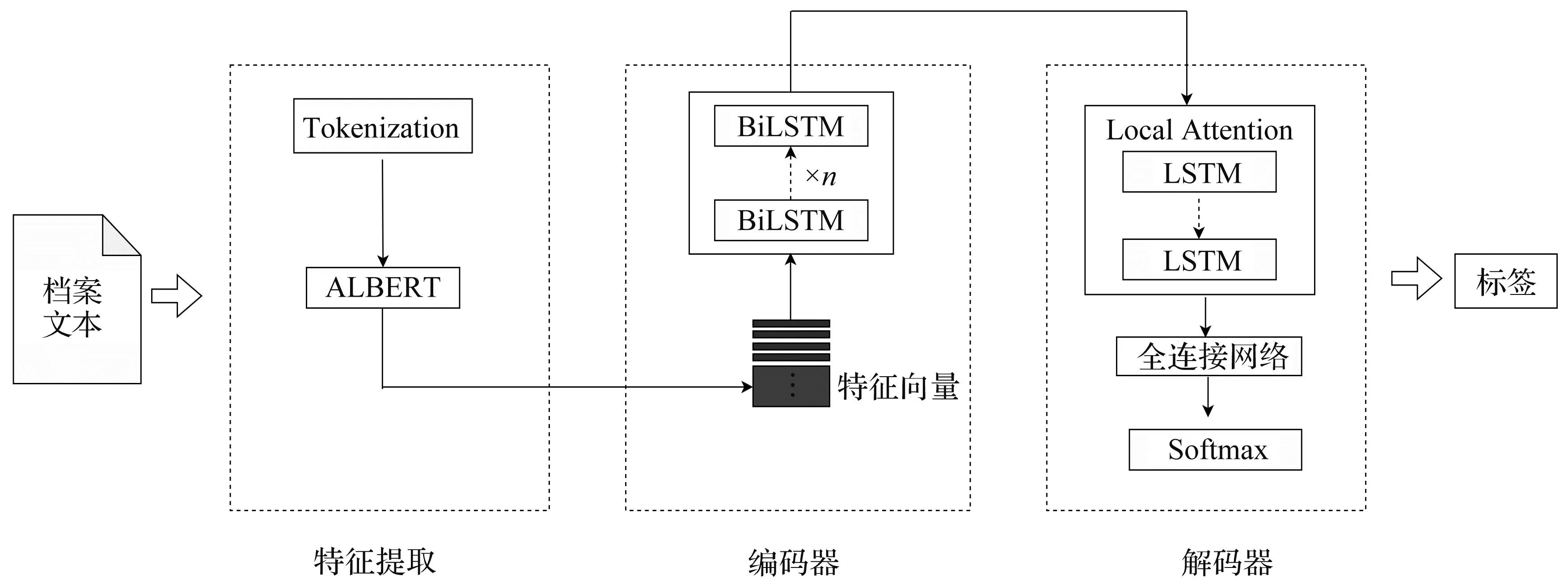
图4 ALBERT-Seq2Seq-Attention网络模型图
为有效解决传统分类算法对档案文本语义抽取不完整、分类精度低、分类结果标签单一和标签间缺乏相关性的问题,本文提出一种新型的基于ALBERT-Seq2Seq-Attention深层神经网络学习结构的多标签档案文本分类模型.模型的算法流程为:
步骤1:将数字化档案文本转换为向量,其表示为:
X=[x1,x2,…,xn],
(7)
其中,每个向量的元素xi对应数字化档案文本中的1个字符.
步骤2:将档案向量用X表示,并将其输入到ALBERT的词嵌入层进行序列化操作,从而得到序列化后的档案文本向量E.E向量用于后续的多标签分类任务.
E=[E1,E2,…,En],
(8)
其中,Ei为文本第i个字符的序列化嵌入向量.
步骤3:在多层双向Transformer编码器中进行训练,经多次的自注意力机制和前向传递,模型能够提取并学习到输入文本中的语义信息和特征,最终输出文本特征向量T.
T=[T1,T2,…,Tn],
(9)
其中,Ti为第i个字符经Transformer编码器编码后的特征向量.
步骤4:将ALBERT编码器提取的特征向量T作为Seq2Seq-Attention编码器的输入,编码端使用双向LSTM来更好地捕捉较长距离的依赖关系,从而输出时刻t的隐藏状态ht.
ht=BiLSTMenc(xt,ht-1),
(10)
其中,xt为目标文本中每个词汇特征值,ht-1为上一个时间点的隐藏状态.
步骤5:解码端使用单向LSTM,输出时刻t的隐藏状态st.
st=LSTMdec(yt,ht-1),
(11)
其中,yt为目标句子中单词的特征值,ht-1为上一个时间点的隐藏状态.
步骤6:通过编码器的隐藏状态和解码器的隐藏状态计算相关系数et,j.其计算公式见式(4).
步骤7:对编码器输出的隐藏状态进行加权平均,得到编码器各个隐藏状态hj的权重系数at,j,计算公式见式(5);利用权重系数得到动态上下文向量Ct,计算公式见式(6).
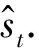
(12)
步骤9:计算最后的目标标签yt的输出概率:
(13)
结束模型训练过程,输出数字化档案文本多标签分类结果.
4 实 验
4.1 标签字典
实验采用合作档案馆提供的数字化档案制作标签字典.档案共分为3 865种类别,涵盖军事、外交、国际、政治、经济、文化、环境、人事、宗教等方面.建立一套标签字典体系,即对每个档案类别标签分配标签id,以作为一个标签库.标注过程和训练过程需要使用到的标签均从标签库中获取,标签库中每个标签平均所对应的档案数量为273篇.数字化档案文本标签字典的部分内容见表1.

表1 标签字典部分内容
4.2 数据格式
content = '必须树立和践行绿水青山就是金山银山的理念,坚持节约资源和保护环境的基本国策,像对待生命一样对待生态环境'.
label = '领导人讲话/方针政策/生态文明'.
与传统多标签文本分类输入传统的one-hot向量不同,其采用类似字典的形式,通过标签的指针找到每一个标签对应的id.其中,在字典中可以找到领导人讲话、方针政策、生态文明,其id分别为11、26、87.one-hot向量为:
label(one-hot):11 26 87,
即以组合在一起的[17 26 87]作为整体输出结果,其可以被理解为一个句子,只不过它的颗粒度是一个标签,而不是我们平时理解的字或词,以这样的方式来表现标签之间的相关性.
4.3 评价标准
采用Micro-precision、Micro-recall、Micro-F1和汉明损失(Hamming Loss)作为评价指标,其中将Micro-F1作为主要的评价指标.各指标的计算公式为:

(14)

(15)
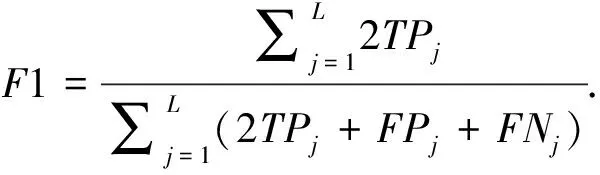
(16)
其中,L为类别标签数量,TP为正样本被预测为正的数量,FP为正样本被预测为负的数量,FN为负样本被预测为正的数量.
Hamming Loss是指被错分的标签的比例大小,也就是两个标签集合的差别占比[10].汉明损失数值越低,表明模型的效果越好.其计算公式为:
(17)
其中,N为档案个数,q为每篇档案的标签数,Z、Y分别为一篇档案的预测标签和真实标签的集合,Δ为二者集合的对称差.
4.4 对比实验
采用ALBERT、ALBERT-TextCNN两个模型进行对比实验,以验证本文所提出的ALBERT-Seq2Seq-Attention网络模型相对传统多标签分类方法的有效性.
(1)ALBERT:采用ALBERT预训练语言模型提取词特征向量,改变交叉熵的计算方式,使下游任务使用全连接层实现多标签分类.
(2)ALBERT-TextCNN:采用ALBERT预训练语言模型提取词特征向量,利用有监督学习的方法,将抽取到的特征向量输入到TextCNN模型中进行训练.
4.5 实验结果与分析
按照3∶1∶1的比例将档案文本随机划分为训练集、验证集和测试集.为避免实验中偶然因素对实验结果产生的干扰,实验均运行10次后对结果求均值,得到对比实验各个模型的精确率、召回率、调和平均值和汉明损失.结果见表2.

表2 对比实验结果表
由表2结果可知,本文提出的基于ALBERT-Seq2Seq-Attention模型的档案多标签分类方法与其他所有模型方法相比,其精确率、召回率和F1值有更好的表现,三项指标都超过90%;与模型ALBERT-TxtCNN相比,其在F1值指标上提高约4个百分点,相对其他两个模型,汉明损失降低了一个数量级,并在多标签分类上表现出更加优越的性能.
由图5和图6可知,在数字化档案多标签分类表现中,ALBERT-Seq2Seq-Attention模型与其他两个模型对比,训练精度曲线在10k steps附近达到稳定,且曲线波动幅度较小.ALBERT-Seq2Seq-Attention模型训练损失曲线下潜速度更快,模型稳步收敛,深度更深,损失更小.

图5 模型训练精度曲线对比
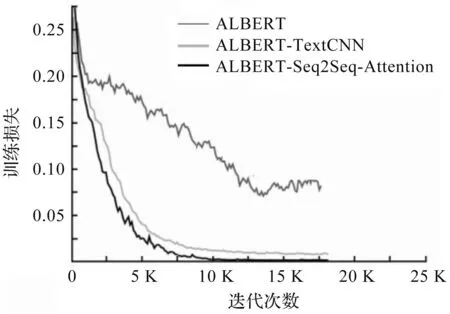
图6 模型训练损失曲线对比
另一组实验采用Seq2Seq、ALBERT-TextRNN两个模型进行对比实验,以验证本文所提出的ALBERT-Seq2Seq-Attention网络模型相比其他采用序列建模在多标签分类上的有效性.除使用合作档案提供的文本数据外,本实验还通过搜集并下载公开的多标签文本分类数据集来补充实验,以验证ALBERT-Seq2Seq-Attention方法在较大数据集上的有效性和其他应用领域上的通用性.以下是补充实验数据集的详情.数据集Blurb Genre Collection(BGC)[11]是作者收集的,由书籍介绍和写作题材组成,有91 892篇文本,共146个类别.中文新闻数据集[12]是作者收集得到的,其来自电视台的真实新闻稿件,该数据集有932 354篇文本,共683个类别.
每轮实验均按照3∶1∶1的比例,将档案文本随机划分为训练集、验证集和测试集.为避免实验中偶然因素对实验结果的干扰,在实验运行10次后对结果求均值,得到对比实验各个模型的精确率、召回率、调和平均值和汉明损失.
使用档案文本作为数据集进行对比实验,结果见表3.

表3 对比实验结果
使用BGC数据集进行对比实验,结果见表4.

表4 对比实验结果
使用中文新闻数据集进行对比实验,结果见表5.

表5 对比实验结果
将ALBERT-Seq2Seq-Attention模型与现有序列建模方法,在3种不同的数据集上进行实验对比和分析,结果表明,ALBERT-Seq2Seq-Attention模型通过利用多个深度学习模型优化了分类效果,其精确率、召回率和F1值均有更好的表现;ALBERT-Seq2Seq-Attention方法在其他应用领域也具有很好的通用性.在训练时间指标上,在相同的数据集、参数集、硬件环境和软件环境中,ALBERT-Seq2Seq-Attention训练完毕的平均每轮epoch时间是ALBERT-TextCNN模型的1.21倍,是ALBERT-TextRNN模型的1.27倍.
在对比实验中,本文还计算了各个模型的推理时间.推理时间即在一次数据结果验证中测试模型所运行的时间.实验中各模型均处于相同的硬件环境和软件环境,在等待当前设备中GPU异步执行和GPU预热两个步骤完成后,分别记录验证前时间戳T1和验证后时间戳T2,计算T2与T1间的时间差作为推理时间.在推理时间指标中,ALBERT模型、Seq2Seq模型与ALBERT-TextRNN模型的推理时间接近,ALBERT-TextCNN模型与ALBERT-Seq2Seq-Attention模型的推理时间接近,且比ALBERT-TextRNN模型的推理时间快1.5倍.
5 结 语
ALBERT-Seq2Seq-Attention模型采用ALBERT预训练语言模型,可以有效地提升词向量的语义表达能力,且使用 Seq2Seq-Attention神经网络可以构造多标签分类器,也可以通过构建标签字典策略来表现标签之间的相关性.该模型在数字化档案多标签分类任务中表现优异,各项评估指标均有出色的表现,在数字化档案应用上具有很大的发展前景和研究意义,符合当今我国数字化社会的变革要求和自然语言处理的发展潮流.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
车迷(2018年11期)2018-08-30
成都信息工程大学学报(2018年3期)2018-08-29
海峡姐妹(2018年3期)2018-05-09
电子设计工程(2017年20期)2017-02-10
公民与法治(2016年10期)2016-05-17
高中生学习·高三版(2016年9期)2016-05-14
电子器件(2015年5期)2015-12-29
新高考·高二数学(2015年11期)2015-12-23
