
基于Stacking集成学习的肺癌患者存活性预测模型研究
2024-03-14 07:38纪江明
湖州师范学院学报 2024年2期
纪江明,赵 玲
(1.湖州师范学院 经济管理学院,浙江 湖州 313000; 2.湖州师范学院 信息工程学院,浙江 湖州 313000)
0 引 言
肺癌是恶性肿瘤中对人们生命造成最大威胁的一种疾病[1].2022年,中国癌症统计数据表明,肺癌发病率非常高.根据最新癌症死亡率调查报告显示,在前十大癌症死亡率排行榜中,无论男性还是女性,肺癌患者的死亡率都高居榜首.因此,医务人员每天都会面临同样的临床问题:患者发病后的最终结局是存活还是死亡,即肺癌患者存活性预测.存活是指未来一段时间内的生活状态是活着.肺癌患者存活性预测非常重要,它可以辅助医生做出更准确的医疗决策[2-3].
当今机器学习算法发展十分迅速[4],很多算法都被运用到智慧医疗中,如随机森林[5-6]、人工神经网络[7-8]、支持向量机[9-10]、逻辑回归[11]等.众多学者的研究成果影响力很大.例如:王月等通过研究改进最大最小爬山算法来提高肺癌患者存活性模型的准确率[12];王宇燕等使用智能优化算法对随机森林进行改进,从而构建出一种新的GA-RF模型,对直肠癌患者存活性进行预测[12];Tapak等采用8种性能不同的机器学习算法进行乳腺癌患者存活性的预测[14],实验结果表明支持向量机得到的效果是最优的;Delen等利用决策树、逻辑回归、神经网络和支持向量机对结直肠癌患者存活性进行预测,实验结果验证了支持向量机得到的结果性能最佳,与Tapak等所得出的结论一致[15].
这些算法也被运用到癌症患者的存活性预测研究中,且多数是使用单独的模型进行训练的,如文献[14][15]分别将数据集输入到单独的模型训练后进行结果测试.单一模型大多表现出运行时间稍长、泛化性能较差等缺点.而Stacking集成学习方法可以融合多个模型来弥补单一模型带来的缺陷.本研究以XGBoost、SVM和LR为基学习器,以朴素贝叶斯为元学习器,通过Stacking[16]集成学习方法来构建一个新的模型.
1 相关理论与技术
1.1 XGBoost模型
XGBoost[19]是一个优化的分布式梯度增强库,可以达到高效、灵活的目的.该模型所采用的树模型是CART回归树模型,其主要思想是:不停地增加新的树,每经历一次特征的分裂,就会增加一棵新的树,且每一棵新的树都会用到一个新函数,将之前预测的残差值拟合在一起,在训练结束后,就会得到K棵树.想要得到预测样本所对应的分数,就要按照该样本的特征,寻找到与其相对应的叶子节点,而每个叶子节点都有一个分数值,最终的预测值就是把每棵树所对应的分数进行求和.XGBoost整体流程见图1.
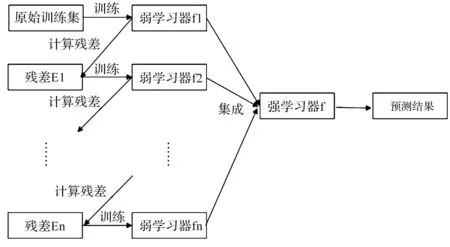
图1 XGBoost流程
1.2 逻辑回归模型
逻辑回归(LR)[11]是一种广义线性回归模型,该模型简单易理解,具有不需要进行大量输入特征的缩放运算、内存资源占用极少等优势.该模型直接对分类的可能性进行建模,且运用极大似然函数推导损失函数和降维操作,对数据实行二分类操作.
1.3 支持向量机模型
支持向量机(SVM)[9-10]是广义线性分类器,其按照监督学习的方式对数据进行二元分类.该模型最主要的目的是寻找到一个最佳的决策边界,以更加准确地将样本分类.
肺癌存活性预测问题是非线性问题,其支持向量机的目标函数为:
f(x)=wT·φ(x)+b,
(1)
其中,x为输入数据,w为权向量,b为偏置向量.
再利用极大化间隔的思想,最终得到的分类决策函数为:
(2)
其中,K(xi,x)为核函数,〈φ(xi)·φ(x)〉为映射到高维特征空间两个点的内积.
1.4 朴素贝叶斯模型
朴素贝叶斯[20]分类算法是基于贝叶斯原理和特性条件的独立假定而提出的,在训练一个目标数据集时,第一步要确保其联合的概率分布是根据学习输入/输出之间的基本特征条件进行独立假设的;第二步是通过该模型输入已知的验证参数x;第三步是根据贝叶斯定理得出输出参数y,该参数y的后检验机率相对较大.朴素贝叶斯实现容易,准确率也很高.
1.5 Stacking集成学习
Stacking是组合多个异质分类器的集成学习方法[16].它不是指某一个模型,而是指一种思想,其主要作用是结合多个基学习器的优点,组建成一个更加强大的模型.一个基本的两层Stacking算法流程见图2.
图2 两层的Stacking模型
2 肺癌患者存活性预测模型构建
2.1 数据来源与预处理
本文所用到的数据集来自美国公开的数据库——SEER数据库.该数据库拥有数10年的美国各个地方癌症患者的医疗记录,其被大众认为是全世界最具影响力的癌症统计数据库[15].登录SEER的官网(http://www.seer.cancer.gov)可免费获取相应的数据.
在该数据库中,关于肺癌的数据集有149个特征,且每个特征的记录都与特定的癌症发病率息息相关.在实验前,需要对这个数据库中关于肺癌数据集的特征和数据的相关资料进行深入了解,并对此数据集进行初始预处理和数据清洗,最终在肺癌数据集中筛选出17个属性,见表1.

表1 肺癌数据集选取的属性
在机器学习建模中,数据的好坏会直接影响模型的准确率等性能,因此数据的处理显得非常重要.本实验选取SEER数据库2008—2017年的肺癌患者记录,其包含57万多条记录.该数据集存在一些值缺失现象,如有些属性为“Unknown”.一般来讲,缺失值的处理方法主要有删除法、人工填写缺失值、使用全局常量填充缺失值等方法.由于该数据集的数据量很多,为避免填充缺失值所造成的额外干扰,本实验采取最简单的删除法来解决缺失值问题.
本实验以肺癌患者5年内存活情况为研究目标,选择病人在术后存活状况Vital status recode (study cutoff used)为结果变量.这是个二分类问题,如果病人的存活时间大于等于60个月,则结果变量改为存活(视为1);如果病人的存活时间小于60个月,则结果变量改为死亡(视为0).
本实验主要预测肺癌患者的存活性,因此只考虑Sequence number-Central值为00的情况.这个属性的含义是描述患者医生可以报告的原发肿瘤的数量和顺序的编码.若某一患者在开始时就被查出恶性肿瘤,则它的值为00;若经过一段时间体内发现第二种恶性肿瘤,则它的值就会由00转为01.
由于数据量太大,所以要适当缩小数据量[15].本文缩小数据量的方法为:在正负样本数据量平衡的基础上,将正负例全部分开,并在正例中不放回随机选取500个样本,同样在负例中不放回随机选取500个样本,最终形成由1 000个样本组成的实验数据集.
肺癌患者存活性影响因素的SHAP值分析见图3.由图3可知:“Reason no cancer-directed surgery”“Regional nodes positive(1988+)”“Regional nodes examined (1988+)”“Age recode with <1 year olds”“Grade (thru 2017)”“RX Summ-Surg Prim Site (1998+)”“Histologic Type ICD-O-3”等因素对肺癌患者5年存活性的影响较大,且经手术治疗的患者的存活性越大;阳性淋巴结的数量越高,患者的死亡率越高;组织学等级越高,肺癌患者的死亡率越高.这些都与临床医生的经验大致相符.
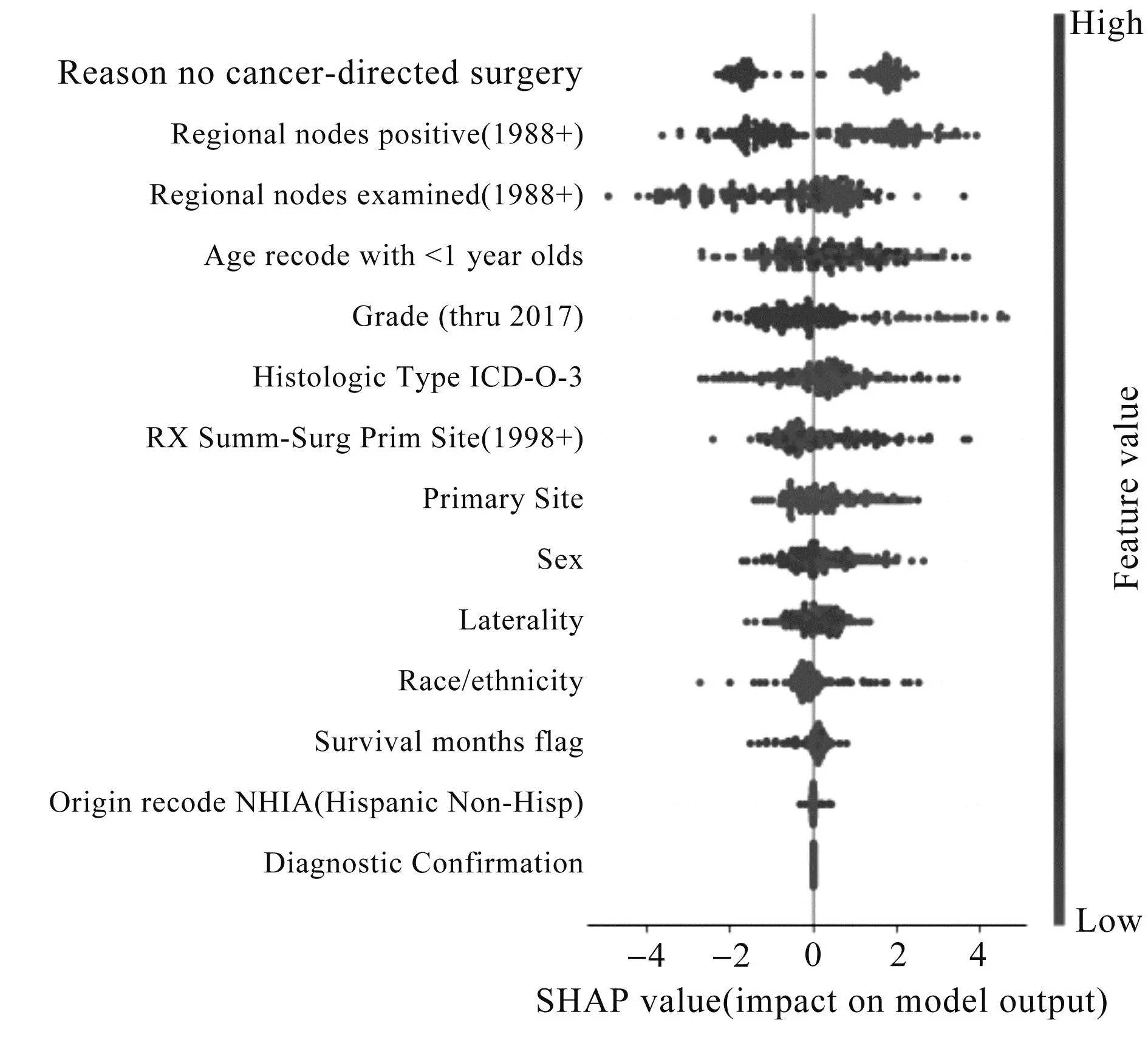
图3 肺癌患者存活性影响因素的SHAP值分布
2.2 构建肺癌患者存活性预测模型
对Stacking算法而言,要使最终的模型性能得到质的提升,学习器的选择非常重要.选择合适的基学习器和元学习器能最大程度地发挥取长补短的效果.
基学习器的选择一般要注意以下几点:①每个学习器的预测效果性能要接近,且要相对优秀;②要保证选择的学习器有一定的差异性.XGBoost虽然简单易用、鲁棒性强、高效可扩展,但也有一些缺点,如不适合处理结构化的数据、算法的参数过多等.SVM具有不容易过拟合的最佳超平面.逻辑回归具有不需要缩放输入特征、占用内存少、简单易理解等优点.以上3种异质算法的差异性,保证了元学习器的改善空间,使得模型的整体预测性能得到提升.因此,选择XGBoost、SVM和逻辑回归作为基学习器,能够更好地发挥每一个基学习器的优势.
元学习器一般选择泛化能力比较好的模型或简单的模型,这样可避免过拟合的现象产生.随机森林可通过降低方差的方法来提高模型的预测能力,是泛化能力较强的模型.朴素贝叶斯模型是较为简单的模型.本文将这两个模型作为候选的元学习器.在不同组合方式下,Stacking模型的预测结果会不同.其部分实验结果见表2.本实验选择朴素贝叶斯作为元学习器来提升模型的准确率和稳定性.

表2 不同模型组合后的预测结果
本实验以XGBoost、SVM、LR为基学习器,以朴素贝叶斯为元学习器.新的预测模型见图4.

图4 肺癌患者存活性预测模型
在实验过程中,选取合适的超参数组合可提升模型的准确率等性能.本文采用Grid Search网格搜索方法[21].该方法主要的作用是:在指定范围内自动调整参数,将所有可能的取值进行排列组合,罗列出所有可能的组合结果并形成“网格”,再对模型进行训练,从而找到表现最优的一组最优超参数.其实质就是穷举法,遍历所有组合,从中选择一组最好的超参数组合.相较于人工调整参数而言,该方法更加省时、省力.
当用Grid Search网格搜索方法寻找最优超参数时,如果网格设置范围大且步长较密集,则消耗时间就会较长;如果范围太小且步长太大,则会找不到最优超参数.最根本的解决办法是在范围大且步长大的网格中寻找参数,在找到合适的参数组合后,再设置更为密集的步长寻找更优的超参数.
采用Grid Search网格搜索方法,会出现训练集效果优于测试集效果的现象.这是因为当训练集用于超参数调整时,超参数会被调整为在训练集上表现效果最优的情况.所以,为避免实验结果值忽上忽下的问题,本文运用十折交叉验证方法[22],以减少实验结果的偶然性,即先将原始的数据集划分成训练集和测试集两个部分,再将训练集分成相同数量的10份,每次选取9份数据作为训练数据进行训练,剩下的1份数据作为验证数据,整个过程重复10次,并将准确率等性能指标的平均值作为最终的模型评价指标.
3 存活性预测实验
3.1 分类性能评价方法
模型的性能好坏是需要一定的标准来衡量的.本文采用准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1分数(F1_score)、AUC(Area Under Curve)指标评估模型.以上所有指标都是根据混淆矩阵中的参数来计算的.混淆矩阵也叫“误差矩阵”,它是一个可视化工具,一般用于比较分类器训练的结果和实际值.其结构见表3.

表3 混淆矩阵
TP(True Positive):真正例,样本本身是正例,分类器分类也为正例.
TN(True Negative):真负例,样本本身是负例,分类器分类也为负例.
FP(False Positive):假正例,样本本身是负例,但分类器分类为正例.
FN(False Negative):假负例,样本本身是正例,但分类器分类为负例.
准确率:分类器分类正确的部分所占的百分比,在本实验中是测量分类器能够准确分辨肺癌患者存活性的能力.其计算公式为:Accuracy =(TP+TN)/(TP+TN+FP+FN).
精确率:用来衡量分类器区分正类占实际正例的占比.其计算公式为:Precision = (TP)/(TP+FP).
召回率:用来衡量分类器正确预测肺癌患者死亡的能力.计算公式为:Recall =(TP)/(TP+FN).
F1指标:综合衡量精确率和召回率两个指标,其计算公式为:F1=(2×Precision×Recall)/(Recall+Precision).
以上所有指标值越大,说明实验模型的性能越佳.
3.2 实验过程与结果
本次实验使用python语言,并在MacOS环境下运行,内存为16 GB.在建立模型前,先对处理后的数据集进行划分,划分的比例为8∶2,即训练集占整个数据集的80%,测试集占整个数据集的20%.本实验采用上述所描述的网格搜索方法找到每个模型的最优超参数,并采用十折交叉验证方法对其进行测验,从而得到最优超参数,见表4.

表4 各模型最优超参数
为验证该模型具有更好的存活性预测性能,本文将集成后的肺癌存活性预测模型与单一的支持向量机、XGBoost、逻辑回归和朴素贝叶斯模型进行对比分析.从准确率、精确率、召回率、F1分数、AUC指标等方面进行比较,对比的结果见表5.为更直观地表达肺癌患者存活性预测模型的性能优势,本文以图形的形式表达实验结果.图5是5种模型经过十折交叉验证后的准确率比较图;图6是精确率比较图;图7是召回率比较图;图8是F1分数比较图;图9是AUC结果比较图.
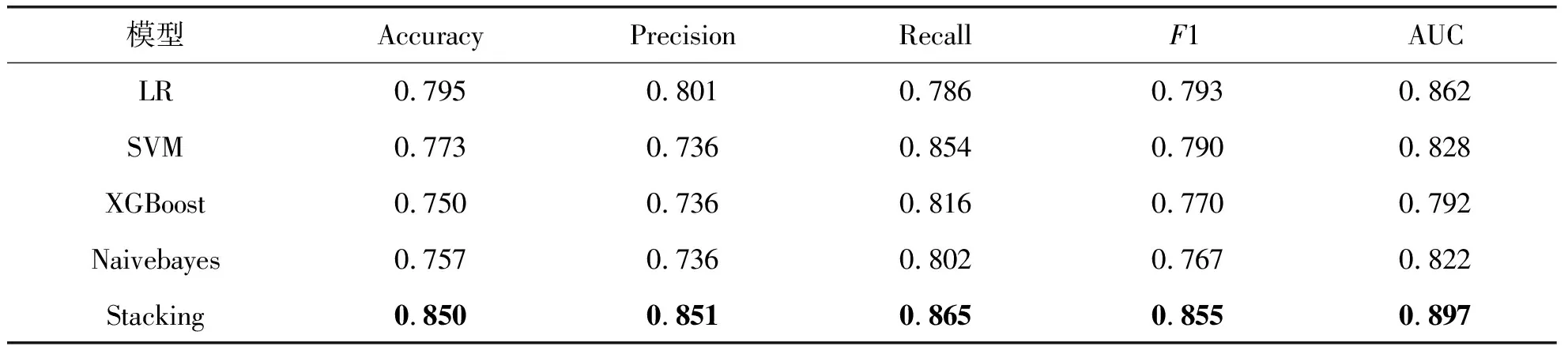
表5 各模型性能指标评估结果
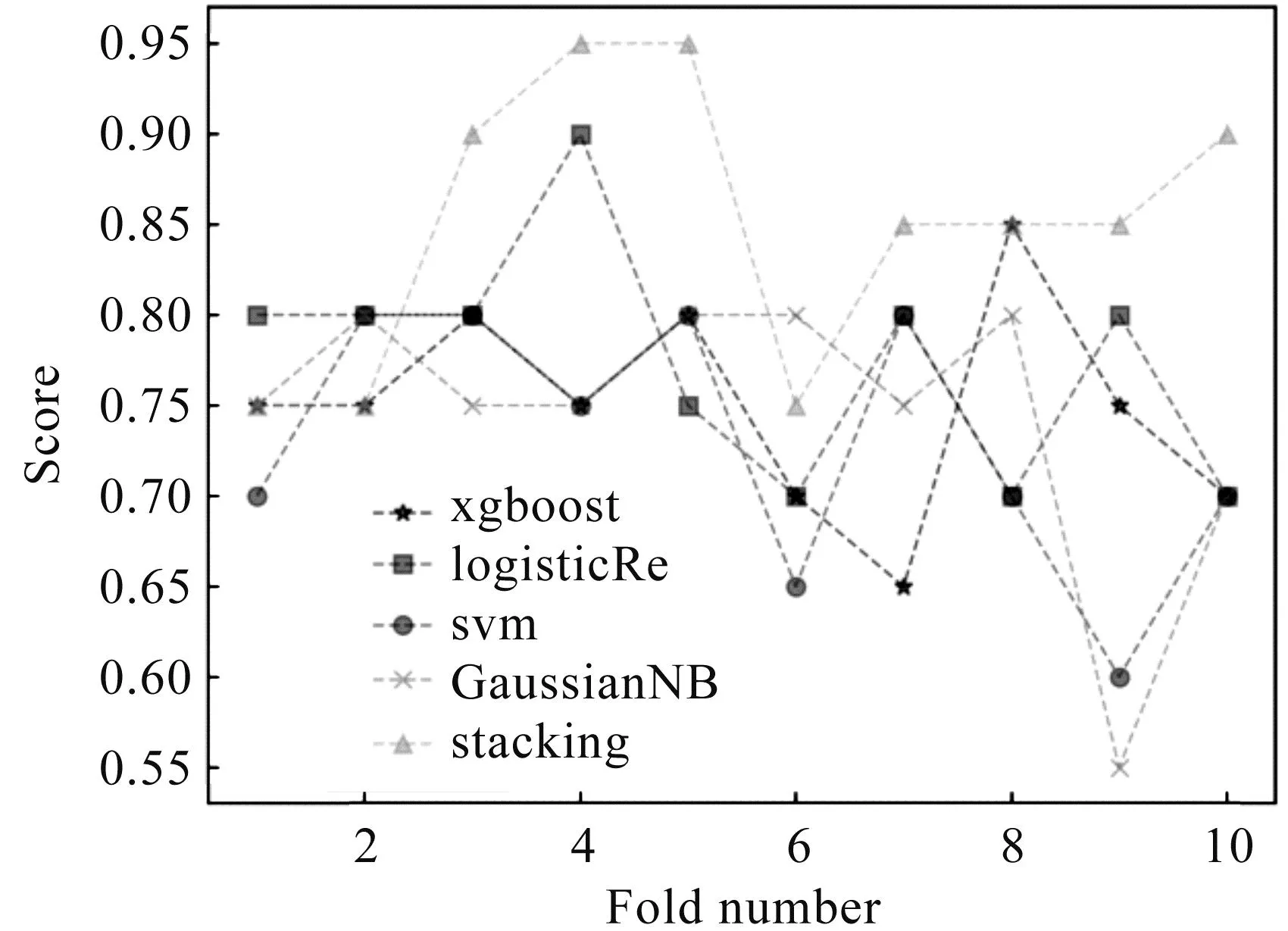
图5 经过十折交叉验证的准确率比较图

图6 经过十折交叉验证的精确率比较图
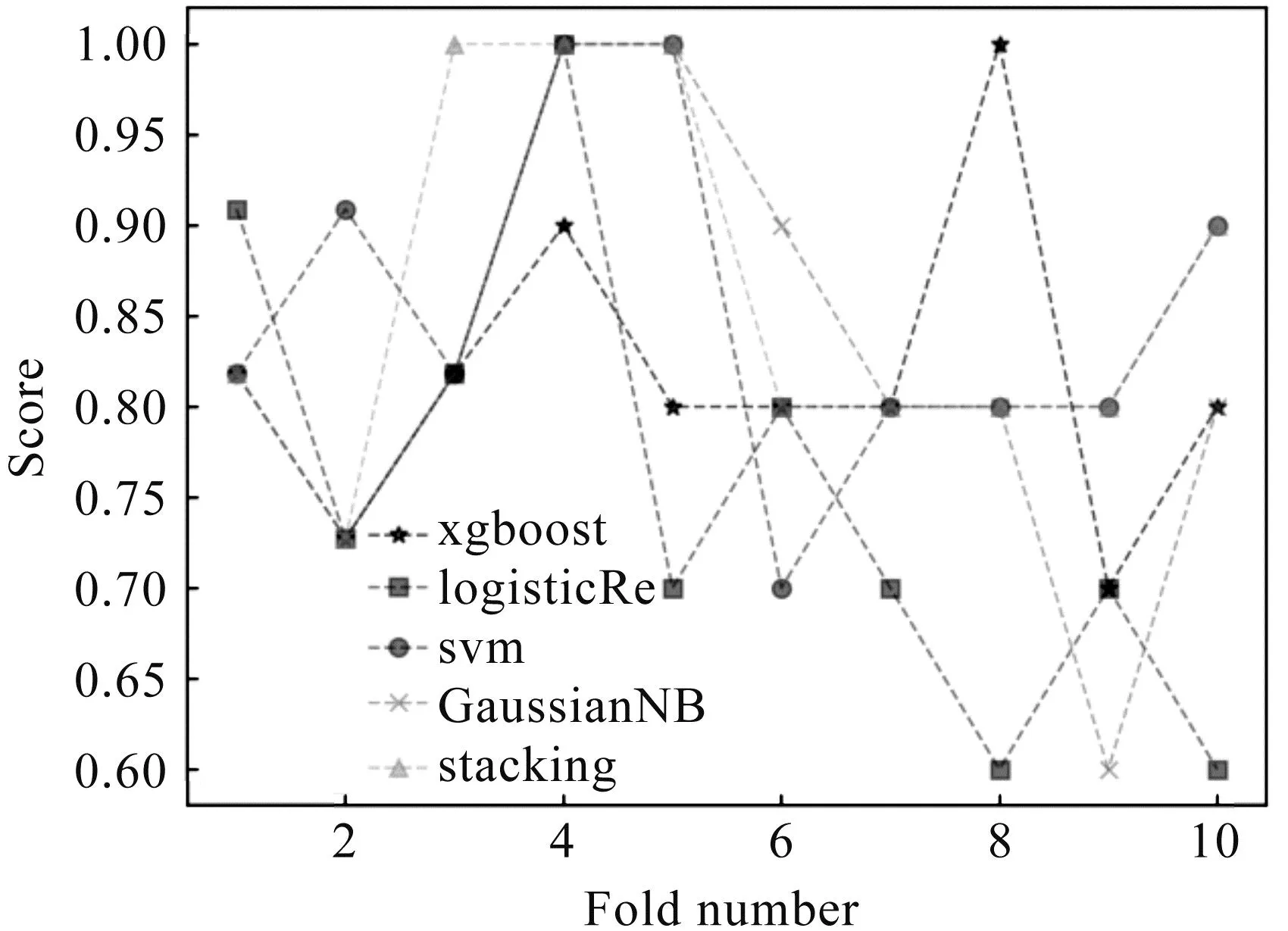
图7 经过十折交叉验证的召回率比较图
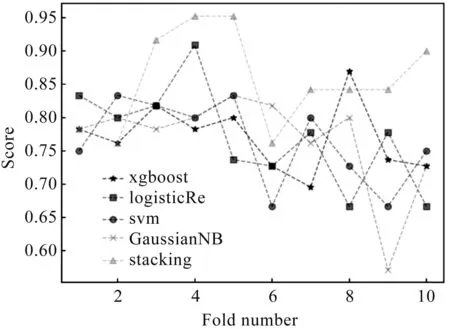
图8 经过十折交叉验证的F1分数比较图

图9 经过十折交叉验证的AUC比较图
通过表5和图5至图9可以得出,LR、SVM、XGBoost、朴素贝叶斯模型的准确率均值分别为:0.795、0.773、0.750、0.757;精确率均值分别为:0801、0.736、0.736、0.736;召回率均值分别为:0.786、0.854、0.816、0.802;F1分数均值分别为:0.793、0.790、0.770、0.767;AUC均值分别为:0.862、0.828、0.792、0.822.通过Stacking方法集成后,模型的准确率均值为0.850,比单一模型提高10%;精确率均值为0.851,比单一模型提高11%;召回率均值为0.865,比单一模型提高8%;F1分数均值为0.855,比单一模型提高9%;AUC分数均值为0.897,比单一模型提高10%.总体来说,通过Stacking集成后,模型的性能显著提升,表明集成后的模型比单一模型更适合肺癌患者的存活性预测.
4 结论与讨论
本文基于SEER数据库真实的肺癌数据,以肺癌患者5年存活状态为目标,构建基于Stacking集成学习的肺癌患者存活性预测模型.首先,对获取的数据进行分析,研究其相关特征,并对数据进行预处理,以减少异常数据对实验造成的影响;其次,根据XGBoost特征重要性得分的高低进行特征选择.本文以XGBoost、SVM和LR为基学习器,以朴素贝叶斯模型为元学习器,构建新的肺癌患者存活性预测模型,其准确率达85%.
逻辑回归采用Sigmoid函数,将线性模型的结果压缩为0~1,使其拥有概率意义.支持向量机最大的优点在于在特征空间中能寻找到使正负类间隔最大的超平面.在这两个模型的基础上,再融合XGBoost模型.由于XGBoost模型用到损失函数的二阶泰勒展开,所以与损失函数更接近,收敛速度更快;在损失函数中加入正则项,可以有效控制模型的复杂度,防止产生过拟合现象.融合后的模型相较原有的基学习器,准确率得到很大提升.
综上所述,通过集成融合方法的模型有着较强的稳定性.将该方法推广到医疗预后,可以辅助医务人员做出更准确的医疗决策,弥补经验的不足,增加癌症患者的满意度,节约医疗资源,降低医疗成本.本研究还存在一些不足:机器学习的特征选择方法有很多,而本研究采用XGBoost特征重要性得分的高低来进行特征选择,没有与其他特征选择方法进行对比.后期需要进一步选择不同的特征选择方法做进一步的对比分析.
未来的学习研究可以将肺癌患者存活性预测具体到肺癌患者存活期的预测,也可进一步研究癌症的转移和复发的可能性预测,在提高模型的普适性和实用价值的同时,更好、更精确地辅助医生做出医疗决策.
猜你喜欢
爱你(2018年24期)2018-08-16
爱你·阳光少年(2018年8期)2018-05-14
电子测试(2018年1期)2018-04-18
数理化解题研究(2017年4期)2017-05-04
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
铁道通信信号(2016年6期)2016-06-01
中国照明(2016年4期)2016-05-17
电子器件(2015年5期)2015-12-29
医学研究杂志(2015年9期)2015-07-01
