
基于人工智能嗅觉技术和化学计量学的白及饮片真伪鉴别*
2024-03-04 13:04桂新景李涵王艳丽范雪花李海洋侯富国姚静张璐施钧瀚刘瑞新李学林
医药导报 2024年3期
桂新景,李涵,王艳丽,范雪花,李海洋,侯富国,姚静,张璐,施钧瀚,刘瑞新,3,4,5,李学林,3,4,5
(1.河南中医药大学第一附属医院药学部,郑州 450000;2.河南中医药大学药学院,郑州 450046;3.河南省中药临床应用、评价与转化工程研究中心,郑州 450000;4.河南中医药大学呼吸疾病中医药防治省部共建协同创新中心,郑州 450046;5.河南省中药临床药学中医药重点实验室,郑州 450000)
白及为兰科植物白及Bletillastriata(Thunb.)Reichb.f.的干燥块茎,始载于《神农本草经》[1]。该药性微寒,味苦、甘、涩,具有收敛止血、消肿生肌功效,主要用于咯血、吐血、外伤出血、疮疡肿毒、皮肤皲裂等[2],是中医药治疗胃肺出血的经典药物。白及主产于四川、贵州、湖南等地[3],除具有较高的药用价值外,还可用于化妆品[4-5]、工业制胶[6-7]及食品行业[8]。因过度采挖和繁育困难,近年来白及野生资源急剧减少[9],产量难以满足市场需求,导致市场上白及饮片品质良莠不齐、掺伪掺假现象时有发生[10]。白及常见的掺伪品是外观较类似的黄花白及、天麻、玉竹等[11-12]。伪品的流通严重影响白及饮片质量、疗效和用药安全。为保证白及饮片质量,建立快速高效的白及真伪鉴别方法迫在眉睫。
白及的鉴别方法主要分为传统鉴别法和现代仪器分析法两类。传统鉴别法即通过眼观、手摸、鼻闻、口尝、耳听等方式结合经验进行鉴别[13],其优点是快速、简便,但该法主观性强,依赖经验;现代仪器分析法即性状、显微、薄层、含量测定[14-19]、分子鉴别[20]等,这类方法能够通过定性或定量鉴别白及饮片,存在较好的重复性,但存在操作繁琐、耗时较长等问题。因此,探索建立一种快速准确的白及饮片鉴别新方法是目前亟需解决的问题。人工智能嗅觉技术是模拟人体嗅觉的一类仿生学技术[21],又称电子鼻技术,该技术起源于20世纪80年代[22]。其原理与人的嗅觉感知模式类似,即通过气敏传感器将待测样品气味物质的物理信号转化为电信号,通过对信号进行处理和模式识别,从而获取待测样品的完整气味信息。目前该技术在中药材产地区分[23-24]、中药鉴定[25-28]、中药炮制[29-30]等方面已得到广泛应用,有望为白及饮片的质量评价开拓新的思路和方法。
笔者在本实验选取白及饮片及其3种常见掺伪品为研究载体,基于电子鼻获得4类样本嗅觉感官数据,使用化学计量学方法分别建立二分类和四分类辨识模型,以模型交互验证正判率为指标,探讨基于人工智能嗅觉技术建立白及饮片真伪快速鉴别方法的可行性,同时为其他饮片的快速鉴别提供参考。
1 仪器与试药
1.1仪器 α-FOX4000电子鼻(法国Alpha MOS公司18根传感器电子鼻-气味分析系统),传感器及其敏感物质见表1;FW-100型高速万能粉碎机(北京科伟永兴仪器有限公司,规格:60~180目);四号药典筛(浙江上虞市道墟五四仪器厂,筛孔内径0.25 μm);BSA2245-CW型电子天平(德国Sartorius公司,感量:0.1 mg);XS105型电子分析天平(瑞士METTLER TOLEDO公司,感量:0.01 mg);HK250型超声波清洗器(上海科导超声仪器有限公司);LEICA DM1000型电子显微镜(上海LAS V4.0系统);TLC ViSuALi ZER2型薄层成像仪(瑞士卡玛公司);GZX-9146MBE型电热鼓风干燥箱(上海博迅实业有限公司医疗设备厂);HHS电热恒温水浴锅(北京科伟永兴仪器有限公司);4-13型高温箱型电阻炉(沈阳市节能电炉厂)。
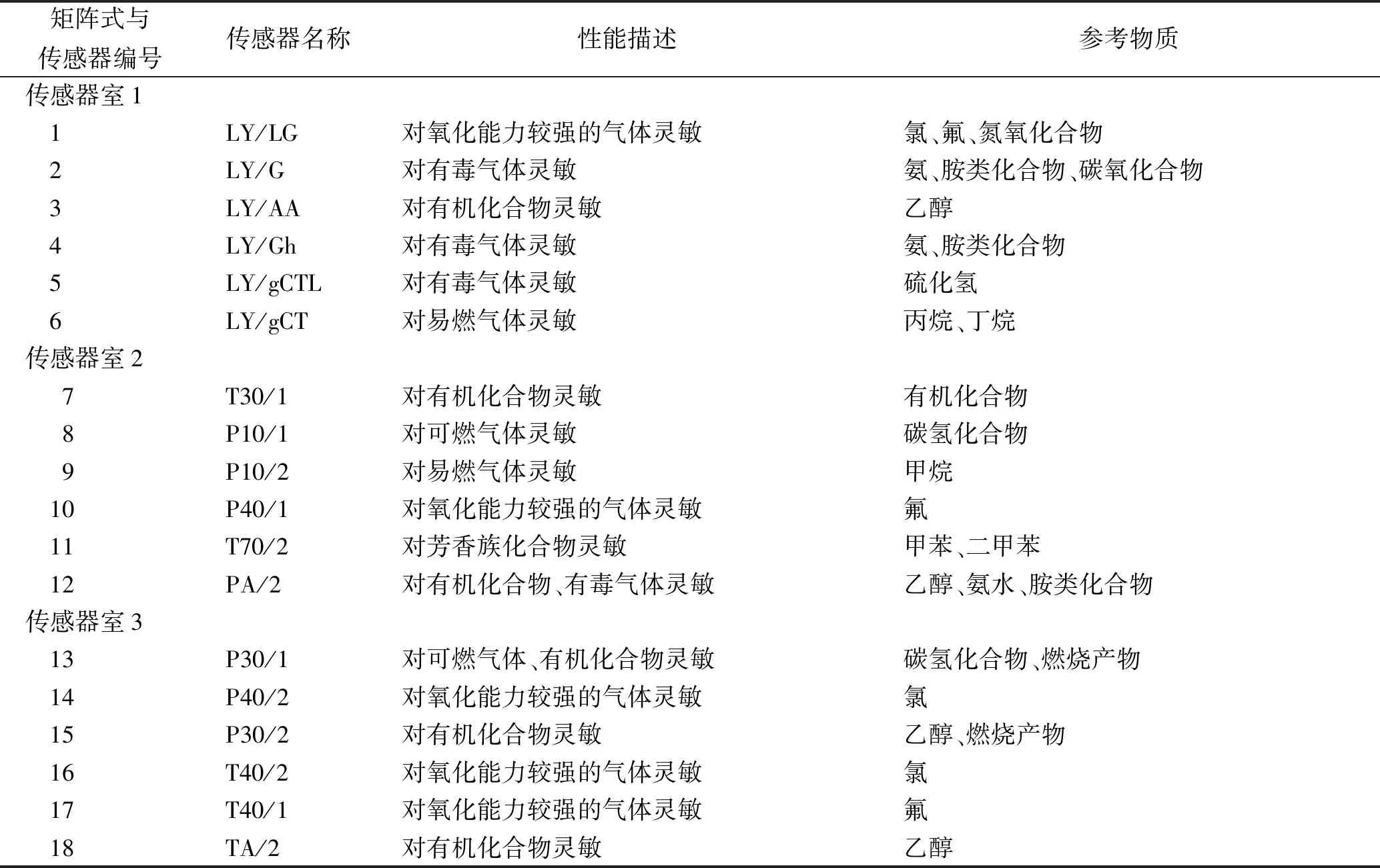
表1 α-FOX4000电子鼻18根传感器敏感物质
1.2材料 Militarine(1,4-二[4-(葡萄糖氧)苄基]-2-异丁基苹果酸酯)(上海源叶生物科技有限公司,批号:K18O9B72711,含量≥98%);天麻素(中国食品药品检定研究院,批号:110807-201809,含量:96.7%);白及对照药材(中国食品药品检定研究院,批号:121261-201706);稀甘油(南昌白云药业有限公司,批号:20180708);水为超纯水;甲醇、乙腈、磷酸均为色谱纯,其他试剂为分析纯。实验用白及45批、天麻30批、玉竹30批和黄花白及29批,分别购自河南中医药大学第一附属医院、河南中医药大学第三附属医院等单位,样品具体信息见表2。
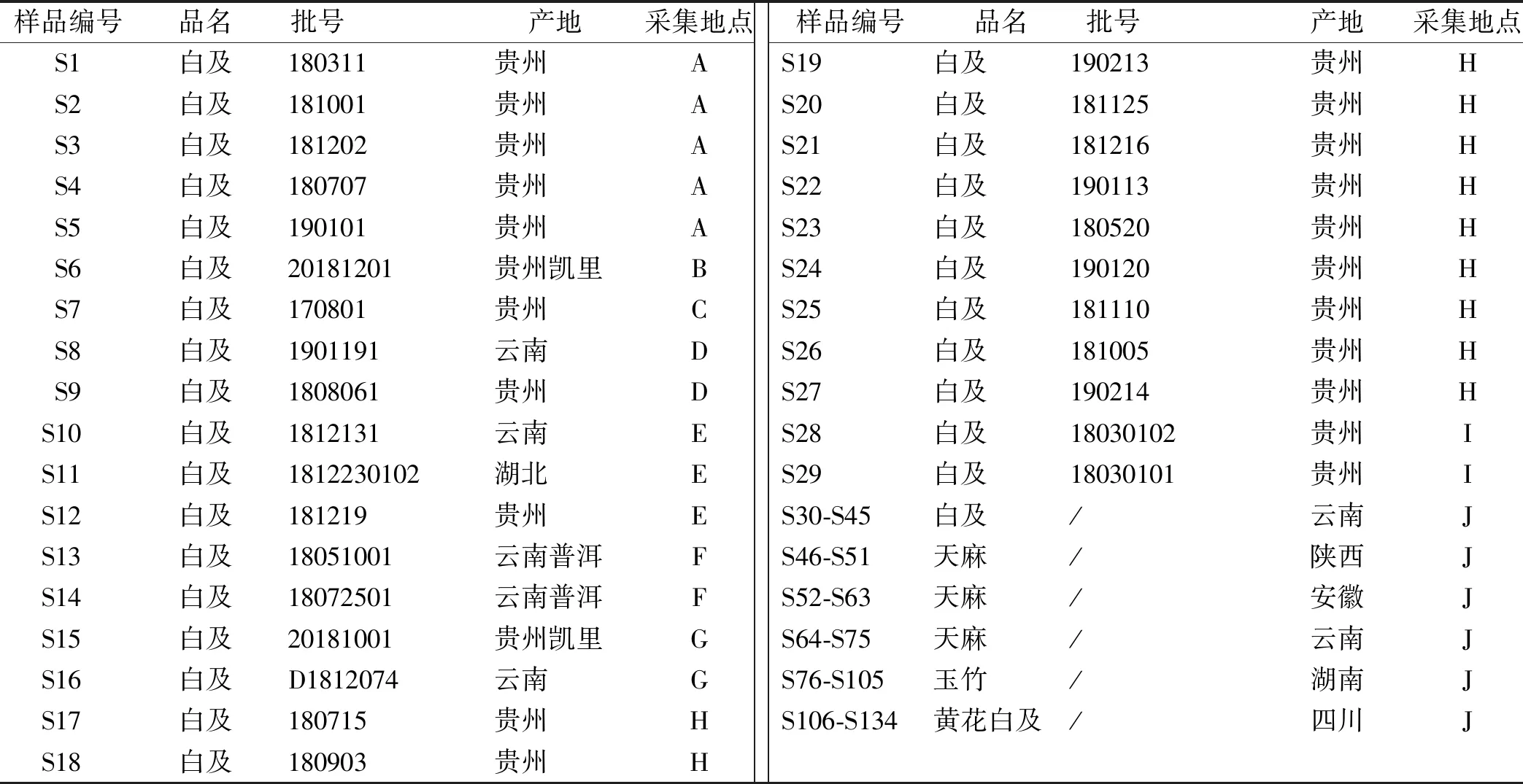
表2 白及、天麻、玉竹、黄花白及样品信息
2 方法
2.1样本的辨识
2.1.1药典辨识 参照2020年版《中华人民共和国药典》(一部)白及项下性状、显微、薄层鉴别、水分、灰分检查方法,对134个样本进行鉴别和测定;并结合2015年版《四川省中药饮片炮制规范》[31]所载黄花白及项下的性状鉴定方法,对4种饮片进行鉴别。
2.1.2电子鼻信号采集 取1-134号样本粉碎后过6号筛[筛孔内径(150±6.6) μm],精密称取样本粉末1 g于样品瓶中,程序参数设定为进样量500 μL,进样量速率500 μL·s-1,进样温度35 ℃,获取时间120 s,进样周期1 s,进样时间720 s,冲洗时间120 s,以空气为载气,气体流速500 μL·s-1,进样针温度45 ℃,每个样品采集3次,取平均值,得到18根传感器嗅觉信息矩阵X(18×134)。
2.4模型(潜变量)与嗅觉传感器对分类贡献度的追踪
2.4.1基于Wilk's Lambda值变异度的分析与排序 以电子鼻的18根传感器为原始变量,通过构建Wilk's Lambda柱状图可以深入分析各传感器携带的变异信息,从而追踪各传感器对模型分类的贡献度大小。
2.4.2最优模型潜变量载荷图追踪 根据“2.2节”和“2.3节”下二分类及四分类的最优模型,分别建立其模型潜变量载荷图,同时结合各传感器Wilk's Lambda值,找到对模型分类结果贡献度较大的传感器。
3 结果
3.1基于药典的鉴别结果 根据性状、显微、薄层鉴别以及水分、灰分检查的综合结果,45批白及饮片符合2020年版《中华人民共和国药典》(一部)白及项下标准,同时不符合2015年版《四川省中药饮片炮制规范》、2009年版《甘肃省中药炮制规范》[32]和2009年版《甘肃省中药材标准》[33]黄花白及项下标准。30批天麻饮片和30批玉竹饮片经河南中医药大学第一附属医院陈天朝主任药师鉴定为正品天麻和玉竹饮片。29批黄花白及饮片与白及对照药材薄层色谱极为相似,难以区别;性状特征和显微特征方面,106-120号黄花白及样本均和白及较为相似,但其显微背景较白及浑浊,不易区分,121-134号黄花白及样本与白及相比,木化严重,质感有明显差异,性状特征与白及不同,符合地方标准中规定的黄花白及项下标准。由此可见,仅靠《中华人民共和国药典》(2020年版)及地方标准,部分黄花白及饮片不易鉴别。
3.2二分类模型辨识结果
3.2.1PCA-DA二分类辨识模型及交互验证正判率 PCA-DA最优辨识模型参数为主成分选择17个,此时这些主成分能够解释样本>99%的信息。样品判别结果见表3,45个白及样本中有5个被误分类,非白及样本中有1个被误分类,模型交互验证正判率为95.52%。模型主成分得分图见图1(A),两类样本在二维空间有重叠,但该模型区分度高,辨识结果中没有未分类样本,因此基本可将白及与非白及饮片区分开来。
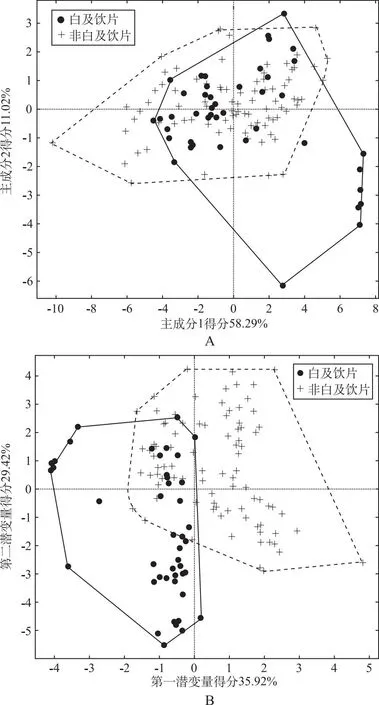
A.PCA-DA二分类辨识模型主成分得分图;B.PLS-DA二分类辨识模型潜变量得分图。

表3 PCA-DA留一法交互验证模型判别结果
3.2.2PLS-DA二分类辨识模型及交互验证正判率 当潜变量个数优选为15时模型性能最优,所选15个潜变量能够解释>99%的自变量变异信息。样品判别结果见表4:45个白及饮片中1个被误分类,89个非白及饮片中3个被误分类,模型交互验证正判率为97.01%。模型潜变量得分图见图1B,两类样本在二维空间有部分重叠,表明白及饮片与非白及饮片在前两个潜变量上有相似之处。该模型区分度好,辨识结果中没有未分类样本,因此该模型可用作白及饮片与非白及饮片的辨识。

表4 PLS-DA留一法交互验证模型判别结果
3.2.3SVM判别模型及交互验证结果 由于样本的原始响应数值较小,因此在建模之前对数据进行“标准正态变换(standard normal variation,SNV)”的行预处理,列预处理方法选择“autoscaling”,核函数选择径向基核函数(radial basis function,RBF),经预试后,核参数初始值设为9,cost values初始值设为1 000,主成分个数应用选择“自动(automatic)”,然后按照此参数设置优选核参数及cost values值,优选结果见图2。

图2 白及SVM二分类辨识模型参数优选
由参数优选的等高线图可知,当cost values值为1 000、核参数为0.8时,模型错误率最小,为0.1。此时模型判别结果混淆矩阵如表5,正判率为91.79%,7、26、33、35、39、43、44号白及被误判为非白及,46、65、69和73号天麻被误判为白及,图3显示了支持向量的个数,为88,红色虚线是SVM模型构造的分类“超平面”,“1”和“-1”线上的样本称为“支持向量”,由图可知,该SVM模型构建的分类超平面能够将两类样本分开。
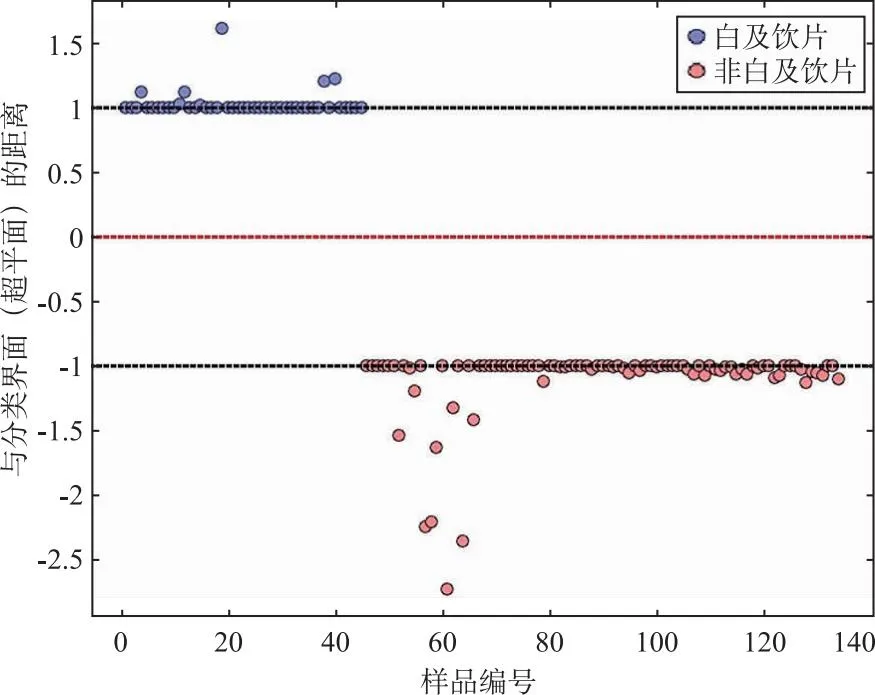
图3 白及SVM二分类辨识模型分类超平面及支持向量

表5 SVM二分类辨识模型留一法交互验证判别结果混淆矩阵
3.2.4BP-NN判别模型及交互验证结果 反向传播神经网络模型无法优选参数,因此需逐个尝试参数,最终优化结果如下:隐藏层个数(hidden layers):4, 每层的神经元个数(neurons per layer):10,学习率(learning rate):0.01, 动量项(alpha):0.9,迭代次数(iterations):500。由图4可知,当训练的迭代次数为500时,模型错误率达到0。此时模型留一法交互验证判别结果及混淆矩阵如表6,白及中36、37、40、44号样本被误分类,46、52、53、56、57、59、61、66、72、74号天麻被误分为白及,67、69号天麻,76、77、78、86号玉竹,127号天麻未分类。模型正判率为84.33%。
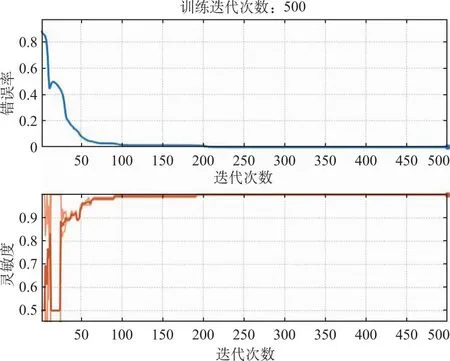
图4 白及BP-NN二分类辨识模型迭代次数及错误率

表6 BP-NN二分类辨识模型留一法交互验证判别结果混淆矩阵
3.3四分类模型辨识结果
3.3.1PCA-DA四分类辨识模型及交互验证正判率 模型性能最优时主成分个数为17,这些主成分能够解释样本>99%的变异信息。样品判别结果见表7,经留一法交互验证后,45个白及饮片、30个天麻饮片、30个玉竹饮片中分别有5、1、6个被误分类,正判率为91.04%。误分类情况具体如下:白及样品38、40、42、43、45号被误分为天麻;天麻样品50号被误判为玉竹;玉竹样品77、78、85、97、99号被误判为天麻,84号被误判为黄花白及;黄花白及无误分类。模型主成分得分图见图5(A),4类样本在二维空间中有相互重叠现象,说明在前2个主成分所表征的气味信息上,4类样本有一定的相似性。该PCA-DA模型辨识结果中无未分类样本,因此,该数学建模方法基本可用于4类饮片的分类辨识。
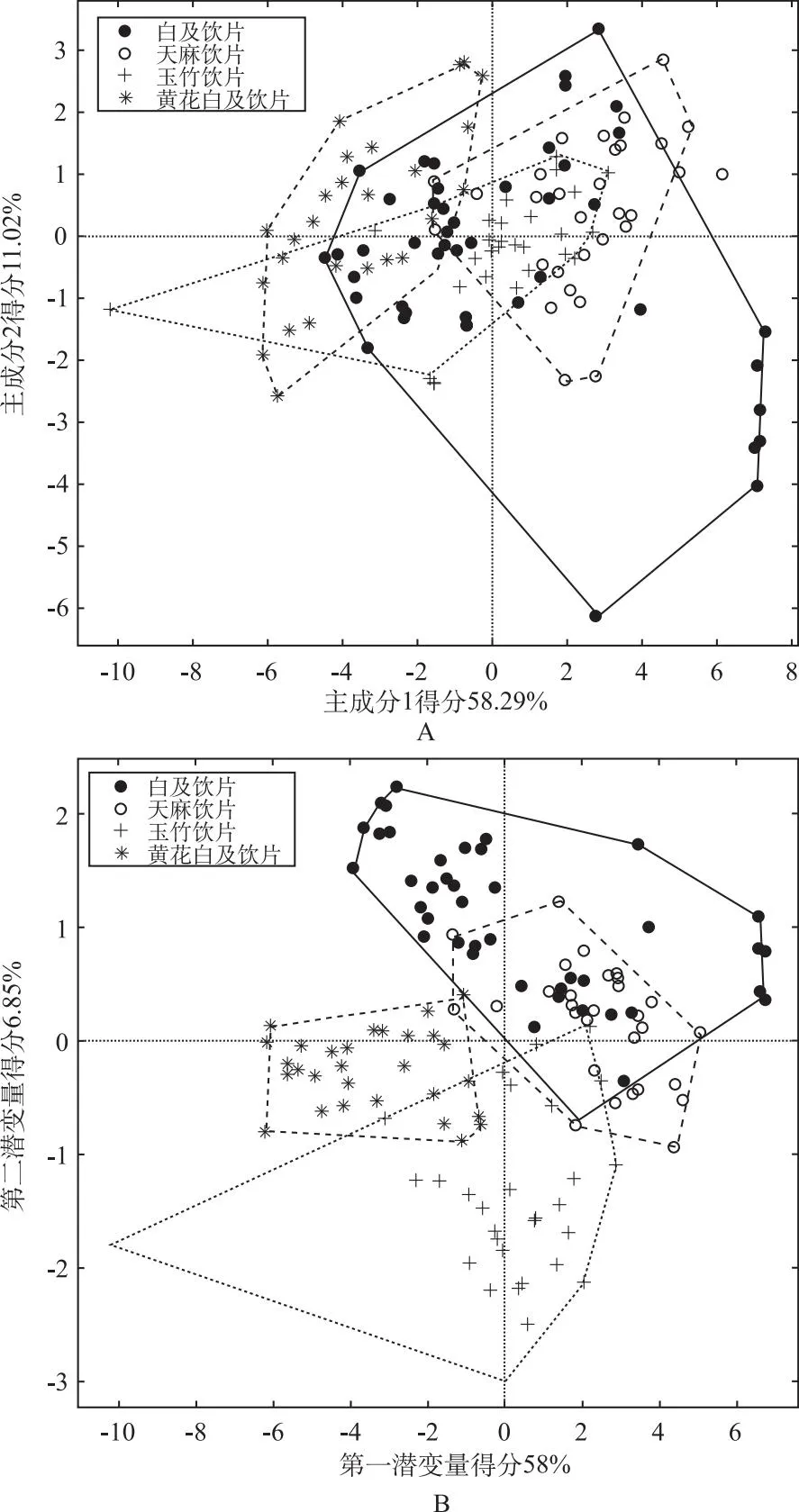
A.PCA-DA四分类辨识模型主成分得分图;B.PLS-DA四分类辨识模型潜变量得分图。
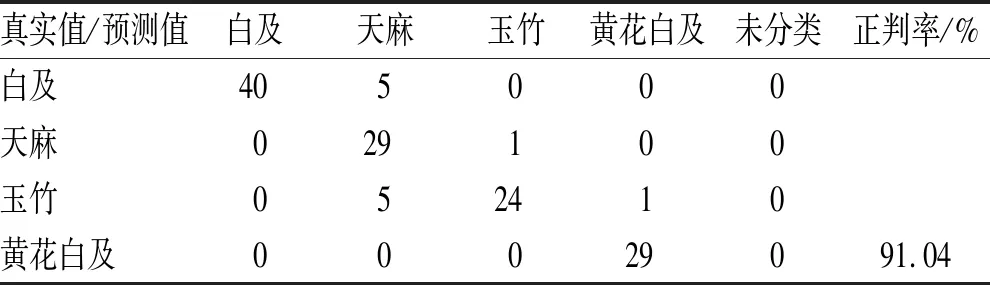
表7 PCA-DA留一法交互验证模型判别结果
3.3.2PLS-DA四分类辨识模型及交互验证正判率模型性能最优时潜变量15个,所选15个潜变量可解释>99%自变量差异信息和约50%因变量差异信息。样品判别结果见表8,经留一法交互验证后,45个白及饮片中有1个被误分类为天麻饮片,5个未分类;30个天麻饮片中有1个被误分类,4个未分类;30个玉竹饮片中有2个被误分类,2个未分类;29个黄花白及饮片中有1个未分类,将未分类样本看作模型判错样本,PLS-DA模型正判率为88.06%。误分类情况具体如下:白及样品26、38、42、43、44号未分类,45号误判为天麻;天麻样品46、48、50、72号未分类,53号被误判为白及;玉竹样品78、84号未分类,77、85号被误判为天麻;黄花白及124号未分类。模型潜变量得分图见图5B,白及饮片与黄花白及饮片在二维空间中无重叠现象,与天麻饮片重叠较多,表明白及饮片与天麻饮片在前两个潜变量所表征的气味信息方面有一定的相似性,这也是1个白及饮片被误分类为天麻饮片的原因。考虑到该模型辨识结果中存在未分类样本,因此用作4类饮片的辨识时其性能还需改进。
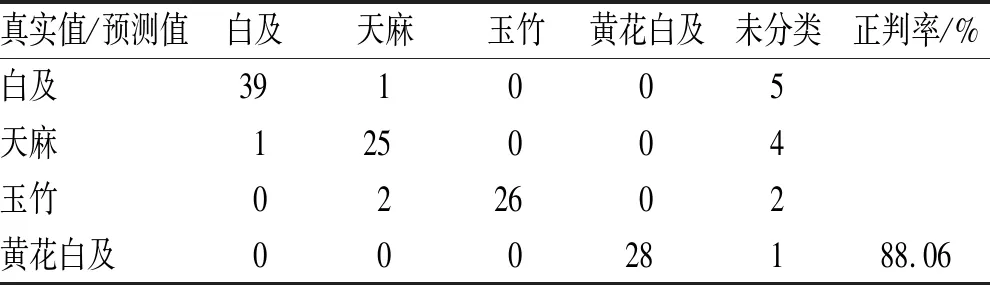
表8 PLS -DA留一法交互验证模型判别结果
3.3.3LS-SVM判别模型及交互验证结果 样品判别结果见表9。经留一法交互验证后,45个白及饮片中有4个被误分类为天麻饮片;30个天麻饮片中有3个被误分类为白及,1个未分类;30个玉竹饮片中有4个被误分类为天麻,1个未分类;黄花白及无误分类。所建立LS-SVM留一法交互验证判别准确率为89.55%。
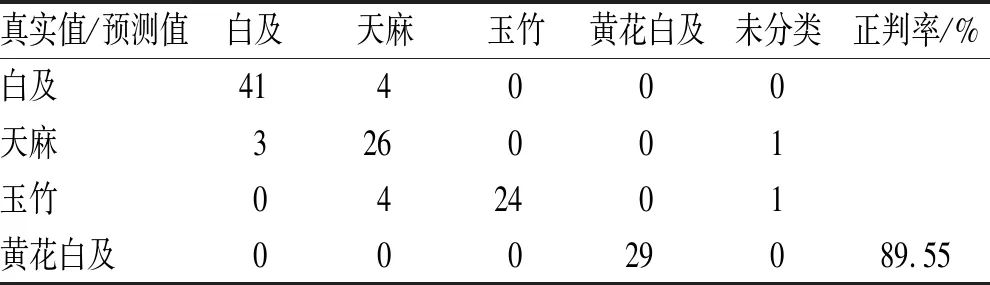
表9 LS-SVM留一法交互验证模型判别结果
3.3.4BP-NN判别模型及交互验证结果 参数设置:隐藏层个数(hidden layers):2, 每层的神经元个数(neurons per layer):10, 学习率(learning rate):0.01, 动量项(alpha):0.5, 迭代次数(iterations):1 000,此时模型错误率最小,见图6。此时模型交互验证判别结果及混淆矩阵见表10。判别结果:6、33、36、38、40、43号白及被误分为天麻;46、59、72、73号天麻被误分类为白及;77、78号玉竹被误分类为天麻;107、124号黄花白及被误分为玉竹。30、37、41号白及,47、66号天麻,86号玉竹和123、130号黄花白及未分类,正判率为82.84%。图7为BP-NN模型在迭代1 000次后对每类样本的输出值,为避免梯度消失或梯度爆炸导致模型不稳定,梯度下降函数将BP-NN算法中权值和阈值设置在0~1,因此,每类样本输出值在该区间内;图中红色线条为可视化类别输出的α值,可以看出BP-NN经学习后对每一类样本的输出值都明显不同于其他3类样本,分类性能良好;在玉竹类别的输出中,有一个样本的输出值显著小于其余玉竹样本的输出值,表明该BP-NN模型在对玉竹类别样本区分时,性能还有待提高。
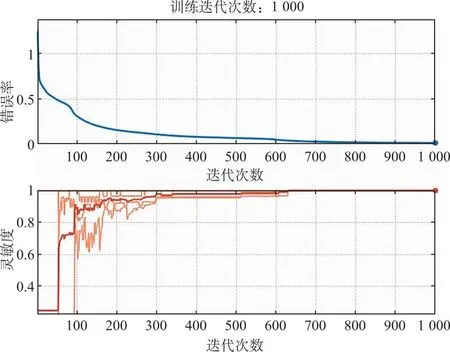
图6 白及样本BP-NN四分类辨识模型迭代次数及错误率

图7 样本BP-NN四分类辨识模型各类别输出值
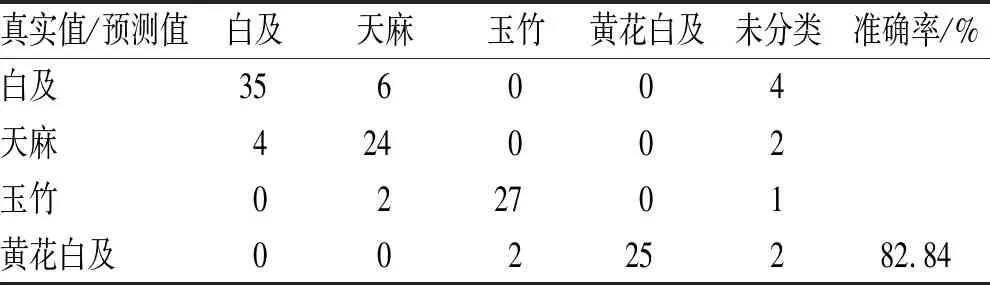
表10 BP-NN四分类辨识模型留一法交互验证判别结果混淆矩阵
3.4电子鼻各嗅觉传感器对模型贡献度分析 二分类辨识选择PLS-DA模型,四分类选择PCA-DA模型。α-FOX4000型电子鼻共有18根传感器,每根传感器携带变异信息值见图8和图9。
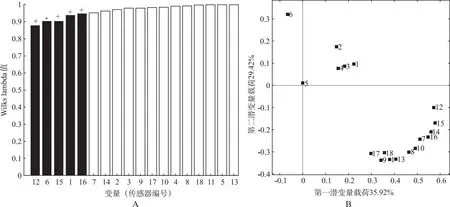
A.Wilk's Lambda柱状图;B.PLS-DA二分类辨识模型变量载荷图。
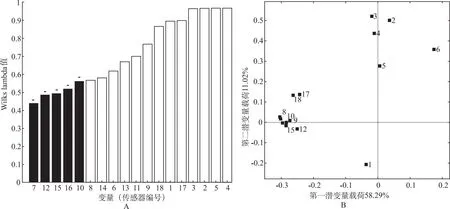
A.Wilk's Lambda柱状图;B.PCA-DA四分类辨识模型变量载荷图。
由图8(A)可知,相较于其他13根传感器,12、6、15、1、16号传感器所携带变异信息较多,对样本二分类贡献度较大,11、5、13号传感器携带变异信息较少。结合图8(B)中各传感器变量在模型第一、第二潜变量上的载荷图,12、15、1、16号传感器为正相关变量,6号传感器为负相关变量,5号传感器在原点附近,说明其特征波动对样本分类影响较小,结合传感器Wilk's Lambda值可知,13号传感器所携带变异信息也较少,但其距离原点较远,这是因为每个变量解释的变异信息是由PLS-DA模型的所有潜变量决定的,而二维图只展现了前两个潜变量所解释的变异,若要反映传感器携带的全部样本变异信息,则需要三维甚至多维的潜变量载荷图来实现。
图9(A)显示,在四分类辨识模型中,7、12、15、16、10号传感器携带样本变异信息较多,对134个样本四分类的辨识贡献度较大,3、2、5、4号传感器携带变异信息较少。结合PCA-DA模型变量载荷图,7、12、15、16、10号传感器均为负相关变量,3、2、5、4号变量距离原点较近,解释变异较小。
4 讨论
4.1电子鼻嗅觉信息数据的确定 由于每个样本的电子鼻原始数据量较大,α-FOX4000型电子鼻中包含每个样本120 s内的传感器响应值,因此需进行电子鼻
嗅觉信息数据的选取。嗅觉信息数据包括以下内容:每个传感器在特定时间点的响应值,每个传感器响应的平均值,每个传感器响应的最大值,每个传感器响应值的方差等。通过多次实验,笔者最终确定选择电子鼻各传感器的响应平均值作为嗅觉信息数据来建模。
4.2电子鼻不同传感器对样品响应分析 通过分析电子鼻不同传感器对4类样品响应均值发现,传感器LY/LG、T30/1、P10/1、P10/2、P40/1、T70/2、PA/2、P30/1、P40/2、P30/2、T40/2、T40/1、TA/2响应值为正值,其中PA/2响应值最大,LY2/LG响应值最小;P30/2等8个传感器对黄花白及响应高于其他饮片,P10/2等5个传感器对白及响应高于其他饮片;整体而言传感器响应值:天麻<玉竹<白及<黄花白及,黄花白及和白及同属白及属植物,因此其化学成分比较接近,这与电子鼻传感器响应情况也是吻合的,多数传感器对黄花白及响应高于白及说明黄花白及中挥发性成分含量相对较高。传感器LY/G、LY/AA、LY/GH、LY/gCTL、LY/gCT响应值为负值,且响应值均<0.005,根据传感器响应特点判断这几根传感器对应的化学成分在4类样品中含量较少。同一传感器对同一类样品的响应也会有一定程度的变化,这是由于中药饮片本身是非标准品,不同批次样品之间气味成分存在差异。
4.3传感器对应敏感成分分析 由“3.4节”可知,对白及及其他3类饮片分类贡献度较大的传感器是LY/LG、LY/gCT、PA/2、P30/2、T30/1、P40/1、T40/2,这些传感器对应的敏感物质分别为乙醇、氨、胺类化合物,丙烷、丁烷,有机化合物,氯、氟、氮氧化合物,氧化能力较强的气体,这些敏感物质与笔者所在课题组前期所做的白及、黄花白及和玉竹中的挥发性成分醇、醛、酯、酮、酸类、烷烃类、烯烃类、吡嗪类等成分有一定的联系。
4.4不同建模方法模型分类性能分析 笔者在本实验采用α-FOX4000型电子鼻对白及、天麻、玉竹、黄花白及4类共134个饮片采集气味信息,并基于PCA-DA和PLS-DA模型对样本进行定性分类辨识。对样本二分类辨识结果中,2个模型的正判率分别为95.52%、97.01%,以PLS-DA模型最优;样本四分类辨识结果中,两者正判率分别为91.04%和88.06%,PCA-DA模型较优。本研究发现,在样本二分类的辨识中两种判别模型都没有未分类情况,且PLS-DA模型分类结果较优。然而在四分类辨识中,PCA-DA模型无未分类样本,PLS-DA模型有12个未分类样本,因此就四分类而言显示PLS-DA分类能力相对较差。笔者推测这与模型的判别机制有关,相较于两种类别,将标杆信息划分为4种类别会使PLS-DA模型的辨识标准更加严苛,从而导致模型无法区分某些特征性不强的样本。PCA-DA四分类模型正判率低于其二分类模型,可以看出PCA-DA模型性能受样本分类的标杆信息影响,当标杆信息值越多时其分类难度增大,正判率会随之降低。PCA-DA和PLS-DA分别是基于主成分回归与PLS回归的判别分析方法,其中PCA-DA能够简化多维数据中相互重叠的样本信息,因此其对于多分类情况中某些成分影响较小的分类更适用;PLS-DA受其线性关系的影响,对多分类样本的辨识有一定局限性。
4.5误分类及未分类样品分析 通过分析4种建模方法分类结果,在二分类辨识中仅有BP-NN模型有未分类样本,其余3种模型均无未分类样本;而四分类辨识中除PCA-DA外,其余3种模型均有未分类样本,且误分类样本数PLS-DA(12个)>BP-NN(9个)>LS-SVM(2个)。误分类及未分类样本存在的原因可能是这些样本与其他同类样本的组内或组间差异较大,导致模型判错或未分类。
4.6基于智能嗅觉技术的中药饮片鉴别方法可行性分析 “辨状论质”是中药材传统经验的总结,是鉴定中药品质真伪优劣的重要方法。中药具有的特征性气味是评价其质量的主要依据之一,也是其真伪鉴别的重要依据。电子鼻作为模拟人工嗅觉系统的机器,相比传统GC、GC-MS 等技术而言具有整体性、快捷、环保、样品预处理简单等优点,基于辨状论质思维采用电子鼻技术用于中药饮片鉴别方面可行性已有多名学者开展研究。杨诗龙[34]采用电子鼻技术结合PCA等化学计量学分析方法,可实现浙贝母、平贝母、川贝母和伊贝母粉末快速准确鉴别;刘红秀等[35]通过电子鼻建立了八角、白豆蔻、砂仁等7种中药材鉴别方法,鉴别准确率100%;王蔚昕[36]采用电子鼻技术,结合PCA等多元统计方法可以对正品防风、北柴胡及其地方习用品准确进行鉴别。本研究采用电子鼻对白及饮片及其掺伪品进行鉴别的最佳二分类和四分类模型正判率分别为97.01%和91.04%,均取得较优鉴别结果,故基于智能嗅觉技术的中药饮片鉴别在方法上是可行的。分析本研究未能达到100%正判率的原因是选择的研究载体白及、黄花白及、玉竹、天麻性状描述均为气微,其气味特征均不明显,容易导致难以辨识其气味特征而出现误分类或者未分类情况。此外,人工智能技术还包含了电子眼、电子舌等,可以考虑融合多种感官信息数据,有利于提高信息维数,对于提高模型正判率会有所帮助。
基于智能嗅觉技术(α-FOX4000电子鼻)所建立的白及真伪二分类最优辨识模型为PLS-DA模型,四分类最优辨识模型分别为PCA-DA模型。上述两种模型均具有良好的预测能力,可以用于白及饮片的真伪鉴别。总体而言,本研究所建立的方法可准确、快速地鉴别白及及其近似饮片,为中药饮片气味客观化表达及真伪鉴别提供了新思路和新方法。
猜你喜欢
中草药(2023年20期)2023-10-19
今日农业(2022年14期)2022-09-15
今日农业(2022年3期)2022-06-05
黄河之声(2020年16期)2020-11-05
今日农业(2020年16期)2020-09-25
中医眼耳鼻喉杂志(2019年3期)2019-04-13
中成药(2018年12期)2018-12-29
天然产物研究与开发(2018年7期)2018-08-21
百科探秘·航空航天(2016年6期)2016-12-01
中老年健康(2015年1期)2015-05-30
