
加权Petri网的字符串序列相似性度量
2024-03-04 06:06胡迎城邢玛丽吴元清
广东工业大学学报 2024年1期
胡迎城,邢玛丽,吴元清
(广东工业大学 自动化学院, 广东 广州 510006)
流程管理的基础在于流程的检索定位,即从流程模型库中寻找指定的相似流程,检索定位的关键技术在于如何度量流程之间的相似性。因此,只有好的流程相似性度量方法才能保障流程检索定位的有效性和准确性[1]。有了好的(快速精准)相似性算法,就能够对繁杂冗余的流程库进行整理更新以实现有效的流程管理,大大提高企业的运行效率及市场竞争力,从而促进企业的发展。流程相似性问题[2]是指给一个流程模型,如何从已经构建的流程模型库中检索出与给定流程相似的流程模型,主要思想是将给定的流程模型与流程库中的每个流程模型进行比对,快速精准地计算流程间的相似度值。目前主要是基于文本、结构和行为相似性3个方面[3]来展开研究的,但仍然存在不足,下面将简单介绍其中的一些缺陷。
文献[4-5]提出的相似性度量方法都是针对流程中相关标签(一般有任务标签、角色标签、资源标签和属性标签等)的文本内容进行相似性分析,但很难筛选出在流程模型本身特征上(即结构和行为特征)的相似流程。李东月等[6]提出的基于活动发生关系(Activity Occurrence Relation,AOR)的流程相似性算法和基于行为轮廓的流程模型及其流程变体的距离相似性分析等,定义了一系列关系来度量模型结构相似性。董子禾等[7]还考虑了循环结构,但计算过程过于复杂且花费时间过长。而针对流程结构的相似性,文献[8]采用图编辑的方法来进行度量。虽然有较高的准确性,但其计算复杂度很高,而且该类方法往往很难识别出结构相似但行为不同的模型,不太适用于实际应用。吴亚锋等[9]提出的基于邻接矩阵的业务流程间距离计算方法,宋金凤等[10]提出的基于任务发生关系的流程模型相似性度量,将行为信息转换成矩阵进行相似性计算,有比较高的度量效果和时间效率,但却是在单一维度上考虑流程间的相似性。对于多维度的相似性度量方法,周长红等[11]提出将模型结构和行为信息相结合,从而提高流程相似度的准确率,但其结构方面的度量仍是采用图编辑距离来计算,其图的编辑操作需要对边和节点进行处理,这些操作的定义困难、复杂度高且时间效率较低。
文献[12]通过对经典工作流网进行数据读写语义的扩展,提出了一种数据感知工作流网,将数据流信息整合到业务流程控制流中,基于数据感知行为从不同角度来量化流程相似度。文献[13]通过建立流程、路径和节点之间的函数表达式,使用独热编码对节点进行向量化表示,建立单层神经网络模型,从而量化流程相似度。文献[14]基于机器学习的方法来计算具有结构和标签差异的一对流程模型之间的相似度。文献[15]将任务流建模为图结构,根据层次划分方法计算图的相似度然后通过谱聚类算法对图进行聚类,使图被划分为聚类。文献[16]在业务流程中使用推荐技术包括某个点提出相关任务,从而使用决策树的方法来度量流程相似性。
本文使用广度优先遍历的方法将Petri网转换为字符串序列,在不降低准确率的基础上,避免了复杂度高的图编辑距离,很大程度上提高了流程的检索效率。
1 相关知识
1.1 加权Petri网
Petri网是一种形式化的方法,用来描述业务流程的执行过程,将业务流程的执行过程表达成一个图的形式。其中,图中的每个节点都代表一个活动或状态信息。另外,现在很多企业都将Petri网作为业务流程的表达形式,并将Petri网作为相关软件的输入输出,因此,选择Petri网作为业务流程相似性的研究对象,其定义如下。
定义1 加权Petri网[11,17]。加权Petri网是一个四元组N=(P,T,F,λ) , 其中P是所有库所的有限集合,T是所有变迁的有限集合,有P∩T=Ø;F是所有边的有限集合,指P,T之间的连接关系,即F⊆(P×T)∪(T×P) ,是一个映射到集合{0,1}的函数,如F(p,t)=1, 则表示p到t是通过一条有向弧相连接的;λ:F →R是一个函数,该函数将每一条有向边映射为一个权值,其中R为实数集。把Petri网中所有节点记为集合X=P∪T,对于任意节点x∈X,节点相邻的边包括输入边和输出边;其相邻节点集合表示为Y={y∈X|(x,y)∈F,(y,x)∈F} ,其 中,·x={y∈X|(y,x)∈F}为前置节点,x·={y∈X|(x,y)∈F}为后继节点。
1.2 流程事件日志
流程事件日志记录了业务流程的各种运行状态信息,包括任务活动、执行角色、资源以及任务事件发生和结束的时间等,能够在很大程度上直观地反映事件的执行情况。下面对流程事件日志中涉及到的一些基本概念[18]进行定义:
定义2 事件(Event)。事件也称为任务活动,是流程中的最小单元,由该事件的一系列属性组成,定义为
式中:事件e的属性C aseID 是 指案例的ID值,EventID是指事件的ID值,E ventName是事件活动名称,是唯一的;S tartTime 和E ndTime是该事件发生和结束的时间戳,该事件的执行时间就可以用e(EndTime)-e(Start Time)来 表示;而A tt1,···,Attm是指该事件的其他相应属性,比如执行角色、所用资源等属性。
定义3 事件轨迹(Event Trace)。通常事件轨迹也称为案例,指流程模型的一次执行结果,是由流程中的一系列事件有序构成的集合,定义t=<e1,e2,···,en> 是一个长度为n的 事件轨迹,其中,ei∈t是事件轨迹t的 第i个 事件,同一个事件轨迹的C aseID值相同。
定义4 事件日志(Event Log)。事件日志是由一系列事件轨迹构建的集合,定义L=<t1,t2,···,tk>是一个包含了k个事件轨迹的事件日志。其中ti∈L是事件日志中的第i个事件轨迹,同一事件日志中的所有事件轨迹都是由同一业务流程运行产生的。如表1所示为某流程被执行后生成的事件日志实例,记为L=<t1,t2,t3,t4,t5,t6>,表示该流程被执行了6次,生成了6个事件轨迹,对应的事件为{e1,e2,e3,···,e17},其出现的任务活动有{a,b,c}。
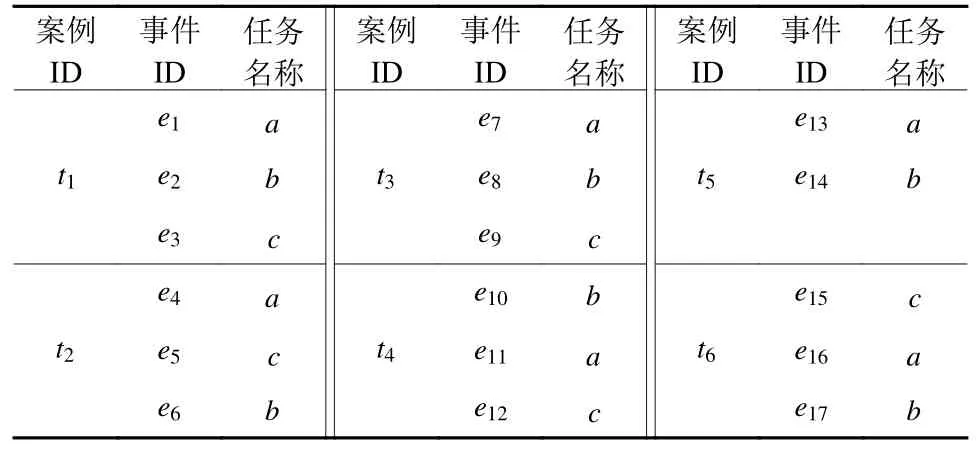
表1 流程事件日志实例Table 1 The instance process event log
1.3 变迁发生关系的相关定义
对于流程模型变迁之间的发生关系,有如下5个定义[19]。
定义5顺序关系。无论库所节点的前置节点和后继节点的个数,该库所节点的任意前置节点和任意后继节点之间的发生关系均为顺序关系,用符号 →表示,即当x∈P,·x={y1,y2∈T},x·={z1,z2∈T}时,有y1→z1,y1→z2,y2→z1,y2→z2。
定义6并行关系。当且仅当不同的库所节点的前置节点或后继节点为同一变迁节点时,其不同的库所节点对应的后继节点或前置节点之间的发生关系为并行关系,用符号 &表示,即当且仅当x1,x2∈P,·x1=·x2={y∈T},x1·={z1∈T},x2·={z2∈T} 或·x1={y1∈T},·x2={y2∈T},x1·,x2·={z∈T} , 分别有yz1&yz2或y1z&y2z。
定义7选择关系。当且仅当库所节点的前置节点或后继节点为多个变迁节点时,该库所节点的前置节点之间或后继节点之间的发生关系为选择关系,用符号|表 示, 当x∈P,·x={y1,y2∈T},x·={z1,z2∈T}, 有y1z1|y1z2,y2z1|y2z2,y1z1|y2z1,y1z2|y2z2。
定义8循环关系。当且仅当不同的库所节点的前置节点和后继节点为同一变迁节点时,其不同的库所节点对应的后继节点和前置节点之间的所有变迁节点与上述同一变迁节点所构成的发生关系为循环发生关系,用符号@ 表示,即当x1,x2,x4∈P,x1·={z1∈T},x2·={z2∈T},·x4={z3∈T},·x1=x4·={y∈T},有yz1@yz2@yz3。
定义9紧邻变迁对。对于同一个库所节点,无论前置节点和后继节点的个数,只要是分别由该库所节点的前置节点和后继节点构成的一对变迁,均称为紧邻变迁对,且变迁对的变迁节点关系是顺序关系,即当x∈P,·x={y1,y2∈T},x·={z1,z2∈T}时,有紧邻变迁对(y1,z1),(y1,z2),(y2,z1),(y2,z2), 且有y1→z1,y1→z2,y2→z1,y2→z2。
2 流程相似性度量方法
基于广度优先遍历的加权序列的流程相似度计算方法主要分为3个步骤:(1) 将事件日志中的行为信息进行处理,获取活动之间的频次比,并作为Petri网中相邻变迁的边系数;(2) 使用广度优先遍历将带边系数的加权Petri网模型转换为字符串序列;(3) 最后计算流程之间的相似度值。
2.1 加权Petri网的构建
对企业内流程实际运行过程中产生的事件日志,或是对模拟生成的事件日志进行操作;然后得到流程模型的行为序列轨迹及其在事件日志中出现的次数,记为:
式中:根据定义9,紧邻变迁对在流程事件日志中表现为两两相邻的一对任务,即紧邻任务对,记作σi=(ei,ei+1),并将所有紧邻任务对组合的集合称为紧邻任务对集,记作Λ =(σ1,σ2,···,σn)。 紧邻任务对σi∈Λ在流程事件日志中出现的频次与轨迹总数的占比记为F(σi,L) , 并将F(σi,L)作为Petri网的紧邻变迁对与库所节点分别相连的两条边的权重系数,当Petri网的某条边有多个权重系数时,则将这多个权重系数的和作为该条边的权重系数,从而构建加权的Petri网流程模型。
如图1所示为某一流程的Petri网流程模型以及对应的加权Petri网,该流程模型的行为序列轨迹及各轨迹在事件日志中出现的次数表示为

图1 Petri网流程模型及对应的加权Petri网Fig.1 Petri net flow model and the corresponding weighted Petri net
2.2 广度优先遍历序列
广度优先遍历序列(Breadth-First Traversal Sequence,BFTS)是指在图中先定义一个起始节点,然后把与起始节点相邻的几个节点依次进行遍历,再遍历距离起始节点稍远一些的节点(相隔一层),然后再遍历距离起始节点更远一些的节点(相隔两层),一层一层地向外遍历,直到遍历所有节点,最后按遍历顺序将这些节点排序,形成广度优先遍历序列。
在Petri网中,基于图的广度优先遍历序列[15],在每一层遍历中,根据字母表的顺序判断遍历结果的顺序,即将遍历得到的变迁节点(活动任务)以字典序列的方式进行排序,形成字符串序列,定义为StringBFTS=S#σ1Rσ2#···#σn-1Rσn#E。其中,为了使转换后的序列能够有效描述Petri网的完整信息,首尾的S,E是添加的虚拟变迁节点,作为遍历的开始标志和结束标志;σi是指上文中提到的紧邻变迁对,σiRσj中R表示紧邻变迁对之间的关系,具体指变迁之间的关系:顺序、并行、选择和循环关系;为了更好地分析业务流程中活动任务之间的关系,对广度优先遍历所得到的每一层结果进行分层,符号“#”作为每层的分隔标志。
2.3 加权Petri网与BFTS的转换
在进行转换的过程中,基于广度优先遍历算法的特点,对每一个遍历节点记录它的相邻节点及其关系,并且使用符号“#”对每一个遍历层的遍历结果进行分层,这样能够更好地体现流程之间的结构信息。Petri网与BFTS的转换步骤如下:
(1) 对Petri网进行预处理,输入所有的库所节点和其相邻的变迁节点及边系数值,定位起始库所节点,其前置节点为S。
(2) 对当前遍历的库所节点搜索其前置节点和后继节点并存储;然后以简化后的带权重值的紧邻变迁对形式记录这些前置节点和后继节点。
(3) 根据1.3节的相关定义,判断步骤2记录的紧邻变迁对之间的关系,并用相关符号将这些紧邻变迁对隔开以表示其关系,每层的遍历结果用符号“#”隔开。
(4) 如果当前遍历的库所节点的后继节点是E,则该库所节点为最后一个遍历节点,遍历结束,形成以S为开头,E为结尾的BFTS。
为了更好地描述节点之间的关系和紧邻变迁对之间的关系的判断过程,将前置节点用Y表示,后继节点用Z表示,下面对判断规则进行介绍。
(1) 库所节点的前置节点集合和后继节点集合里分别选择一个节点组成节点对,称为紧邻变迁对,取它们中较小的边系数值作为该紧邻变迁对的权重值,带权重值的紧邻变迁对记为σ 。其中,节点对的关系为顺序关系Y→Z,为了方便记录,将符号” →”省略,若其权重值为0.5,则将简化的带权重值的紧邻变迁对记为σ =0.5YZ。
(2) 当遍历的库所节点的前置节点或后继节点有多个时,则分别从前置节点和后继节点各选择一个节点,节点构成的紧邻变迁对 σi,σj之间的关系若为选择关系,记为σi|σj。
(3) 若当前遍历库所节点的前置节点(后继节点)与另一已遍历库所节点的前置节点(后继节点)相同时,则其紧邻变迁对 σi,σj之间为并行关系,记为σi&σj。
(4) 如果当前遍历库所节点的某一后继节点是另一已遍历库所节点的前置节点,该后继节点与另一已遍历库所节点的前置节点内之间的所有变迁节点组成新的紧邻变迁对,等之间的关系为循环关系,其新的权重值为循环边系数与原紧邻变迁对的权重值的乘积,记为σ@σ@σ。
下面用一个加权Petri网流程模型的例子对每一条规则进行详细说明,如图2所示。
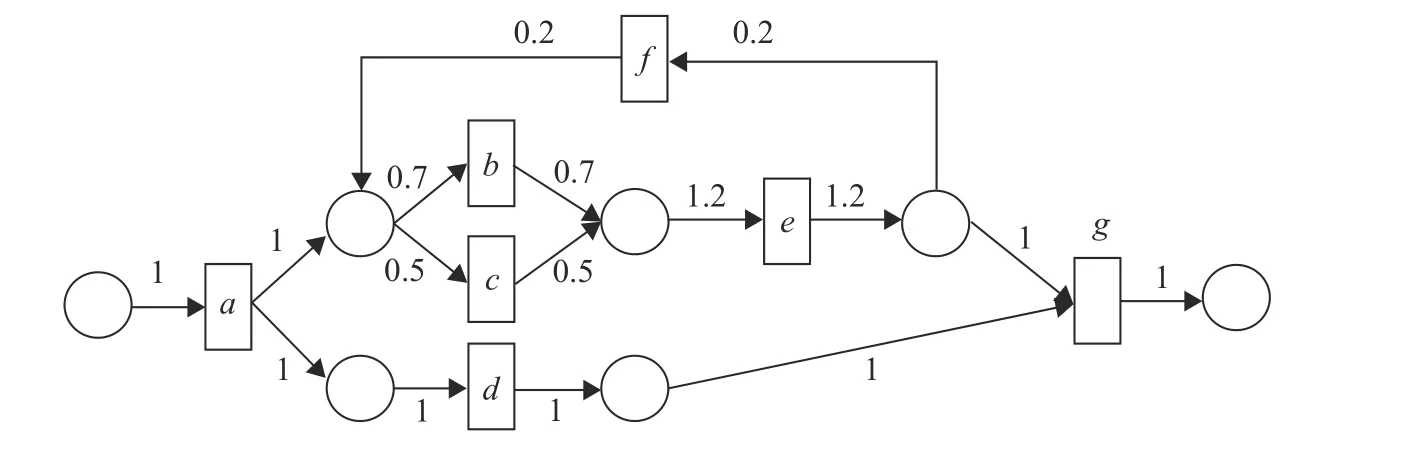
图2 加权Petri网流程模型Fig.2 Weighted Petri net flow model
(1) 首先定位在起始库所节点,其前置节点为添加的节点S,对该库所节点搜索到后继节点a,并且其边系数值为1,从而得到紧邻变迁对σ1=S a,第一层结束,并添加符号“#”。
(2) 遍历第二层,其第二层的第一个库所节点搜索到前置节点a、f,后继节点b、c,并且其边系数分别为1、1.2和0.7、0.5,从而得到紧邻变迁对σ2=0.7ab,σ3=0.5ac,σ4=0.7fb,σ5=0.5fc,这些紧邻变迁对之间的关系为选择关系,有σ2|σ3|σ4|σ5;第二层的第二个库所节点搜索到前置节点a,后继节点d,边系数均为1,得到紧邻变迁对 σ6=ad,由于这两个库所节点的前置节点a相同,所以有并行关系σ6&(σ2|σ3),第二层结束,添加符号“#”。
(3) 遍历第三层,第一个库所节点搜索到前置节点b、c,后继节点e,边系数分别为0.7、0.5和1.2,得到紧邻变迁对σ7=0.7be,σ8=0.5ce, 有选择关系σ7|σ8;第二个库所节点搜索到前置节点d,后继节点g,边系数均为1,得到紧邻变迁对σ9=dg,第三层结束,添加符号“#”。

(5) 遍历第五层,该库所节点搜索到前置节点g,后继节点为添加的节点E,边系数为1,得到紧邻变迁对为σ12=gE,遍历结束。得到Petri网的转换结果为
将转换得到的广度优先遍历序列展开有
将带边系数值的Petri网流程模型转换成BFTS的算法,具体如算法1所示。

算法1使用广度优先遍历将加权Petri网流程模型N=(P,T,F)转换成字符串序列Str,字符串序列Str存储了流程模型的所有活动节点、活动序列及其逻辑结构,保存着活动节点之间依赖的行为信息及相应活动节点之间逻辑的结构信息。
2.4 相似度计算
从模型结构和流程行为两个维度进行流程相似性的计算。在由Petri网转换成的字符串序列中,字符对与字符对之间的逻辑关系表示模型结构,字符与字符的依赖关系表示流程行为。首先将BFTS序列中含手动添加的首尾节点S、E的紧邻变迁对删除,再将其他代表活动与活动之间依赖关系的紧邻变迁对提取出来,并获取该紧邻变迁对的权重值,形成一个带权重值的紧邻变迁对集,称为行为集合,用来表示流程行为信息。然后再将BFTS序列中代表字符对与字符对之间逻辑关系的特殊符号提取出来,其中,循环部分的特殊符号只提取一个符号“@”,然后形成一个结构字符串,用来表示模型结构信息,称为结构序列。最后,运用多集的交并运算和字符串编辑距离的方法分别计算其相似度,并将这两个相似度值进行加权求和,最终得到两个流程模型之间的相似度值。
2.4.1 多集的交并运算过程及计算公式
由带权重值的紧邻变迁对组合成的行为集合可以被看作是一个多集,该多集中每个元素由两个部分组成:一是用数值表示的权重大小,二是用两个相邻的活动名称形成的一对字符。因此,计算该多集的相似度不能简单地通过判断集合中相同元素的个数来计算,而是需要根据交并运算来计算。假设A和B是两个由上述部分组成的多集,下面具体介绍A和B的交并运算过程。
定义这两个多集A={α1e1e2,···,αmei-1ei}和B={β1e1e2,···,βnej-1ej}, 其多集的元素个数分别为m和n,紧邻变迁对用 σ表示,每个紧邻变迁对 σ的权重值分别为α1,···,αm和 β1,···,βn。则这两个多集的交并运算如下:

2.4.2 字符串编辑距离
字符串编辑距离定义为将一个字符串转换成另一个字符串的最小字符编辑操作数,其编辑操作包括字符的插入、删除和替换,每个操作的权重值均设定为1。然后,将字符串之间的编辑距离除以字符串中较长字符串的长度值,使编辑距离值转换为字符串的相似度值,这样便将多个字符串之间的距离计算结果统一化,从而有效对比分析字符串之间的相似性。给定两个结构字符串S1和S2,定义它们之间的相似度为
式中: SimS(S1,S2)表示两个字符串之间的相似度,max(len(S1),len(S2))表示两个字符串中较长字符串的长度值, dist(S1,S2)表示字符串的编辑操作数,|skip|表示字符串转换过程中需要插入或删除的字符个数, |sub|表示字符串转换过程中需要替换的字符个数。
2.4.3 加权求和计算
最后,对行为集合相似度和结构序列相似度进行加权,最终得到两个流程模型之间的相似度,其计算公式为
式中:S im(N1,N2)表 示两个流程模型N1和N2之间的相似度, θ表示流程的行为集合对流程模型的重要性系数,记为流程行为相似性的权重参数,可以根据所检索的流程模型对活动名称、模型结构和流程行为的注重程度进行赋值,假设流程模型中行为和结构对最终结果的重要性相同,对θ 参数赋值为0.5。
为了更好地描述相似度计算过程,给出两个Petri网流程模型P0和P1, 如图3所示。其中P1是 基于P0改变获得的,对其删除了一个活动节点及对应的并行结构,并且增加了一个活动节点及对应的循环结构。

图3 P 0 和 P1的Petri网流程模型Fig.3 Petri net flow models of P 0 andP1
首先,将图3中的两个Petri网流程模型构造加权Petri网;然后基于转换规则将其转换成BFTS,得到相应的字符串序列,如表2所示;其次,对BFTS提取相应的行为集合和结构序列,其结果如表3所示;最后,通过式 (2) 和 (3) 计算行为集合相似度和结构序列相似度,有 SimB(A,B)=3/5.4 和S imS(S1,S2)=2/5,再通过式 (4) 加权求和,得到这两个Petri网流程模型的最终相似度值为S im(P0,P1)=0.478。

表2 P 0 和 P1的转换结果Table 2 The conversion results of P 0 and P1
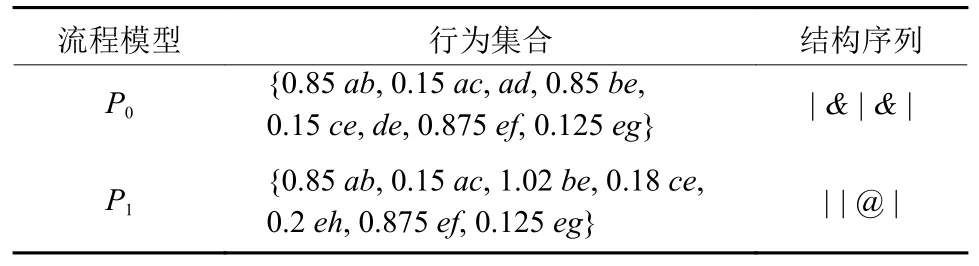
表3 P 0 和P 1的BFTS提取结果Table 3 BFTS extraction results of P 0 andP1
3 实验设计与分析
为了衡量提出的度量方法的特点和优势,本实验选择了3种具有代表性的相似度计算方法与之对比:基于变迁图编辑距离的流程相似性算法[8](TGED)、基于触发序列集合的流程模型行为相似性算法[7](PTS++)和基于模型结构与日志行为的流程相似度算法(WBPG)[11]。TGED方法是从模型结构的角度,通过图编辑距离的方式计算流程相似度;PTS++方法是从流程行为角度,通过统计处理任务之间的发生关系来计算相似度值,而WBPG方法则是从模型结构和流程行为的综合角度,并通过图编辑距离的方式计算相似度值。
3.1 实验数据
本实验的数据集来自文献[20],其数据集中的检索流程P0来源于一个真实的业务流程,其Petri网流程模型如图4所示。然后对其进行处理后建立基准数据集: (1) 创建混淆流程,即加入一个不相关的流程模型作为相关流程; (2) 改造相关流程,人为地改造了对应的9个相关流程; (3) 对相关流程进行排序,通过用户调查,对所有流程模型P1~P10进行排序。改造相关流程时主要在于分支结构和权重的变化,包括删除、添加分支结构及分支结构的性质变化;其中,分支结构有选择、并行和循环结构。
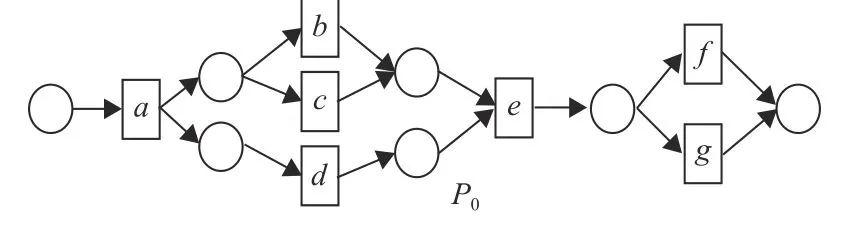
图4 检索流程 P0的Petri网模型Fig.4 Petri Net modelof the retrieval process P0
3.2 实验结果分析
实验过程中,对检索流程及其相关流程模型进行仿真,模拟流程模型的执行,产生事件日志并作为对应的行为信息,加权至Petri网中构造加权Petri网模型;然后经过广度优先搜索算法获得相应的字符串序列,再通过式 (2) 和 (3) 计算行为集合相似度和结构序列相似度,最后经式 (4) 加权计算得到相关流程P1~P10与 检索流程P0之间的相似度值。将方法与上述提到的3种方法进行比较,其对应的相似度值如表4所示。

表4 不同方法的度量结果Table 4 The measurement results of different methods
基于表4中各方法计算得到的相似度值大小对这10个相关流程进行从大到小的排序。另外,根据文献[16]的用户调查,采访了23位领域专家,分别根据自己的专业知识对该检索流程的相关流程进行相似度大小的排序,即基于相关流程与检索流程的相似程度,从大到小进行排序,最后将这些专家的排序结果进行整合,得到这些相关流程的一个基准排序结果。然后根据基准排序结果赋予对应序号的相关流程一个权重(本实验对排在第1名的流程模型赋予权重0.9,后面依次递减0.05,至最后第10名为0.45),最后得到如表5所示的排序结果。

表5 相似度排序结果Table 5 The sorting results of similarity
该实验选择归一化折损累计增益(Normalized Discounted Cumulative Gain,NDCG)对度量方法的准确率进行评估,其计算公式为
式中:NDCG用来衡量相似性的度量准确性,DCG(Discounted Cumulative Gain)用来表示在实验情况下的增加相关度影响比重,IDCG(Ideal Discounted Cumulative Gain)用来表示在理想情况下的增加相关度影响比重,p表示预设流程模型的数量,a表示实验排序结果中的排序位置, rela表示实验排序结果中排在第a位的预设流程模型对应的权重值,b表示基准排序结果中的排序位置, relb表示基准排序结果中排在第b位的预设流程模型对应的权重值。
基于表5的排序结果及相应的权重值,通过式(5)计算各度量方法的NDCG值,从而将流程相似性度量的准确率数值化,计算结果如表6所示。

表6 不同方法排序结果的评估结果Table 6 Evaluation results of sorting results based on different methods
NDCG值可以体现出这些方法的度量结果与专家给出的基准排序结果的吻合程度,其中NDCG值越大,吻合程度越高,即度量方法越准确。从表6中的数据可以看出,本文提出的度量方法有很好的度量准确性,其准确率高达99.51%,优于其他3种度量方法,更符合领域专家判定的结果。
3.3 方法评估
当前企业有着数以万计的大规模业务流程,企业已经不仅仅关心流程检索的准确度,也看重其检索的效率,从而减少检索过程中所花费的时间和成本。值得一提的是,本文方法由于将图编辑距离替换成了字符串编辑距离,在检索效率方面有着比较大的优势,本文方法与其他方法的时间复杂度如表7所示。

表7 时间复杂度对比Table 7 The comparison of time complexity
本文采用广度优先遍历算法将流程模型转换成了字符串序列,然后通过字符串编辑距离以及多集的交并运算来计算流程相似度,避免了高复杂度的图编辑距离。图编辑距离的时间复杂度为O(n3),这在大规模的业务流程库的流程检索中的时间消耗会成倍增加,其检索效率低下;而广度优先遍历算法的复杂度为O(n) ,字符串编辑距离的复杂度为O(m*n),多集的交并运算的复杂度为O(m+n),当业务流程库的规模越大,其相对于图编辑距离的时间消耗就越少,所以本文方法在检索的时间效率上有着不错的优势。本文方法的优势还在于,由于没有采用图编辑距离,从而避免了对图的边和节点处理的编辑操作,这些处理包括节点和边的插入、删除和替换,每个编辑操作代价是通过相应的代价函数得出的,而这些编辑操作的代价函数定义困难,所以本文方法计算起来更简单,也更容易理解。另外,相比于其他方法,还对文本、结构和行为3个方面都进行了分析度量,所以,对于不同场景下的业务流程一样具有很好的度量效果,解决了单一维度下的相似性度量带来的适应能力不足的问题。综上所述,在时间复杂度和准确度方面,本文方法相比于其他度量方法都有更好的效果。
4 结论
为了解决已有流程相似性度量方法存在的一些问题,提高在流程模型库中检索到相似流程的效率,提出一种基于广度优先遍历的加权序列的流程相似性度量方法。该方法同时考虑了多种属性进行流程相似性的度量,首先基于事件日志中的信息构造加权Petri网,然后使用广度优先遍历将加权Petri网模型转换为广度优先遍历序列(BFTS),并且给出了详细的转换规则,再将该序列分为一个带权重的紧邻变迁对集和一个结构序列,最后通过加权这两部分来计算流程之间的相似度值。通过实验对比和分析,提出的方法比其他3种方法有更好的度量准确率以及有着更高的检索效率,可以更加准确地推荐相似流程。但是,方法在计算过程中,还需要提供流程的事件日志,其计算的输入条件相比其他方法更多一些,另外,本文的实验基础是相关领域专家给出的人造数据集,未来的工作主要在于如何将方法运用到实际的大量真实的流程数据集中。
猜你喜欢
电子器件(2021年1期)2021-03-23
无线互联科技(2020年11期)2020-12-01
湖南教育(2017年3期)2017-02-14
贵州工程应用技术学院学报(2016年3期)2016-08-19
东北师大学报(自然科学版)(2016年2期)2016-06-30
华侨大学学报(自然科学版)(2014年4期)2014-10-11
吉林大学学报(工学版)(2014年1期)2014-04-12
燕山大学学报(2014年1期)2014-03-11
测绘科学与工程(2013年6期)2013-03-11
制造技术与机床(2012年3期)2012-09-26
