
基于新闻情感分析和区间分解的汇率预测研究
2024-02-29 08:31刘金培陶志富陈华友
安徽大学学报(自然科学版) 2024年1期
刘金培,储 娜,罗 瑞,陶志富,陈华友
(1.安徽大学 商学院,安徽 合肥 230601;2.安徽大学 大数据与统计学院,安徽 合肥 230601)
汇率波动对国家经济的发展及内外均衡起着决定性的作用[1].受复杂多变的国际经济形势以及持续反复的新冠疫情等多重影响,外汇市场存在大量的不确定性因素.在此背景下,如何构建精确有效的汇率预测模型成为一项重要的研究课题.汇率变化具有连续性和区间关联度特征.点值预测模型难以准确分析汇率的连续波动,而区间数据不仅包含了日内的最大值和最小值,还能刻画变量取值的不确定性和连续变化性[2].因此,基于区间数据的预测模型具有更强的稳定性,对于掌握中国宏观经济的未来发展趋势具有重要的理论价值[3].
现有汇率预测模型主要分为3类:计量经济、人工智能和分解集成模型.传统的计量经济模型[4-7]在处理复杂非线性问题方面存在局限性.而人工智能模型[8-11]虽然在处理非线性时间序列上表现出了相对优越的性能,但也存在过拟合以及参数不确定等问题,且单一模型无法同时提取汇率序列的多尺度特征.依据“分而治之”的思想,分解集成方法成为智能预测领域的主流.Das等[12]提出了基于经验模态分解(empirical mode decomposition,简称EMD)与核极限学习机(kernel extreme learning machine,简称KELM)的汇率预测模型.Huang等[13]使用遗传算法(genetic algorithm,简称GA)对变分模态分解(variational mode decomposition,简称VMD)的参数进行优化,并结合LSTM(long short-term memory)预测美元兑加元汇率等多个金融时间序列.熊志斌[14]利用自适应噪声完备经验模态分解(complete ensemble empirical mode decomposition with adaptive noise,简称CEEMDAN)和LSTM 预测与人民币有关的4种汇率的波动情况.分解集成模型有利于提高汇率的预测精度,然而,传统的数据分解方法仅适用于点值时间序列,会造成区间汇率波动性特征的较大损失.另外,二维经验模态分解(bidimensional empirical mode decomposition,简称BEMD)虽然可以处理非线性、非平稳的区间时间序列,但其分解结果存在上下界混叠的问题.为此,论文提出一种新的区间经验模态分解(interval empirical mode decomposition,简称IEMD)方法,该方法不仅可以实现区间序列的有效分解,而且能够克服分解后区间子序列上下界混叠的问题.
除了上述预测方法的改进,预测因子的选择也会对预测效果产生重要的影响.汇率的预测因子主要包括两类:一类为芝加哥期权交易所波动率(the Chicago board options exchange volatility index,简称VIX指数)[15]、居民消费价格指数[16]和消费者信心指数[17]等经济指标的结构化数据.另一类为基于网络搜索指数和文本的非结构化数据.其中,结构化的预测因子难以提供实时信息,会导致预测结果存在滞后性.在大数据的时代背景下,学者们逐渐将研究视角转向时效性更强的非结构化数据.Lin等[18]发现将百度指数作为预测因子,可以提高美元兑人民币汇率的预测精度.刘金培等[19]从百度指数中提取相关的非结构化数据用于汇率预测,有效改善了预测效果.张杰等[20]引入互联网新闻对汇率进行预测,提高了预测的准确率.孙少龙等[21]通过构建情感词典对在线外汇新闻进行情感分析,实现了模型预测性能的有效提升.上述研究均表明,非结构化数据能够为汇率预测提供更多的有效信息.因此,将海量的新闻文本量化为情感倾向,并与结构化指标相结合,以作为模型的辅助变量,对汇率预测具有一定意义.
此外,汇率还易受到各种不确定重大事件的影响,如欧债危机、英国脱欧[22]、新冠疫情(corona virus disease 2019,简称COVID-19)[23]等.2020年初爆发的COVID-19疫情对全球经济造成了巨大的冲击,外汇市场也不可避免地受到了影响.Feng等[23]通过实证发现COVID-19确诊病例数量的增加会加剧汇率波动.朱宁等[24]研究得出COVID-19会通过影响生产活动和人们的心理预期,改变消费、投资等行为,从而影响人民币汇率.由此可见,COVID-19疫情会引发汇率的异常波动.论文以COVID-19疫情为例,通过引入全球恐惧指数(the global fear index,简称GFI)量化疫情对汇率的影响,以期为重大事件影响下的汇率预测提供借鉴和参考.
综上所述,现有研究存在以下3个方面的问题:①汇率的影响因素复杂,而大多数传统预测研究仅考虑历史数据或结构化指标,无法实时反映市场情绪的变化,导致预测结果存在滞后性.②现有预测模型未能反映新冠疫情等重大事件引起的汇率波动,从而缺乏适用性.③针对汇率区间时间序列,现有多尺度分解方法存在上下界混叠的问题.针对以上问题,论文提出一种基于新闻情感分析和区间分解的汇率波动预测模型.首先引入外汇新闻文本、VIX指数和GFI指标作为汇率的影响因素,并提出一种新的IEMD方法对原始汇率序列进行分解,接着针对不同序列的特征选取合适的预测方法进行组合预测.最后通过4组对比实验验证所提模型的准确性和适应性.
1 模型构建
1.1 恐惧指数(GFI)构建
COVID-19的快速传播造成了巨大的生命损失,疫情爆发给人们带来了明显的恐惧[25].为了反映疫情的影响,论文引入GFI指标[26]来对汇率进行预测,GFI旨在衡量人们对COVID-19的传播和严重程度的日常关注和情绪.
首先,根据每日报告的确诊和死亡病例总人数,计算报告病例指数(reported cases index,简称RCI)和报告死亡指数(reported death index,简称RDI)
然后,根据RCI和RDI计算GFI指标
1.2 区间经验模态分解(IEMD)
为了解决传统经验模态分解(EMD)仅适用于点值时间序列的问题,论文针对区间时间序列,提出一种新的区间经验模态分解(IEMD)方法.
EMD是一种将信号分解为几个本征模态函数(intrinsic mode function,简称IMF)和一个余项的方法[27],主要包括5个步骤:①确定原始序列中的所有局部极值点;②生成上下包络线,用3次样条插值拟合上下包络线,并计算上下包络线的平均值m(t);③从原始序列中减去m(t),得到分量h(t);④判断序列h(t)是否满足IMF的条件,若满足则h(t)就是第一个IMF分量c1(t),若不满足则用h(t)代替原始序列重复步骤1~3,直到满足IMF条件;⑤从原始序列中减去c1(t)得到余项r1(t),将r1(t)作为原始序列重复上述过程,当rn(t)成为单调函数或小于特定阈值时,结束分解过程.
虽然EMD可以有效降低非线性、非平稳数据的复杂性,但它只能实现点值数据的分解.为此,论文在EMD的基础上进行改进,提出可以分解区间时间序列的IEMD方法,具体步骤如下:
(1)将原始区间序列构造成中心-半径形式,即
(3)将半径的趋势分量rn(t)按照等比序列的原则分成m份,分别加减到中心序列的各个分量中,得到区间分解后的上界和下界,从而避免了分解后上下界混叠的问题,即
将剩下的n-1个分量相加,得到汇率残差序列R
(4)此时原始区间序列就被分解成m个区间子序列和1个残差序列,即
论文提出的IEMD分解方法可以实现对区间时间序列的分解,有效降低序列复杂度.另外,该方法能够克服传统区间分解方法存在的上下界混叠问题,以保留原始区间序列的波动特征.
1.3 组合预测方法
由于分解重构后的区间子序列具有不同的尺度特征,论文选择极限学习机(extreme learning machine,简称ELM)、多层感知机(multi-layer perceptron,简称MLP)、随机森林(random forest,简称RF)、二次曲面支持向量回归(quadric surface support vector regression,简称QSSVR)4种单项预测方法对它们进行组合预测.
1.3.1 极限学习机(ELM)
极限学习机(ELM)是一种基于单隐层前馈神经网络架构的快速高效算法[28],它的输入权重和隐藏层偏差是随机选择的,不需要在整个学习过程中进行调整以确定输出权重.ELM 的损失函数可以描述为
其中:N为训练样本数量,L为隐含层的神经元数,βi为隐含层与输出层之间的网络权重,g(x)为激活函数,Wi为输入层与隐含层之间的网络权重,Xj为输入数据,bi为隐含层的阈值,tj为输出数据.
1.3.2 多层感知机(MLP)
多层感知机(MLP)是一种前馈神经网络,它具有高度的非线性映射能力,可以解决复杂的非线性问题.MLP由输入层、隐含层和输出层组成,其中隐含层可以为一个或多个,且层与层之间的关系为全连接.输入层负责接收信号,隐含层负责转换输入值并将信息转发到输出层,输出层根据输入信号以决策或预测的形式计算结果.反向传播算法是训练MLP最常用的学习算法之一.
1.3.3 随机森林(RF)
随机森林(RF)模型是由Breiman[29]提出的一种集成回归算法,其过程如下:
(1)使用Bootstrap抽样方法随机抽取x个样本集,并将这些样本集输入到x颗回归树中进行预测.
(2)对于每颗回归树,随机选择p维变量作为备选分支变量,使用分类和回归树(classification and regression tree,简称CART)算法来训练回归树,直到生成最佳回归树.
(3)计算x个回归树输出的平均值作为RF的最终输出.
1.3.4 二次曲面支持向量回归(QSSVR)
核函数支持向量回归模型能够有效提取复杂序列的非线性特征,但核函数及其参数的选择没有通用的规则,需要耗费大量的计算时间.为克服其缺陷,论文引入无核的QSSVR 模型[30],对训练集,yi∈R进行非线性拟合.QSSVR模型可以在不利用任何核函数的情况下,生成二次曲面,对n个训练点进行有效拟合,其中:(W,b,c)为未知参数,具体形式如下
与经典的SVR模型类似,QSSVR模型的目标是生成一个“管道”,然后试图在这个“管道”中包括尽可能多的训练点.即对于一个给定的δ,首先忽略“管道”内训练点|y-(0.5xTWx+bTx+c)|≤δ的误差,然后,为了在该“管道”中包括尽可能多的数据点,将“管道”边界之间的距离最大化,将“管道”外的数据点的误差ξi最小化.因此,QSSVR模型可以表述为
使得
其中:δ,Cp>0为模型超参数.
在对指标因子以及相关方法的理论性和可行性进行详细阐述的基础上,论文进一步提出了基于新闻情感分析和区间分解的汇率波动预测模型,如图1所示.该模型主要包括4个步骤:

图1 模型框架图
(1)数据提取.首先,从相关网站收集所需的原始数据,包括汇率区间数据、VIX指数、外汇新闻标题、新冠疫情确诊和死亡病例.然后,利用Python自带的第三方库Snownlp对爬取的外汇新闻标题进行情感分析,每条新闻标题对应一个情感分数,分数越接近1表明情感倾向越积极.同时,利用新冠疫情确诊和死亡病例数据构建GFI指标.
(2)区间分解.在分解阶段,由于汇率具有连续变化的特征,为了保留其波动信息,使用IEMD对汇率的原始数据进行区间分解,对其他子序列进行EMD简单分解.然后,基于样本熵对分解后的各子序列进行重构,依次得到对应的汇率数据、VIX指数、情感分数和GFI的高、中、低频区间序列以及汇率残差序列.
(3)组合预测.在预测阶段,将相同频率的区间汇率历史数据和VIX指数、情感分数、GFI作为对应,分别用ELM,MLP,RF和QSSVR对高频序列、中频序列、低频序列和残差序列进行预测.
(4)模型评估.为了验证论文模型的有效性,作者使用区间均方误差(interval mean squared error,简称IMSE)、区间平均绝对误差(interval mean absolute error,简称IMAE)和区间平均绝对百分比误差(interval mean absolute percentage error,简称IMAPE)3种误差评价指标,对汇率区间预测结果进行检验.
2 实证研究
2.1 数据提取
论文选取日度美元兑人民币(USD/CNY)、澳元兑人民币(AUD/CNY)和瑞士法郎兑人民币(CHF/CNY)3种汇率区间数据作为研究对象.所用的数据集包括4个部分:汇率历史数据、VIX指数、外汇新闻标题、新冠疫情确诊和死亡病例数.其中汇率历史数据和VIX指数均来源于Wind金融终端,外汇新闻标题从和讯网的外汇专场板块爬取获得,疫情数据来源于Our World in Data数据网站(https://ourworldindata.org/).样本区间设置为2019年1月1日—2022年10月28日,剔除周末和节假日,共927个区间数据.其中,将2019年1月1日—2022年1月19日的742个数据作为训练集,2022年1月20日—2022年10月28日的185个数据作为测试集.
为了确保数据的可用性,使用Snownlp对爬取的汇率新闻标题进行情感分析,并将相同日期的情感分数取平均,得到每日的情感分数值.同时,根据1.1节的方法构建GFI指标.
2.2 区间分解
该节使用IEMD对3种汇率数据进行区间分解,设置参数q=1/8,得到对应的汇率区间序列和残差序列,同时对其他子序列进行EMD简单分解.然后,通过计算各个序列的样本熵,按照频率高低对分解后的各子序列进行重构,依次得到对应的汇率数据、VIX指数、情感分数和GFI的高频序列、中频序列、低频序列以及残差序列.图2展示了重构后的USD/CNY 区间序列和残差序列.可以看出,重构后的USD/CNY区间序列无上下界混叠,且趋势明显,易于预测.
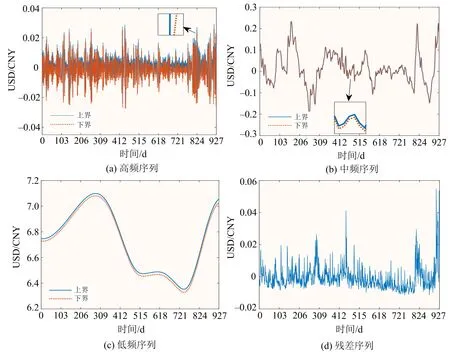
图2 重构后的USD/CNY区间序列与残差序列
2.3 组合预测
将重构后相同频率的VIX指数、情感分数和GFI与汇率区间序列对应,以提前1期的高频序列、中频序列、低频序列和残差序列作为输入变量.进而,分别运用极限学习机(ELM)、多层感知机(MLP)、随机森林(RF)和二次曲面支持向量回归(QSSVR)对高频序列、中频序列、低频序列和残差序列进行预测,对所有子序列的预测值进行组合即可得到最终的区间预测结果.将最终预测结果分别与3种汇率数据的实际值进行对比,上下界的预测效果如图3所示.可见预测值与实际值之间的变动趋势基本一致,模型的预测精度较高.

图3 该模型预测效果图
2.4 模型评估
为了验证论文所提方法的有效性,将论文模型与另外8个相关的预测模型进行比较,采用IMSE,IMAE和IMAPE 3个评价指标进行误差检验,结果如表1所示.
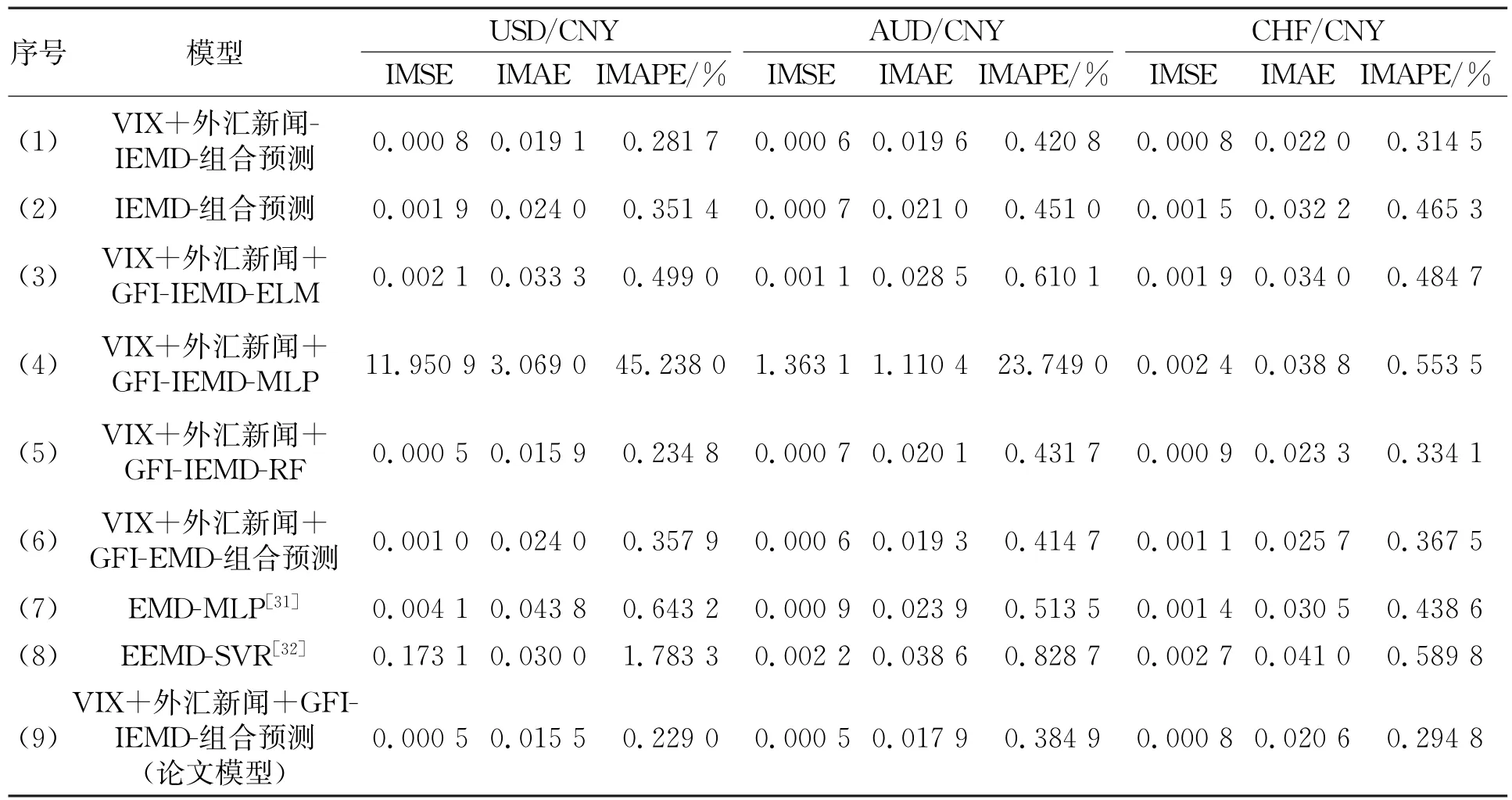
表1 各模型预测误差评价指标对比
(1)与不同影响因素的对比.为了比较不同影响因素对汇率预测的影响,在论文方法的基础上,将论文模型与只考虑VIX+外汇新闻的模型和不考虑任何影响因素的模型进行对比,分别记为VIX+外汇新闻-IEMD-组合预测方法和IEMD-组合预测方法,如表1中(1)和(2)所示.可见,论文所提出的考虑了VIX+外汇新闻+GFI的模型在所有指标下都具有最好的预测效果,体现了该模型的有效性;然后,与未考虑GFI的模型相比,考虑了GFI的模型预测效果更好,这说明将GFI添加到模型中参与预测有助于提高汇率的预测精度;最后,将只考虑了“VIX+外汇新闻”的模型(1)和没有考虑任何影响因素的模型(2)对比,前者预测效果更好,说明将外汇新闻中涵盖的市场情绪量化,并结合VIX指数参与预测,可以有效改善汇率区间序列的预测效果.
(2)与不进行区间分解的对比.将论文提出的IEMD区间分解方法与EMD简单分解方法进行对比,记为VIX+外汇新闻+GFI-EMD-组合预测方法,如表1中(6)所示,表明作者所提出的IEMD区间分解方法可以为汇率预测提供更多的有效信息,从而提高预测精度.
(3)与单项预测方法的对比.基于论文预测模型,对分解重构后具有不同尺度特征的子序列采用单项预测方法进行预测,记为VIX+外汇新闻+GFI-IEMD-ELM 方法、VIX+外汇新闻+GFI-IEMD-MLP方法和VIX+外汇新闻+GFI-IEMD-RF方法.对比结果如表1中(3)~(5)所示.其中,采用MLP进行单项预测的模型误差最高,效果最差.而采用RF进行单项预测的模型效果最好,这体现了单项预测方法的不稳定性.此外,论文模型的各项误差评价指标均明显低于上述3种单项预测方法,这表明对汇率序列进行区间分解和重构,进而根据不同分量的频率特征选择不同的方法对其进行组合预测,能够更有效地拟合序列的变化趋势和细节波动,从而提高预测的准确性.
(4)与已有预测模型的对比.将论文模型与其他预测汇率相关文献中使用过的模型EMD-MLP[27]以及EEMD-SVR[28]进行比较分析,对比结果如表1中(7)和(8)所示,可以看出,论文模型的预测误差要明显低于EMD-MLP和EEMD-SVR模型,体现了论文模型的合理性.
3 结束语
针对汇率数据的高波动性、不确定性特征以及传统区间分解方法存在的缺陷,论文提出了一种基于新闻情感分析和区间分解的汇率预测方法.首先,基于Snownlp情感词典将爬取的外汇新闻标题量化为情绪评分,并利用疫情数据构建GFI指标,与VIX指数一起作为汇率时间序列的影响因子;其次,使用IEMD和EMD分别对汇率区间数据和影响因子进行分解,并根据样本熵重构得到高、中、低频区间序列和一个残差项;然后,将对应频率的汇率区间序列和影响因素序列进行组合,并对不同特征的序列采取合适的预测方法;最后,通过实证对比分析,证明论文模型预测精度较高,对于汇率的突发波动能够及时、准确地进行拟合,适用于疫情冲击下的汇率区间时间序列预测,与已有研究相比具有更高的预测精度和稳定性.
综上所述,该研究具有以下3个方面的优势:①在预测因子上,选取了反映市场情绪的外汇新闻和VIX指数,此外还引入GFI来量化疫情的影响,为重大事件下的汇率预测提供了有效参考.②提出了针对区间序列的分解方法,并取得了良好的预测效果,说明该方法可以为预测提供更多的有效信息,更具现实意义.③在预测阶段,根据不同序列的尺度特征,选取合适的方法对其进行组合预测.对比分析结果表明该方法比单项预测方法更加稳定有效.此外,论文所提出的区间分解方法还可以应用于其他区间时间序列的预测中,如碳价格预测、空气质量预测等.
论文的研究还存在一定的不足,汇率的波动是各种复杂因素综合影响的结果,而论文提出的模型无法涵盖所有的影响因素.因此,在未来的研究中可以考虑加入更多其他的影响因素,以提高汇率的预测效果.
猜你喜欢
中学数学研究(广东)(2023年9期)2023-06-03
中学生数理化·八年级物理人教版(2022年9期)2022-10-24
中国外汇(2019年17期)2019-11-16
中国外汇(2019年13期)2019-10-10
中国外汇(2019年11期)2019-08-27
中国外汇(2019年21期)2019-05-21
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
浙江大学学报(工学版)(2015年11期)2015-03-01
浙江大学学报(工学版)(2015年5期)2015-03-01
浙江大学学报(工学版)(2015年1期)2015-03-01
