
基于信息量-随机森林模型的地震带地质灾害易发性评价:以松潘-较场地震带为例
2024-02-20 09:55刘亚静刘红健
科学技术与工程 2024年1期
刘亚静, 刘红健
(1.华北理工大学矿业工程学院, 唐山 063210; 2.唐山市资源与环境遥感重点实验室, 唐山 063210;3.河北省矿山生态修复工业技术研究院, 唐山 063210; 4.河北省矿业开发与安全技术重点实验室, 唐山 063210)
地震是由地球板块运动引起的地表振动或破坏,会加大海啸、滑坡、崩塌、地裂缝等次生灾害的发生概率[1],地震高发地带往往也成为地质灾害频发区[2]。中国幅员辽阔,东西部位于板块交界地带,地壳活动频繁剧烈,复杂的地质构造为地质灾害发育提供了孕灾条件,导致地震及地质灾害频发[3]。据统计,中国2021年共发生5级以上地震37次,地质灾害4 772起。因此,对地震带灾害多发区进行地质灾害风险监测和评价,了解其空间易发性和控制因素对于制订应对策略以降低风险至关重要。
地质灾害易发性是指在一定地质环境条件下区域发生地质灾害的概率[4],据应急管理部的数据显示,中国69%的国土面积存在较高滑坡、泥石流、崩塌等地质灾害风险,近10年因灾害导致的直接经济损失达4 000多亿元。虽然中国每年在防灾减灾领域投入大量人力物力,但受限于经济发展和技术水平制约,取得效果有限[5]。地质灾害易发风险研究经历了从地球观测数据进行实地调查及制图到基于包括全球定位系统(global positioning system,GPS)、地理信息系统(geographic information system,GIS)、遥感(remote sensing,RS)的3S技术构建地质灾害风险评价体系的发展过程,主要可分为定性研究和定量研究[6]。目前主要的研究模型可分为以层次分析法(analytic hierarchy process,AHP)[7]、证据权[8]、信息量[9]为代表的统计分析模型及以随机森林(random forest,RF)、神经网络(artificial neural network,ANN)[10]、支持向量机(support vector machine,SVM)[11]等机器学习算法为代表的数学分析模型,以地理空间分析技术为载体,应用于地质灾害评价与监测领域[12]。如杨锐等[13]以加权信息量的方法对榆社县的地质灾害易发性进行分析评价;Pei等[14]基于随机森林模型分析了横断山区风险灾害的空间格局及控制因素;Han等[15]基于贝叶斯神经网络模型实现了地震灾害链的危险性制图;丁茜等[16]建立了基于径向基函数(adical basis function,RBF)核的多分类SVM评价模型运用到滑塌易发性分析领域。
由于地质条件的复杂性,地质灾害易发性评价的指标因子难以统一量化,而且传统经验统计分析评价模型在因子定权时大多采取等权或主观判断因子权重的方式,往往导致与因子实际权重不符,无法体现因子与地质灾害间的关联程度,导致最终结果与实际有较大误差[17]。为了修正传统经验模型的局限性,目前大多采用统计分析模型和数学分析相结合的方法,建立综合评价模型来分析灾害易发性,代表性的有随机森林-频率比(RF-FR)模型[18]、信息量-SVM模型[19]、逻辑回归-随机森林(LR-RF)模型[20]等,相比于传统模型,优化的综合评价模型往往具有更高的预测精度[4]。
信息量模型在避免主观判断的基础上能够反映因子对因变量的贡献程度[9],客观地反映评级结果,但其未考虑评价指标权重,无法解释指标对因变量的贡献程度[21]。而随机森林(RF)作为基于集成学习的算法,是目前应用广泛的机器学习算法之一,具有泛化能力强、平衡误差、处理高维数据的优点[22]。因此,在信息量模型基础上,建立信息量耦合随机森林的综合评价模型,以弥补单一模型的局限性。现以四川松潘-较场地震带的平武县为例,选取地形地貌特征、地层地质条件、气象水文、地震带发育特征、土壤植被、人类工程活动影响6个方面的22个影响因子,以信息量模型、信息量-AHP模型、信息量-RF 3种评价模型对研究区地质灾害易发性进行分析,探索适用地震带区域的地质灾害易发性评价方法,从而为当地灾害预测及防治工作提供有效参考。
1 研究区概况及数据来源
1.1 研究区概况
平武县位于四川省绵阳市西北部,地理坐标31°59′31″N~33°02′41″N,103°50′31″E~104°59′13″E;属于四川盆地西北部的盆周山区,位居涪江上游,其地势西北高、东南低,处于中国三大构造域接合部位,中、新生代构造运动强烈,具有典型的山地地貌,主要由近南北走向的岷山山脉、近东西走向的摩天岭山脉和近北东至南西走向的龙门山脉组成,海拔1 000 m以上的山地占辖区面积的90%以上,地势起伏突出,高差悬殊,因地处中纬度地带,地貌受控于地质构造,因此地形地貌多样。气候属于北亚热带山地湿润季风气候,降水充足,气候温和,年平均降水量约866 mm。全县面积约5 950 km2,大部分地区处于松潘-较场地震带,属于地震及地质灾害频发区,近期最严重的是3·16平武7.2级大地震,崩塌、滑坡、泥石流等因斜坡岩土体运动导致的约占地质灾害总数的83%。平武县地理位置及灾害点分布如图1所示。
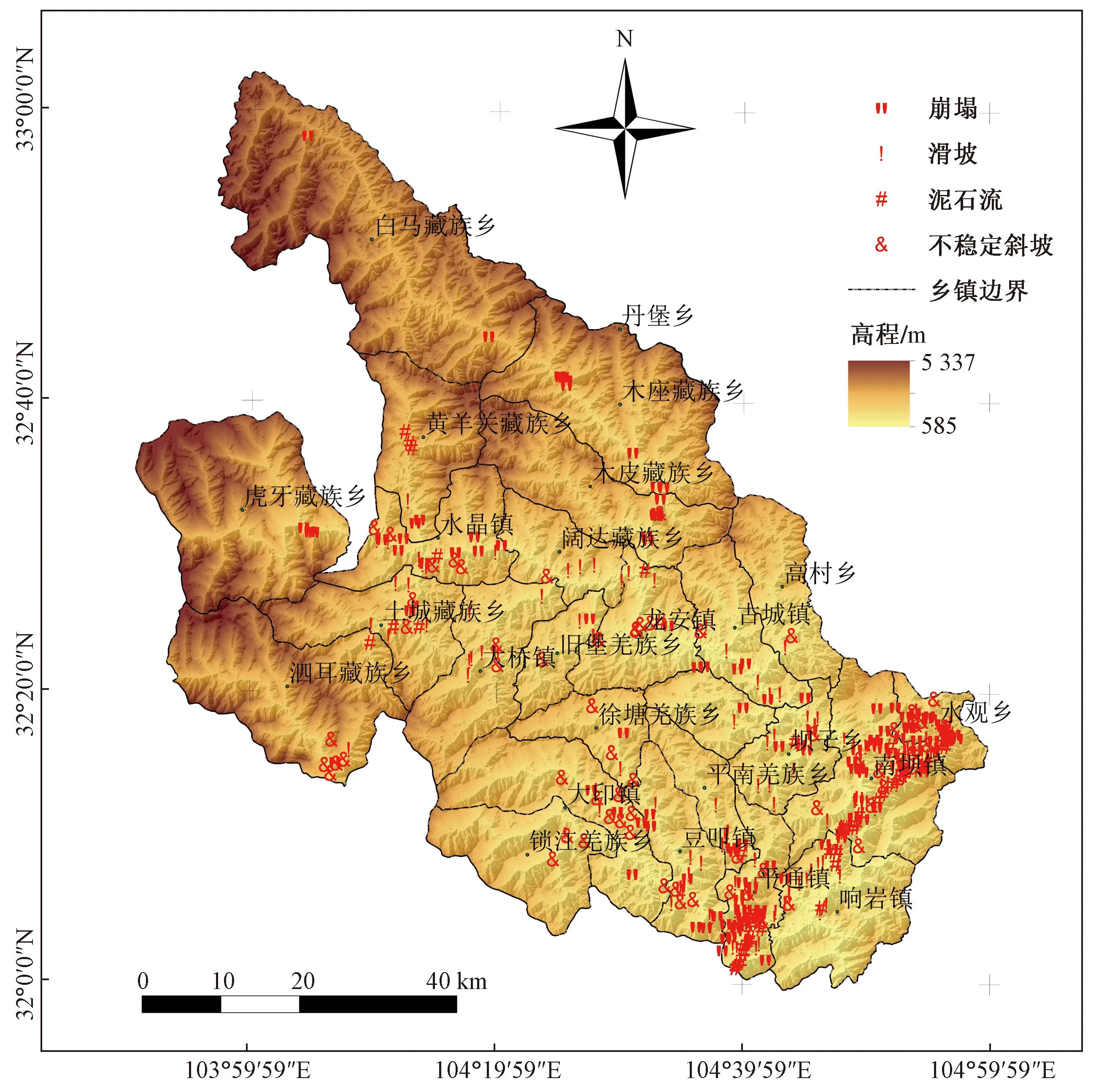
图1 研究区地理位置及灾害点分布Fig.1 Geographical location of the study area and distribution of disaster sites
1.2 数据来源
地质灾害数据来源于中科院资源环境科学与数据中心的地质灾害点空间分布数据;数字高程模型(digital elevation model,DEM)数据来源于国家地理空间数据云的GDEMV3 30 m高程数据集,用以坡度、坡向、剖面曲率、地形粗糙度、地形起伏度、坡向变率、河网及地形湿度指数(topographic wetness index,TWI)等指标因子的提取;降水量、断层分布、地震点历史数据来源于国家地球系统科学数据中心;地震动峰值加速度数据是基于《中国地震动参数区划图》(GB 18306—2015)矢量化制作;土壤侵蚀数据来源于中科院李佳蕾等[23]制作的中国水蚀区土壤侵蚀数据集;地貌类型来源Hartmann等[24]的30 m精度地貌类型栅格数据集;地层岩性数据是由Sayre等[25]的250 m精度栅格数据重采样得到;土壤类型数据来源于中国土壤数据库;精细地表覆盖数据来自刘良云、张肖制作的全球30 m精细地表覆盖产品;路网、兴趣点(point of interest,POI)矢量数据基于网络爬虫获取。
2 研究方法
2.1 层次分析法
层次分析法(AHP)是一种基于多目标决策问题而提出的一种层次权重决策分析方法[26]。根据决策者的经验判断比较确定权重,从而为多目标、多准则或无结构特性的复杂决策问题提供简便的决策方法[27]。
层次分析法被广泛应用于复杂决策分析问题。其核心过程为:根据1~9标度法构造出判断矩阵对评价指标两两进行比较,最终确定各指标因子的相对权重。用一致性比率(CR)来检验判断矩阵合理性,当CR<0.1时,认为判断矩阵一致性较好,即通过一致性检验。其公式为

(2)
式中:λmax为最大特征值;N为唯一非0特征根,即判断矩阵的维数;CI为定义的一致性指标,当CI=0,有完全的一致性,CI接近于0,有满意的一致性;CI越大,不一致越严重;RI为引入的随机一致性指标。
2.2 信息量模型
信息量模型,又称双变量统计模型[17],是以信息论、概率论和数理统计方法为基础,以信息熵的概念通过信息量值表示地灾影响因子的各个指标要素对地质灾害的贡献程度,基于信息值分析地质灾害易发性的模型。通过指标分级,分析各指标因素等级对地质灾害发生的“贡献率”,来判断地质灾害发生难易程度,即I值。当信息量大于0时,表示该地区发生地质灾害的可能性较高;反之,当信息量小于0时,表示该地区发生地质灾害的可能性较低;信息量为0,表示该地区未发生地质灾害,可去除不作为预测要素。其表达式为
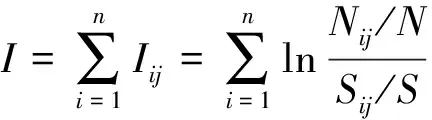
(3)
式(3)中:I为n种评价因子的总信息量值;Iij为第i个评价因子在第j分类下的信息量;Nij为第i个评价因子在第j分类下的地质灾害点数量;Sij为第i个评价因子在第j分类下的评价单元数量;N为该地区地质灾害点总数量;S为研究区内评价单元总数。
2.3 随机森林(RF)模型
随机森林(RF)是由Leo Breiman和Adele Cutler提出的一种基于Bagging思想,根据多决策树进行分类和回归的集成学习算法[28]。其由多棵决策树构成,每棵决策树都取决于独立采样的随机向量值,其原理模型在进行分类预测时会根据N个样本建立N个独立的决策树作为基分类器,并基于Bootstrap抽样算法对初始训练集进行多次抽样,从训练集中有放回地随机抽取,得到N种分类结果,通过每颗决策树对每个记录采用投票方式进行判断选择最优分类结果[29]。其模型公式为
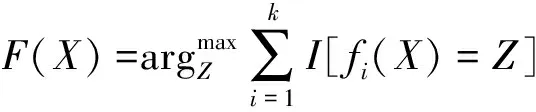
(4)
式(4)中:F(X)为RF模型;fi(X)为某个单独决策树模型;Z为输出变量(目标变量);I为示性函数。
相比于单一决策树,随机森林通过对样本和特征随机采样的方法能够明显提高易发性评价模型的精度和稳定性[30],且对大数据集、多维数据有强大的泛化能力,对异常值和噪声等具有很强的容错率[31],并且每棵树的训练样本及节点的分裂属性均为随机选取,在其交互作用下避免了模型的过拟合效应[32],成为应用最为广泛的机器学习算法之一。
3 评价指标选取及处理
3.1 评价指标单元划分
为了保证评价单元内部的统一性与单元之间的差异性,需要对评价单元继续统一划分,目前常用的方法主要有栅格单元、斜坡单元、子流域单元等[33]。其中,栅格和斜坡单元大多应用于地质灾害的易发性评价中。采用的基础数据比例尺为1∶50 000,根据地质灾害特征及危害范围,在参考前人研究经验的基础上,采取30 m×30 m的栅格单元进行平武县地质灾害易发评价模型,在ArcGIS软件中共划分6 613 214个基础栅格单元,如图2所示。
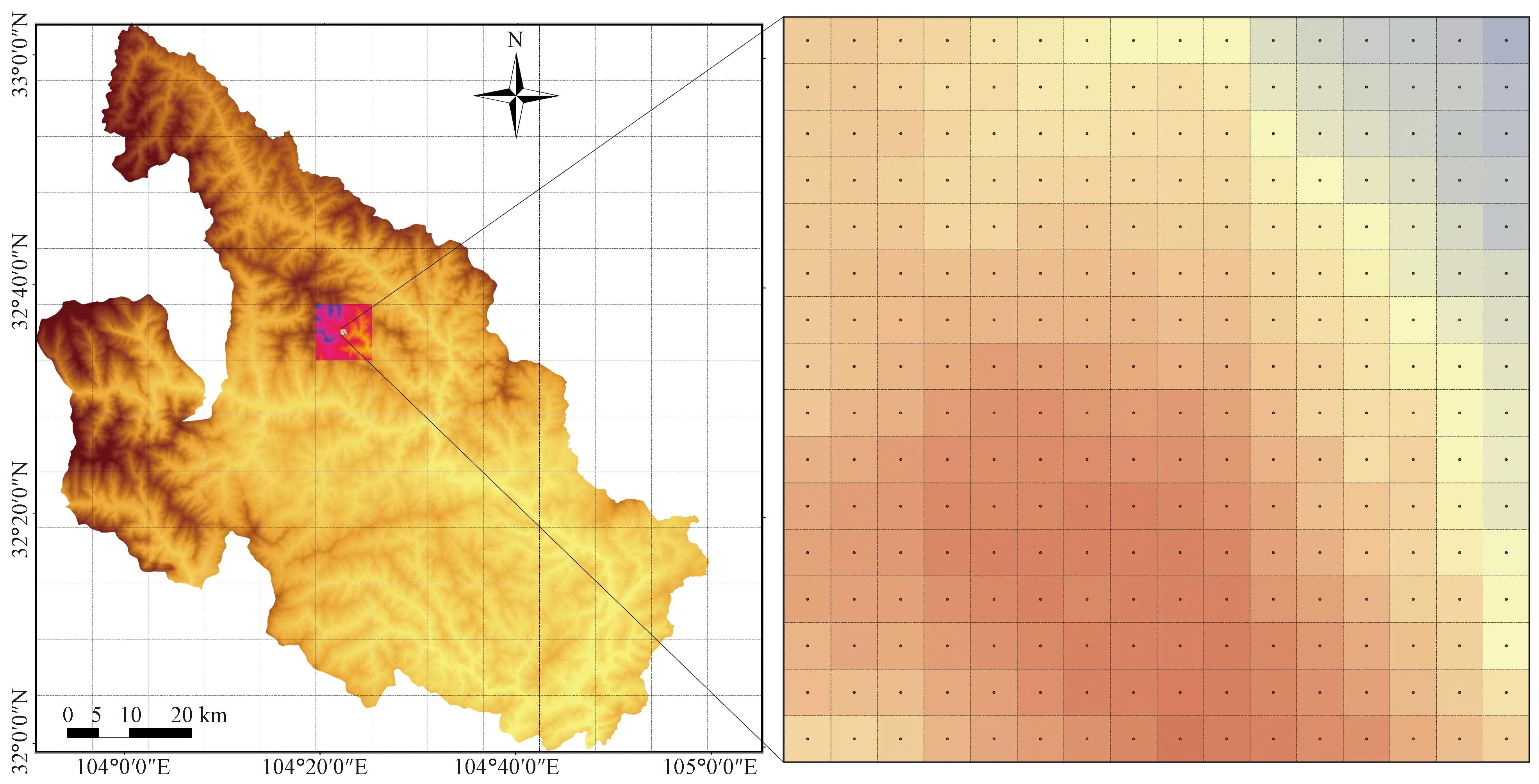
图2 栅格单元划分示意图Fig.2 Grid cell division diagram
3.2 评价指标选取与分级
地质灾害的诱发原因是多种影响因素共同作用的结果,基于平武县孕灾地质条件及人文环境,结合地质灾害发育特征等,主要从地形地貌特征、地层地质条件、气象水文、地震带发育特征、土壤植被、人类工程活动影响等六大控制因素选取指标因子,共计选取22项指标,如图3所示。
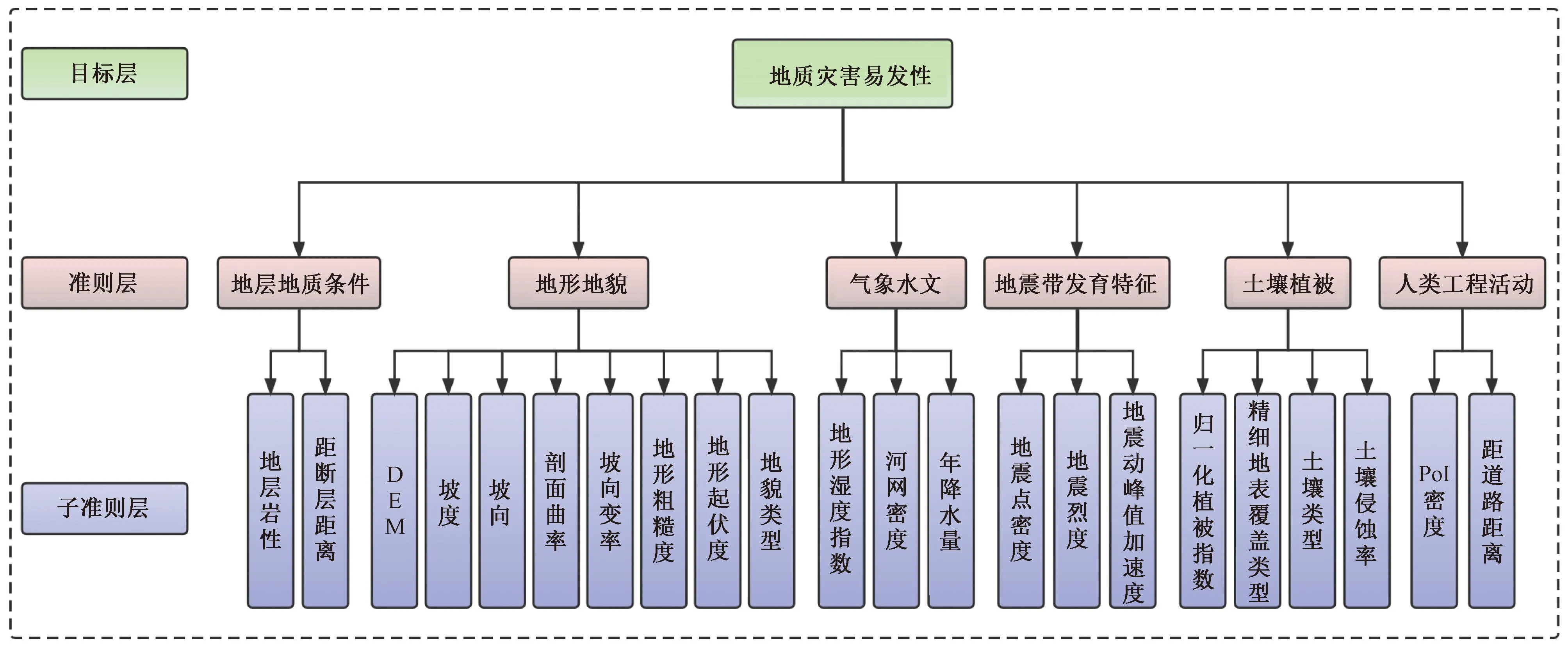
图3 评价指标因子结构图Fig.3 Evaluation index factor structure chart
3.2.1 地形地貌
地形地貌是地质灾害的基础控制因素,主要分为两类,一类以DEM高程数据为基础、基于ArcGIS软件空间分析功能提取坡度、坡向、剖面曲率、坡向变率、地形粗糙度、地形起伏度6类地形因子,用来说明平武县地表区域地形特征。其次为地貌类型分布特征。由图4可知,平武县地势西高东低,最低点与最高点高差达4 752 m,山地沟壑纵横,地表起伏度较大,地貌以中高海拔大起伏山地为主。
3.2.2 地层地质条件
地层地质条件主要包括地层岩性及断裂带分布,是地质灾害发育的重要内在因素,影响灾害的发育程度及规模特征。平武县地层岩性以混合沉积岩和硅质碎屑沉积岩为主,灾害点主要分布在东南部的混合沉积岩地层中。地质构造控制岩层的岩体结构及其组合特征,对地质灾害的发育起综合控制作用,研究以距断层距离来表达断裂带对地质灾害的影响程度,平武县的断裂带主要中部及东部地区,以500 m为步长建立多环缓冲区将距断层距离分为5类,其中,东部地区位于平武-青川断裂带,这一地带灾害点分布较为密集,且主要集中分布在距断层2 000 m范围内。
3.2.3 气象水文
气象水文指标包括地形湿度指数(TWI)、河网密度、年降水量,TWI是指区域地形对径流流向和蓄积影响,能够定量描述区域地表水分的空间分布情况。降水和河流侵蚀作为滑坡、泥石流的主要诱发因素之一,水力冲刷及侵蚀作用加大了灾害发生概率。使用ArcGIS基于DEM数据提取平武县河网分布,并基于核密度分析计算河网密度,平武县年降水量较高,导致其河网水系发达,在起伏较大地区极易发生滑坡和泥石流危害。
3.2.4 地震带发育特征
平武县属于亚欧板块和印度洋板块的分界地带,属于四川境内的松潘-较场地震带,地震及板块运动活跃。选取地震点密度、地震烈度、地震动峰值加速度3个指标体现地震带发育特征对灾害易发性的影响。通过地震点密度体现地壳活跃程度对地表微型变化的影响。地震烈度作为衡量地震强度的重要指标,用来说明地震对地表及工程建筑物等的影响程度,而地震加速度值是指地震时地面运动的加速度,用作辅助确定烈度的依据。平武县历史地震点的震源中心大多集中在东南部,地震点密度和地震烈度也显著高于西北部地区,其分布特征与地质灾害分布呈现相似性。
3.2.5 土壤植被
植被覆盖能有效降低产流产沙量,减少径流量,改善土壤理化性质,提高土壤抗侵蚀能力,与土壤协同提高地表水土保持能力,降低滑坡、泥石流灾害等发生概率。土壤植被指标主要包括归一化植被指数(normalized difference vegetation index,NDVI)、精细地表覆盖类型、土壤类型、土壤侵蚀率。根据图4、图5的分布特征可知,平武县NDVI平均值为0.84,整体植被覆盖水平较高。境内土壤类型主要有黄棕壤、暗棕壤、黑毡土等,以黄棕壤为代表的壤土约占总面积的87.15%。不同植被对水土的保持能力不同,其地表覆盖类型以常绿阔叶林、落叶阔叶林为主,地质灾害主要集中在以森林为主体的不透水表面、水体附近。土壤侵蚀是指土壤在水力、风力等外力作用下,被破坏、剥蚀和搬运的过程,土壤侵蚀速率体现出单位面积时间内的土壤侵蚀程度,平武县土壤侵蚀率较高的地区集中在西北至东南的走廊地带以及东南地带的龙门山脉地带。
3.2.6 人类工程活动
人类工程活动包括兴趣点(POI)密度和距道路距离,频繁的工程建设活动会改变斜坡应力状态及降低边坡稳定性,平武县以山地为主,频发的崩滑流灾害对道路安全性具有重大威胁,伴随其多雨气候极易产生不稳定斜坡增加危险性。以平武县路网分布为基础,根据灾害体影响程度,与断裂带采取相同的分类方法以500 m步长为分类标准建立缓冲区,研究区POI高密度区集中在中部及东南部,其中,东南部为灾害集中区。
3.3 指标相关性分析
为了避免因子间多重共线性对评价模型的复合影响,从而降级预测精度,对选取的22个评价指标进行相关性分析,以剔除相关性较高的因子。当因子相关性绝对值系数大于0.5时,相关性较强,即认为因子间存在多种共线性,应剔除该因子;反之,因子相关性绝对值系数小于0.5,即相关性较低,因子间基本不会相互影响,可用于模型的预测分析。根据相关性分析结果可知,地形粗糙度、地形起伏度与坡度,距道路距离、地貌类型与DEM,年降水量、精细地表覆盖类型与地震动峰值加速度的相关性均大于0.5,因此,将DEM、地形粗糙度、地形起伏度与地震动峰值加速度4项指标剔除,最终得到18项指标进行地质灾害易发性评价分析。
4 地质灾害易发性评价及对比分析
4.1 基于信息量模型的易发性评价
利用信息量模型将各评价因子状态划分,将数值连续状态因子分为十级,其余因子根据各分级统计计算各评价因子各分级状态的信息量,信息量数值越大表示对地质灾害发生的影响程度越高,计算得到各指标因子各等级的信息量值,叠加得到栅格对于地质灾害的总信息量值,将结果归一化后根据概率比值按照自然间断分级划分为极高、高、中、低和极低5个易发区等级,如图6所示。

图6 基于信息量模型的灾害易发性分区图Fig.6 Disaster susceptibility partition map based on information volume model
4.2 基于信息量-AHP模型的易发性评价
在信息量模型的基础上,采用层次分析法(AHP)根据专家打分对18个因子进行重要性排序, 根据构造的判断矩阵计算各指标因子权重,一致性检验结果CR=0.033<0.1,一致性检验通过,对信息量进行加权叠加。同上将结果归一化后采用自然间断法将AHP-信息量模型结果分为5类等级,如图7所示。

图7 基于信息量-AHP模型的灾害易发性分区图Fig.7 Disaster susceptibility partition map based on information-AHP model
4.3 基于信息量-RF模型的易发性评价
平武县共395处地质灾害点,在此基础上,随机选取3倍于地质灾害点的1 185个非地质灾害点作为反向训练样本,根据随机森林模型的分类要求,将发生过地质灾害的其余划分为一类,记为“1”,未发生过地质灾害的其余划分为另外一类,记为“0”,以此将地质灾害易发性研究问题转变为二分类问题。共计1 580个训练样本,在划分基础数据集为训练集与测试集的过程中,训练集与测试集的比率划分不恰当会影响模型的预测精度,因此参考相关文献研究,将样本集按照7∶3的比例划分,即选取70%的样本点作为训练数据,30%的样本点作为测试数据。经过模型训练并获取各指标因子的客观权重,经预测得到信息量-RF模型的易发性预测结果,同上分为5类,如图8所示。
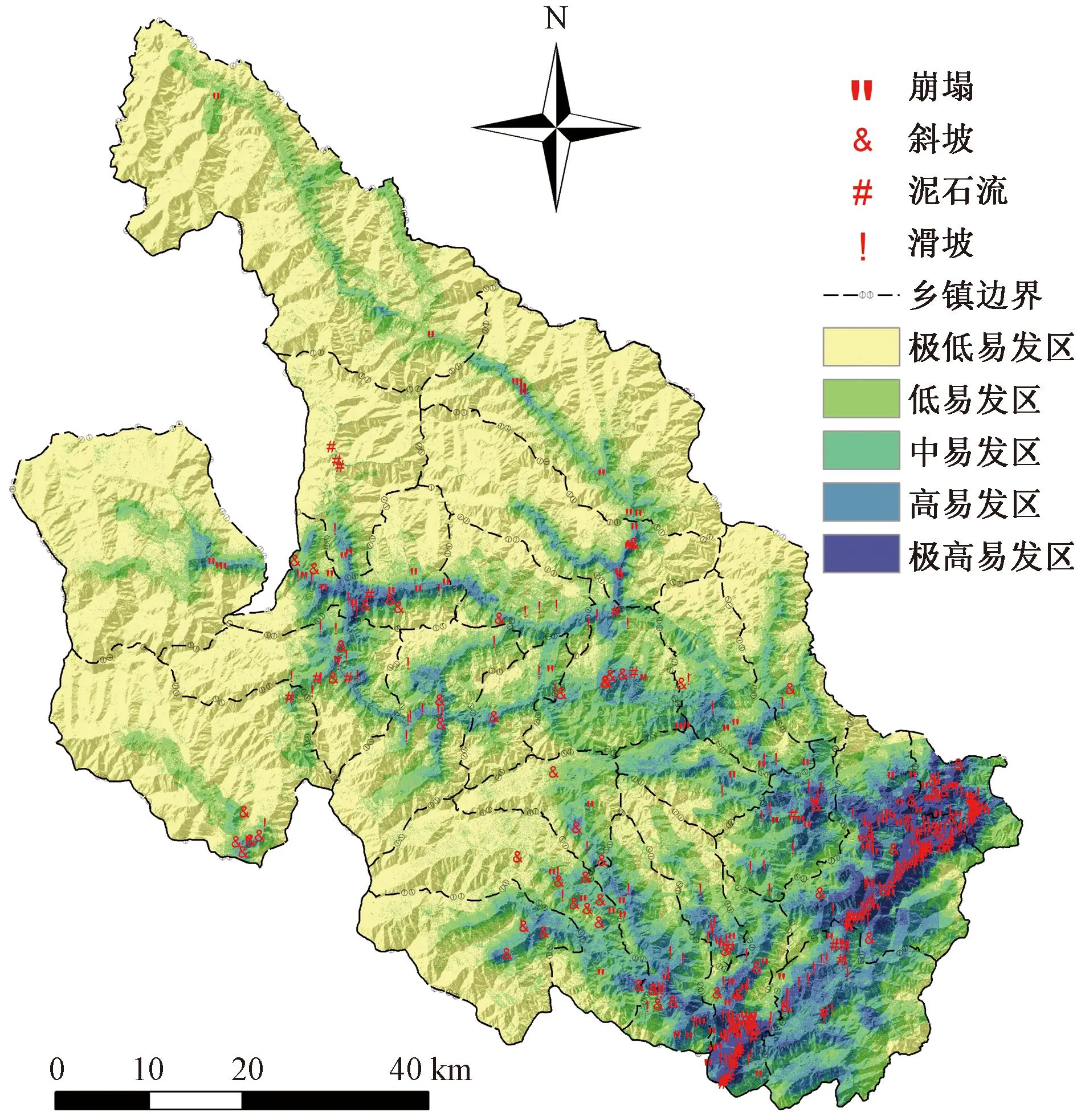
图8 基于信息量-RF模型的灾害易发性分区图Fig.8 Disaster susceptibility zoning map based on information volume-RF model
AHP与RF都对指标因子的重要性进行分析,两种模型的因子重要性对比如图9所示。由图9可知,AHP分析的因子重要性前三位为距道路距离、地震烈度、地震点密度,RF对训练样本分析的因子重要性前三位为地震点密度、土壤类型、距道路距离,地震点密度和据道路距离作为两种方法公认的高贡献指标,能更好地描述平武县典型山地区地形因素对崩滑流等灾害的诱发条件,RF模型分析的因子贡献率两极分化较为明显,前五项指标的客观权重达71.37%,AHP分析的因子权重呈现梯度下降的趋势,并未出现断崖式差距。
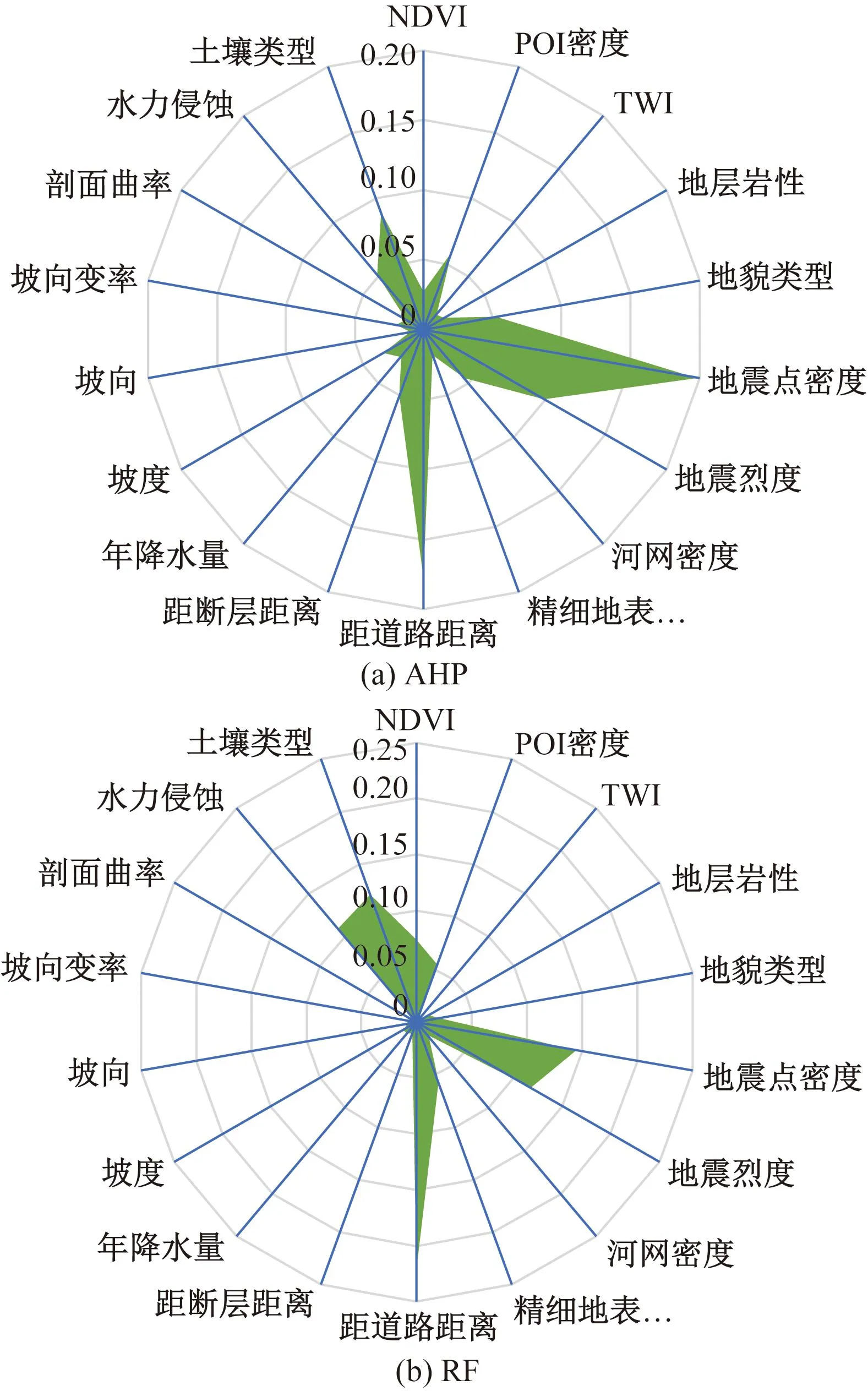
图9 AHP与RF指标因子重要性比对Fig.9 Comparison of importance of AHP and RF index factors
4.4 模型对比分析
从3种模型的结果可知,其地质灾害易发性分区呈现出相似的空间分布,极高易发区主要分布在东南部的水观乡、南坝镇、响岩镇等地,以及在中部以龙安和古城镇为中心向周围分散的条带分布,大部分极高易发区属于高山河谷地带,涪江的支流水系贯穿此地,暴雨和洪水灾害较多,其引发的泥石流、滑坡也较为集中,其次,龙门山断裂带贯穿此地,地震频发导致的地表运动剧烈也是重要的诱发原因,应对此地重点防治及监测。高易发区重要集中在极高易发区的边缘地带,以坝子乡、豆叩镇、大印镇分布最广,大多位于断裂带边缘,地质灾害较为集中,可作为次防治区观察。总体上平武县的地质灾害易发特征表现为西北低风险、东南高风险及中部条带性的聚集性分布,但相较于另外两种评价模型,信息量-RF模型的极高和高易发区范围较小,地质灾害点分布密度也更为聚集。为更直观进行对比分析,对3种模型的分类结果进行分区统计,结果如表1所示。
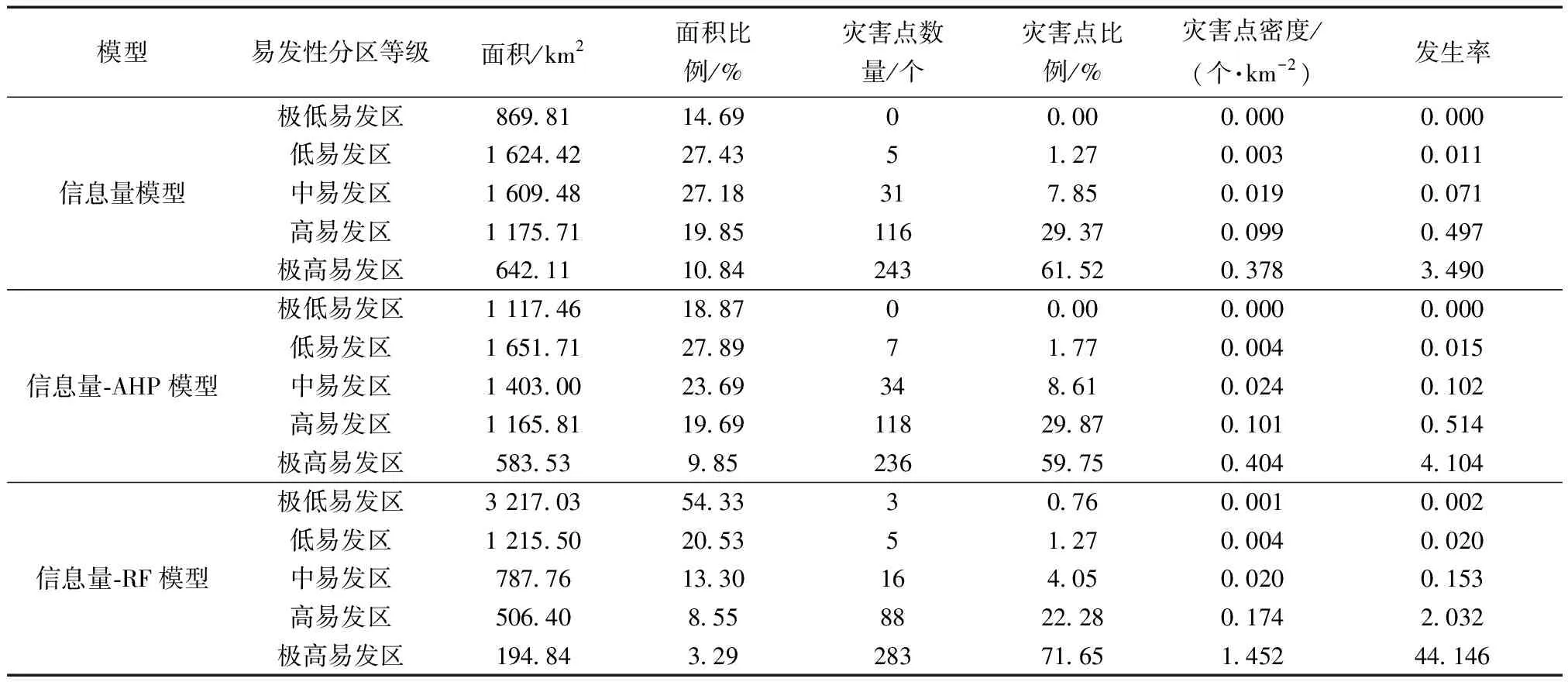
表1 分区统计结果
从对比结果来看,信息量-RF模型预测的高易发区和极高易发区面积分别为506.40 km2和194.84 km2,面积综合占比为11.84%,低于信息量模型的30.70%和信息量-AHP模型的29.54%;信息量-RF模型的高易发区含有88个灾害点,占比22.28%,灾害点密度为0.174 个/km2,极高易发区含有283个灾害点,占比71.65%,灾害点密度为1.452 个/km2,高和极高易发区共包含了总灾害点的93.92%,灾害点占比与其余两种模型接近,但从灾害点密度对比结果分析来看,信息量-RF模型要显著优于另外两种模型,尤其在极高易发区,这种差异更为明显。灾害发生率体现了模型预测的相对准确性,发生率越高,说明地区灾害点更为集中,发生地质灾害的相对概率也更大,对防治区划等级划分具有重大作用。信息量-RF模型预测的高易发区和极高易发区的发生率分别为2.032和44.146,要明显高于信息量模型(0.497,3.490)和信息量-AHP模型(0.514,4.104),信息量-AHP模型经过加权优化后,相比于等权评价的信息量模型,其灾害点密度、灾害发生率要优于信息量模型,但这种提升是有限的。从整体结果来看,3种模型分区结果符合灾害点分布特征,高和极高易发区都解释了约90%的地质灾害分布,而相比于等权信息量评定,经专家打分修正权重的信息量-AHP模型对比分析结果要略优于信息量模型,但相比于信息量-RF,其无论在灾害集中程度,分区的精确程度均优于其余两种模型,但其在极低易发区存在极少的灾害点数量,可能是对指标进行了过度拟合,导致与实际结果不符,在划分防治区划,应合理地进行人为规避,整体来看,信息量-RF模型的评价结果精准度较高,满足预期。
4.5 模型预测精度评估
为了进一步检验易发性评价模型的准确度和预测能力,采用受试者工作特征曲线(receiver operating characteristics,ROC)对3种模型的预测性能进行检验,以曲线下的面积(area under curve,AUC)对模型进行评价。AUC表示曲线下方与坐标轴围成的面积,其中,X轴为假阳性率,即1-特异性,表示非灾害点被错误预测的概率;Y轴为真阳性率,即敏感性,表示灾害点被正确预测的概率,曲线越靠近左上角,面积越接近于1,说明模型分类的准确率越高,预测结果越正确。如图10所示,信息量模型、信息量-AHP模型、信息量-RF模型的的AUC值分别为0.920、0.931和0.991,信息量-RF模型的预测精度高于其余两个模型,说明基于信息量耦合随机森林的综合易发性评价模型比单一信息量模型、信息量-AHP模型更适用于预测类平武县的地质灾害易发性。
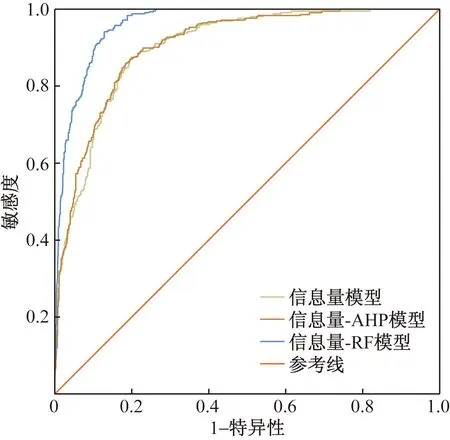
图10 ROC曲线评价模型对比Fig.10 Comparison of ROC curve evaluation models
5 结论
以松潘-较场典型地震带的平武县为例,充分考虑孕灾地质环境因素,从地形地貌特征、地层地质条件、气象水文、地震带发育特征、土壤植被、人类工程活动影响6个方面选取了22项地质灾害的诱发因子,采用信息量模型、信息量-AHP模型、信息量-RF模型对平武县地质灾害进行易发性评价,得出结论如下。
(1)从分区统计对比结果来看,信息量-RF模型的高和极高易发区的灾害点密度和灾害发生率最高,信息量-AHP模型次之,信息量模型最差,说明采用信息量-RF的分类结果更具有针对性,能够增加灾害防治效率,有针对性地作出预测,防治成本较小。
(2)ROC精度分析结果显示,信息量-RF模型的AUC值为0.991,高于信息量模型(0.920)和信息量-AHP模型(0.931),说明基于信息量耦合随机森林的综合易发性评价模型比单一信息量模型、信息量-AHP模型更适用于预测类平武县的地质灾害易发性,具有较高的准确性、稳定性以及良好的预测功能。
猜你喜欢
体育时空(2022年7期)2022-06-07
中国药学药品知识仓库(2022年9期)2022-05-23
大众科学(2022年5期)2022-05-18
今日农业(2021年10期)2021-11-27
今日农业(2021年1期)2021-03-19
四川地质学报(2020年2期)2020-05-31
西南交通大学学报(2018年5期)2018-11-08
新闻传播(2016年11期)2016-07-10
计算机工程(2015年4期)2015-07-05
武夷学院学报(2014年5期)2014-07-19
