
可解释的视觉问答研究进展
2024-02-18 14:16张一飞孟春运蒋洲栾力ErnestDomanaanmwiGanaa
计算机应用研究 2024年1期
张一飞 孟春运 蒋洲 栾力 Ernest Domanaanmwi Ganaa


摘 要:在视觉问答(VQA)任务中,“可解释”是指在特定的任务中通过各种方法去解释模型为什么有效。现有的一些VQA模型因为缺乏可解释性导致模型无法保证在生活中能安全使用,特别是自动驾驶和医疗相关的领域,将会引起一些伦理道德问题,导致无法在工业界落地。主要介绍视觉问答任务中的各种可解释性实现方式,并分为了图像解释、文本解释、多模态解释、模块化解释和图解释五类,讨论了各种方法的特点并对其中的一些方法进行了细分。除此之外,还介绍了一些可以增强可解释性的视觉问答数据集,这些数据集主要通过结合外部知识库、标注图片信息等方法来增强可解释性。对现有常用的视觉问答可解释方法进行了总结,最后根据现有视觉问答任务中可解释性方法的不足提出了未来的研究方向。
关键词:视觉问答; 视觉推理; 可解释性; 人工智能; 自然语言处理; 计算机视觉
中图分类号:TP391 文献标志码:A 文章编号:1001-3695(2024)01-002-0010-11
doi:10.19734/j.issn.1001-3695.2023.05.0181
Research advances in explainable visual question answering
Abstract:In the context of visual question answering (VQA) tasks, “explainability” refers to the various ways in which researchers can explain why a model works in a given task. The lack of explainability of some existing VQA models has led to a lack of assurance that the models can be used safely in real-life applications, especially in fields such as autonomous driving and healthcare. This would raise ethical and moral issues that hinder their implementation in industry. This paper introduced various implementations for enhancing explainability in VQA tasks and categorized them into four main categories: image interpretation, text interpretation, multi-modal interpretation, modular interpretation, and graph interpretation. This paper discussed the characteristics of each approach, and further presented the subdivisions for some of them. Furthermore, it presented several VQA datasets that aimed to enhance explainability. These datasets primarily focused on incorporating external know-ledge bases and annotating image information to improve explainability. In summary, this paper provided an overview of exis-ting commonly used interpretable methods for VQA tasks and proposed future research directions based on the identified shortcomings of the current approaches.
Key words:visual question answering; visual reasoning; explainability; artificial intelligence; natural language processing; computer vision
0 引言
随着深度学习技术的不断发展,作为深度学习两大领域——计算机视觉(CV)和自然语言处理(NLP)的交叉领域之一的视觉问答任务(VQA)[1,2]逐渐兴起。VQA指的是给定一张图片和一个与该图片相关的自然语言问题,计算机能输出一个正确的回答。显然,这是一个融合了CV與NLP技术的多模态问题,计算机需要同时学会理解图像和文字。正因如此,直到2015年相关技术取得突破式发展,VQA的概念才被Antol等人[1]正式提出。
视觉问答是一种涉及计算机视觉和自然语言处理的学习任务。这一任务的定义如下:一个VQA系统以一张图片和一个关于这张图片形式自由、开放式的自然语言问题作为输入,以生成一条自然语言答案作为输出。简单来说,VQA就是根据给定的图片进行问答。视觉问答可以被应用于在线教育、盲人辅助导航、视频监控自动查询等领域,但是由于现有深度学习模型大部分缺乏可解释性,当模型出错时,用户无法理解为什么会出错和如何避免,这导致模型在某些关键领域的使用可能会危害人的生命安全。所以这些先进的技术在生产中落地时,常常会面临伦理道德乃至法律层面的问题。例如,最近的欧洲通用数据保护和法规(general data protection and regulation,GDPR)引入了这样一种观点,即用户应该拥有获得由自动化处理提出的决策的解释的权利[3]。但是用现代机器学习方法,尤其是基于深度学习的方法,很难满足这样的要求。因此,为了提高深度学习模型在生产实践中的安全性问题和解决由于深度学习的“黑盒”特性带来的伦理道德以及安全问题,提高视觉问答模型的可解释性十分必要,所以大量的研究试图通过对深层神经网络的决策过程生成人类可理解的解释,使其更加透明。
大多数最先进的VQA系统[4~8]都是通过训练,使用问题和视觉特征简单地拟合答案分布,并在简单的视觉问题上实现高性能。然而这些系统往往可解释性一般,因为它们只关注简单的视觉特征和问题特征,而不是为正确的原因找到正确的答案[9,10]。当问题需要更复杂的推理和常识知识时,类似的低可解释性问题就变得越来越严重。本文的主要贡献如下:a)综述了视觉问答任务中的各种可解释方法的特点,将解释模型的方法划分为视觉解释、文本解释、模块化解释、图解释和多模态解释,并且对其中的一些大类又进行了细分,最后综合分析了现有方法的优点和不足,并提出了改进的方向;b)介绍了VQA任务中涉及可解释性的数据集,讨论了不同数据集的区别,并对如何利用数据集来提升可解释性提出了建议;c)讨论了VQA任务中可解释性的发展情况以及未来展望,并对文中介绍的视觉问答可解释性方法提供了建议。
1 可解释性方法发展历程
1.1 基本定义
可解释性目前没有数学定义,Miller[11]认为可解释性是人类理解决策原因的程度;Kim等人[12]认为可解释性是人类可以一致地预测模型结果的程度。可解释性可以翻译为interpretable或explainable,一开始这两个词经常互换使用,因为翻译成中文是同一含义,即对模型的输出结果可以产生合理的解释。然而Miller[11]认为,这两个词在学术上有细微的差别:interpretable是指本就透明的白盒模型,其本身就可以解释输出的答案,所有经验水平的使用者都可以明白模型的含义;而explainable是指研究人员对黑盒模型的输出结果作出人们能理解的解释。本文所讨论的可解释性是指包含这两种概念的更加广义的可解释性,所以不再另外区分。
1.2 可解释性方法
从目前已有的可解释性方法来看,可解释性方法可以分为事后可解释方法和构造本质上可解释的模型的方法。事后可解释方法可以理解为通过观察模型的输出结果或隐层状态来研究输入的相关特征与模型输出结果之间的因果关系。构造本质上可解释的模型则可以让模型把内部推理过程以白盒的方式直观地呈现给人类,因为其本质上推理流程就容易被人理解所以无须使用显著图等事后可解释方法。本文所讨论的视觉问答中的可解释性方法都可以归类到上述两种可解释方法中,并且在最后给出了一些与视觉问答可解释性相关的数据集。
2 视觉问答任务中的可解释方法分类
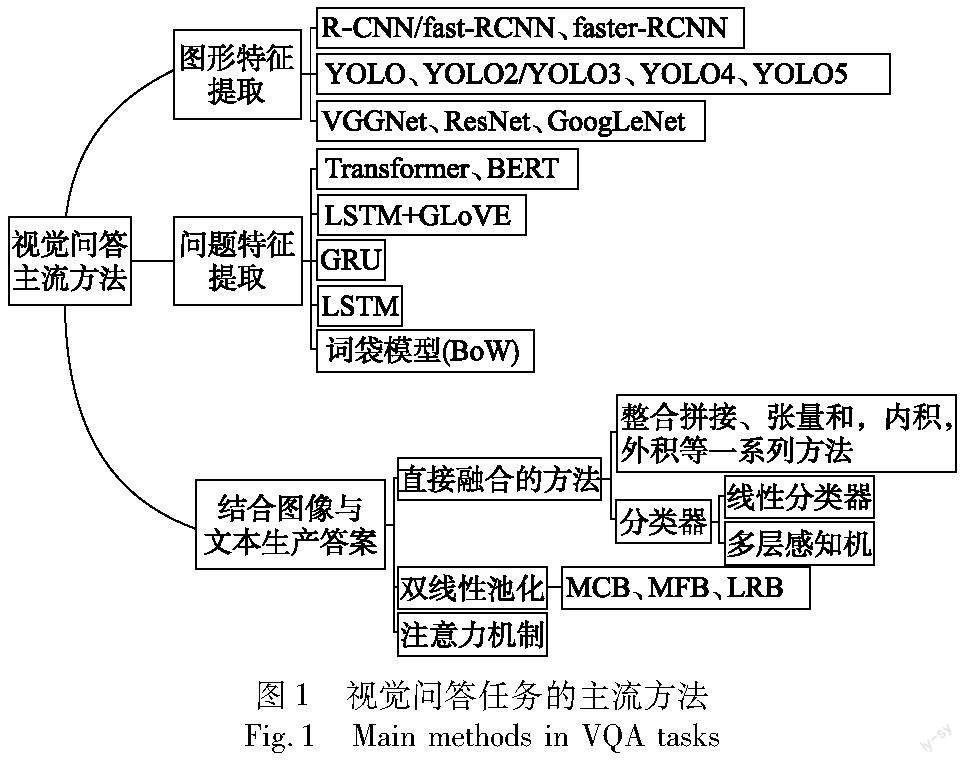
解释的视觉问答任务可以定义为:给定一个图像或视频V和一个问题Q,模型预测答案A并且给出相应的解释E。本文根据智能问答与视觉推理中的可解释性的实现方式将视觉问答中的可解释模型分为图像解释、文本解释、多模态解释、模块化解释和图解释。视觉问答(VQA)任务当前主流方法主要是首先提取问题和图像特征,然后结合融合图像和文本特征进行分类,最后得到答案。如图1所示,视觉问答任务涉及对输入图像和输入问题的处理,当考虑视觉问答中的可解释方法时,主要从文本和图像的可解释性方面去考虑。
此外,一些其他视觉问答的处理方法也具有可解释性,如可解释的模块化神经网络和一些结合图神经网络和外部知识库的方法等,对这些方法的详细分类如图2所示。本文提出的分类方法从视觉问答任务本身的特性去考虑,只考虑视觉问答模型中的可解释性问题,除去了一些传统机器学习中使用的并且与视觉问答任务无关的可解释方法。具体来说,在图像解释方法中,讨论了基于注意力的图像解释方法、区域掩模方法和基于梯度的方法,在文本解释方法中,讨论了图像描述法和外部知识库法。此外还讨论了一些与常规图像解释和文本解释不同的解释方法,这些方法包括多模态解释方法、模块化推理方法和包含图像图和问题图的图解释方法。
2.1 利用图像解释的方法
图像解释的方法主要是通过探究图像的整体或部分特征和推理结果之间的关系来达到解释模型输入与输出之间关系的目的。图像解释的方法可以大体分为基于注意力的图像解释方法、利用区域掩模的方法和基于梯度的方法三类。
2.1.1 基于注意力的图像解释
注意力模块不仅可以提取细粒度和精确的二元关系,还可以提取更为复杂的三元关系。这两种与问题相关的视觉关系提供了更多更深层次的视觉语义,从而提高了问题回答的视觉推理能力。此外,该模块还结合了外观特征和關系特征,有效地协调了两类特征。
目前,大多数VQA算法都专注于通过使用普通的VQA方法将注意力机制应用于关注相关的视觉对象,或通过视觉关系推理中现成的方法来考虑对象之间的关系,然而,它们仍然有一些缺点:a)它们主要对对象之间的简单关系进行建模,由于未能提供足够的知识,导致许多复杂的问题无法正确回答;b)它们很少利用视觉外观特征和关系特征的交互。为了解决这些问题,Peng等人[5]提出了一种新的端到端VQA模型,称为多模态关系注意力网络(MRA-Net),是一个旨在提高性能和可解释性的模型,通过提取二元和三元关系来实现。MRA-Net包括三个模块:(a)自引导词关系注意模块用于提取隐含的语义关系知识,为推理过程提供支持,它能够自动学习并捕捉不同对象之间的关系,并生成语义关系图;(b)对象注意模块用于识别与答案最相关的对象,帮助模型更好地理解问题;(c)可视化关系注意模块利用两个支持问题提取对象之间的细粒度二元和三元关系,通过识别对象及其关系,该模块能够提供深刻的视觉语义,从而提高视觉推理的可解释性。这些模块的组合使得MRA-Net能够在推理任务中表现出更好的性能,并提供可解释的结果。
Ben-Younes等人[6]提出了一种基于双线性体系结构的VQA模型MUTAN,通过融合视觉和文本信息来进行视觉推理。该模型引入了基于多模态张量的塔克分解,不仅能控制视觉和文本特征之间双线性交互的复杂性,还能保持良好的可解释性。Wang等人[7]提出了一种基于注意力的加权上下文特征(MA-WCF)的VQA任务系统,该系统使用基于RNN的编码器-解码器结构提取语义上下文特征,并使用基于MDLSTM的编码器-解码器结构提取图像上下文特征。具体来说,系统中的RNN结构被选择为双向LSTM结构[8]。这个多模态系统可以根据问题和图像本身的特征以及其上下文特征分配自适应权值从而产生更好的效果。由此可见,注意力机制在VQA任务中有广泛的应用,它有助于关注视觉信息和文本信息的兴趣领域。为了正确回答问题,模型需要有选择地瞄准图像的不同区域,这表明基于注意力的模型可能会从明确的注意力监督中受益。由于缺乏人类注意数据,Qiao等人[9]首先提出了人类注意网络(HAN)来生成类人注意地图,在人类注意数据集(VQA-HAT)上进行训练;然后,将预先训练好的HAN应用于VQA v2.0数据集,自动生成所有图像问题对的类人注意地图,为VQA v2.0数据集生成的类人注意图数据集被命名为类人注意(HLAT)数据集;最后,将类人注意监督应用到一个基于注意的VQA模型中。实验证明,添加类人监督可以产生更准确的关注和具备更好的性能。
虽然如此,获得特定于视觉基础的人类注释仍是困难和昂贵的,Zhang等人[10]提出了一种具有视觉定位监督的VQA架构,该架构的注意区域定位可以从可用的区域描述和对象注释中自动获得。他们的工作表明,视觉问答模型使用这种监督训练生成的视觉区域定位,相对于人工注释的定位获得了更高的相关性,同时实现了最先进的VQA精度。陈婷等人[13]提出了一种问题文本特征引导图像的视觉问答算法,该算法在问题特征提取过程中通过对关键词的筛选加强对问题中有效信息的关注,实现对问题的注意;同时,该算法还增强了对图像属性特征的关注,使得图像信息更加丰富。通过问题强化和图像强化,该算法引导视觉问答模型在推理过程中根据问题信息更有效地关注于图像中的关键区域,而图像中的关键区域又为推理过程提供了依据和解释。
基于注意力机制的视觉解释只能显示与推理结果相关的视觉区域,但不能解释如何利用这些区域来推导出结果。在组合推理任务中,视觉解释很难表达不同推理链接之间的逻辑关系。此外,当前视觉推理模型中注意力机制产生的参与图像区域通常与人类注意机制[14]不同,这也限制了推理模型的有效性。
2.1.2 区域掩膜方法
区域掩膜类型的方法主要通过区域掩码和对象去除对图像进行语义编辑,从而识别图像中与问题和答案相关的对象并进行相应的推理过程解释,这实际上是一种基于扰动的视觉解释,扰动的视觉可解释性可以定义为:a)保留解释,为了保留模型的原始输出,图像中必须保留的最小区域;b)删除解释,为了改变模型的原始输出,图像中必须删除的最小区域。Fong等人[15]提出了一种模型不可知和可测试的解释方法,该方法可以学习一个扰动掩膜,通过有意义的扰动输入的图像找到对分类输出分数影响最大的区域。与其他图像显著性方法不同,该方法显式地编辑图像,以达到可解释的目的。Liu等人[16]在CLEVR[17]的基础上构建了用于理解指称表达式的诊断数据集CLEVR-Ref+,并在文献[18]的基础上提出了一种用于视觉推理的神经模块网络IEP-Ref。IEP-Ref中的分割模块使用LSTM生成器将引用表达式转换为一系列结构化模块,每个模块由一个小CNN参数化。执行IEP-Ref可以生成优秀的分割掩膜,清晰地揭示网络的推理过程,从而使模型拥有更强的可解释性。
大多数基于区域掩膜的可解释VQA模型过于依赖相关性进行推理,而且容易产生虚假的相关性。因此,Agarwal等人[19]提出了一种语义视觉变异方法,采用基于GAN的再合成模型[14]去除图像中的目标,检验模型预测的一致性。删除对象有两种情况:a)删除与问题无关的对象,答案保持不变;b)移除问题中涉及的对象,答案就会以可预测的方式改变。被移除的对象以基于扰动的方法为推理过程提供了可解释性。与基于注意力机制的视觉解释类似,语义编辑也无法解释如何使用这些对象来派生结果,难以表达不同推理步骤之间的逻辑关系。
2.1.3 基于梯度的方法
图像一般是通过向量方式表示,即一张图片可以表示为{x1,…,xn,…,xN},假设图片有一个对应的类别yk,现在每次给图片的某个像素加入一个δx,那么对应的类别yk就会发生变化,记为yk+δx。如果想要知道每個像素的扰动对最终结果的影响,就需要计算δx/δy,通过计算每一个像素点对预测类别的影响可以绘制出显著图,通过观察显著图可以判断不同像素点对预测类别的影响,显著图亮度越高的区域对预测结果的影响最大,这就是基于图像的可解释性方法的概念。在VQA模型中,梯度方法就是利用每个图像中的某些区域的损失梯度为VQA模型提供解释。
显然,基于梯度的方法需要用到显著性方法,关于显著性方法,Simonyan等人[20]讨论了两种基于输入图像计算类分数的梯度的可视化技术:a)类模型可视化(class model visualisation)方法,给定一个学习好的分类ConvNet网络和一类感兴趣的类别,可视化方法包括数值生成一个图像,再根据ConvNet类评分模型代表该类;b)图像特定的类显著性可视化(image-specific class saliency visualisation)方法,这种方法计算特定于给定图像和类的类显著性映射,这种映射可以用于弱监督对象的分类分割。这两种方法都是基于批次梯度下降法的方法。Shrikumar等人[21]提出了DeepLIFT(deep learning important features),一种通过将网络中所有神经元对输入的每个特征的贡献反向传播来分解神经网络对特定输入的输出预测的方法。DeepLIFT将每个神经元的激活与其“参考激活”进行比较,并根据差异分配贡献分数。通过选择性地单独考虑积极和消极的贡献,DeepLIFT也可以揭示其他方法所遗漏的依赖关系。
以上两种方法的缺点是违反了Sundararajan 等人[22]提出的灵敏度和实现不变性公理,所以Halbe[23]尝试使用集成梯度(IG)用于可解释性。IG根据网络的预测计算输入特征的属性,这些属性将输入特征的信用/责任分配给输入特征(图像时的像素和问题时的单词),这些特征负责模型的输出。这些属性可以帮助识别模型的准确性,如过度依赖图像或可能的语言先验,它们是根据一个基线输入来计算的。此外,Selvaraju等人[24]提出了一种用于从基于卷积神经网络(CNN)的大类模型中生成决策的可视化解释的方法Grad-CAM,使用任何目标概念的梯度,流入最终的卷积层,生成一个粗糙的本地化地图,突出显示图像中用于预测概念的重要区域。Grad-CAM使用特定于类的梯度信息来定位重要区域。这些定位与现有的像素空间可视化相结合,创建了一种新的高分辨率和类鉴别性可视化,称为引导Grad-CAM。这些方法有助于更好地理解基于CNN的模型,包括图像字幕和VQA模型。Grad-CAM为理解基于CNN的模型提供了一种新的方法,将Grad-CAM与现有的细粒度可视化相结合,创建了一个引导式Grad-CAM模型,为图像描述和VQA提供视觉解释。
最近,利用在原始数据中生成反事实图像来增强可解释性的方法也利用到了以上基于扰动和梯度的方法。例如,Boukhers等人[25]引入了一种通过生成反事实图像的可解释性方法。具体来说,生成的图像是导致VQA模型给出一个不同的答案且与原始图像相比变化最小的,此外,他们的方法确保了生成的图像是真实的。由于不能使用定量指标来评估所提出模型的可解释性,他们通过用户研究来评估方法的不同方面。梯度方法可以识别正确的结果是否取决于简单视觉推理中错误的原因,然而,这类方法的缺点是只能显示与推理结果相关的视觉区域,但不能解释如何利用这些区域来推导出结果。
常用的图像解释模型在VQA v1和VQA v2上准确率的对比如表1所示,可以看出MA-WCF在两个数据集上分别以6.16%和8.44%的准确率优于其他模型。这是因为MA-WCF作为一种注意加权上下文特征的可解释的多模态系统,相比于其他模型,可以根据问题和图像的重要性为其上下文特征赋予自适应权重。实验结果表明了合理利用上下文特征信息对提升视觉问答模型准确率的重要性。
2.2 利用文本解释的方法
VQA系统需要有正确的理由才能很好地推广到测试问题。虽然视觉解释[26]只标记图像的哪些部分对答案贡献最大,但文本解释[27]能编码更丰富的信息,如详细的属性、关系或常识知识,这些信息不一定全都能在图像中直接找到。VQA系统中的文本解释方法主要分为使用自然语言生成技术生成图像描述的方法和利用外部知识库的方法。
2.2.1 图像描述法
图像描述法是指用自然语言来描述指定图像中的视觉信息。现有的方法可以分为基于模板的方法和基于神经的方法。基于模板的方法利用计算机视觉的最新进展来检测视觉元素,如对象、关系和位置,然后通过使用预定义的语言模板来转换这些元素。Farhadi等人[28]提出了一个图像描述的自动方法,它可以计算一个连接一个图像到一个句子的分数。通过比较图像的意义估计和句子的意义估计来获得分数,此分数可用于将描述性句子附加到给定的图像上,或者获得说明给定句子的图像。Kulkarni等人[29]提出的图像描述方法由两部分组成:a)内容规划,通过从大量的视觉描述性文本池中挖掘出的统计数据,对基于计算机视觉的檢测和识别算法的输出进行平滑,以确定用于描述图像的最佳内容词;b)表面实现,根据自然语言的预测内容和一般统计数据,选择单词来构建自然语言句子。基于神经网络的方法大部分使用CNN对视觉信息进行编码,并使用RNN解码对图像的文字描述。Mao等人[30]提出了一个多模式递归神经网络(mRNN)来生成新的图像描述。它直接模拟了生成一个单词和一个图像的概率分布。图像描述是根据此分布而生成的。该模型由句子的深度递归神经网络和图像的深度卷积网络组成,这两个子网络在一个多模态层中相互作用,形成整个mRNN模型。Xu等人[31]将注意力机制引入到图像描述中,通过引入一个基于注意力的模型可以自动学习描述图像的内容,通过使用标准的反向传播技术和随机地以确定性的方式训练这个模型,并通过最大化变分下界。
利用自然语言处理的方法从图片中生成文字信息并用作解释开始是被Li等人[32]提出作为对答案的解释的,但是Li等人提出的VQA-E模型没有把对答案的解释本身作为信息在推理过程中加以利用,所以Cai等人[33]在此基础上首先利用该模型中的图像处理方法提取图像中的目标信息,将其与文本信息相结合,并在结合过程中使用协同注意力机制而不是VQA-E模型中只关注图像,然后将解释与问题信息相结合输入到LSTM系统中。他们的方法丰富了视觉问答中的文本信息,提高了答案的准确性。与普通的协同注意力机制不同,Hendricks等人[34]提出了一种更具鉴别性的方法,重点关注可见对象的鉴别属性,联合预测一个类标签并解释了为什么预测的标签适合于图像,他们还提出了一种基于抽样和强化学习的新的损失函数,来学习生成实现全局句子属性的句子。视觉解释突出了决策背后的关键图像区域,然而它们并不能解释推理过程和突出显示的区域之间的关键关系,文本解释恰恰弥补了这一缺点。
2.2.2 利用外部知识库法
当人类看到一个图像时就可以自动推断出图像中隐藏的视觉之外的东西,比如物体的功能、物体的状态等。然而要实现这种功能对计算机来说是非常困难的,例如,关于吹风机可以用来干什么的问题,不仅需要在图片中识别出吹风机,而且还需要知道吹风机可以用来吹头发。想要让计算机实现这种类似的功能需要引入外部知识库。
在VQA模型中引入外部知识库的方法有很多。Wang等人[35]构建了一个FVQA数据集、一个附带的数据集以及从三个不同来源提取的事实知识库,即WebChild[36]、DBpedia[37]和ConceptNet[38];同时还开发了一个模型,利用支持事实中存在的信息来回答有关图像的问题,他们的方法不是直接学习从问题到答案的映射,而是学习从问题到KB查询的映射,所以它更可扩展到答案的多样性。该方法不仅给出了视觉问题的答案,还提供了得出答案的支持事实,从而增强了推理过程的可解释性。文献[35]实际上是关键字匹配技术,从问题中提取关键字,并从知识库中检索包含这些关键字的事实。显然,在这种方法中同义词和同构词容易带来误解,为了解决这个问题,Narasimhan等人[39]开发了一种基于学习的检索方法,该方法学习了事实和问题图像对到嵌入空间的参数映射。为了回答一个问题,使用了与提供的问题-图像对最一致的事实。基于神经网络的模型的缺陷是对于自然语言部分需要进行训练,模型难以调试,并且因为神经网络的“黑盒”性质导致缺乏可解释性。为了应对这类问题,Basu等人[40]提出了AQuA框架,AQuA不存在所有纯基于神经网络方法中的缺陷,通过结合常识知识和使用ASP进行推理来复制人类的VQA行为。AQuA框架中的VQA使用了以下知识来源:使用YOLO算法提取的对象的知识、从问题中提取的语义关系、从问题中生成的查询、常识知识。AQuA运行在查询驱动的、可扩展的答案集编程系统上,该系统可以提供一个证明树作为正在处理的查询的理由。AQuA会将问题转换为ASP查询而无须任何培训,密切地模拟了人类的操作方式。
利用外部知识库增强可解释性的方法在一些用来模拟人类应对可解释性问题的方法中也有应用,因为人类在解决问题时会自然而然地利用外部知识。Riquelme等人[41]提出了一个VQA模型,该模型将处理模块集成到模拟人类视觉注意、利用先前的视觉知识开发外部来源,以及用自然语言提供解释来支持每个答案。这三个处理模块模拟了人类解决VQA问题的方式:将注意力集中在与回答每个问题相关的图像区域的能力;使用适当的背景知识,如常识知识,构建合适的答案的能力;用连贯的解释支持答案的能力。
现有的基于知识的视觉问答的解决方案的一个限制是,它们联合嵌入了各种信息而没有细粒度的选择,这将引入意想不到的噪声来推理正确的答案。如何捕捉以问题为导向、信息互补的证据,一直是解决这一问题的关键挑战。Yu等人[42]提出了一种基于图的循环推理网络GRUC,用于需要外部知识的视觉问题回答,侧重于图结构多模态知识表示的跨模态知识推理。本文从视觉、语义和事实观点的多个知识图中描述了多模态知识来源。引入高级抽象的语义图对基于知识的视觉问答模型带来了显著的改进,该模型通过对多个模块进行多次叠加进行传递推理,在不同模式的约束下得到面向问题的概念表示;最后利用图神经网络,综合考虑所有概念推导出全局最优解。Wang等人[43]也提出了一种与GRUC类似的方法VQA-GNN,通过统一的像素级信息和概念知识进行联合推理。给定一个问题-图像对,VQA-GNN从图像中构建一个场景图,从知识图谱中检索一个相关的语言子图,从VisualGenome中检索一个视觉子图,并将这三个图和问题统一到一个联合图,即多模态语义图;然后,VQA-GNN学习聚合消息,并在多模态语义图捕获的不同模态之间进行推理。该方法提供了跨视觉和文本知识域的可解释性。
以上方法的局限性是,从纯文本的知识库捕获的相关知识只包含事实表示的一阶谓词或语言描述,而缺乏复杂的、但不可或缺的多模态知识的视觉理解。基于此,Ding等人[44]提出了用一个显式三元组表示多模态知识的MuKEA将视觉对象和事实答案与隐式关系关联起来。该方法首先提出了一种用显式三元组表示多模态知识单元的新模式,将问题所涉及的视觉对象嵌入到头部实体中,将事实答案的嵌入保留在尾部实体中,通过三元组显式关系表达头部与尾部之间的隐性关系。该方法提出了三个客观损失函数,通过对比正负三元组、对齐真值三元组和提炼实体表示,从粗到细学习三元组的表示。在此基础上,提出了一种基于前训练和微调的学习策略,从域外和域内的VQA样本中逐步积累多模态知识,用于可解释推理。
本文在VQA v2、FVQA和OK-VQA数据集上对比了上文讨论的利用文本解释的视觉问答模型的准确率,对比结果如表2所示。其中E-Q-I模型是作为利用图像描述法增强可解释性的方法之一,在VQA v2数据集上取得了最佳结果。该方法利用协同注意力机制使模型同时关注于图像和文本信息。同时,模型中的问题信息与生成的解释信息相结合,丰富了视觉问答中的文本特征信息,提升了模型的准确率。GRUC作为一种图推理视觉问答方法,在基于知识的FVQA数据集上取得了最高准确率,该模型通过基于记忆的递归推理网络收集面向问题的视觉和语义信息,相比其他模型得到了显著的改进。MuKEA在OK-VQA上的准确率超过了GRUC,因为该模型相比其他方法在利用外部知识进行推理的过程中考虑了多模态知识和现有知识库的互补信息,同时该方法通过采用预训练和微调学习策略逐步积累基本知识和特定领域的多模态知识,用于答案预测。总之,使用基于外部知识的VQA模型,不仅使模型能理解数据集中的外部信息,还增强了模型的可解释性。
2.3 多模态解释
与单一的视觉解释方法和文本解释方法不同,目前多模态解释在VQA模型中主要是结合图像解释和文本解释的方法,先利用注意力机制定位图像中的关键区域,然后再对关键区域生成文本解释。Park等人[27]提出了一个视觉推理模型指向与推理模型(PJ-X)来生成多模态解释。PJ-X模型在回答了VQA问题后会为答案生成文本解释,生成的文本解释能指出图片中支持答案的区域,PJ-X通过注意掩模指向图片中支持解释的证据。因为缺乏包含人类为决策作出的解释的数据集,Park等人还提出了两个数据集ACT-X和VQA-X。Park等人的方法也有不足,他们实际上采用了一种“事后理由”的形式,并沒有真正遵循和反映系统的实际处理,Wu等人[45]认为解释应该更忠实地反映底层系统的实际处理过程,以便让用户对系统有更深入地理解并且出于正确的原因增加信任,而不是试图简单地说服他们相信该系统的可靠性,所以Wu等人提出了一种更可信任的方法。为了忠实,文本解释生成器只关注于一组有助于预测答案的对象,并只从与实际VQA推理过程一致的标准解释中得到适当的监督而且方法中的解释模块直接使用了VQA参与的特征,并通过GradCAM训练生成可追溯到相关对象集的解释。
与以上方法不同,Zhang等人[46]提出了一种融合了图推理的多模态解释方法,具体来说,该方法采用预先训练的语义关系嵌入的多图推理与融合(MGRF)层来同时推理位置和语义关系,并自适应地融合这两种关系。MGRF层可以进一步深度堆叠,形成深度多模态推理和融合网络(DMRFNet),以充分推理和融合多模态关系。多模态解释方法能结合其他各种单一解释方法的优点,并且推理过程中指向解释证据的方式更加贴近于人类。邹芸竹等人[47]提出了一种基于多模态深度特征融合的视觉问答模型,该模型利用卷积神经网络和长短时记忆网络分别提取图像和文本的特征;然后通过使用元注意力单元组合构建的深度注意力学习网络,实现了图像和文本之间以及模态内部的注意力特征交互学习;最后,将学习到的特征进行多模态融合表示,并进行推理预测输出。该方法使用了自注意力和交互注意力这两种元注意力单元。通过单层内两次递进的跨模态特征交互,实现了图像特征和文本特征相互指导注意力权重的学习。这些学习到的注意力权重为模型输出的答案提供了解释。
表3对比了DMRFNet和CDI-VQA方法,DMRFNet相比CDI-VQA准确率提升了20.67%。DMRFNet设计了一种有效的多模态推理和融合模型,以实现细粒度的多模态推理与融合。具体而言,该方法通过多图推理与融合层MGRF,该层采用预先训练好的语义关系嵌入,对视觉对象之间复杂的空间关系和语义关系进行推理并自适应融合。MGRF层可以进一步进行深度叠加,形成深度多模态推理融合网络,充分推理和融合多模态关系。
2.4 模块化推理方法
所谓模块化推理方法,就是将模型分解成神经网络子模块,每个模块的功能各不相同。在智能问答与推理中,模块化方法能让人类更好地理解答案是怎么产生的,从而增强模型的可解释性。Andreas等人[48]在2015年首次提出了基于神经模块网络的新模型架构(NMN),如图3所示,这个架构将问题解析为语言子结构,并将较小的模块组装成特定于问题的深度网络,每个模块解决一个子任务。这种架构使得使用联合训练的神经模块集合回答关于图像的自然语言问题成为可能,这些模块可以动态地组装成任意的深度网络。然而,Andreas等人提出的NMN实现依赖于脆弱的现成的解析器,并且仅限于这些解析器提出的模块配置,而不是从数据中学习它们;所以随后Hu等人[49]在2017年提出了端到端模块网络(N2NMN)。它可以通过在没有解析器帮助的情况下直接预测特定实例的网络布局来学习推理,将文本问题中提出的复杂推理问题分解为几个连接在一起的子任务,并学习使用序列对序列RNN实现的布局策略预测每个问题合适的布局表达式。在训练过程中,该模型可以首先从专家布局策略中通过行为克隆进行训练,并使用强化学习进一步进行端到端优化。以上的模块化网络首先分析问题,然后预测一组预定义的模块,每个模块实现为一个神经网络,这些模块连接在一起来预测答案。然而,他们需要一个专家布局,或监督模块布局来训练布局策略,以获得良好的准确性。Hu等人[50]在2018年又提出了进一步优化的模块化网络结构Stack-NMN,可以在没有布局监督的情况下进行训练,并用基于堆栈的数据结构替换布局图。该模型同时解决了这两个任务,利用相关任务应该共享共同的子任务,并在任务之间共享共同的神经模块集。与以前的模块化方法相比,该模型诱导将推理过程分解为子任务,同时不需要专家的布局监督。该模型可以通过一系列软模块选择、图像注意和文本注意来解释其推理步骤。
与以上单一的模块化推理方法不同,Shi等人[51]提出了一种融合了图推理的模块化方法XNMS。如图4所示,XNMS将对象作为节点、对象关系作为边来构成场景图进行可解释推理。XNMS包括AttendNode、AttendEdge、Transfer和Logic四个模块。Ren等人[52]将神经网络模块应用于定性推理,从而增强了模型的可解释性,具体来说,他们使用端到端的神经网络来模拟预测和比较这两个推理任务,每个推理链都包含多个神经模块,为理解和推理过程提供透明的交互预测。
表4对比了四种模块化推理方法,其中NMN模型是模块化推理方法的先驱,该方法通过执行每一个子模块来获得推理过程中间步骤的结果。N2NMN在NMN的基础上通过直接预测实例特定的网络布局来学习推理,无须解析器的帮助,该模型在学习生成网络结构的过程中同时学习网络参数。Stack-NMN与以上两个方法的不同之处在于,该方法通过自动诱导期望的子任务分解来执行组合推理,而不依赖于强力的监督。该方法允许通过共享的模块来连接不同的推理任务,不同的子模块会处理任务之间的通用例程。XNMS模型超越了现有的神经模块网络,使用场景图作为结构化的知识进行可解释推理,该模型仅由四个元模块网络构成,相比之前的方法大大减少了网络的参数量。
总而言之,模块化方法就是通过把神经网络模型分解成一个个子模块来达到增强模型可解释性的目的。在具体实验过程中,还可以与一些其他可解释性方法结合,如文本解释和图解释等,从而使模型的可解释性更强。
2.5 利用图解释的方法
在视觉问答与智能推理中,图解释方法主要是通过把问题中的图像和问题分解为图结构来进行推理从而增强模型的可解释性。这种解释方法主要分为图像图和问题图两种类型。具体来说,图像图通过检测目标,把目标物体作为节点,目标物体之间的关系作为边来构造图;问题图通过解析VQA任务中问题的语义信息,包括对象的属性、关系等来建模图结构。与端到端的黑盒模型相比,加入圖形结构的网络可以直观地为答案提供更多的解释信息。
2.5.1 图像图
基于图像图的图解释方法主要通过图像中目标对象的信息、关系来生成图结构,从而为推理过程提供解释。Norcliffe-Brown等人[53]提出了一种基于图解释的VQA模型。该模型中的图形学习器学习以问题为条件的图像的图形表示,并对场景中对象之间的相关交互进行建模。该模型可以学习图像的图结构表示,然后利用学习到的图结构来学习更好的图像特征。Li等人[54]提出了一种关系感知图注意网络ReGAT,它将每个图像编码成一个图,并通过图注意机制建模多类型的对象间关系,以学习问题自适应关系表示。ReGAT利用了两种类型的视觉对象关系:一是表示对象之间几何位置和语义交互的显式关系,二是捕捉图像区域之间隐藏动态的隐式关系,通过图的注意来学习一个关系感知的区域表示。Guo等人[55]从图的角度重新考察了VQA任务中的双线性注意网络。经典的双线性注意网络建立了一个双线性注意图来提取问题中单词与图像中对象的联合表示,但缺乏对复杂推理中单词之间的关系的充分探索。相比之下,Guo等人开发的双线性图网络来建模单词和对象的联合嵌入的上下文。图像图学习问题中的单词与图像中对象之间的图,生成它们的联合嵌入,而问题图对单词之间的图进行建模,以交换上下文信息。图像图将检测到的对象的特征传输到它们相关的查询词中,使输出节点能够同时具有语义和事实信息。问题图从图像图中在这些输出节点之间交换信息,以放大对象之间隐式而重要的关系。这两种图相互合作,因此模型可以建模对象之间的关系和依赖关系,从而实现多步骤推理。
邹品荣等人[56]提出了一个场景关系视觉问答模型,通过关注于图像中实体间的语义关系和空间位置关系来分别生成语义关系图和空间关系图,然后利用图注意力神经网络学习自适应问题的视觉关系区域表示,学习到的关系区域表征最终被送入自注意单元和引导注意单元生成跨媒介的语义特征用以分类输出答案。该方法在推理的过程中显式地提供了图像中物体间的空间位置关系和语义关系,为模型推理出的答案提供事实依据作为解释。张昊雨等人[57]提出了一种基于图结构的级联注意力模型,用于捕捉不同候选框区域图像的空间信息以及与问题之间更高的层次关系。該模型使用单词嵌入和递归神经网络提取文体特征。对于图像表示方法,使用候选框坐标和相应的图像特征向量来构建成对描述符特征。这些文本特征和图像组合特征被输入到图学习模块,用于学习一个邻接矩阵。该邻接矩阵使得空间图卷积不仅关注图像中的目标对象,还关注与问题最相关的对象关系。在空间图卷积的输入中,除了来自学习模块的邻接矩阵,还包括从极坐标函数获取的空间信息。融合了空间图卷积和文本特征的特征向量被输入到后续的深度级联层网络,最终通过预测层给出分类答案。总体来说,该方法引入了新的关系编码方式,可以对图像区域各个对象之间的关系进行空间建模,以此来揭示更加细粒度的图像概念,从而为模型提供一个整体的解释。
与以上只通过图像信息生成图像图的视觉问答方法不同,兰红等人[58]提出了一个问题引导的空间关系图推理视觉问答模型QG-SRGR用于处理图像图数据。该模型通过引入问题信息的引导实现了基于问题的空间关系推理。模型利用问题引导的聚焦式注意力,分为节点注意力和边注意力,用于发现与问题相关的视觉对象和空间关系。通过节点注意力和边注意力的权重,构造了门控图推理网络。该网络利用信息传递机制和控制特征信息的聚合,获得节点的深度交互信息,从而学习到具有空间感知的视觉特征表示。通过这种方式,模型能够实现基于问题的空间关系推理。该方法在图推理的过程中,来自问题的注意力信息为图推理提供了依据,相比传统的图推理方法拥有更强的可解释性。
2.5.2 问题图
理解VQA任务中的自然语言问题并将问题解析为逻辑形式是个困难的任务,目前的一些方法通过类似于斯坦福解析器[59]的语言解析器来解析问题的结构。问题通常包含一个或两个关系三联体,这要求模型由多步推理来预测合理的答案。Cao等人[60]在2019年提出了HVQA模型,通过知识路由模块网络KM-Net将问题解析为一系列相关的基本查询的结构组合来生成不同的多跳推理问题;随后Cao等人[61]又提出了用于视觉问题推理的语言驱动的图胶囊网络,通过在语言解析树的指导下从底部到顶部合并胶囊,在CNN内雕刻一个树结构。该方法通过每个单独解析的语言布局引导胶囊网络学习每个图像问题对的自适应推理历程,CNN中的树结构提供了推理的解释。
Vatashsky等人[62]提出了一种方法,它由两个主要部分组成:生成一个问题图表示和一个回答过程。在把问题映射为图的过程中,将问题表示为有向图,其中节点表示对象,边表示对象之间的关系。图结构的组件包括对象类、属性和关系。节点表示包括回答此问题所需的所有对象视觉需求。这种方法将问题到图的任务作为一个从自然语言问题转换成图表示的问题来处理,将基于LSTM的序列训练到序列模型[63]。图在DFS遍历后被序列化并表示为字符串序列,因此模型任务是将问题序列转换为图序列。
以上方法中,图像图的建模提取了图像中物体之间的关系,问题图和回答程序的结合给了问答方法解释其答案的能力。但是以上方法都是单一的偏向于某一个单独模态的图解释方法,最近Xiong等人[64]应用结构化对齐,使用视觉和文本内容的图结构表示,旨在捕捉视觉和文本模式之间的深层联系,他们首先将不同的模态实体转换为连续的节点和邻接图,然后合并它们进行结构化对齐。这种方法在改善交叉模态表示的同时显式地表达了它们的内部关系,更容易被人理解,具有更强的可解释性。
表5对比了八种具有代表性的图解释方法在VQA v2数据集上的实验结果,其中BGN模型的准确率最高,该方法从图的角度对视觉问答任务中的双线性注意网络进行了新的研究。经典的双线性注意网络通过构建双线性注意图提取问题中的词与图像中对象的联合表示,但在复杂推理中缺乏对词之间关系的充分挖掘。BGN模型使用双线性图网络来模拟单词和对象的联合嵌入上下文信息,该方法研究了图像图和问题图两种图。图像图将被检测对象的特征传递到与之相关的查询词上,使输出节点同时具有语义信息和事实信息;问题图在图像图的这些输出节点之间交换信息,以放大对象之间隐式且重要的关系。这两类图之间相互配合,使模型可以对对象之间的关系和依赖关系进行建模,从而实现多步推理。
3 数据集
现有的视觉问答数据集种类已经十分丰富,但是这些数据集大部分存在以下阻碍视觉问答任务的可解释性问题:a)数据集中的图片不够贴近真实世界,很多数据集的图片都是通过互联网收集的,比如VQAv2.0等,这导致训练出来的模型在实际应用时难以取得理想的效果;b)视觉问答数据集中的单一样本答案缺乏多样性,现有的视觉问答数据集中有的对图像的标注信息有很多,但是答案只有一个,缺乏多样性,此外答案和问题的语言也大部分是英文,导致数据集应用的泛化性受限;c)数据集偏见的问题,因为涉及到的问题和概念的多样性巨大且不平衡,往往会阻止模型学习推理,导致它们执行有根据的猜测[65],从而导致类似于Clever Hans的问题出现,即模型过度依赖偏差,阻碍其泛化。表6介绍了一些能增强可解释性的数据集。
最近的研究[69]发现,VQA模型所作出的回答可能依赖于语言相关性,而不是逻辑推理,例如在VQAv1.0数据集上,关于某个问题,只需要回答“是”就可以获得40%~90%的准确率。VQA模型如果仅仅记住训练数据中的强语言先验值,就是所谓的语言偏见,VQA-CP[69]提出的减轻语言偏见的一个简单解决方案是通过使用额外的注释或数据扩充来增强训练数据,比如利用上文提到的视觉解释和文本解释提高视觉标注能力[4];此外,在数据集中生成对抗样本[70~72]有助于平衡训练数据。这些方法证明了无偏见的训练对提高VQA模型泛化性的效果。然而,VQA-CP的提出是为了验证VQA模型是否能够分离学习的视觉知识和记忆的语言先验[69],因此,如何在有偏训练下进行无偏推理仍然是一个主要挑战。目前已有的解决方案包括通过在训练集中使用单独的仅提问分支来学习语言先验[73]和一种称为CF-VQA的新型反事实推理框架[74],以减少VQA中的语言偏见。具体来说,CF-VQA将语言偏见表述为问题对答案的直接因果效应,并通过从总因果效应中减去直接语言效应来缓解偏见。Zhao等人[75]提出了一种由基本模型分支、仅问题模型分支和可视化模型分支三部分组成的进一步改进视觉内容的方法,以增强视觉内容对答案的影响。由此可见,VQA任务可以通过对数据集的修改来解决视觉问答问 题中的语言偏见问题从而能够让模型输出的答案更加准确合理,容易被人理解。
4 展望與挑战
单一的图像解释和文本解释存在难以反映推理过程的共同问题,其中,利用外部知识库的文本解释方法还存在依赖外部知识库的问题。模块化方法虽然能直观体现推理过程的每个步骤,但是却存在泛化能力差的问题。图解释方法不仅可以反映推理过程,而且可以融合图像解释和文本解释方法,但是当图结构中节点较多时,存在模型效率变低的问题。多模态解释的方法能充分利用数据中的信息,更接近人类直观感受,但是与单一的解释方法相比模型比较复杂。表7对本文讨论的视觉问答可解释性方法进行了总结,并在最后提出了已有的问题和未来的发展方向。
由此可见,可解释的视觉问答仍是一个新兴的研究,仍然有很多方面等待发展和优化。具体而言,有以下几个方面:a)多图解释结合,将文本生成的问题图和图片生成的场景图结合,同时可以将外部知识和信息转换成类似于知识图谱的结构化信息加入到图推理中;b)探索更多与模型无关的视觉问答可解释方法,当解释方法可以应用于任何模型时,机器学习开发人员可以自由使用他们喜欢的任何机器学习模型,任何建立在机器学习模型解释上的东西,如图形或用户界面,也独立于底层机器学习模型;c)将基于实例的可解释方法应用到视觉问答系统中,例如加入反事实样本和对抗样本等,这种方法同时也是与模型无关的方法,但是基于实例的方法通过选择数据集的实例而不是通过创建特征来解释模型,如反事实解释、对抗样本、有影响的实例等可解释方法都是基于实例的;d)可解释性缺乏评价指标,目前的可解释方法很多,但是缺乏评价指标,所以难以比较哪种可解释性方法更好;e)可以利用可解释性来增强模型的鲁棒性,目前的视觉问答系统对问题或图像中的信息十分敏感,如果修改图片或者问题中的句子就可能导致答案的变化,从而鲁棒性降低,如果利用类似于模型解耦[76]等可以增强模型可解释性的方法找出问题和图像中对改变答案影响大的区域,然后再有针对性地优化模型,就可以提高模型的鲁棒性,然而目前视觉问答中这方面的研究较少;f)深度神经网络可解释性研究理论框架的缺失问题,近年来,深度学习可解释性的研究虽然有诸多的进展,但是依旧缺乏理论体系框架的支撑,使得研究的创新点过于分散,后来者很难收集前人的足迹点进行对比研究,评估并从中作出具有突破性的创新点。
5 结束语
可解释性是一个非常有前景的研究领域,该领域已经成为国内外学者的研究热点,并且取得了许多瞩目的研究成果。但到目前为止,视觉问答与推理的可解释性研究还处于初级阶段,依然存在许多关键问题尚待解决。为了总结现有研究成果的优势与不足,探讨未来研究方向,本文从可解释性相关方法进行了归类、总结和分析,同时讨论了当前研究面临的挑战和未来潜在的研究方向,旨在为推动视觉问答的解释性研究的进一步发展提供帮助。
参考文献:
[1]Antol S, Agrawal A, Lu Jiasen, et al. VQA: visual question answe-ring[C]//Proc of IEEE International Conference on Computer Vision. Washington DC: IEEE Computer Society,2015:2425-2433.
[2]Marino K, Rastegari M, Farhadi A, et al. OK-VQA:a visual question answering benchmark requiring external knowledge[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2019:3190-3199.
[3]Wachter S, Mittelstadt B, Russell C. Counterfactual explanations without opening the black box: automated decisions and the GDPR[EB/OL].(2018-03-21).https://arxiv.org/abs/1711.00399.
[4]Selvaraju R R, Lee S, Shen Yilin, et al. Taking a hint: leveraging explanations to make vision and language models more grounded[C]//Proc of IEEE/CVF International Conference on Computer Vision.Piscataway,NJ:IEEE Press,2019:2591-2600.
[5]Peng Liang, Yang Yang, Wang Zheng, et al. MRA-Net:improving VQA via multi-modal relation attention network[J].IEEE Trans on Pattern Analysis and Machine Intelligence,2022,44(1):318-329.
[6]Ben-Younes H, Cadene R, Cord M, et al. MUTAN: multimodal tucker fusion for visual question answering[C]//Proc of IEEE International Conference on Computer Vision. Washington DC:IEEE Computer Society,2017:2612-2620.
[7]Wang Yu, Shen Yilin, Jin Hongxia. An interpretable multimodal visual question answering system using attention-based weighted contextual features[C]//Proc of the 19th International Conference on Autonomous Agents and Multi-agent Systems.Richland, SC:International Foundation for Autonomous Agents and Multiagent Systems,2020:2038-2040.
[8]Graves A, Schmidhuber J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures[J].Neural networks,2005,18(5-6):602-610.
[9]Qiao Tingting, Dong Jianfeng, Xu Duanqing. Exploring human-like attention supervision in visual question answering[EB/OL].(2017-09-19).https://arxiv.org/abs/1709.06308.
[10]Zhang Yundong, Niebles J C, Soto A. Interpretable visual question answering by visual grounding from attention supervision mining[C]//Proc of IEEE Winter Conference on Applications of Computer Vision.Piscataway,NJ:IEEE Press,2019:349-357.
[11]Miller T. Explanation in artificial intelligence: insights from the social sciences[J].Artificial Intelligence,2019,267(2):1-38.
[12]Kim B, Khanna R, Koyejo O. Examples are not enough. Learn to criticize! Criticism for interpretability[C]//Proc of the 30th International Conference on Neural Information Processing Systems.Red Hook,NY:Curran Associates Inc.,2016:2288-2296.
[13]陳婷,王玉德,任志伟.基于问题增强的问题引导图像视觉问答算法[J].通信技术,2022,55(2):166-173.(Chen Ting, Wang Yude, Ren Zhiwei. Question-guided image attention based on question enhancement for visual question answering[J].Communication Technology,2022,55(2):166-173.)
[14]Shetty R, Fritz M, Schiele B. Adversarial scene editing:automatic object removal from weak supervision[C]//Proc of the 32nd International Conference on Neural Information Processing Systems.Red Hook,NY:Curran Associates Inc.,2018:7717-7727.
[15]Fong R C, Vedaldi A. Interpretable explanations of black boxes by meaningful perturbation[C]//Proc of IEEE International Conference on Computer Vision.Washington DC:IEEE Computer Society,2017:3429-3437.
[16]Liu Runtao, Liu Chenxi, Bai Yutong, et al. CLEVR-Ref+: diagnosing visual reasoning with referring expressions[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Pisca-taway,NJ:IEEE Press,2019:4180-4189.
[17]Rissanen J. Modeling by shortest data description[J].Automatica,1978,14(5):465-471.
[18]Johnson J, Hariharan B, Van Der Maaten L, et al. Inferring and executing programs for visual reasoning[C]//Proc of IEEE International Conference on Computer Vision.Washington DC:IEEE Computer Society,2017:3008-3017.
[19]Agarwal V, Shetty R, Fritz M. Towards causal VQA: revealing and reducing spurious correlations by invariant and covariant semantic editing[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2020:9687-9695.
[20]Simonyan K, Vedaldi A, Zisserman A. Deep inside convolutional networks: visualising image classification models and saliency maps[EB/OL].(2014-04-19).https://arxiv.org/abs/1312.6034.
[21]Shrikumar A, Greenside P, Kundaje A. Learning important features through propagating activation differences[C]//Proc of the 34th International Conference on Machine Learning.2017:3145-3153.
[22]Sundararajan M, Taly A, Yan Qiqi. Axiomatic attribution for deep networks[C]//Proc of the 34th International Conference on Machine Learning.2017:3319-3328.
[23]Halbe S. Exploring weaknesses of VQA models through attribution driven insights[C]//Proc of the 2nd Grand-Challenge and Workshop on Multimodal Language.Stroudsburg,PA:Association for Computational Linguistics,2020:64-68.
[24]Selvaraju R R, Cogswell M, Das A, et al. Grad-CAM:visual explanations from deep networks via gradient-based localization[J].International Journal of Computer Vision,2020,128(2):336-359.
[25]Boukhers Z, Hartmann T, Jürjens J. COIN: counterfactual image generation for VQA interpretation[J].Sensors,2022,22(6):2245.
[26]Das A, Agrawal H, Zitnick L, et al. Human attention in visual question answering:do humans and deep networks look at the same regions?[J].Computer Vision and Image Understanding,2017,163(10):90-100.
[27]Park D H, Hendricks L A, Akata Z, et al. Multimodal explanations:justifying decisions and pointing to the evidence[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Pisca-taway,NJ:IEEE Press,2018:8779-8788.
[28]Farhadi A, Hejrati M, Sadeghi M A, et al. Every picture tells a story: generating sentences from images[C]//Proc of the 11th European Conference on Computer Vision.Cham:Springer,2010:15-29.
[29]Kulkarni G, Premraj V, Ordonez V, et al. BabyTalk: understanding and generating simple image descriptions[J].IEEE Trans on Pattern Analysis and Machine Intelligence,2013,35(12):2891-2903.
[30]Mao Junhua, Xu Wei, Yang Yi, et al. Deep captioning with multimodal recurrent neural networks (m-RNN)[EB/OL].(2015-06-11).https://arxiv.org/abs/1412.6632.
[31]Xu K, Ba J, Kiros R, et al. Show, attend and tell: neural image caption generation with visual attention[C]//Proc of the 32nd International Conference on International Conference on Machine Lear-ning.2015:2048-2057.
[32]Li Qing, Tao Qingyi, Joty S, et al. VQA-E:explaining,elaborating, and enhancing your answers for visual questions[C]//Proc of the 15th European Conference on Computer Vision.Cham:Springer,2018:570-586.
[33]Cai Wenliang, Qiu Guoyong. Visual question answering algorithm based on image caption[C]//Proc of the 3rd IEEE Information Technology,Networking, Electronic and Automation Control Conference.Piscataway,NJ:IEEE Press,2019:2076-2079.
[34]Hendricks L A, Akata Z, Rohrbach M, et al. Generating visual explanations[C]//Proc of the 14th European Conference on Computer Vision.Cham:Springer,2016:3-19.
[35]Wang Peng, Wu Qi, Shen Chunhua, et al. FVQA:fact-based visual question answering[J].IEEE Trans on Pattern Analysis and Machine Intelligence,2018,40(10):2413-2427.
[36]Tandon N, De Melo G, Suchanek F, et al. WebChild: harvesting and organizing commonsense knowledge from the Web[C]//Proc of the 7th ACM International Conference on Web Search and Data Mi-ning.New York:ACM Press,2014:523-532.
[37]Auer S, Bizer C, Kobilarov G, et al. DBpedia:a nucleus for a Web of open data[C]//Proc of the 6th International Semantic Web Confe-rence.Berlin:Springer,2007:722-735.
[38]Liu H, Singh P. ConceptNet: a practical commonsense reasoning tool-kit[J].BT Technology Journal,2004,22(4):211-226.
[39]Narasimhan M, Schwing A G. Straight to the facts: learning know-ledge base retrieval for factual visual question answering[C]//Proc of the 15th European Conference on Computer Vision.Cham:Springer,2018:451-468.
[40]Basu K, Shakerin F, Gupta G. AQuA: ASP-based visual question answering[C]//Proc of the 22nd International Symposium on Practical Aspects of Declarative Languages.Cham:Springer,2020:57-72.
[41]Riquelme F, De Goyeneche A, Zhang Yundong, et al. Explaining VQA predictions using visual grounding and a knowledge base[J].Image and Vision Computing,2020,101(9):103968.
[42]Yu Jing, Zhu Zihao, Wang Yujing, et al. Cross-modal knowledge reasoning for knowledge-based visual question answering[J].Pattern Recognition,2020,108(12):107563.
[43]Wang Yanan, Yasunaga M, Ren Hongyu, et al. VQA-GNN:reaso-ning with multimodal semantic graph for visual question answering[EB/OL].(2022-05-23).https://arxiv.org/abs/2205.11501.
[44]Ding Yang, Yu Jing, Liu Bang, et al. MuKEA: multimodal knowledge extraction and accumulation for knowledge-based visual question answering[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2022:5079-5088.
[45]Wu Jialin, Mooney R J. Faithful multimodal explanation for visual question answering[C]//Proc of ACL Workshop BlackboxNLP:Analyzing and Interpreting Neural Networks for NLP. Stroudsburg,PA:Association for Computational Linguistics,2019:103-112.
[46]Zhang Weifeng, Yu Jing, Zhao Wenhong, et al. DMRFNet:deep multimodal reasoning and fusion for visual question answering and explanation generation[J].Information Fusion,2021,72(8):70-79.
[47]邹芸竹,杜圣东,滕飞,等.一种基于多模态深度特征融合的视觉问答模型[J].计算机科学,2023,50(2):123-129.(Zou Yunzhu, Du Shengdong, Teng Fei, et al. Visual question answering model based on multi-modal deep feature fusion[J].Computer Science, 2023,50(2):123-129.)
[48]Andreas J, Rohrbach M, Darrell T, et al. Neural module networks[C]//Proc of IEEE Conference on Computer Vision and Pattern Re-cognition.Washington DC:IEEE Computer Society,2016:39-48.
[49]Hu Ronghang, Andreas J, Rohrbach M, et al. Learning to reason:end-to-end module networks for visual question answering[C]//Proc of IEEE International Conference on Computer Vision. Washington DC:IEEE Computer Society,2017:804-813.
[50]Hu Ronghang, Andreas J, Darrell T, et al. Explainable neural computation via stack neural module networks[C]//Proc of the 15th European Conference on Computer Vision.Cham:Springer,2018:53-71.
[51]Shi Jiaxin, Zhang Hanwang, Li Juanzi. Explainable and explicit visual reasoning over scene graphs[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2019:8368-8376.
[52]Ren Mucheng, Huang Heyan, Gao Yang. Prediction or comparison: toward interpretable qualitative reasoning[EB/OL].(2021-06-04).https://arxiv.org/abs/2106.02399.
[53]Norcliffe-Brown W, Vafeias E, Parisot S. Learning conditioned graph structures for interpretable visual question answering [C]// Proc of the 32nd International Conference on Neural Information Processing Systems.Red Hook,NY:Curran Associates Inc.,2018:8344-8353.
[54]Li Linjie, Gan Zhe, Cheng Yu, et al. Relation-aware graph attention network for visual question answering[C]//Proc of IEEE/CVF International Conference on Computer Vision.Piscataway,NJ:IEEE Press,2019:10312-10321.
[55]Guo Dalu, Xu Chang, Tao Dacheng. Bilinear graph networks for visual question answering[J].IEEE Trans on Neural Networks and Learning Systems,2023,34(2):1023-1034.
[56]鄒品荣,肖锋,张文娟,等.融合场景语义与空间关系的视觉问答[J].西安工业大学学报,2023,43(1):56-65.(Zou Pinrong, Xiao Feng, Zhang Wenjuan, et al. Visual question answering based on scene semantic relation and spatial relation[J].Journal of Xian Technological University,2023,43(1):56-65.)
[57]张昊雨,张德.基于图结构的级联注意力视觉问答模型[J].计算机工程与应用,2023,59(6):155-161.(Zhang Haoyu, Zhang De. Cascaded attention visual question answering model based on graph structure[J].Computer Engineering and Applications,2023,59(6):155-161.)
[58]蘭红,张蒲芬.问题引导的空间关系图推理视觉问答模型[J].中国图象图形学报,2022,27(7):2274-2286.(Lan Hong, Zhang Pufen. Question-guided spatial relation graph reasoning model for visual question answering[J].Journal of Image and Graphics,2022,27(7):2274-2286.)
[59]Klein D. Manning C D. Accurate unlexicalized parsing[C]//Proc of the 41st Annual Meeting of the Association for Computational Linguistics.Stroudsburg,PA:Association for Computational Linguistics,2003:423-430.
[60]Cao Qingxing, Li Bailin, Liang Xiaodan, et al. Explainable high-order visual question reasoning:a new benchmark and knowledge-routed network[EB/OL].(2019-09-23).https://arxiv.org/abs/1909.10128.
[61]Cao Qingxing, Liang Xiaodan, Wang Keze, et al. Linguistically driven graph capsule network for visual question reasoning[EB/OL].(2020-03-23).https://arxiv.org/abs/2003.10065.
[62]Vatashsky B Z, Ullman S. VQA with no questions-answers training[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2020:10373-10383.
[63]Sutskever I, Vinyals O, Le Q V. Sequence to sequence learning with neural networks[C]//Proc of the 27th International Conference on Neural Information Processing Systems.Cambridge,MA:MIT Press,2014:3104-3112.
[64]Xiong Peixi, You Quanzeng, Yu Pei, et al. SA-VQA:structured alignment of visual and semantic representations for visual question answering[EB/OL].(2022-01-25).https://arxiv.org/abs/2201.10654.
[65]Kervadec C, Antipov G, Baccouche M, et al. Roses are red, violets are blue… but should VQA expect them to?[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Pisca-taway,NJ:IEEE Press,2021:2775-2784.
[66]Plummer B A, Wang Liwei, Cervantes C M, et al. Flickr30k Entities: collecting region-to-phrase correspondences for richer image-to-sentence models[C]//Proc of IEEE International Conference on Computer Vision.Piscataway,NJ:IEEE Press,2015:2641-2649.
[67]Krishna R, Zhu Yuke, Groth O, et al. Visual Genome: connecting language and vision using crowdsourced dense image annotations[J].International Journal of Computer Vision,2017,123(1):32-73.
[68]Zhu Yuke, Groth O, Bernstein M, et al. Visual7W: grounded question answering in images[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2016:4995-5004.
[69]Agrawal A, Batra D, Parikh D, et al. Dont just assume; look and answer: overcoming priors for visual question answering[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2018:4971-4980.
[70]Chen Long, Yan Xin, Xiao Jun, et al. Counterfactual samples synthesizing for robust visual question answering[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Pisca-taway,NJ:IEEE Press,2020:10797-10806.
[71]Abbasnejad E, Teney D, Parvaneh A, et al. Counterfactual vision and language learning[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2020:10041-10051.
[72]Liang Zujie, Jiang Weitao, Hu Haifeng, et al. Learning to contrast the counterfactual samples for robust visual question answering[C]//Proc of Conference on Empirical Methods in Natural Language Processing.Stroudsburg,PA:Association for Computational Linguistics,2020:3285-3292.
[73]Cadene R, Dancette C, Ben-Younes H, et al. RUBi:reducing unimodal biases for visual question answering[C]//Proc of the 33rd International Conference on Neural Information Processing Systems.Red Hook,NY:Curran Associates Inc.,2019:841-852.
[74]Niu Yulei, Tang Kaihua, Zhang Hanwang, et al. Counterfactual VQA:a cause-effect look at language bias[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2021:12695-12705.
[75]Zhao Jia, Zhang Xuesong, Wang Xuefeng, et al. Overcoming language priors in VQA via adding visual module[J].Neural Computing and Applications,2022,34(11):9015-9023.
[76]Hu Jie, Cao Liujuan, Tong Tong, et al. Architecture disentanglement for deep neural networks[C]//Proc of IEEE/CVF International Conference on Computer Vision.Piscataway,NJ:IEEE Press,2021:652-661.
猜你喜欢
商界(2019年12期)2019-01-03
IT经理世界(2018年20期)2018-10-24
小康(2017年16期)2017-06-07
计算机应用(2016年12期)2017-01-13
无线互联科技(2016年13期)2017-01-10
现代电子技术(2016年22期)2016-12-26
中国科技纵横(2016年17期)2016-11-30
南风窗(2016年19期)2016-09-21
电脑知识与技术(2016年10期)2016-06-16
电脑知识与技术(2016年5期)2016-04-14
