
改进YOLOv3的轻量级铸件焊缝表面缺陷检测*
2024-01-27 06:24穆春阳刘永鹿秦政硕
组合机床与自动化加工技术 2024年1期
李 闯,马 行,b,穆春阳,刘永鹿,秦政硕,张 弘
(北方民族大学 a.电气信息工程学院;b.宁夏智能信息与大数据处理重点实验室;c.机电工程学院,银川 750021)
0 引言
随着工业化进程的加快,铸件在机械制造行业中的应用越来越广泛[1]。然而,在铸件的生产制造过程中,焊缝缺陷是一个常见的问题。焊缝表面缺陷在工程应用中大大降低了铸件的使用寿命[2]。因此,对铸件焊缝缺陷的检测变得尤为重要。传统检测方法主要基于人工视觉和显微镜图像分析,其繁琐的操作和不可靠性限制了其在现代工业生产中的应用[3]。
近年来,深度学习技术的发展为焊缝缺陷检测提供了新的思路和方法。其中,许多学者基于卷积神经网络的方法已经取得了一定的成功。如王睿等[4]将YOLO-M网络部署到边缘计算设备上,使用边缘计算设备检测图像缺陷。该方法的检测速度受限于所使用的设备,对硬件要求高。刘金海等[5]采用小样本的方法,在数据集较少的情况下,完成管道焊缝缺陷检测任务。该方法需要使用外部设备采集图像,增加成本的同时不能直接用于工业检测焊缝表面缺陷。SUYAMA等[6]尝试了多种基于深度学习的焊缝分类模型,并对其进行了测试和评估,以验证其在焊缝缺陷检测任务中的识别能力。该方法虽然进行了多种实验,但是针对目标单一,背景简单,无法检测两个及两个以上的目标。
针对以上问题,提出了改进的YOLOv3[7]检测模型YOLOv3-GN,使用Labelimg软件标注焊缝缺陷类别,并且反复验证,确保标注信息无误性;引入轻量级网络GhostNet[8]替换YOLOv3的主干网络,减少参数量的同时有效的提取网络特征信息;添加空间金字塔池化结构,利用池化结构提取上文特征信息并进行特征融合,能够更好地捕捉物体多个尺度下的特征,提高模型的检测能力;使用1×1卷积扩充通道数,防止在提取特征过程中信息的丢失;采用通道注意力机制,提升对敏感区域的关注度,减少通道中的冗余计算量,提高模型的精度。
1 改进的轻量化YOLOv3算法
在YOLOv3算法的基础上,优化网络结构,使其更加适用于复杂环境下缺陷小目标快速准确的识别和定位。具体做法是使用轻量化的GhostNet网络替换原始主干网络,加快模型的检测速度和有效的提取特征图信息;并且为了将多尺度特征信息进行融合,实现更加高效的特征提取能力,在主干网络的最后一层输出端引入了SPPF(spatial pyramid pooling-fast)[9]并替换激活函数,将其命名为LeakSPPF;在FPN[10]中添加1×1卷积和注意力机制,增加对小目标和中目标的的关注度,提升检测准确率。其改进模型结构如图1所示。
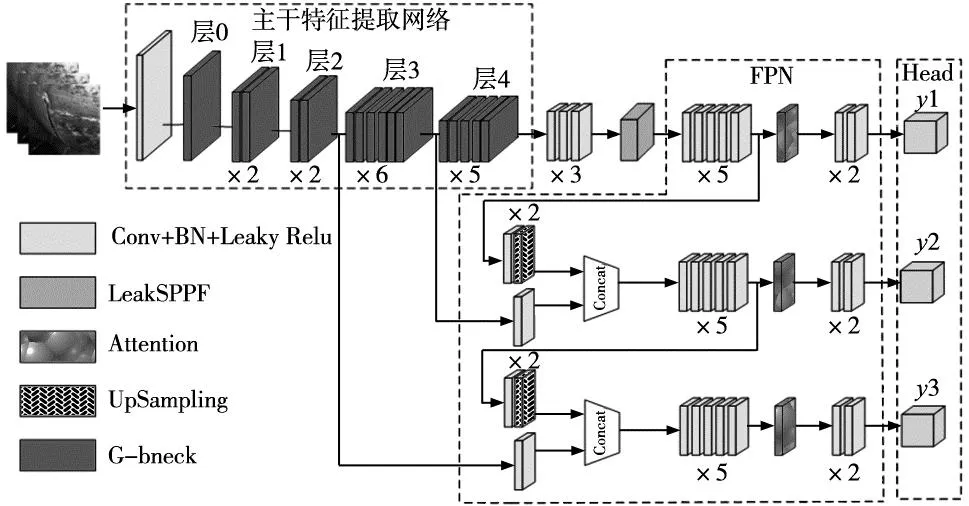
图1 YOLOv3-GN结构图
图1中,YOLOv3-GN主要包含3部分,主干特征提取网络、特征融合FPN模块和检测头Head模块。首先输入网络的图片为640×640×3,经过主干特征提取网络生成80×80×40、40×40×112、20×20×160三个初步特征信息提取层;然后第1、2层分别使用1×1卷积增加特征通道数,第3层使用空间金字塔池化结构,对不同尺度的信息进行特征融合,在FPN和Head之间加入了注意力机制,增加对敏感信息的特征提取能力;最后送入检测头y1,y2,y3中,输出所有的检测框信息。
1.1 替换主干网络
主干网络用到GhostNet的主要部分,不包括平均池化、1×1的卷积和全连接层。并且输入图片大小为640×640,三通道彩色图片。主干网络参数信息如表1所示,GhostNet是一种高效的轻量级卷积神经网络。GhostNet基于模型复制的思想,利用低成本和高效率的特殊卷积操作来减少模型的参数数量和计算复杂度,从而在保持准确性的情况下提高了模型的速度和通用性。Ghost模块是GhostNet模型中的一个重要组成部分,它是一种基于通道分组的卷积结构。基本思想是将输入通道分成多个组,在每个组内进行卷积操作,然后将不同组之间的特征进行交互和融合。主要目的是减少模型的参数量和计算量,从而提高模型的训练速度和推理速度。
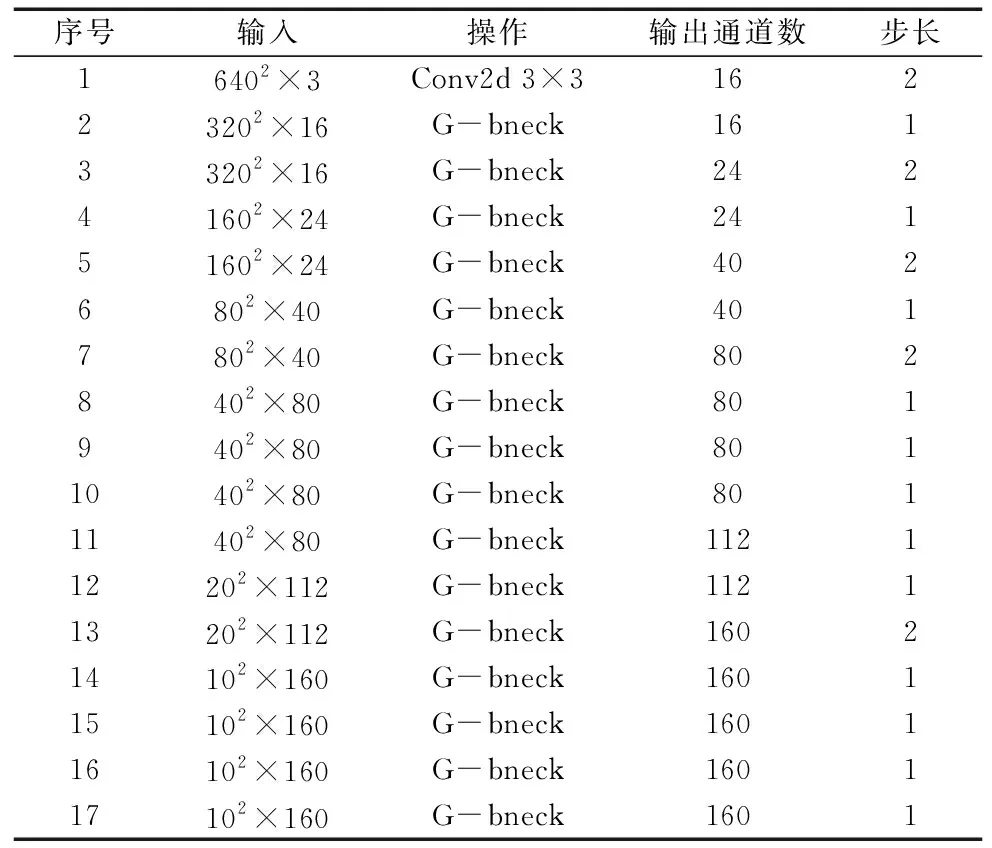
表1 主干网络参数信息
表1中G-bneck有两种不同的网络结构,当步长为1时,由两个Ghost模块组成,当步长为2时,在两个Ghost模块中间加入DW(Depthwise)[11]卷积,并且采用了残差连接和批规范化等方法。
1.2 改进的空间金字塔池化结构
原始的SPPF所采用的激活函数是SiLU[12],SiLU的计算复杂度较高,需要进行指数运算和除法运算,计算量比Leaky ReLU[13]激活函数要大。这可能会导致在深度神经网络中运行速度变慢,从而影响模型的训练和推理效率。综合上述因素采用Leaky ReLU替换SiLU激活函数。LeakSPPF主要用于提取不同尺度的特征,以适应不同大小的目标物体。具体来说,在主干网络之后的卷积层,会接入一个LeakSPPF模块,这个模块将输入特征图分割成不同大小的多个子区域,并对每个子区域进行最大池化操作。不同大小的池化结果会被拼接到一起,形成一个固定长度的特征向量。这个特征向量能够有效地捕捉不同尺度的目标物体的特征。LeakSPPF的网络结构如图2所示。
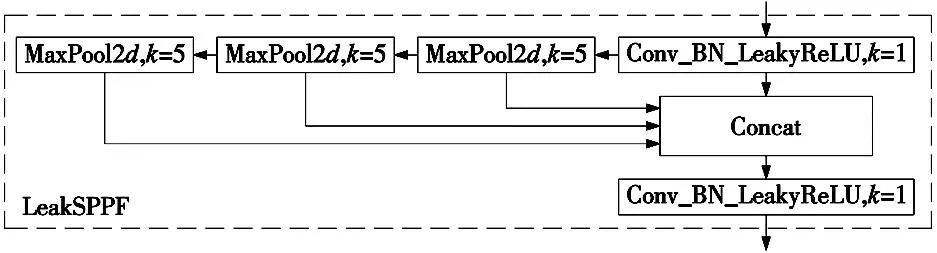
图2 改进的LeakSPPF结构
图2中输入特征图经过不同最大池化结构和卷积操作,将输出特征图在通道维度上进行拼接,输出特征图的通道数是输入特征图的4倍。最后经过卷积操作,通道数减半。
1.3 添加损失函数
Focal Loss[14]是一种用于处理类别不平衡问题的损失函数。在传统的交叉熵损失函数中,每个样本的损失都被平等地对待,而在类别不平衡问题中,一些类别的样本数量很少,而另一些类别的样本数量非常多,这会导致模型对于少数类别的预测效果很差[15]。Focal Loss通过引入一个可调参数γ来缓解这个问题,使得模型更加关注难以分类的样本。具体来说,对于易分类的样本,损失函数的权重被降低,而对于难以分类的样本,损失函数的权重被增加。这种方法可以有效地提高模型对于少数类别的预测准确率。Focal Loss的计算公式如式(1)所示。
FL(pt)=-αt(1-pt)γlog(pt)
(1)
式中:αt是一个权重因子,用于平衡分类问题中不同类别的样本数量;γ为可调参数,当γ=0时,Focal Loss退化为标准的交叉熵损失函数;pt表示模型预测为正样本的概率。
1.4 添加注意力机制
本文采用的注意力机制为SE(squeeze excitation)[16],SE属于通道注意力机制,可以自适应学习不同通道之间的依赖关系[17]。它可以使卷积神经网络模型增强对特征图中关键信息的学习和理解,被广泛嵌入卷积神经网络模型中,在训练和测试过程中,添加SE模块有利于模型关注更多有用的信息,而忽略不重要的信息,对改进模型网络有很大的帮助[18]。注意力机制结构图如图3所示。

图3 注意力机制结构图
图3由全局平均池化层、全连接层1和全连接层2组成。不同连接层后所使用的激活函数不同。
2 实验数据与实验环境
2.1 增强的数据集
本文采用的数据集是实验室自建的,原始数据集861张,包含5种缺陷类别,分别是焊瘤、夹渣、裂纹、气孔和未熔合。由于原始图片尺寸太大,消耗计算机内存,不适合传入模型并进行训练,所以减少原始图片大小,调整为800×800大小。然后将调整好的图片经过随机旋转、水平平移、改变亮度和添加噪声等图像增强方法,使图片数量达到4305张。增强后的结果如图4所示。扩充数据集,增加数据集的多样性,有效弥补数据集样本过少的缺点,防止过拟合情况的发生,从而提升网络模型的泛化能力[19]。本文将数据集分为训练数据集、验证数据集和测试数据集,三者的比例为8∶1∶1。

图4 增强的数据集
2.2 实验环境
实验环境基于Linux操作系统,服务器的GPU型号为NVIDIA Tesla P40,显存为24 GB,4块显卡并行训练,具体的环境配置信息如表2所示。

表2 环境配置信息
3 实验结果与分析
3.1 评价指标
本文采用的评价指标为平均精度(average precision,AP),平均精度均值(mean average precision,mAP),模型参数量(model parameters,MP)和检测速度(frames per second,FPS)。AP和mAP的计算公式如式(2)和式(3)所示。
(2)
(3)
式中:AP是P-R曲线围成的面积,P(precision)是精确率,即模型预测为目标的样本中实际为目标的比例,R(recall)是召回率,即实际为目标的样本中被模型正确预测为目标的比例,其中P为曲线的纵轴,R为曲线的横轴,m是类别数。
3.2 实验设置
每个模型都是从0开始训练的,迭代次数为300次,初始学习率为0.01,动量为0.937,并采用余弦退火学习策略动态调整学习率,喂入模型中的图片批量设置为32,优化器选择随机梯度下降法(stochastic gradient descent,SGD),每训练30次保存一次权值文件。
3.3 对比实验
为了验证本文算法提出的有效性,将本文算法与YOLOv3、SSD[20]和Faster R-CNN[21]做对比。对比实验如表3所示。
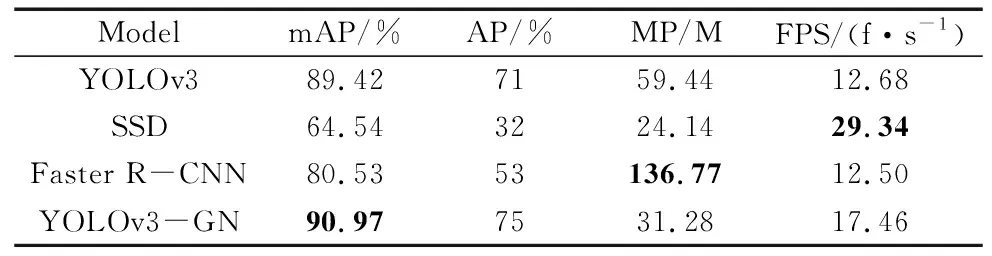
表3 对比实验
表3中AP是小目标气孔的平均精度值,YOLOv3-GN是本文改进的模型。改进模型的平均精度均值为90.97%,分别高于YOLOv3、SSD和Faster R-CNN模型1.55%、26.43%、10.44%。YOLOv3-GN气孔的平均精度值为75%,高于YOLOv3模型4%;参数量为31.28 M,少于YOLOv3模型28.16 M;检测速度为17.46 f/s,高于YOLOv3模型4.78 f/s。通过对比实验分析得到,本文提出的算法具有低参数量和高检测速度,更适合于复杂环境下实时检测焊缝缺陷的需求。
3.4 消融实验
为了进一步验证不同的改进策略对本文算法的影响,本文在YOLOv3的基础上进行消融实验分析。不同改进策略如表4所示。

表4 消融实验
表4中实验1为基础模型,主干网络为GhostNet,实验2~7都是在实验1基础上进行改进的,可以看出不同改进策略对实验精度的提高。对比实验1,实验2~7的mAP分别提高1.30%、0.71%、1.54%、1.16%、1.52%、3.33%。实验7在检测速度方面虽然低于实验1,但是在准确率方面有所提升,提升3.33%。
3.5 检测效果与分析
为了验证改进模型的实际检测效果,从其他网络途径网上下载图片并进行预测,并与原始YOLOv3模型预测结果进行对比,对比结果如图5所示。

(a) 改进YOLOv3检测结果1 (b) YOLOv3检测结果1
图5a检测缺陷的置信度普遍高于图5b的置信度,并且图5b的焊瘤缺陷重复预测,检测效果不理想。虽然图5c预测未熔合的置信度低于图5d,但是图5c没有漏检焊瘤缺陷,图5d存在漏检的情况。图5f也存在漏检裂纹缺陷的情况。
4 结论
本文在YOLOv3的基础上提出了一种YOLOv3-GN的目标检测算法,该算法的模型参数量约为原始YOLOv3模型参数量的一半,检测速度提高4.78 f/s,同时mAP也有所提升,极大的满足实时应用场合的需求。其主要改进为:
(1)在替换轻量级主干网络的基础上,加入了空间金字塔池化结构,使得模型关注更多的细节特征信息,有效提高卷积神经网络的特征表达能力,从而提升模型的性能指标。
(2)使用1×1卷积和注意力机制,提升输入特征图的维度,提取对模型更有用的信息,让模型识别关键信息并将重点放在有用的输入上,以便更好的检测缺陷目标,达到有效的识别和定位。
猜你喜欢
军事文摘(2024年2期)2024-01-10
计算机工程与应用(2023年22期)2023-11-27
科学技术与工程(2023年3期)2023-03-15
软件导刊(2022年3期)2022-03-25
广东教育·高中(2022年1期)2022-03-16
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
计算机技术与发展(2019年1期)2019-01-21
北京航空航天大学学报(2018年1期)2018-04-20
新课程研究(2016年21期)2016-02-28
