
几何属性引导的三维语义实例重建
2024-01-22 10:27万骏辉刘心溥陈莉丽敖晟张鹏郭裕兰
中国图象图形学报 2024年1期
万骏辉,刘心溥,陈莉丽,敖晟,张鹏*,郭裕兰
1.中山大学电子与通信工程学院,深圳 518107;2.国防科技大学电子科学学院,长沙 410005;3.军事科学院国防科技创新研究院人工智能研究中心,北京 100071
0 引言
语义实例重建是一项综合性任务,它的目的是从部分观测中估计场景中实例物体的语义类别和姿态,并恢复这些物体的完整形状。作为机器人与现实世界的三维环境交互的关键步骤(龙霄潇 等,2021),已广泛应用于许多视觉应用中,如虚拟现实、视觉导航和室内设计。然而,由于室内空间结构的复杂性、高遮挡和多变性,语义实例重建仍然是一个开放的挑战。
在过去的几年里,关于语义实例重建问题有许多解决方案。一种经典的方法是基于二维图像的场景实例重建。Gkioxari 等人(2019)提出的Mesh R-CNN(mesh region based convolutional neural networks)先预测二维图像中的实例物体,之后再预测物体的三维形状。然而这种方法缺乏准确的深度信息,会导致物体的位置定位出现偏差。因此,之后的研究工作更注重于对三维数据的处理。与图像相比,点云的几何信息有助于精准定位物体(Guo 等,2020)。然而,点云具有稀疏性和不规则性等特点,在点云上直接使用基于网格的卷积神经网络(convolutional neural network,CNN)进行场景实例重建存在一定的困难。因此一种方法是用体素网格或截断的符号距离函数(truncated signed distance function,TSDF)来表示三维场景,并使用三维卷积神经网络(three dimensional convolutional neural networks,3DCNN)预测体素标签,从而在实例层面上重建场景。Hou 等人(2020)提出的RevealNet 首先对稠密体素网格进行实例分割,然后用3D-CNN 进行实例重建。由于内存成本随体素分辨率的增加而不断增长,因此这种方法的计算成本巨大。此外,该方法可恢复的实例分辨率十分有限,无法重建出场景中的高保真物体。另一种方法是通过检索最相似的CAD(computer aided design)模型来替换真实场景中的残缺物体。Avetisyan 等人(2019)提出的Scan2CAD 首先基于CAD 模型和原始扫描对场景内所有实例进行姿态预测,然后根据估计的姿态对每个模型进行对齐匹配。然而,这些方法在真实扫描和CAD 模型之间存在几何保真度方面的差异。此外,形状匹配的效率也与CAD数据集的规模有关。
Nie 等人(2021)提出的RfD-Net 在原始点云上同时完成了目标检测和语义物体重建任务。其首先在场景点云里定位物体,然后采样物体的局部点云以提取局部细节特征,并融合物体的全局先验特征进行网格重建。该方法可以识别和重建高分辨率网格物体,取得了突出的效果。然而该方法未能充分考虑到场景中物体的几何属性,导致无法重建出高保真的物体。首先,场景中的物体具有不同的种类和几何尺寸,这就导致了它们具有较大的形状差异。其次,物体的摆放位置也十分复杂,例如部分书架放置在桌子上方,许多椅子放置在桌子下方,桌子和椅子之间互相嵌入,但RfD-Net 采用统一尺度球体采样的方法,并没有有效地利用物体的先验几何尺度信息,从而采样到大量属于其他物体的噪声点,丢失了大量有效的物体前景点,导致重建质量效果一般。此外,其在提取局部细节特征时对全部前景点采用最大池化操作,这会导致网络难以有效地提取出物体关键点的几何信息。实际上,在基于点云的语义实例重建的算法流程中,场景中的物体具有丰富的先验几何和语义信息。因此,三维目标检测器提取出来的检测框可作为实例的先验几何尺度信息,以引导进行更精确的局部点云采样。Nie 等人(2020)在基于二维图像进行实例重建的方法Total3D(total 3D understanding)中,融合了先验语义信息,引导网络生成更高质量的物体模型。Liu 等人(2022)提出的AGFA-Net(adaptive global feature augmentation network for point cloud completion)以物体点云关键的几何坐标信息作为引导,利用Transformer 结构自适应地增强物体的细节和全局特征,有效地提升了物体点云补全的性能。Fu 等人(2023)提出的VAPCNet(vewpoint-aware 3D point cloud completion network)学习部分点云的抽象表征,以区分空间中的各种视角,然后利用准确的视角信息和点云的局部几何特征来预测缺失的点,进一步提升了物体点云补全的性能。
针对这些问题和思路,本文提出一种几何属性引导的语义实例重建算法(geometric attributeguided network,GANet)。本文算法可以从场景的稀疏物体点云中重建出高质量的物体网格,其主要创新点如下:1)为了有效利用物体的几何细节和语义属性信息,针对场景物体的特点,重新设计了物体检测框的采样方案。此外,为了利用关键点的几何信息引导细节特征的融合,设计了一种基于Transformer 的三维点云特征提取方法。该方法捕获了物体中更多的高质量前景点,从而增强了特征的表征性,有效地提升了物体重建的性能。2)针对场景物体重建存在特征空间不一致的问题,提出了一个特征转换模块将全局特征和局部几何特征进行对齐。在特征融合时,保证了全局特征和局部特征对物体重建的贡献度一致,提升物体重建的性能。3)为了证明所提算法的鲁棒性和有效性,在真实点云场景数据集ScanNet v2(Dai等,2017a)上对物体进行了重建。实验结果表明,本文算法的实例重建平均精度均值(mean average precision,mAP)比RfD-Net 方法高8%。
1 相关工作
1.1 三维形状补全
三维形状补全任务的目的是从一个物体的部分扫描中恢复其完整的形状。目前的形状补全方法可以分为基于点、基于体素、基于符号距离函数(signed distance function,SDF)和基于网格的方法。这些方法大多遵循一个共同的算法流程。具体来说,首先对不完全扫描的点云用卷积神经网络进行编码,然后预测不可见部分、孔洞和缺陷表面。Yuan 等人(2018)提出的PCN(point completion network)网络是一种开创性的点云形状补全方法。然而,该方法通常只能补全有限个数的点,无法表征高分辨率的物体。Dai等人(2017b)以稠密体素网格作为输入,构建三维编码器—解码器的网络结构以进行物体形状补全,得到了具有高分辨率的三维物体网格。Mescheder 等人(2019)提出了OccNet(occupancy network)用于恢复物体在任意分辨率下的连续形状。它将物体的真实点云编码为隐式特征,然后预测重建物体的候选空间采样点的占用情况,最后采用移动立方体算法(marching cubes algorithm)(Lorensen 和Cline,1987)进行网格生成。三维形状补全可以生成物体的完整三维模型,本文算法利用其完成三维实例重建中的重建任务。具体来说,即使用OccNet 的解码器进行空间点的占用预测,并最终生成网格模型进行实例重建。
1.2 场景补全
场景补全不是关注单个物体,而是从一个输入场景的2D/3D 观测中恢复可见和不可见场景(包括物体)的完整几何形状。前期工作曾使用过多种复杂的插值方法来完成场景补全任务。目前的主流方法均采用深度学习策略来提升场景补全的效果。Roldão 等人(2022)根据输入的数据格式,将当前的方法分为基于二维表示的方法、基于三维网格的方法和基于三维点云的方法。基于二维表示的方法以深度图或范围图像作为输入,并基于二维卷积神经网络构建整个场景补全的框架。Han 等人(2019)输入单一深度图像,联合三维场景体积重建和三维深度预测,完成场景补全任务。基于三维网格的方法主要是利用三维占用网格或 TSDF 网格来编码输入数据。这种表示方式的优点是可以方便地转化为二进制网格,便于压缩。最后基于三维卷积神经网络框架,在可见区域和遮挡区域预测所有体素网格的语义和实例标签。SPSG(self-supervised photometric scene generation)由Dai 等人(2021)提出,其首先通过体积融合将RGB-D(RGB-depth)扫描和相机姿态用TSDF 表示,然后利用二维视图做引导,以自监督学习的方式估计遮挡区域的场景几何和颜色,从而将输入的RGB-D 图像重建为高质量彩色三维模型。由于点云的稀疏性和不规则性,基于原始三维点云的场景补全方法较少。Zhong 和Zeng(2020)提出了一种语义场景补全方法SPCNet(semantic point completion network)。该方法采用编码—解码器结构,其中一个观测点编码器用于提取观测点的特征,另一个遮挡点解码器将前述特征映射到遮挡点上。在此基础上,SPCNet 进一步引入图像点特征,并结合纹理信息以提升语义场景补全的性能。
场景补全是指推断出场景(包括背景和物体)的三维语义的同时,补全其三维形状的任务。本文的研究目标是场景实例形状重建,即从输入数据中恢复出场景中的物体实例及其三维形状(不包括背景)。这两个任务都是基于三维点云或RGB-D 图像的,其相关性在于它们都需要对输入数据进行深度理解,以便更好地推断出场景的三维语义和物体实例几何结果。
1.3 语义实例重建
除了对单一物体进行形状补全和对整个场景进行恢复之外,还有一种语义实例重建任务,这也是本文关注的重点。该任务首先需要对场景内的实例进行定位,随后对被定位的实例进行重建。现有一些方法用CAD 模型代替场景里的实例以实现语义实例重建。Scan2CAD(Avetisyan 等,2019)通过设计的3D-CNN 网络学习真实物体和合成物体之间对应的热力图,最后基于热力图通过位姿优化算法对齐相应的CAD 模型完成重建。另一类方法则通过相应的网格重建网络生成实例结果。Hou 等人(2020)提出的RevealNet 将三维扫描离散到TSDF 网格中,利用3D-CNN 预测语义实例的占用网格情况。Nie 等人(2020)提出的Total3D 在二维RGB 图像上进行物体检测和网格重建。RfD-Net(Nie 等,2021)采用直接处理点云的方式,它将候选方案编码到潜在空间中,并使用隐函数预测候选空间采样点的占用情况以进行网格重建。Tang 等人(2022)提出的DIMR(disentangled instance mesh reconstruction)使用了更多的标注信息,先对场景点云进行实例和语义分割,然后利用一个预训练的网络自编码器来完成网格重建。
2 本文方法
2.1 网络框架
本文提出的基于几何属性引导的语义实例重建网络GANet 的整体框架如图1 所示。网络以真实场景点云作为输入,输出场景内物体的网格模型。具体而言,1)首先使用点云三维目标检测器获取实例目标的特征Fp,生成场景内的物体检测框,从而定位候选对象。2)随后通过目标筛选策略来选择高质量的三维检测框,并利用检测框的几何信息引导前景点采样,分组和对齐检测框内的局部点云。物体局部点云的几何和语义属性信息被输入到去噪器中,进行前景点分割。3)进一步地,设计了一个基于Transformer 的特征提取器以提取点云特征。该特征提取器在物体关键点的几何属性引导下学习了实例点云局部特征Fo,并采用设计的特征转换器对齐物体的全局先验特征Fg,两者串联融合得到Fm。4)最后,使用网格生成器学习规范空间中的占用函数来表示实例的形状,并根据占用点的占用情况,利用移动立方体算法生成网格,同时根据物体几何参数将重建的网格放置在场景中。
2.2 几何属性引导的空间转换
2.2.1 目标筛选
为了保证检测的准确率,目标检测器通常在初始检测阶段会产生冗余的候选目标。与图像不同,三维点云具有很强的稀疏性,很多空间实际上是没有物体实例的。如果考虑所有的候选目标,将会涉及大量的负样本。在本文算法的流程中,考虑到被检测到的候选目标需要送入形状生成模块进行物体重建,因此大量负样本会影响形状生成器的学习效果。此外,考虑全部候选目标的方案也会带来计算量过大的问题,降低了方法的效率。因此在训练阶段,本文算法会尽可能地从所有候选目标中保留更高质量的物体。具体来说,GANet会选择置信度得分较高的Kc个候选目标。在推理阶段,由于候选对象的数量不受限制,因此本文算法使用三维非极大值抑制(non-maximum suppression,NMS)来消除冗余的负样本。经过目标筛选后,Kc个正样本被保留下来。
2.2.2 几何属性引导的目标点采样
本文算法在获得Kc个正样本后,通过在场景点云中采样这些样本的局部点云,以获取更精细的物体信息。现有方法通常采用球体采样的方案获得局部点云。具体来说,以候选检测框的中心为球体中心,设置一个半径r=1 的球,通过随机采样得到球内的Ns个候选点。实际上,这种采样策略在语义实例重建任务里存在一定的问题。因为场景里的物体种类和大小不一,对所有物体进行固定半径的球体采样并没有考虑到物体的几何属性多样性。对于过小的物体来说,会采集多余的噪声点;对于过大的物体来说,会丢失物体的关键特征点。为解决该问题,本文算法采用了盒采样的方案,利用检测框在场景内采样目标候选点,并通过几何属性引导获取到更多属于物体的局部点。
盒采样与球体采样的对比如图2 所示。若检测框内的点数大于Ns,则对框内的点进行最远点采样(farthest point sampling,FPS);若点数小于Ns,则复制里面的点进行补充。进行盒采样后,每个实例获取到了更多的有效物体点,同时也减少了其他物体的噪声点。之后,本文算法将不同物体中的点对齐到一个规范统一的坐标系,对输入点进行归一化(包括去中心和旋转的操作)。规范空间处理消除了形状重建中不同物体空间平移和旋转的偏差,降低了形状学习的难度。
由于从真实场景中获得的三维点往往是有噪声的,因此进一步利用一个去噪器来提取前景点。去噪器由PointNet(Qi 等,2017)组成,通过对每个点进行特征提取,进而判断是否属于前景点。其中物体采样点的三维坐标(归一化处理后)和每个点相对于场景地面之间的高度差作为网络输入。为提高特征鉴别力,本文算法还将物体的类别先验信息添加到输入数据中。具体来说,GANet 对检测到的物体对象类别进行一位有效编码(one-hot),再与前述几何特征进行串联。随后,GANet 将特征值为0 的点视为背景点,使用基于Transformer 的点云编码器从预测的前景点中提取局部几何特征Fo∈RCs。
2.2.3 特征转换器
目标检测器得到的物体特征实际上是包含了物体类别和大小的信息,该特征可作为物体形状生成的先验信息。由于此特征是从整个场景原始点云中提取而来,而从检测框内采样的点云经过了归一化处理,且物体的局部点都处于规范空间中,因此,规范空间中的局部点云特征和真实空间中的物体先验特征是特征不对齐的,这在一定程度上会干扰物体的形状生成。这里,本文设计了一个简单的多层感知机将全局物体先验特征转换到规范空间下。考虑到全局物体先验特征和局部物体几何特征是权重相当的,因此同时利用两个多层感知器(multi-layer perceptron,MLP)将全局物体先验特征从128 维升至512 维,增加特征的表征性,得到转换后的物体特征,具体为
式中,Fp代表目标检测器得到的物体特征,Fg代表转换后的物体特征。
2.2.4 物体点云特征编码器
获取到物体前景点后,本文算法使用AGFA-Net(Liu等,2022)中基于Transformer的多尺度点云特征编码器来获取物体的局部细节特征。图3 为点云特征编码器的结构图。特征编码器的目标是生成一个特征向量Fo,该特征项包含了局部点云的局部几何细节特征和全局形状特征,用于后续的解码过程。为了增强物体特征的表达效果,本文算法同样利用了物体的类别先验信息。具体来说,被保留下来的物体前景点,其几何特征与前述的语义one-hot 向量进行串联,得到语义几何特征矩阵Fge。从实验结果可知,类别编码提供了形状先验,有助于提升物体重建的效果。其中,特征嵌入层由两个MLP 串联组成,用以将输入数据映射到特征空间中,从而更好地拟合深度网络。将Fge输入到特征嵌入层中,生成一个尺寸为Ns× 32 的特征矩阵Fin。然后本文算法对Fge进行FPS,利用其对应的空间索引从Fin里取出尺寸为(Ns/ 2) × 32 的关键点特征矩阵Fin_0。将Fin和Fin_0分别转换为K、V(此处K和V相同)和Q,送入多头注意力层(Vaswani 等,2017)。其中,注意力层得到的特征矩阵与Q构成残差连接。为了增强编码器的表征能力,本文算法利用残差连接的多层感知机以进一步更新特征。更新后的特征与Fin_0进行串联,送入自注意力层(Vaswani 等,2017),得到第1 阶段的特征向量Fin_1。之后本文算法按照这个操作由粗到细迭代3 次,不断提取并融合物体的关键点特征。最后一层经过最大池化后得到一个可表征实例的特征向量Fo。
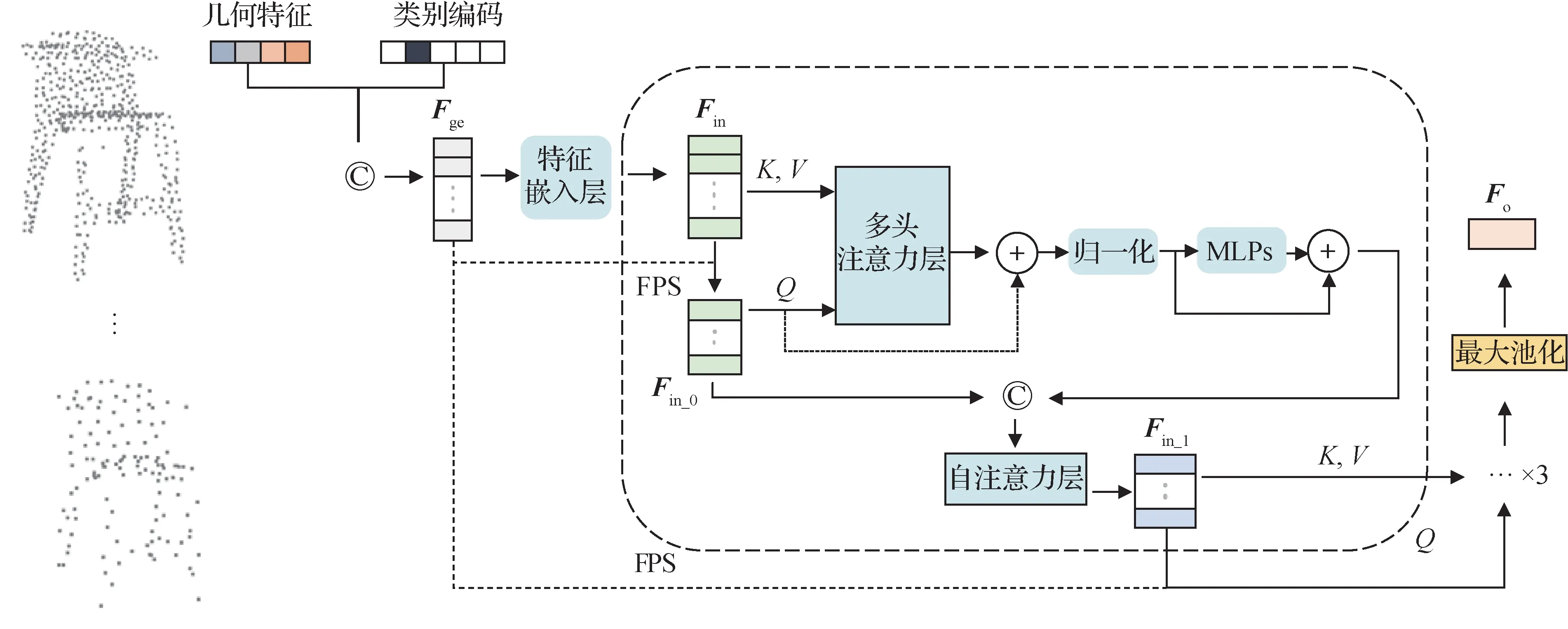
图3 基于Transformer的点云特征编码器结构图Fig.3 The framework of Transformer-based point cloud feature encoder
最后将物体全局先验特征和物体局部细节特征进行串联,送入网格生成器,即
式中,©代表串联操作,Fg代表物体全局先验特征,Fo代表物体局部细节特征,Fm代表融合后的物体特征。
2.3 目标形状生成
本文算法参考OccNet(Mescheder 等,2019),将目标的三维形状表示成一个占用函数,形状生成的过程如下:首先初始化一个立方体,在立方体内统一采样空间点p∈R3,占用函数根据输入的物体特征Fm预测这些空间点的二元占用值o∈{0,1}(0 表示物体表面外,1 表示物体表面内)。具体来说是采用条件批处理归一化层对输入进行处理,使解码器能根据物体的特征来回归每个候选空间点的占用值。另外,本文算法参考RfD-Net 将形状解码器构建为一个概率生成模型。利用OccNet设计的编码器,从输入点p、占用值o和物体特征Fm,预测均值和标准差(μ,α)来近似标准正态分布。对此分布进行采样,产生一个向量z∈Rl。用单层MLP 将p和z处理成等维,然后进行求和,并用5 个条件块来预测空间点最终的占用值o。在推理阶段,本文算法将向量z设置为零,并使用移动立方体算法生成物体网格模型。
本文与RfD-Net 的区别在于:1)采样策略。本文采用一种几何属性引导的目标点盒采样而非固定尺度的球体采样,从而能提取到更多有效的前景点。2)特征编码。RfD-Net 对所有点使用简单的最大池化操作,丢失了许多几何关键信息。本文算法采用一种基于Transformer 的点云特征编码器,可由粗到细地提取局部细节特征。3)特征融合。为了更好地融合局部细节特征和全局先验特征,本文设计了一种特征转换器以进行特征对齐,而RfD-Net 并未考虑该问题。
2.4 损失函数
本文算法的损失函数主要由检测损失和形状重建损失两部分组成。检测损失用于监督检测器所生成的候选物体及其对应相关的检测框参数;形状重建损失用于监督实例重建的训练过程。
2.4.1 检测损失
参考VoteNet,三维目标检测的损失函数包括置信度损失、边界框(中心c、目标大小s、航向角θ)估计损失和语义分类(语义标签sl)损失。具体为
式中,交叉熵损失用于定义置信度损失Lcon,Smooth-L1 损失用于定义中心损失Lc。本文算法将尺度损失Ls和方向损失Lθ定义为分类(交叉熵)损失和回归(Smooth-L1)损失的混合形式。同时,交叉熵损失还用于定义语义分类损失Ll。此外,本文算法利用了一个额外的投票损失Lv。对上述损失进行加权并相加,得到最终的检测损失Ldet。
2.4.2 形状重建损失
首先,对于每个候选目标检测框中的点,本文算法采用交叉熵来监督前景点分割损失Lseg。形状生成器在训练中会学习一个近似标准正态分布的均值和标准差(μ,α),本文算法从此分布中采样一个潜在向量z以预测空间候选点的占用值。最终的形状重建损失为
式中,KL代表KL散度(Kullback-Leibler divergence),Lce代表交叉熵损失函数。和oi,j分别代表第i个正样本物体中第j个空间候选点的预测占用值和真实占用值。代表的是隐式向量zi的预测分布,p(zi)是与之对应的标准正态分布。
最终的损失函数由检测损失和形状重建损失加权求和组成。即
3 实验与分析
本节首先介绍数据集的细节、损失函数、评估指标和实验细节。然后将本文算法GANet与几种最先进的方法进行比较。最后通过消融实验来证明GANet所提出的各个模块的有效性。
3.1 数据集
本文使用ScanNet v2(Dai 等,2017a)、ShapeNet(Chang 等,2015)和Scan2CAD(Avetisyan 等,2019)3 个数据集开展实验测试。ScanNet v2 数据集由1 513 个真实场景扫描数据组成,通常用于三维语义、实例分割和目标检测等任务的性能评估。本文算法采用了与RfD-Net 方法相同的点云预处理操作(在训练和测试数据集中随机采样80 K 个点),并参考RfD-Net 和RevealNet 进行训练集/测试集划分。由于Scan2CAD 已将ShapeNet 中的物体CAD 模型与ScanNet v2 场景中的实例进行对齐,因此本文算法将Scan2CAD 中的物体边界框和对齐的物体CAD 模型作为目标检测和形状生成的监督信息。
3.2 评估指标
本文从三维目标检测和语义实例重建两个方面进行评估。本文参考RfD-Net,使用三维交并比(intersection over union,IoU)阈值为0.5 的平均精度均值(mAP)来评估三维目标检测和语义实例重建的性能。其中,语义实例重建指标衡量的是预测的物体网格在三维场景中与对应完整物体网格之间的重合度。为了进行公平对比,本文采用与RfD-Net一样的设置,对物体进行体素化处理。
3.3 实验细节
本文采用PyTorch 深度学习框架,使用两张NVIDIA GeForce RTX3090 显卡来进行训练。网络的训练分为3 个阶段:目标检测预训练阶段、形状重建阶段和端到端联合训练。训练过程中的batchsize设置为8。预训练阶段采用的初始学习率为1 × 10-3,形状重建阶段采用的初始学习率为1 ×10-4,端到端训练采用的初始学习率为5 × 10-5,每80 个周期减小到原来的0.5 倍。每个阶段的epoch都设置为240。
式(3)的检测损失中,λcon和λl分别设置为0.5和0.1,式(4)中的λseq设置为100,目标检测预训练阶段中式(5)的λ设置为0,形状重建阶段,λ设置为1,联合训练阶段,λ设置为0.005。
3.4 实验结果分析
3.4.1 定量比较
1)语义实例重建方面。本文将GANet方法与现有的方法DIMR、RfD-Net 和RevealNet 进行了比较。与RevealNet 类似,本文还比较了实例分割算法3DSIS(3D semantic instance segmentation)(Hou 等,2019)和形 状完成算 法Shape Completion(Dai 等,2017b)的组合以及扫描完成算法ScanComplete(Dai等,2018)和3D-SIS的组合。
本文算法与其他算法在ScanNet v2和Scan2CAD数据集上的语义实例重建实验结果的对比如表1 所示。其中,“*”代表该方法提供的模型权重文件重新在同一平台上进行推理。由表1 可得,在重建指标mAP@0.5上,本文算法获得了比其他方法更好的性能,在大多数类别上的重建效果都达到了最佳。DIMR采用实例分割—重建的框架。由于场景点云残缺严重,导致其预测的实例位置和尺寸无法与真值精确匹配,从而影响了最终性能。具体而言,GANet方法对浴缸、垃圾桶、沙发和橱柜的语义实例重建精度均值优于整体排名第2 的RfD-Net 方法,主要是因为GANet方法采用先验几何信息引导的盒采样方案,相比固定尺度球体采样方案,获取到了物体更多的有效局部信息。在局部点的几何属性引导下,网络可提取出物体的关键特征,而不是全局的粗略特征,从而使得重建结果的关键结构更符合物体本身。
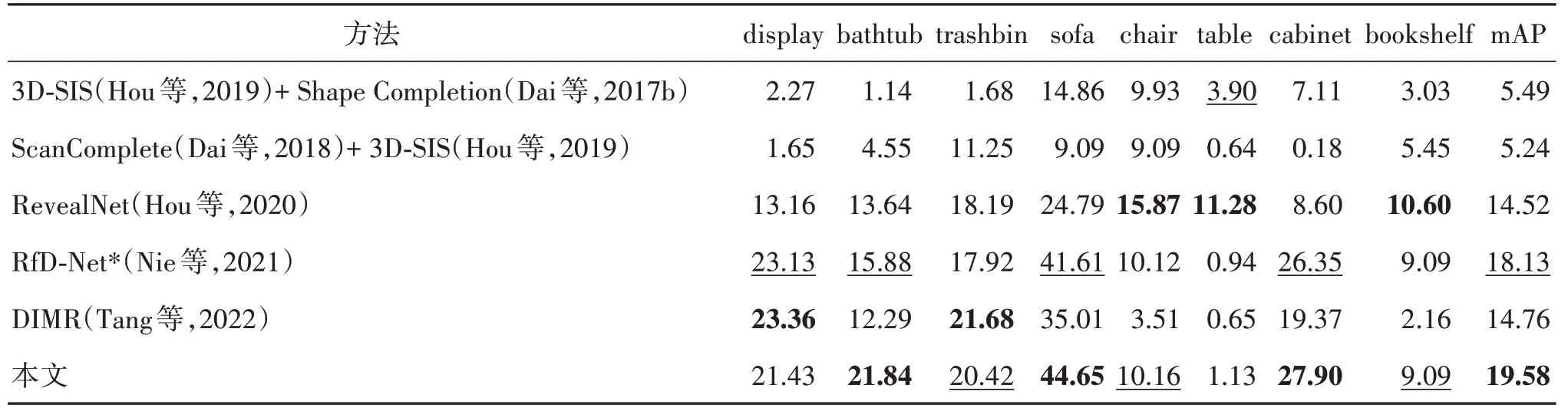
表1 ScanNet v2和Scan2CAD数据集上的语义实例重建实验结果的对比Table 1 Comparisons of semantic instance reconstruction results on the ScanNet v2 and Scan2CAD datasets/%
2)三维目标检测方面。本文算法与现有算法,如3D-SIS、MLCVNet(Xie 等,2020)、RevealNet 和RfD-Net 进行了比较,实验结果如表2 所示。其中,w/o 和w/分别表示未用和已用生成网格结果来优化检测结果。
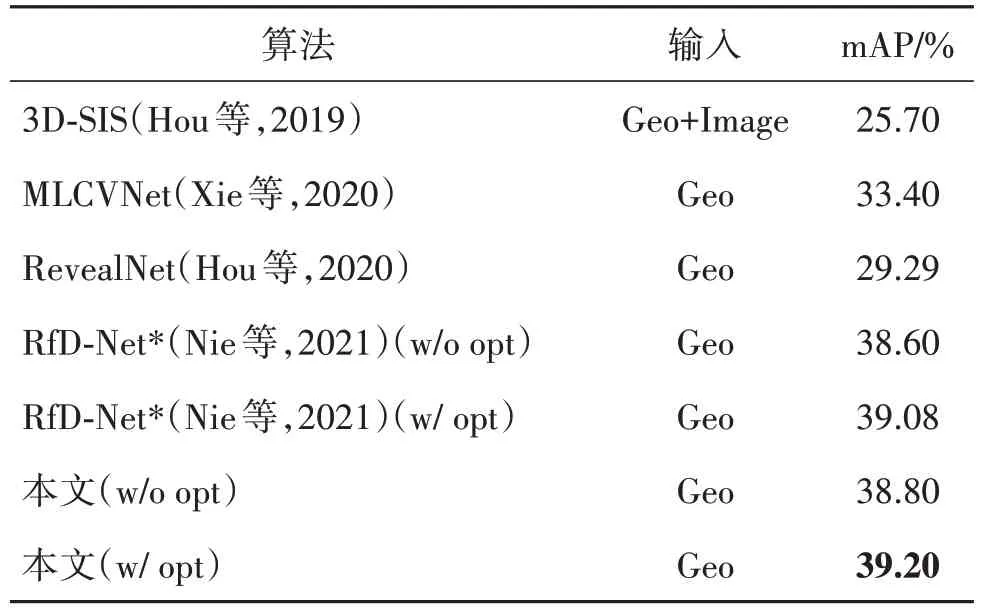
表2 ScanNet v2数据集上的三维目标检测结果对比Table 2 Comparison of 3D object detection results on ScanNet v2
从表2 可以看出,3D-SIS 和RevealNet 的结果较差,主要是因为它们都对场景进行了网格化处理,丢失了物体的几何细节信息。考虑到该问题,MLCVNet方法省略网格化步骤,直接对场景点云进行处理,因此获得了较好的检测性能。由于MLCVNet方法仅对目标检测器进行训练而忽视了形状生成器,导致mAP仍不太理想,仅有33.40%。相比之下,RfD-Net方法融合了目标检测器和形状生成器,并对两者进行联合训练,取得了更高的mAP,即39.08%。但RfD-Net方法在融合过程中引入了过多的噪声信息,且并未执行特征对齐。本文方法GANet通过引入有效的盒采样策略和特征对齐模块很好地解决了上述问题,因此取得了最好的三维目标检测结果。
3.4.2 定性比较
在ScanNet v2测试集上的定性结果如图4所示。在图4第1行可以看到:RfD-Net方法重建出来的桌子和椅子质量不佳,它们相互之间几乎完全重叠。主要是因为场景里的桌子和椅子本身就紧密地靠在一起,球体采样的方案会提取到大量属于其他物体的噪声点,影响重建的效果。本文GANet方法采用检测框盒采样的方案能获取到更多属于目标实例的前景点,减少噪声点的影响。此外,可以观察到DIMR方法所预测的桌子位置和尺寸与真实值有所偏差,主要是因为其采用的点云实例分割技术难以准确地预测残缺物体的尺寸和中心。特别地,若桌子并未与其他物体靠在一起(图4第2、3行)时,RfD-Net方法难以重建出精细的桌子网格模型,而DIMR方法仅能恢复桌面且错误地预测了朝向。相比之下,本文方法能捕获到物体的几何关键信息,更准确地判断候选点的占用情况,恢复出更符合原场景的网格模型。
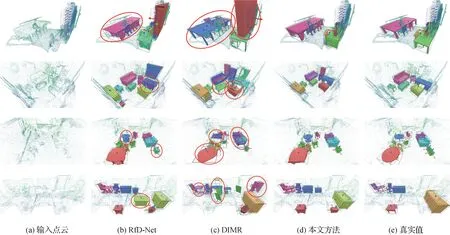
图4 本文算法在ScanNet v2数据集上部分场景进行语义实例重建的定性结果Fig.4 Qualitative results of semantic instance reconstruction for some scenarios on ScanNet v2
3.4.3 消融实验
本文算法的核心设计主要有检测框盒采样、基于Transformer 的物体点云特征编码器、语义先验的嵌入和特征空间转换模块。为了验证各个设计的有效性,本文在真实场景数据集上进行了5 组实验。包括完整的GANet 模型([E]);将GANet 中的检测框盒采样替换为球体采样([A]);将GANet 中的点云特征编码器替换为PointNet 网络([B]);点云编码器和去噪器只有几何信息输入,没有语义先验信息([C]);去掉特征转换模块([D])。
表3 给出了消融实验的结果。其中,w/o 代表缺失相应模块。从结果中可以观测到,检测框采样的方案将实例重建结果的精度从18.60% 提升到19.58%。这是因为检测框采样获取到了更多有效的物体前景点,同时降低了其他物体噪声信息对于重建目标物体的负面影响。对比实验[B]和实验[E],如果本文算法将基于Transformer 的点云特征编码器换成PointNet 网络,结果将降低为17.73%。主要是因为原方案对所有局部点的细节信息只进行简单的最大池化,丢失了物体关键点信息。与完整模型相比,实验[C]的性能下降为18.88%,证明了物体语义先验信息一定程度上能提升物体重建的性能。实验[D]直接将检测器提取的特征与物体局部几何特征串联起来,而本文算法首先通过特征转换器对方案特征进行对齐,然后再进行串联。从表3中可以看出,特征转换器提高了物体重建的性能。
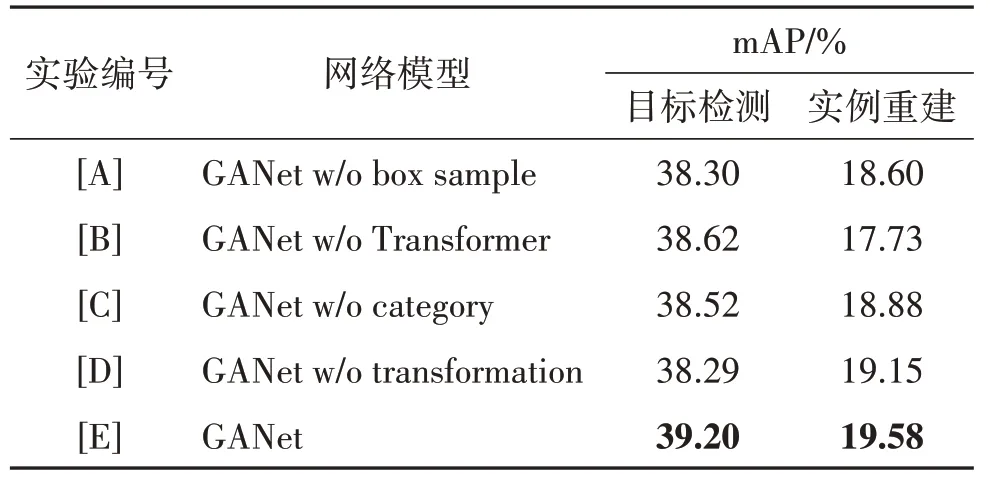
表3 消融实验对比结果Table 3 Comparison results of ablations studies
3.4.4 场景点云对比实验
本文进一步测试GANet算法在不同稀疏性场景点云中的效果。本文算法将场景输入点云的数目固定为20 K、40 K 和80 K,分别进行训练和测试。本文算法在不同稀疏性场景上的结果对比和实例重建效果图分别如表4和图5所示。
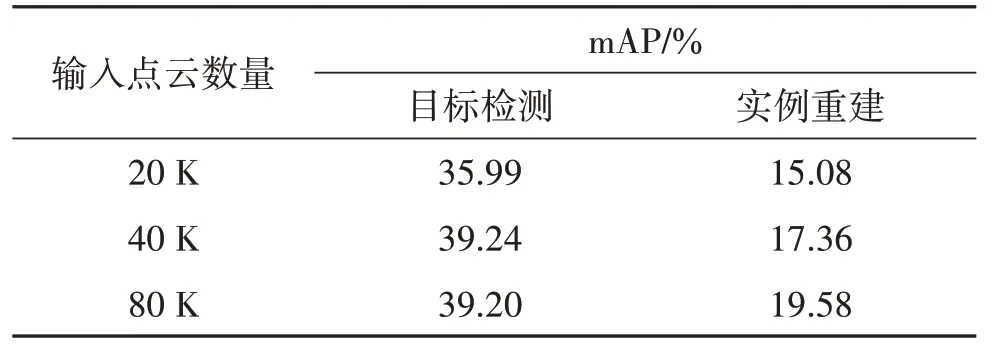
表4 不同规模输入点的比较Table 4 Comparison with different scales of input points
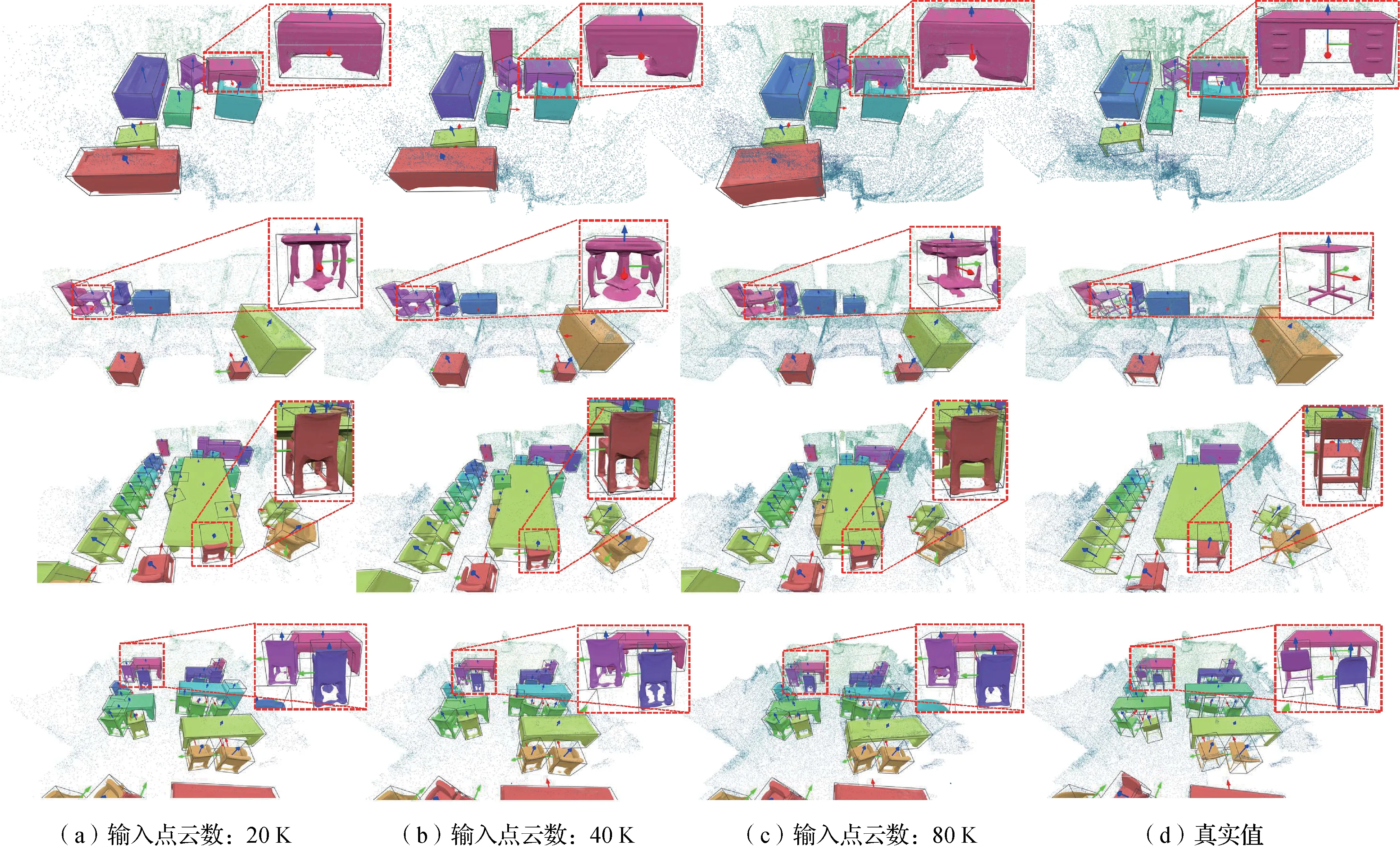
图5 不同点云稀疏度下的实例重建结果对比Fig.5 Comparison of the instance reconstruction results with different point sparsity
表4和图5中的结果表示,即使场景点云非常稀疏,仅有20 K 个点,本文算法依然能得到令人满意的实例重建结果。
4 结论
本文提出了一个新的语义实例重建算法GANet,用于点云的场景物体重建。GANet 有效地利用物体的几何尺度信息,设计了检测框盒采样策略,获取到了更多有效的物体前景点。进一步地,为了有效利用物体的前景点信息,本文算法采用了基于Transformer 的点云特征编码器,以物体的关键几何属性信息为引导,提取物体的关键局部细节特征。同时,物体的语义属性信息的嵌入进一步提升了重建的性能。与RfD-Net 算法相比,本文算法在Scan-Net v2 数据集上取得了8%的实例重建性能提升。但值得注意的是,本文算法依然是基于先理解后重建的框架来完成语义实例重建任务,理解的结果会较大地影响后续的重建结果。因此,如何设计一种更为完善的算法及损失函数,使得理解与重建任务之间可以互相促进,将是未来三维语义实例重建的主要研究方向之一。
猜你喜欢
中学生天地(A版)(2022年11期)2022-11-25
开放教育研究(2020年2期)2020-03-31
新世纪智能(英语备考)(2018年11期)2018-12-29
小学生学习指导(低年级)(2016年10期)2016-12-01
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
外语学刊(2011年1期)2011-01-22
中学生英语·中考指导版(2008年6期)2008-12-19
