
合成数据驱动目标姿态追踪的快速收敛网络
2024-01-22 10:26彭泓王骞贾迪赵金源庞宇恒
中国图象图形学报 2024年1期
彭泓,王骞*,贾迪,2,赵金源,庞宇恒
1.辽宁工程技术大学电子与信息工程学院,葫芦岛 125105;2.辽宁工程技术大学电气与控制工程学院,葫芦岛 125105
0 引言
在视频序列中精确追踪目标的6D 姿态是虚拟现实(virtual reality,VR)、增强现实(augmented reality,AR)和机器人操作领域的一项重要任务。可将现有方法分为两类:1)基于检测的姿态估计方法(Issac 等,2016;Sundermeyer 等,2018;Xiang 等,2018;Mitash 等,2019;Wang 等,2019b;Li 等,2019;Deng等,2020;He等,2020);2)基于跨时间的姿态估计方法(Choi 和Christensen,2010;Wüthrich 等,2013;Tobin 等,2017;Tremblay 等,2018b;Deng 等,2019;Marougkas等,2020;Wen等,2020a;李冬冬 等,2022)。
基于检测的姿态估计方法通常通过对目标关键点信息进行匹配(Hinterstoisser 等,2012)或通过点对特征获取全局模型描述(Drost 等,2010;Guo 等,2021)来实现姿态估计。现有这类方法在模板匹配的基础上加入PnP(perspective-n-point)算法,以求解物体局部2D—3D 特征一致性估计物体姿态(Collet等,2011)。这类方法的缺点在于面对复杂场景环境时鲁棒性较差,当场景或目标物体发生改变时需要手动更新网络中的大量超参数。现阶段,估计单张快照中物体姿态的方法已较为成熟,例如NOCS(normalized object coordinate space for category-level 6D object pose and size estimation)(Wang等,2019b)、6-PACK(category-level 6D pose tracker with anchorbased keypoints)(Wang 等,2020)、CASS(learning canonical shape space for category-level 6D object pose and size estimation)(Chen 等,2020)和FS-Net(fast shape-based network for category-level 6D object pose estimation with de-coupled rotation mechanism)(Chen 等,2021)等方法。估计视频序列中目标姿态的结果要求平滑且连贯,将Tremblay等人(2018b)和Wen 等人(2020a)的估计单张照片的方法应用于连续视频序列中可能导致相邻帧姿态估计不一致的错误结果,此外计算数据冗余度高、网络计算成本高昂和追踪速度有限等弊端影响了这种方法的实时性应用。Chen 等人(2020)和Chen 等人(2021)的方法可以准确计算目标物体的位置并估计目标物体的三维边框,但无法满足估计目标6D 姿态的要求,如追踪机械操控下的目标6D姿态(杨步一 等,2021)。
基于跨时间的姿态估计方法通过捕捉视频序列中目标的连续时空信息估计其姿态。在早期工作中,Choi 和Christensen(2012)通过提取目标特征估计物体姿态,如提取目标关键点或物体边缘信息,缺点是在复杂场景或目标姿态大幅度改变的情况下追踪精度不足。随着深度传感器的发展,基于RGB-D(red,green,blue,depth)数据驱动的姿态追踪方法极大改善了目标姿态估计的准确性(Prisacariu 和Reid,2012;Schmidt 等,2014;Pauwels 等,2016;Tjaden 等,2016,2017;Zhong 等,2018;Deng 等,2019;Wen 等,2020a;Marougkas 等,2020;Li 等,2020;Wen 和Bekris,2021)。Prisacariu 和Reid(2012)提出的PWP3D(real-time segmentation and tracking of 3D objects)网络采用一种优化目标CAD(computer-aided design)轮廓投影的方法,Wang 等人(2019a)提出的DenseFusion(6D object pose estimation by iterative dense fusion)网络在RGB信息的基础上结合深度信息,建立目标点云作为网络输入迭代求取目标姿态,Wüthrich 等人(2013)改善了目标被遮挡条件下的姿态估计问题,Issac 等人(2016)在RGF(robust Gaussian filter)网络中采用高斯滤波来提高姿态估计的精度。Liu 等人(2023a)在SSA-Net(joint spatial and scale attention network for multi-view facial expression recognition)中通过空间注意力机制和尺度注意学习的方式实现了更为准确的多视角面部表情识别。以上大部分实例级姿态估计方法需要通过大量手工标注的真实数据训练网络,以此满足真实场景中的使用要求,在目标物被严重遮挡和剧烈位移时鲁棒性不足,易产生错误的姿态估计结果。
相较于目标姿态估计的任务,追踪目标6D姿态更具复杂性和挑战性,主要指标包括严重遮挡条件下的鲁棒性、实时追踪效率和累计误差等。一个性能优异的追踪网络训练需要以大量手工标记的真实数据作为支撑,复杂的位置信息和昂贵的数据收集成本成为追踪目标6D姿态的制约条件。近年来,互联网上出现的大量3D 模型加快了深度学习在追踪目标姿态领域的发展,显著提高了姿态估计的准确性和鲁棒性,Wen 等人(2020b)和Tekin 等人(2018)解决追踪目标姿态精度不足的问题,Deng 等人(2019)和Li 等人(2020)克服目标物被严重遮挡条件下目标物姿态估计缺乏鲁棒性的困难。Xiang 等人(2018)提出的PoseCNN(convolutional neural network for 6D object pose estimation in cluttered scenes)网络给出一种基于目标点对点框架下的语义分割与计算目标旋转和平移的方法。Redmon 等人(2016)提出的YOLO(you only look once)网络通过估计图像中目标三维边框提高物体姿态估计精度。Kehl等人(2017)提出的SSD-6D(making RGB-based 3D detection and 6D pose estimation great again)网络在目标姿态估计中加入视觉点分类提高了室内物体检测精度。Peng 等人(2019)在PVNet(pixel-wise voting network for 6D of pose estimation)网络中引入像素投票机制,对关键点像素进行回归解决了多物体场景下的姿态估计问题。Li 等人(2020)在DeepIM(deep iterative matching for 6D pose estimation)网络通过采用Dosovitskiy 等人(2015)提出的FlowNet(learning optical flow with convolutional network)网络结构迭代渲染姿态和估计姿态,以此提高追踪精度及平滑度。Deng 等 人(2019)在PoseRBPF(Rao-Blackwellized particle filter for 6D object pose tracking)网络通过解耦目标物体三维位置和方向提高了目标追踪性能。Tjaden 等 人(2016)采 用GPU(graphics processing unit)并行的计算方式提高了实时追踪的效率。在此基础上,Tjaden 等人(2017)采用不同时间序列下的局部色彩直方图来提高姿态追踪的性能。Liu 等人(2023b)提出表情片段转化器(expression snippet transformer,EST),将连续的表情动作分解为一系列的表情片段,并提高了转化器在片段内和片段间的视觉建模能力,以此提高在连续视频中对表情识别的准确率。这类方法尽管降低了真实数据采集难度,但高昂的数据标注成本降低了这类方法的实用性(Choi和Christensen,2012;Chen等,2021)。
合成数据可以模拟目标的真实碰撞和重力属性(Mitash 等,2017;Tremblay 等,2018a),缺点是物理属性(如光照、镜头等)模拟效果较差(Ge和Loianno,2021),缩小合成数据与真实数据间差距成为难点(Tremblay 等,2018a)。合成数据在训练过程中为网络提供足够的模拟变量(Tobin 等,2017),前期的工作重点落在域随机,如物体、姿态、纹理和光照,合成数据中的目标姿态从预置姿态中直接采样(Tobin等,2017;Xiang 等,2018;Deng 等,2019),使网络更容易提取到目标的特征信息。Wen 等人(2020a)提出一个物理可行域随机化管道(physically plausible ddomain randomization,PPDR)在域随机的基础上加入深度信息,从预置姿态推广到随机初始姿态,同时随机生成纹理、光照和干扰物体等数据,增强了网络在不同环境下目标姿态追踪的鲁棒性。以上方法在追踪过程中需要人工重新初始化目标姿态来消除累计误差,重新初始化的时间成本较高,无法满足真实场景下的使用需求。Dong 等人(2021)提高了无纹理目标追踪的准确性,Sun 等人(2021)提高了模糊目标追踪的准确性,Zhu 等人(2021)提高了外观骤变目标追踪的准确性。Wen 等人(2020a)提出的se(3)-TrackNet(data-driven 6D pose tracking by calibrating image residuals in synthetic domains)网络通过分解特征编码来辅助减少姿态估计过程中产生的域偏移,实现了在视频序列中对目标6D姿态估计长期追踪的稳定性。Ge 和Loianno(2021)提出的VIPose(real-time visual-inertial 6D object pose tracking)网络采用一种新的DNN(deep neural network)网络架构,通过融合目标图像与其惯性特征来估计连续图像帧间的相对6D 姿态。Liu 等人(2023c)提出动作正向分离学习(action-positive separation learning,APSL)方法,通过特征分离、聚类和定位计算视频序列中的目标动作。以上这些工作采用合成数据替代真实数据训练,降低了数据的采集成本,但需要通过大量合成数据训练才能达到真实场景使用需求,网络收敛性能有待提高。
为了解决上述问题,本文提出一种合成数据驱动目标6D姿态追踪的快速收敛网络,通过迭代计算目标物体在连续帧中的时空特征信息获取其三维旋转与平移矩阵,对矩阵做指数映射得到旋转和平移差异,以此获得实时目标姿态追踪结果,主要贡献点如下:1)提出一种快速收敛的目标实时6D姿态追踪网络结构。该网络使用少量合成数据驱动,与现有姿态追踪方法相比,着重提取连续帧中目标时空变化信息来预测其相对姿态,采用李代数se(3)表示物体的三维移动和旋转,通过李群SE(3)表示刚体的6 维姿态变换并计算预测差异,提高了姿态估计的准确性。2)给出一种残差采样滤波模块结构,通过残差映射增强了网络对目标特征的学习能力,相较于其他姿态追踪网络更加关注相邻帧间的姿态差异,在严重遮挡条件下仍然保持目标的高精度姿态追踪性能。3)给出一种特征聚合模块结构,将特征通道分割为两个不同方向的一维编码,分别沿时间和空间方向捕获长程依赖并保留位置信息,生成一组位置敏感和时间感知的互补特征图,从而增强目标6D姿态的特征提取能力,间接加快网络收敛速度。
与其他姿态追踪网络相比,本文方法较好地利用了相邻帧间目标相对姿态变化信息,在提取特征时引入信息的时空差异,能够更好地估计目标6D姿态,提高网络收敛速度。通过在数据集YCB-Video(Yale-CMU-Berkeley-video)和 YCBInEoAT(Yale-CMUBerkeley in end-of-arm-tooling)上进行实验,并与近年来的相关方法进行定性、定量对比,本文方法在收敛速度、精度及追踪性能上均获得了最优结果。
1 方 法
6D 姿态追踪的目的是连续地估计视频序列中目标与相机间的位姿变换,可通过矩阵[ρ,θ]表示,其中ρ和θ分别为目标的三维平移与旋转。在构造数据集阶段,通过对PPDR 管道生成的数据做增强处理,包括随机对象和干扰物的物理特性,如位置、姿态、纹理、光照和对比度等,提高模型在复杂场景下的通用性。在数据预处理阶段,对训练图像采用旋转、平移、缩放、增加高斯噪声和遮挡部分深度信息等操作增加数据集的多样性,提高模型的泛化能力和网络对特征的敏感性,降低模型的过拟合风险,提高网络学习目标特征信息的能力。
网络的总体结构如图1 所示,采用模型信息渲染视频序列第1 帧(t=0)目标的初始姿态P0,将当前帧Ot(t>0)与前一帧(t-1)的目标估计姿态Pt-1作为网络输入,计算目标的相对姿态变化ΔPt,并与Pt-1叠加输出t帧的预测姿态Pt。

图1 目标6D姿态追踪流程Fig.1 Target 6D pose tracking process
1.1 网络整体结构
网络设计如图2 所示,输入一组大小为H176×W176×C4的当前帧RGB-D 图像Ot与前一帧姿态估计 结果Pt-1(H176×W176×C4代表长 为176、宽 为176、通道数为4的图像),通过PostTransforms模块生成一组4 维张量τ(Ot)和τ(Pt-1),分别输入到特征编码器φA(τ(Ot))和φB(τ(Pt-1))中,经升维残差采样滤波处理后,通过特征编码器α(φB(τ(Pt-1)) -φA(τ(Ot)))获得姿态差异δt,即
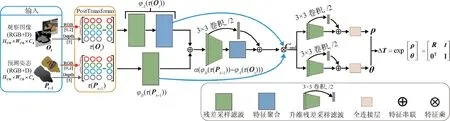
图2 网络整体结构Fig.2 Overall network structure
式中,α(·)为鲁棒损失函数,φ(·)为经编码器后的像素强度值(Engel 等,2018),通过特征乘操作将姿态差异δt与特征编码器φA,φB的结果进行融合,具体为
式中,MLP为共享多层感知机(multilayer perceptron,MLP),⊕用于串联同维度特征,λ为特征差异权重,用于估计t时刻目标的三维平移ρ、旋转θ及相对姿态ΔPt。由相对姿态ΔPt与前一帧的估计姿态Pt-1计算获得当前估计姿态Pt,其中最优相对变换解为
式中,J为物体姿态Pt的雅各比矩阵,结合式(4)和式(3),得到
相邻帧间姿态张量τ(Ot)和τ(Pt-1)的冗余信息越多,相对姿态ΔPt估计越准确。将损失函数L定义为目标移动与旋转损失,采用均方误差(meansquare error,MSE)进行计算,具体为
式中,N为待测样本数量,yi为样本标签表示样本预测概率。根据本文需求对MSE 进行修改,给出损失函数L的定义,具体为
式中,K1和K2为目标物体三维平移和旋转的权重系数,本文方法中K1和K2的初始值为1,ρ与θ为目标的三维平移与旋转分支预测值。采用李群SE(3)对目标三维平移与旋转表示为
式中,R和t分别为目标的旋转和平移向量,R 为域空间。对李群SE(3)做对数映射得到李代数se(3),李代数se(3)的每个6维向量元素ξ表示为
式中,ρ表示前三维平移,θ表示后三维旋转。对李代数做指数映射获得李群SE(3)。由式(9)(10)获得分支差异预测ΔT,具体为
式中,exp 表示指数映射,Δξ表示预测李代数se(3)的6维向量预测元素。
1.2 残差采样滤波模块
图3(a)为残差采样滤波模块图,用于保持图像分辨率的同时提取图像特征。图3(b)为升维残差采样滤波模块图,用于特征编码器α与解耦目标姿态获得位移与旋转矩阵。
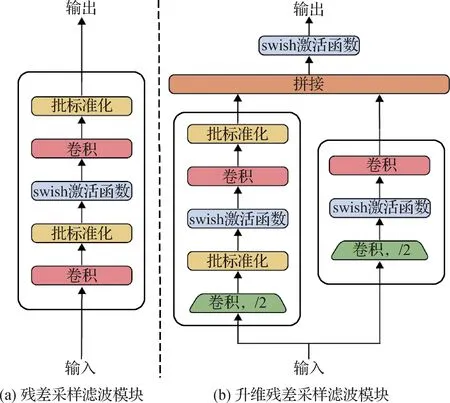
图3 两种残差采样滤波模块Fig.3 Two types of residual sampling filter modules
将图像输入至残差采样滤波模块处理,可根据输入通道数和输出通道数选择是否对图像进行升维,令残差采样滤波模块输出为y,计算过程为
式中,f(·)为对图像进行网络传播,残差映射f1(·)与f(·)的区别为首次卷积是否降低图像分辨率并提升维度。fRSF(·)为对输入x的残差采样,残差采样滤波后将残差映射f1(·)与fRSF(·)进行拼接获得结果y。cin和cout为图像的输入和输出通道数。
ReLU(rectified linear unit)激活函数在深度学习中的性能优异,缺点是参数复杂,需要多次手动调整(Glorot 等,2011)。本文采用自门控swish 激活函数s(x) 对于物体边缘特征进行保留(Ramachandran等,2018),相较于ReLU 函数,swish 函数具有更加平滑的导数,在深层网络中可以更准确地估计目标姿态。
图4(a)为swish 函数图 像,当x→+∞,则s(x) →x;当x→-∞,则s(x) →0;当x>0 时,函数不会出现梯度消失的情况。图4(b)为swish 导数函数图像,函数处处可导且具有不饱和、平滑和非单调的特点,输入接近0 时仍可保持线性增长,避免梯度消失等问题。令swish激活函数为
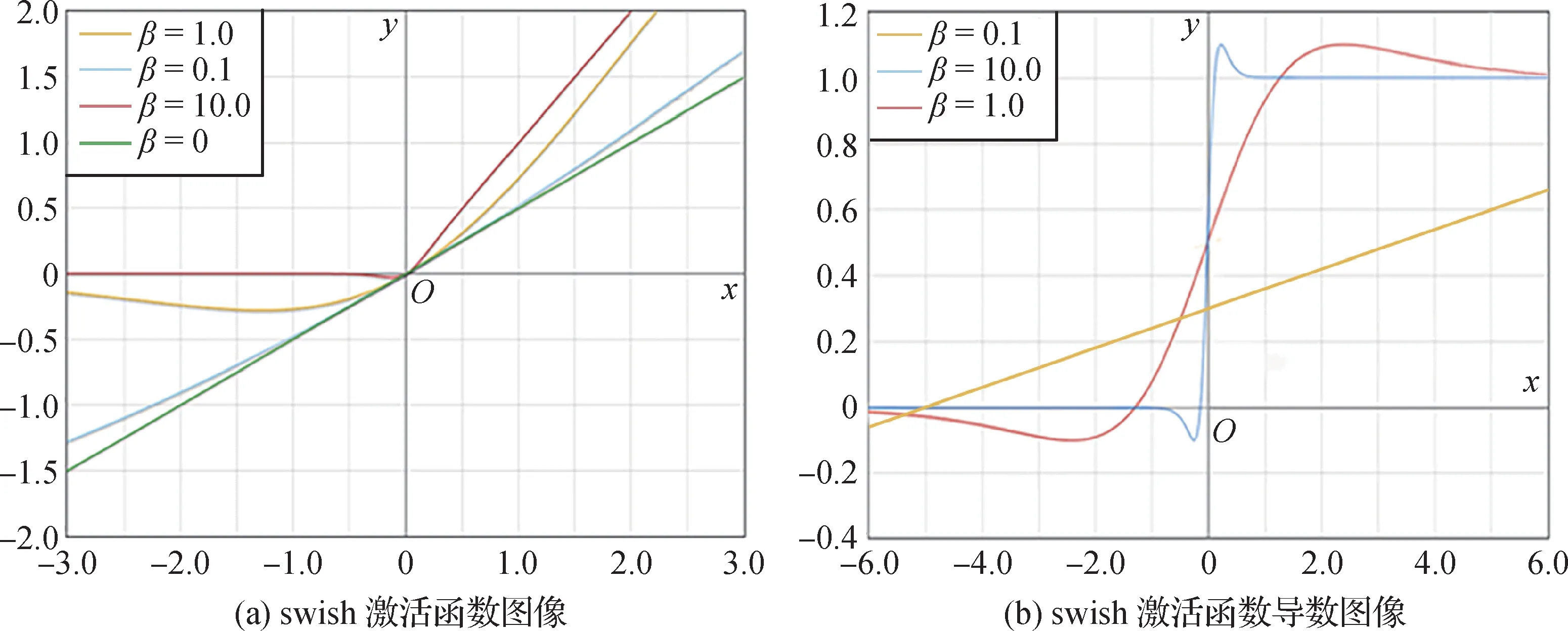
图4 swish函数及其导数图像Fig.4 The swish function and its derivative images
式中,β为常量,在本文方法中取值β=1,σ(x)计算为
函数σ(x)的导数σ′(x)为
可得函数s(x)的导数s′(x)为
1.3 特征聚合模块
Wang 等人(2019a)和Zhou 等人(2021)在编码—解码框架的最后一层将分支特征关联,忽略了相邻帧间姿态的差异。本文提出一种新的分层特征聚合模块解决该问题,通过自动计算特征间差异的权重,获得更多特征信息并加强相邻帧间的特征差异。将特征分解为水平(H,1)与垂直(1,W)方向的分量,通过聚合获得一维特征编码,分别沿时间和空间方向捕获长程依赖并保留位置信息,生成一组具有位置与时间感知的互补特征图,以此加强目标特征提取能力,丰富的特征也将加快网络收敛速度。如图5所示。
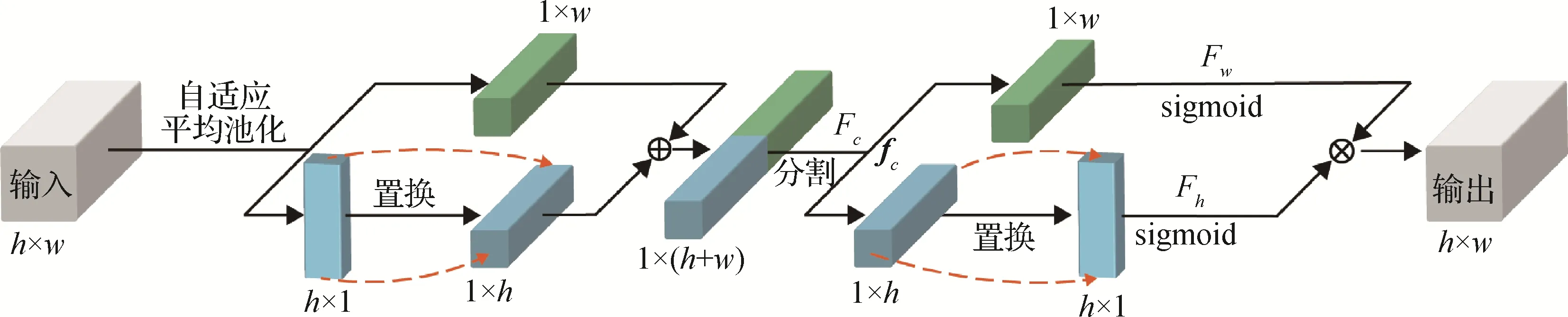
图5 特征聚合模块Fig.5 Feature aggregation module
水平分量在w处的输出通道数和垂直分量在h处的输出通道数具体为
式中,x为输入图像通道数,h和w为图像的长与宽。
通过自适应平均池化提取不同分量特征,将h×1 大小的垂直分量置换获得1 ×h大小的水平分量,与另一个大小为1 ×w的水平分量串联后输入到1 × 1 的卷积变换函数Fc,以此获得水平方向和垂直方向编码的中间特征图fc,中间特征图fc的表示为
式中,⊕为向量拼接操作,s(·)为swish 激活函数,zh和zw为垂直分量和水平分量在h和w处的输出。分割中间特征图fc获得1 ×w大小的水平分量tw和经置换操作得到的h× 1 大小的垂直分量th,分别通过sigmoid 函数处理后获得水平分量Tw=fsigmoid(Fw(tw))及垂直分量Th=sigmoid(Fh(th))。式中,Fw和Fh为反卷积变换操作,用于还原水平分量和垂直分量的图像通道数。水平分量Tw和垂直分量Th经过向量乘⊗后得到输出y(i,j),即
通过向量乘的操作融合时空信息提取图像关键特征,在卷积变换Fc中将图像通道降低至max(8,Cin/8),以降低数据计算量,确保输入和输出图像大小及通道数相同。
2 实 验
本文采用两种指标ADD(average distance of model points)和ADD-S(average closest point distance)评估对称及非对称目标追踪的准确率,使用曲线下面积(area under curve,AUC)衡量两种评估指标的优劣(Xiang等,2018),具体为
式中,m为样本数,R和T是物体真实的旋转和平移量,是预测的旋转和平移量,AUC 最大误差阈值为0.1 m。对于非对称目标,常采用ADD 指标评估姿态估计的准确性,计算模型每个预测点到真实点的欧几里德距离,并将这些距离求和后取平均值;对于对称目标,采用ADD 指标进行评估不够合理,这是由于同一图像中对称目标可能存在多个正确姿态,而ADD-S 通过将真实模型和预测模型分别投影到对称面上,再计算投影点间的平均距离,更适用于对称目标的姿态追踪结果评估。
实验采用数据集YCB-Video与YCBInEoAT评估相关方法性能。YCB-Video 数据集包含严重遮挡条件下移动相机拍摄的复杂场景,YCBInEoAT 数据集为机械臂对目标移动的场景。通过两种不同数据集验证网络的通用性和鲁棒性,消融实验用于评估各模块对于网络的作用。
网络训练和验证使用合成数据,评估使用真实视频序列,实验在IntelCore i7-8700@3.2 GHz 处理器和NVIDIA RTX 3060 GPU的台式机上进行。
完整数据集中每个目标含有约230 000 组大小为H176×W176的图像,容量约15 GB。网络训练采用自适应学习率优化Adam 算法,在参数更新时通过动量和自适应学习融合相关梯度信息,进一步加快收敛速度。通过在不同epoch 轮次中对学习率进行自适应调整,有效地处理了不同参数间的梯度差异,加速模型的收敛并减少过拟合风险,使训练过程更加稳定。训练时batch size设为80,采用300个epoch训练,起始学习率为0.01,从第100 个epoch 和第200 个epoch 起,分别设置0.9 和0.99 作为衰减率参数。
2.1 YCB-Video数据集与实验
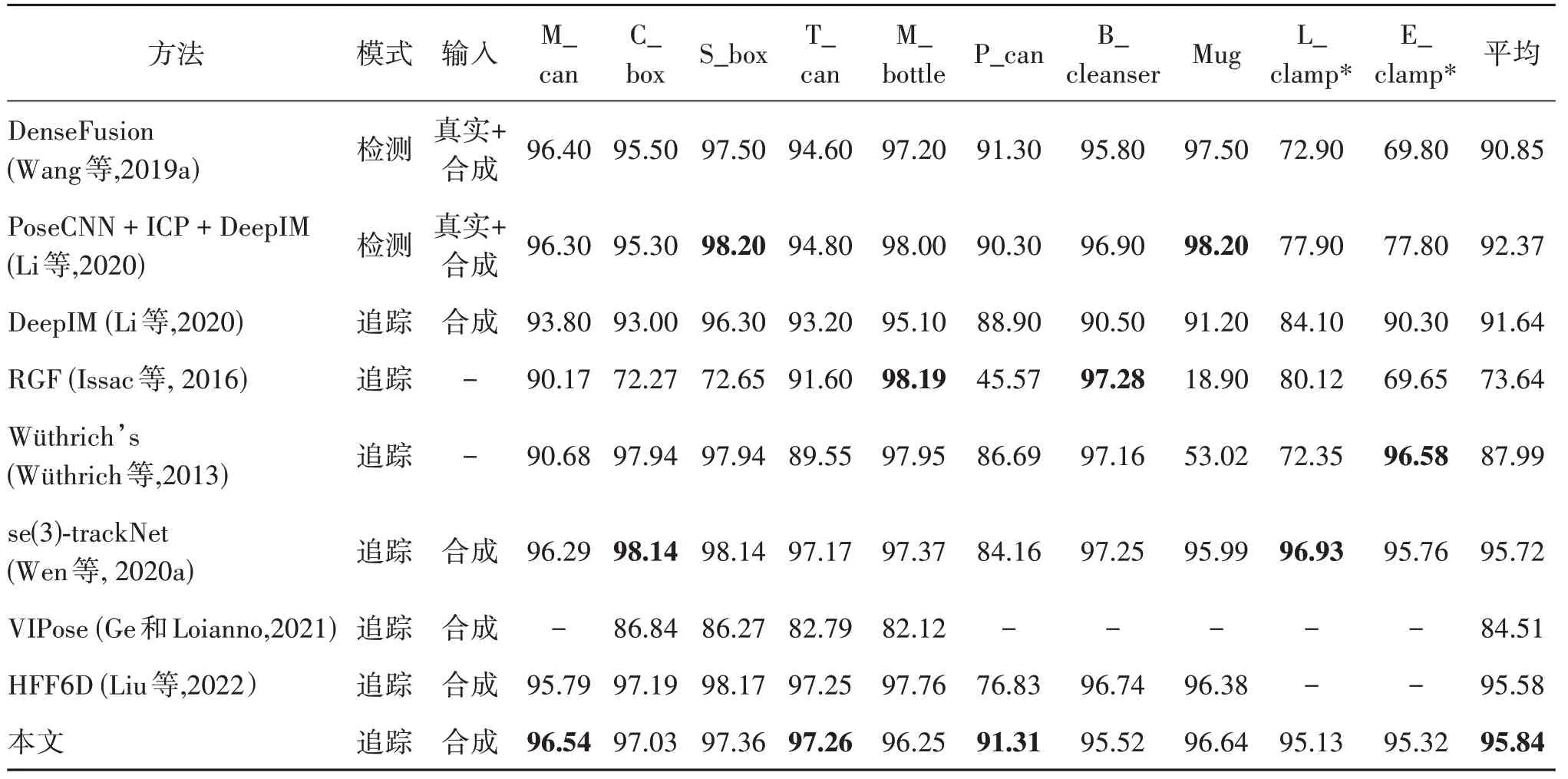
表1 不同方法在YCB-Video数据集上的ADD-S结果Table 1 ADD-S of different methods on the YCB-Video dataset
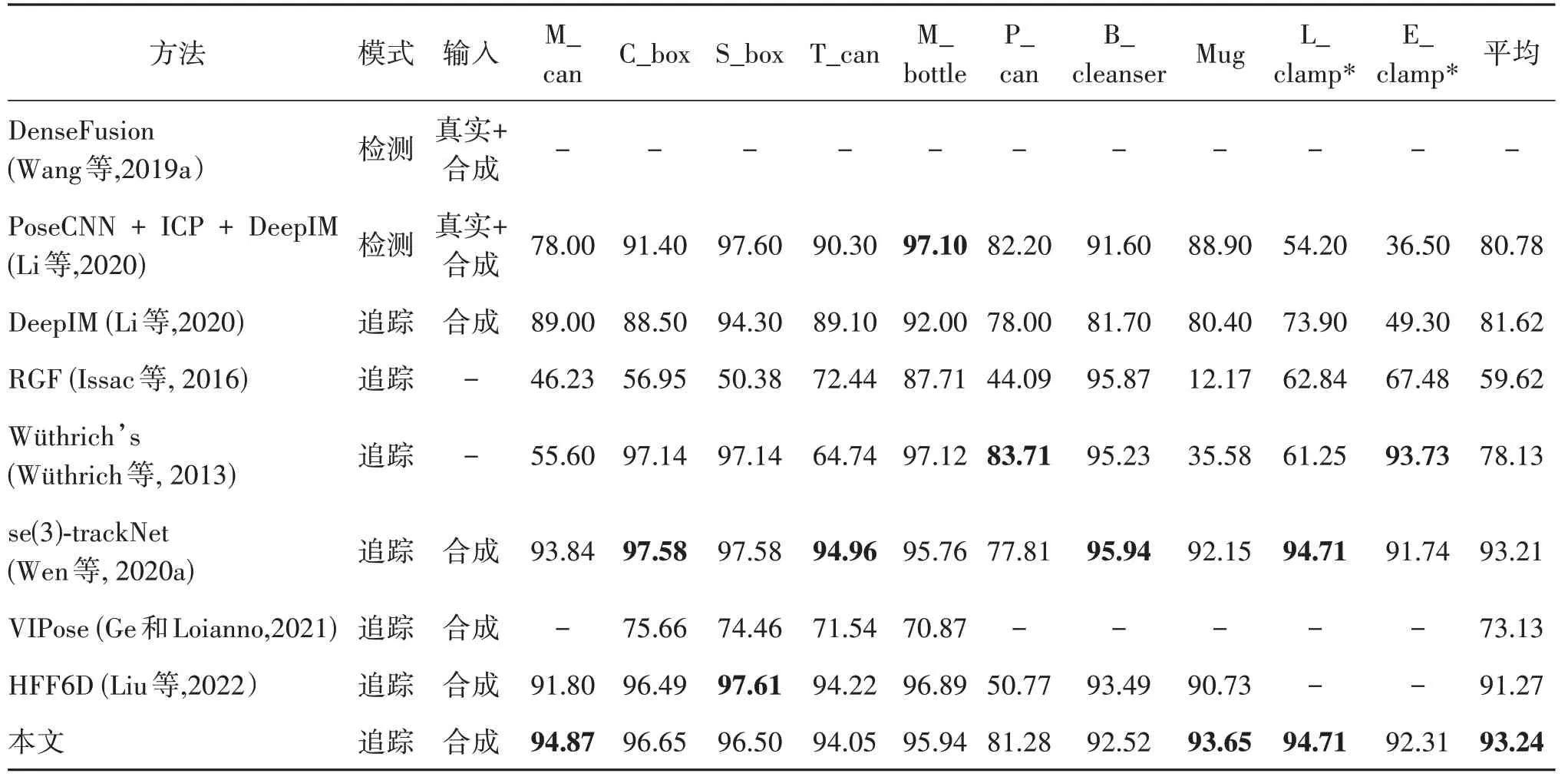
表2 不同方法在YCB-Video数据集上的ADD结果Table 2 ADD of different methods on the YCB-Video dataset
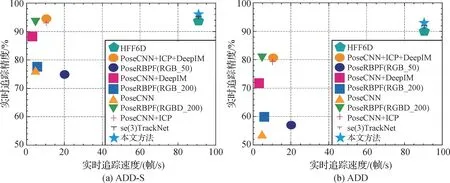
图6 不同方法在YCB-Video和YCBInEoAT数据集上的综合评估结果Fig.6 Combined evaluation results of different methods on the YCB-Video and YCBInEoAT datasets((a)ADD-S;(b)ADD)
2.2 YCBInEoAT数据集与实验
现有公开的常用数据集采用移动镜头对静置目标进行拍摄,由于目标物缺乏物理运动,不能完全反映网络对运动中目标的6D 姿态追踪性能。YCBInEoAT数据集包含5个YCB目标物的运动视频序列,由Yaskawa Motoman SDA10f 双臂机器人对目标物动态操纵,包括单臂夹取与放置、臂内运动和旋转等,模拟了现实场景中可能出现的情况。视频包含5 个YCB 物体,如图7 所示,分别为清洁剂(bleach cleanser)、芥末 瓶(mustard bottle)、番 茄汤 罐头(tomato soup can)、糖 果盒(sugar box)和饼 干盒(cracker box),5个YCB目标均为对称物品,选取ADD作为主要评估指标,ADD-S作为辅助评估指标。

图7 YCBInEoAT数据集中的目标物3D模型Fig.7 3D model of the target in the YCBInEoAT dataset
本文方法与同类相关方法在YCBInEoAT 数据集上的评估结果如表3和表4所示。可以看出,本文方法在平均ADD指标上获得了最高分数93.26。
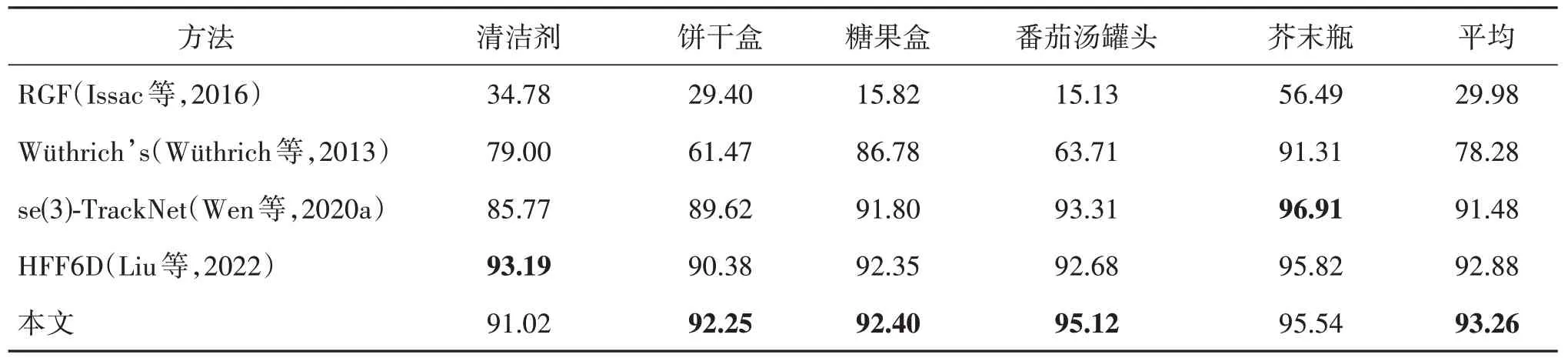
表3 不同方法在YCBInEoAT数据集上的ADD结果Table 3 ADD of different methods on the YCBInEoAT dataset
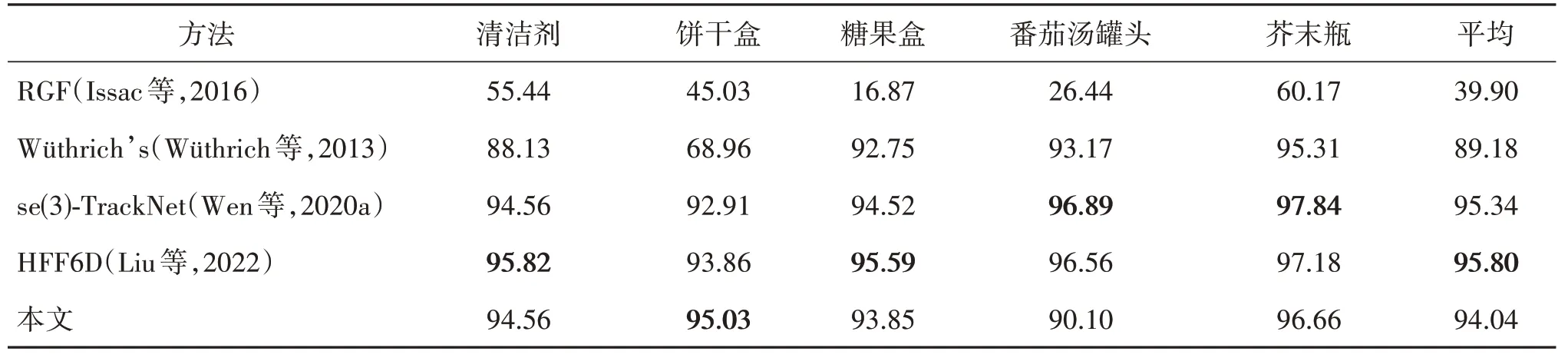
表4 不同方法在YCBInEoAT数据集上的ADD-S结果Table 4 ADD-S of different methods on the YCBInEoAT dataset
Wen 等人(2020a)提出的se(3)-TrackNet 网络在完整YCBInEoAT 数据集上通过84 h 的训练收敛,与se(3)-TrackNet网络相比,本文使用少量YCBInEoAT数据集训练,分别选取5 个YCB 目标物的6 000、8 000 和10 000 组数据对比,实验结果如表5 和表6所示。结果表明,本文方法的追踪性能指标均显著好于se(3)-TrackNet 网络。对10 000 组数据训练,指标ADD 和ADD-S 可达89.38 和94.01,网络收敛时间约为4 h。

表5 本文方法与se(3)-Track Net(Wen等,2020a)在少量YCBInEoAT数据集上的ADD结果Table 5 ADD of the proposed method and se(3)-TrackNet(Wen et al.,2020a)on a small number of YCBInEoAT dataset

表6 本文方法与se(3)-TrackNet(Wen等,2020a)在少量YCBInEoAT数据集上的ADD-S结果Table 6 ADD-S of the proposed method and se(3)-TrackNet(Wen et al.,2020a)on a small number of YCBInEoAT dataset
综上,本文方法在少量合成数据(10 000 组,约600 MB 大小)驱动条件下的目标6D 位姿追踪效果显著,优于现有同类方法,在采用完整数据集(230 000 组,约15 GB 大小)训练条件下,追踪指标均高于同类方法,实时追踪速度可达90.9 Hz。采用本文方法训练10 000 组数据,可视化追踪结果如图8 所示,分别包含严重遮挡、机械臂抓取、移动、放置和旋转等操作,以此测试本文方法和se(3)-Track-Net 对连续变化条件下的目标追踪性能。清洁剂经10 000 组数据训练后可投入现实场景中使用,其余4 个目标均可在8 000 组数据训练后达到实际场景使用要求。实验结果表明,se(3)-TrackNet 在同样数量的数据训练后,目标物体的姿态与真值差异较大,本文方法在复杂场景中仍然可以获得与目标位姿真值相近的结果,满足真实场景中对目标姿态的追踪需求,验证了网络的有效性和鲁棒性。

图8 本文方法与se(3)-TrackNet在少量YCBInEoAT数据集上的不同场景追踪结果对比Fig.8 Comparison of different scene tracking results between the method in this paper and se(3)-TrackNet on a small number of YCBInEoAT dataset((a)severe occlusion scene;(b)robotic arm grasping target object scene;(c)displacement scene;(d)placement scene;(e)rotation scene)
为了验证本文方法的收敛性能,在YCBInEoAT少量数据集上将本文方法和Wen 等人(2020a)的se(3)-TrackNet 网络进行比较,结果如图9 所示。纵轴采用式(8)的均方误差损失函数L计算预测结果与旋转和平移的真值损失均值,其中,平移和旋转权重系数K1,K2的初始值均为1。与se(3)-TrackNet(图9 中红色曲线)表现相比,本文方法(图9 中蓝色曲线)在前200 迭代轮次中的损失振荡更小,且误差损失下降较快;在200~300 迭代轮次中误差损失更低,体现出本文方法具有更快的收敛速度。
2.3 消融实验
为了验证本文方法的有效性,在YCBInEoAT 数据集上进行不同模块的消融实验,如表7 所示。采用3个YCB 目标物的10 000组数据训练作为评估基准,验证不同模块的有效性。
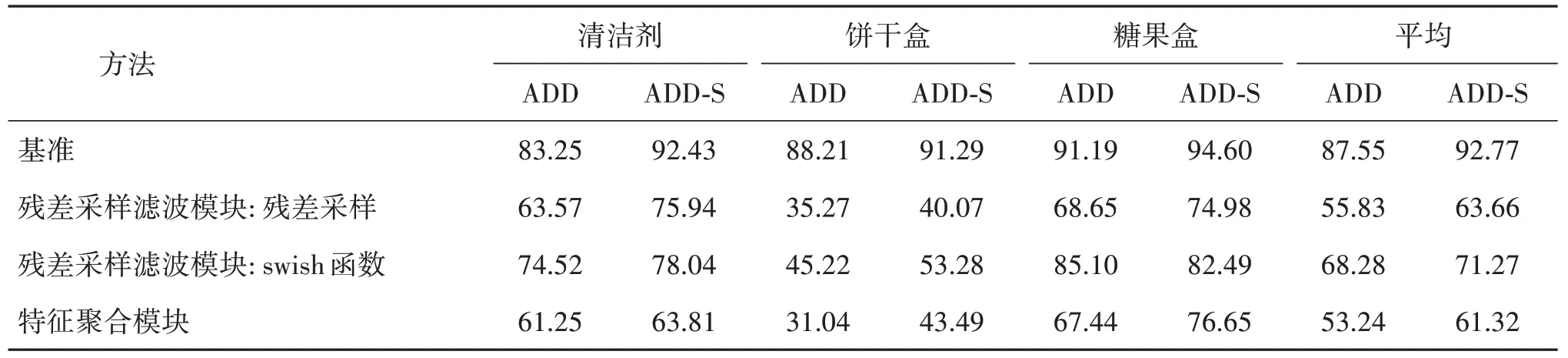
表7 消融实验:在YCBInEoAT数据集上评估不同模块对于网络的作用Table 7 Ablation experiment:evaluate the roles of clifferent modules for the network on the YCBInEoAT dataset
1)残差采样滤波模块。从网络中去除残差采样滤波模块进行实验,实验结果如表7 所示,未采用残差采样滤波模块的ADD 和ADD-S 评估指标得分为55.83 和63.33,与基准的ADD 和ADD-S 指标评估得分87.55 和92.77 相比,分别降低了31.27 和29.11。由于残差采样滤波模块增强了相邻帧间的姿态差异,因此提高了复杂场景条件下目标姿态估计的准确性。
至于保健品维生素C,一片都不一定有80mg呢,而且保健品这么贵,都舍不得一次性多吃几片的……总之,维生素C是个好东西,就算不生病,平时多补充一些也是大有裨益的。但是如果买很贵的而且添加了一堆色素、香精的保健品维生素C,补充了一丁点维生素C,却吃进去不少添加剂的话,就得不偿失了。那么98块钱的维生素C和两块钱一瓶的维生素C有什么区别?同样的东西,它们的差距在哪里?简要概括:
将激活函数替换为ReLU 进行实验,不仅网络的收敛速度有所下降,精确度也大幅降低,未采用swish 激活函数的ADD 和ADD-S 评估指标得分为68.28 和71.27,与基准的ADD 和ADD-S 指标评估得分87.55 和92.77 相比,分别降低了19.27 和21.50。自门控swish激活函数可以保留目标的细节特征,在长期追踪过程中减小因视角变化产生的目标物抖动。
2)特征聚合模块。采用特征串联代替特征相乘,验证特征聚合模块在方法中的有效性,结果如表7 所示。未采用特征聚合模块的网络评估得分最低,ADD 和ADD-S 评估指标得分为53.24 和61.32,与基准的ADD 和ADD-S指标评估得分87.55和92.77 相比,分别降低了34.31 和31.46。由于特征聚合模块在相邻帧间建立了充足的空间和位置信息交互,因此增强了目标姿态和位置的特征提取能力。
消融实验结果表明,在上述模块的共同作用下,网络可以长期实时地追踪目标物的6D姿态,实验结果验证了不同模块对网络的有效性。
3 结论
本文提出一种目标6D实时追踪网络结构,该网络通过提取目标物体前后帧的姿态差异特征,迭代计算目标物体在连续帧中的时空特征信息,获取其三维旋转与平移矩阵,对矩阵做指数映射得到旋转和平移差异,以此获得实时目标姿态追踪结果。
1)在数据预处理阶段通过增强合成数据,弥补合成数据与真实数据训练的差距;
2)经过残差采样滤波结构和自门控swish 激活函数处理,保留目标物体更多的细节特征输入网络学习;
3)通过特征聚合模块将目标物体特征信息分解为不同方向的特征分量,分别沿时间和空间捕获长程依赖并保留目标物体的位置信息,生成一组时空间互补特征图,加强目标物体特征提取能力并加快网络收敛速度;
4)经过两个具有挑战性的数据集测试,实验结果表明,本文网络可以只使用少量合成数据训练即可为复杂场景中的目标物体提供优秀的实时追踪效果。与其他方法相比,本文方法追踪误差更低,能够更精确地实时追踪目标物体,在一定程度上解决了目标物体遮挡所带来的挑战,取得了更高的准确性与鲁棒性。
本文提出的网络结构存在一定冗余,在场景物体较多的情况下追踪速度不能维持稳定,在复杂场景中仍有较大提升空间。未来的工作中将简化网络并实现多目标姿态追踪,以提高复杂场景条件下的目标物实时姿态追踪性能。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2020年10期)2020-11-14
学生天地(2020年3期)2020-08-25
中学生数理化·高一版(2020年1期)2020-02-20
自动化学报(2019年6期)2019-07-23
中学生数理化·八年级物理人教版(2018年10期)2018-12-06
汽车观察(2018年9期)2018-10-23
中国自行车(2018年8期)2018-09-26
科普童话·百科探秘(2015年4期)2015-05-14
河南科技(2015年8期)2015-03-11
