
融合ViT与对比学习的面部表情识别
2024-01-22 10:26崔鑫宇何翀赵宏珂王美丽
中国图象图形学报 2024年1期
崔鑫宇,何翀,赵宏珂,王美丽,2,3*
1.西北农林科技大学信息工程学院,杨凌 712100;2.农业农村部农业物联网重点实验室(西北农林科技大学),杨凌 712100;3.陕西省农业信息感知与智能服务重点实验室(西北农林科技大学),杨凌 712100
0 引言
面部表情是指通过面部肌肉的变化来表现各种情绪状态,在人类沟通中帮助理解他人意图。美国心理学家Ekman 和Friesen(1971)定义基本面部表情类型为快乐、悲伤、愤怒、恐惧、惊讶、厌恶。随后Ekman和Friesen(1978)提出了一种面部动作编码系统来研究人的面部动作进而判断表情。目前面部表情分析已经成为计算机视觉和人工智能领域的重要方向(彭小江和乔宇,2020),面部表情识别技术在安全监控、教育教学和人机交互等领域具有广阔应用。
人脸表情识别的任务是对于给定的一幅人脸图像,输出这张人脸对应表情的类别。目前的深度人 脸表情识别系统存在真实世界环境下其他与表情无关因素变量带来的干扰问题(李珊和邓伟洪,2020)。在非受控环境下(自然条件)构建的数据集,如RAFDB(real-world affective faces database)(Li 等,2017)、AffectNet(Mollahosseini 等,2019)、FERPlus(facial expression recognition plus)(Barsoum 等,2016),相比于受控条件下数据集更接近真实场景,使其更具有研究意义。目前,非受控条件下的人脸表情识别由于受到姿态变换、遮挡和光照差异等多种因素的影响,导致人脸表情识别的准确性较低。解决好以上问题将会大大推动真实场景下人脸表情识别的发展,对人工智能领域具有重大意义。
自监督学习使用特定的数据增强应用于输入数据,并产生伪标签来训练或预训练模型,利用大量的无标注数据并提取图像本身的先验知识分布,提升下游任务的效果。然而,对比学习属于自监督学习,它可以通过增加任务难度从而进一步学习姿态、光线变化下同类图像之间的内在一致特征信息。受此思路的启发,本文认为基于负例的对比学习模型可以解决现实条件下遮挡、姿态和光线变化对于表情识别影响的问题,提升识别准确度。
具有强大的特征提取网络可以增强对比学习的特征表征能力。基于Transformer(Vaswani 等,2017)的网络结构性能超过标准的卷积神经网络(convolutional neutral network,CNN),视 觉 Transformer(vision Transformer,ViT)(Dosovitskiy 等,2021)通过在非重叠图像块上直接应用自然语言处理(natural language processing,NLP)中的标准Transformer 编码器,展现了图像分类的强大性能。本文利用 ViT 强大的特征提取能力来提高对比学习在非受控条件下的表情识别性能。
为了更好地降低真实场景中各类因素对识别效果的影响,提高表情识别准确率,本文工作贡献如下:1)针对现实条件下的人脸表情识别数据集存在较多遮挡问题,采用基于负例的自监督对比学习方法实现人脸表情识别,增加原图像和经过遮挡增强图像的正样本对对比,并将字典机制应用到MoCo v3)(momentum contrast v3)(Chen 等,2021)中,解决训练中显存不足的问题,将该识别模型在ImageNet数据集(Deng 等,2009)上进行预训练,将预训练模型应用于表情识别数据集进行微调,以提高表情识别任务的分类准确率。2)将基于Transformer 的ViT网络作为骨干特征提取网络,结合对比学习预训练,在表情识别公共数据集RAF-DB、FERPlus、Affect-Net-7 和AffectNet-8 上取得89.02%、90.84%、64.94%和60.63%的识别准确度,与一些表情识别流行算法进行比较,表明了算法的有效性。
1 相关工作
1.1 人脸表情识别方法
表情标注具有主观性和差异性,因此数据集中的标签噪声难以避免(姚鸿勋 等,2022)。由于大规模人脸表情数据集具有不确定性,Wang 等人(2020a)提出了一个简洁高效的自修复网络(selfcure network,SCN),有效地抑制不确定性,从而提高表情识别算法的鲁棒性。Zhao 等人(2021)提出轻量级表情识别算法EfficientFace,引入简单但有效的标签分布学习(label distribution training,LDL)作为训练策略,通过学习样本之间的关系,对每个表情类别建模其可能的分布。Face2Exp(combating data biases for facial expression recognition)(Zeng 等,2022)通过元优化框架从数据中提取去偏信息来消除数据偏差。本文增加原图像和经过遮挡增强后图像的正样本对对比,减少遮挡和数据不确定性对识别效果带来的影响。
Li 等人(2019b)为了增强模型学习特征的判别力,提出了Separate Loss 损失函数,使用该损失函数学习的特征具有类内紧凑和类间分离的特点。Farzaneh 和Qi(2020)提出了判别无关分布(discriminant distribution-agnostic,DDA)损失用于野外面部表情识别,该研究通过优化极端类不平衡场景的嵌入空间,在嵌入空间中产生分离良好的深度特征簇。Farzaneh 和Qi(2021)提出了一种深度注意力中心损失(deep attentive center loss,DACL)的方法,集成注意力机制,并使用卷积神经网络中的中间空间特征图作为上下文来估计与特征重要性相关的注意力权重。Fard和Mahoor(2022)提出了一种自适应相关性(adaptive correlation,Ad-Corre)损失来引导网络生成对于类内样本具有高相关性、对于类间样本具有较低相关性的嵌入特征向量。以上方法虽然通过使用更好的损失函数来引导模型学习,但并未聚焦特征提取和学习。
因此,一些工作增强模型学习特征的能力,以此来提高表情识别的性能。Li 等人(2019a)提出了基于CNN 和注意力机制的人脸表情识别方法自注意力卷积神经网络(CNN with attention mechanism,ACNN),能够自动感知遮挡的面部区域,并将注意力集中于未遮挡和信息丰富的区域,在实验室条件下和真实环境条件下都取得了不错的识别效果,并提出了第一个专注真实环境下面部遮挡的数据集FEF-RO(facial expression dataset with real-world occlusions)。Wang 等人(2020b)提出了区域注意力网络(region attention networks,RAN)来捕捉对遮挡和姿态变换图像重要的区域,并提出了区域偏差损失函数(region biased loss,RB-loss)来让更重要的区域得到更多的注意力权重。Li等人(2020)提出了使用SE(squeeze excitation)模块和滑动块的整体面部注意力模型(slide-patch and whole-face attention model with SE blocks,SPWFA-SE),感知面部的判别局部特征和信息丰富的全局特征,利用多级特征提取和注意机制增强所学特征的代表性。Huang 等人(2021)提 出FER-VT(facial expression recognition with grid-wise attention and visual Transformer)表情识别算法,利用注意力机制从面部图像中捕捉不同区域的依赖关系,利用Transformer 注意力机制学习全局表示。Zhang 等人(2022)提出了一种擦除注意力一致性(erasing attention consistency,EAC)方法来自动抑制训练过程中的噪声样本。
然而,上述研究使用注意力机制在一定程度上解决了在遮挡等不利因素影响下的表情识别,但忽略了数据本身的特征分布。本文融合ViT 和对比学习,不仅更好地提取特征,还能学习表情的特征分布。
此外,还有使用知识蒸馏实现表情识别的工作,如Li 等人(2021)提出知识富集的教师网络(knowledgeable teacher network,KTN),解决在各类表情数据集分布不平衡的影响下区分高度相似的表情,提出AdaReg损失函数和粗—细标签策略,引导模型从易到难对高度相似的表示进行分类。
1.2 对比学习概况
对比学习属于自监督学习,无需标注数据,在多个模型上的效果超过有监督模型。基于负例的对比学习方法动量对比(MoCo)(He 等,2020)开创自监督视觉表示学习,通过在ImageNet-1k 数据集预训练,在7 个下游学习任务上超过标准监督算法的性能。
SimCLR(simple framework for contrastive learning of representations)(Chen 等,2020a)算法表明,多种数据增强方式的组合、表示和对比损失之间引入非线性转换、更大的批量和更多的训练步骤能有效提高图像分类准确率。但是由于采用了大量的数据增强策略,训练复杂度较高,需要大量的计算资源。
BYOL(bootstrap your own laten)(Grill 等,2020)模型基于非对称网络结构的方法,不使用负样本对,训练分为在线网络和目标网络两部分,有效解决了训练坍缩问题。但是训练过程中需要维护在线网络和目标网络,增加了模型训练和存储的复杂度。
SwAV(swapping assignments between multiple views of the same images)(Caron 等,2020)算法为基于对比聚类的方法,在对比学习中引入聚类,先对训练样本进行聚类,然后在类间进行对比学习,通过聚类后再做对比操作,减少了对比的数量,可有效降低计算复杂度。然而,聚类的数量对训练速度有较大影响,需要进行合理的聚类数量选择。
Barlow Twins(self-supervised learning via redundancy reduction)(Zbontar 等,2021)是一种基于冗余消除损失函数的方法,它提出一个目标函数,通过衡量同一样本两个不同视图输入到相同网络得到嵌入的互相关矩阵,使其接近单位矩阵,该方法依赖于非常高维的输出向量。由于该方法使用高维特征进行计算,需要更多的存储空间和计算资源。
2 提出的面部表情识别方法
本文结合MoCo 对比学习框架设计了针对表情识别任务的学习框架,运用了MoCo系列的动量编码机制、队列机制等,同时加入了投影头、预测头等提高模型的提取特征的能力,最后对正负样本对做对比损失计算。
编码器网络fq包括1 个骨干网络ViT、1 个投影头、1 个预测头。动量编码器网络fk包括1 个骨干网络ViT 和1 个投影头,没有预测头。fk通过fq的滑动平均更新,预测头不更新。投影头是1个3层多层感知机(multilayer perceptron,MLP),预测头是一个2层MLP。
输入的图像经过数据增强后,原图像和数据增强后的图像分别经过编码器网络进行特征提取,编码器提取的特征经过投影层、预测层和动量编码器后,进行正负样本对的相似度计算,结束后编码器网络进行参数更新,动量编码器网络进行动量更新。
MoCo v1(He 等,2020)主要使用移动平均更新模型权重和队列方法形成一个字典查询问题,解决难以应用大量负样本进行训练的问题。MoCo v2(Chen 等,2020b)改进了图像数据增强的方法,增加使用模糊增强方法,在编码器得到表示信息后添加非线性层等,使模型以更小的批量大小和训练轮数,在ImageNet 数据集分类任务上取得了更好的效果。MoCo v3 中使用更大的批次大小进行训练,取代了之前改进的Memory Queue,使用基于Transformer 的ViT 作为编码器,在负例编码器上添加预测头,并解决了对比学习在ViT 训练过程中表现出的不稳定问题,图像分类效果得到进一步提升。
由于MoCo v3 框架预训练需要大量的显存资源支持,导致其无法广泛使用,本文将MoCo v1 和MoCo v2 所采用的字典机制运用到MoCo v3 中,其中的样本队列采用的是字典机制,在显存资源缺乏的情况下仍能进行训练。改进数据增强和正样本对对比方式,改进后的对比学习框架如图1所示。
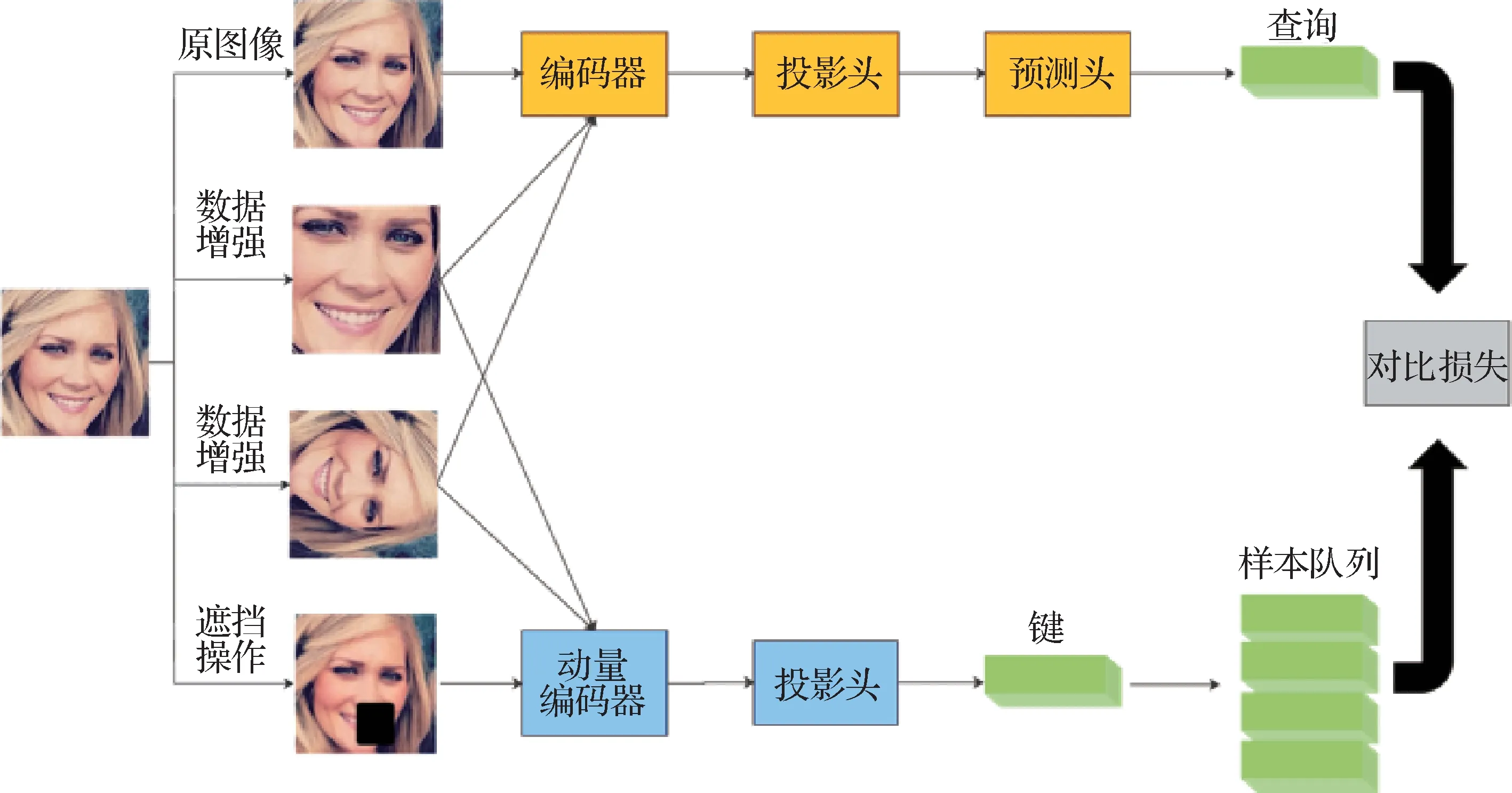
图1 对比学习框架图Fig.1 Contrastive learning frame diagram
2.1 数据增强及正负样本对对比
数据增强方式的选择对于对比学习的效果会产生比较大的影响。针对现实情况下图像识别存在遮挡的问题,本文在MoCo 框架的基础上,对数据增强方式和正负样本对比方式进行改进,原框架中对输入的图像进行随机数据增强,包括水平翻转、颜色抖动、随机调整大小的裁剪、灰度转换、模糊和曝光等,对数据增强后的图像进行两次裁剪,将裁剪后的两幅图像输入两个编码器中进行编码。本文在此基础上,增加了一组正样本对比,将原图进行数据增强的遮挡操作,再将原图像和经过遮挡后的图像输入到编码器中进行编码。编码器fq和动量编码器fk输出向量为q和k,采用最小化对比损失函数InfoNCE 进行相似度计算,分子部分表示正例之间的相似度,分母表示正例与负例之间的相似度。相同类别样本相似度越大,不同类别样本相似度越小,损失函数的值越小,计算为
式中,k+是q的同一幅图像经过编码器fq的输出,作为q的正样本;k-表示其他图像经过动量编码fk的处理输出,作为q的负样本;t是归一化q、k的温度超参数;K代表字典中样本数量。本文设计的对比学习正样本对示意图如图2所示。

图2 对比学习正样本对示意图Fig.2 Schematic diagram of contrastive learning positive sample pairs
通过这样的对比方式可以有效地挖掘令网络学习更有效的样本,从而推动网络寻找图像分类的边界线。X为原图像,X0为加入随机遮挡后的图像,X1是经过水平翻转后的图像,X2是经过随机裁剪后的图像,X,X1,X2通过编码器fq分别得到特征q,q1,q2,X0,X1,X2通过动量编码器fk分别得到特征k,k1,k2,维度为n,特征空间由一个长度为c的向量表示,分别做矩阵相乘,得到3 个维度为(n,n)的矩阵,3 个矩阵相加得到1 个维度为(n,n)的矩阵,矩阵对角线元素代表的是正样本对的相似度,对角线元素越大越好,整个矩阵接近单位矩阵越好。
2.2 编码器
使用ViT-small 作为特征提取网络,输入图像尺寸为224 × 224 像素,patch 大小为16 × 16,嵌入维度大小为384,ViT 的核心流程包括图像分块处理、图像块嵌入与位置编码、Transformer 编码器和MLP分类处理等4 个主要部分,其模型架构如图3所示。
ViT的前向过程为:首先将输入图像分为N个图像块Xp,表示为向量;然后将图像块变换嵌入为N×D大小的特征序列,并在特征序列头部加入可学习的面部表情分类编码Xs,对特征序列加入位置编码得到Transformer 第1 层输入z0;然后经过多个Transformer 编码器,其中包括层归一化(layer normalization,LN)、多头自注意力模块(multi-head self-attention,MSA)和MLP,最后得到面部特征。具体计算为
式中,N代表图像分块数,P代表图像分块大小,C代表通道数,E代表图像分块线性变换嵌入,D为线性变换嵌入后的特征大小,Ep表示图像分块的位置编码,表示在第l层经过MSA 模块和残差连接后得到的面部特征序列,zl表示在第l层经过MLP模块和残差连接后得到的面部特征序列,表示经过L层Transformer 编码器后得到的面部特征,最终得到经过多层Transformer 编码器处理后的面部特征y。
3 数据集介绍
针对实际问题和实际需要采用RAF-DB、FERPlus、AffectNet等自然条件下的公开数据集。
RAF-DB 数据集包含29 672 幅从网络采集的真实人脸图像,包含单标签子集和多标签子集。在本文实验中使用单标签子集,包括快乐、中性、惊讶、愤怒、悲伤、恐惧、厌恶等7 种基本情绪,由12 271 幅训练样本和3 068幅测试样本组成。
FERPlus 数据集包括28 709 幅训练样本、3 589幅验证样本和3 589幅测试样本,是从谷歌搜索引擎收集而来,除7 种基本情绪外,蔑视类别也包括在标签中。
AffectNet 数据集是一个大型的表情数据集,是从网络中收集而成,由超过1 000 000 幅面部图像组成。在实验中,使用与FERPlus数据集相同的8个基本表情以及去除蔑视外的7类表情作为识别任务。
4 实验结果与分析
首先在ImageNet数据集上进行无监督对比学习预训练,预训练完成后在目标表情数据集上进行微调。本文实验均在Ubuntu 20.04 系统中完成,环境配 置为 Intel i7-6700 CPU 3.40 GHz,16 GB 内 存,GeForce RTX 1080Ti GPU。为了验证所提出方法的有效性,本研究在RAF-DB、FERPlus、AffectNet-7 和AffectNet-8 数据集上进行实验,并与一些流行的算法进行比较,训练集、验证集按照官网默认划分的结果进行实验。
将InfoNCE(information noise contrastive estimation)作为损失函数,采用网络结构ViT-small,以自适应矩估计(adaptive moment estimation,Adam)为优化器,批量大小设置为128,迭代轮次设置为200,学习率初始化为0.000 3,采用余弦退火学习率衰减策略,学习率衰减周期设置为30。
基于本算法模型在RAF-DB、FERPlus、Affect-Net-7 和AffectNet-8 公开面部表情数据集上进行实验,得到各类表情识别结果,本文将该模型与其他13 种方法进行了对比,结果如表1 所示。本模型在RAF-DB 数据集上取得了89.02%的识别准确度,比Face2Exp 算法提升了0.48%,在FERPlus 数据集上取得了90.84%的识别准确度,比KTN 算法提升了0.35%,说明本模型在小规模数据集上具有良好的性能。本模型在AffectNet 数据集(7 类)上取得了64.94% 的识别准确度,略低于DACL 算法的65.20%,在AffectNet数据集(8类)上取得了60.63%的识别准确度,比SCN 算法提升了0.4%,说明本模型在较大规模数据集上仍然具有良好的性能。图4展示了本模型在AffectNet-8数据集上的识别效果。
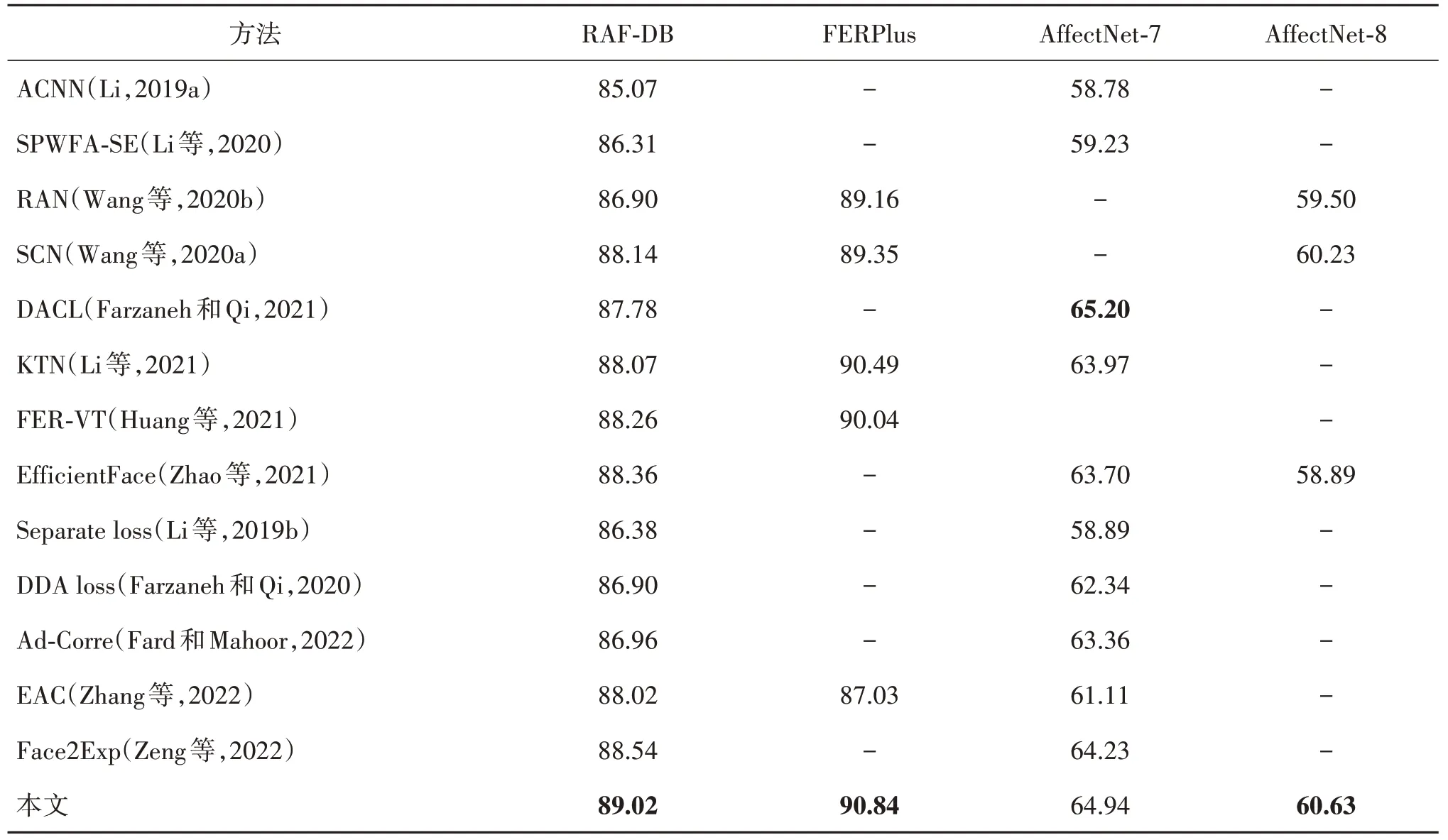
表1 本模型与其他方法结果比较Table 1 Comparison of the results of this model with other methods/%

图4 在AffectNet-8数据集的检测识别效果Fig.4 Detection and recognition effect in AffectNet-8 dataset
该算法模型在各个面部表情数据集上的混淆矩阵如图5—图8 所示,由图中可以看出,快乐、惊讶、中性表情具有较高的识别准确度,蔑视、恐惧、厌恶等表情识别准确度较低,与面部变化不明显有关系。不平衡数据集在分类问题中,当训练集样本数量在类中分布不均匀时,样本较多的类别识别效果较好,如果样本数量不平衡度很高,会影响分类器的性能并导致网络偏向较大的样本。本数据集训练集中高兴表情数量最多,厌恶、蔑视等表情样本数较少,对识别准确度造成了一定程度的影响。
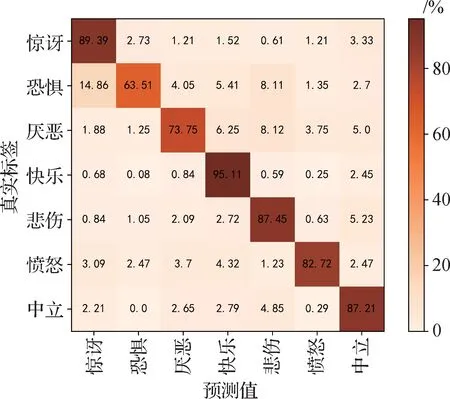
图5 在RAF-DB数据集中测试的混淆矩阵Fig.5 Confusion matrix tested on the RAF-DB dataset
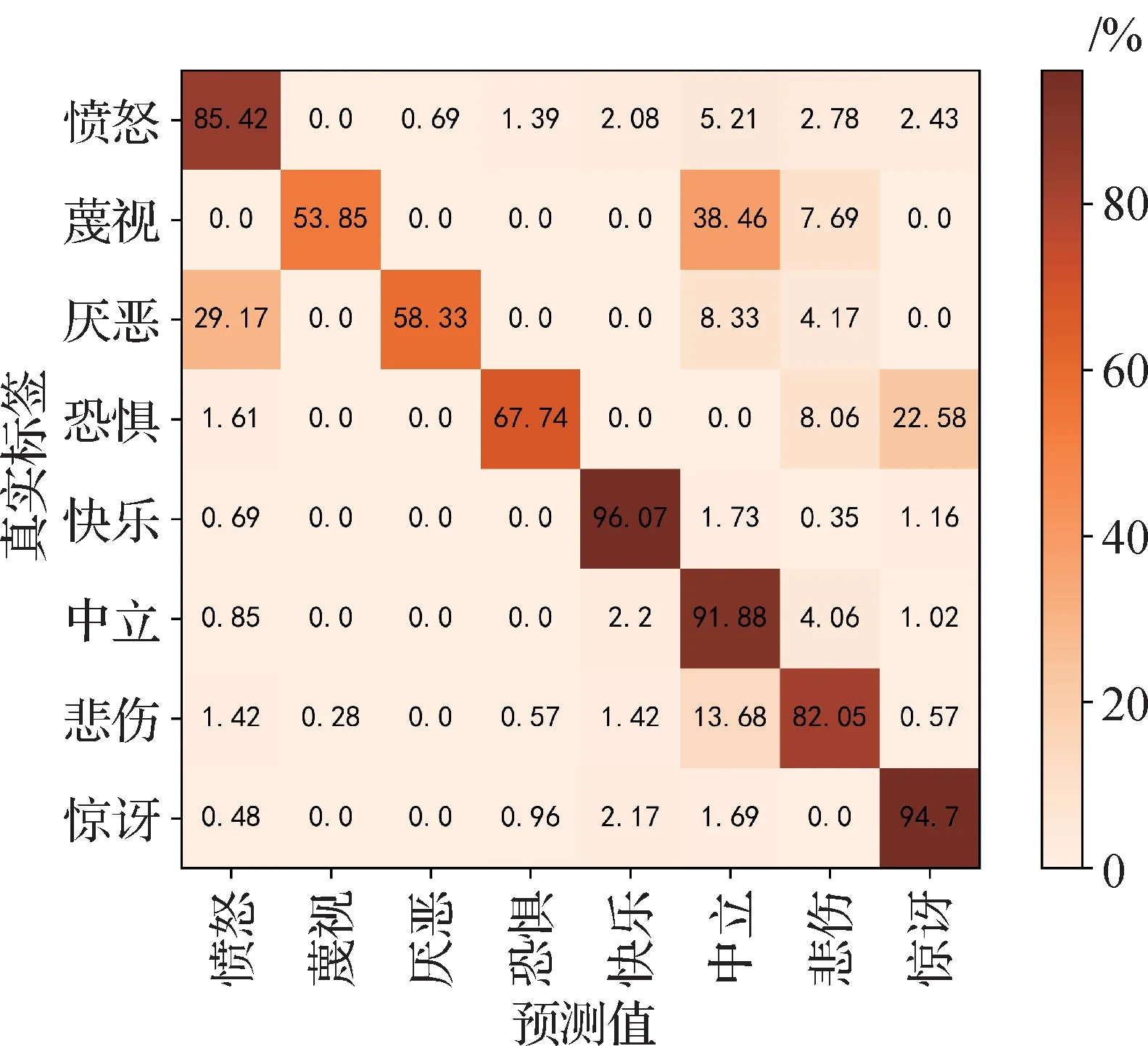
图6 在FERPlus数据集中测试的混淆矩阵Fig.6 Confusion matrix tested on the FERPlus dataset
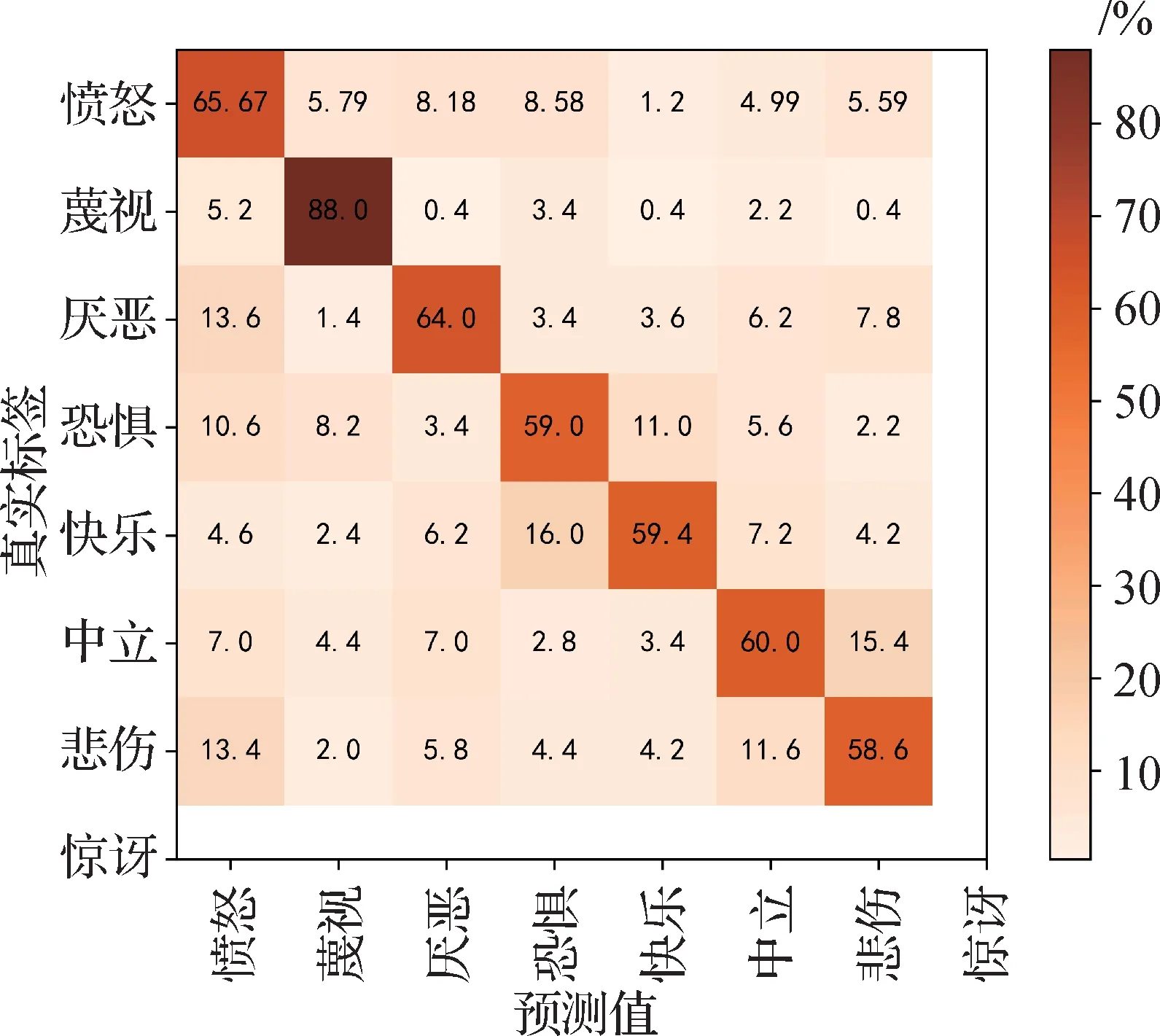
图7 在AffectNet-7数据集中测试的混淆矩阵Fig.7 Confusion matrix tested on the AffectNet-7 dataset
5 结论
针对非受控条件下表情识别中存在的遮挡、姿态变化和光照变化等问题,本文提出一种基于自监督对比学习的人脸面部表情识别算法。该算法包括预训练和微调两个阶段,预训练阶段融合ViT 为骨干网络,并增加数据增强方式和正负样本对比次数,强化了模型的特征表征提取能力和对图像遮挡、姿态、光照条件变化的鲁棒性;微调阶段,利用人脸表情识别数据集进行训练获得识别结果。
本文主要创新在于融合ViT 到对比学习框架,可以充分利用大量无标签和噪声遮挡数据,充分学习人脸表情数据分布特征,在人脸表情识别数据集RAF-DB、FERPlus、AffectNet-7 和AffectNet-8 上获得了较好的准确率。利用对比学习框架和先进的特征提取网络,将增强深度学习方法应用于日常视觉任务中。
然而,本文存在以下不足:负面表情的识别准确率有待提高,这与数据集中负面表情样本数量有限有关,网络没有学习到更多的负面表情特征。未来,本文将致力于对负面表情的准确识别,探索更强大的特征提取网络和高效简洁的对比学习方法,进一步提高人脸表情识别的准确率。此外,本文方法基于2D 人脸表情数据集,随着未来3D 人脸数据的完善,表情识别将有更多的研究空间,本文将继续探索研究3D人脸数据下的表情识别。
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20
中学生数理化·高一版(2021年2期)2021-03-19
动漫星空(2018年9期)2018-10-26
成都信息工程大学学报(2018年3期)2018-08-29
知识经济·中国直销(2018年8期)2018-08-23
数学学习与研究(2017年3期)2017-03-09
电子设计工程(2017年20期)2017-02-10
中国老区建设(2016年1期)2016-02-28
电子器件(2015年5期)2015-12-29
发明与创新(2015年33期)2015-02-27
