
基于数据筛选及平滑处理的风电功率曲线建模方法研究
2024-01-12 05:39杜强
微型电脑应用 2023年12期
杜强
(中广核新能源安徽有限公司, 安徽, 合肥 230000)
0 引言
风力发电在解决能源短缺和环境污染方面扮演着重要的角色,风力发电的应用越来越广泛。风电功率曲线是表达风速与风电功率关系的曲线。功率曲线能有效反映风能的利用效率和机组的发电性能状态。通过对风电功率曲线的分析,可为风机的设计、风电功率的预测和风电机组的安全运行控制等问题提供重要的参考。但风电机组要受到空气密度、湍流强度等各种环境因素的影响,同一风速下的风电功率往往存在较大范围波动的情况[1],给风电功率曲线建模带来了较大的困难。因此研究具有高建模精度的风电功率曲线建模方法具有重要意义。
风电功率曲线建模方法主要有参数法和非参数法两类。参数法包括分段线性模型、动态功率曲线、概率模型等。参数法推理过程简单,便于计算,但其对数据样本的准确性要求过高[2]。非参数法无需预先确定函数模型,而是由数据样自身提取所需要的信息,非参数法具有适应能力强的优点。文献[3]研究表明对数据进行核密度筛选可提高风电功率曲线建模的精度。文献[4]在对数据样本进行筛选后利用支持向量机建立风电功率曲线模型,取得了较好的结果,但支持向量机存在结果不稳定的缺陷。文献[5]采用BP神经网络进行风电功率曲线建模,但BP神经网络存在易陷入局部最优的问题。
以上文献均未对风速进行预处理,且采用的功率曲线建模方法存在建模精度不理想的问题。由此本文提出一种风电功率曲线建模的新方法,对数据进行筛选及平滑处理后,再利用小波神经网络建立风电功率曲线映射模型,并通过功率曲线建模实例的对比分析验证该方法的有效性和优越性。
1 风电机组功率曲线数据筛选

(1)
式(1)中,N表示样本的数量,hv和hp表示风速v和功率p的窗宽,K表示核函数,本文采用高斯核函数。
窗宽h的大小对核密度的计算有重要的影响,窗宽过大,会造成结果的判别率较低,而窗宽过小,又会造成计算结果不稳定。本文采用插入法选择窗宽,它基于最小平方差的原理,利用平均积分平方误差MISE最小来获得窗宽的最优值[8]。平均积分平方误差MISE为
(2)
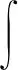
对MISE求解后可得:

(3)
(4)
式(3)~式(4)中,o(h4+1/Nh)表示积分高级项,N表示样本的数量,h表示窗宽大小,K表示核函数。
求取MISE最小值便可得最优窗宽,表达式为
(5)
2 风速数据的平滑预处理
风速时间序列呈现出杂乱无章的随机现象[9],为提高风电功率曲线建模的精度,需获得风速在多维空间内的规律性, 本文首先对风速时间序列进行相空间重构。设初始风速时间序列为 {x(1),x(2),…,x(N) },N为采集点的总数目,进行相空间重构后的相点时间序列向量为
(6)
式(6)中,τ表示延迟时间,M表示相空间总维数,m表示嵌入维数。
本文采用C-C法获得的风速时间序列τ为 16、m为5时的Lyapunov 指数为 0.125,表明风速时间序列具有混沌特征,可对其进行时间序列平滑预处理,而平滑阶数是平滑处理中的一个关键指标,平滑阶数不同,处理后的风速与功率间单值映射关系也会不同。若要使求取的风电功率曲线误差最小,则需选择一个最优的平滑阶数。本文利用皮尔逊积矩相关系数来评价不同坐标分量与风速时间序列之间的联系紧密程度[10],表达式为
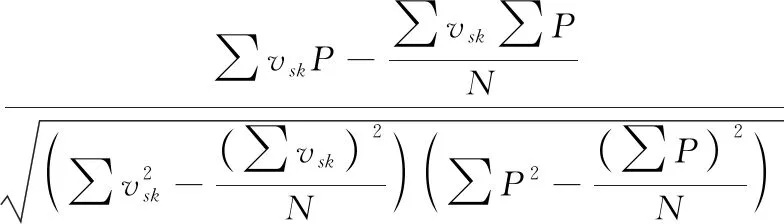
(7)
(8)
式(7)~式(8)中,r表示皮尔逊相关系数值,vsk表示平滑处理后的风速,k表示平滑阶数,P表示风力发电的功率值,v表示风速的实际值,t表示时间,N表示采样点总数。
风电机组实际的风速和功率关系是一个宽的带状分布图,风电功率不仅与当前的风速有关,还与过去其他时刻的风速相关。采用平滑预处理获得的输入风速,可包含多时刻风速的综合信息。
3 风电功率曲线建模方法
概率密度值较高的风速功率数据点可有效表征风电机组的发电状态,而风速功率散点分布图中的集中部分概率密度要大于散点分布较少的区域,对集中区域进行数据拟合便能有效反映机组的发电能力。本文采用耗时较短的核密度估计法筛选风速功率散点集中区域内的正常运行数据。
现有的风电功率曲线建模方法多选用与功率对应时刻的风速作为输入,但由于同一风速下风电功率存在较大范围波动的现象,导致传统建模方法的风电功率曲线精度较低。因此,本文采用基于时间序列平滑的预处理方法对输入风速进行处理。
对于风速与功率之间非线性函数的建模,本文采用小波神经网络,它具有比传统神经网络预测精度更高的优点,其强大的时频局域化能力可有效反映风速与功率非线性映射情况[11]。小波神经网络主要结构如图1所示。
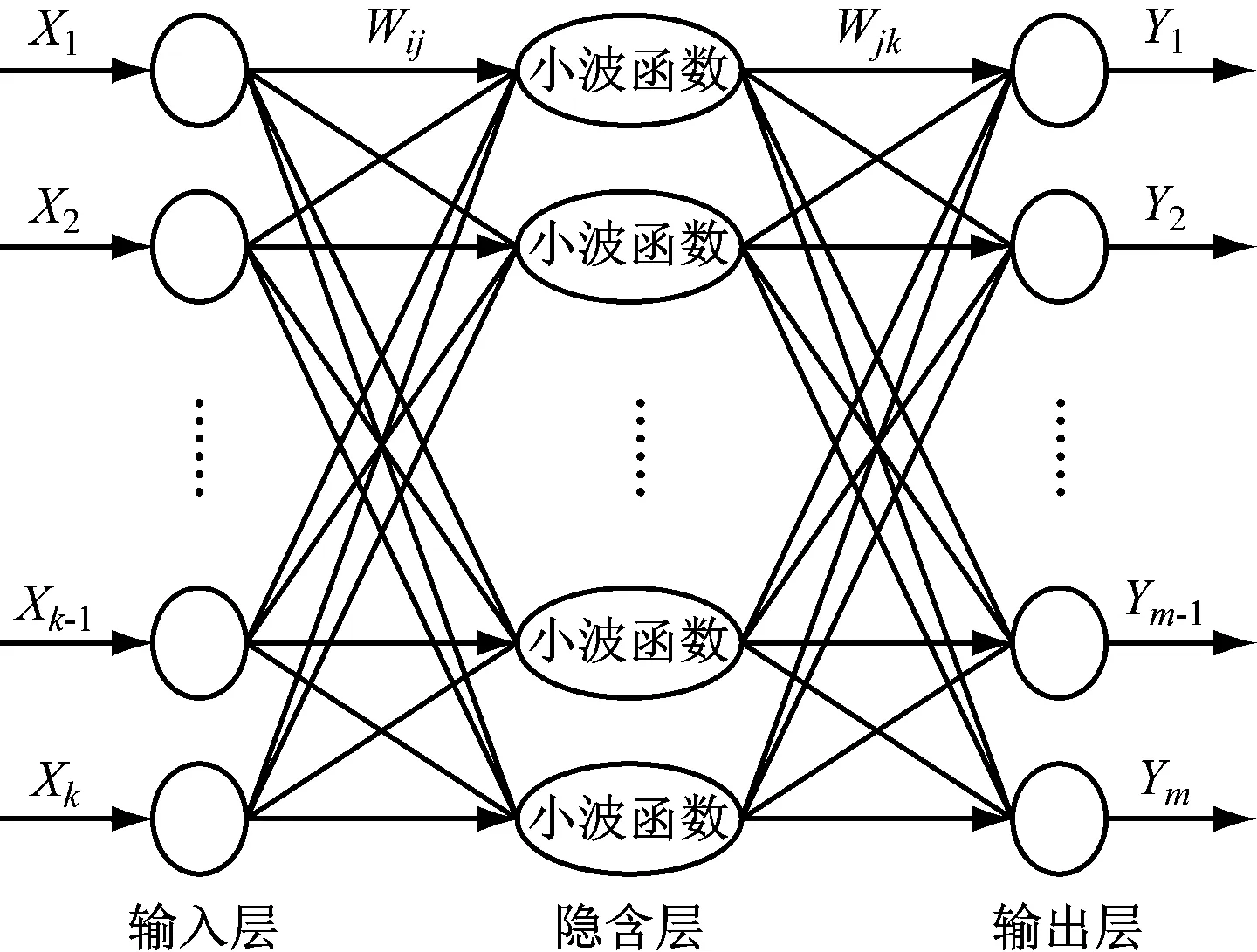
图1 小波神经网络结构图
假设小波神经网络的输入为X1,X2,…,Xk,预测输出为Y1,Y2,…,Ym,输入层和隐含层的权值为wij,隐含层和输出层的权值为wjk,则隐含层输出h(j)为
(9)
式(9)中,l表示隐含层的节点总数,aj和bj表示伸缩因子和平移因子,hj表示小波基函数。
小波神经网络输出层的输出为
(10)
式(10)中,h(i)表示隐含层节点i的输出,l、m分别表示隐含层和输出层的节点总数。
本文风电功率曲线建模方法的主要过程如图2所示。首先对采集到的风速功率数据进行标准化预处理,包括数据的归一化以及对原始数据的完整性和合理性进行检验等;然后采用核密度估计法对数据做筛选处理。对于风速数据,采用基于时间序列平滑的预处理方法进行处理;然后以平滑后的风速为输入,风电功率为输出,建立并训练小波神经网络模型,从而得到需要的风电功率曲线;最后采用测试数据对建立的功率曲线模型进行评价。

图2 风电功率曲线建模方法
本文对风电功率曲线建模精度的评价采用均方根误差(NRMSE)和平均绝对误差(NMAE):
(11)
(12)
式(11)~式(12)中,pf和pa表示功率的估计值和实际值,N表示测试样本数据的数量。
4 风电功率曲线建模算例分析
4.1 算例
本文以西南地区某风电场的某台风电机组为例进行分析,选取该机组2020年10月的输出功率与实测风速样本数据,样本数据采样周期为1 s,样本数据总数为10 000。
对于原始的风速功率样本数据进行归一化处理及相关检验和筛选处理后,采用不同阶数平滑处理获得的风速与功率的皮尔逊积矩相关系数关系如图3所示。

图3 风速功率相关系数
由图3可知,平滑阶数为1时,皮尔逊积矩相关系数为0.9162,随着平滑阶数的增大,皮尔逊积矩相关系数出现先增大后减小的变化趋势;当阶数达到16时,相关系数达到最大值0.9583,而皮尔逊积矩相关系数是评估风速与功率之间的联系紧密程度的参数,该参数值越大,表明两者之间联系越紧密、相关性越大。本文选取的最优平滑阶数为16。
4.2 风电功率曲线建模结果比较分析
为验证本文风电功率曲线建模方法的有效性和优越性,采用多项式拟合法、支持向量机法、BP神经网络法和本文小波神经网络方法分别对是否进行过数据筛选和平滑处理作风电功率曲线建模比较分析,各种情况下的建模精度结果如表1所示。本文方法拟合得到风电功率曲线如图4所示。
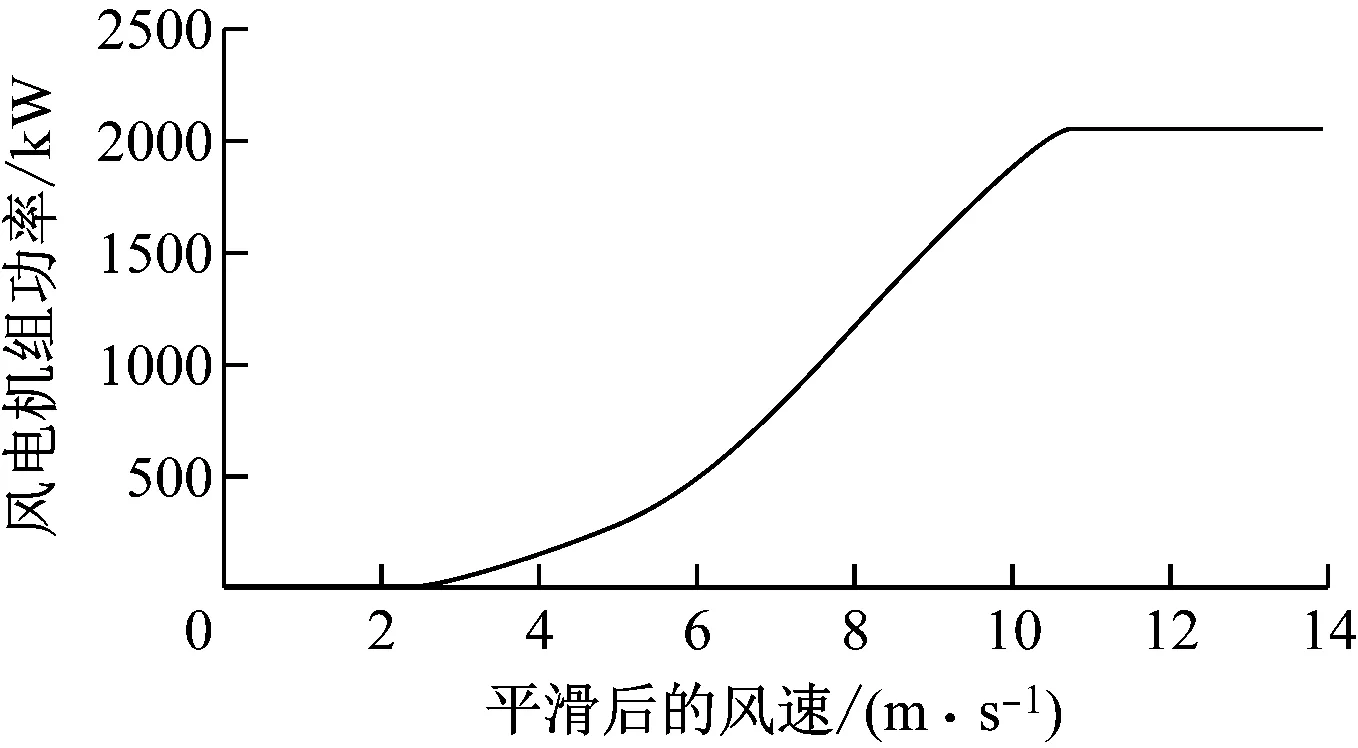
图4 风电功率曲线图
根据表1可知,采用核密度估计法对数据做筛选处理和风速平滑处理后,再用小波神经网络法进行风电功率曲线建模的精度是最好的,其均方根误差NRMSE(0.0203)和平均绝对误差NMAE(0.0161)均是所有建模方法中误差最小的。在风电功率曲线建模时,对数据做筛选处理和风速平滑处理均能有效提高建模的精度,而采用小波神经网络法建模比多项式拟合法、支持向量机法、BP神经网络法获得误差更小,建模精度更高。建模结果表明,本文方法获取的功率曲线的误差是最小的,具有很好的优越性。
5 总结
风电功率曲线能有效反映风力发电机组性能发电能力。本文利用核密度估计法进行数据筛选处理后,再对风速进行平滑预处理;然后利用小波神经网络法获得需要的风电功率曲线,通过风电功率曲线建模实例的比较分析,结果表明利用核密度估计法对数据进行筛选处理能提高功率曲线建模的精度,对风速平滑进行处理能进一步提高建模的精度,而小波神经网络具有更优良的非线性映射能力,采用本文方法获得的功率曲线,其均方根误差和平均绝对误差均优于其他建模方法。本文方法可获得更高建模精度的风电功率曲线,可为风电功率曲线的建模及风电机组的状态评估提供有效的参考和技术指导。本文主要针对单台风电机组的情况,未考虑多台风电机组间相关性和尾流效应等的影响,后续将针对风电场多台机组的情况作进一步研究。
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
大学数学(2021年5期)2021-10-30
华东师范大学学报(自然科学版)(2021年3期)2021-06-03
电机与控制应用(2021年12期)2021-02-28
中学生数理化·中考版(2020年12期)2021-01-18
中学生数理化·中考版(2020年12期)2021-01-18
海洋通报(2020年5期)2021-01-14
中学生数理化·中考版(2018年12期)2019-01-31
西南交通大学学报(2016年4期)2016-06-15
电网与清洁能源(2015年3期)2015-02-28
