
基于机器学习的迭代式数据均衡分区算法研究
2024-01-12 04:39张镝吴宇强
微型电脑应用 2023年12期
张镝, 吴宇强
(1.长春医学高等专科学校,思想政治理论教研部(公共学科), 吉林, 长春 130031;2.哈尔滨工业大学, 计算学部, 黑龙江, 哈尔滨 150000)
0 引言
随着互联网技术的发展,数据量呈现井喷式增长[1-2],面对庞大的数据,如何快速、准确而全面地从中挖掘出有价值的信息,已经成为各个领域和行业共同面临的一大难题[3-4]。MapReduce并行计算框架是一种非常高效和热门的计算工具,数据分区是其中一个重要环节。由于数据类型复杂、数据量大,数据分区规律通常难以获取,从而对价值信息的精准挖掘造成了困扰。因此,数据分区成为MapReduce框架顺利运行的一个难点,传统的数据分区方法难以达到均衡。
为此,国内外相关专家进行了长期的探索和研究,提出了许多分区算法。文献[5]基于数据分区研究高维数据均衡分流问题,主要依靠数据分布特征分析、分区维度计算以及边界计算实现,为后续研究提供了一种新的数据分区思路。文献[6]提出了一种基于自动分区的数据计算框架,通过元数据处理完成自动分区算法设计,该算法在特定领域中计算速率得到了很大提升。文献[7]提出了一种基于数据分区的不平衡大数据混合抽样方法,将所有数据样本划分到不同的数据区域,对不同区域的数据样本进行噪声滤除等处理,然后作为过采样种子生成合成样本,该文数据分区及处理为抽样提供了有效的基础。文献[8]提出了一种新的数据分区方法来提高现代高性能计算系统中异构并行应用程序的性能。文献[9]方法基于数据集的有效分区收集相关记录数据,通过数据分区过程的向低维特征空间移动,获取了稳健的分析结果,但分区准确率不高。
针对上述数据均衡分区算法现状,本文在机器学习的基础上提出迭代式数据均衡分区算法,并通过实验验证了所提算法性能。本文主要贡献点如下:①采用中心数据仓库技术对异构数据进行集成,以此提高分区速度,提升数据分区效率,并为数据特征提取奠定基础;②引入机器学习,通过决策树算法构建分类器模型,辨别数据属性与区域之间的关系,提高数据分区效果;③通过实验分析验证本文算法性能,结果表明,与传统方法相比,所提算法有了极大的提高。
1 基于机器学习的迭代式数据均衡分区算法
数据均衡分区能够帮助用户快速完成数据挖掘,为此提出基于机器学习的迭代式数据均衡分区算法。迭代式数据均衡分区总体框架如图1所示。
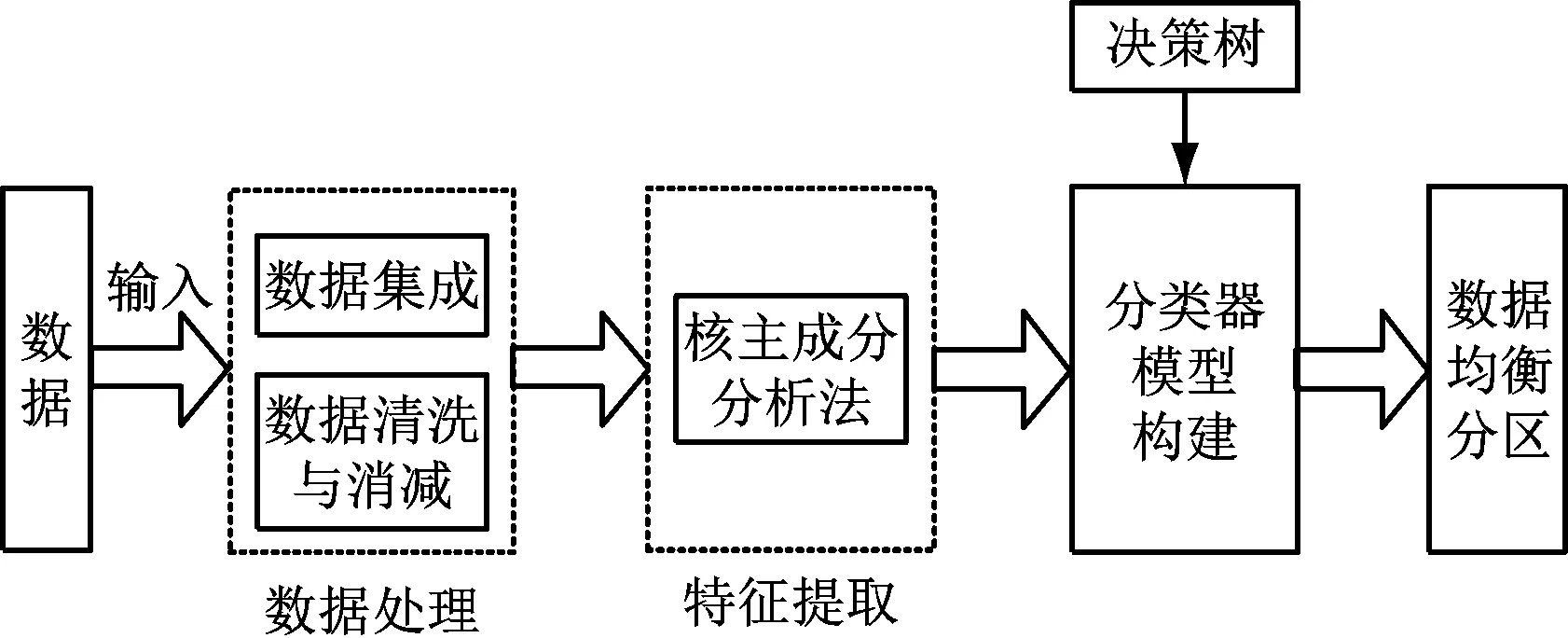
图1 基于机器学习的迭代式数据均衡分区总体框架
1.1 数据集成与处理
考虑到数据来源和格式的差异性,为提高数据分区速率,需要在分区之前采用中心数据仓库技术对异构数据进行集成。具体过程如下:
将过采样权重引入数据集成的过程,即将多数样本数据、少数样本数据和数据误分率相乘,得到过采样权重系数为
(1)
式(1)中,Smin表示原始样本数据中的少数样本数据,Smax表示原始样本数据中的多数样本数据,α表示数据过采样率,其取值范围为[0,1],Bmin表示少数类子簇,Cmax表示多数类子簇,n表示多数类子簇的样本量,m表示少数类子簇的样本量,E(·)表示误差率。
根据式(1)得到的过采样权重系数,可以实现对不同样本数据的分簇处理,但是在分簇过程中会受到无关数据的影响,造成分簇结果有所偏差,因此需要引入少数类子簇概率分布控制方法,实现不同类数据之间的平衡。在少数类子簇中,假设r为构成子簇Bmin的概率分布样本,则少数类子簇概率分布结果可以通过式(2)得到:
(2)
式(2)中,K表示相邻样本数据,φ表示过采样前的样本权值,Wijk表示样本数据的分簇结果,ri表示第i个少数类子簇的概率分布样本。综上,实现数据集成处理,为后续操作奠定基础,以有效提高数据分区速率。
1.2 数据特征提取
以1.1节得到的数据集成结果为样本数据,对其进行特征提取。传统的主成分分析方法是当前数据特征提取最常用的方法之一,然而该方法主要针对线性问题的处理,对于非线性问题往往不能发挥其作用。为此,以主成分分析为基础,将核方法应用其中,构成核主成分分析方法,以实现有效精准的数据特征提取,为后续的数据分区提供可靠的支撑。先将待分析的一组数据利用多层传感器核函数映射到合适的高维特征空间中,表示为
O(xi,yi)=tanh[b(xi,yi)+c]
(3)
式(3)中,b、c表示参数,且b、c>0,tanh表示激活函数,O(xi,yi)表示非线性映射后数据在高维特征空间中的坐标。
然后在这一空间中根据非线性映射规则,利用线性学习器进行数据处理和分析,具体过程为
(4)
式(4)中,T(xi,yi)表示线性处理后的数据坐标,k表示空间维数,ζ表示非线性映射规则,即映射函数。
根据处理后的数据,构建特征集Q和F,二者之间的线性变换为F=ZQ,其中Z表示线性变换矩阵。对其进行矩阵转置可以得到:
RF=ZRQZT
(5)
式(5)中,RF和RQ分别表示向量Q和F的自相关矩阵,其中RQ可以通过Q的M个样本估计得到,其计算公式为
(6)
式(6)中,xj表示第j个数据样本,当T为正交矩阵时,RF有i个正实特征根pi,i=1,2,…,n,即主分量(数据特征值),由它们共同组成的矩阵RF为
RF=[pi],p1>p2>…>pn
(7)
此时,可选择f个最大特征值对应的特征矢量构成维数子空间,其中分量与数据特征值的比值能够反映正实特征根集合Y中第i个分量yi整体方差的贡献,其贡献越大,该分量越重,计算公式为
(8)
根据式(8)提取出贡献较大的分量,将其作为数据特征,完成数据特征的提取处理。
1.3 构建分类器模型
以上述数据特征提取结果为基础构建分类器模型,实现迭代式数据的均衡分区,以机器学习中的决策树为依据构建分类器模型,从而精准、高效地实现迭代式数据均衡分区。
首先,提取决策树中的信息熵来反映迭代式样本数据的不确定性:
(9)
式(9)中,o表示所提取的特征样本数据量,P(i)表示数据集中属于类别i的样本占总样本数量的比例。
根据数据的时空特性,给出迭代式数据的时空距离公式:
(10)
式(10)中,Dis(i,j)表示第i个数据时间点在序列x和第j个数据时间点在序列y之间的时空距离,d(x(i),y(j))表示在时空位置(i,j)的特征点x(i)和y(j)之间的距离,min(d(i-1,j),d(i,j-1),d(i-1,j-1))表示到达位置(i,j)的3种可能路径中的最小距离。
根据迭代式数据的时空距离公式,可得到迭代式数据间的相似度公式如下:
(11)
假设t表示数据采样周期,每隔周期t进行1次数据均衡分区操作。在建立数据分区规则过程中,假设Load(OSDm)表示样本数据当前的分区情况,若分区节点OSDm的I/Q(即数据属性与区域)任务列表Qm中的数据任务数为R,则:
(12)
分类器模型分区均衡度的计算公式如下:

(13)
式(13)中,r0表示分类器的整体分区水平,r0越大,分类器分区水平越高,Cm表示节点OSDm的负载水平。依据决策树构建分类器,寻找数据属性与区域之间的关系,即分辨出数据属于哪一个分区,从而实现数据的准确分类。
综上所述,在数据集成与数据特征提取的基础上实现对迭代式数据的均衡分区。
2 实验分析
2.1 数据集和实验指标
为测试基于机器学习的迭代式数据均衡分区算法的有效性,使用公共数据集KDD99作为实验数据集,该数据集包含网络连接的相关信息,主要涉及网络连接的特征和类别标签。特征包括连接的网络通信协议及传输协议类型,具体包括源IP地址、目标IP地址、目标端口号、连接时长等通信信息。在该数据集中随机选取400 000个数据,分别构建训练集和测试集。对于测试数据集,其数据量为200 000,使用学习率0.001进行运算,周期为20个;对于训练数据集,其数据量为200 000,使用学习率0.0001进行运算,周期为80个。在多次训练测试过程中,不断优化参数,提高分类器模型性能,使其在处理大数据样本时可更好地实现迭代式数据均衡分区。测试相关平台配置如表1所示。

表1 平台配置
考虑数据分区后,数据实现均衡分布,将查全率、查准率和数据分区均衡性作为评价指标。其中,查全率能够反映算法分区结果的全面性,查全率越高,检测和识别少数类别样本的效果越好,即表示本文算法性能越好。计算公式为
(14)
式(14)中,TP表示数据正确分区数量,FN表示数据错误分区数量。
查准率是衡量算法分区结果的准确率,指的是将某一类别样本分为真正属于该类别样本中的比例。查准率越高,表示本文算法在分辨不同类别上具有较高的准确性和可靠性。其计算公式为
(15)
式(15)中,FP表示错标为正样本的负样本数。
数据分区均衡性是相关数据分区方法的重要衡量标准,其值越大,说明分区水平越高,主要由分类器的整体分区水平决定,故其计算公式见式(13)。
2.2 实验结果
从图2可以看出,利用本文算法对数据样本进行迭代式均衡分区,查全率呈现持续增长的趋势,高于90%,而文献[5]和文献[7]方法的最高查全率在70%左右,文献[6]、文献[8]和文献[9]方法的最高查全率在50%左右。与其他文献方法相比,本文算法的查全率增长幅度较为明显,因此本文提出的基于机器学习的迭代式数据均衡分区算法性能更优越。
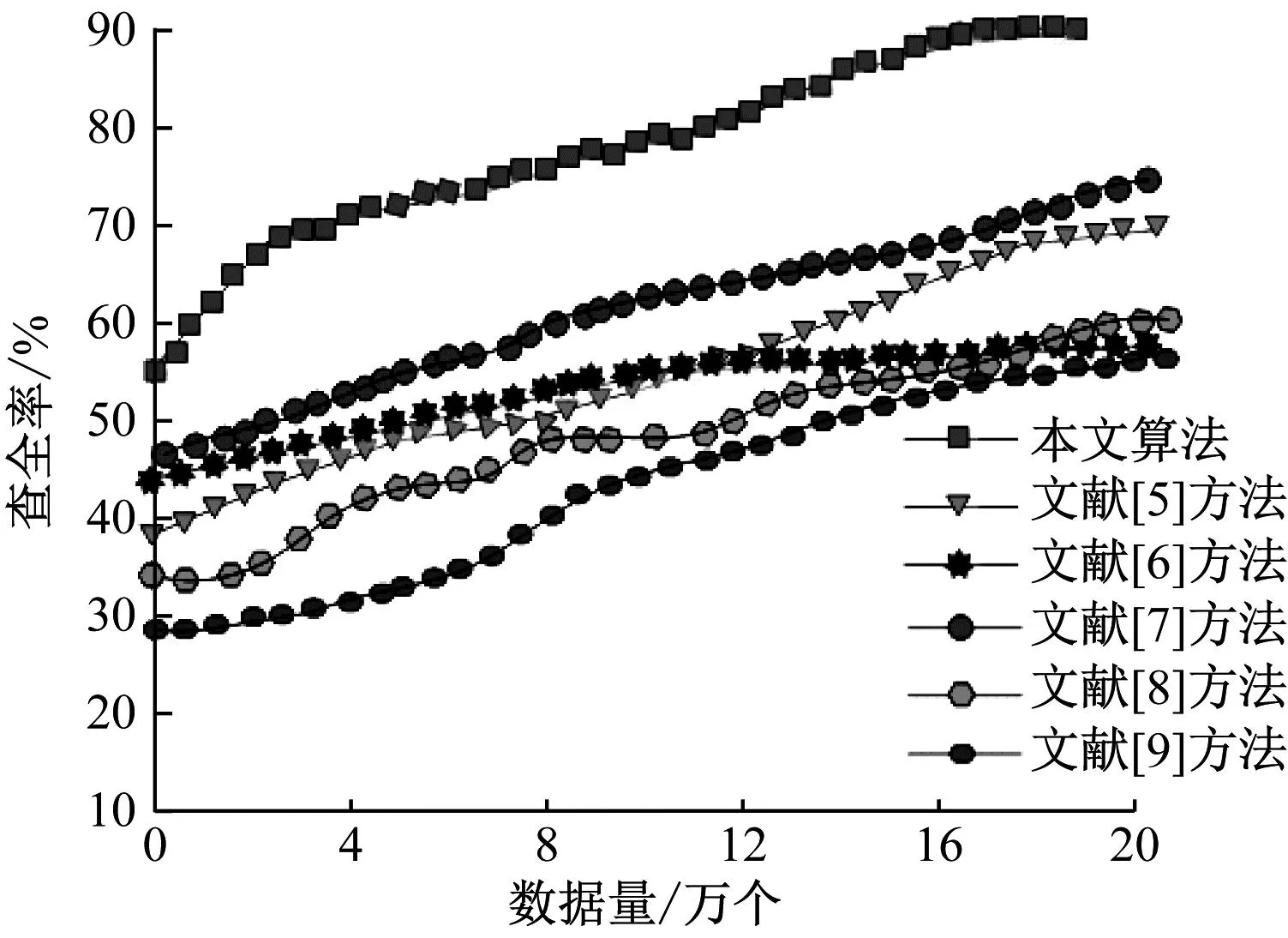
图2 不同算法的查全率对比结果
分析图3可知,随着检测时间的增加,6种方法的数据查准率均有所下降,但是本文算法的平均查准率明显高于其他文献方法。虽然在8~12 s的区间里,本文算法的查准率有所下降,但是在实验后期又有所提高,并持续保持平稳,平均查准率在 85%以上。相比较之下,其他文献方法只在实验开始阶段保持较高的查准率,随着检测时间的增加,查准率呈极度下降的趋势,尤其是文献[5]和文献[8]方法,文献[6]和文献[9]方法次之,文献[7]方法的查准率相对较高,但对比本文算法差距仍较大。根据上述分析可知,本文算法在查准率方面具有明显的优势,可以在对迭代式数据进行均衡分区中保持良好的准确性,确保分区结果的可靠性。
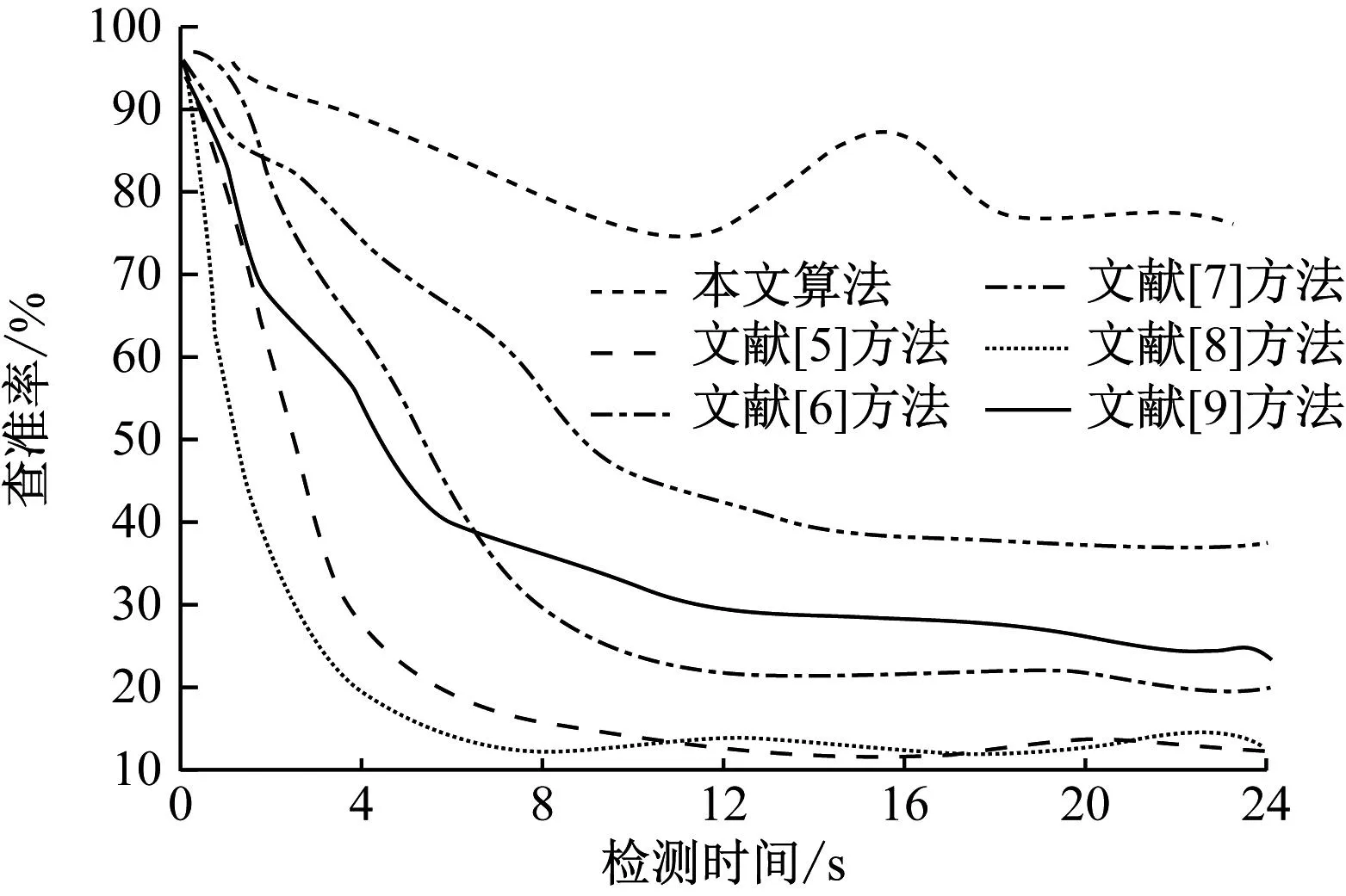
图3 不同方法的数据查准率比较结果
分析图4可知,文献[5]和文献[6]方法的均衡性存在波动现象,说明这2种方法的数据分区均衡性较差,文献[8]和文献[9]方法的波动性虽然较小,但均衡性数值低,文献[7]方法的波动性小且均衡性相对较高,但仍旧低于本文算法。较其他方法,本文算法的均衡性数值较高,均值在6左右,且波动幅度较小,说明本文算法不仅能够完成对迭代式数据的均衡分区,并且分区过程较为稳定。这是由于所提算法在中心数据库的辅助下对数据进行集成,该数据库最大优点是能够对提取到的数据进行最大控制,能够有效解决数据分散性、多元性和冗余性等问题,从而提高了数据分区的均衡性。
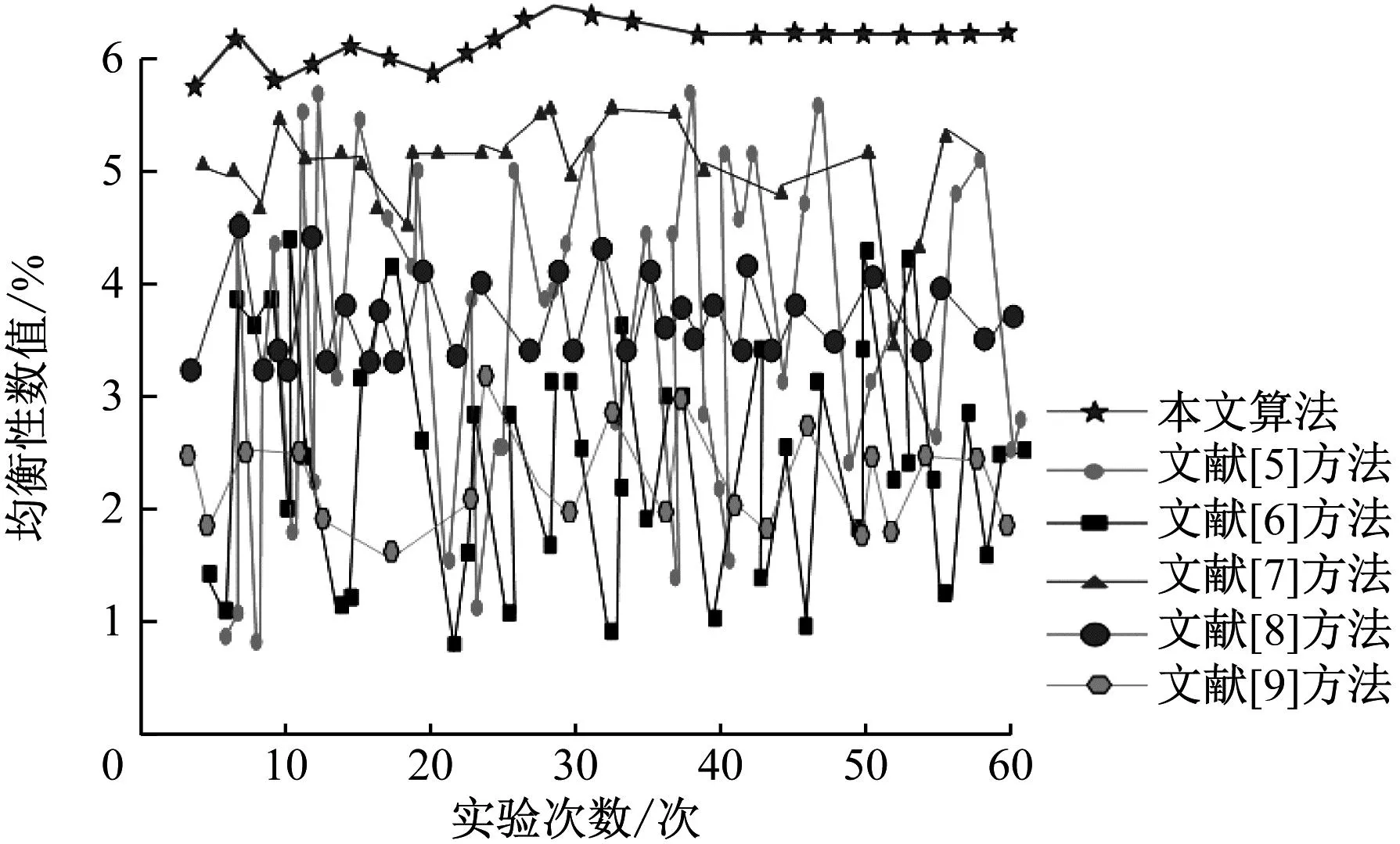
图4 不同方法的数据分区均衡性比较结果
3 总结
本文针对传统方法存在的数据查准率、查全率较低和均衡性较差的问题,在机器学习的基础上,对数据进行迭代式数据均衡分区研究,提高了数据分区的查全率和查准率,并且本文算法在数据分区均衡性方面均优于传统方法,能够为数据分区工作提供参考,提高工作效率。未来会将研究重点放在抗干扰方面,以期进一步提高数据采集的准确性,提升数据查全率,从而提升迭代式数据均衡分区效果。
猜你喜欢
经济与管理(2020年4期)2020-12-28
现代电子技术(2018年20期)2018-10-24
现代电子技术(2018年16期)2018-08-21
现代情报(2018年11期)2018-01-07
现代电子技术(2017年23期)2017-12-20
计算机应用(2016年10期)2017-05-12
行政法论丛(2016年0期)2016-07-21
学习月刊(2016年14期)2016-07-11
学术探索(2015年7期)2015-12-17
中国管理信息化(2009年10期)2009-06-19
