基于同步辐射X射线荧光光谱与一维卷积神经网络的癌症筛查方法
2024-01-09 02:54魏超杰解宏鑫李玉锋李玉文
中国无机分析化学 2024年1期
魏超杰 李 超 解宏鑫 王 欣 李玉锋 李玉文 刘 杨 王 伟*
(1.中国农业大学 工学院,暨全国金属组学创新研究中心,北京 100083;2.安徽医科大学 第二附属医院,暨全国金属组学创新研究中心,合肥 230032;3.中国科学院高能物理研究所,中国科学院-香港大学金属组学与健康和环境联合实验室,中国科学院纳米生物效应与安全性重点实验室,暨全国金属组学创新研究中心,北京 100049;4.安徽医科大学 基础医学院,暨全国金属组学创新研究中心,合肥 230032)
癌症是引起全球范围内高发病率和高死亡率的公共卫生疾病之一。根据国际癌症研究机构(International agency for research on cancer,IARC)的报告,人类癌症的发病率和死亡率正在迅速增加[1]。对于晚期癌症患者,经过有效治疗5年存活率小于50%[2]。若能尽早发现并治疗,能够在很大程度上降低死亡率。而临床上对于癌症患者筛查需要一系列操作,速度较慢,因此有必要开发一种快速癌症筛查的方法。
目前癌症的临床诊断方法有体液生化指标检测、X射线影像[3]、计算机断层成像[4]、核磁共振影像[5]、超声影像[6]、内镜检查[7]等,这些方法存在主观依赖性强、价格昂贵、局限性大等不足,迫切需要快速、准确、无损的癌症筛查方法。金属组学[8]是系统研究生命体内自由或络合的全部金属/类金属元素的含量、分布、化学种态及其功能的一门新兴学科。以健康与癌症人群体内血液的金属组作为靶标物,有助于癌症患者的筛查。
微量元素的浓度是身体疾病的另一种信息来源。众所周知,某些元素在调节和决定生物体健康的多种生化过程中发挥着重要作用。CHEN等[9]通过使用原子荧光光谱法(AFS)和电感耦合等离子体原子发射光谱法(ICP-AES)测定健康人与心血管患者血液与尿液中的9种元素(铬、铁、锰、铝、镉、铜、锌、镍和硒),发现正常人血液与尿液内所有的元素浓度均高于心血管疾病组,使用决策树建立分类模型最高可达到97.6%的准确率。CARTER等[10]以微波诱导等离子体原子发射光谱法(MIP-ONS)与电感耦合等离子体质谱法(ICP-MS)测定脚趾甲22种元素并结合其他指标作为特征,采用随机森林建立糖尿病预测模型,最优模型的受试者工作特征曲线下面积达到0.9。LIN等[11]采用ICP-AES与ICP-MS技术测定血清中39种微量元素,结合机器学习算法对精神分裂症的识别准确率能够达到99.21%。因此人体内元素水平可以反应健康状态,用于疾病的筛查。
使用电感耦合等离子体光学发射光谱(ICP-ONE)和ICP-MS法可以量化元素的含量,具备精确度高、检出限低等优点。但具有破坏性,同时测量浓度差异较大的多种元素时,需要使用多种技术组合。而SRXRF具有预处理少、非破坏、宽分析范围[从轻元素(锂、硼)到重金属元素(铀、钚)]、检测速度快、适用样品广等优点。SRXRF技术通过校正仪器响应和建立标准曲线来预测元素的含量,但定量分析受到多种因素影响。因此本文尝试使用SRXRF作为研究手段进行癌症患者的筛查。
基于SRXRF的平均光谱偏最小二乘判别分析(PLSDA)与支持向量机(SVM)的机器学习算法,预处理方法单一,样本数量有限[12]。为了从大数据集中挖掘数据特征,此次研究增加了血清样本数量,以同一个样本不同位置的光谱作为输入开发卷积神经网络,以适应大数据发展时代下的癌症筛查方法研究。
受生物视觉感知机制启发的卷积神经网络(Convolutional Neural Network,CNN)被证明可以从原始数据中提取有效特征进行分类或者回归的有效手段[13]。二维卷积神经网络在图像处理[14]和目标检测[15]方面取得一定的研究成果。但一维卷积神经网络(One dimensional-convolutional neural network,1DCNN)可以处理序列数据,且具有较少的参数量,较小的过拟合风险,成功用于近红外光谱[16]、拉曼光谱[17]和其他一维信号[18]等研究。因此,构建1DCNN模型,从SRXRF数据中提取深层特征,建立癌症患者的筛查模型具有可行性。
在本研究中,将SRXRF和1DCNN结合展示非靶标金属组学在血清样本中筛选癌症患者中的应用。通过分析光谱差异,研究控制组与癌症组的标志物。建立预处理与化学计量学和1DCNN的癌症分类模型。并以特异性,灵敏性验证模型性能。本研究有助于推动SRXRF技术在癌症患者筛查方法的应用研究。
1 实验方法
1.1 样品准备
本研究的血清样本采集实验在安徽医科大学第二附属医院进行,于上午6:00-8:00采集志愿者空腹状态下的静脉血液,保存于离心管内,使用3 000 r/min离心机离心10 min,取上层血清。无各类疾病的健康志愿者与病理证实的肺癌与胃癌志愿者提供血清样本,两者在年龄、性别上无明显差异。健康志愿者的血清样本称为控制组,癌症志愿者为癌症组,共收集269份血清样本,包含161份控制组与108份癌症组样本。所有志愿者均签署了知情同意书,本工作获得了安徽医科大学伦理委员会同意。
1.2 数据获取
在北京同步辐射装置4W1B束线上进行SRXRF数据采集,设备运行的能量为2.5 GeV,束流强度为150~250 mA[19]。将60 μL血清滴在滤纸上,风干后固定在移动平移台上,采用Si(Li)固态探测器检测X射线荧光强度。在每个血清样本的不同位置进行22次连续点扫描,共收集5 918(269×22)条荧光光谱。计算每个样品的22条光谱的平均值称为平均光谱,共269条用于化学计量学的模型建立,5 918条荧光光谱称为像素级光谱,用于1DCNN模型建立。
1.3 光谱预处理
采用归一化处理、Savitzky-Golay平滑(SG)、迭代自适应加权惩罚最小二乘法(Adaptive iteratively reweighted penalized least squares,airPLS)、标准正态变化(Standard normal variate,SNV)作为光谱预处理手段。归一化处理可以消除志愿者体内微量元素量级差异对SRXRF的影响。采用15点2次线性SG平滑对曲线进行去噪,减少仪器与环境对光谱曲线的影响。目前效果最好的基线校正方法是airPLS,采用基于误差的迭代加权策略,基于上一次循环拟合的基线和原始信号之间的差异来纠正谱线。SNV能够消除光程差异、散射和样品稀释等引起的误差,使数据具有可比性。
1.4 化学计量学算法
采用偏最小二乘判别(Partial least squares linear discriminant analysis,PLSDA)、K近邻算法(K-nearest neighbor,KNN)、簇类独立软模式分类(Soft independent modeling of class analogy,SIMCA)对癌症组进行筛选。PLSDA是一种常用的多变量校准方法,它通过将光谱数据投影到一个新的空间中来搜索一系列与响应变量高度相关的潜在变量,本研究采用五折交叉验证法优化潜变量的数量[20]。KNN是一种非常经典的分类算法,未知样本的类别由其最接近的K个临近值来代表[21]。采用欧式距离作为度量,采用五折交叉验证选择最优邻域值K。SIMCA是以主成分分析为基础的定性分析方法[22],通过将数据投影到最优主成分子空间中实现分析和分类的目的。
1.5 深度学习算法
CNN是在前馈神经网络的基础上通过增加卷积操作而发展起来的。SRXRF能够反应血清中微量元素的信息,因此可以将连续的SRXRF数据作为一维方向的像素点,使CNN应用于SRXRF分析具有可行性。本文参考LeNet模型,将二维卷积神经网络变形,以连续通道的SRXRF光谱作为输入,共提出三种1DCNN框架(图1)。
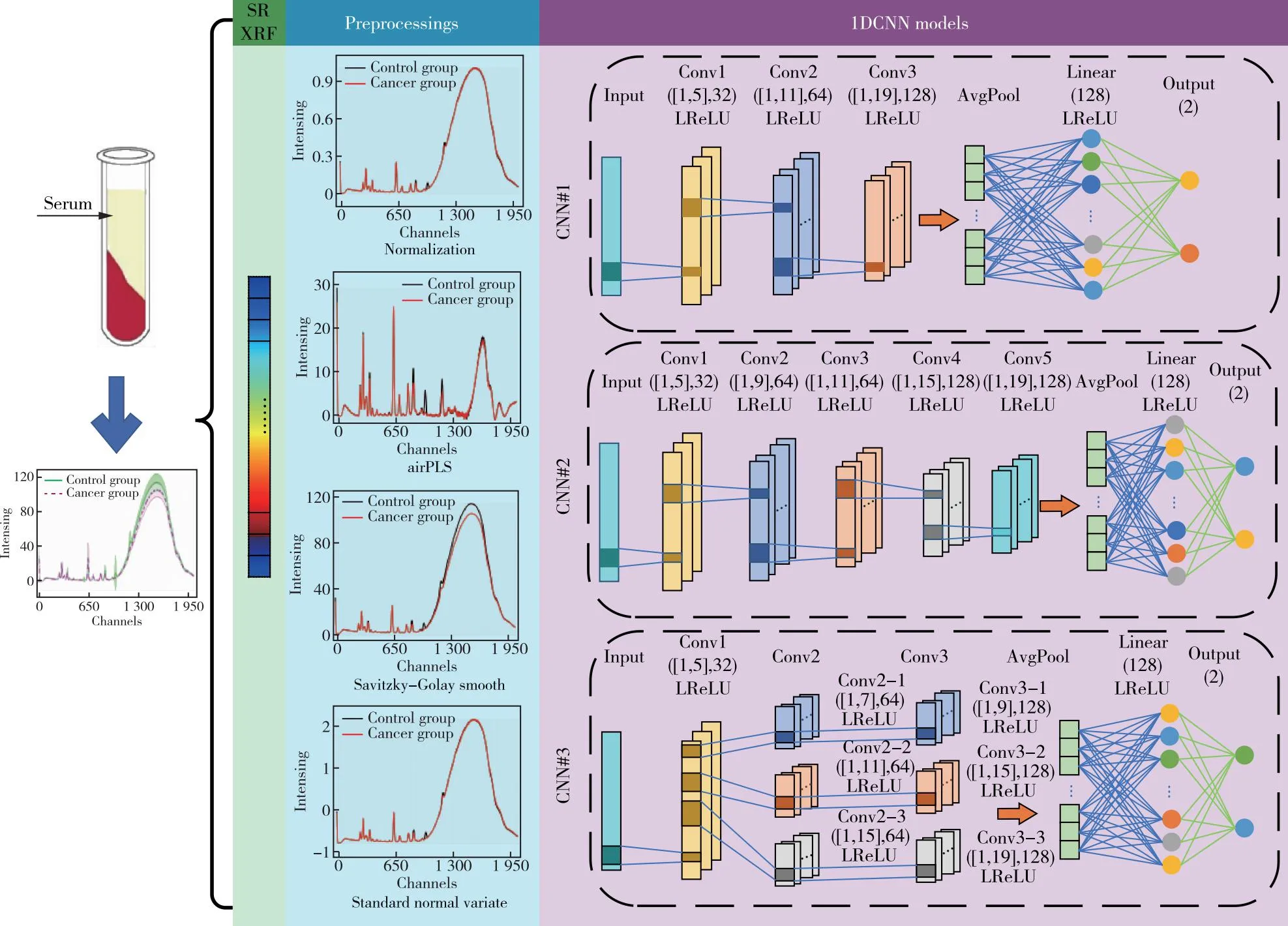
图1 一维卷积神经网络模型Figure 1 A one-dimensional convolutional neural network model.
第一个1DCNN模型是由三个卷积层和一个全连接层组成的浅CNN模型(CNN#1)。三层卷积的卷积尺度大小分别为1×5、1×11、1×19,卷积核为32、64、128,步幅为2、5、9。第二个模型是由五个卷积层和一个全连接层组成深CNN模型(CNN#2)。CNN#2与CNN#1第一层卷积相同,第二到五层卷积的卷积尺度大小分别为1×7、1×9、1×11、1×13,卷积核为64、64、128、128,步幅为3、3、5、7。第三个是宽CNN模型(CNN#3),CNN#3与前两个模型的第一层卷积相同,而Conv3、Conv2与Conv1串联,Conv2与Conv3内各含有三个卷积层,并保持并行处理数据,其中Conv2-1与Conv3-1串联,并保持小的卷积尺寸,Conv2-2和Conv3-2保持中等卷积尺寸,Conv2-3与Conv3-3保持最大卷积尺寸,具体参数如图1所示。三种模型的卷积层后采用BatchNorm进行归一化和Leaky ReLU函数进行激活,激活函数的表达式如式(1)所示:
(1)
α称为Leaky系数,在此处取0.1。特征提取后采用自适应最大池化和全连接层,输出有两个节点,分别对应控制组与癌症组。
模型的训练过程,将SRXRF光谱(1×2025)输入到3个1D-CNN模型中,将标签0、1转换为One-hot形式,三种模型的输出层为2个神经元,使用“Sigmoid”激活函数判断分类概率。设置Batch size的大小为512,初始学习率为1×103,迭代次数Epoch为600,模型损失函数为BCEloss,优化器为Adam(Adaptive moment estimation)优化器,为了训练过程中更好的收敛,Adam动量项权重衰减系数β1为0.9,学习率衰减系数为0.999。采用t-分布随机邻域嵌入算法(t-distributed stochastic neighbor embedding,tSNE)进行卷积神经网络模型的特征可视化。
1.6 模型评价
在建立模型前,样本被随机分为校正集(2/3)和预测集(1/3),通过计算校正集和预测集的正确分类率(Correct classification rate,CCR)来评价模型,CCR的计算公式如式(2)表示:
(2)
其中,N1和N2分别为校正集和预测集正确的数量和总数。进一步,为了评估模型的鲁棒性和可靠性,从混淆矩阵计算得到特异性与灵敏度,分别使用式(3)或(4)来评估每种类型样本的分类精度。

(3)

(4)
式中TP、TN、FN、FP分别代表真阳性(True positive)、真阴性(True negative)、假阴性(False negative)、假阳性(False positive)。
在Windows系统上基于Matlab和Classification toolbox 5.4搭建化学计量学模型。基于PyCharm开发环境与Pytorch框架搭建1DCNN模型,采用NVIDIA GeFore RTX 1650 4GB GPU进行模型训练。
2 结果与讨论
2.1 光谱分析
图2显示了两类志愿者血清数据在0~2 025通道内的SRXRF平均光谱及标准差。光谱曲线基本走势与HE等[12]的研究一致。在本实验中,数据采集条件一致,血清样本体积相同,通过对光谱曲线峰面积的拟合,可反应血清中金属元素的差异,其中371、588、862、992、1 189通道附近的峰面积拟合为Ca、Mn、Zn、Ge、Br。呈现出的规律为控制组中对应的通道强度高于癌症组,即控制组体内上述元素含量高于癌症组。CALLEJN-LEBLIC等[23]的研究提出V/Mn与V/Zn的比值作为肺癌中金属标志物,HE等[13]提出Ca和Zn作为癌症标志物,PIACENTI等[24]的研究指出癌症组织中的Ca、Cu、Zn低于正常组织,上述文献与本研究中SRXRF的Ca、Mn、Zn差异情况一致。
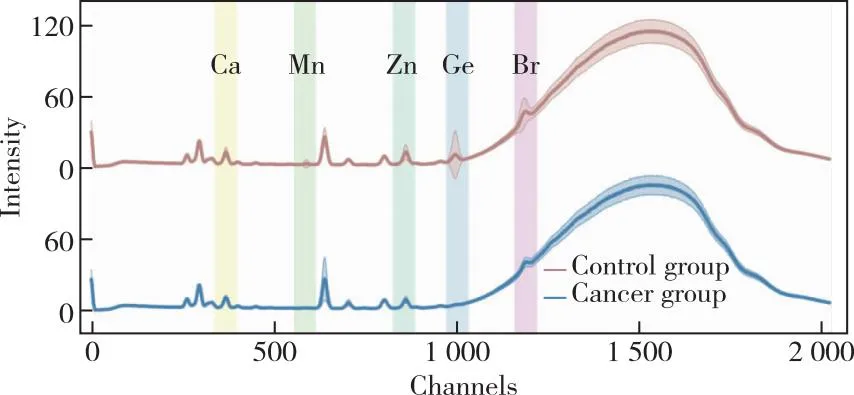
图2 控制组与癌症组SRXRF均值曲线Figure 2 The averaged SRXRF spectra of serum samples in the control group and cancer group.
Ge是一种能在外部诱发癌症的一种微量元素,在肿瘤患者体内作为重要标志物[25]。曾昭华等[26]的研究表明,土壤中Br与食道癌、宫颈癌死亡率呈负相关,与肝癌、鼻咽癌死亡率成正相关。以上元素对于癌症的筛查具有显著意义,对于提取特征通道,简化模型,识别癌症标志物具有重要意义。
2.2 化学计量学模型
PLSDA、KNN和SIMCA分类准确率及最优的关键参数列于表1,参数LVs/K表示PLSDA与SIMCA的最优潜变量数与KNN的最近邻数。在PLSDA模型中,预处理后的准确率相对于原始数据均有一定程度的改善,airPLS基线校正后的准确率最高,校正集、预测集和交叉验证集分别达到了90.76%、89.76%、88.67%。在KNN模型中,原始数据的预测集准确率达到了92.13%,仅有SG平滑预处理改善了准确率,而其他预处理准确率低于原始数据预测结果,KNN的分类结果整体上均优于PLSDA模型。在SIMCA模型中,归一化预处理取得最优分类结果,校正集、预测集与交叉验证集分别为91.93%,90.95%和90.45%。

表1 基于化学计量学的分类性能
根据模型预测结果,预处理能够改善模型准确率,但错误地使用预处理方式会削弱有效信息甚至引入新的噪声。模型的选择比预处理方式的选择对模型的分类影响更大,本次数据中KNN的模型准确率优于其他模型。
为了进一步验证模型的预测能力,预处理与三种模型的最优组合airPLS-PLSDA、SG-KNN、Normalization-SIMCA的预测集的混淆矩阵如表2所示。三个模型对于癌症组的灵敏性均大于91.67%,而特异性均大于84.91%,对于癌症的精确度最高仅为89.47%,表明易将控制组样本误识别为癌症组样本。采用一维卷积神经网络进一步提高准确率。

表2 化学计量学模型的混淆矩阵
2.3 卷积神经网络模型
为了增加模型的泛化能力增加鲁棒性,以5 918条SRXRF谱线作为网络的输入。三种1DCNN的预测结果如表3所示。在模型中,归一化预处理对于CNN#1的准确率有所改善,其他预处理相对于原始数据会造成模型的准确率下降,这跟ZHANG等[27]相关研究中表述的一致,虽然预处理可以改善原始数据,但会导致原始信息的丢失,甚至不恰当预处理,反而会引入新的噪声,造成模型准确率下降。

表3 卷积神经网络模型性能
CNN#2相对于CNN#1的准确率有所提高,是卷积层在提取特征方面发挥作用,CNN#1卷积层数较少,提取特征有限,并不能充分发挥模型优势,而CNN#2增加了卷积层的层数,预测集的准确率提高了1.68%。但在提高准确率的同时,导致模型参数增加,训练模型花费的时间更多,CNN#1迭代一个周期仅需0.29 s,即仅需180 s可完成模型的训练,而CNN#2迭代一次需要消耗0.56 s,时间是CNN#1的1.93倍。CNN#3相对CNN#1而言具有相似的准确率,虽然具备更宽的卷积尺度,但并没有明显提升,原因可能是CNN#1中Conv2和Conv3具备较宽的卷积尺寸,模型的特征提取能力与CNN#3相同,均能够提取原始光谱中绝大部分有效特征。
卷积神经网络的卷积层具备提取特征的能力,将三种模型提取特征后的输出(128个特征)进行tSNE降维处理,保留前三个维度,可视化后的结果如图3所示,发现控制组和癌症组绝大部分能够很好地分为两类,但是依然有重叠的部分存在,表示神经网络提取的特征能够有效筛查癌症患者。
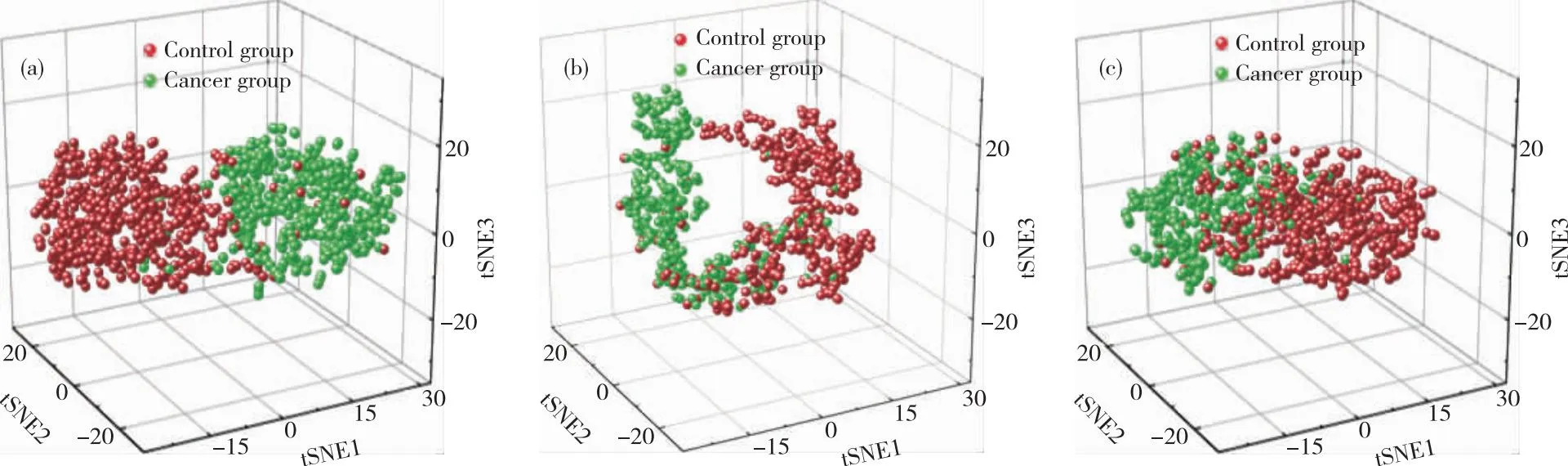
图3 1DCNN提取特征tSNE(a)CNN#1;(b)CNN#2;(c)CNN#3Figure 3 tSNE diagrams of 1DCNN feature extraction(a)CNN#1;(b)CNN#2;(c)CNN#3.
3 结论
针对控制组与癌症组志愿者的血清样本,采用SRXRF对血清样本进行数据采集,获得5 918个SRXRF数据。对原始谱线分析发现了控制组与癌症组的有效标志元素Ca、Mn、Zn、Ge、Br。采用预处理与化学计量学结合的方法,建立基于平均光谱的分类模型,模型准确率为93.6%。采用1DCNN进行分类,模型准确率为95.24%,并可视化提取的特征,提取的特征对筛查癌症患者具有较好的可分性。本研究有利于推动SRXRF结合深度学习开发非靶标金属组学方法,实现癌症患者的快速筛查。
猜你喜欢
好日子(2021年8期)2021-11-04
青少年科技博览(中学版)(2019年7期)2019-10-11
文教资料(2019年31期)2019-01-14
海峡姐妹(2018年7期)2018-07-27
特别健康(2018年4期)2018-07-03
特别健康(2018年2期)2018-06-29
制导与引信(2017年3期)2017-11-02
校园英语·中旬(2016年8期)2016-07-09
工业设计(2016年11期)2016-04-16
环境科技(2015年6期)2015-11-08