
基于平衡二叉树和Bloom过滤器的可变长地址路由查找算法
2024-01-09 02:42:10黄永锦覃毅芳周旭张心晴
计算机应用 2023年12期
黄永锦,覃毅芳*,周旭,张心晴
基于平衡二叉树和Bloom过滤器的可变长地址路由查找算法
黄永锦1,2,覃毅芳1*,周旭1,张心晴1,2
(1.中国科学院 计算机网络信息中心,北京 100083; 2.中国科学院大学,北京 100049)(∗通信作者电子邮箱qinyifang@cnic.cn)
可变长地址是未来网络领域的重要研究内容之一。针对传统路由查找算法在面向可变长地址时查找效率低的问题,提出一种基于平衡二叉树AVL(Adelson-Velskii and Landis)树和Bloom过滤器的适用于可变长地址的高效路由查找算法,简称为AVL-Bloom算法。首先,针对可变长地址灵活可变且无界的特点,利用多个片外哈希表分别存储前缀比特位数相同的路由条目及其下一跳信息,同时应用片上Bloom过滤器加速搜索可能匹配的路由前缀;其次,为了解决基于哈希技术的路由查找算法在查找最长前缀路由时需多次哈希对比的问题,引入AVL树技术,即通过AVL树组织每组路由前缀集合的Bloom过滤器及其哈希表,优化路由前缀长度的查询顺序,并减少哈希计算次数进而降低查询时间;最后,在3种不同的可变长地址数据集上将所提算法与METrie(Multi-Entrance-Trie)和COBF(Controlled prefix and One-hashing Bloom Filter)这两种传统路由查找算法进行对比实验。实验结果表明,AVL-Bloom算法的查询时间明显少于METrie和COBF算法,分别减少了将近83%和64%;同时,AVL-Bloom算法在路由表项数变化较大的情况下也能维持稳定的查找性能,适用于可变长地址的路由查找转发。
可变长地址;路由查找;AVL树;Bloom过滤器;哈希算法
0 引言
随着移动互联网的广泛普及,互联网承载的业务种类不断丰富,网络新应用也层出不穷;然而,随着互联网与各行各业不断深入融合,以及以增强现实(Augmented Reality, AR)、虚拟现实(Virtual Reality, VR)和全息通信等为代表的全新业务、全新场景的涌现,传统互联网基于固定有界的网际互联协议(Internet Protocol, IP)地址实现互联互通的缺陷逐渐暴露,且缺乏灵活、有效的扩展方式适应未来多样化、专业化业务的发展需求。可变长地址技术是解决上述问题的一种有效方案,它能够根据网络规模和应用场景需求的不同提供适应长度的地址结构。由于满足各种异构网络、异构终端实现万物互联的需求,支持可变长地址结构的未来网络体系也相继被提出并成为研究的热点,如泛在IP(Ubiquitous IP, UIP)协议体系[1]、FlexIP(Flexible IP)协议体系[2]、NewIP(Network 2030 and the future of IP)协议体系[3-4]等。
然而,虽然可变长地址具有灵活可变长的优点,能够依据实际需求定制地址长度,但是也给路由查找带来了一定的困难。如果仍然以最长前缀的地址长度统一存储所有路由条目并基于此进行路由查找,将对路由查找算法的存储空间和查找性能带来巨大挑战。
通常,传统路由查找算法基于Trie[5-6],或者基于硬件三态内容寻址存储器(Ternary Content Addressable Memory, TCAM)[7-9]实现路由查找。基于Trie的路由查找算法结构简单、易于实现,但是每次路由查询时都需要大量的内存访问。由于可变长地址长度灵活,所以它的长度远大于传统IP的地址长度,若直接将基于Trie算法的路由查找技术应用于可变长地址路由查询,它的查询性能将受到极大的限制,因此基于Trie算法的路由查找技术不适合可变长地址的路由查找。基于硬件的路由查找算法由于受到高成本和高功耗的限制,而且难以灵活扩展,因此也不适用于面向灵活可变长地址的路由查找。可变长地址给路由查找及其数据结构设计带来了新的挑战,传统的路由查找算法难以直接应用,所以针对可变长地址的特点展开路由查找算法的研究成为当前的热点。
鉴于此,本文基于平衡二叉树AVL(Adelson-Velskii and Landis)树和Bloom过滤器提出了一种适用于可变长地址的高效路由查找算法——AVL-Bloom算法。该算法对每一组长度相同的路由前缀都利用一个Bloom过滤器和相应的存储哈希表构建,哈希表存储路由前缀及其下一跳信息;同时,该算法依据地址前缀长度构建平衡二叉树,每一个树节点包含一组前缀长度相同的Bloom过滤器及其哈希表,用于检验任意可变长地址的路由前缀是否存在于该节点。AVL-Bloom算法不但解决了由于地址长度过长导致分支树前缀扩展带来的内存资源浪费问题,而且可以有效地缓解基于哈希进行路由查找时需要从地址最大比特长度位数依次递减进行多次哈希比较,直到获得最长前缀的缺陷。
1 相关工作
路由查找是分组交换网络中通过查询路由前缀集合以获取下一跳转发信息的过程,它的结果用于指导路由器进行数据包的转发。路由查找的效率很大程度上决定了路由器的性能,因此,各种基于软硬件的路由查找算法也相继被提出,如基于Trie树和基于TCAM等一系列路由查找算法。
在未来网络研究领域,可变长地址结构的相关设计与研究也逐渐成为热点,可变长地址背景下的路由查找相关解决方案也成为领域内亟须解决的难题。
METrie(Multi-Entrance-Trie)[10]是首先被提出用于可变长地址的路由查找算法。METrie使用了多分类路由表的存储方法,并通过地址长度扩展的方式将非对齐的可变长地址分类为固定长度的地址,使可变长地址能够使用传统的Trie树算法查找;然而,METrie的结构复杂,特别是动态更新操作时需要进行大量的修剪和扩展,导致了频繁的内存访问,难以满足海量数据通信下未来网络业务的高效路由需求。
COBF(Controlled prefix and One-hashing Bloom Filter)[11-12]是一种基于Bloom过滤器的路由查找算法,该算法通过可控前缀扩展限制可变长地址的前缀长度,减少了所需Bloom过滤器数,并通过优化Bloom过滤器的哈希函数,减小了误报对算法的影响;然而,COBF算法由于哈希技术的局限性,查找最佳路由前缀时需要多次哈希运算操作,哈希运算次数的增加会显著影响算法的查找效率,特别是在可变长地址的情况下,多次哈希运算导致的影响更加严重。
命名数据网络采用可变长地址结构的内容名称作为网络标识符,并基于此提出了面向可变长内容地址的路由查找算法。文献[13]中针对命名数据网络可变长字符标识符的特点,提出了一个基于哈希的命名数据网络路由查找算法。该算法通过比较不同类型的函数选取最优哈希函数,并结合Bloom过滤器预查询取得了较好的路由查找性能;然而该算法并没能降低查询过程的哈希次数,不能从根本上解决基于哈希算法的弊端。
传统基于哈希的路由查找算法中,各个路由条目数据没有相关性,每个哈希表只能存储同一长度的路由前缀,进行路由查询时也只能对每个前缀进行哈希匹配实现精确查找。当查找最长路由前缀时,只能从地址的最大比特位长度开始依次递减进行多次哈希,直到找到匹配的前缀为止,因此算法中的哈希次数成为影响路由查找算法查找效率的关键因素。针对此问题,文献[14]中首先提出通过降低哈希次数提升路由查找效率的算法。该算法将路由条目存储于哈希表,并使用平衡二叉树二分查找所有的哈希表,提高了路由查找效率;然而该算法直接将路由条目存储于哈希表,在每次路由比对时都需要进行内存访问,对路由查找效率造成了较大的影响。
综上所述,现有的可变长地址路由查找算法尚存在以下几点不足:1)由于可变长地址长度可变,路由条目基数较大,存储开销的问题亟须解决;2)由于可变长地址的长度较长,在查找最优最长路由前缀时,需要频繁地访问内存,极大影响算法的整体性能;3)基于哈希的算法虽然能够在一定程度上缓解存储空间占用的问题,但是在最长前缀的前提下进行查找需要多次哈希计算,加重了网元设备的处理负担。
针对上述路由查找算法存在的缺点,本文结合可变长地址的特点,设计了一个基于平衡二叉树和Bloom过滤器的可变长地址路由查找算法。该算法利用Bloom过滤器有效解决了可变长地址由于数量多所带来的内存开销过大及访存频繁的问题,同时通过AVL树推进最长前缀的查找顺序,有效地解决了基于哈希进行路由查找时哈希次数过多的问题。
2 AVL‑Bloom算法
针对可变长地址的特点,本文基于平衡二叉树和Bloom过滤器提出了AVL-Bloom算法。该算法利用片外哈希表存储长度相同的路由前缀及其下一跳信息,同时为了减少片外哈希表的访存次数,对每个片外哈希表都建立一个Bloom过滤器进行预筛选。虽然Bloom过滤器引入的哈希计算开销和天然存在的假阳性影响了查找性能,但是与访存带来的时间开销相比,它的总体查找性能仍然可以获得较大的提升,且内存访问次数更少。此外,针对查找时哈希次数过多的问题,AVL-Bloom算法使用一棵平衡二叉树组织不同长度前缀的哈希表和它的Bloom过滤器。在路由查找时,可以利用平衡二叉树快速查询的特性,将哈希计算次数从地址长度的比特位数级别降低到二叉树的高度级别,以大幅提升算法的查找性能。
2.1 AVL-Bloom算法的结构
AVL-Bloom算法的结构主要由AVL树结构、Bloom过滤器和存储路由条目的哈希表组成,具体结构如图1所示。虽然哈希表与Bloom过滤器技术在路由查找领域应用较广泛,然而基于朴素哈希表查找路由需要多次访问内存,传统Bloom过滤器天然存在假阳性和需要额外哈希计算的特点,直接应用这些技术查找路由的算法在整体性能上并不理想,特别是可变长地址。一些路由查找算法[15-16]通过改进哈希函数、减少冲突次数达到提升查找性能的目的。然而优化哈希函数并不能解决在最长前缀查找前提下需要多次哈希计算的问题,AVL-Bloom算法通过引入路由前缀控制技术和单哈希多次取余的方法优化路由查找的性能,同时依据长度分类路由条目并构建AVL树结构,使整个算法构建的查找树的高度维持在一个平衡状态,有效地控制了算法在查找最长路由前缀时所需的哈希计算次数,最大限度地提升整个路由查找算法的查找效率。
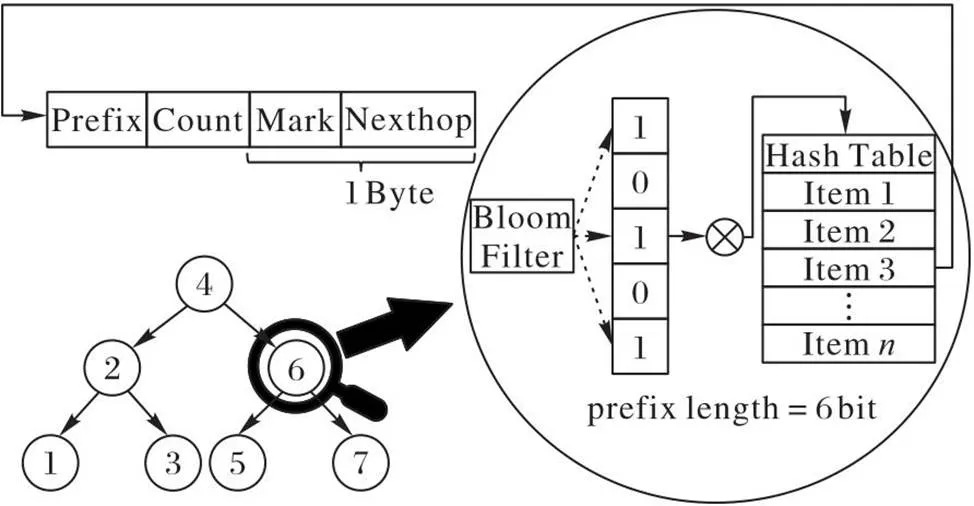
图1 AVL-Bloom算法的结构
2.1.1AVL-Bloom的AVL树结构
AVL-Bloom 算法的整体结构为一棵平衡二叉树,每一个树节点代表具有相同路由前缀长度的处理集合。以最大长度为7 b的可变长地址为例,根据AVL-Bloom算法构建的AVL树结构如图1左下部分所示。图1中每个树节点的数字代表当前树节点所存储路由前缀的比特位数,如根节点的值为4,即代表可变长地址所有路由前缀比特位数为4的路由条目都存储于该节点的哈希表中。由于基于哈希的路由查找算法在查找最佳路由前缀时,只能从目标地址的最大比特位数依次减少哈希位数寻找最长路由前缀,而AVL-Bloom树结构则采用折半查找的方式,极大地减少了哈希计算次数;因此AVL-Bloom算法通过AVL树优化查找推进顺序,有效提高路由查找效率。
2.1.2AVL-Bloom 树节点的数据结构
AVL-Bloom的每个树节点用于处理具有相同长度的路由前缀,由一个Bloom过滤器及其对应的哈希表组成。可变长地址的路由前缀可通过哈希表将不规则的路由前缀存储在有规律的哈希表中,并通过Bloom过滤器进行预筛选,可以有效地减少哈希表访问次数,提高路由查找的效率。在进行路由查找时,首先将待查询的地址输入Bloom过滤器进行比较,由于Bloom过滤器存在一定的假阳性概率,为了验证查找结果是否真实匹配,需再次检查片外哈希表。如果片外哈希表中存在相应的路由信息,则结束当前路由查找并根据相应信息转发;否则,继续根据AVL树的特点查询下一树节点,直至匹配成功或获取默认转发为止。
2.1.3AVL-Bloom 树节点哈希表结构
AVL-Bloom每个树节点哈希表所存储的路由条目由路由前缀Prefix、路由前缀计数器Count和下一跳信息Nexthop组成,Nexthop的最高位为最佳路由前缀标志位Mark。AVL-Bloom算法为了提高查询速度,避免算法在树的左右子树之间振荡,将路由前缀的子前缀插入遍历路径上的所有树节点。前缀计数器Count统计当前路由前缀是否为其他更长路由前缀的子前缀,便于路由条目删除时能够正确删除它相应的子前缀。Mark位标记当前路由条目是否为最佳路由前缀。当前缀计数器Count值为1时,说明该前缀只为一条路由的子前缀,它的结果和最长前缀一致,并将Mark位置为1标为最佳路由前缀。在进行路由查找时,当树节点中的Bloom过滤器预判该前缀存在于此节点并在哈希表中找到相应的路由条目时,首先判断该路由条目的Mark位是否为1,如果为1则结束查询并返回该前缀的下一跳信息;否则,说明该前缀不是最优前缀,继续往AVL树的右子树方向进行查找,直到找到最佳路由前缀。
2.1.4AVL-Bloom 树结构的建立
AVL-Bloom算法的建立过程主要是对核心数据结构进行实现并将路由前缀条目依次插入。具体描述如下所示:
步骤1 数据预处理。根据路由前缀集合的分布情况进行预处理,如果不同长度路由前缀的条目数差距较大,将导致树节点存储分布不均匀,查找递进比特位数较少,进而影响算法的查找效率。为此,可通过控制路由前缀方法[17],即采用“叶推法”将路由前缀长度的比特位数推到特定长度,从而减少树节点的数量和控制树的高度。
步骤2 建立AVL树。根据路由前缀集合中路由条目不同长度类型的数量建立AVL树,同时初始化各个树节点的哈希表及其对应的Bloom过滤器。
步骤3 添加数据。将集合中的路由条目依次遍历AVL树,查找合适的树节点并将该路由条目存储在节点的哈希表中,同时更新Bloom过滤器。
至此完成了AVL-Bloom算法的树结构的建立。
2.2 AVL-Bloom查找
路由查找算法的核心是查找效率,AVL-Bloom 算法的路由查找本质是一个二叉树遍历的过程,即通过依次比较树节点是否存在相应的路由条目实现路由查找的过程。假设可变长地址存在一条路由前缀为F506112233440000/48,根据AVL-Bloom的添加规则,当该路由条目添加到AVL树中时,将会在遍历路径上比它小的两个树节点(如图2中44和36节点),也分别存储该路由条目的子路由,并设置相应的Mark位。如图2所示,44节点存储了该路由条目的子路由,且没有其他路由的子路由与它相同,此时将Mark位置为1,标记为最佳路由;同时,由于36节点也存储了其他路由条目的子路由,则它的Mark位置为0。当进行路由查找时,可以根据Mark位标记当前路由是否为最佳路由,以便提前结束路由查询,提升算法查询效率。
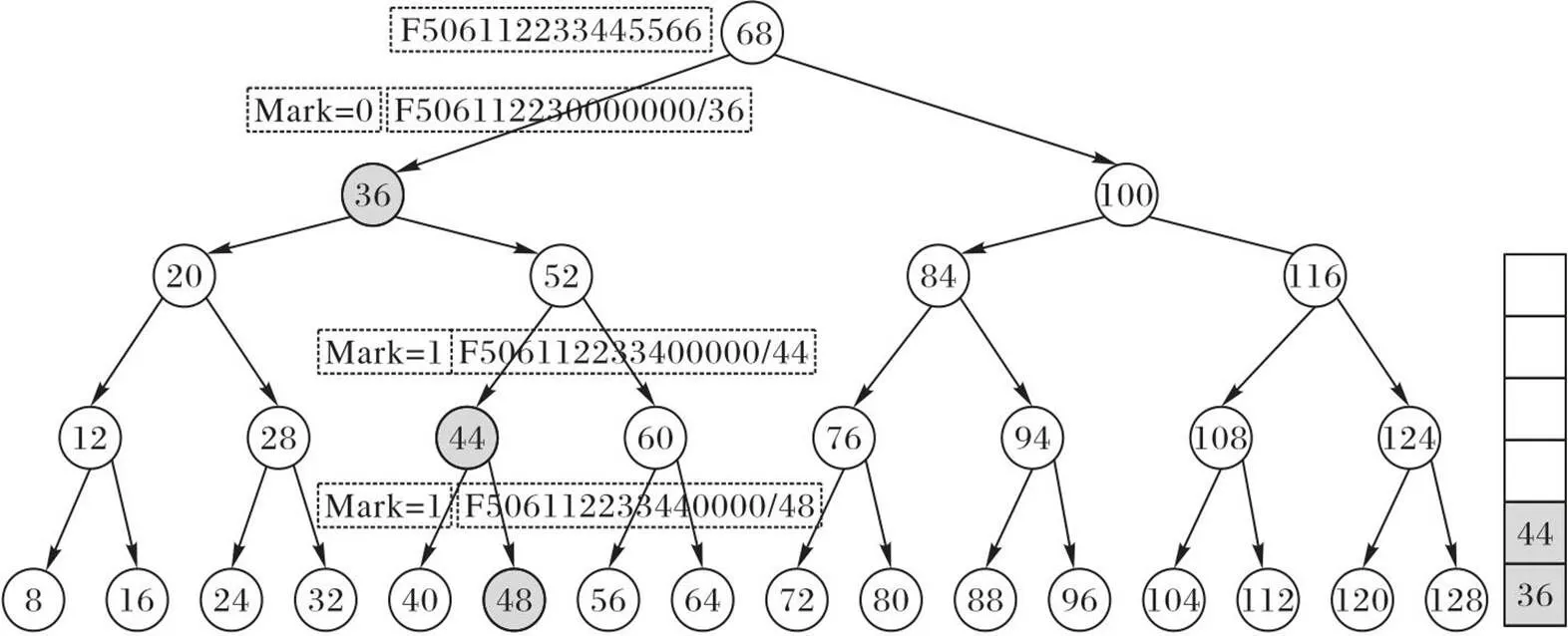
图2 AVL-Bloom 的查找过程
AVL-Bloom算法的路由查找流程如算法1所示,主要是在树结构中验证是否存在待查找路由前缀并返回相应的下一跳信息。具体描述如下所示:
步骤1 初始化查询栈。AVL-Bloom算法在AVL树中找到第一个路由前缀长度不大于待查询可变长地址长度的树节点,并将它记录(入栈)。
步骤2 遍历查询栈。当查询栈不为空时,将栈中的树节点依次出栈,并利用树节点Bloom过滤器验证待查询的可变长地址,判断是否存在相应的路由前缀。如果经Bloom过滤器验证存在相应的路由前缀,则访问相应的片外哈希表,再次检查前缀是否存在,避免由于过滤器的假阳性对查询造成影响,如果片外哈希表存在相应路由条目,则获取相应的下一跳信息;如果Bloom过滤器验证不存在,则说明最佳前缀长度小于当前节点,将左子节点入栈,继续查找。
步骤3 获取最优前缀。在获取下一跳信息后对其中的Mark位进行验证,查看该路由条目是否为最佳前缀,即路由前缀长度最长的条目。如果是,则返回该前缀值,结束查询;如果否,则将当前节点的右子节点入栈(Mark=0,说明存在更长的最优前缀),继续遍历查询栈查找最优路由前缀条目。
至此获取最优的下一跳转发信息。
算法1 AVL-Bloom路由查询。
输入 目标地址, AVL树的根节点;
输出 目标地址的下一跳。
1) 初始化查询栈,获取的长度
2) while!= null do
3)←.pop()
4) if.>then
5) while..>do
6)←.
7) end while
8) if.!= null then
9)←.push(.)
10) end if
11) continue
12) end if
13)← get.bits of
14)← Hash()
15) if.BF() and.HashFind() then
16)←.HashGet()
17)←.
18) if.== 1 then
19) return
20) else
21)←.push(.)
22) end if
23) else
24)←.push(.)
25) end if
26) end while
27) return
2.3 AVL-Bloom更新
AVL-Bloom算法的更新包含路由条目的添加和删除,根据路由生成算法得到的结果或者用户配置策略依次对AVL树进行动态更新,使得路由能够适应网络的拓扑变化。
2.3.1添加
AVL-Bloom算法的添加过程是通过在平衡二叉树上找到相应的树节点,并将路由条目添加到哈希表中和更新Bloom过滤器,同时将路由条目的子路由添加到查询路径上存储路由前缀长度小于该路由长度的所有树节点上。以在AVL中添加一条F506112233445566/64的路由前缀为例,它的过程如图3所示。
AVL-Bloom算法的路由添加流程如算法2所示,主要是根据待插入路由条目前缀长度在树结构中找到合适的树节点并添加至相应数据结构。具体描述如下所示:
步骤1 初始化修改栈。通过遍历平衡二叉树查询当前查找树节点前缀长度等于待插入路由前缀长度的节点,并将在遍历过程中树节点前缀长度小于待插入路由前缀长度的节点记录(入栈)。
步骤2 遍历修改栈。将修改栈中的树节点依次出栈,并将待插入路由前缀条目修剪至与当前节点前缀长度相同,再添加到当前节点的哈希表中,同时更新Bloom过滤器。
步骤3 修改下一跳信息。当路由前缀添加至哈希表时,如果检测到该路由前缀已经存在于哈希表中,则将最优前缀的Mark置为0,否则置为1,同时修改Count计数字段,以便在删除时用于判断是否需要删除该路由前缀。
至此完成路由前缀条目的更新插入。
算法2 AVL-Bloom路由添加。
输入 待插入路由条目, AVL树的根节点;
输出 None。
1) 初始化修改栈
2) while.!=.do
3) if.≤.then
4)←.push()
5) end if
6) if.>.then
7)←.
8) else
9)←.
10) end if
11) end while
12) while!= null do
13)← get.bits of
14)← Hash()
15)←.pop()
16)←.HashGet()
17) if!= null then
18).← 0
19) else
20).← 1
21).BloomFilterAdd()
22) end if
23).←.+ 1
24).HashAdd(,)
25) end while
2.3.2删除
AVL-Bloom算法的删除与添加基本相同,主要差异是找到相应树节点后从中删除目标路由前缀条目,并更新相应的数据结构。由于AVL-Bloom算法存在一个子路由条目被多个共用的问题,为了避免删除对其他路由条目造成影响,在插入子条目时通过引入计数器Count统计当前子路由条目被共用的情况。删除时,只有当Count值为0时再删除该路由条目。如图4所示,以在AVL树中删除路由前缀为F506112233445566/48的路由条目为例。
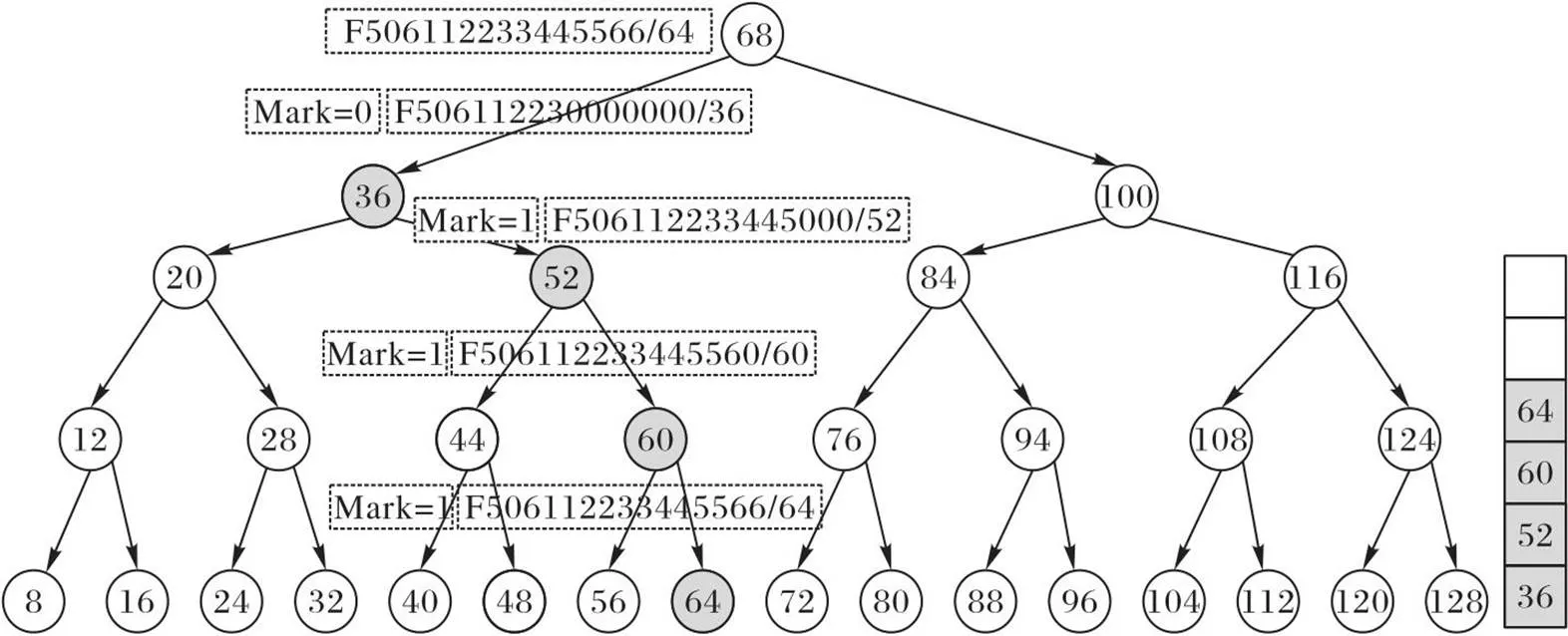
图3 AVL-Bloom 的添加过程
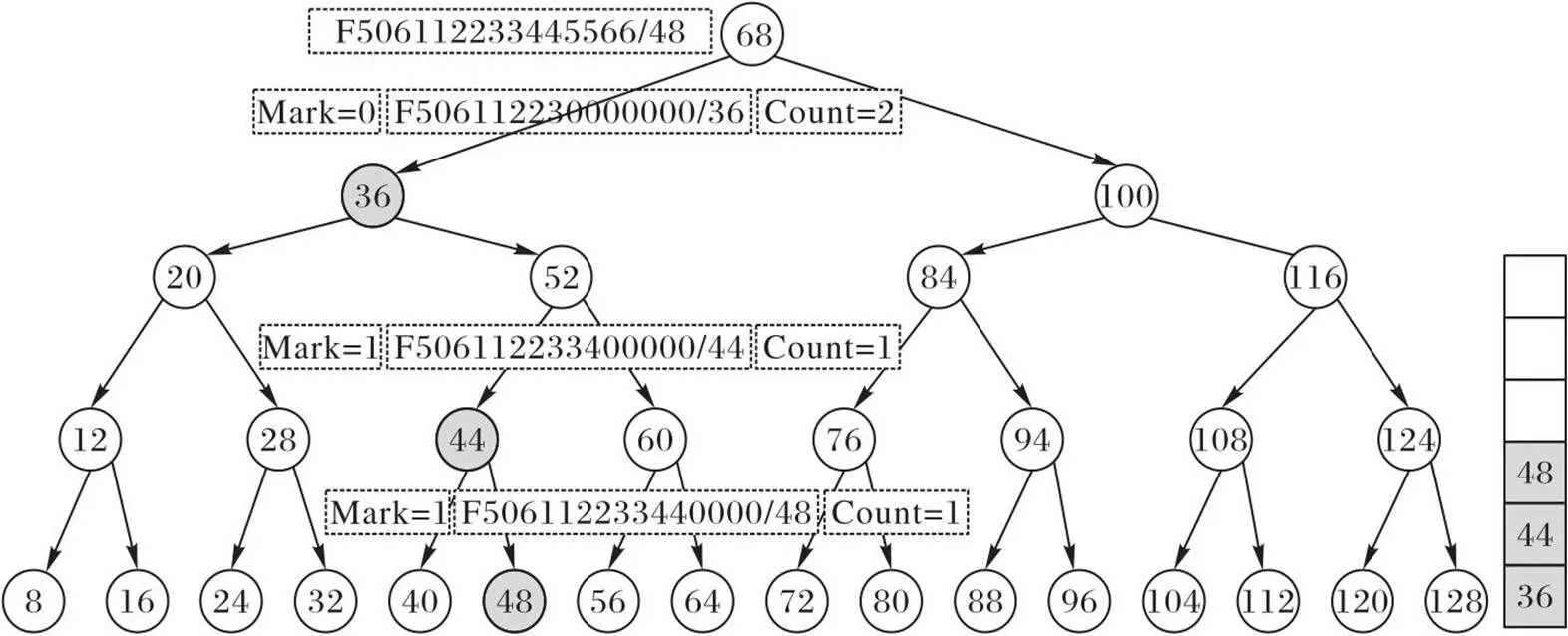
图4 AVL-Bloom 的删除过程
AVL-Bloom算法的路由删除流程如算法3所示,主要是从树结构中找到目标树节点并删除相应的路由前缀条目。具体描述如下所示:
步骤1 初始化删除栈。在AVL树中查找树节点前缀长度等于目标路由前缀长度的节点,并记录遍历过程中树节点前缀长度小于待删除路由前缀长度的节点记录(入栈)。
步骤2 遍历删除栈。将删除栈中的树节点依次出栈,同时将该前缀修剪至与当前节点前缀长度相同,并通过该树节点的Bloom过滤器验证。如果存在,则寻找哈希表中相应的路由条目,将它的计数器Count减1。当Count变为0时,则删除该子路由条目,并完成Bloom过滤器的更新。
至此完成目标路由前缀条目的删除。
算法3 AVL-Bloom路由删除。
输入 待删除路由条目, AVL树的根节点;
输出 None。
1) 初始化修改栈
2) while.!=.do
3) if.≤.then
4)←.push()
5) end if
6) if.>.then
7)←.
8) else
9)←.
10) end if
11) end while
12) while!= null do
13)←.pop()
14)← get.bits of
15)← Hash()
16) if.BF() and.HashFind() then
17)←.HashGet()
18).←.- 1
19) if.≤ 0 then
20).BloomFilterDel()
21).HashDel()
22) end if
23) end if
24) end while
2.4 AVL-Bloom 性能分析
AVL-Bloom算法的本质是基于哈希的路由查找算法,因此减少哈希计算次数和片外哈希表访问次数是提高此类算法查找效率的关键。AVL-Bloom算法通过对片外哈希表存储的路由条目建立Bloom过滤器进行预筛选,由于Bloom过滤器体量较小,可以加载在片内存储器,因而能够有效地减少哈希表的访问次数,提高查找效率(关于引入Bloom过滤器后路由查找的性能分析可参考文献[11-12])。同时,AVL-Bloom算法通过构建平衡二叉树组织不同长度前缀的哈希表和它的Bloom过滤器。路由查找时,可利用平衡二叉树的快速查询特性将哈希计算次数从地址的比特位数级别降低到二叉树的高度级别,从而大幅提升算法的查找性能。
AVL-Bloom树的高度决定了算法的查找效率,假设可变长的地址长度为,在进行路由查找时AVL-Bloom算法通过构建的平衡二叉树优化最长前缀的查询进程,使哈希计算次数由传统朴素哈希查找的减少为log,大幅提高了算法的查找效率。特别是对于可变长地址,地址长度越长,普通的路由查找算法越难适用,而AVL-Bloom路由查找算法则可以有效应对。
同时通过Bloom过滤器进行预筛选,在片上存储器提前判断路由前缀是否存在,避免哈希表的无效访问,减少存于片外存储器中哈希表的访问次数,有助于降低访存开销,进一步提升算法的查找性能。Bloom过滤器主要通过个哈希函数标记位数组中相应位置,然而Bloom过滤器存在假阳性,对于未标记在过滤器中的元素,它的哈希索引对应的位置上因其他元素的插入而被标记为存在时,就会发生假阳性的情况。假阳性发生的概率可近似认为:
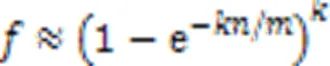
在算法设计时,为了减少因Bloom过滤器误报而造成的访存开销,需要尽可能地使假阳性发生的概率为极小值。一个bloom过滤器由一个长度为b的数组及个哈希函数组成,表示bloom过滤器存储数组的比特位数(长度),为待存储数据集的数据量(数据量的上限)。最优值为:
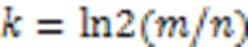
从而取得了最小的假阳性率:
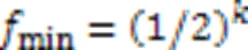
通过合理配置Bloom过滤器数组比特位数和哈希函数的数量,可降低访存开销,使整个查找算法获得较高的查找效率。以一个长度为128 b的可变长地址在图2所示的树形结构中查找路由为例,当前路由表中并不存在适合它的路由前缀。如果采用传统的朴素哈希方法进行查找,则需要从最长的128 b依次递减直到1 b,经过128次哈希计算才能知道路由表中不存在适合该地址的路由前缀。如果采用AVL-Bloom算法,仅需5次哈希计算便可发现路由表中不存在合适的路由前缀。AVL-Bloom算法通过AVL树及其相应的查询标记,将查询哈希计算次数从降至log,同时利用片上Bloom过滤器减少对片外存储器上哈希表的访问次数,大幅提高了路由算法的查找效率。
3 实验与结果分析
为了验证AVL-Bloom算法路由查找的有效性和正确性,在多组数据集下与METrie[10]和COBF[11-12]路由查找算法进行对比实验。实验在一台配置Intel Core i7-11700 CPU@3.20 GHz、缓存为64 KB L1、256 KB L2、12 MB L3以及8 GB 运行内存的计算机上开展,安装的操作系统为Ubuntu 16.04 64 b。
本文实验中,各种路由查找算法的性能对比通过比较平均查询时间和内存消耗情况展开。本文设置了3组不同的路由表作为仿真实验的数据集,测试数据符合UIP协议[1]的可变长地址编码规范。UIP协议的可变长地址主要分为四大类,地址长度由1 B跨越到255 B,且每类地址的长度都灵活可变,因此在进行路由查找性能测试时,数据集的路由条目分布情况需要考虑各类地址应用场景以及每类地址的数量比例。由于UIP协议仍然处于研究阶段,目前还没有真正的路由数据,因此每组数据分别符合UIP地址分布规律随机生成,数据量从10 000到100 000条路由条目组成。为了进行比较分析,数据集1的路由条目在符合地址分布规律的基础上主要偏向超长地址(最大长度为2 048 b)的路由条目;数据集2的路由条目主要侧重于中长地址(最大长度为1 024 b);同理,数据集3的路由条目主要集中于长地址(最大长度为512 b)。各个数据集路由前缀长度动态地变化更有利于检验算法是否适用于可变长地址的路由查找。
图5显示了METrie、COBF和AVL-Bloom这3种不同路由查找算法在3个不同数据集上路由查询时间的变化情况。从图5可见,AVL-Bloom算法具有较好的查询效率,它的查询时间显著低于COBF和METrie。在综合不同数据集的情况下,AVL-Bloom算法的路由查询时间相较于METrie算法和COBF算法减少了近83%和64%。随着每个数据集路由条目数的增加,3种路由查找算法的查询时间也明显增加。METrie和COBF的路由查询时间几乎呈线性增长趋势,而AVL-Bloom算法的查询时间受影响较小。这是由于AVL-Bloom算法采用了AVL树推进路由查找时所需进行哈希计算地址位数,使得整个算法在进行路由查找时哈希计算次数稳定在log级别。对比图5(a)~(c)中每个算法的曲线变化情况可以发现,METrie在3个不同数据集上的曲线抖动较明显,而COBF和AVL-Bloom算法的曲线则较平稳。这是由于3种算法所采用核心数据结构不同,METrie核心的Trie树结构不能很好地适应可变长地址灵活可变长、长短地址分布不均匀等特点;COBF和AVL-Bloom算法是基于哈希设计的路由查找算法,通过哈希可以将地址长度分布不均匀、长度差距较大的地址分类存储不同的哈希表中,极大缩短了路由查找所需的时间开销,显著提高了整个算法的查找效率。
更进一步,对比3个不同数据集下不同算法的内存开销情况,结果如图6所示。从图6可见,各种路由算法的内存开销情况随着数据集路由条目数的增加而增加,且基于哈希技术实现的路由查找算法内存开销远大于基于Trie树的算法。由于METrie算法在实现时,每个子树采用Radix Tree实现,通过压缩路径的方式节省了大量的节点开销;但是,这也给路由查找效率带来了一定的影响,需遍历节点的所有元素,查询效率不高。值得注意地,由于基于哈希的路由查找算法需要通过哈希表存储每一条路由前缀,而基于Trie树的算法则通过相同前缀合并路由条目,因此随着数据集路由条目数的增加,基于哈希路由查找算法的内存开销几乎是线性增长,而基于Trie的路由查找算法由于合并相同路由前缀,使得内存开销增长趋势并不明显。

图5 不同算法的查询时间比较

图6 不同算法的内存开销比较
由于AVL-Bloom算法和COBF都基于哈希表技术实现,因此哈希计算次数成为了影响这两个算法路由查找效率的关键因素。为了探究基于哈希路由查找性能差异产生的原因,本文继续测试了COBF和AVL-Bloom算法在不同数据集下的哈希计算总次数。图7显示了这两种算法的哈希计算总次数的实验结果。从图7可见,COBF在不同数据集下的哈希计算次数远高于AVL-Bloom算法。由于AVL-Bloom算法引入了平衡二叉树,使得它在进行最长路由前缀查找时不需要从地址最长前缀长度的比特位数依次减少进行哈希计算,从而减少了哈希计算次数,使算法总体查找效率提高较明显。
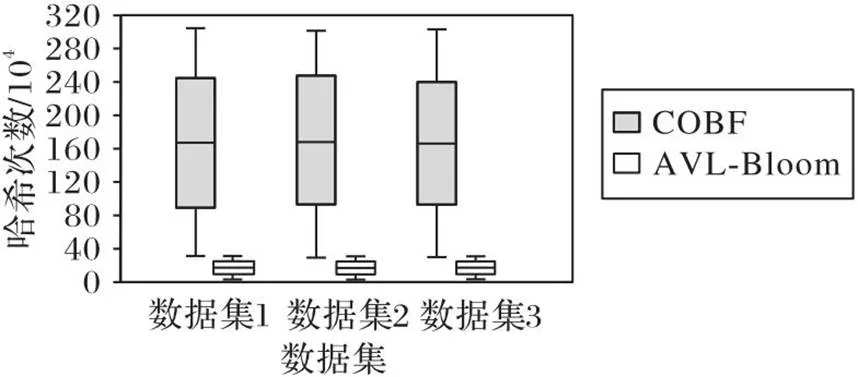
图7 COBF算法和AVL-Bloom算法的哈希计算次数比较
4 结语
可变长地址结构是未来网络发展的一种趋势,是根据未来多态异构网络互联场景需求而提出的新型网络地址格式。本文针对这种可变长地址提出了一种路由查找算法AVL-Bloom算法,实现地址长度可变情况下的高效路由查找。实验结果表明,相较于其他路由查找算法,AVL-Bloom算法可以实现更高的查询效率,能够满足未来网络海量数据通信下全新业务的高效路由需求。在接下来的工作中,将进一步研究未来网络发展趋势和需求,结合可变长地址结构的特点,不断地改进和创新AVL-Bloom路由查找算法,探索它在不同网络环境下的适用性。
[1] 周旭,蒋胜,张杰,等. 泛在IP协议体系[J]. 电信科学, 2021, 37(10):47-54.(ZHOU X, JIANG S, ZHANG J, et al. Ubiquitous IP protocol system[J]. Telecommunications Science,2021,37(10):47-54.)
[2] TANG J, ZHANG W, GONG X, et al. A flexible hierarchical network architecture with variable-length IP address[C]// Proceedings of the IEEE INFOCOM 2020 — IEEE Conference on Computer Communications Workshops. Piscataway: IEEE, 2020:267-272.
[3] 郑秀丽,蒋胜,王闯. NewIP:开拓未来数据网络的新连接和新能力[J].电信科学,2019,35(9):2-11.(ZHENG X L, JIANG S, WANG C. NewIP: new connectivity and capabilities of upgrading future data network[J]. Telecommunications Science, 2019,35(9): 2-11.)
[4] CHEN Z, WANG C, LI G, et al. New IP framework and protocol for future applications [C]// Proceedings of the NOMS 2020-2020 IEEE/IFIP Network Operations and Management Symposium. Piscataway: IEEE, 2020: 1-5.
[5] ASAI H, OHARA Y. Poptrie: a compressed trie with population count for fast and scalable software IP routing table lookup [C]// Proceedings of the 2015 ACM Conference on Special Interest Group on Data Communication. New York: ACM, 2015:57-70.
[6] YANG T, XIE G, LI Y, et al. Guarantee IP lookup performance with FIB explosion [C]// Proceedings of the 2014 ACM Conference on SIGCOMM. New York: ACM , 2014:39-50.
[7] HUANG J-Y, WANG P-C. TCAM-based IP address lookup using longest suffix split[J]. IEEE/ACM Transactions on Networking, 2018, 26(2): 976-989.
[8] SUN Y, LIU H, KIM M S. Using TCAM efficiently for IP route lookup[C]// Proceedings of the 2011 IEEE Consumer Communications and Networking Conference. Piscataway: IEEE, 2011: 816-817.
[9] LE H, PRASANNA V K. Scalable high throughput and power efficient IP lookup on FPGA[C]// Proceedings of the 2009 17th IEEE Symposium on Field Programmable Custom Computing Machines. Piscataway: IEEE, 2009:167-174.
[10] REN S, YU D, LI G, et al. Routing and addressing with length variable IP address [C]// Proceedings of the ACM SIGCOMM 2019 Workshop on Networking for Emerging Applications and Technologies. New York: ACM, 2019:43-48.
[11] LIU S, LUO W, ZHOU X, et al. OBF: a guaranteed IP lookup performance scheme for flexible IP using one bloom filter [C]// Proceedings of 2021 IEEE 29th International Conference on Network Protocols. Piscataway: IEEE, 2021:1-6.
[12] LIU S, LUO W, ZHOU X, et al. An efficient addressing scheme for flexible IP address[C]// Proceedings of the 2021 2nd International Conference on Control, Robotics and Intelligent System. New York: ACM, 2021:111-116.
[13] SO W, NARAYANAN A, ORAN D, et al. Toward fast NDN software forwarding lookup engine based on hash tables[C]// Proceedings of 8th ACM/IEEE Symposium on Architectures for Networking and Communications Systems. New York: ACM, 2012:85-86.
[14] WALDVOGEL M, VARGHESE G, TURNER J, et al. Scalable high speed IP routing lookups[C]// Proceedings of the ACM SIGCOMM’97 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communication. New York: ACM, 1997:25-36.
[15] ZHANG C, XIE G. Using XorOffsetTrie for high-performance IPv6 lookup in the backbone network[J]. Computer Communications, 2022, 181: 438-445.
[16] SHI S, QIAN C. Ludo hashing: compact, fast, and dynamic key-value lookups for practical network systems[J]. ACM SIGMETRICS Performance Evaluation Review, 2020, 48(1):57-58.
[17] SRINIVASAN V, VARGHESE G. Faster IP lookups using controlled prefix expansion [J]. ACM SIGMETRICS Performance Evaluation Review, 1998, 26(1):1-10.
Routing lookup algorithm with variable-length address based on AVL tree and Bloom filter
HUANG Yongjin1,2, QIN Yifang1*, ZHOU Xu1, ZHANG Xinqing1,2
(1,,100083,;2,100049,)
The variable-length address is one of the important research content in the field of future network. Aiming at the low efficiency of traditional routing lookup algorithms for variable-length address, an efficient routing lookup algorithm suitable for variable-length addresses based on balanced binary tree — AVL (Adelson-Velskii and Landis) tree and Bloom filter, namely AVL-Bloom algorithm, was proposed. Firstly, multiple off-chip hash tables were used to separately store route entries with the same number of prefix bits and their next-hop information in view of the flexible and unbounded characteristics of the variable-length address. Meanwhile, the on-chip Bloom filter was utilized for speeding up the search for route prefixes that were likely to match. Secondly, in order to solve the problem that the routing lookup algorithms based on hash technology need multiple hash comparisons when searching for the route with the longest prefix, the AVL tree technology was introduced, that was, the Bloom filter and hash table of each group of route prefix set were organized through AVL tree, so as to optimize the query order of route prefix length and reduce the number of hash calculations and then decrease the search time. Finally, comparative experiments of the proposed algorithm with the traditional routing lookup algorithms such as METrie (Multi-Entrance-Trie) and COBF (Controlled prefix and One-hashing Bloom Filter) were conducted on three different variable-length address datasets. Experimental results show that the search speed of AVL-Bloom algorithm is significantly faster than those of METrie and COBF algorithms, and the query time is reduced by nearly 83% and 64% respectively. At the same time, AVL-Bloom algorithm can maintain stable search performance under the condition of large change in routing table entries, and is suitable for routing lookup and forwarding with variable-length addresses.
variable-length address; routing lookup; Adelson-Velskii and Landis (AVL) tree; Bloom filter; hash algorithm
This work is partially supported by Project of Beijing Municipal Science and Technology Plan (Z191100007519007), Fund of Youth Innovation Promotion Association of Chinese Academy of Sciences (2020175).
HUANG Yongjin, born in 1996, M. S. candidate. His research interests include future network system.
QIN Yifang, born in 1984, Ph. D., senior engineer. His research interests include future network architecture, 5G mobile communication.
ZHOU Xu, born in 1976, Ph. D., research fellow. His research interests include future network architecture, new generation wireless network.
ZHANG Xinqing, born in 1999, M. S. candidate. Her research interests include future network system.
TP393.05
A
1001-9081(2023)12-3882-08
10.11772/j.issn.1001-9081.2022121915
2023⁃01⁃04;
2023⁃03⁃08;
2023⁃03⁃09。
北京市科技计划项目(Z191100007519007);中国科学院青年创新促进会基金资助项目(2020175)。
黄永锦(1996—),男,广西南宁人,硕士研究生,主要研究方向:未来网络系统;覃毅芳(1984—),男,广西河池人,高级工程师,博士,主要研究方向:未来网络架构、5G移动通信;周旭(1976—),男,四川成都人,研究员,博士生导师,博士,CCF会员,主要研究方向:未来网络架构、新一代无线网络;张心晴(1999—),女,山西阳泉人,硕士研究生,主要研究方向:未来网络系统。
猜你喜欢
电脑报(2022年37期)2022-09-28 05:31:07
现代计算机(2021年14期)2021-07-09 17:19:40
电子测试(2018年9期)2018-06-26 06:45:56
趣味(语文)(2018年2期)2018-05-26 09:17:55
武汉轻工大学学报(2016年4期)2017-01-16 08:53:03
工业设计(2016年8期)2016-04-16 02:43:34
计算机工程(2015年8期)2015-07-03 12:20:04
自动化博览(2014年6期)2014-02-28 22:32:20
计算机工程(2014年6期)2014-02-28 01:25:40
中国氯碱(2014年11期)2014-02-28 01:05:07
