
基于马尔可夫优化的高效用项集挖掘算法
2024-01-09 04:01:18钟新成刘昶赵秀梅
计算机应用 2023年12期
钟新成,刘昶,赵秀梅
基于马尔可夫优化的高效用项集挖掘算法
钟新成1,2*,刘昶2,赵秀梅1
(1.长治学院 计算机系,山西 长治 046000; 2.中国科学院 沈阳自动化研究所,沈阳 110169)(∗通信作者电子邮箱cy12016596@czc.edu.cn)
基于树型和链表结构的高效用项集挖掘(HUIM)算法通常需要指数量级的搜索空间,而基于进化类型的挖掘算法未能充分考虑变量间的相互作用,因此提出一种基于马尔可夫优化的HUIM算法(HUIM-MOA)。首先,采用位图矩阵表示数据库和使用期望向量编码,以实现对数据库的快速扫描和效用值的高效计算;其次,通过计算优势个体间的互信息估计马尔可夫网络(MN)结构,并根据它们的局部特性使用吉布斯采样以产生新的种群;最后,为防止算法过快陷入局部最优和减少高效用项集的缺失,分别采用种群多样性保持策略和精英策略。在真实数据集上的实验结果表明,相较于次优的基于粒子群优化(PSO)的生物启发式HUI框架(Bio-HUIF-PSO)算法,在给定较大最小阈值的情况下,HUIM-MOA可以找到全部的高效用项集(HUI),收敛速度平均提升12.5%,挖掘HUI数平均提高2.85个百分点,运行时间平均减少14.6%。HUIM-MOA较进化型HUIM算法有更强的搜索性能,能有效减少搜索时间和提高搜索质量。
高效用项集挖掘;马尔可夫网络;位图矩阵;吉布斯采样;精英策略
0 引言
数据挖掘旨在从数据库提取有用的模式或训练模型,以理解过去或预测未来。频繁项集挖掘(Frequent Itemset Mining, FIM)是一项被研究广泛的数据挖掘任务,且应用于许多领域。它可以被视为分析数据库的一般任务,以查找一组事务数据库中同时出现的项[1]。尽管频繁模式挖掘有用,但假设它依赖频繁模式虽有趣却并不适用于许多应用程序。比如,在事务数据库中,模式{牛奶,面包}可能是频繁的,但该模式是无趣的,因为该模式在日常生活中常见且不会带来太多的利润。另一方面,模式{茅台,鱼子酱}可能是非频繁的,但它有着丰厚的利润。因此,为了在数据库中找到更多有趣的模式,可以考虑其他方面的因素,如利润或效用。若项集在数据库中的效用不小于用户指定的最小效用阈值,则称该项集为高效用项集(High Utility Itemset, HUI)。高效用项集挖掘(High Utility Itemset Mining, HUIM)在现实生活中应用广泛,如在购物超市中挖掘高利润商品组合模式、在电商平台产生的数据流中挖掘购物者的高消费模式和在移动通信数据中挖掘高消费客户群体的消费规律等。
HUIM算法大致可分为精确算法和进化算法(Evolutionary Algorithm, EA)两种类型[2]。前者致力于找到所有的HUI,但同时承受指数量级的搜索空间,随着问题规模增大,此类算法的运行时间变得不可接受;后者致力于快速找到大部分的HUI,但不能保证找到所有的HUI。日常生活中,找到所有HUI并非必要,若能在较短的时间内找到大部分HUI,对指导商家作出决策也非常有意义。
已有学者提出了几种EA实现HUIM。Kannimuthu等[3]等提出一种基于遗传算法(Genetic Algorithm,GA)的HUIM算法,首次使用EA研究HUIM;但是它没有考虑HUI是挖掘更多满足最小效用阈值的项集而非简单地寻找最优的HUI,所以在一些数据集上的挖掘效果不理想。Zhang等[4]改进了基于GA的高效用算法,提出了基于个体改善、邻域探索和种群多样性保持等策略的挖掘算法,实验结果表明在这些策略的综合作用下,在不同数据集上的各项指标都有较大改善。Lin等[5-6]提出一种基于粒子群优化(Particle Swarm Optimization, PSO)的HUIM算法,该算法提出粒子编码长度由高事务加权效用1项集决定,在此种编码下能有效地缩小搜索空间并提高搜索效率。Song等[7-8]和Wu等[9]提出基于人工鱼群[7]、人工蜂群[8]和蚁群[9]的HUIM算法,这些算法都模拟群体智能以进化种群,挖掘质量各有所长。Pazhaniraja等[10]提出一种基于布尔代数的灰狼算法挖掘HUI,在运行时间、收敛速度和挖掘数量上都有较好表现。Song等[11]提出了基于生物进化启发的HUIM框架,包含GA、PSO算法和蝙蝠算法,这些算法采用通用框架,只在具体编码和操作上略有差异,其中位图表示、位图操作和非期望向量剪枝策略都提高了遍历解空间的速度,并且在各数据集上都有良好的表现,基于该框架的算法大幅提高了挖掘效率。然而,基于EA的HUIM算法挖掘所有满足最小效用阈值的HUI仍然耗时较长:一方面EA通常沿着上一代最优值的方向搜索,这可能使某些HUI在迭代过程中被遗漏;另一方面,基于EA的HUIM算法相较于搜索新的HUI通常效率较低。
马尔可夫优化算法(Markovian Optimization Algorithm,MOA)[12]是分布估计算法(Estimation of Distribution Algorithm, EDA)[13]的一个分支。该类算法是一种基于概率论的优化算法,主要思想是分析优势群体的分布模型,并用它影响新一代群体的分布,可以更有效地处理非线性、高维复杂问题[14]。此外,EDA还有其他EA不具备的优势,如自适应算子、问题结构和先验知识的利用等[15]。
目前,较少有学者将MOA应用于HUI的相关挖掘工作。为提高挖掘效率,本文提出一种基于马尔可夫优化的HUIM算法(HUIM Algorithm based on Markovian Optimization, HUIM-MOA),主要特点有:1)使用位图表示、位图操作和非期望编码检验策略加速HUI的挖掘;2)通过计算变量间的互信息估计马尔可夫网络(Markov Network, MN)结构并构建各变量的条件概率模型[16-17];3)通过吉布斯采样法产生新的个体;4)通过种群多样性保持策略防止算法陷入局部最优,采用精英策略减少HUI的缺失。
1 相关工作
1.1 HUIM
表1事务信息
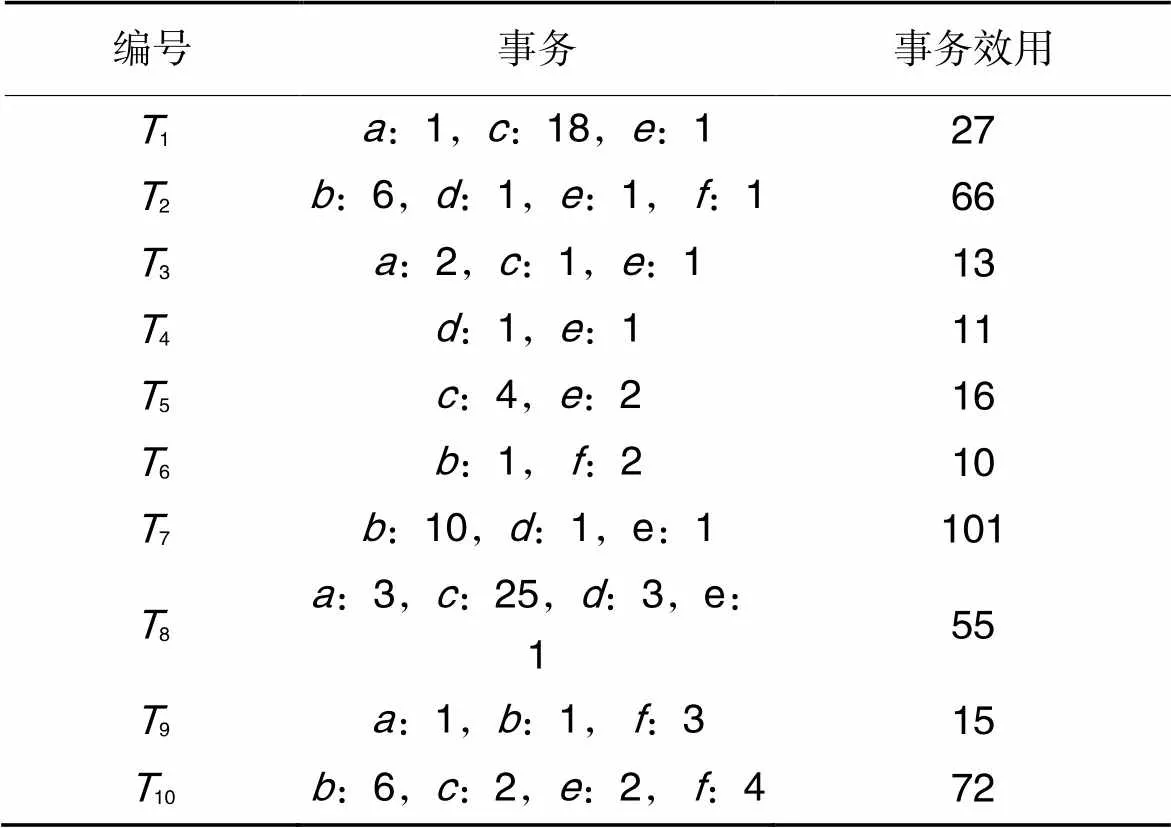
Tab.1 Transaction information
表2外部效用
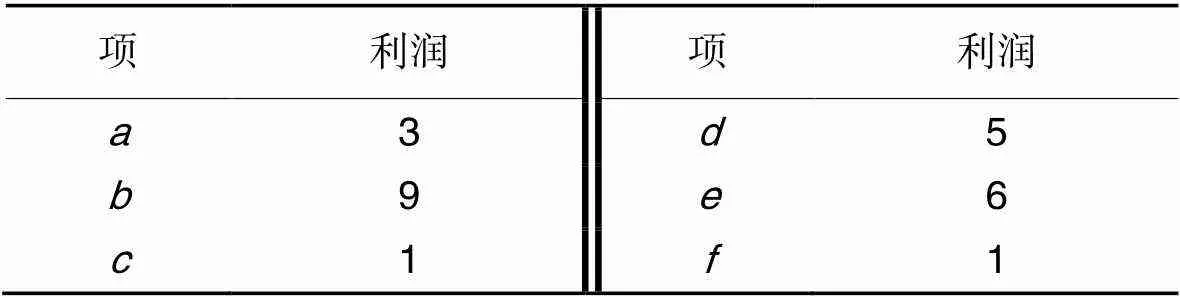
Tab.2 External utility
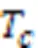
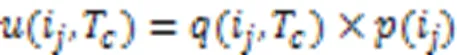
其中:()表示内部效用,()表示外部效用。
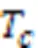
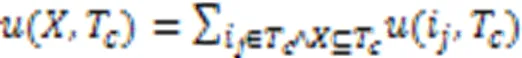
例如:({,},10)=(,10)×()+(,10)×()=2×6+4×1=16。
定义2 项集在数据库中的效用记为(),如式(3)所示,式(3)也作为HUIM的目标函数:
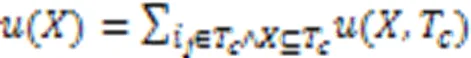
例如:({,,})=({,,},1)+({,,},3)=(,1)+(,1)+(,1)+(,3)+(,3)+(,3)=3+18+6+6+1+6=40。
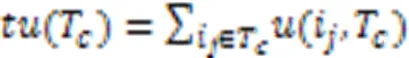
定义4 事务数据库中项集经常出现在多个事务中,将各事务效用进行累加得到的效用称为事务加权效用,记做(),如式(5)所示:
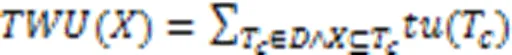
例如:({,})=(1)+(3)+(5)+(8)+(10)=27+13+16+55+72=183。
定义5 根据用户偏好,将最小效用阈值系数设为,如果项集的效用值不小于最小效用值,记为,则称项集是HUI。定义如式(6)所示:
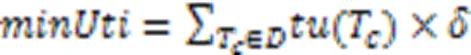
例如:假设=25%,则=(27+66+13+11+16+10+101+55+15+72)×25%=386×25%=96.5。由于({,})=183>96.5,所以{,}是HUI;由于({,,})=60<96.5,所以{,,}不是HUI。
定义6 如果项集满足()>,则称为高事务加权效用项集,记为HTWUI。包含个项目的HTWUI记为-HTWUI。例如:假设=115,则高事务加权效用1项集(1-HTWUI)的挖掘结果如表3所示。
表3高事务加权效用1项集的挖掘结果
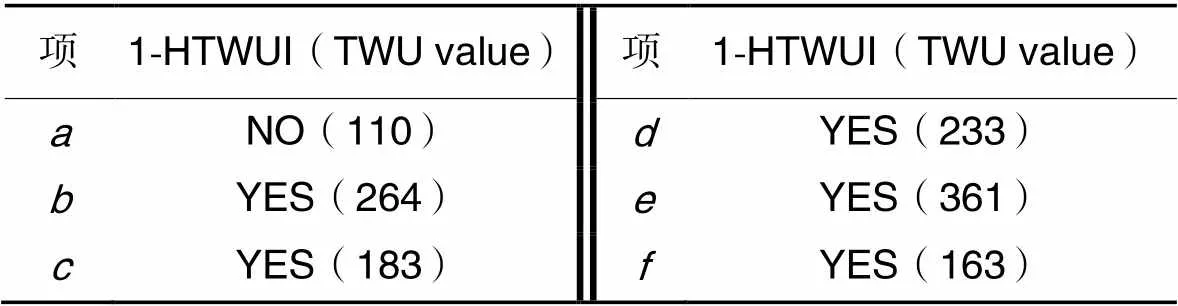
Tab.3 Mining results for 1-HTWUI
注:NO()表示非高事务加权效用1项集,YES()表示是高事务加权效用1项集,()里面的数字是事务加权效用值。
事务加权效用具有3个重要性质,尤其当某1项集为低事务加权效用项集时,可以对搜索空间进行大范围剪枝,从而缩小搜索空间,这也是基于EA的HUIM算法经常采用的一个初始挖掘手段。
性质1 对于某项集总有()>(),表明项集的事务加权效用是对本身效用值的向上估计。
性质3 若()<,则项集和它的超集都是低效用项集。
1.2 MOA
MOA是EDA的一个分支。有别于EA利用群体智能引导种群进化,EDA通过捕捉变量间的相互依赖关系构建概率模型,从而获得先验概率以引导种群进化。局部马尔可夫特性强调了由MN结构编码的条件概率可以直接用于采样,而不需要建立复杂的联合概率分布模型。此外,MOA采用吉布斯抽样法进行采样并包含了温度参数,该参数可以平衡对搜索空间的探索和利用,并允许算法处理由循环表示的相互作用。局部马尔可夫特性被定义为变量之间的邻域关系,如式(7)所示:
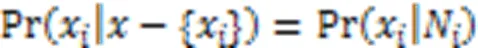
其中N是节点x的相邻节点集。式(7)表明节点x的条件概率可以由它的邻域节点集N定义,N有时也被称为马尔可夫毯。基于马尔可夫特性的EDA工作流程如下所示:
步骤1 随机生成含个解的总体。
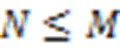
步骤3 用中数据估计MN结构。
步骤5 用新的种群替代旧种群,然后返回步骤2,直到满足终止条件。
从上述流程可以看出,MOA的关键步骤为确定MN结构和根据局部马尔可夫条件概率进行采样。通常可用不同方法确定一个无向图结构,MOA采样一种基于熵的互信息方法确定MN结构,即估计解中每对变量的互信息以创建一个互信息矩阵。若每对变量间的互信息高于某一设定的阈值,则它们可成为相邻节点;另外,为了防止网络结构过于复杂,任一节点的相邻节点数应设置一个上限。两个变量和之间的互信息由式(8)给出:
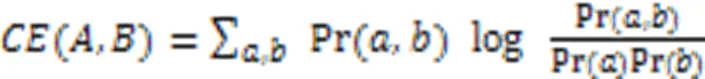
估计网络结构后,再估计每一节点的条件概率,最后根据条件概率采样新的种群。吉布斯抽样法是MOA中的一类蒙特卡洛采样方法,它始于一个随机解和一个固定的迭代次数,然后随机选择解中的某一变量并计算它在MN结构下的条件概率以得到该变量的某一新的取值,接着用轮盘赌的方法采样其他变量的新值,当达到迭代次数时,输出新解。在吉布斯抽样法中,条件概率一般估计为:
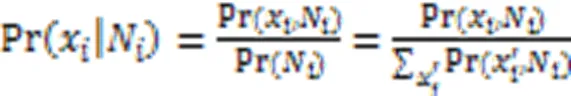
假设变量是二值变量,一般只需计算变量取值为1的概率,因为取0的概率可以根据互斥性给出,式(9)可写为:
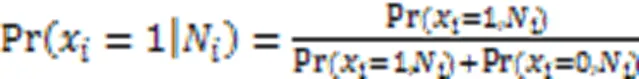
为了实现MOA中基于温度的吉布斯抽样法,式(9)的条件概率可估计为:
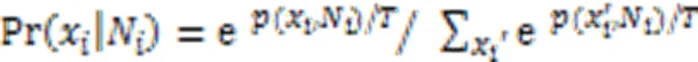
对于二值变量,则x取1的条件概率可由它的相邻节点估计为:
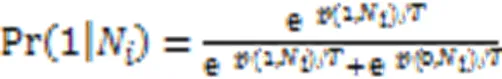
2 本文算法
本文提出的HUIM-MOA依赖于位图数据库表达并涉及以下几个主要步骤:种群初始化、选择优势个体、构建概率模型、吉布斯采样、种群多样性保持策略和精英策略。本章首先介绍两个重要的准备工作:位图表示和期望向量编码。
2.1 位图表示和期望向量编码
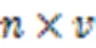
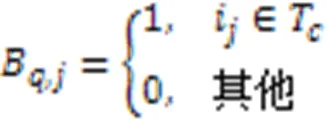
表4展示了表1对应数据库的位图表示。
表4对应事务信息的位图表示
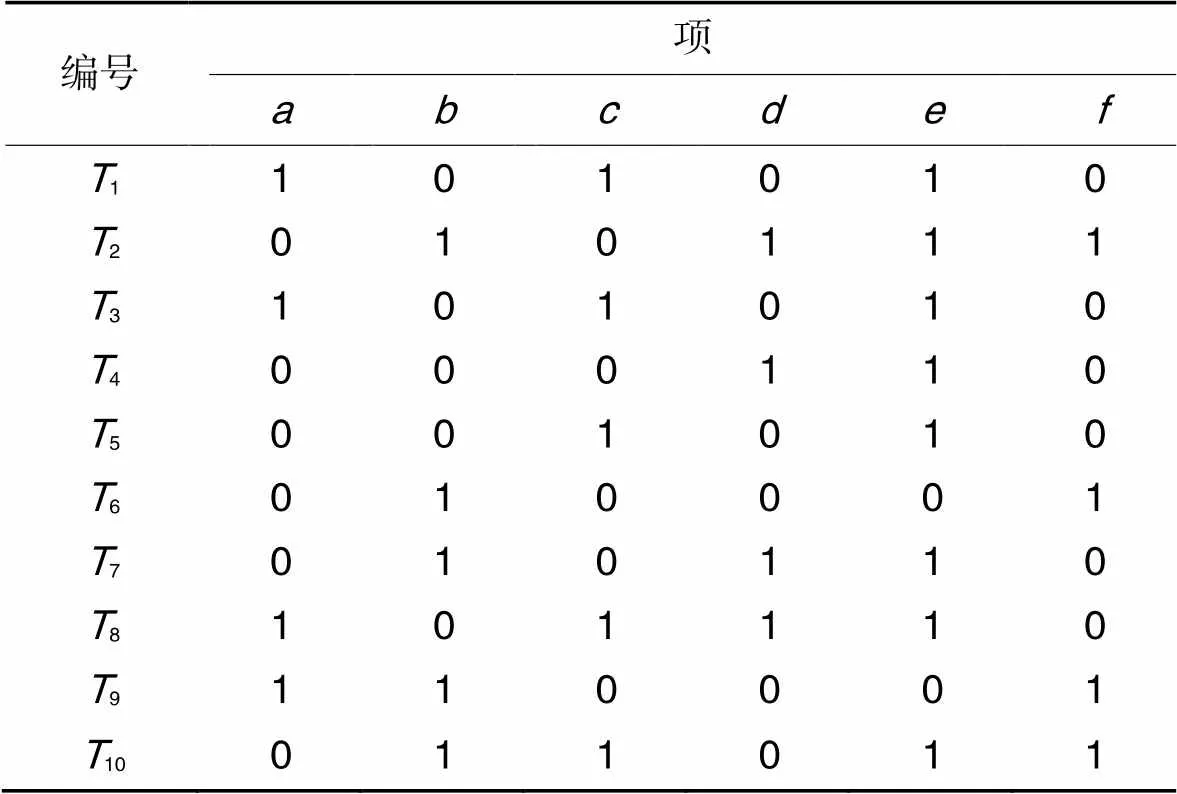
Tab.4 Bitmap representation of corresponding transaction information
定义7 若项集编码向量的位图覆盖全为0,则称该向量为非期望编码向量(UnPromising Encoding Vector, UPEV),反之则称为期望编码向量(Promising Encoding Vector, PEV)。UPEV表示该编码向量对应的项集在数据库中不存在,不可能成为HUI,删除UPEV的过程称为非期望编码向量修剪策略(UPEV Cut strategy, UPEVC)。UPEVC的伪代码如算法1所示。
算法1 PEV_Check()。
输入 编码向量;
输出 期望编码向量。
1)计算中1的位数
3)=(1)
4) for=2 todo
8) 改变中的一位i状态
9) end if
11) end for
12) return
HUIM-MOA中使用了两种策略修剪搜索空间:其一是使用事务加权向下闭包属性删除低效用项集以有效减小搜索空间和提高计算速度[11];其二是使用UPEV修剪事务数据库中不存在的项集。在上述两种策略下,MOA编码的长度完全由1-HTWUI决定。例如,假设=115,则1-HTWUI有{,,,,},相应编码长度为5。每个编码位置对应一个项,编码为1表示该项出现在该位置;编码为0则表示不出现。图1表示项集{,}是一个潜在的解。
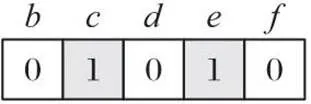
图1 编码示例
在种群初始化阶段,每个个体根据1-HTWUI的TWU初始化,若某1-HTWUI的TWU较高,则它被选中的概率相应也更高。算法2展示了这个初始化过程。在算法2中,每个个体各编码位置初始被指派为0,接着根据每个1-HTWUI的TWU的大小采用轮盘赌的形式确定该位置1出现的概率。每个位置取1的概率由式(14)决定:
若一个个体生成完毕,则加入种群,如此反复,最后返回初始种群。
算法2 Pop_Init()。
输入 数据集,种群规模;
输出 第一代种群。
1)遍历数据集,并删除1‑LTWUI
2)将数据集表示为bitmap
3) for=1 todo
4) 产生随机数num
5) 运用轮盘赌方式产生一个位向量
6) ifnum>1 then
7)=PEV_Check()
8) 改变中的一位i状态
9) end if
10) end for
2.2 构建概率模型
种群初始化后计算相应项集的效用值,若高于设定阈值,则加入HUI,并对该种群按照效用值从高到低进行排序,按设定比例截取前面的优良个体组成新的数据集。接着使用数据集估计MN结构。构建概率模型的伪代码如算法3所示。
算法3 Pro_Model()。
输入 优势个体组成的种群,重要系数,最大相邻节点数;
输出 MN结构。
1)=len([0])
2)0
3) for=1 to,=+1 todo
4) 用式(8)估计变量x和x的互信息m
5) end for
6)计算平均互信息
7) for=1 to,=+1 todo
8) ifm>then
9) 在变量x和x间创建一条边
10) end if
11) end for
12) for=1 todo
13) if NB>then
14) 保留x的互信息排名前个相邻节点
15) end if
16) end for
2.3 吉布斯采样
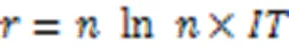
算法4 Gibbs_sample()。
输入 MN结构,种群规模,冷却系数,迭代系数;
输出 新一代种群。
2)=1
4) 随机产生一个解=(1,2,…,x)
6) 从中随机选择一个x
7) 以概率P(1|NB)置x为1;←用式(12)
8) end for
9)=PEV_Check()
11) end while
12) return
2.4 精英策略和种群多样性保持策略
2.5 HUIM-MOA算法总体设计及实例演示
HUIM-MOA的伪代码如算法5所示。步骤1)~4)是算法的初始化,5)~21)是整个算法的迭代过程,其中6)~12)是筛选HUI的过程,13)是按效用值由高到低进行排序,14)是按设定比例选择优势个体,15)是构建概率模型,16)是执行吉布斯采样,17)~18)是执行精英策略和种群多样性保持策略。
算法5 HUIM-MOA。
输入 事务数据集,最小效用阈值;
输出 所有的高效用项集。
1) Pop_Init()
2)=1
5) while≤_do
6) for each individualdo
7) 确定与位图向量对应的项集
11) end if
12) end for
13)按的第一元素进行排序
14)按比例截取的第二元素组成新种群
15) Pro_Model()
16) Gibbs_Sample()
17)执行精英策略
18)执行多样性保持策略
19)++
20) end while
21) return
根据前述数据库、效用表和位图举例。假设=115,被挖掘的1-HTWUI如表3所示,则个体编码长度为5,表5展示了种群初始化所得的10个个体,经过HUI筛选后,将项集:166,:216,:131分别加入高效用项集。接着按效用值排序并按1∶2选取优势个体,得到新的位图如表6所示。
表5初始种群
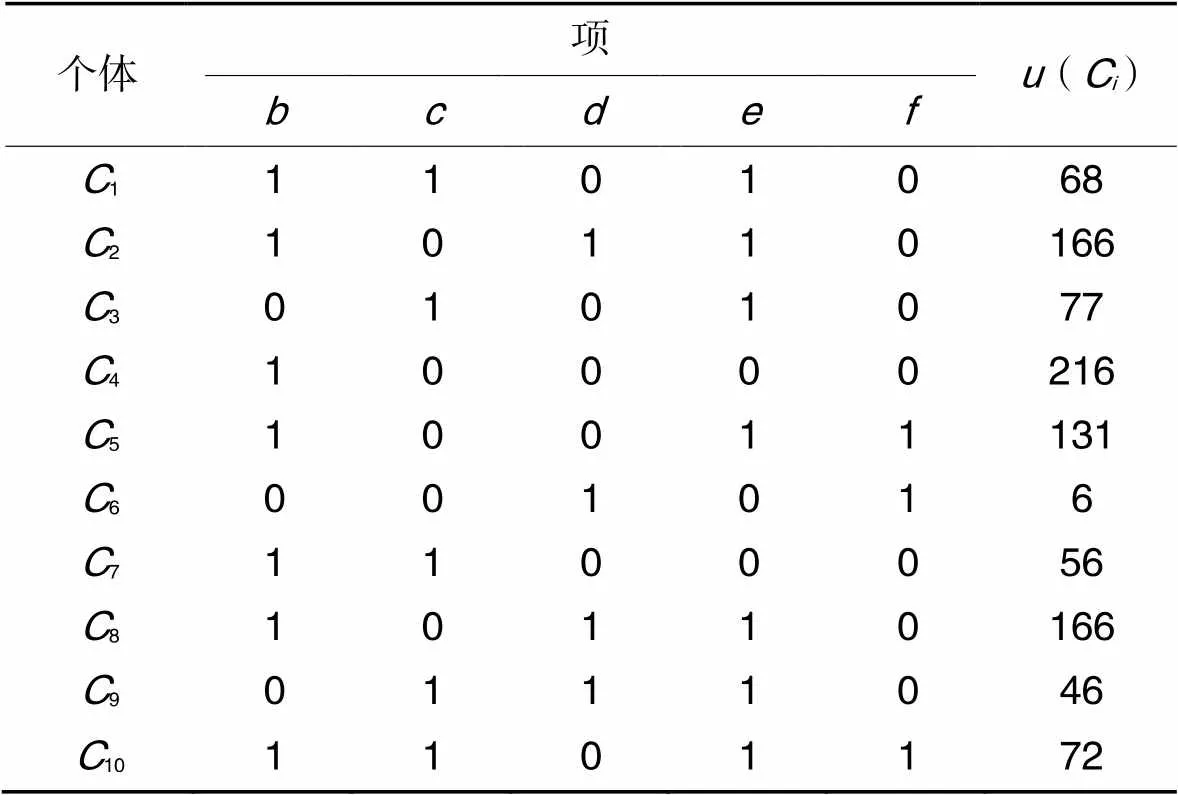
Tab.5 Initial population
表6截断后优势个体组成的种群
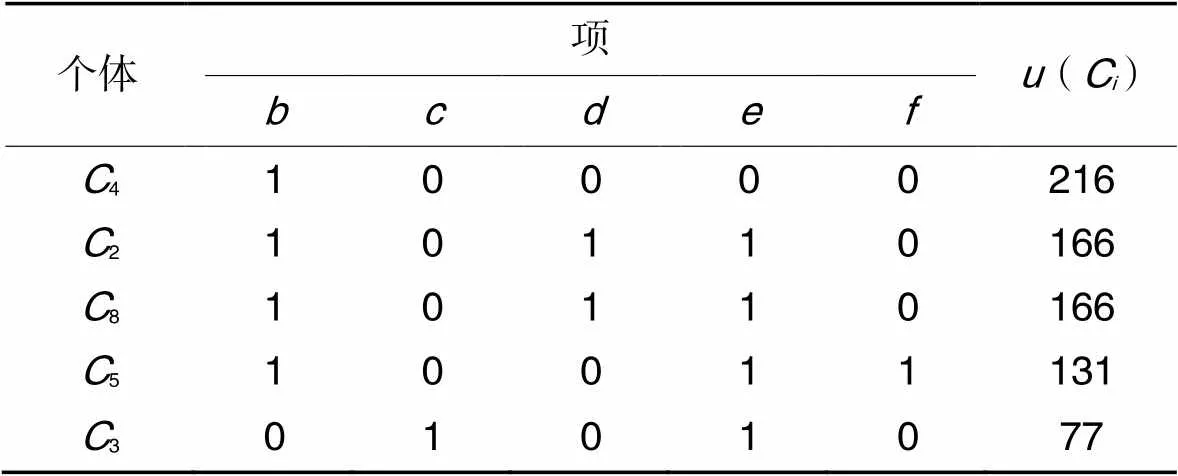
Tab.6 Population composed of dominant individuals after truncation
首先,计算各变量两两间的互信息。设定=1.2,经计算平均互信息为0.117 8,其中有、、、、间互信息大于平均互信息,分别为0.5、0.118 5、0.118 5、0.118 5、0.118 5,故这些变量之间可以分别连一边,于是可以估计MN结构如图2所示。
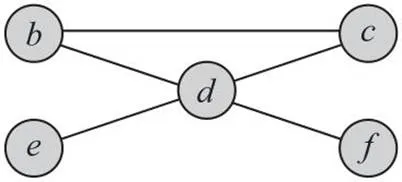
图2 MN结构
其次进行吉布斯采样。该采样从一个随机解=(1,0,1,0,1)开始,随机选定一维变量4==0;接着用变量的条件概率采样新的,此时的邻边集为{},且此时=1。设定=4,于是在=1的情况下取1的概率计算为:
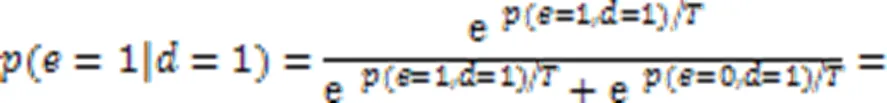
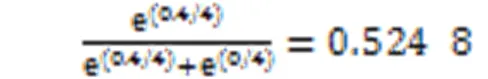
由式(15)计算结果可知,此时以0.524 8的概率取1。令的新值为1,新的个体变为=(1,0,1,1,1),再随机取一维变量2==0,的邻边集为{,},且此时=1,=1。于是在此情况下取1的概率可计算为:
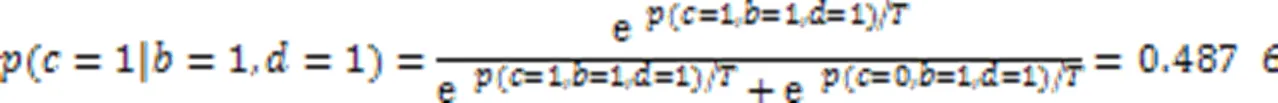
令的新值取0,新的个体变量为=(1,0,1,1,1),依此继续采样,直到迭代完毕获得一个新个体。假设最终新个体是=(1,0,1,1,1),经PEVC检测后存在,则不用修改;若不存在,则作相应修改。如此下去,便得到了新的种群。
最后,执行精英策略和种群多样性保持策略,这里不再赘述。
3 实验与结果分析
将HUIM-MOA和目前最先进的基于EA的HUIM算法进行实验对比以综合评估算法性能。这些算法包括基于PSO的生物启发式HUI框架(Bio-inspired HUI Framework based on PSO,Bio-HUIF-PSO)、基于GA的生物启发式HUI框架(Bio-inspired HUI Framework based on GA,Bio-HUIF-GA)、基于或/非树结构PSO的HUIM算法(HUIM algorithm based on PSO with a OR/NOR tree structure,HUIM-PSO_tree)、基于人工鱼群的HUIM算法(HUIM algorithm based on Artificial Fish swarm, HUIM-AF)。性能指标包括收敛速度、挖掘的HUI数、挖掘全部或不同比例HUI所需要的运行时间。
3.1 实验环境和数据集
实验所用电脑配置如下:Intel Core i5-6402P CPU 2.8 GHz,16 GB内存,64位Windows 7操作系统,编程语言为Java。用Mushroom、Connect、Foodmart和Chainstore这4个数据集进行实验对比,4个数据集均来自开源社区SPMF[18]。Foodmart数据集包含了消费者在商店的购物记录;Connect数据集记录了游戏步数;Chainstore数据集记录了美国加州一家大型连锁杂货店的客户交易数据;Mushroom数据集包含了各类蘑菇及其相应特征,如气味、形状等。各数据集详情如表7所示。
表7数据集详情
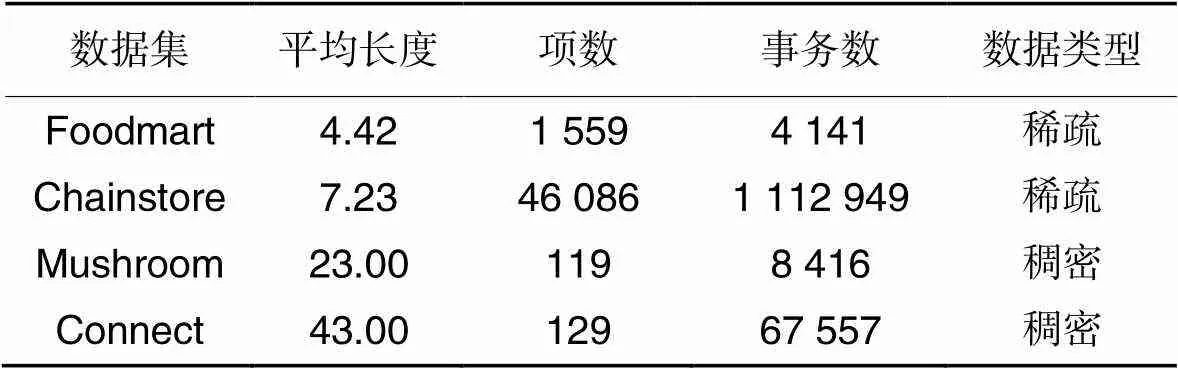
Tab.7 Details of datasets
对于Chainstore数据集上的对比实验,最大迭代次数设置为2 000;其他数据集上的对比实验,最大迭代次数设置为1 200,种群规模统一设置为40。Chainstore数据集上的迭代次数设置更大的原因是它为大型稀松数据集,在给定最小阈值下找到全部或绝大多数HUI需要更多的迭代次数。HUIM-MOA的相关参数设置如下:平均互信息重要系数设为1.5,温度冷却速率系数设为4,种群截断比例设置为1∶2。
3.2 收敛性对比
用每个算法在10次独立运行后获得的平均结果比较收敛性能。5个算法在各数据集相应阈值上的收敛效果如图3所示。从图3可见,HUIM-MOA在各数据集上都达到最高的收敛速度,Bio-HUIF-PSO次之。HUIM-MOA的收敛速度较Bio-HUIF-PSO平均提升了12.5%,主要原因是采用的种群多样性保持策略能有效防止算法陷入局部最优;此外,吉布斯采样温度系数的合理设置也能让算法在探索和开发中取得平衡,因此,HUIM-MOA算法始终保持探索新的HUI的能力。由于HUIM-PSO_tree、HUIM-AF在数据集Chainstore上的运行时间超过3 h,对比它们的收敛性已无意义,故图3(d)中没有它们的收敛曲线。
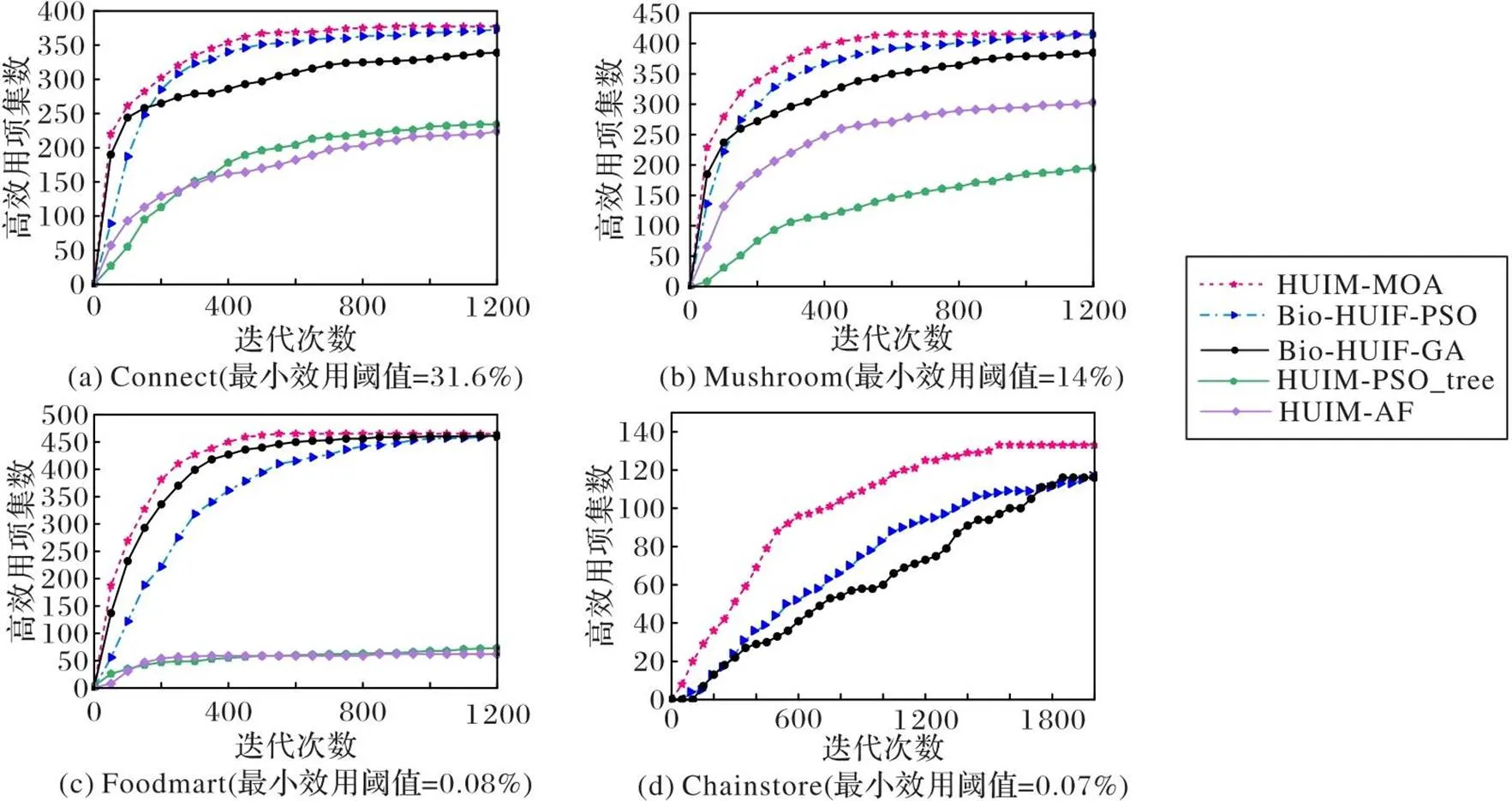
图3 各算法在给定阈值下的收敛情况
3.3 运行时间
图4展示了5个算法在各数据集不同阈值下的运行时间。可以看出,HUIM-MOA在4个数据集上的运行时间都是最少的,Bio-HUIF-PSO的运行时间次之。HUIM-MOA在各数据集上的运行时间较Bio-HUIF-PSO平均减少了14.6%。HUIM-PSO_tree、HUIM-AF整体运行时间都较长,在Chainstore这样的大型稀松数据集上运行时间超过3 h;HUIM-PSO_tree虽然采用OR/NOR tree的结构避免了不必要项集的产生,但相较于位图表示和期望向量编码依然更费时。
3.4 挖掘到的HUI数
在稠密数据集上阈值一般设置得较高,而在稀松数据集上阈值一般设置得较低,这是由于在稠密数据集上若设置较低阈值,则满足要求的HUI会大幅增加,在设定的迭代过程中难以找到绝大多数的HUI;若在稀松数据集上设置较高阈值,则可能导致没有满足要求的HUI,如在稀松数据集Foodmart上,当阈值设定为0.22%时,则没有满足要求的HUI。表8展示了5个算法在各数据集不同阈值下挖掘的HUI数的百分比。
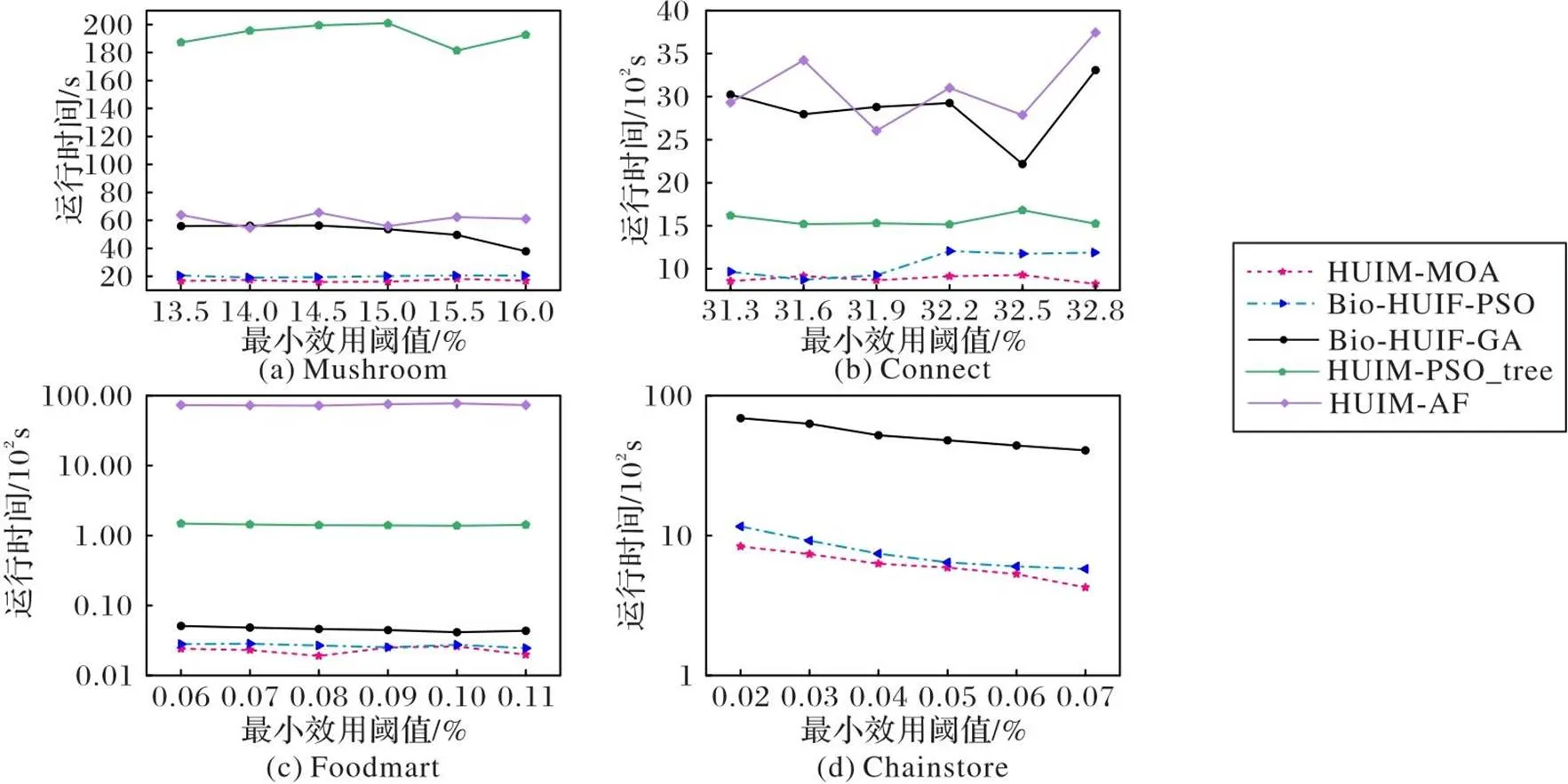
图4 各算法在给定阈值下的运行时间
表8对比算法在各数据集不同阈值下挖掘的HUIs的百分比 单位:%
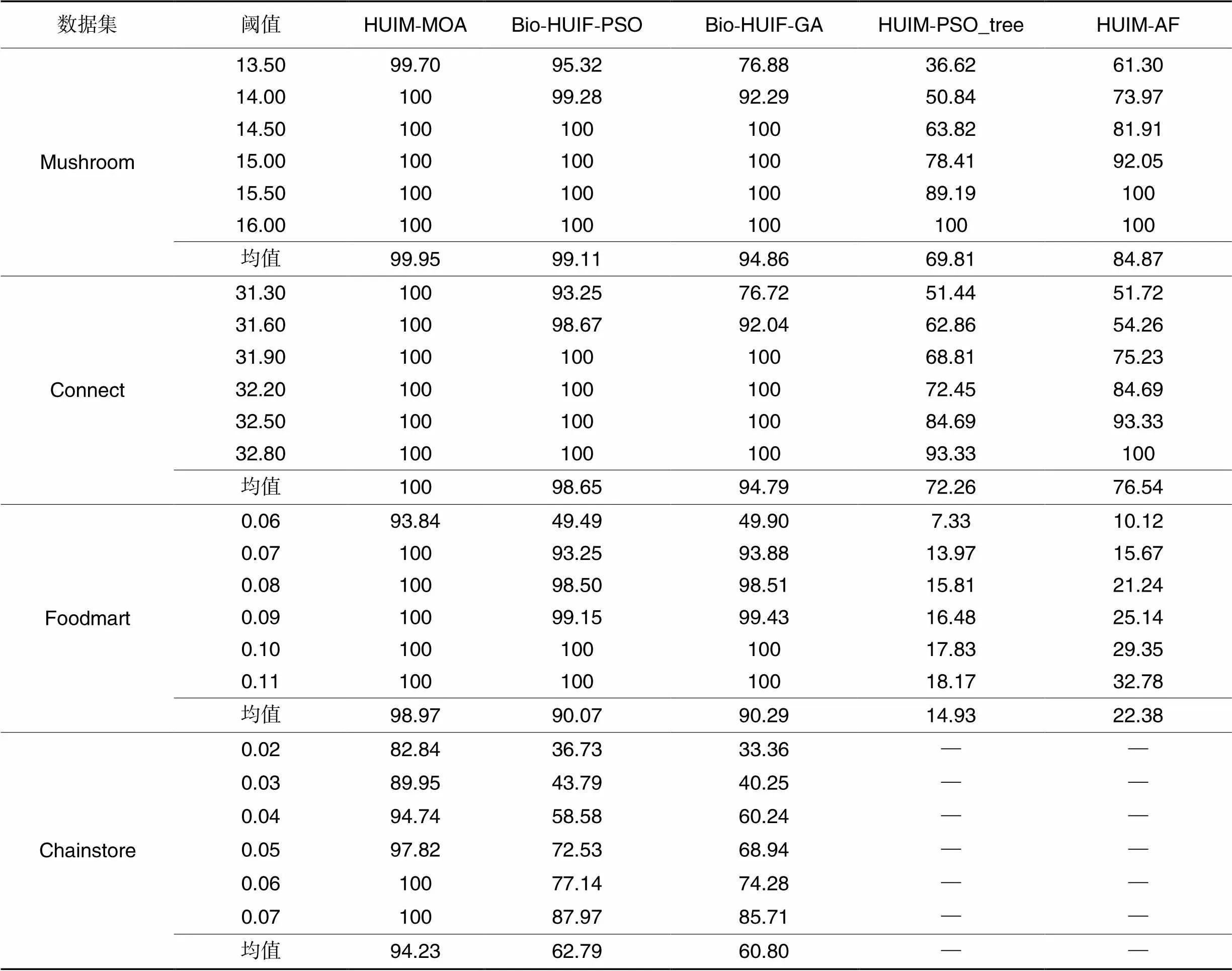
Tab.8 Percentage of HUIs mined by comparative algorithms with different thresholds for each dataset unit:%
可以看出,当给定阈值较大时,HUIM-MOA可以挖掘所有的HUI,相较于次优的Bio-HUIF-PSO,它挖掘的HUI平均数的百分比在4个数据集上提高了2.85个百分点。这是由于HUIM-MOA采样了MN结构的局部特性,它充分利用变量间的依赖关系,从而能找到更多的HUI;此外,种群多样性保持策略和精英策略也能在一定程度上防止算法陷入局部最优,实现更广泛的搜索,使得算法在后期也能持续搜索新的HUI。值得注意地,在稀松数据集Foodmart上,当阈值设定为0.06%时,两个基于BIO-HUIF框架的算法都只能找到近一半的HUI,HUIM-PSO_tree、HUIM-AF表现则更差,而HUIM-MOA能找到93.84%的HUI,这也充分体现了HUIM-MOA处理高维稀松数据集的优越性。在大型稀松数据集Chainstore上,各算法能找到的HUI的比例都大幅降低,这表明进化型算法处理大型稀松数据集存在一定的劣势。由于HUIM-PSO_tree、HUIM-AF的运行时间超过3 h,对比它们的挖掘数已无意义,故表8中未显示它们的挖掘百分比。
4 结语
本文算法(HUIM-MOA)通过分析优势个体间的互信息估计MN结构,并用MN的局部特性估计每个变量的条件概率,使得MOA相较于基于全局特性的算法更易实现;接着使用带温度下降的吉布斯采样法生成新的种群;为提高算法的运行效率,采用了位图表示法和期望向量编码;为使种群不过快陷入局部最优和减少HUI的缺失,分别采用了种群多样性保持策略和精英策略,加强HUIM-MOA的搜索能力;同时,互信息重要系数和温度冷却系数的恰当设定也使算法在开发和探索上达到一个平衡。从4个真实数据集上的实验结果可以看出,无论是在稠密集还是稀松集上,HUIM-MOA在收敛速度上比其他4个算法更高、运行时间更少,挖掘HUI数也最多。
未来将进一步优化基于MN的概率建模和采样过程,使算法的运行时间更少,同时还将尝试用其他类型的EDA与EA进行结合的方法挖掘HUI。当然,其他更合理更有效的剪枝策略、搜索策略也是下一步要重点研究的问题。
[1] CHEE C-H, JAAFAR J, AZIZ I A, et al. Algorithms for frequent itemset mining: a literature review[J]. Artificial Intelligence Review, 2019, 52: 2603-2621.
[2] FOURNIER-VIGER P, LIN J C-W, TRUONG-CHI T, et al. A survey of high utility itemset mining[M]// High Utility Pattern Mining. Cham: Springer, 2019: 1-45.
[3] KANNIMUTHU S, PREMALATHA K. Discovery of high utility itemsets using genetic algorithm with ranked mutation [J]. Applied Artificial Intelligence, 2014, 28(4): 337-359.
[4] ZHANG Q, FANG W, SUN J, et al. Improved genetic algorithm for high-utility itemset mining [J]. IEEE Access, 2019, 7: 176799-176813.
[5] LIN J C-W, YANG L, FOURNIER-VIGER P, et al. Mining high-utility itemsets based on particle swarm optimization[J]. Engineering Applications of Artificial Intelligence, 2016, 55: 320-330.
[6] LIN J C-W, YANG L, FOURNIER-VIGER P, et al. A binary PSO approach to mine high-utility itemsets [J]. Soft Computing, 2017, 21: 5103-5121.
[7] SONG W, LI J, HUANG C. Artificial fish swarm algorithm for mining high utility itemsets [C]// Proceedings of the 12th International Conference on Swarm Intelligence. Cham: Springer, 2021: 407-419.
[8] SONG W, HUANG C. Discovering high utility itemsets based on the artificial bee colony algorithm [C]// Proceedings of the 2018 Pacific-Asia Conference on Knowledge Discovery and Data Mining. Cham: Springer, 2018: 3-14.
[9] WU J M-T, ZHAN J, LIN J-W. Mining of high-utility itemsets by ACO algorithm [C]// Proceedings of the 3rd Multidisciplinary International Social Networks Conference on SocialInformatics 2016, Data Science 2016. Cham: Springer, 2016: Article No. 44.
[10] PAZHANIRAJA N, SOUNTHARRAJAN S, KUMAR B S. High utility itemset mining: a Boolean operators-based modified grey wolf optimization algorithm [J]. Soft Computing, 2020, 24(21): 16691-16704.
[11] SONG W, HUANG C. Mining high utility itemsets using bio-inspired algorithms: a diverse optimal value framework[J]. IEEE Access, 2018, 6: 19568-19582.
[12] SHAKYA S, SANTANA R. MOA-Markovian optimisation algorithm[M]// Markov Networks in Evolutionary Computation. Berlin: Springer, 2012: 39-53.
[13] 王圣尧,王凌,方晨,等. 分布估计算法研究进展[J]. 控制与决策, 2012, 27(7): 961-966,974.(WANG S Y, WANG L, FANG C, et al. Advances in estimation of distribution algorithms [J]. Control and Decision, 2012, 27(7): 961-966,974.)
[14] SEBAG M, DUCOULOMBIER A. Extending population-based incremental learning to continuous search spaces [C]// Proceedings of the 1998 International Conference on Parallel Problem Solving from Nature. Cham: Springer, 1998: 418-427.
[15] LARRAÑAGA P, ETXEBERRIA R, LOZANO J A, et al. Optimization in continuous domains by learning and simulation of Gaussian networks [C]// Proceedings of the 2th Genetic and Evolutionary Computation Conference. San Mateo:Morgan Kaufmann, 2000:201-204.
[16] SANTANA R. A Markov network based factorized distribution algorithm for optimization [C]// Proceedings of the 2003 European Conference on Machine Learning. Cham: Springer, 2003: 337-348.
[17] SHAKYA S, McCALL J. Optimization by estimation of distribution with DEUM framework based on Markov random fields[J]. International Journal of Automation and Computing, 2007, 4: 262-272.
[18] FOURNIER-VIGER P, LIN J C-W, GOMARIZ A, et al. The SPMF open-source data mining library version 2 [C]// Proceedings of the 2016 Joint European Conference on Machine Learning and Knowledge Discovery in Databases. Cham: Springer, 2016:36-40.
High utility itemset mining algorithm based on Markov optimization
ZHONG Xincheng1,2*, LIU Chang2, ZHAO Xiumei1
(1,,046000,;2,,110169,)
To address the problems that the High Utility Itemset Mining (HUIM) algorithms based on tree and link table structures often consume search spaces of orders of magnitude, and the evolutionary type-based mining algorithms fail to fully consider the interactions between variables, an HUIM algorithm based on Markov Optimization (HUIM-MOA) was proposed. Firstly, a bitmap matrix for expressing database and expectation vector encoding were used to achieve fast scanning of the database and efficient computation of utility values, respectively. Then, the Markov Network (MN) structure was estimated by computing the mutual information among dominant individuals and new populations were generated by using Gibbs sampling according to their local characteristics. Finally, population diversity preservation strategy and elite strategy were used to prevent the algorithm from falling into local optimum too quickly and to reduce the missing of high utility itemsets, respectively. Experimental results on real datasets show that compared with Bio-inspired High Utility Itemset Framework based on Particle Swarm Optimization (Bio-HUIF-PSO)algorithm, HUIM-MOA can find all the High Utility Itemsets (HUIs) when given a larger minimum threshold, with on average 12.5% improvement in convergence speed, 2.85 percentage point improvement in mined HUI number, and 14.6% reduction in running time. It can be seen that HUIM-MOA has stronger search performance than the evolutionary HUIM algorithm, which can effectively reduce the search time and improve the search quality.
High Utility Itemset Mining (HUIM); Markov network; bitmap matrix; Gibbs sampling; elite strategy
This work is partially supported by Science and Technology Innovation Project of Colleges and Universities in Shanxi Province in 2022 (2022L517).
ZHONG Xincheng, born in 1987, M. S., lecturer. His research interests include data mining, reinforcement learning.
LIU Chang, born in 1973, Ph. D., associate research fellow. Her research interests include data mining, schedule optimization.
ZHAO Xiumei, born in 1970, M. S., lecturer. Her research interests include software testing.
TP301.6
A
1001-9081(2023)12-3764-08
10.11772/j.issn.1001-9081.2022121844
2022⁃12⁃09;
2023⁃02⁃28;
2023⁃03⁃03。
2022年度山西省高等学校科技创新项目(2022L517)。
钟新成(1987—),男,湖南长沙人,讲师,硕士,主要研究方向:数据挖掘、强化学习;刘昶(1973—),女,辽宁沈阳人,副研究员,博士,主要研究方向:数据挖掘、调度优化;赵秀梅(1970—),女,山西高平人,讲师,硕士,主要研究方向:软件测试。
猜你喜欢
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
数学物理学报(2017年5期)2017-11-23 07:51:31
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:53
西北工业大学学报(2015年4期)2016-01-19 03:31:47
电测与仪表(2015年9期)2015-04-09 11:59:22
弹箭与制导学报(2015年1期)2015-03-11 15:32:31
卷宗(2014年5期)2014-07-15 07:47:08
计算机工程(2014年6期)2014-02-28 01:26:12
新课程学习·中(2013年3期)2013-06-14 05:55:20
