
基于生成对抗网络的联邦学习中投毒攻击检测方案
2024-01-09 04:01陈谦柴政王子龙陈嘉伟
计算机应用 2023年12期
陈谦,柴政,王子龙,陈嘉伟
基于生成对抗网络的联邦学习中投毒攻击检测方案
陈谦,柴政,王子龙*,陈嘉伟
(西安电子科技大学 网络与信息安全学院,西安 710071)(∗通信作者电子邮箱 zlwang@xidian.edu.cn)
联邦学习(FL)是一种新兴的隐私保护机器学习(ML)范式,然而它的分布式的训练结构更易受到投毒攻击的威胁:攻击者通过向中央服务器上传投毒模型以污染全局模型,减缓全局模型收敛并降低全局模型精确度。针对上述问题,提出一种基于生成对抗网络(GAN)的投毒攻击检测方案。首先,将良性本地模型输入GAN产生检测样本;其次,使用生成的检测样本检测客户端上传的本地模型;最后,根据检测指标剔除投毒模型。同时,所提方案定义了F1值损失和精确度损失这两项检测指标检测投毒模型,将检测范围从单一类型的投毒攻击扩展至全部两种类型的投毒攻击;设计阈值判定方法处理误判问题,确保误判鲁棒性。实验结果表明,在MNIST和Fashion-MNIST数据集上,所提方案能够生成高质量检测样本,并有效检测与剔除投毒模型;与使用收集测试数据和使用生成测试数据但仅使用精确度作为检测指标的两种检测方案相比,所提方案的全局模型精确度提升了2.7~12.2个百分点。
联邦学习;投毒攻击;生成对抗网络;F1值损失;精确度损失;阈值判定方法
0 引言
机器学习(Machine Learning, ML)[1]被广泛应用于从数据提取信息。大数据时代的数据量飞速增长,收集海量的数据用于机器学习变得异常困难。随着人们隐私保护意识的增强,利用包含用户敏感信息的数据进行集中式ML的方式受到了极大的限制[2],联邦学习(Federated Learning, FL)[3]应运而生。区别于传统的数据集中式ML,FL的分布式结构降低了收集训练数据带来的高昂通信开销,节省了稀缺的网络带宽,提升了通信效率;此外,包含敏感信息的原始数据自始至终没有离开客户本地,用户隐私得以保障。因此,FL因为高效的通信效率和良好的隐私保护性能被广泛部署在电子医疗[4]和垃圾邮件检测[5]等场景。
投毒攻击在传统的ML场景中已经得到广泛研究[6],而FL更易受到投毒攻击的威胁[7]。敌手通过挟持客户端、篡改训练数据间接篡改本地模型[8],或者通过修改模型参数直接篡改上传的本地模型[9]。聚合篡改后的模型会污染全局模型,降低全局模型的收敛速度和精确度。依据攻击目标,投毒攻击一般可以被分为随机攻击(或无目标攻击)和有目标攻击[10]。在随机攻击时,敌手随机篡改本地训练数据或模型,使得全局模型预测精确度下降;在有目标攻击时,敌手通过修改训练数据的某一特定特征或特定模型参数,使模型错误预测某一特定类型样本。
针对投毒攻击这一重大威胁,一系列防御措施被相继提出和研究,这些防御方案可以归纳为被动防御和主动防御两类。被动防御方案通常由中央服务器依据统计方法获得本地模型分布特征,并设计相应的聚合方法,在聚合过程中剔除投毒模型以提升全局模型性能[11-14];但是经过精心设计的投毒模型可以获得与正常模型相似的统计特征,规避聚合方法的检测,污染全局模型[8]。主动防御方案通过检测本地模型性能剔除投毒模型,可以有效地检测投毒模型并完全消除投毒模型对全局模型的负面影响[15-17];因此,主动防御方案已成为设计FL中投毒攻击检测方案的新趋势。例如,Jagielski等[15]提出一种由服务器收集部分本地训练样本并训练对比模型,通过迭代估计对比模型和本地模型残差值的检测方法,该方法可以有效抵御针对训练数据的投毒攻击;然而,当本地训练集中含有较多恶意样本时,该方法检测效果较差;同时,该方法在构建使用的训练集时需要用户上传隐私训练数据,违背了FL中训练数据不出本地的初衷。Zhao等[16]首次提出使用生成对抗网络(Generative Adversarial Network, GAN)[18]产生检测样本的方法,但由于仅采用精确度作为检测指标,该方案无法准确检测有目标攻击;此外,由于现实的本地模型预测精确度还受到用户数据非独立同分布、训练误差和传输误差等因素的影响,该方案仅根据单次聚合结果判定恶意用户的操作存在误判的可能。
针对服务器无法获得优质检测数据这一问题,本文引入GAN的方法,设计并实现基于GAN的FL中投毒攻击检测方案。该方案将未受到攻击的本地模型作为GAN的输入,输出一组用于检测的检测样本,然后利用该检测样本检测本地模型的F1值损失和精确度损失,从而剔除有目标投毒模型和无目标投毒模型这两类投毒模型。同时,针对文献[16]中方案的误判问题,本文方案设计了阈值判定方法以提高误判鲁棒性。
本文的主要工作如下:
1)定义并应用了全面的检测指标。针对两种不同类型的投毒攻击模型,定义了F1值损失和精确度损失这两种检测指标,并在所提方案中使用这两种指标检测和剔除有目标投毒模型和无目标投毒模型,将投毒攻击的检测范围扩大至全部两种类型。
2)提出了一种广泛适用的FL中投毒攻击检测方案。针对服务器缺少检测样本的问题,所提方案使用GAN产生检测样本(称为生成测试集),并将它用于检测客户端上传的本地模型。该方案尤其适用于由于隐私限制、有损通信信道等因素导致的服务器无法收集高质量检测数据的现实场景。同时,引入多次检测的阈值判定方法处理误判问题,确保所提方案的误判鲁棒性。所提方案能够检测并剔除FL系统中同时存在的两种投毒模型,提升全局模型的收敛速度和最终全局模型精确度,有效消除投毒攻击对FL的威胁。
3)设计并实现了仿真实验。为验证所提方案的有效性,分别在MNIST和Fashion-MNIST两个图像数据集进行仿真实验。实验结果表明,所提方案中基于GAN产生的生成测试集具有和理想测试集相近的投毒模型检测效果;同时,通过比较在生成测试集上计算得到的F1值损失和精确度损失,所提方案不仅获得更好的随机攻击抵御效果,而且可以更加有效地抵御有目标攻击。在两种攻击场景下,全局模型的精确度相较于有攻击场景大幅提高至与无攻击场景相近的水平。以Fashion-MNIST数据集为例,相较于收集测试数据的方法[15]与使用生成测试数据但只使用精确度作为检测指标的方法[16],在随机攻击下,所提方案将全局模型的精确度分别提高了12.2个百分点和5.0个百分点;在有目标攻击下,将全局模型精确度分别提高了4.5个百分点和2.7个百分点。
1 FL中的投毒攻击
一个典型的FL系统由中央服务器和一组客户端组成,它的目标是客户端在中央服务器的协调下协作训练一个ML模型。客户端将隐私的训练数据保存在本地,并在本地训练本地模型,随后中央服务器聚合本地模型以更新全局模型;然而这样的设置容易受到投毒攻击的威胁,攻击者可以通过上传恶意篡改的本地模型污染全局模型。
1.1 FL系统

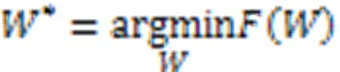
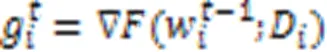
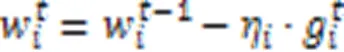
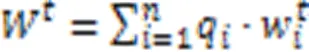
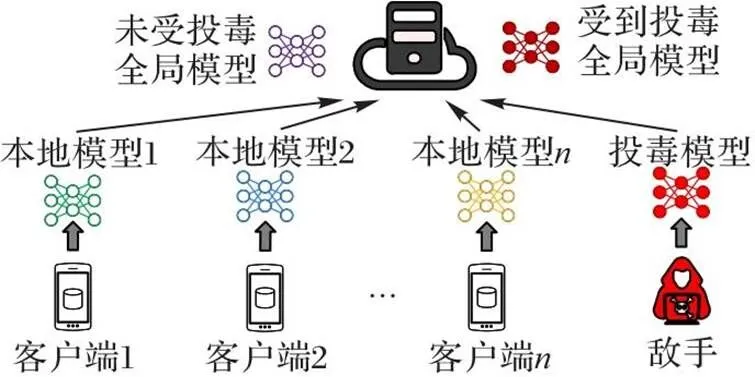
图1 FL与投毒攻击
1.2 投毒攻击
1.2.1威胁模型
本文考虑FL中广泛应用的威胁模型[19],其中敌手通过控制参与FL的客户端完成投毒攻击。具体威胁模型定义如下:
敌手目标 敌手通过制造投毒模型并向中央服务器上传投毒模型,降低全局模型的整体预测精确度或者在特定类别样本上的预测精确度,从而达到污染全局模型的目的。
敌手知识 敌手已知全局模型和所控制客户端的本地模型和数据,因此可以使用它控制的恶意客户端训练投毒模型;但敌手无法通过任何方法获知中央服务器抵御投毒攻击的检测方法以及对应的全局模型聚合方法。
1.2.2投毒攻击的种类
根据敌手对全局模型性能的影响程度,投毒攻击分为随机攻击和有目标攻击两种。本文设想的FL系统中同时存在随机攻击[20-21]和有目标攻击[19,22-23]。
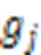
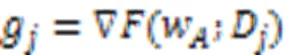
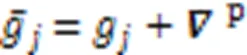
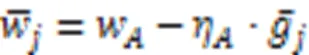
对应地,中央服务器聚合的全局模型如下:
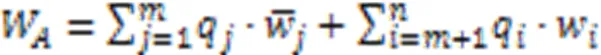
有目标攻击 同样地,敌手可以通过上传经过精心构造的模型执行有目标攻击[19]。系统中正在执行有目标攻击的敌手首先在它控制的每个恶意客户端本地将特定类别样本的标签篡改为其他类别,从而构造恶性数据集[22]。敌手在该数据集训练有目标攻击投毒模型如下:
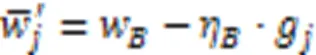
此时中央服务器聚合得到的全局模型为:
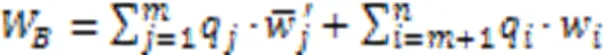
2 投毒攻击防御方法研究现状
2.1 被动防御
被动防御中,服务器通过分析上传的本地模型的统计特征设计抗投毒模型的聚合方法,从而在聚合本地模型过程中剔除投毒模型。Yin等[11]提出了Trimmed-Mean方案和Median方案。这两个方案首先在模型的每个维度上对所有本地模型参数进行排序,其次Trimmed-Mean方案去掉规定个数的模型参数的最大值与最小值,并计算剩余模型参数的平均值;而Median方案则将每个维度的梯度中位数组合后作为全局模型。
通常投毒模型与正常模型的差异较大,因此通过计算几何意义上的相似度以检测投毒模型是一种有效的方法。Blanchard等[12]提出的Krum方案通过度量欧氏距离,选择全部本地梯度中与其他本地梯度最相似的值作为全局梯度;Multi-Krum方案作为Krum方案的变体,通过选择多个最相似的梯度并计算它们的均值,获得了更高的模型收敛速度和全局模型精确度。Guerraoui等[24]提出了Bulyan方案,首先迭代使用Krum方案以选择多个梯度,其次计算选中梯度的Trimmed-mean值,它的本质是Krum方案和Trimmed-Mean方案的结合。Muñoz-González等[13]提出的AFA(Adaptive Federated Averaging)方案在每个FL聚合轮次中首先计算收集的梯度加权平均值,其次计算该加权平均值与每个梯度之间的余弦相似度,最终综合考虑余弦相似度的均值、中位数和标准差,检测并剔除离群梯度。陈宛桢等[14]提出了一种基于区块链的隐私保护FL算法,首先,客户端在本地训练模型参数,并以秘密共享的方式上传模型更新至附近的边缘节点;其次,边缘节点计算所有更新间的欧氏距离并将计算结果与模型更新上传至区块链;最后,区块链重构模型参数之间的欧氏距离,去除投毒模型更新。
被动防御方法实现简单,并且在检测过程中不需要评估模型,检测效率较高;但是,本地模型特征的统计偏差将造成误判,影响投毒模型的检测精确度,因此被动防御方法在实际中无法得到有效应用。
2.2 主动防御
主动防御方法是近年来FL中投毒攻击检测方法的新方向。Steinhardt等[25]提出使用数据清洗的方法,即通过清洗训练集,筛选并剔除投毒数据,完成对投毒攻击的抵御;但是这样的方法无法在敌手直接篡改模型参数的本地模型投毒攻击形式中发挥作用[19]。Feng等[17]提出了一种基于逻辑回归分类器的数据投毒防御策略,通过检测异常值的方式去除异常度超出阈值的样本;然而该方法假设服务器预先知道投毒样本在训练数据中的比例,这在FL中无法实现。Jagielski等[15]提出一种由服务器收集部分本地训练样本、训练比对模型,并迭代估计比对模型和本地模型残差值的检测方法,可以有效抵御针对训练数据的投毒攻击;然而,当本地训练集中含有较多恶意样本时,该方法检测效果较差,且在构建该方法使用的训练集时需要用户上传隐私训练数据,违背了FL中训练数据不出本地的初衷。Zhao等[16]首先提出使用GAN产生检测样本的方案,在保护用户隐私训练数据的同时,进一步缓解了投毒攻击的影响;但当FL系统受到有目标攻击时,由于只采用精确度作为检测指标,该方案无法准确检测并剔除所有的投毒模型;此外,该方案仅根据单次聚合结果判定恶意用户,存在误判的可能。由于现实的本地模型预测精确度还受到用户数据非独立同分布、训练误差和传输误差等因素的影响,使用该方案对此类场景下的本地模型进行检测时存在误判的可能。
在已有研究的基础上,本文定义了F1值损失和精确度损失两种检测指标,扩大了投毒攻击的检测范围,增强了检测方案的实用性。使用GAN产生的高质量检测样本检测客户端上传的本地模型,提高了检测准确率。引入多次检测的阈值判定方法,解决现实场景中潜在的误判问题,提升了检测方案的误判鲁棒性。
3 GAN
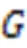
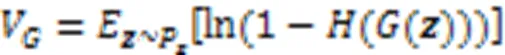
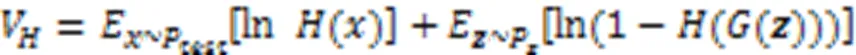
4 基于GAN的投毒攻击检测方案
4.1 检测指标
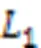
定义1 F1值损失。F1值损失为先前轮次全局模型和当前轮次本地模型对特定样本分类情况的F1值的差,即:
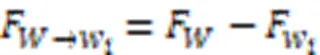
此外,随着有目标攻击的目标样本种类增加,有目标攻击同样也会影响模型整体的精确度[19];同时,随机攻击也会对模型精确度产生较大影响。精确度作为ML领域最常见的评价指标,直观反映了模型的性能[30],因此,本文设计精确度损失衡量投毒攻击对模型产生的影响。
定义2 精确度损失。精确度损失为先前轮次全局模型和当前轮次本地模型在测试集上精确度的差,即:
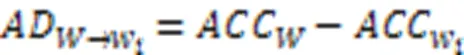
4.2 方案设计
为了抵御FL中的投毒攻击,本文提出一种基于GAN的投毒攻击检测方案(如图2所示)评估客户端本地模型,以检测并剔除投毒模型。方案使用的检测指标为F1值损失和精确度损失。为了确保检测样本不依赖包含用户隐私的原始数据,本文引入GAN生成高质量的检测样本。
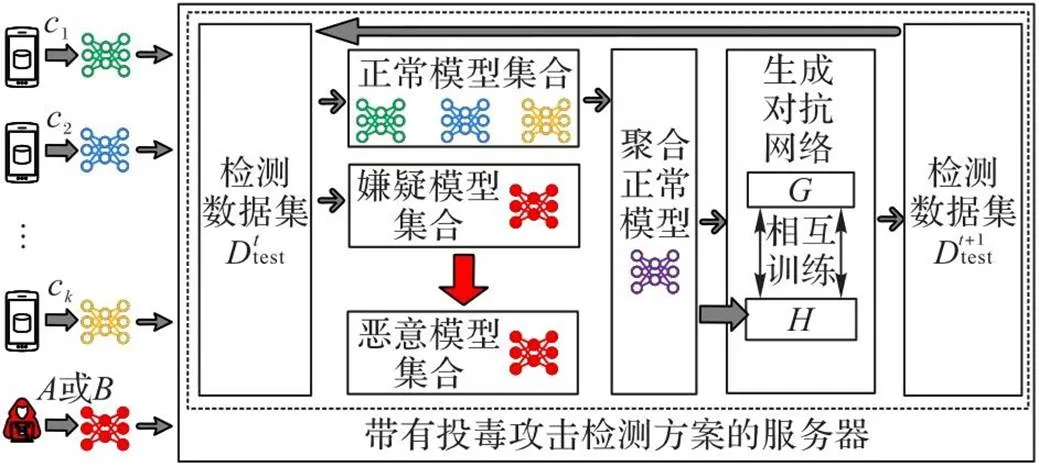
图2 基于GAN的投毒攻击检测方案

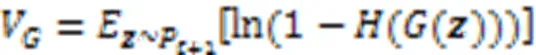
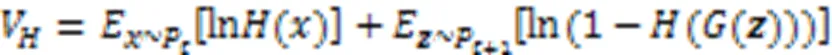
最后,中央服务器下发全局模型,各客户端继续使用本地数据训练全局模型。上述本地模型上传、投毒模型检测、本地模型聚合和检测样本生成过程重复执行,直到全局模型收敛。

4.3 复杂度分析
算法1 投毒模型检测算法。
ELSE
END IF
END IF
END FOR
5 实验与结果分析
5.1 实验数据
5.2 实验设置
实验对FL系统做如下规定:中央服务器持有初始测试数据集的样本数为5 000,每种类别的样本数大致相同;系统中共有30个拥有本地模型训练能力的客户端,敌手控制其中14个客户端。为了模拟现实场景中FL的数据非独立同分布情况,本文实验将MNIST和Fashion-MNIST训练集中的样本按照期望为1 000、方差为2 500的正态分布划分为30份作为各客户端的本地训练集。
MNIST数据集和Fashion-MNIST数据集中的理想测试样本分别如图3(a)所示,它们的清晰度较高,可以表示中央服务器有能力获得高质量检测数据的理想情况;但这与现实场景中央服务器无法获得高质量测试样本的困境不符。因此本文实验对它们做干扰处理,模拟在现实场景中采用收集检测数据时遇到的传感器故障、信道不理想和解码错误等客观问题[19]。通过在测试集的各测试样本中依次加入若干种包括高斯噪声、泊松噪声和椒盐噪声在内的噪声,最终形成如图3(b)的低质量测试集。为了便于描述,将干扰处理前后的测试集分别称为理想测试集和原始测试集。通过观测可以发现,原始测试集中样本模糊不易辨认,而图3(c)所示的生成测试集中样本具有和理想测试集中样本相近的清晰度,质量较高。

图3 MNIST数据集和Fashion-MNIST数据集的3种检测数据
针对不同的实验数据集,实验中图像分类模型均为卷积神经网络(Convolutional Neural Network, CNN)。客户端和中央服务器持有的模型结构相同,均由3个卷积层和2个全连接层组成,每个卷积层后接1个池化层,全连接层后接1个柔性最大值(Softmax)激活函数。本地模型训练过程设定随机梯度下降(Stochastic Gradient Descent, SGD)为模型优化算法,并设定模型初始学习率为0.001,衰减率为1×10-6。中央服务器用于生成测试样本的网络为GAN。其中生成器由1个上采样层、2个卷积层、2个池化层和1个全连接层组成,全连接层后接一个双曲正切激活函数tanh。此外,实验设定将当前轮次聚合后的全局模型作为判别器模型,它的网络结构和图像分类模型结构相同。同时设定GAN使用Adam算法进行模型优化,初始学习率为0.000 2,衰减率为0.5。
5.3 实验结果与分析
为了验证本文方案抵御投毒攻击的有效性和广泛性,分别将它部署在受到随机攻击和有目标攻击的FL场景中,与未受到投毒攻击和分别受到两种投毒攻击的FL进行比较。不同场景中全局模型的最终性能记录在表1、2中。图4分别展示了MNIST数据集和Fashion-MNIST数据集在不同实验设置下的全局模型训练过程。“无攻击”表示未受到任何攻击的全局模型;“随机攻击”和“有目标攻击”分别表示受到随机攻击和受到有目标攻击的全局模型;“检测并剔除随机攻击”和“检测并剔除有目标攻击”分别表示在受到两种投毒攻击时,采用所提方案对投毒模型进行检测并剔除投毒模型后的全局模型。以MNIST数据集为例分析实验结果。观察图4(a)(b)可以发现,在受到两种投毒攻击时,全局模型收敛速度变低,精确度下降,损失的最终收敛值上升。同时由表1可知,在无攻击场景下,全局模型的最终损失值为0.058 6,最终精确度为98.2%。在随机攻击场景下,全局模型的最终损失值为0.654 1,最终精确度为74.3%;在有目标攻击场景下,全局模型的最终损失值为0.112 1,最终精确度为94.6%。在部署所提方案后,随机攻击场景和有目标攻击场景下的全局模型最终损失值分别为0.062 5和0.060 9,最终精确度分别为97.4%和98.0%,两者都接近无攻击场景下的全局模型收敛效果,即损失值仅增加了0.002 3,精确度仅减少了0.2个百分点。以上结果表明,在受到两种类型的投毒攻击时全局模型最终性能下降,而部署所提方案后的全局模型最终性能和未受到投毒攻击时接近。观察图4(c)所示的全局模型的受试者特征(Receiver Operating Characteristic,ROC)曲线也可得到相似的结论。观察图4(a)(b)还可以发现,在FL初始阶段(0~10的FL聚合轮次),部署所提方案的全局模型收敛速度低于未受到投毒攻击的全局模型,主要原因是所提方案在FL初始阶段并未生成高质量的检测样本,无法准确检测全部投毒模型;但随着FL的进行,所提方案可以生成高质量检测数据,从而准确高效地检测和剔除投毒模型。
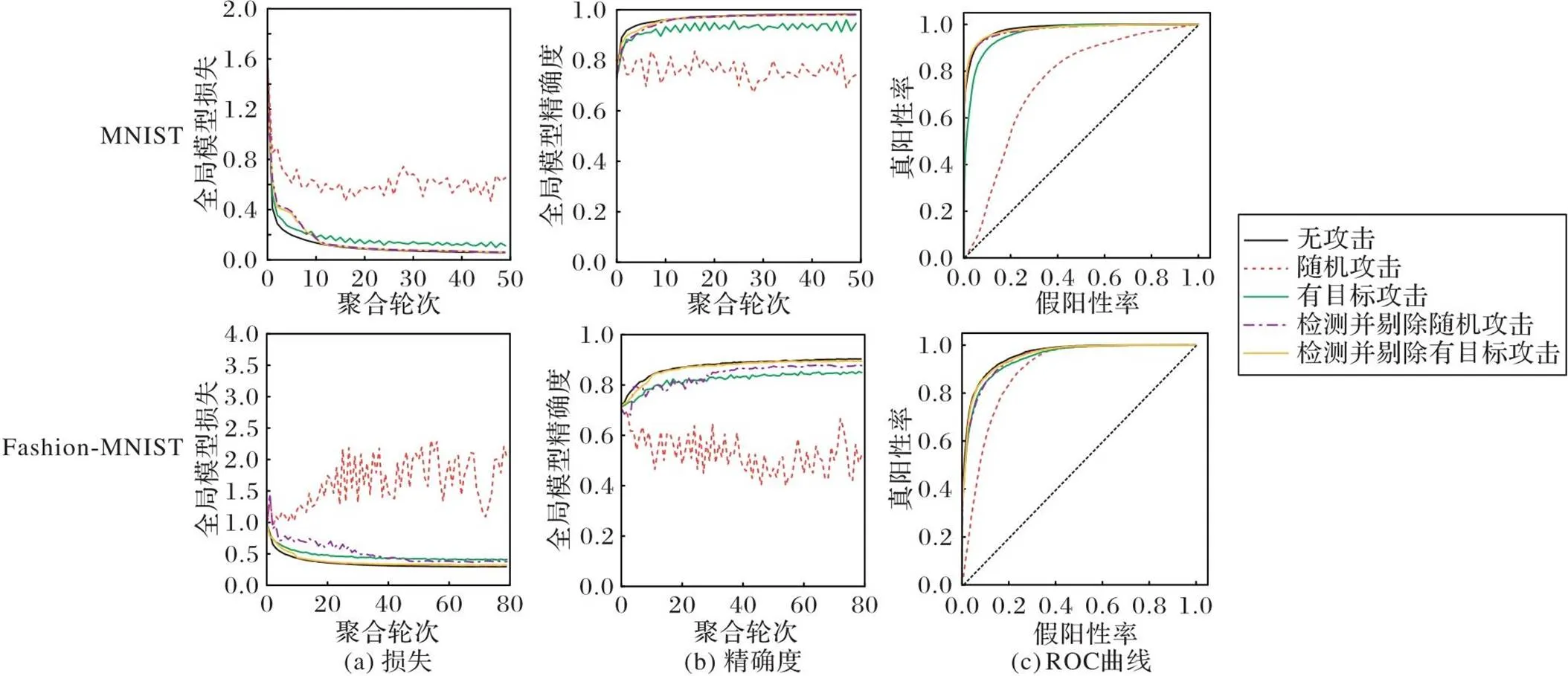
图4 MNIST数据集和Fashion-MNIST数据集上的全局模型性能
表1不同方案对MNIST数据集的全局模型性能
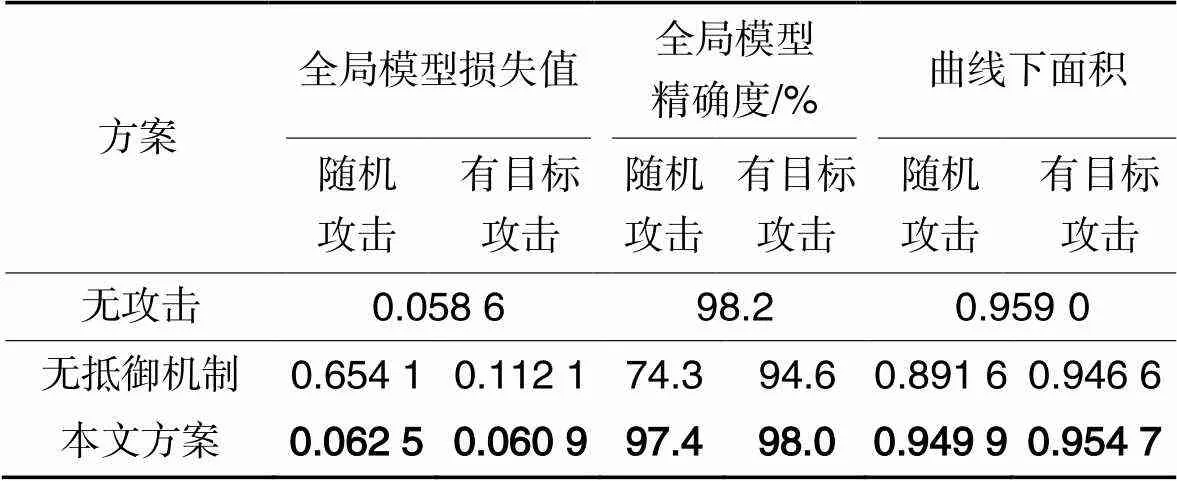
Tab.1 Global model performance of different schemes on MNIST dataset
为验证本文方案抵御投毒攻击的高效性,将它与文献[15-16]方案分别在两种攻击场景进行比较。全局模型最终性能记录在表2,以Fashion-MNIST数据集为例,相较于收集测试数据的方法[15]与使用生成测试数据但只使用准确率作为检测指标的方法[16],在随机攻击下,本文方案将全局模型的精确度分别提高了12.2和5.0个百分点;在有目标攻击下,将全局模型精确度分别提高了4.5和2.7个百分点。图5记录了Fashion-MNIST数据集上采用不同方案检测并剔除两种投毒模型后的全局模型性能曲线,其中:收集检测数据方案[15]表示在原始测试集上比较F1值损失和精确度损失的方案;精确度方案[16]表示在生成测试集上比较精确度的方案;“本文方案”表示在生成测试集上比较F1值损失和精确度损失的方案。观察图5(a)并结合表2可知,在受到有目标攻击时,全局模型损失值为0.411 0。“收集检测数据方案”通过在原始测试集上比较F1值损失和精确度损失,将全局模型的损失值降低为0.412 0;“精确度方案”通过在生成测试集上比较精确度,将全局模型的收敛损失值降低为0.388 1,两种方案对有目标攻击投毒的抵御效果都不明显。可见,由于仅检测在所有类别样本上的全局模型精确度,而忽略了在某一特定类别上的全局模型精确度,因此文献[15-16]方案都不能有效地检测有目标攻击投毒模型,无法有效地抵御有目标攻击。本文方案在生成测试集上比较F1值损失,可以有效地检测有目标攻击投毒模型,从而将全局模型的损失值降低为0.317 6,这一数值和未受到投毒攻击时的全局模型的损失值相近。可见,所提方案可以对有目标攻击的投毒模型进行有效的检测和剔除。观察图5(b)中的全局模型精确度变化曲线可以得到相同的结论。并由表2可知,在受到有目标攻击时,全局模型的最终精确度值为84.9%;采用文献[15-16]方案时,全局模型的精确度分别为84.9%和86.7%;而在部署本文方案后,全局模型的精确度提高至89.4%,这一数值同样和未受到投毒攻击时相近。与文献[15-16]方案相比,全局模型的精确度分别提高了4.5个百分点和2.7个百分点。观察随机攻击场景下的全局模型损失值和全局模型精确度变化曲线,结合表2可知,在受到随机攻击时,全局模型损失值为2.029 8,并存在较大震荡。采用文献[15-16]方案时,全局模型的损失值分别降低为0.736 2和0.549 2;而在部署本文方案后,全局模型的收敛损失值降低为0.376 8,这一数值和未受到投毒攻击时的全局模型的损失值相近。可见,所提方案可以对随机攻击的投毒模型进行有效的检测和剔除。观察图5(b)中的全局模型精确度变化曲线并结合表2可以得到相同的结论。在受到随机攻击时,全局模型的精确度呈下降趋势,最终精确度值为52.1%,并存在较大震荡;采用文献[15-16]方案后,全局模型的精确度分别提高到75.5%和82.7%;而在采用本文方案后,全局模型的精确度提高到87.7%,这一数值同样和未受到投毒攻击时相近。与文献[15-16]方案相比,全局模型的精确度分别提高了12.2个百分点和5.0个百分点。综合以上结果,相较于仅能抵御随机攻击的文献[15-16]方案,所提方案不仅能更好地抵御随机攻击,同时可以有效地抵御有目标攻击。
表2Fashion-MNIST数据集上不同方案的全局模型性能
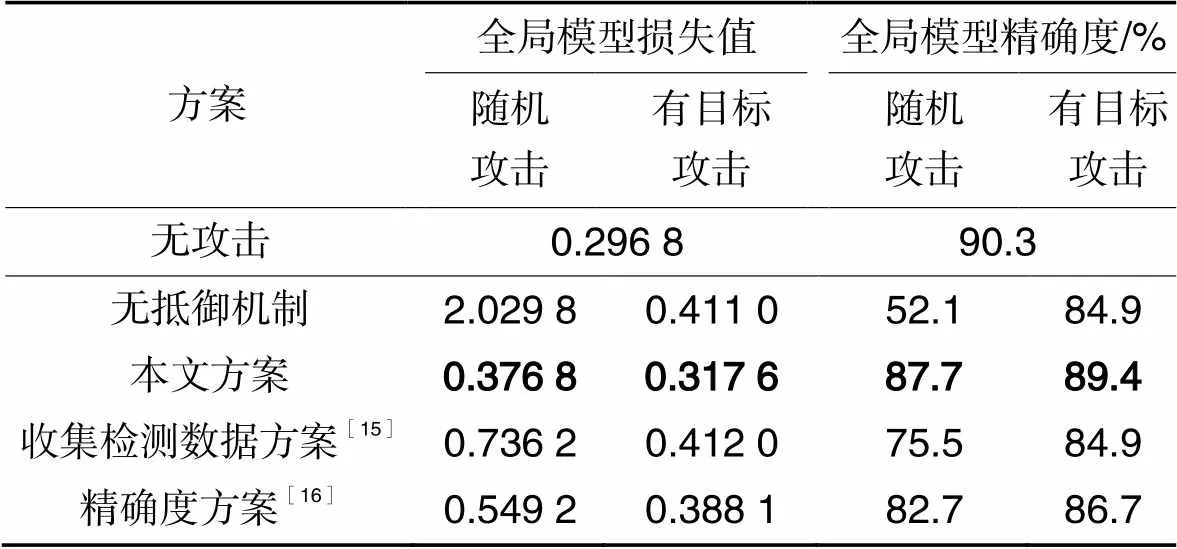
Tab.2 Global model performance on Fashion-MNIST dataset of different schemes
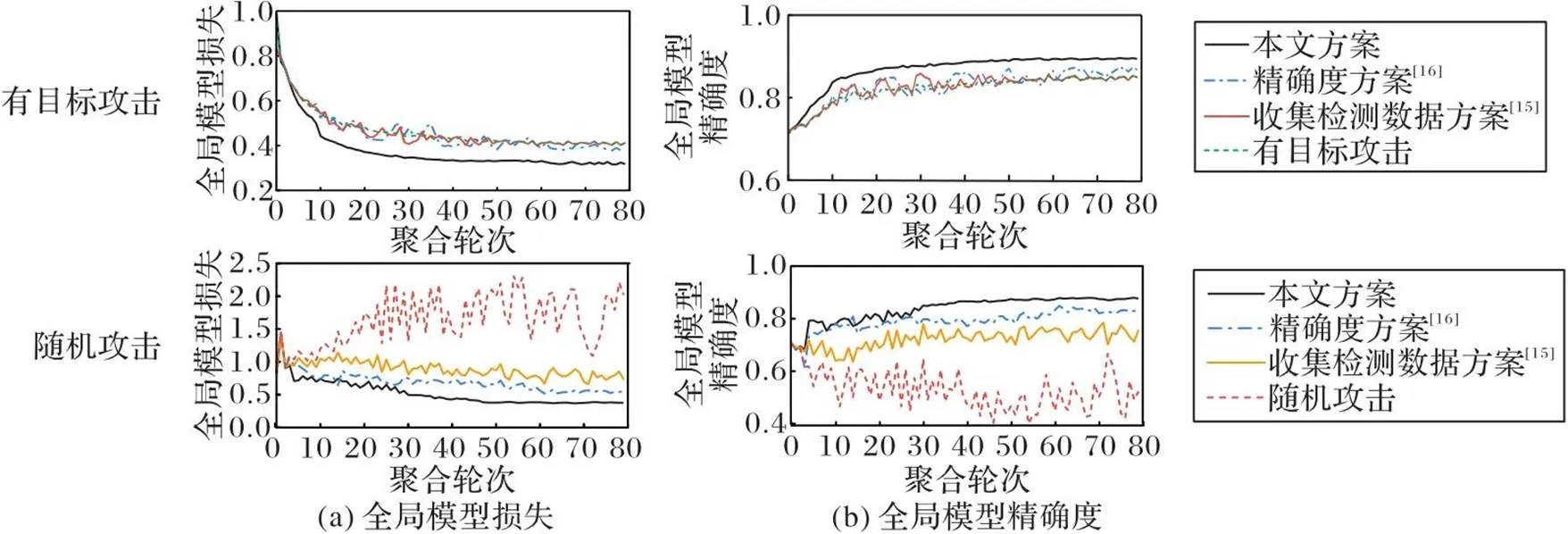
图5 Fashion-MNIST数据集上不同方案检测并剔除投毒模型性能
图6 阈值判定方法对所提方案性能的影响

图7 检测指标的判定阈值对所提方案性能的影响
6 结语
FL作为一种分布式ML框架,因具有良好的隐私保护性能和通信效率得到广泛的应用;然而它聚合本地模型的范式易受到投毒攻击的威胁。为了检测并抵御投毒攻击,本文提出一种基于GAN的投毒攻击检测方案。所提方案利用GAN产生检测样本,并使用F1值损失和精确度损失作为检测指标对模型进行阈值检测从而剔除投毒模型。在MNIST和Fashion-MNIST数据集上的实验结果表明,通过部署所提方案,中央服务器可以获得高质量的检测样本,从而有效地检测并剔除全部两种类型的投毒攻击,最终获得性能良好的FL全局模型。
现阶段FL系统的投毒攻击与抵御措施研究都建立在无隐私保护机制FL场景。由于中央服务器可以直接获取客户端的本地模型,存在隐私泄漏的风险;而在使用同态加密与差分隐私等隐私保护FL场景下,现有的抵御措施无法有效检测并剔除投毒模型。因此,在隐私保护FL的现实场景中,针对密态模型和扰动模型的投毒攻击抵御措施有待进一步研究。
[1] JORDAN M I, MITCHELL T M. Machine learning: trends, perspectives, and prospects[J]. Science, 2015, 349(6245): 255-260.
[2] VOIGT P, VON DEM BUSSCHE A. The EU General Data Protection Regulation (GDPR)[S]. Cham: Springer, 2017.
[3] MCMAHAN H B, MOORE E, RAMAGE D, et al. Communication-efficient learning of deep networks from decentralized data[C]// Proceedings of the 20th International Conference on Artificial Intelligence and Statistics. Brookline: Microtome Publishing, 2017: 1273-1282.
[4] XU J, GLICKSBERG B S, SU C, et al. Federated learning for healthcare informatics[J]. Journal of Healthcare Informatics Research, 2021, 5(1): 1-19.
[5] CHEN Q, WANG Z L, LIN X D. PPT: a privacy-preserving global model training protocol for federated learning in P2P networks [J]. Computers & Security, 2023, 124: 102966.
[6] TIAN Z, CUI L, LIANG J, et al. A comprehensive survey on poisoning attacks and countermeasures in machine learning[J]. ACM Computing Surveys, 2022, 55(8): 1-35.
[7] KAIROUZ P, MCMAHAN H B, AVENT B, et al. Advances and open problems in federated learning [J]. Foundations and Trends®in Machine Learning, 2021, 14(1/2): 1-210.
[8] TOLPEGIN V, TRUEX S, GURSOY M E, et al. Data poisoning attacks against federated learning systems [C]// Proceedings of the 25th European Symposium on Research in Computer Security. Cham: Springer, 2020: 480-501.
[9] FANG M H, CAO X Y, JIA J Y, et al. Local model poisoning attacks to Byzantine-robust federated learning [C]// Proceedings of the 29th USENIX Security Symposium. Berkeley: USENIX Association, 2020: 1605-1622.
[10] TAHMASEBIAN F, XIONG L, SOTOODEH M, et al. Crowdsourcing under data poisoning attacks: a comparative study[C]// Proceedings of the 2020 IFIP Annual Conference on Data and Applications Security and Privacy. Cham: Springer, 2020: 310-332.
[11] YIN D, CHEN Y, KANNAN R, Byzantine-robust distributed learning: towards optimal statistical rates [C]// Proceedings of the 35th International Conference on Machine Learning. San Diego: JMLR, 2018: 5650-5659.
[12] BLANCHARD P, EL MHAMDI E M, GUERRAOUI R, et al. Machine learning with adversaries: byzantine tolerant gradient descent [C]// Proceedings of the 31st International Conference on Neural Information Proceedings Systems. La Jolla: NIPS, 2017: 118-128.
[13] MUÑOZ-GONZÁLEZ L, CO K T, LUPU E C. Byzantine-robust federated machine learning through adaptive model averaging [EB/OL]. (2019-09-11)[2022-04-25]. https://arxiv.org/pdf/1909.05125.pdf.
[14] 陈宛桢,张恩,秦磊勇,等.边缘计算下基于区块链的隐私保护联邦学习算法[J].计算机应用,2023, 43(7): 2209-2216.(CHEN W Z, ZHANG E, QIN L Y,et al. Privacy-preserving federated learning algorithm based on block chain in edge computing [J]. Journal of Computer Applications, 2023, 43(7): 2209-2216.)
[15] JAGIELSKI M, OPREA A, BIGGIO B, et al. Manipulating machine learning: poisoning attacks and countermeasures for regression learning [C]// Proceedings of the 39th IEEE Symposium on Security and Privacy. Piscataway: IEEE, 2018: 19-35.
[16] ZHAO Y, CHEN J, ZHANG J, et al. Detecting and mitigating poisoning attacks in federated learning using generative adversarial networks[J]. Concurrency and Computation: Practice and Experience, 2020, 34(7): e5906.
[17] FENG J, XU H, MANNOR S, et al. Robust logistic regression and classification[C]// Proceedings of the 27th International Conference on Neural Information Proceeding Systems. La Jolla: NIPS, 2014: 253-261.
[18] GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets[J] Communications of the ACM, 2020, 63(11): 139-144.
[19] BHAGOJI A N, CHAKRABORTY S, MITTAL P, et al. Analyzing federated learning through an adversarial lens[C]// Proceedings of the 36th International Conference on Machine Learning. San Diego: JMLR, 2019: 634-643.
[20] SHEJWALKAR V, HOUMANSADR A. Manipulating the byzantine: optimizing model poisoning attacks and defenses for federated learning [C]// Proceedings of 28th Annual Network and Distributed System Security Symposium. Reston: Internet Society, 2021: 1-19.
[21] ALKHUNAIZI N, KAMZOLOV D, TAKÁČ M, et al. Suppressing poisoning attacks on federated learning for medical imaging [C]// Proceedings of the 2022 International Conference on Medical Image Computing and Computer-Assisted Intervention, LNCS 13438. Cham: Springer, 2022: 673-683.
[22] SUN J, LI A, DIVALENTIN L, et al. FL-WBC: enhancing robustness against model poisoning attacks in federated learning from a client perspective [C]// Proceedings of the 2021 Advances in Neural Information Proceedings Systems 34. La Jolla: NIPS, 2021:12613-12624.
[23] NGUYEN T D, RIEGER P, MIETTINEN M, et al. Poisoning attacks on federated learning-based IoT intrusion detection system[C]// Proceedings of the 2020 Decentralized IoT Systems and Security Workshop. Washington: Internet Society, 2020: 1-7.
[24] GUERRAOUI R, ROUAULT S. The hidden vulnerability of distributed learning in Byzantium[C]// Proceedings of the 35th International Conference on Machine Learning. San Diego: JMLR, 2018: 3521-3530.
[25] STEINHARDT J, KOH P W, LIANG P. Certified defenses for data poisoning attacks[C]// Proceedings of the 31st International Conference on Neural Information Proceedings Systems. La Jolla: NIPS, 2017: 3520-3532.
[26] LEDIG C, THEIS L, HUSZÁR F, et al. Photo-realistic single image super-resolution using a generative adversarial network [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 4681-4690.
[27] CHEN Z, ZHU T, XIONG P, et al. Privacy preservation for image data: a GAN‐based method [J]. International Journal of Intelligent Systems, 2021, 36(4): 1668-1685.
[28] WANG Z, SONG M, ZHANG Z, et al. Beyond inferring class representatives: user-level privacy leakage from federated learning[C]// Proceedings of the 2019 IEEE Conference on Computer Communications. Piscataway: IEEE, 2019: 2512-2520.
[29] TRUEX S, BARACALDO N, ANWAR A, et al. A hybrid approach to privacy-preserving federated learning[C]// Proceedings of the 12th ACM Workshop on Artificial Intelligence and Security. New York: ACM, 2019: 1-11.
[30] TOLPEGIN V, TRUEX S, GURSOY M E, et al. Data poisoning attacks against federated learning systems [C]// Proceedings of the 2020 European Symposium on Research in Computer Security, LNCS 12308. Cham: Springer, 2022: 480-501.
[31] LeCUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition [J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324.
[32] XIAO H, RASUL K, VOLLGRAF R. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms [EB/OL]. [2022-10-28].https://arxiv.org/pdf/1708.07747v1.pdf.
Poisoning attack detection scheme based on generative adversarial network for federated learning
CHEN Qian, CHAI Zheng, WANG Zilong*, CHEN Jiawei
(,,’710071,)
Federated Learning (FL) emerges as a novel privacy-preserving Machine Learning (ML) paradigm. However, the distributed training structure of FL is more vulnerable to poisoning attack, where adversaries contaminate the global model through uploading poisoning models, resulting in the convergence deceleration and the prediction accuracy degradation of the global model. To solve the above problem, a poisoning attack detection scheme based on Generative Adversarial Network (GAN) was proposed. Firstly, the benign local models were fed into the GAN to output testing samples. Then, the testing samples were used to detect the local models uploaded by the clients. Finally, the poisoning models were eliminated according to the testing metrics. Meanwhile, two test metrics named F1 score loss and accuracy loss were defined to detect the poisoning models and extend the detection scope from one single type of poisoning attacks to all types of poisoning attacks. Besides, a threshold determination method was designed to deal with misjudgment, so that the robust of misjudgment was confirmed. Experimental results on MNIST and Fashion-MNIST datasets show that the proposed scheme can generate high-quality testing samples, and then detect and eliminate poisoning models. Compared with the global models trained with the detection scheme based on directly gathering test data from clients and the detection scheme based on generating test data and using test accuracy as the test metric, the global model trained with the proposed scheme has significant accuracy improvement from 2.7 to 12.2 percentage points.
Federated Learning (FL); poisoning attack; Generative Adversarial Network (GAN); F1 score loss; accuracy loss; threshold determination method
This work is partially supported by the National Natural Science Foundation of China (62172319, U19B200073).
CHEN Qian, born in 1993, Ph. D. candidate. His research interests include privacy preservation, machine learning, federated learning.
CHAI Zheng, born in 1999, M. S. candidate. His research interests include federated learning, poisoning attack.
WANG Zilong, born in 1982, Ph. D., professor. His research interests include information theory, cryptography.
CHEN Jiawei, born in 1998, M. S. candidate. His research interests include federated learning, reinforcement learning.
TP309.2
A
1001-9081(2023)12-3790-09
10.11772/j.issn.1001-9081.2022121831
2022⁃12⁃13;
2023⁃05⁃09;
2023⁃05⁃10。
国家自然科学基金资助项目(62172319, U19B200073)。
陈谦(1993—),男,陕西西安人,博士研究生,主要研究方向:隐私保护、机器学习、联邦学习;柴政(1999—),男,黑龙江大庆人,硕士研究生,主要研究方向:联邦学习、投毒攻击;王子龙(1982—),男,河南郑州人,教授,博士,主要研究方向:信息论、密码学;陈嘉伟(1998—),男,陕西西安人,硕士研究生,主要研究方向:联邦学习、强化学习。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
小猕猴智力画刊(2022年4期)2022-05-05
数学物理学报(2022年2期)2022-04-26
云南教育·中学教师(2020年11期)2021-01-07
山东煤炭科技(2020年1期)2020-03-06
金桥(2018年4期)2018-09-26
中国卫生(2014年5期)2014-11-10
小雪花·成长指南(2014年8期)2014-08-26
教育与职业(2014年1期)2014-04-17
计算机工程(2013年1期)2013-09-29
