
基于对比超图转换器的会话推荐
2024-01-09 02:40党伟超程炳阳高改梅刘春霞
计算机应用 2023年12期
党伟超,程炳阳,高改梅,刘春霞
基于对比超图转换器的会话推荐
党伟超,程炳阳*,高改梅,刘春霞
(太原科技大学 计算机科学与技术学院,山西 太原 030024)(∗通信作者电子邮箱 s202120210809@stu.tyust.edu.cn)
针对会话推荐本身存在的噪声干扰和样本稀疏性问题,提出一种基于对比超图转换器的会话推荐(CHT)模型。首先,将会话序列建模为超图;其次,通过超图转换器构建项目的全局上下文信息和局部上下文信息。最后,在全局关系学习上利用项目级(I-L)编码器和会话级(S-L)编码器捕获不同级别的项目嵌入,经过信息融合模块进行项目嵌入和反向位置嵌入融合,并通过软注意力模块得到全局会话表示,而在局部关系学习上借助权重线图卷积网络生成局部会话表示。此外,引入对比学习范式最大化全局会话表示和局部会话表示之间的互信息,以提高推荐性能。在多个真实数据集上的实验结果表明,CHT模型的推荐性能优于目前的主流模型。相较于次优模型S2-DHCN(Self-Supervised Hypergraph Convolutional Networks),在Tmall数据集上,所提模型的P@20最高达到了35.61%,MRR@20最高达到了17.11%,分别提升了13.34%和13.69%;在Diginetica数据集上,所提模型的P@20最高达到了54.07%,MRR@20最高达到了18.59%,分别提升了0.76%和0.43%,验证了所提模型的有效性。
会话推荐;超图转换器;对比学习;注意力机制
0 引言
推荐系统作为一种有效缓解信息过载的基础设施工具,已被广泛应用在许多网络搜索应用、电子商务平台和在线娱乐平台。在这些应用中,传统的推荐系统主要依据用户的个人信息和长期历史交互完成推荐,事实上很多服务器上无法访问这些信息,只有当前会话的匿名信息可用,匿名用户和系统之间的这些交互被组织成会话。与传统的推荐系统不同,基于会话的推荐系统[1](简称会话推荐系统)利用用户的点击行为序列构建用户的行为模式,进而预测下一项用户可能感兴趣的物品。
会话推荐系统具有很高的实用性,相关研究成果不断涌现。当前基于图神经网络的推荐模型[2-3]取得了良好的推荐性能,但仍存在几个关键挑战:首先,噪声干扰在大多数推荐场景中普遍存在;其次,样本稀疏性问题仍然阻碍着用户项交互建模。鉴于上述挑战,本文提出了一种新的基于对比超图转换器的会话推荐(Contrastive Hypergraph Transformer for session-based recommendation, CHT)模型。
本文的主要工作如下:
1)提出一种对比超图转换器,从有噪声的用户交互数据中挖掘更有价值的用户偏好信息,高效地捕获所有会话中的项目级表示。
2)在获得项目级表示的基础上,通过全局关系学习和局部关系学习生成全局和局部会话表示,并在两个会话表示之间引入对比学习范式辅助推荐模型,缓解数据稀疏性问题。
1 相关工作
1.1 基于会话的推荐
基于会话的推荐是推荐系统的典型应用。会话推荐系统的初步探索主要集中于序列建模,主要包括基于项目的邻域方法[4]和基于马尔可夫链的序列方法[5]。尽管基于项目的邻域方法根据项目相似性矩阵完成推荐,但它忽略了项目之间的顺序。为解决这一问题,基于马尔可夫链的序列方法利用每个相邻的两次点击之间的顺序行为建模用户的短期偏好[6],但无法捕捉长期偏好。Zhan等[7]将两者结合,避免了对局部序列信息的依赖。近期,研究人员提出了一些基于深度学习的模型:Hidasi等[8]提出GRU4Rec(Gated Recurrent Unit for Recommendation),首次使用循环神经网络(Recurrent Neural Network, RNN)根据单击项对会话进行建模;NARM(Neural Attentive Recommendation Machine)[9]被设计为混合RNN和注意力机制的编码器,以建模用户的顺序行为;STAMP(Short-Term Attention/Memory Priority)[10]利用MLP(MultiLayer Perceptron)网络和注意力机制,捕获用户的一般兴趣和当前的兴趣。
随着图神经网络在计算机视觉和自然语言处理领域的成功,研究人员考虑将图神经网络融入会话推荐以提升推荐性能。其中,Wu等[11]提出SR-GNN(Session-based Recommendation with Graph Neural Networks)将序列建模为会话图,并通过门控图神经网络学习项目的表示。随着SR-GNN的成功应用,一些GNN的变体也取得了良好的性能。其中,Qiu等[12]提出了FGNN(Function Graph Neural Networks)模型,通过考虑会话内特定项目的转换模式补偿SR-GNN。虽然上述方法在会话推荐(Session-Based Recommendation, SBR)中取得了很好的性能,但仍未能捕获项目之间复杂的高阶关系。
1.2 超图学习
超图[13]为捕获项目之间复杂的高阶关系提供了可行性。随着超图神经网络的发展,一些研究将超图学习与推荐系统结合。Yadati等[14]首次将超图卷积网络用于顺序推荐,通过将序列构造为超图以建模用户的短期偏好;Xia等[15]提出了S2-DHCN(Self-Supervised Hypergraph Convolutional Networks),通过构造双通道超图建模用户之间的高阶关系。然而噪声干扰在大多数推荐场景中普遍存在,具体地,直接应用超图聚合信息将破坏原始特征空间中的节点相似性,损害准确的用户表示;更严重地,由于低维节点只有少量的邻居,它们从邻域接收的信息非常有限,导致基于超图的推荐系统不能为新用户或项目提供满意的推荐。为了应对这些挑战,本文提出了一种新的超图转换器,有效地捕获了所有会话中的项目转换模式。
1.3 对比学习
对比学习[16]是一种新兴的机器学习范式,旨在从原始数据中学习数据表示。近年来,对比学习也引起了研究人员对图表示的广泛关注[17]。受图的对比学习的启发,SGL(Self-supervised Graph Learning)通过生成具有随机节点和边缘退出操作的对比视图产生先进的性能[18]。根据这一研究路线,本文的工作重点从会话级表示的角度,将对比学习范式集成到超图转换器架构,联合训练全局会话表示与局部会话表示,有效地缓解了数据稀疏性的问题。
2 基于对比超图转换器的会话推荐
2.1 总体架构
本文CHT模型的总体架构如图1所示。首先,通过自适应超图和权重线图构建项目的全局上下文信息和局部上下文信息。其次,在全局关系学习上通过会话级(Session-Level, S-L)编码器和项目级(Item-Level, I-L)编码器得到两个级别的项目嵌入,经过信息融合模块进行项目嵌入和反向位置嵌入融合,并通过软注意力模块得到全局会话表示;在局部关系学习上利用平均池化层和权重线图卷积网络层学习局部会话表示。再次,将对比学习范式集成到CHT模型中。最后,通过预测层,输出下次点击的项推荐列表。
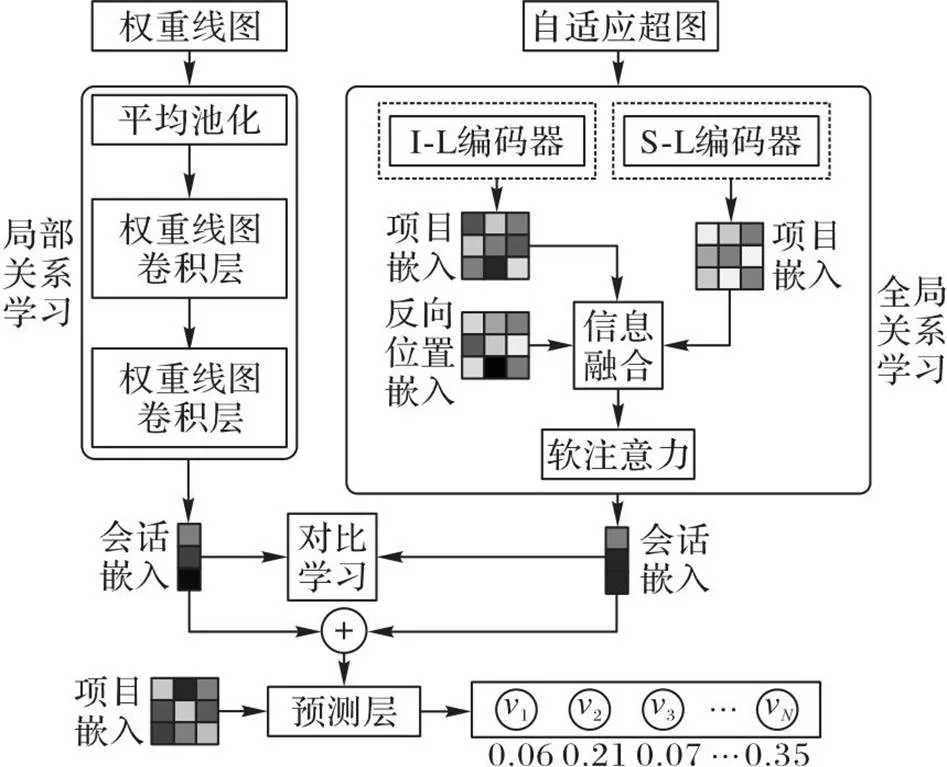
图1 CHT模型的总体架构
2.2 问题定义
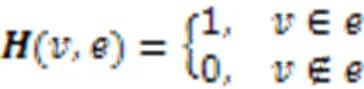
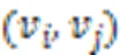
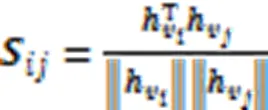
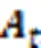
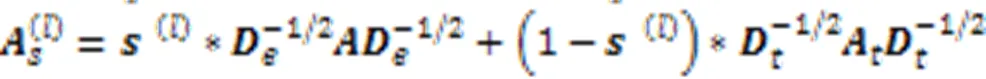
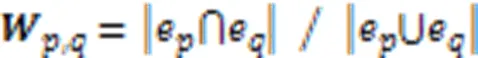
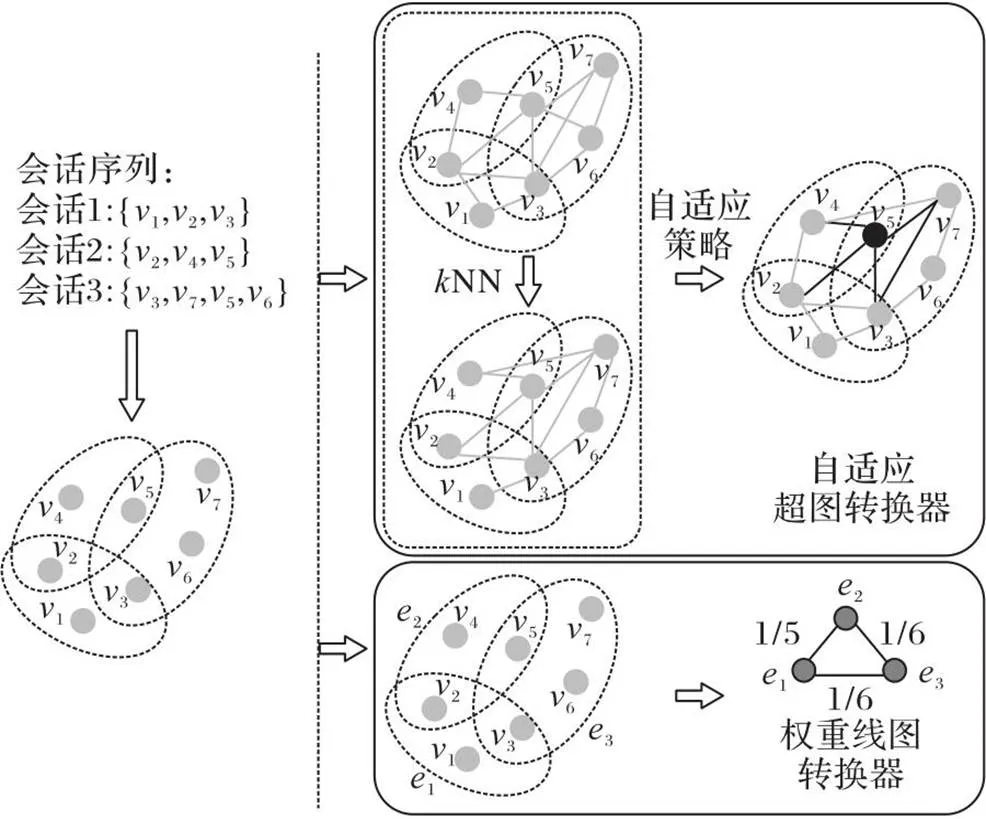
图2 超图转换器的结构
2.3 全局关系学习
全局关系学习通过项目级(I-L)编码器和会话级(S-L)编码器得到两个级别的项目嵌入,经过信息融合模块进行项目嵌入和反向位置嵌入融合,并通过软注意力模块得到全局会话表示。
2.3.1I-L编码器
I-L编码器通过自适应超图卷积层获取会话中项目之间的高阶关系。与传统的图相比,超图中的超边可以在多个节点之间聚合特征,可以看作是“顶点-超边-顶点”特征转换的两级细化。将超图卷积定义为:
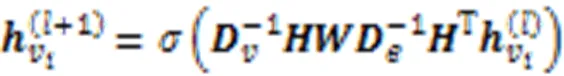
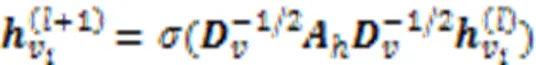
其中表示卷积网络总层数。
2.3.2S-L编码器

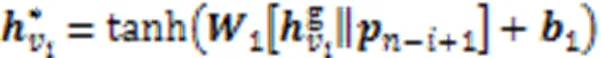
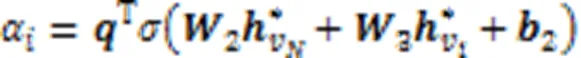
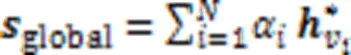
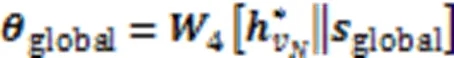
2.4 局部关系学习
局部关系学习利用平均池化层和权重线图卷积网络学习局部会话表示。
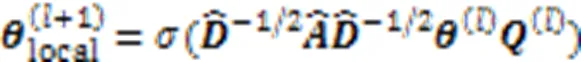
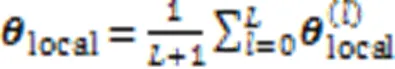
2.5 预测层
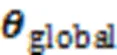
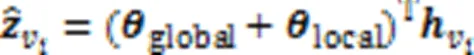
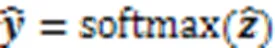
在训练过程中,损失函数定义为预测值和真实值的交叉熵函数,公式为:
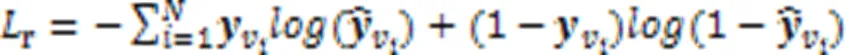
2.6 对比学习联合所有模块
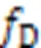
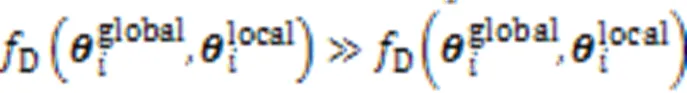
采用InfoNCE损失函数,最大化不同层次的会话表示之间的互信息,作为本文的学习目标:
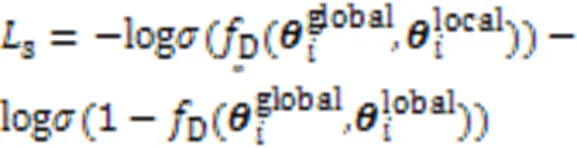
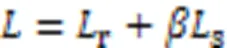
3 实验与结果分析
3.1 数据集及预处理
在3个真实的基准数据集Diginetica、Tmall和Nowplaying[19]上进行了广泛的实验。其中:Diginetica来自CIKM Cup 2016,包含具有代表性的交易数据;Tmall来自IJCAI-15竞赛,包含了天猫购物平台上的匿名用户的购物日志;Nowplaying包含用户收听音乐的行为。为了公平地进行比较,按照Xia等[15]实验设置,对3个基准数据集进行预处理。表1给出了3种数据集经过预处理过程后的基本统计信息和使用的属性信息。
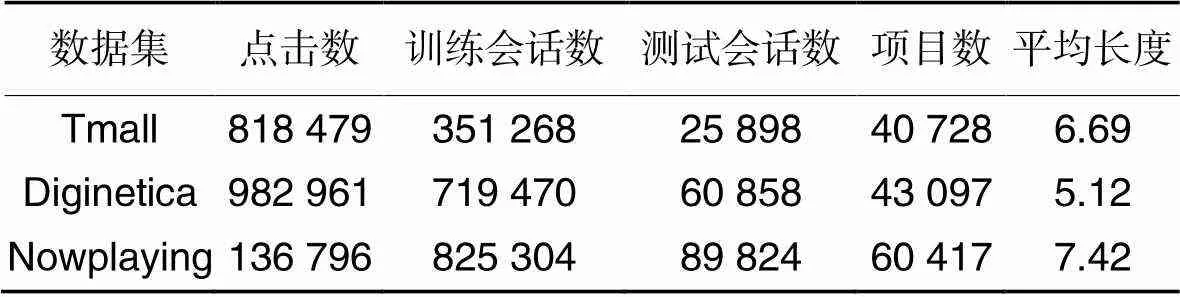
表1 预处理后的数据集统计信息
注:训练会话数和测试会话数的值表示增强后的样本数。
3.2 评价指标
为了便于与基线模型比较,选择了常用的精确率(Precision)和平均倒数排名(Mean Reciprocal Rank, MRR)评估提出的模型的性能。
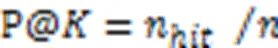
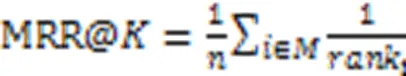
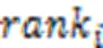
本文将设置为20。
3.3 参数设置
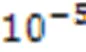
3.4 模型性能比较与分析
本文将CHT模型与现有的9种主流的模型进行比较(现有模型的超参数设置与原文一致):
1)POP。推荐当前数据集中点击频率最高的个物品。
2)Item-KNN[4]。将物品同时出现的频率作为相似度,并推荐相似度最高的个物品。
3)FPMC[5]。融合了矩阵分解和马尔可夫链的混合模型,在捕获用户长期偏好的同时考虑了序列的时间信息。
4)GRU4Rec[8]。通过使用 RNN 神经网络处理会话的长期特征。
5)NARM[9]。采用RNN结合注意力机制对序列模式进行建模。
6)STAMP[10]。在RNN上引入注意力机制,从会话上下文的长期记忆中捕获一般兴趣,并将最后一项作为用户对当前会话的短期兴趣进行预测。
7)SR-GNN[11]。将会话序列建模为图结构,通过GNN模型提取项目间的转换关系,并使用注意力机制捕获用户的长期兴趣。
8)FGNN[12]。通过考虑项目转换模式的固有顺序来扩展NARM。
9)S2-DHCN[15]。利用超图捕获高阶关系,并构造自监督学习进行训练。
总体性能的实验结果见表2。
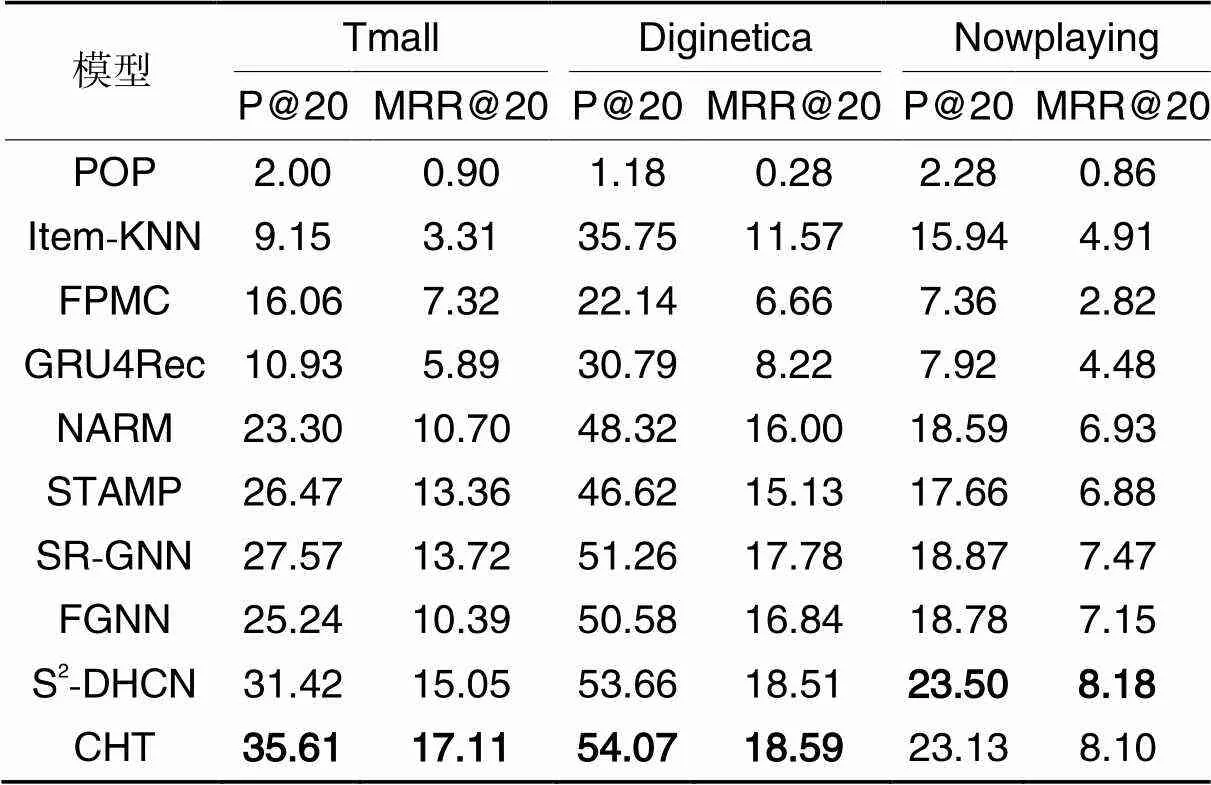
表2 不同模型在公开数据集上的性能对比 单位:%
注:加粗表示最优数值。
通过分析,可以得出以下结论:
1)从表2中可以看出,基于RNN推荐方法优于POP、FPMC和Item-KNN等传统方法,这表明RNN在会话推荐模型中的关键作用。基于GNN的模型(SR-GNN、FGNN)的性能优于基于RNN的模型,这种改进归功于图神经网络的巨大容量;然而,基于GNN的模型只捕获当前会话中的顺序模式,而没有利用其他会话中的项目转换信息。S2-DHCN通过对项目之间的高阶关系进行建模,性能得到较大提升。由于直接应用超图聚合信息,将破坏原始特征空间中的节点相似性,损害准确的用户表示,因此将基于会话的数据直接建模为超图可能会受噪声干扰的影响。
2)融入对比学习的CHT模型取得了不错的效果。特别是在Tmall、Diginetica这两个数据集的平均长度较短的会话中,对比学习扮演了更重要的角色,这符合本文假设,即会话数据的稀疏性可能阻碍CHT模型的建模,对比学习通过最大化两个会话表示之间的互信息解决了这个问题。
3)CHT模型在几乎所有数据集上都显示了较大的优势。CHT模型在Tmall数据集上实现了最大的提升,P@20和MRR@20指标分别为35.61%和17.11%,相较于次优模型分别提升了13.34%和13.69%,这得益于对全局和局部会话表示的综合考虑;同时,CHT模型在Diginetica上也取得了最优的性能,P@20最高达到了54.07%,MRR@20最高达到了18.59%,相较于次优模型分别提升了0.76%和0.43%,这也验证了CHT模型的有效性;CHT在Nowplaying上的性能提升并不明显,因为Nowplaying的平均会话长度比其他两个数据集更长,在一定程度上阻碍了对比学习在稀疏数据集上的学习能力。
3.5 消融实验
CHT模型可以看作是不同模块联合的结果。为了验证所提模块的实际价值,分别删除了CHT的5个主要部分,得到5个变体分别是CHT-I-L,CHT-S-L,CHT-C,CHT-G和CHT-L,其中:CHT-I-L为删除CHT的I-L编码器模块的模型;CHT-S-L为删除CHT的S-L编码器模块的模型;CHT-C为删除对比学习模块的模型;CHT-G为删除自适应超图转换器模块;CHT-L为删除权重线图转换器模块。
消融实验结果如表3所示,CHT模型在Tmall和Diginetica数据集上的性能始终优于5个变体,这表明每个模块都对CHT模型的推荐过程有贡献,并验证了本文模型的有效性。总体地,S-L编码器利用当前会话的内部连接捕获会话级的连接信息,当删除S-L编码器时,可以发现在所有指标上的性能都显著降低。相对而言,I-L编码器的贡献较少,但在相对稀疏的Nowplaying数据集上,I-L编码器可以通过预训练所有会话的项目转换信息帮助模型作出更准确的预测。当删除对比学习模块时,在所有情况下都会产生明显的性能下降,这验证了本文引入对比学习的有效性。在Tmall和Diginetica数据集上,CHT-L的性能优于CHT-G,说明使用自适应超图可以有效地捕获高阶信息。在Nowplaying数据集上,CHT-L比CHT-G表现更好,这可能是由于Nowplaying数据集中的会话的平均长度比其他两个数据集中的长,这有助于在局部关系学习上对会话中项目之间的依赖关系的学习。
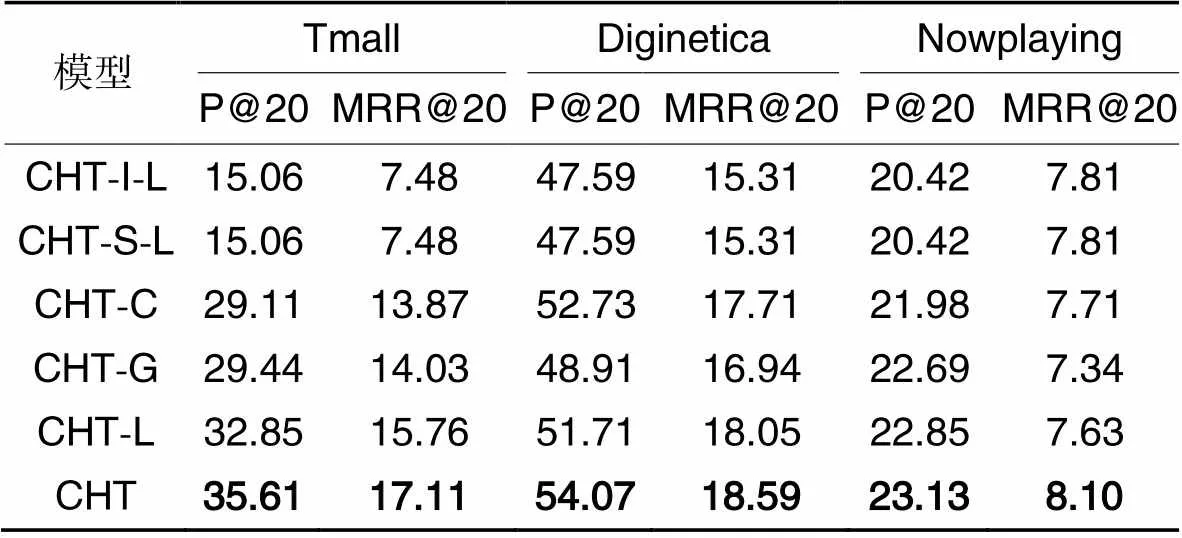
表3 CHT模型的消融实验结果 单位:%
3.6 对比学习参数比较与分析
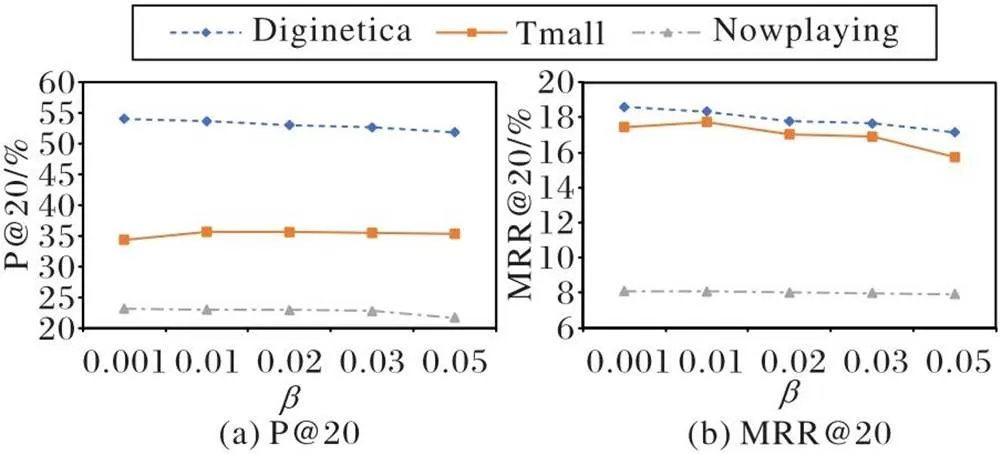
图3 对比学习中参数大小的影响
3.7 模型深度的影响
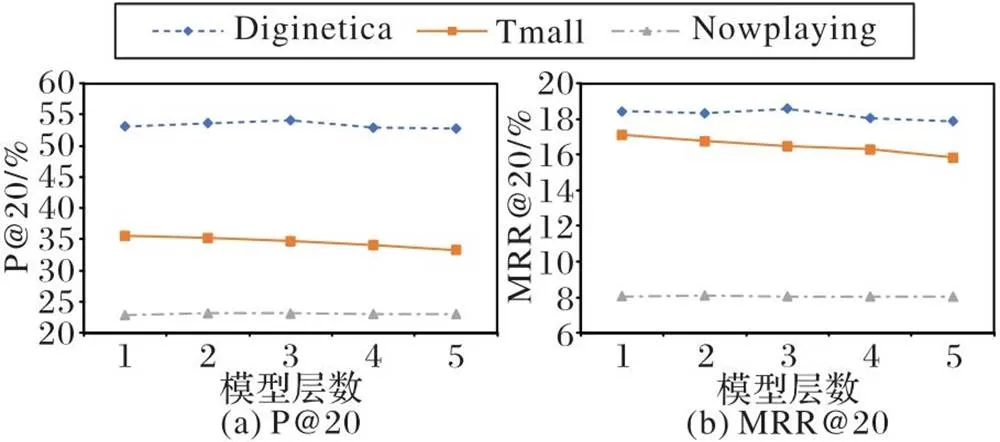
图4 模型深度的影响
3.8 效率分析
为分析模型的效率,本文研究了时间复杂度和空间复杂度对所提模型性能的影响。
表4显示了CHT模型与基线模型在Tmall数据集上训练30轮后得到平均每轮的训练时间。先进的模型S2-DHCN的训练时间比其他方法高,大约为4倍,这表明与普通图模型相比,沿着超图传播信息较耗时;但CHT模型可以保持良好的效率。由上述推理,CHT模型利用图节点自适应策略动态地调整来自图的结构和节点特征的信息,降低了模型的计算量,从而降低了邻域采样过程的时间复杂度。
此外,选择来自RecSys 2015挑战赛中Yoochoose数据集的数据信息,它包含了用户在在线零售平台6个月内的点击信息和购买行为。在Yoochoose1/64数据集上做进一步实验以获取不同模型的参数量、模型大小和运行时占用内存。从表5可见,模型参数量与模型大小和占用内存相关,说明模型的空间复杂度与参数量有关。综合看,CHT模型在包含大量会话和项目的真实会话推荐场景中具有较大优势。
表4不同模型在Tmall数据集上的平均训练时间 单位:s

Tab.4 Average training time of different models on Tmall dataset unit:s
表5模型参数量分析
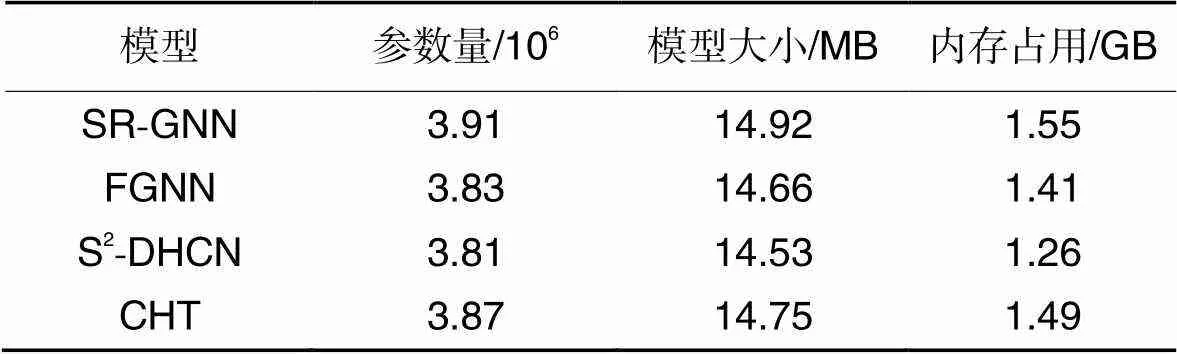
Tab.5 Parameter number analysis of models
4 结语
为解决会话推荐存在的问题,本文提出了一种新的基于对比超图转换器的会话推荐模型。该模型不仅通过超图转换器提高了基于图的会话推荐对噪声扰动的鲁棒性,还通过全局会话表示和局部会话表示设计了辅助任务以产生自监督信号进行对比学习,增强了模型对会话数据提取的能力,有效缓解了数据稀疏性对推荐性能的影响。CHT模型主要考虑推荐准确度,较少关注推荐效率。下一步我们将从轻量化的角度,将知识蒸馏技术[20]融入CHT模型以实现高效的推荐性能,从而提升它推荐的实时效率。
[1] WANG S, CAO L, WANG Y, et al. A survey on session-based recommender systems[J]. ACM Computing Surveys, 2022, 54(7): No.154.
[2] 党伟超,姚志宇,白尚旺,等. 基于图模型和注意力模型的会话推荐方法[J]. 计算机应用, 2022, 42(11):3610-3616.(DANG W C, YAO Z Y, BAI S W, et al. Session recommendation method based on graph model and attention model [J]. Journal of Computer Applications, 2022,42(11): 3610-3616.)
[3] 南宁,杨程屹,武志昊. 基于多图神经网络的会话感知推荐模型[J]. 计算机应用, 2021, 41(2):330-336.(NAN N, YANG C Y, WU Z H. Multi-graph neural network-based session perception recommendation model[J]. Journal of Computer Applications, 2021, 41(2):330-336.)
[4] SARWAR B, KARYPIS G, KONSTAN J, et al. Item-based collaborative filtering recommendation algorithms[C]// Proceedings of the 10th International Conference on World Wide Web. New York: ACM, 2001: 285-295.
[5] FENG S, LI X, ZENG Y, et al. Personalized ranking metric embedding for next new POI recommendation[C]// Proceedings of the 24th International Joint Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2015: 2069-2075.
[6] MOBASHER B, DAI H, LUO T, et al. Using sequential and non-sequential patterns in predictive Web usage mining tasks[C]// Proceedings of the 2002 IEEE International Conference on Data Mining. Piscataway: IEEE, 2002: 669-672.
[7] ZHAN Z, ZHONG L, LIN J, et al. Sequence-aware similarity learning for next-item recommendation[J]. The Journal of Supercomputing, 2021, 77(7): 7509-7534.
[8] HIDASI B, KARATZOGLOU A. Recurrent neural networks with top-gains for session-based recommendations[C]// Proceedings of the 27th ACM International Conference on Information and Knowledge Management. New York: ACM, 2018: 843-852.
[9] LI J, REN P, CHEN Z, et al. Neural attentive session-based recommendation[C]// Proceedings of the 2017 ACM Conference on Information and Knowledge Management. New York: ACM, 2017: 1419-1428.
[10] LIU Q, ZENG Y, MOKHOSI R, et al. STAMP: short-term attention/memory priority model for session-based recommendation[C]// Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2018: 1831-1839.
[11] WU S, TANG Y, ZHU Y, et al. Session-based recommendation with graph neural networks[C]// Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2019: 346-353.
[12] QIU R, LI J, HUANG Z, et al. Rethinking the item order in session-based recommendation with graph neural networks[C]// Proceedings of the 28th ACM International Conference on Information and Knowledge Management. New York: ACM, 2019: 579-588.
[13] FENG Y, YOU H, ZHANG Z, et al. Hypergraph neural networks[C]// Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2019: 3558-3565.
[14] YADATI N, NIMISHAKAVI M, YADAV P, et al. HyperGCN: a new method for training graph convolutional networks on hypergraphs [C]// Proceedings of the 33rd International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2019: 1511-1522.
[15] XIA X, YIN H, YU J, et al. Self-supervised hypergraph convolutional networks for session-based recommendation[C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2021: 4503-4511.
[16] ZHOU K, WANG H, ZHAO W X, et al. S3-Rec: self-supervised learning for sequential recommendation with mutual information maximization[C]// Proceedings of the 29th ACM International Conference on Information and Knowledge Management. New York: ACM, 2020: 1893-1902.
[17] HWANG D, PARK J, KWON S, et al. Self-supervised auxiliary learning with meta-paths for heterogeneous graphs[C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2020: 10294-10305.
[18] WU J, WANG X, FENG F, et al. Self-supervised graph learning for recommendation[C]// Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2021: 726-735.
[19] ZANGERLE E, PICHL M, GASSLER W, et al. #nowplaying music dataset: extracting listening behavior from Twitter[C]// Proceedings of the 1st International Workshop on Internet-Scale Multimedia Management. New York: ACM, 2014: 21-26.
[20] WU X, HE R, HU Y, et al. Learning an evolutionary embedding via massive knowledge distillation[J]. International Journal of Computer Vision, 2020, 128(8/9): 2089-2106.
Contrastive hypergraph transformer for session-based recommendation
DANG Weichao, CHENG Bingyang*, GAO Gaimei, LIU Chunxia
(,,030024,)
A Contrastive Hypergraph Transformer for session-based recommendation (CHT) model was proposed to address the problems of noise interference and sample sparsity in the session-based recommendation itself. Firstly, the session sequence was modeled as a hypergraph. Secondly, the global context information and local context information of items were constructed by the hypergraph transformer. Finally, the Item-Level (I-L) encoder and Session-Level (S-L) encoder were used on global relationship learning to capture different levels of item embeddings, the information fusion module was used to fuse item embedding and reverse position embedding, and the global session representation was obtained by the soft attention module while the local session representation was generated with the help of the weight line graph convolutional network on local relationship learning. In addition, a contrastive learning paradigm was introduced to maximize the mutual information between the global and local session representations to improve the recommendation performance. Experimental results on several real datasets show that the recommendation performance of CHT model is better than that of the current mainstream models. Compared with the suboptimal model S2-DHCN (Self-Supervised Hypergraph Convolutional Networks), the proposed model has the P@20 of 35.61% and MRR@20 of 17.11% on Tmall dataset, which are improved by 13.34% and 13.69% respectively; the P@20 reached 54.07% and MRR@20 reached 18.59% on Diginetica dataset, which are improved by 0.76% and 0.43% respectively; verifying the effectiveness of the proposed model.
session-based recommendation; hypergraph transformer; contrastive learning; attention mechanism
This work is partially supported by Doctoral Research Start-up Fund of Taiyuan University of Science and Technology (20202063), Graduate Education Innovation Project of Taiyuan University of Science and Technology (SY2022063).
DANG Weichao, born in 1974, Ph. D., associate professor. His research interests include intelligent computing, software reliability.
CHENG Bingyang, born in 1996, M. S. candidate. His research interests include recommendation system.
GAO Gaimei, born in 1978, Ph. D., associate professor. Her research interests include network security, cryptography.
LIU Chunxia, born in 1977, M. S., associate professor. Her research interests include software engineering, database.
TP391.4
A
1001-9081(2023)12-3683-06
10.11772/j.issn.1001-9081.2022111654
2022⁃11⁃04;
2023⁃05⁃26;
2023⁃05⁃29。
太原科技大学博士科研启动基金资助项目(20202063);太原科技大学研究生教育创新项目(SY2022063)。
党伟超(1974—),男,山西运城人,副教授,博士,CCF会员,主要研究方向:智能计算、软件可靠性;程炳阳(1996—),男,河南商丘人,硕士研究生,主要研究方向:推荐系统;高改梅(1978—),女,山西吕梁人,副教授,博士,CCF会员,主要研究方向:网络安全、密码学;刘春霞(1977—),女,山西大同人,副教授,硕士,CCF会员,主要研究方向:软件工程、数据库。
猜你喜欢
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
成都信息工程大学学报(2018年3期)2018-08-29
数学物理学报(2017年5期)2017-11-23
疯狂英语(双语世界)(2017年4期)2017-04-28
电子设计工程(2017年20期)2017-02-10
海外华文教育(2016年3期)2017-01-20
电子器件(2015年5期)2015-12-29
电测与仪表(2014年13期)2014-04-04
山西大同大学学报(社会科学版)(2014年5期)2014-01-23
