
基于语义引导自注意力网络的换衣行人重识别模型
2024-01-09 02:45:02钟建华邱创一巢建树明瑞成钟剑锋
计算机应用 2023年12期
钟建华,邱创一,巢建树,明瑞成,钟剑锋*
基于语义引导自注意力网络的换衣行人重识别模型
钟建华1,邱创一1,2,巢建树2,明瑞成2,钟剑锋1*
(1.福州大学 先进制造学院,福建 泉州 362000; 2.中国科学院海西研究院 泉州装备制造研究中心,福建 泉州 362000)(∗通信作者电子邮箱 zhongjianfeng@fzu.edu.cn)
针对换衣行人重识别(ReID)任务中有效信息提取困难的问题,提出一种基于语义引导自注意力网络的换衣ReID模型。首先,利用语义信息将图像分割出无服装图像,和原始图像一起输入双分支多头自注意力网络进行计算,分别得到衣物无关特征和完整行人特征。其次,利用全局特征重建模块(GFR),重建两种全局特征,得到的新特征中服装区域包含换衣任务中鲁棒性更好的头部特征,使得全局特征中的显著性信息更突出;利用局部特征重组重建模块(LFRR),在完整图像特征和无服装图像特征中提取头部和鞋部局部特征,强调头部和鞋部特征的细节信息,并减少换鞋造成的干扰。最后,除了使用行人重识别中常用的身份损失和三元组损失,提出特征拉近损失(FPL),拉近局部与全局特征、完整图像特征与无服装图像特征之间的距离。在PRCC(Person ReID under moderate Clothing Change)和VC-Clothes(Virtually Changing-Clothes)数据集上,与基于衣物对抗损失(CAL)模型相比,所提模型的平均精确率均值(mAP)分别提升了4.6和0.9个百分点;在Celeb-reID和Celeb-reID-light数据集上,与联合损失胶囊网络(JLCN)模型相比,所提模型的mAP分别提升了0.2和 5.0个百分点。实验结果表明,所提模型在换衣场景中突出有效信息表达方面具有一定优势。
换衣行人重识别;多头自注意力网络;语义分割;特征重建;特征重组
0 引言
行人重识别(person Re-IDentification, ReID)是在跨摄像头情况下,对不同摄像头拍摄的同一行人进行重新识别[1]。目前在常规ReID任务中,检测识别的精度已经取得了较大的进步。但是在现实生活中,通常会发生行人更换衣服的情况,例如在犯罪场景中,犯罪分子在摄像头无法拍摄的区域可能会通过换衣躲避监管部门的追查[2];或者在长达数天的ReID任务中,行人换衣的情况是通常发生的。如果按照现有的常规ReID方法进行换衣情况下的ReID,行人被正确识别的难度大幅增加。因此,换衣ReID的研究具有实际意义。
现有的常规ReID目的是充分学习并利用行人图像的各种有效特征信息。文献[3]中提出的强壮骨干网络仅使用全局特征提取行人信息,添加随机擦除[4]等方法更有效地提取信息;文献[5]中提出分块特征提取网络PCB(Part-based Convolutional Baseline),证明图像的局部特征在ReID任务中比全局特征包含更多的细节信息;文献[6]中提出的多粒度网络(Multiple Granularity Network, MGN)结合全局和局部特征,进一步提高模型性能;文献[7]中提出使用局部灰度域得到更稳健的特征。
对比常规ReID任务,换衣ReID的挑战在于ReID中最大的识别区域(即上衣与裤子)是正确识别目标行人的阻碍。目前,研究人员已经在换衣ReID任务领域取得了较多成果:文献[8]中在换衣ReID胶囊网络(Capsule network for cloth-changing ReID, ReIDCaps)[9]上添加标签平滑的交叉熵损失与圆损失(circle loss)[10],提高模型的性能;文献[2]中提出将行人轮廓进行空间极性变换(Spatial Polar Transformation, SPT)后输入神经网络,保证最大区分不同行人的身材轮廓,并且避免了衣物颜色信息的导入;文献[11]中使用单张图像的相邻图像设置步态信息,并结合步态信息和色彩(Red, Green and Blue, RGB)信息输出行人特征;文献[12]中提出结合RGB信息和三维行人体态信息的双流网络提升对衣物纹理与颜色的鲁棒性,使用对抗网络生成ReID数据集中缺失的三维人体模型;文献[13]中提出结合图像的RGB信息和行人轮廓信息的双流网络,设计损失函数纠正额外模型分割的轮廓信息;文献[14]中提出多正类分类损失与衣服信息损失进行对抗学习,通过多正类分类损失使网络在衣物区域更多地学习行人的体态特征。
现有的换衣ReID模型大多基于卷积神经网络(Convolutional Neural Network, CNN)的骨架网络,但是:1)由于CNN的局部依赖性[15],网络的注意力大多集中在较小的判别区域;2)CNN在缩小模型规模时不可避免地使用降采样操作[16-18],容易在网络的传播中丢失细节信息,而细节信息对于换衣任务中的有效信息区域相较于常规ReID任务更重要。这两个缺点导致基于CNN的模型判别条件苛刻,换衣任务精度难以提升。多头自注意力网络[15]能够更有效地捕捉长期依赖关系,因此能够充分利用全局特征,并且因为无下采样操作,能够保留更多的细节信息。此外,现有的换衣ReID模型主要使用轮廓信息或者身体姿态等辅助学习原图像,没有充分挖掘图像RGB信息,也没有对换衣任务中的特征进行进一步处理。
因此本文提出基于语义引导自注意力网络的换衣ReID模型。通过语义信息引导双分支网络,将完整图像与无服装图像输入网络,保证网络能学习完整的行人特征和避免衣服干扰的行人特征;利用多头自注意力网络提取更丰富的细节信息,并能更有效地获得全局信息;同时,提出全局特征重建模块(Global Feature Reconstruction module, GFR)在换衣任务中强调显著性信息,使网络对图像的关注区域更全面;提出局部特征重组重建模块(Local Feature Reorganization and Reconstruction module, LFRR),以输出换衣任务中干扰较少的头部和鞋部特征,并将它们进行重组重建,提高模型的鲁棒性;最后,提出特征拉近损失(Feature Pull Loss, FPL),拉近两个全局特征之间的距离,拉近全局与局部特征之间的距离,进一步强调显著性信息,从而提升换衣ReID模型的准确性。
1 本文模型
本文模型的整体框架如图1所示。
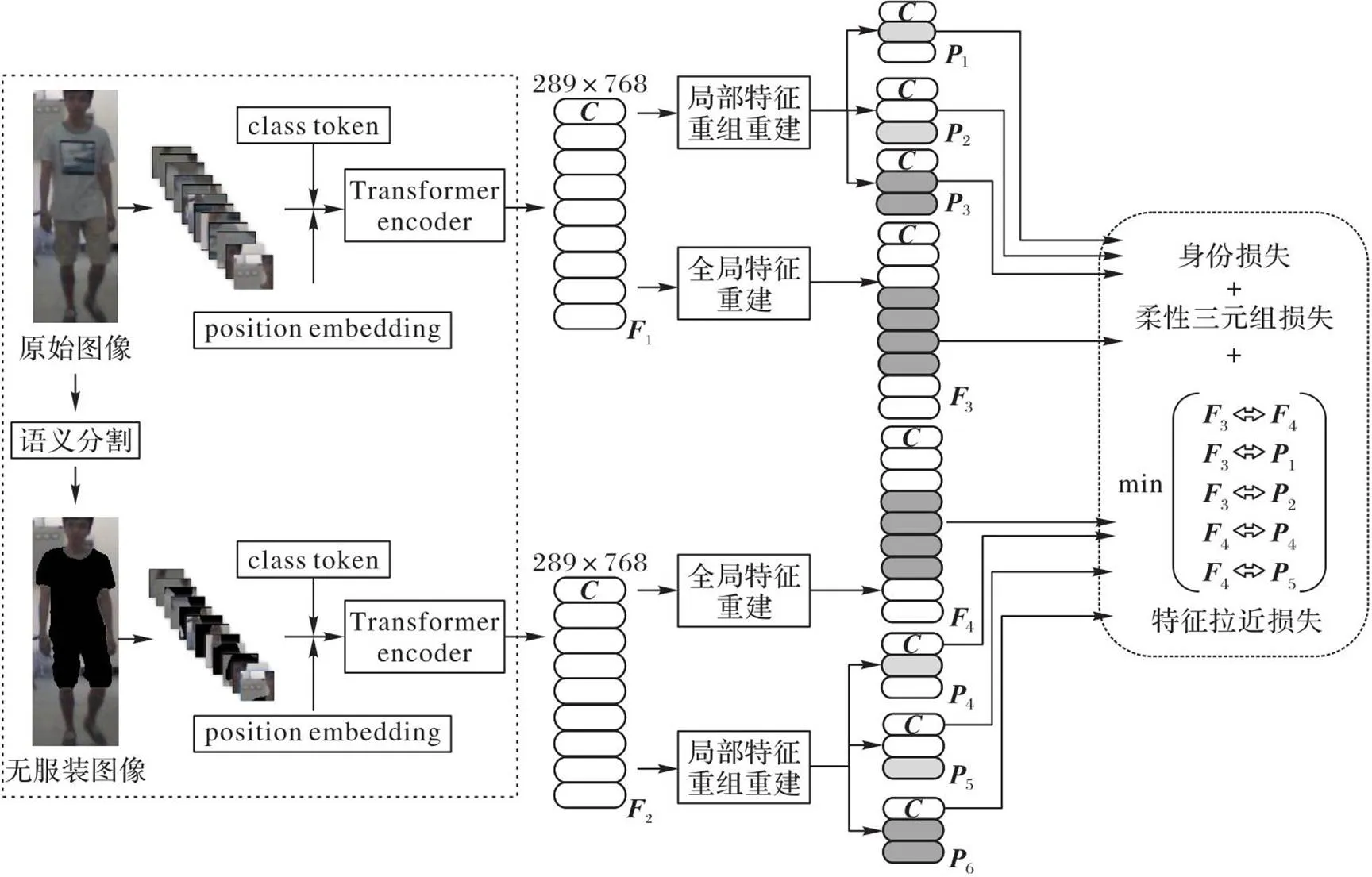
图1 本文模型的整体框架
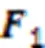
1.1 训练流程策略
本文模型的训练流程如图2所示。首先对原始图像做语义分割得到无衣物信息的行人图像,将原始图像和无服装图像输入双分支多头自注意力网络进行训练,原始图像分支学习行人的完整信息,无服装图像分支学习排除了服装干扰的行人信息。
在多头自注意力网络的训练中,两类图像被分别分割为大小一致的块输入网络,并将块拉伸成向量序列。在输入的向量序列前,添加一个额外的可学习的分类标志(class token)向量作为模型的分类预测。为了表示每个块在图像中的顺序,在每个向量序列前添加位置嵌入(position embedding)。将向量序列输入Transformer编码器,使用多层多头自注意力网络提取特征。
在多头自注意力网络的最后一层自注意力模块前分别进行全局特征重建和局部特征重组重建:全局特征融合头部特征和行人的服装特征,突出显著性信息的同时不丢弃辅助信息;局部特征重组重建操作将图像分块,取出换衣任务中显著的头部和鞋部特征,并将两种局部特征进行重组重建,增强模型的鲁棒性。
最后通过损失函数进行迭代更新,除了常用的身份损失和柔性三元组损失,提出FPL,拉近两个全局特征之间的距离,在全局特征中强调非服装等无干扰信息,同时拉近全局与局部特征之间的距离,使用局部特征突出全局特征中的细节信息,提高网络在服装变化情况的鲁棒性。
图2 本文模型的训练流程
1.2 语义引导多头自注意力网络结构
换衣ReID任务中,由于服装对网络造成干扰,因此提出语义信息引导网络结构,使用语义分割将原始图像分成服装信息和非服装信息两个类别,剔除服装信息得到无服装图像。考虑到实际情况中模型不只对换衣任务进行ReID,仍然有大量非换衣的常规情况,因此保留原始图像,将无服装图像和原图像输入双分支网络进行训练。骨干网络选择多头自注意力网络,是因为相较于CNN,多头自注意力网络没有池化等操作,能保留更多细节信息;同时由于网络的自注意力结构,每个局部块都有全局的感受野,像素距离较远的头部和鞋部同样有紧密的相互关系,能更好地捕获远程依赖性。
1.3 GFR
多头自注意力网络能够更有效地利用全局特征,在换衣ReID任务中,行人服装会发生变化,而行人的脸部信息通常变化较少,网络对于头部的关注度大于身体部位,因此把头部信息作为在全局特征中的显著性信息进行强化。在全局特征处理中,本文模型没有丢弃躯干区域的服装信息,而是把它与同区域的身材、手臂饰品等作为对于换衣情况下的辅助信息输入网络,因此提出GFR,如图3所示。
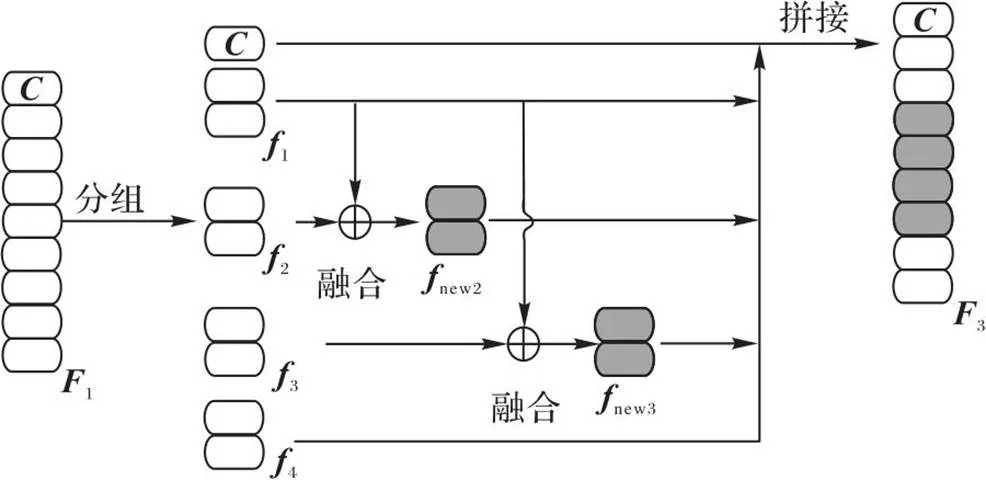
图3 全局特征重建模块
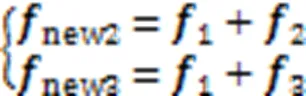
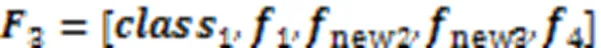
1.4 LFRR
在ReID任务中,局部特征相较于全局特征能够更有效地反映行人细节信息[5];但在换衣情况中,服装部分的局部信息容易导致判别失误,于是提出LFRR。在局部特征中只使用图像的头部和鞋部特征,头部特征最显著,在长时间的ReID中,鞋子在换衣任务中不经常替换,因此鞋子也是识别换衣行人重要的特征,所以选择头部和鞋部特征作为模型的局部特征进行输出,但由于长时间的ReID中,鞋子依然有替换的可能,因此进行局部特征重组重建,降低鞋子替换对网络造成的干扰,LFRR如图4所示。
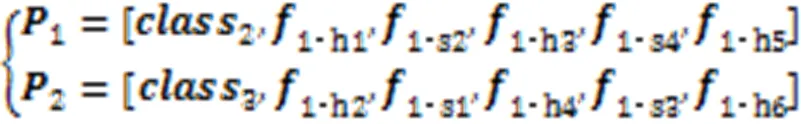
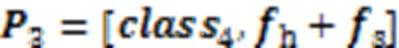
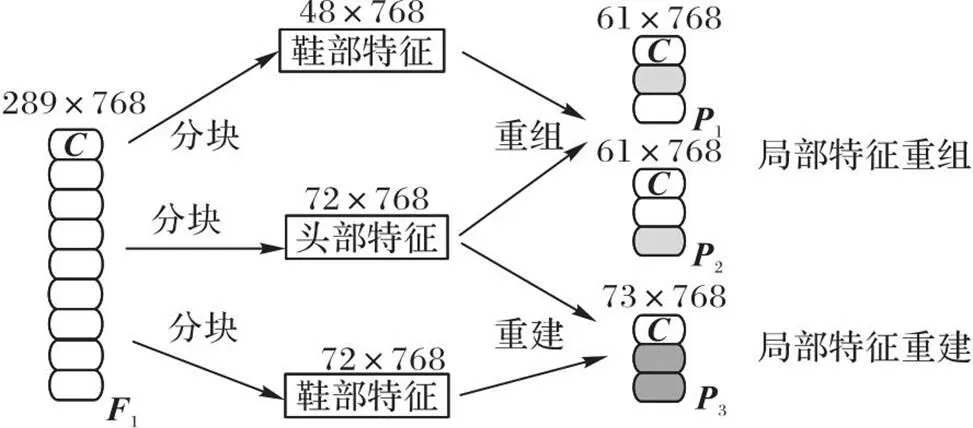
图4 局部特征重组重建模块
1.5 损失函数
本文模型在训练阶段使用了3种损失函数,包括:身份损失[19]、柔性三元组损失[20]和FPL函数。
身份损失函数是基于模型预测身份和行人身份标签间的交叉熵,计算公式如式(5)所示:
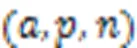
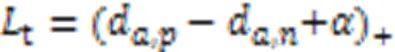

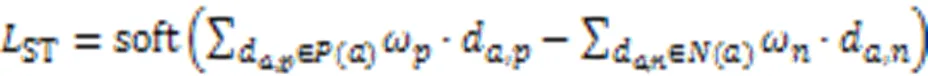
同时由于换衣情况下服装是干扰信息,非换衣情况下服装是正确识别信息,导致网络注意力并没有完全集中在非服装区域,在换衣情况下鲁棒性不强,因此需要加强非服装方面的特征表示。本文提出FPL函数,以强调在换衣任务中的有效信息,拉近局部和全局特征使得网络注意力集中在重组后的头部和鞋部信息,拉近完整图像全局特征和无服装图像全局特征使得网络注意力集中在非服装信息。FPL计算公式如式(8)(9)所示。式(8)表示拉近完整图像全局特征和无服装图像全局特征的损失函数,式(9)表示拉近全局与局部特征的损失函数:
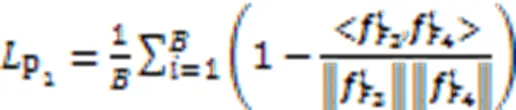
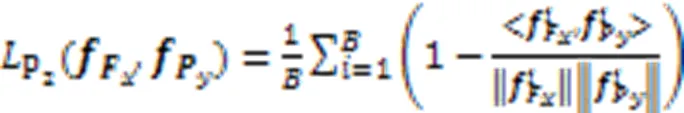
本文使用上述3种损失联合训练。为了避免3种损失函数收敛时振荡[3],在身份损失前添加归一化层[23]。整体网络模型的损失函数包括对全局和局部特征的身份损失和三元组损失收敛,完整全局特征和无服装全局特征的拉近损失收敛,全局和局部特征的拉近损失收敛,如式(10)所示:
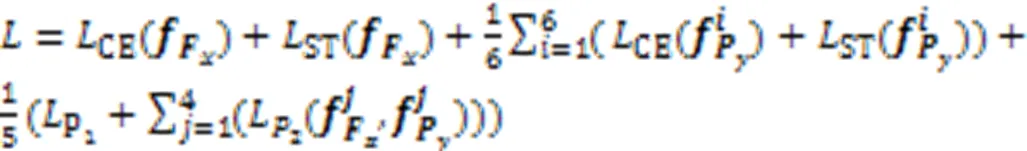
2 实验与结果分析
2.1 数据集与评价指标
为验证本文模型的有效性,在PRCC (Person ReID under moderate Clothing Change)[2]、VC-Clothes (Virtually Changing-Clothes)[24]、Celeb-reID (Celebrities re-IDentification)[9]和Celeb-reID-light (light version of Celebrities re-IDentification)[9]这4个公开换衣ReID数据集上进行换衣情况测试。
PRCC数据集包含221个行人,共有33 698张行人图像,由3个不同角度相机拍摄组成,相机A和B中每个人穿着相同的衣服,相机C中的行人穿着不同的衣服。训练集包含150个行人,图像张数为17 896。测试集中共有71个行人,图像张数为3 384。查询集中相同服装的有71个行人,3 543张图像;换衣情况的有71个行人,3 873张图像。
VC-Clothes数据集是虚拟数据集,包含512个行人,共有19 060张行人图像,4个相机视角拍摄组成,相机2和相机3的行人不换衣,相机3和相机4的行人换衣。训练集包含256个行人,9 449张图像;测试集包含256个行人,8 591张图像;查询集包含256个行人,1 020张图像。
Celeb-reID和Celeb-reID-light是最早针对换衣ReID提出的数据集之一,其中Celeb-reID-light是Celeb-reID的子集,两个数据集并没有严格地区分换衣和非换衣的情况。在Celeb-reID数据集上:训练集包含632个行人,20 208张图像;测试集包含420个行人,11 006张图像;查询集包含420个行人,2 972张图像。在Celeb-reID-light数据集上:训练集包含490个行人,9 021张图像;测试集包含100个行人,934张图像;查询集包含100个行人,887张图像。
为了评估模型的有效性,评价指标采用ReID中常用的累计匹配特征(Cumulative Matching Characteristic, CMC)曲线和平均精确率均值(mean Average Precision, mAP)。累计匹配特性曲线表示搜索结果前张图像中有正确结果的概率,其中Rank-1表示搜索结果置信度最高的图像有正确结果的概率,Rank-5表示搜索结果置信度排行前5的图像中有正确结果的概率,Rank-10表示所搜结果置信度排行前10的图像中有正确结果的概率。mAP表示正确结果排序靠前的程度,体现整体多张图像的检索性能。
2.2 实验设置
本文的实验采用Ubuntu 20.04操作系统,深度学习框架为PyTorch 1.9.0,编程语言版本为Python 3.7,硬件基础为V100 GPU。
本文实验的骨干网络为多头自注意力网络,初始权重在ImageNet-21K上预先训练,然后在ImageNet-1K上进行网络调整。图像的大小统一调整为384×192,使用随机水平翻转、填充、随机裁剪和随机擦除[4]的数据增强方法对图像进行预处理。本文选择的语义分割方法为LIP (Look Into Person)数据集[25]预先训练的自我纠错人体解析(Self Correction Human Parsing, SCHP)模型[26]。批量大小为64,每个行人在一批次中有8张图像,初始化为0.003 5,使用余弦学习率衰减学习率,采用随机梯度下降法(Stochastic Gradient Descent, SGD)优化模型,迭代次数为60。在此,将本文模型简称为SGSNet(Semantic-Guided Self-attention Network)。
2.3 结果与分析
2.3.1消融实验
验证模型的各个模块在换衣ReID任务中的有效性,在PRCC数据集上的消融实验结果如表1所示。其中,使用多头自注意力网络做基准网络(Baseline),语义引导网络结构(Semantic Guidance Network structure, SGN)、全局特征重建模块(GFR)、局部特征重组重建模块(LFRR)和特征拉近损失(FPL)在表1中都用缩略语表示。消融实验部分验证提出的不同模块在换衣场景下ReID情况的有效性。
从表1可以看出,在PRCC数据集换衣情况使用语义引导多头自注意力网络对性能有较大提升,相较于只使用多头自注意力网络(Baseline),Rank-1和mAP分别提升了6.7和7.1个百分点,这是因为新增的语义引导网络分支使用的图像经过语义分割去除了衣服的干扰,使得网络可以独立学习换衣情况下的无服装信息,精度的提升表明使用语义信息引导网络发挥了作用。
表1在PRCC数据集上的消融实验结果 单位: %
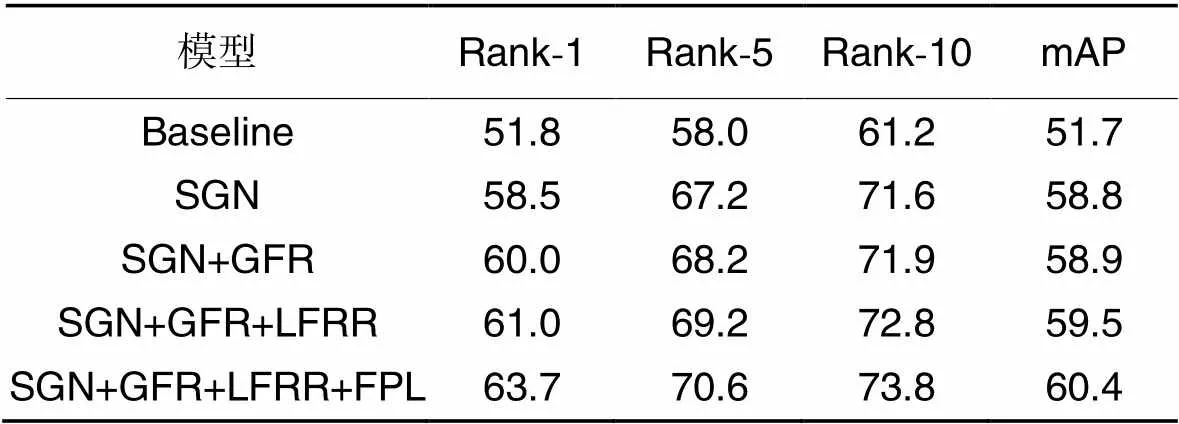
Tab.1 Ablation experimental results on PRCC dataset unit: %
在SGN的基础上,添加GFR,通过分块、融合和拼接的方式,强调了换衣任务中显著的头部信息,弱化了服装信息,降低了换衣情况下的噪声干扰,同时又保留了服装同区域的体态信息作为辅助信息输入。添加GFR后,Rank-1和mAP分别提升了1.5和0.1个百分点,结果表明GFR是在换衣情况下是有效的。
在添加LFRR的测试中,通过分块、重组重建操作,提取在换衣任务中更有效的头部和鞋部特征,重组重建两种局部特征,突出了头部和鞋部的细节信息。在添加LFRR后,Rank-1和mAP分别提升了1.0和0.6个百分点,结果表明LFRR能够强调有效细节信息,提高模型鲁棒性。
最后添加FPL,拉近全局与局部特征之间的距离,拉近完整图像全局特征与无服装图像全局特征之间的距离,Rank-1和mAP分别提升了2.7和0.9个百分点,精度的提升表明同时使用两种FPL在换衣情况下是有效的。
2.3.2特征重组重建模块实验
本节对特征重组重建模块进行测试,提出特征平均分块、特征重组重建模块两种策略进行测试。特征平均分块指对图像横向平均分块成4份,分成4份局部特征,包含对服装特征的输出。LFRR即本文模型的模块,将头部特征与鞋部特征进行重新组合。使用PRCC数据集进行测试,性能比较如表2所示。

表2 特征平均分块和特征重组重建模块在 PRCC数据集上的性能比较 单位:%
在表2的对比中,特征重组重建模块效果相较于特征平均分块的Rank-1提升了0.8个百分点,表明特征重组重建模块能够有效提高模型的鲁棒性,弱化服装信息,减少换鞋情况时单独输出鞋部局部特征的干扰。
2.3.3FPL实验
本文对不同的FPL函数策略进行测试,包括模型中不使用FPL(No FPL)、仅对局部和全局特征之间使用FPL(FPL between Local features and Global features, FPL-LG)、仅对两种全局特征之间使用FPL(FPL between Two Global features, FPL-TG)、本文设置的使用两种FPL结合(用FPL表示)。使用PRCC数据集进行测试,性能对比如表3所示。
在表3中,仅在局部与全局特征中使用FPL,相较于没有使用FPL,Rank-1和mAP分别提升了0.8和0.2个百分点,说明拉近局部和全局特征距离能够使网络更有效关注显著性特征的细节信息。仅在两种全局特征中使用FPL函数,相较于没有使用FPL,Rank-1提升了2.3个百分点,mAP基本不变,原因是拉近两者特征减弱了两条分支中服装的关注程度,减小了图像中的干扰因素。使用本文提出的FPL,相较于没有使用FPL,Rank-1和mAP分别提升了2.7和0.9个百分点,局部与全局特征中使用FPL稳定全局特征的注意力,并在全局特征中强调局部特征中的细节信息,两种全局特征之间使用FPL,突出显著特征,降低了干扰,两者叠加提高了模型的精度。
表3不同特征拉近损失函数策略在PRCC数据集的性能比较 单位:%
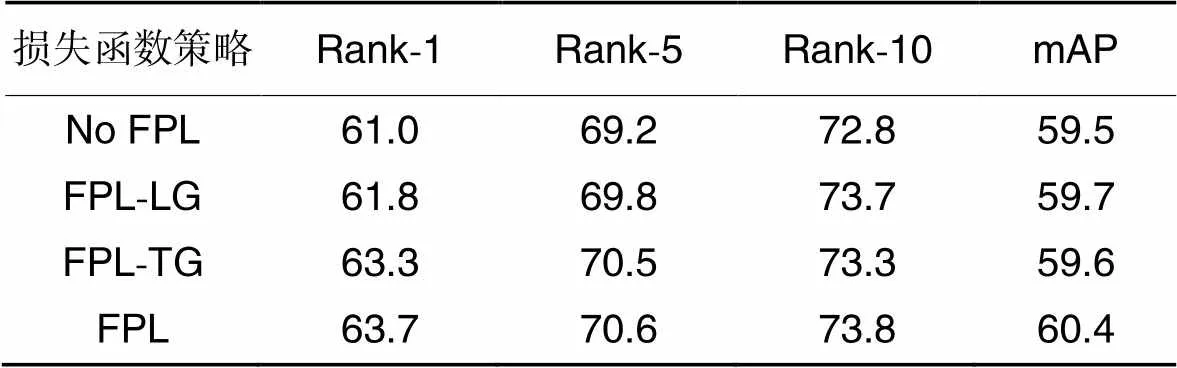
Tab.3 Performance comparison of different FPL function strategies on PRCC dataset unit: %
2.3.4与现有方法比较
为了验证本文解决方案的有效性,在PRCC、VC-Clothes、Celeb-reID和Celeb-reID-light这4个换衣ReID数据集上与目前先进的换衣ReID方法进行比较。用Rank-1和mAP作为评价指标。在PRCC和VC-Clothes数据集上的性能比较结果如表4所示,在Celeb-reID和Celeb-reID-light的性能比较结果如表5所示。
表4不同方法在PRCC和VC-Clothes数据集上的性能比较 单位:%
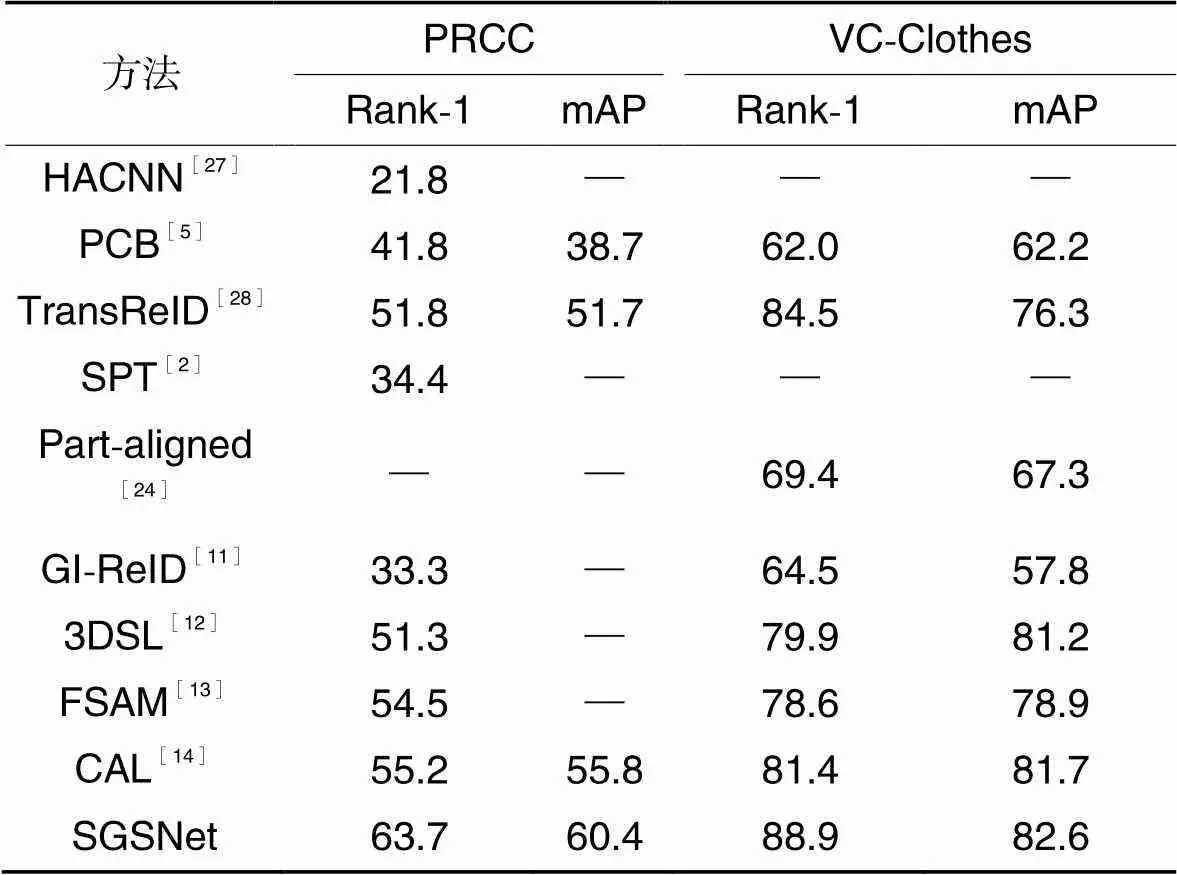
Tab.4 Performance comparison of different methods on PRCC and VC-Clothes datasets unit:%
注:“―”表示原文献中没有该项实验结果。
和谐注意力卷积神经网络(Harmonious Attention Convolutional Neural Network,HACNN)[27]、PCB[5]和基于Transformer网络的物体重识别(Transformer-based object Re-Identification, TransReID)[28]是近年来具有代表性的常规ReID方法;SPT[2]和局部对齐(Part-aligned)网络[24]是分别提出PRCC和VC-Clothes两个换衣ReID数据集的方法;步态识别驱动图像ReID(Gait recognition to drive the Image ReID, GI-ReID)[11]、三维形态学习(3D Shape Learning, 3DSL)[12]、细粒度形状外观互相作用学习框架(Fine-grained Shape-Appearance Mutual learning framework, FSAM)[13]和基于衣物对抗损失(Clothes-based Adversarial Loss, CAL)模型[14]是近年来具有代表性的换衣ReID方法。在表4中,本文模型在换衣场景,PRCC数据集中Rank-1和mAP分别达到63.7%和60.4%,VC-Clothes数据集中Rank-1和mAP分别达到了88.9%和82.6%。在PRCC数据集和VC-Clothes数据集中,相较于CAL,文本模型的mAP分别提升了4.6和0.9个百分点;相较于其他对比ReID方法,本文模型表现优秀,精度有一定的提升。
如表5所示,在Celeb-reID和Celeb-reID-light换衣数据集上,选取HACNN[27]、PCB[5]、MGN[29]这3种常规ReID方法,ReIDCaps[9]和联合损失胶囊网络(Joint Loss Capsule Network, JLCN)[8]这2种换衣ReID方法进行比较,在Celeb-reID换衣数据集上,本文模型的Rank-1和mAP分别达到53.0%和11.0%,在Celeb-reID-light换衣数据集中,Rank-1和mAP分别达到25.8%和16.1%,相较于对比的先进方法取得了优秀水平。在Celeb-reID和Celeb-reID-light数据集上,相较于JLCN模型,本文模型的mAP分别提升了0.2和5.0个百分点。因此,本文模型在换衣情况中优于其他对比ReID方法,在4个换衣ReID数据集的对比实验中验证了本文模型的有效性。
表5不同方法在Celeb-reID和Celeb-reID-light数据集上性能比较 单位:%
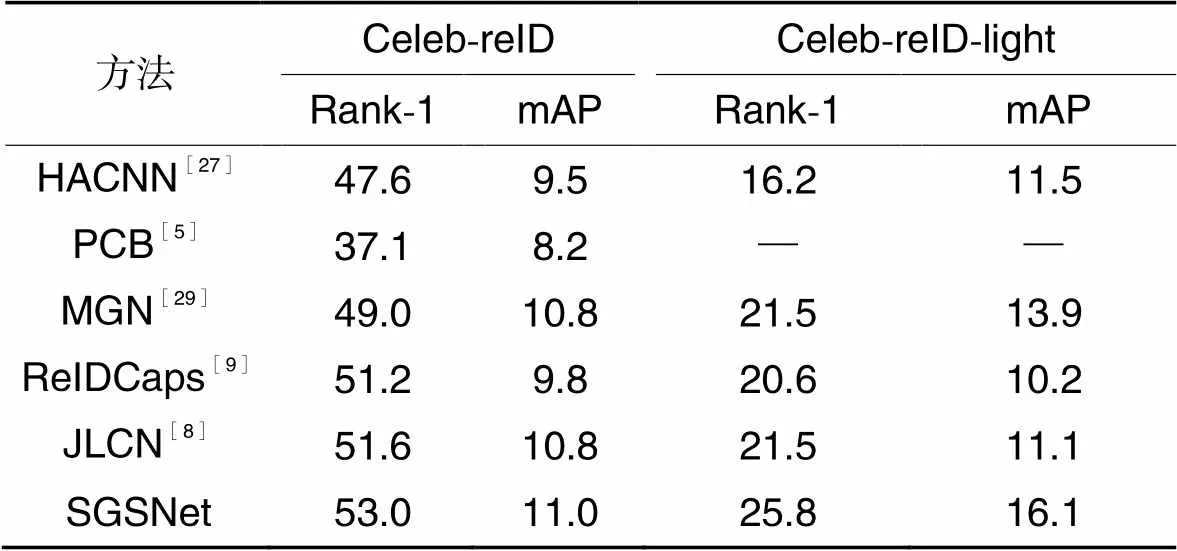
Tab.5 Performance comparison of different methods on Celeb-reID and Celeb-reID-light datasets unit:%
2.3.5可视化分析
为了验证本文模型在换衣场景中的有效性,在PRCC数据集上进行可视化排序,将Baseline模型和本文模型进行比较,分别查询Top-1~Top-5图像,选3张示意图进行对比,可视化结果如图5所示,其中query表示查询图像。
图5(a)和图5(b)中,对于Top-1~Top-5图像,Baseline模型和本文模型全部检索正确,说明自注意力网络能够提取丰富的细节信息,在换衣任务中能保持一定的准确性。图5(c)中,对于Top-1~Top-5图像,Baseline模型对Top-1、Top-2、Top-4与Top-5检索错误,本文模型只有Top-4检索错误,说明本文模型的有效性。从图5可以看出,本文模型能够有效提高检索精度。
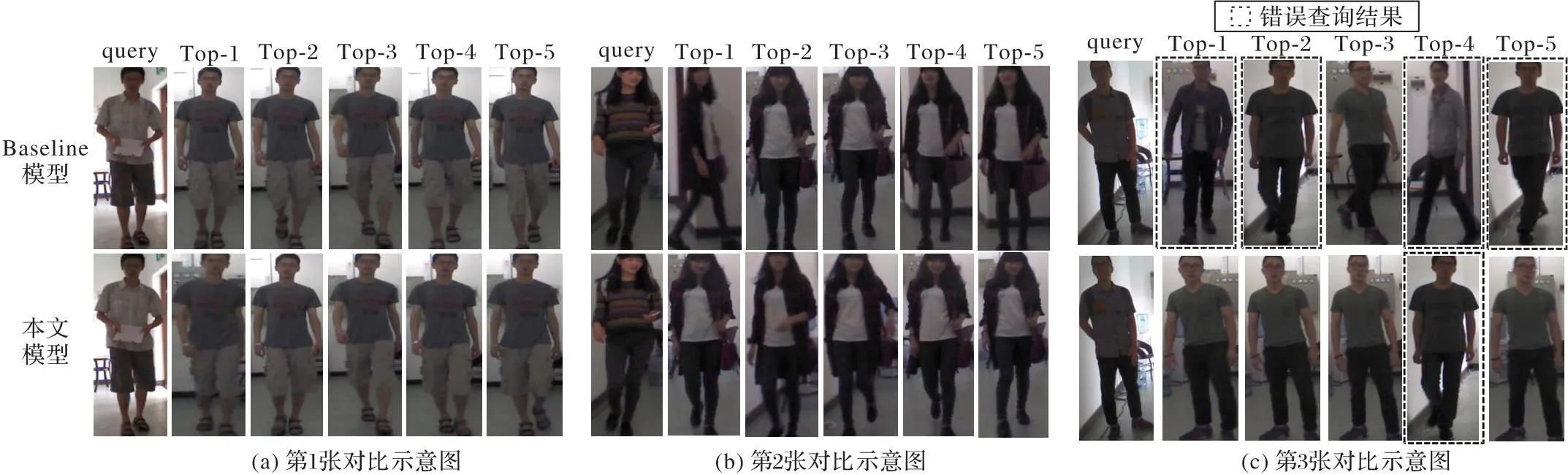
图5 使用Baseline模型与本文模型返回的前5张检索图像对比
3 结语
本文提出一种基于语义引导自注意力网络的换衣ReID模型,利用语义分割提取无服装图像,与完整图像输入双分支多头自注意力网络,提取图像的完整信息与不受服装干扰的信息。通过全局特征重建和LFRR提高显著性特征的细节信息,保留辅助信息。最后提出FPL拉近特征之间的距离,强调非干扰信息,并突出它的细节信息。实验结果表明本文模型具有一定优势,在换衣场景中有较高的鲁棒性与检索精度。接下来将研究针对复杂场景中因为语义分割误差导致的检索错误问题,进一步提高换衣任务中的模型性能。
[1] 罗浩,姜伟,范星,等.基于深度学习的行人重识别研究进展[J]. 自动化学报, 2019, 45(11): 2032-2049.(LUO H, JIANG W, FAN X, et al. A survey on deep learning based on person re-identification [J]. Acta Automatica Sinica, 2019, 45(11): 2032-2049.)
[2] YANG Q, WU A, ZHENG W-S. Person re-identification by contour sketch under moderate clothing change [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(6): 2029-2046.
[3] LUO H, JIANG W, GU Y, et al. A strong baseline and batch normalization neck for deep person re-identification [J]. IEEE Transactions on Multimedia, 2019, 22(10): 2597-2609.
[4] ZHONG Z, ZHENG L, KANG G, et al. Random erasing data augmentation [C]// Proceedings of the 2020 AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2020: 13001-13008.
[5] SUN Y, ZHENG L, YANG Y, et al. Beyond part models: person retrieval with refined part pooling (and a strong convolutional baseline)[C]// Proceedings of the 2018 European Conference on Computer Vision. Cham: Springer, 2018: 501-518.
[6] WANG G, YUAN Y, CHEN X, et al. Learning discriminative features with multiple granularities for person re-identification [C]// Proceedings of the 26th ACM International Conference on Multimedia. New York: ACM, 2018: 274-282.
[7] 龚云鹏,曾智勇,叶锋. 基于灰度域特征增强的行人重识别方法[J]. 计算机应用, 2021, 41(12): 3590-3595.(GONG Y P, ZENG Z Y, YE F. Person re-identification method based on grayscale feature enhancement [J]. Journal of Computer Applications, 2021, 41(12): 3590-3595.)
[8] 刘乾,王洪元,曹亮,等.基于联合损失胶囊网络的换衣行人重识别[J]. 计算机应用, 2021, 41(12): 3596-3601.(LIU Q,WANG H Y, CAO L, et al. Cloth-changing person re-identification based on joint loss capsule network [J]. Journal of Computer Applications, 2021, 41(12): 3596-3601.)
[9] HUANG Y, XU J, WU Q, et al. Beyond scalar neuron: adopting vector-neuron capsules for long-term person re-identification [J]. IEEE Transactions on Circuits and Systems for Video Technology, 2019, 30(10): 3459-3471.
[10] SUN Y, CHENG C, ZHANG Y, et al. Circle loss: a unified perspective of pair similarity optimization [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE , 2020: 6397-6406.
[11] JIN X, HE T, ZHENG K, et al. Cloth-changing person re-identification from a single image with gait prediction and regularization [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 14258-14267.
[12] CHEN J, JIANG X, WANG F, et al. Learning 3D shape feature for texture-insensitive person re-identification [C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 8142-8151.
[13] HONG P, WU T, WU A, et al. Fine-grained shape-appearance mutual learning for cloth-changing person re-identification [C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 10508-10517.
[14] GU X, CHANG H, MA B, et al. Clothes-changing person re-identification with RGB modality only [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 1050-1059.
[15] DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16×16 words: Transformers for image recognition at scale [EB/OL]. (2021-06-03)[2022-12-13]. https://arxiv.org/pdf/2010.11929.pdf.
[16] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [EB/OL]. (2015-04-10)[2022-12-13]. https://arxiv.org/pdf/1409.1556.pdf.
[17] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the 2016 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778.
[18] HUANG G, LIU Z, VAN DER MAATEN L, et al. Densely connected convolutional networks [C]// Proceedings of the 2017 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 2261-2269.
[19] SUN Y, ZHENG L, DENG W, et al. SVDNet for pedestrian retrieval [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2017: 3820-3828.
[20] LAWEN H, BEN-COHEN A, PROTTER M, et al. Compact network training for person ReID [C]// Proceedings of the 2020 International Conference on Multimedia Retrieval. New York: ACM, 2020: 164-171.
[21] SCHROFF F, KALENICHENKO D, PHILBIN J. FaceNet: a unified embedding for face recognition and clustering [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 815-823.
[22] HERMANS A, BEYER L, LEIBE B. In defense of the triplet loss for person re-identification [EB/OL]. (2018-03-24)[2022-12-13]. https://arxiv.org/pdf/1703.07737.pdf.
[23] IOFFE S, SZEGEDY C. Batch normalization: accelerating deep network training by reducing internal covariate shift [C]// Proceedings of the 32nd International Conference on Machine Learning. New York: ACM, 2015: 448-456.
[24] WAN F, WU Y, QIAN X, et al. When person re-identification meets changing clothes [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 3620-3628.
[25] GONG K, LIANG X, ZHANG D, et al. Look into person: self-supervised structure-sensitive learning and a new benchmark for human parsing [C]// Proceedings of the 2017 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 6757-6765.
[26] LI P, XU Y, WEI Y, et al. Self-correction for human parsing [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 44(6): 3260-3271.
[27] LI W, ZHU X, GONG S. Harmonious attention network for person re-identification [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 2285-2294.
[28] HE S, LUO H, WANG P, et al. TransReID: Transformer-based object re-identification [C]// Proceedings of the 2021 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2021: 14993-15002.
[29] WANG G, YUAN Y, CHEN X, et al. Learning discriminative features with multiple granularities for person re-identification [C]// Proceedings of the 26th ACM International Conference on Multimedia. New York: ACM, 2018: 274-282.
Cloth-changing person re-identification model based on semantic-guided self-attention network
ZHONG Jianhua1, QIU Chuangyi1,2, CHAO Jianshu2, MING Ruicheng2, ZHONG Jianfeng1*
(1,,362000,;2,,,362000,)
Focused on the difficulty of extracting effective information in the cloth-changing person Re-identification (ReID) task, a cloth-changing person re-identification model based on semantic-guided self-attention network was proposed. Firstly, semantic information was used to segment an original image into a cloth-free image. Both images were input into a two-branch multi-head self-attention network to extract cloth-independent features and complete person features, respectively. Then, a Global Feature Reconstruction module (GFR) was designed to reconstruct two global features, in which the clothing region contained head features with better robustness, which made the saliency information in the global features more prominent. And a Local Feature Reorganization and Reconstruction module (LFRR) was proposed to extract the head and shoe features from the original image and the cloth-free image, emphasizing the detailed information about the head and shoe features and reducing the interference caused by changing shoes. Finally, in addition to the identity loss and triplet loss commonly used in person re-identification, Feature Pull Loss (FPL) was proposed to close the distances among local and global features, complete image features and costume-free image features. On the PRCC (Person ReID under moderate Clothing Change) and VC-Clothes (Virtually Changing-Clothes) datasets, the mean Average Precision (mAP) of the proposed model improved by 4.6 and 0.9 percentage points respectively compared to the Clothing-based Adversarial Loss (CAL) model. On the Celeb-reID (Celebrities re-IDentification) and Celeb-reID-light (a light version of Celebrities re-IDentification) datasets, the mAP of the proposed model improved by 0.2 and 5.0 percentage points respectively compared with the Joint Loss Capsule Network (JLCN) model. The experimental results show that the proposed method has certain advantages in highlighting effective information expression in the cloth-changing scenarios.
cloth-changing person re-identification; multi-head self-attention network; semantic segmentation; feature reconstruction; feature reorganization
This work is partially supported by National Natural Science Foundation of China (52275523).
ZHONG Jianhua, born in 1985, Ph. D., associate professor. His research interests include image processing, pattern recognition.
QIU Chuangyi, born in 1998, M. S. candidate. His research interests include image processing, person re-identification.
CHAO Jianshu, born in 1984, Ph. D., research fellow. His research interests include image processing, deep learning.
MING Ruicheng, born in 1994, M. S., engineer. His research interests include image processing, deep learning.
ZHONG Jianfeng, born in 1988, Ph. D., associate professor. His research interests include structural health detection, deep learning.
TP391.41
A
1001-9081(2023)12-3719-08
10.11772/j.issn.1001-9081.2022121875
2022⁃12⁃26;
2023⁃02⁃23;
2023⁃02⁃28。
国家自然科学基金资助项目(52275523)。
钟建华(1985—),男,福建龙岩人,副教授,博士,主要研究方向:图像处理、模式识别;邱创一(1998—),男,福建福州人,硕士研究生,主要研究方向:图像处理、行人重识别;巢建树(1984—),男,江苏江阴人,研究员,博士,主要研究方向:图像处理、深度学习;明瑞成(1994—),男,湖北十堰人,工程师,硕士,主要研究方向:图像处理、深度学习;钟剑锋(1988—),男,福建龙岩人,副教授,博士,主要研究方向:结构健康检测、深度学习。
猜你喜欢
数学物理学报(2022年4期)2022-08-22 04:07:12
数学物理学报(2022年2期)2022-04-26 14:08:04
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
意林(2021年5期)2021-04-18 12:21:17
扬子江(2019年1期)2019-03-08 02:52:34
金桥(2018年4期)2018-09-26 02:24:54
传媒评论(2017年3期)2017-06-13 09:18:10
小天使·一年级语数英综合(2017年6期)2017-06-07 23:51:16
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
中国卫生(2014年5期)2014-11-10 02:11:26
