
基于改进YOLOv5 的皮革抓取点识别及定位
2024-01-08 07:47:04金光任工昌桓源洪杰
皮革科学与工程 2024年1期
金光,任工昌,桓源,洪杰
(陕西科技大学机电工程学院,陕西 西安 710021)
引言
制革行业是轻工业的重要分支,在制造业中有着不可或缺的地位[1]。然而,现阶段皮革加工过程仍需要大量人力搬运和铺展皮革,整个过程劳动强度极大,且作业环境较恶劣。为了利用机器人技术完成皮革自动化操作,Huan 等[2]设计出了一种专门用于抓取铺展皮革的机械手,可实现对皮革的各种操作。任工昌等[3]提出了一种双臂抓取铺展皮革的方法,可实现对皮革的铺展操作。由于皮革具有边缘不规则、受力易变形、弯曲遮挡等自身因素,以及加工环境中背景杂乱、光照变化等外部因素,导致机器视觉很难精确识别皮革及其抓取点。为解决上述机器视觉识别皮革过程中存在的难题。本文基于在处理复杂遮挡问题上有很大的优势的目标检测算法来实现皮革抓取点的识别与定位[4-6]。
现阶段的目标检测分为Fast Region-based Convolutional Network (FAST R-CNN)[7-9]、Single Shot MultiBox Detector(SSD)[10-13]和You Only Look Once (YOLO)[14-17]系列, 其中YOLO 系列相比于 FAST R-CNN 和SSD,其特点是运行速度快,可以实时检测目标。段洁利等人[18]提出了一种改进YOLOv5 算法,将原始的损失函数替换成EIOU Loos,加快了模型的收敛,降低了损失值;杨秋妹等人[19],通过将SE-Net 自注意力机制模块添加到骨干网络中,使模型更加关注被遮挡的目标信息,提升了模型的检测性能。Fu 等人[20]提出了一种轻量化神经网络,通过去除骨干网络的SPP 模块,简化颈部网络的卷积数,可以快速检测目标。
综上,针对皮革的自身特性以及其在加工过程中的外部环境因素,提出了一种基于改进YOLOv5的皮革抓取点的识别与定位算法。通过引入Coordinate Attention(CA)注意力机制模块到Backbone(骨干网络)中,用Focal-EIOU Loss 替换了原始算法中的CIOU Loss,以提高对皮革抓取点的识别与定位精度。最后,通过Intel RealSense D435i 深度相机对皮革抓取点进行识别定位获取其三维坐标,验证了该算法识别与定位的精度。
1 改进YOLOv5 算法
YOLOv5 包括 YOLOv5s、YOLOv5l、YOLOv5m和YOLOv5x。考虑到机器人对皮革及抓取点识别过程中的实时性和高效性,本文选择较轻量化的YOLOv5s 作为基础模型。其网络结构如图1 所示,主要分为Input(输入端),Backbone(骨干网络),Neck(颈部网络)和Prediction(预测网络)。通过引入CA 注意力机制和使用Focal-EIOU Loss 对CIOU Loss 进行替换两方面进行改进。

图1 YOLOv5s 网络结构Fig.1 Network structure of YOLOv5s
1.1 CA 注意力机制
注意力机制就是定位局部信息的机制,可以使网络聚焦于感兴趣的关键信息,忽略无用信息,从而加速计算,提升检测效率[21]。为提升目标检测的效果,本文在YOLOv5 算法中添加注意力机制,来突出皮革以及其抓取点的重要特征。采用引入CA 模块[22]到Backbone 层中,CA 模块可以同时从通道维度和空间维度上来考虑注意力,更加关注皮革抓取点的特征信息。CA 模块的结构框架如图2 所示。

图2 CA 模块Fig.2 CA Blocks
通过给定一个输入X=[x1,x2,…xC]∈RC×H×W,然后使用pooling kernel(池化核),其参数为(H,1)和(1,W),C、H、W分别为X的通道数以及输入图片的高宽,在X方向和Y方向上分别对每个通道进行编码,得到的一个输出为高度h的第c个通道,可以表示为公式(1):
同样,宽度为w的第c个通道的输出可以表示为公式(2):
将式(1)、(2)中分别生成的结果Zh、Zw进行级联,然后进行变换从而得到中间特征,如式(3):
式中δ表示非线性激活函数,f∈RC/r×(H+W)是X方向和Y方向上的中间特征图,F1表示卷积变换函数,r表示下采样率。
式(4)和(5)中σ 为sigmoid 激活函数,Fh和Fw为两个1×1 的卷积,gh∈RC/r×H和gw∈RC/r×W,是g在h维度和w维度分成的两个张量,对gh和gw进行展开,CA 模块的输出如式(6):
1.2 Focal-EIOU 损失函数
YOLOv5 的损失函数包括分类概率损失、边框回归损失以及置信度损失。YOLOv5 中的原损失函数CIOU Loss 无法返回目标框的宽高与置信度之间的不同,从而阻止了模型的优化相似性。因此本文用Focal-EIOU Loss[23]对CIOU Loss 进行替换,Focal-EIOU Loss 是EIOU Loss 和FocalL1 Loss 的整合。其中EIOU Loss 对CIOU Loss 存在的不足进行了优化,主要由重叠损失、中心距离损失和宽高损失组成,其惩罚项如式(7)所示将纵横比的影响因子分开,然后分别进行计算bounding box(目标框)和anchor box(锚框)的长和宽。
式(7)中,Cw和Ch表示覆盖Ground truth box(真实框)和Prediction box(预测框)的最小闭包区域的宽度和高度;LIOU、Ldis、和Lasp分别表示IoU损失、距离损失和边长损失;b和bgt表示预测框和真实框的中心点;ρ表示两个中心点之间的欧氏距离;c表示预测框和真实框的最小闭包矩形的对角线长度;w和wgt分别表示预测框和真实框的宽度;h和hgt分别表示预测框和真实框的高度。
为解决皮革样本质量不平衡,导致识别效果较差这一难题,引入FocalL1 Loss 来设置不同梯度,从而降低低质量样本对检测性能的影响。FocalL1 Loss借鉴了Focal Loss 的思想,用以解决样本质量不平衡的问题,其梯度如式(8):
式中β是控制曲线的弧度,α用于将梯度的值控制在[0,1],e为自然常数,x代表真实值与预测值的差值。
根据式(8) 中的导数,求其积分可以得到FocalL1 Loss,如式(9):
式(9)中C为常数。
将EIOU Loss 和FocalL1 Loss 进行整合,得到Focal-EIOU Loss,如式(10):
2 皮革及抓取点的定位
为了获取皮革及抓取点的信息,本文采用Intel RealSense D435i 深度相机,其输出的深度图像分辨率为1 280×720,可以探测的目标范围为0.1~100 m,检测帧速率最高可达90 fps,深度相机的参数如表1所示。
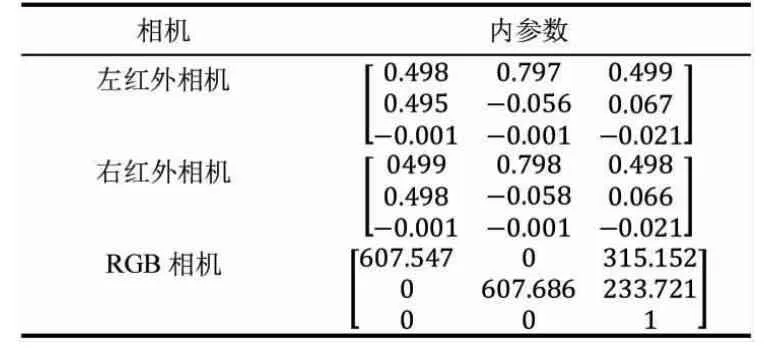
表1 Intel RealSense D435i 相机内参数Tab.1 Parameters of Intel RealSense D435i camera
2.1 目标定位原理
YOLOv5 目标边界框回归公式如式(11),用来预测边界框的宽高以及中心点。
式中,bx和by分别表示预测框的中心点,bw和bh分别表示预测框的宽与高;σ 表示Sigmoid 函数[24],tx和ty分别表示预测目标中心坐标的偏移量,tw和th分别表示预测目标的宽高的尺度缩放;(cx,cy)表示目标中心在网格中相对于图像左上角的偏移量;pw和ph和分别表示的是锚框的宽和高。
将bx、by、bw、bh分别转化成预测框左上角和右下角的坐标值,如图3 所示(x1,y1)和(x2,y2)为皮革抓取点预测框的坐标值,(x3,y3)和(x4,y4)为皮革预测框的坐标值。通过几何关系可以求出皮革抓取点的定位坐标(u1,v1)和皮革的定位坐标(u2,v2),如式(12):

图3 目标边界框和定位点回归Fig.3 Target bounding box and anchor regression
2.2 D435i 深度相机标定
通过深度相机获取皮革抓取点的信息,欲获取定位点在世界坐标系(Xw,Yw,Zw)下的三维坐标,就要获得定位点的坐标系变换关系。即如图4 所示,要考虑到定位点到相机坐标系(Xc,Yc,Zc)的变换关系、相机坐标系到图像坐标系(x,y)的变换关系和图像坐标系到像素坐标系(u,v)的变化关系。

图4 定位点坐标系转换示意图Fig.4 Schematic diagram of anchor coordinate system conversion
对于图像坐标系(x,y)和像素坐标系(u,v)之间的变换关系为式(13):
相机坐标系(Xc,Yc,Zc)和图像坐标系(x,y)之间的变换关系为式(14):
式中f表示为焦距。
世界坐标系(Xw,Yw,Zw)和相机坐标系(Xc,Yc,Zc)之间的变换关系为式(15):
式中R表示正交单位旋转矩阵,T为三维平移矩阵。
由式(13)、(14)和(15)可以得到世界坐标系和像素坐标系之间的变换关系为式(16):
式中,fx、fy、u0和v0为表1 中的相机内参数,R和T为相机的外参数。
如图5 所示,深度相机的左右两个红外相机来获取皮革的深度信息,RGB 相机获取皮革的RGB图,将深度图与RGB 图进行配准。配准后获取深度图像中皮革及抓取点的深度和RGB 图像中皮革及抓取点的定位点,然后检测到RGB 图像素坐标以及对应的深度图像素坐标,最后通过坐标转换公式(16)获得皮革及抓取点的空间坐标(x1,y1,z1)和(x2,y2,z2)。
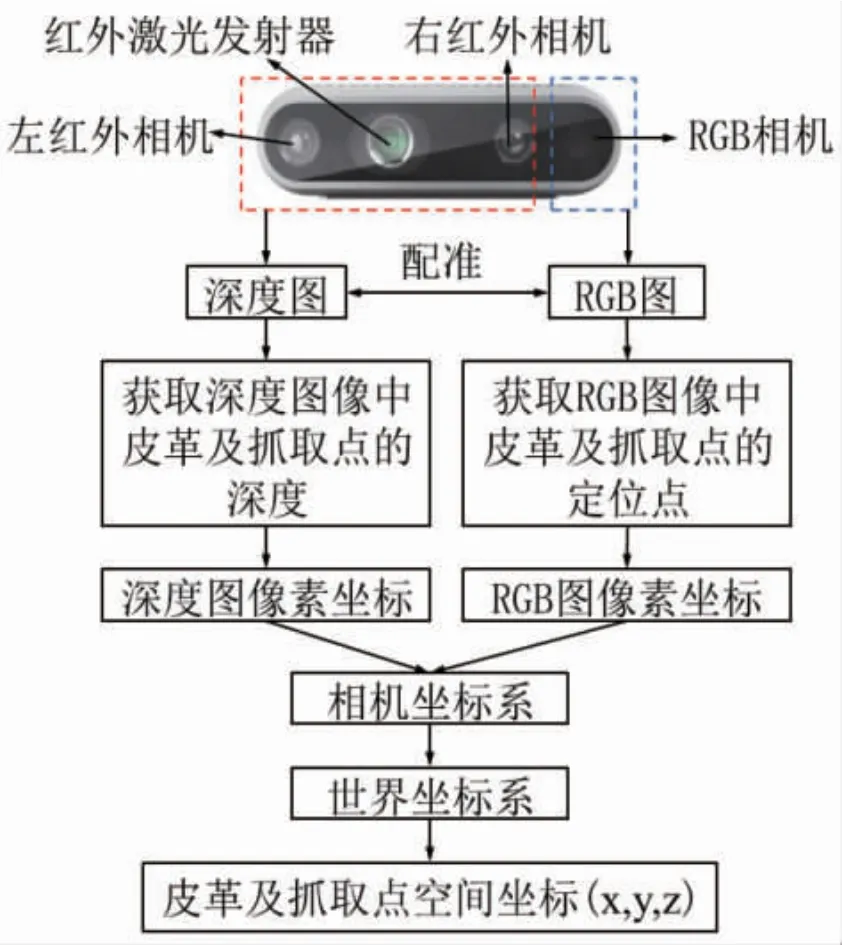
图5 相机的目标定位示意图Fig.5 Schematic diagram of camera targeting
3 实验与分析
3.1 实验数据准备
3.1.1 图像获取
该研究使用高像素的相机对皮革进行采样,考虑到皮革的非规整性、自身遮挡、背景复杂多变以及光照等因素的影响,对皮革进行室内和室外两种环境下多角度拍摄,同时对皮革进行人为遮挡拍摄。如图6 所示,根据影响因素将皮革样本分为图像遮挡,光照充足、光照不足、背景杂乱和背景纯净5 大类,共采集样本5 000 张。按照7∶3 的比例依次将样本划分到训练集和测试集的images 文件夹中。

图6 部分样本图片(a)图像遮挡,(b)光照充足,(c)光照不足,(d)背景杂乱,(e)背景纯净Fig.6 Photos of some samples(a)Image occlusion,(b)Adequate illumination,(c)Insufficient illumination,(d)Cluttered background,(e)Clean background
3.1.2 图像预处理
用图像标记软件Labelme 对采集的皮革数据进行标注,共分为两个标记类别,分别是leather(皮革)和point(抓取点)。按照7∶3 的比例将标注文件分别放入训练集和测试集中,共同组成本次实验所需的数据集。
3.2 实验设计与评价指标
实验的评价指标选取为:Precision(P,准确率)、Recall(R,召回率)和mean Average Precision(mAP,平均精确率的平均值)。
式中,TP表示正样本被正确的检测,FP表示正样本被错误检测,TN表示负样本被正确检测,FN表示漏报的正样本个数,N表示类别个数,本研究N=2,mAP表示平均精确率的平均值。
定位实验是通过模型训练实验的结果对皮革抓取点进行目标检测,将皮革抓取点的检测框中心点作为其定位点并获取该点的三维坐标。根据坐标转换关系公式可以将相机到皮革抓取点的距离转换成其他两个坐标值Xc和Yc,所以相机到皮革抓取点之间的距离Zc是定位实验的误差源。为实现对Zc进行精度评估,验证皮革抓取点定位的准确性,采用如图7 所示的激光测距仪作为验证设备。将激光测距仪和深度相机紧靠放置于同一平面,由于激光测距仪和深度相机之间的距离误差远小于到定位点的距离,可忽略不计。深度相机测得的定位点距离值为Zc1,激光测距仪测得的定位点距离值为Zc2。采用误差Ev和误差比Evr来评价定位精度,分别如式(20)和(21):

图7 定位点距离测试示意图Fig.7 Schematic diagram of anchor point distance test
3.3 实验条件
实验环境使用Windows 11 操作系统,基于Pytorch 框架搭建,定位实验,使用Intel RealSense D435i 深度相机获取皮革抓取点三维坐标,采用激光测距仪进行对比实验。如表2 为具体实验配置。

表2 实验配置Tab.2 Experimental configuration
3.4 测试与分析
3.4.1 模型训练结果
在模型的训练过程中,训练参数的设置如表3。
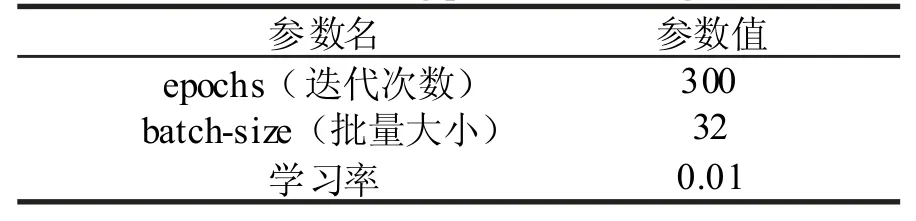
表3 训练参数设置Tab.3 Training parameter settings
在训练数据、迭代次数、优化器、学习率、批量大小和训练设备一致的条件下,将本文改进的YOLOv5 算法分别与Faster R-CNN 算法、原始YOLOv5 算法进行对比实验,如表4 所示。与Faster R-CNN 算法比较改进YOLOv5 算法的准确率提高了6.9%,召回率提高了8.39%,mAP 提高了8.13%;与原始YOLOv5 进行对比,改进YOLOv5 算法的准确率提高了2.63%,召回率提高了0.5%,mAP 提高了0.21%。从训练结果看改进后的YOLOv5 算法能够很好的提升模型对皮革及抓取点的特征提取能力。图8 为本研究改进的YOLOv5 算法对皮革及其抓取点的识别效果,其中测试采用的样本为训练集中的皮革和非训练集中的皮革,以检测算法的识别性能。

表4 模型训练结果Tab.4 Results of model training

图8 皮革及抓取点识别效果(a)和(b)为训练集中的皮革,(c)和(d)为非训练集中的皮革Fig.8 Identification effect of leather and grab point(a)and(b)are leather in the training set,while(c)and(d)are leather not in the training set
3.4.2 消融实验结果
改进YOLOv5 算法在原始YOLOv5 的基础上加入了CA 注意力机制模块,以及用Focal-EIOU Loss 对原始算法的损失函数进行了替换。为对比每个改进模块对算法的影响效果,对改进的算法进行消融实验,如表5 所示。分别进行4 组实验,在原始算法的基础上逐个添加改进模块,并进行对比平均精度mAP。
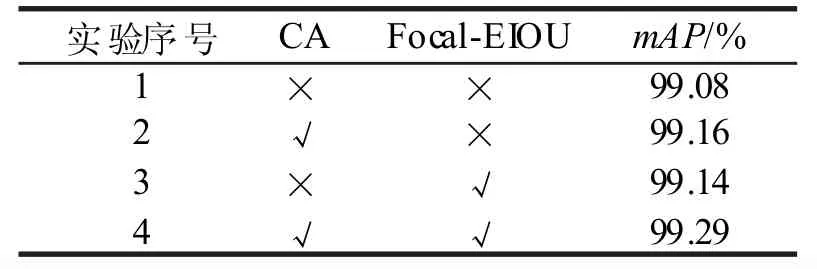
表5 消融实验结果Tab.5 Results of ablation test
实验1 为原始算法,在不增加CA 模块和Focal-EIOU Loss 的条件下mAP为99.08%;实验2 和实验3 在原始算法的基础上分别引入CA 模块和Focal-EIOU Loss,mAP 分别提升了0.08%和0.06%;实验4 为同时添加了CA 模块和Focal-EIOU Loss,mAP 为99.29%,提升了0.21%。
图9 为改进YOLOv5(实验4)和原始YOLOv5(实验1)损失的对比曲线。由图9 中分类概率损失曲线可知,在迭代次数为0~80 次时,原始YOLOv5算法和改进YOLOv5 算法的分类概率损失相近,在之后的迭代中,改进YOLOv5 算法的损失值一直小于原始YOLOv5 算法的损失值。由图9 中边框回归损失曲线可知,改进YOLOv5 算法相比原始YOLOv5 算法损失值下降更快,且损失值小于原始YOLOv5 算法损失值。由图9 中置信度损失曲线可知,改进YOLOv5 算法与原始YOLOv5 算法损失值相近,且在迭代次数达到20 次后一直小于原始YOLOv5 算法的损失值。通过对比3 种损失曲线可知,改进YOLOv5 算法最终损失值小于原始YOLOv5 算法的最终损失值。

图9 训练损失函数Fig.9 Training Loss Function
3.4.3 定位实验结果
通过模仿机械臂抓取皮革过程,人与深度相机的距离为1.5~2 m,分别采用本研究改进的YOLOv5算法、Faster R-CNN 算法和原始YOLOv5 算法对皮革抓取点进行识别与定位。在识别完皮革第一个抓取点的定位后,将第一个抓取点抓起,重新让皮革处于自然垂落状态,然后再次识别皮革第二个抓取点的定位,即为一组测试。每个算法进行5 组定位测试,每组定位实验的同时采用激光测距仪同步对抓取点的定位距离进行测量。如图10 为利用3 种算法对皮革抓取点识别定位的实验过程,并获取到了定位点的三维坐标值。记录每次深度相机测量的定位点距离值Zc1和激光测距仪测得的定位点距离值Zc2,计算二者误差Ev和误差比Evr,如表6 所示。图11 中检验框上的信息“leather”和“point”分别表示类别名皮革和抓取点,类别名后面对数字表示置信度,图中白色圆点及其后面的数值表示定位点的三维坐标。
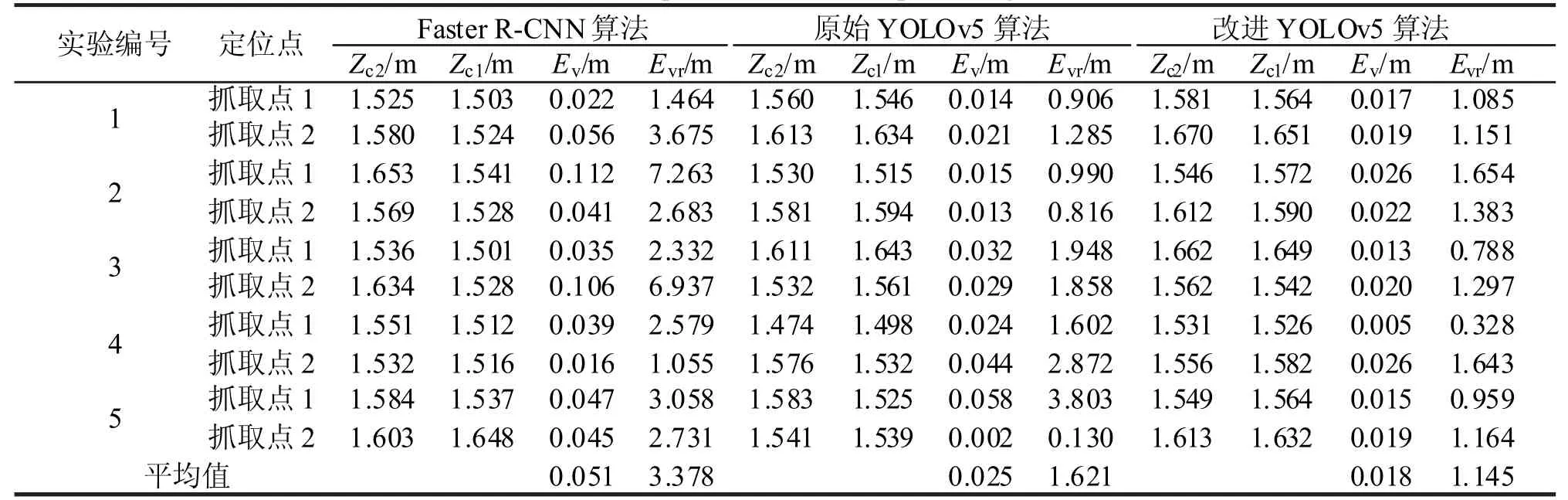
表6 定位实验结果1)Tab.6 Experimental results of positioning

图10 定位实验部分可视化图像(a)Faster R-CNN 算法,(b)原始YOLOv5 算法,(c)改进的YOLOv5 算法Fig.10 Visual images of positioning experiment parts(a)Faster R-CNN,(b)original YOLOv5,(c)improved YOLOv5
根据表6 的实验结果可知:三种算法得到的误差平均值分别为0.051、0.025 和0.018 m,误差比的平均值分别为3.378%、1.621%和1.145%。改进的YOLOv5 算法的误差平均值与Faster R-CNN 算法和原始YOLOv5 算法像比对,分别下降了0.033 m和0.007 m;误差比平均值相比于两种算法,分别下降了2.233%和0.476%。在本次实验中,误差值大于0.05 m 的视为错误定位,Faster R-CNN 算法在1 号实验3 号实验的抓取点2 出现定位错误。原始YOLOv5 算法在5 号实验的抓取点1 定位出现定位错误,改进YOLOv5 算法没有出现定位错误,且0.018 m 的误差平均值远远小于现有机械手夹爪开口距离。在此误差下,机械手夹爪可准确夹取皮革抓取点。综上所述,相比于Faster R-CNN 算法和原始YOLOv5 算法,改进YOLOv5 算法的定位效果得到了提升。
4 结论
为了实现对抓取过程中皮革抓取点的识别与定位,本研究在原始YOLOv5 算法基础上引入了CA 注意力机制模块,并用Focal-EIOU Loss 替换了原始算法中的CIOU Loss,在目标检测阶段获取皮革抓取点的定位点,通过D435i 深度相机获取定位点的三维坐标。
1)在识别实验中,与原始YOLOv5 进行对比,改进YOLOv5 算法对皮革抓取点的识别准确率提高了2.63%,召回率提高了0.5%,mAP 提高了0.21%。
2)在定位实验中,改进YOLOv5 算法相比于原始YOLOv5 算法误差平均值和误差比平均值分别下降0.007 m 和0.476%,提升了对皮革抓取点的定位效果。
文章提出的改进YOLOv5 算法,能够很好地识别和定位皮革抓取点,满足机器人在抓取皮革过程中机器视觉的定位要求;可推进机器人在修边、绷展干燥等需要抓取铺展皮革的工序中应用,且对制革行业的智能制造发展具有指导意义。
猜你喜欢
电气化铁道(2023年6期)2024-01-08 07:45:48
小资CHIC!ELEGANCE(2021年32期)2021-09-18 06:17:14
保健医苑(2021年9期)2021-09-08 14:38:06
电气化铁道(2018年4期)2018-09-11 07:01:38
中学生数理化·七年级数学人教版(2018年4期)2018-06-28 03:26:28
数学大世界(2018年1期)2018-04-12 05:39:03
金色少年(奇趣科普)(2017年4期)2017-06-05 15:03:46
中等数学(2017年2期)2017-06-01 12:21:50
小学阅读指南·低年级版(2017年5期)2017-05-18 11:21:04
Coco薇(2015年12期)2015-12-10 02:44:33
