
基于改进DCGAN的钢轨表面缺陷图像扩充方法
2024-01-06 01:52闵永智李嘉峰
铁道学报 2023年12期
闵永智,李嘉峰,王 果
(1.兰州交通大学 自动化与电气工程学院,甘肃 兰州 730070;2.兰州交通大学 甘肃省人工智能与图形图像处理工程研究中心,甘肃 兰州 730070)
由于列车运行中轮毂与钢轨长期的接触摩擦、冲击,钢轨缺陷多由表面开始并逐渐加剧。列车长期在有缺陷的轨道上运行,轮轨冲击振动会引起强度、疲劳破坏,影响轮轨系统安全性和寿命,因此及时检测轨面缺陷具有现实意义。
在轨面缺陷检测中,常规的无损检测方法有射线检测、漏磁检测、涡流检测和超声检测等。射线检测分析透过钢轨的射线差异来判断缺陷是否存在,可对缺陷进行准确的定性定量,但由于设备结构复杂,主要应用于钢轨生产加工时的前期缺陷检测[1]。漏磁检测通过获取钢轨浅表层缺陷处产生的漏磁场来检测缺陷,可靠性高,但难以检测钢轨内部缺陷。涡流检测利用电磁感应原理,当钢轨存在缺陷时感生涡流的强度和分布将改变,通过涡流变化确定缺陷位置[2],检测速度快,无需耦合介质,但由于涡流的趋肤效应,只能检测近表面的缺陷。超声检测通过超声波在钢轨中传播的散射能量及返回能量的幅度来确定缺陷位置[3],检测厚度大、灵敏度高,在我国钢轨探伤中应用广泛,但受轨面几何形状、粗糙度的影响,对近表面的微裂纹检测效果不佳。
机器视觉检测法是一种自动化程度高的新兴检测方法,通过对钢轨二维图像进行预处理,提取形状特征,将缺陷从图像中定位或分割出来[4],具有非接触、连续长时间工作于铁路恶劣环境的优点,可满足大规模线路的检测需求。贺振东等[5]对钢轨图像进行反向P-M扩散并与原图差分,根据缺陷边缘特性和面积滤波分割出缺陷图像,可以很好地识别块状缺陷和线状缺陷;陈后金等[6]根据钢轨图像的灰度梯度特征提取钢轨缺陷的内边缘,通过膨胀运算定位缺陷部位,可有效区分正常轨面、缺陷区域和干扰区域;张辉等[7]使用基于曲率滤波和改进高斯混合模型的方法检测轨面缺陷,提高了检测精度;谢敏杰等[8]设计一种基于线阵CCD相机的轨面缺陷检测系统,用改进的最大熵阈值分割法分割钢轨图像,根据形态学上连通区域大小是否满足要求检测缺陷,获得了较低的误检率和漏检率。以上方法实现了特定场景下轨面缺陷的识别,但都需要人工设计和提取特征,算法复杂。
当前,深度学习已在表面缺陷检测上有所应用。深度学习检测法利用神经网络提取特征,通过大量样本学习到更深层抽象的特征,检测速度快,可实现端到端训练,无需复杂调参,但训练样本不足时容易产生过拟合,影响模型对新数据的接受度。生成对抗网络(Generative Adversarial Network, GAN)[9]为样本不足提供了一种新的数据扩充方法,但其一直存在梯度消失、训练不稳定等问题;Mirza等[10]提出CGAN,将条件变量引入其中指导生成过程;Arjovsky等[11]提出WGAN,用Wasserstein距离替换GAN损失函数中的J-S散度,解决了梯度消失问题;Radford等[12]将CNN与GAN相结合,提出深度卷积生成对抗网络(DCGAN),通过限制网络结构很好地稳定了训练过程,目前成为GAN研究的标准架构。张曼等[13]针对遥感图像少、标注困难的问题,在DCGAN的判别器中加入多特征图特征融合技术,融合3种尺度特征来提高图像质量,再结合掩膜图像与遥感背景图像生成样本标签;戚银城等[14]在DCGAN中加入自我注意力机制使卷积提取样本的模式更充分,在其损失函数中加入相对均值鉴别器和梯度惩罚来平衡生成器和判别器的能力,提高了生成的缺陷螺栓图像的IS值;龙程[15]将残差块引入DCGAN减少棋盘效应;于文家等[16]在条件生成对抗网络(CGAN)中引入自我注意力机制,不仅增加了图像各个部分之间的连接,还可以生成类别标签;李秋丽等[17]在DCGAN的生成器中加入自我注意力机制使网络有目的地学习,在判别器中加入频谱规范化来稳定判别器的训练,提高了生成图像的IS值;刘学平等[18]将自我注意力机制引入DCGAN的多个卷积层上进行文字图像修复,当文字图像中含噪声、遮挡和笔画丢失时仍能准确修复图像。
由于维护及时,从铁路工务部门获取的轨检图像中缺陷样本较少,这使得深度学习方法在实际检测中表现不佳。为此,罗晖等[19]采用裁剪、缩放和GAN方式对钢轨数据集RSDDs进行扩充,并改进Faster R-CNN实现了多尺度检测与识别;吕邦欢[20]通过添加噪声、Gamma变换、旋转变换和DCGAN扩充轨面缺陷图像,再使用Faster R-CNN检测轨面缺陷,但均存在生成缺陷图像过于相似、多样性不足的问题。
受上述方法启发,本文将自我注意力机制与通道注意力机制引入DCGAN,提出一种基于注意力机制的深度卷积生成对抗网络(Attention-DCGAN)用于扩充钢轨表面缺陷图像。该网络使用注意力机制捕获图像中长距离尺寸依赖性和通道依赖性,弥补了卷积只能处理局部邻域信息的缺点,相比DCGAN,生成的缺陷图像多样性显著增强。
1 相关理论
1.1 生成对抗网络
GAN是一种生成式模型,主要由生成器G和判别器D两部分组成,其工作原理见图1。生成器接收一个随机噪声z,然后训练它去拟合原始样本的分布,使其越来越接近真实样本;判别器用来分辨生成样本和真实样本之间的差异。理想情况下,二者相互对抗并不断优化各自网络参数,最终会使判别器难以判断收到的样本来自真实样本还是生成样本,即达到纳什平衡D(G(z))=0.5,此时就可以认为生成器学习到了原始图像的数据分布。

图1 GAN的工作原理
GAN的目标函数为
Ez~Pz(z)[lg(1-D(G(z)))]
(1)
式中:V(D,G)为生成样本和真实样本的差异度;x为真实样本输入;G(z)为生成样本;E为数学期望;Pdata(x)为真实样本分布;Pz(z)为噪声分布如高斯分布;D(x)为判别器判断真实样本是否真实的概率;D(G(z))为判别器判断生成样本是否真实的概率。
判别器的能力越强,D(x)应该越大,D(G(z))应该越小,这时V(G,D)会变大,其目的是求最大值(Dmax);生成器希望自己生成的图片越真实越好,即D(G(z))尽可能大,这时V(G,D)会变小,因此式(1)对于生成器来说是求最小值(Gmin)。优化生成器和判别器的目标函数分别为
(2)
Ez~Pz(z)[lg(1-D(G(z)))]
(3)
DCGAN的网络结构见图2。

图2 DCGAN的网络结构
1.2 注意力机制
注意力机制是机器学习中的一种仿生数据处理方法,机器通过模拟人类阅读、听说中的注意力行为来自动忽略低可能、低价值的信息。具体来说是根据任务目标对关注的方向和加权模型进行调整,在隐藏层增加注意力机制的加权,使不符合注意力模型的内容弱化或者遗忘。注意力机制已在深度学习各个领域广泛使用。Chorowski等[21]通过注意力机制提高了长时间语音输入的鲁棒性;Hou等[22]提出一种有效的注意力机制来实现在线语音识别;Vaswani等[23]提出一种单纯基于注意力机制的网络,完全省去了递归和卷积,在翻译任务中表现良好;Yao等[24]提出一种时间注意力机制,在视频描述任务中自动选择最相关的时间段;Zhang等[25]设计一个对称的全卷积网络用于目标检测中显著性特征的提取。
注意力模型可以理解为一个查询Query到一系列键值对Key-Value的映射,其原理见图3。其中Source为输入序列,由一系列Key-Value组成,同时网络还存在一种查询向量。注意力机制本质上是通过相似函数计算Query和各个Keyi的相关性,得到每个Keyi对应Valuei的权重,最终将权重和对应的Valuei加权求和,即

图3 注意力机制原理
Attention(Query,Source)=
(4)
式中:Lx为序列长度;Similarity为计算Query和每个Keyi的相似度的函数。
2 注意力深度卷积生成对抗网络
2.1 自我注意力模块
由于卷积核大小的限制,卷积只能处理局部邻域信息,因此单独使用卷积层难以有效构建图像的长距离依赖关系。自我注意力(Self-Attention)机制[26-27]是注意力机制的变体,它是一种非局部机制,可以更好地利用全局信息去生成图像。将其引入DCGAN,可以使远距离的要素位置信息用于生成详细信息,判别器也可以检查图像中距离较远的细节特征是否一致。计算机视觉中自我注意力机制的原理见图4。

图4 自我注意力机制的工作原理
首先通过1×1卷积对上一个隐藏层中的特征图x∈RC×N进行线性变换和通道调整转换为三个特征空间f、g、h。其中f、g用来计算关注度,将f的输出转置并和g的输出相乘,经过softmax归一化得到注意力映射,并和线性变换后的原始特征h逐像素相乘,再通过1×1卷积调整通道数就得到自我注意力特征图,其数学表达式为
(5)
[sij]=[f(xi)]T[g(xj)]
(6)
式中:[f(xi)]=Wfxi,[g(xi)]=Wgxi为从不同权重矩阵的图像特征提取到的两个特征空间;βj, i为合成第j个区域时,模型关注第i个位置的程度。
注意力层的输出为
o=(o1,o2,…,oj,…,oN)∈RC×N
(7)

将自我注意力特征图乘以一个比例参数,并和原始卷积特征图加权求和作为下一隐藏层的输入
yi=γoi+xi
(8)
式中:γ为可学习的标量,初值为0,然后逐渐学会为非局部特征分配更多权重。引入它可以让网络首先依赖于邻域信息,之后再逐渐把权重分配到远距离信息上,从而先学习简单任务,再逐步增加任务的复杂性。
2.2 挤压激励模块
挤压激励(Squeeze-and-Excitation)操作[28]是一种具备通道注意力机制的模型,通道注意力用来衡量不同通道捕捉到的不同特征间的重要程度。卷积通过在局部接受域内融合空间和通道信息提取特征,挤压激励通过对卷积特征的通道间的相互依赖建模来提高网络性能。挤压建立通道间的依赖关系,激励重新校准特征,二者结合强调有用特征抑制无用特征,其工作原理见图5。
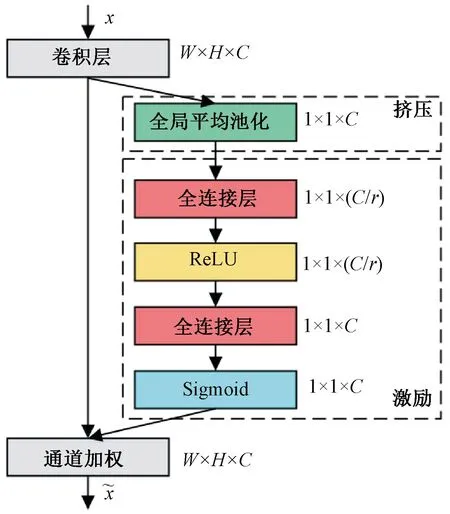
图5 挤压激励的工作原理
首先通过一个卷积层将隐藏层中的特征图x映射为W×H×C的特征图,挤压操作对输入的W×H×C特征图进行全局平均池化得到1×1×C大小的特征图,C为通道总数 ,通过聚集空间维度上的特征映射生成通道描述符,通道描述符生成响应全局分布的信道特征,使每个特征图都能利用其他特征图的上下文信息,从而具有全局感受野,其计算式为
(9)
式中:i为高H;j为宽W;c为通道数;uc(i,j)为空间维度W×H×C中的第c个特征图;Fsq为压缩操作;zc为将uc进行压缩后的结果。
激励操作使用两个全连接层做非线性变换来生成每个通道调制权重的集合,其计算式为
s=Fex(z,W)=σ(W2δ(W1z))
(10)
式中:W1为第一个全连接层的权重,其维度是(c/r)×c;W2为第二个全连接层的权重,其维度是c×(c/r),其中r为通道压缩倍率;W1z为第一个全连接层;δ为ReLU函数,然后与W2相乘为第二个全连接层;σ为Sigmoid函数;W为每个特征通道生成的权重;Fex(z,W)为对W和挤压后的结果z的激励操作;s用来刻画uc的权重。
最后将每个通道对应的权重乘到对应通道的输入特征上,其计算式为
(11)
2.3 网络结构
Attention-DCGAN生成器和判别器网络结构见图6、图7。
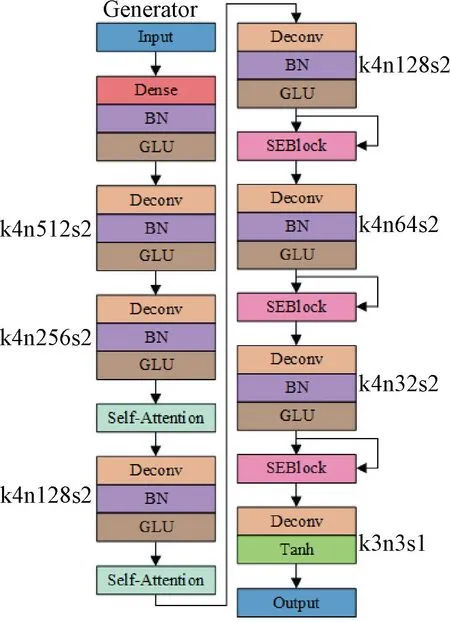
图6 Attention-DCGAN的生成器网络结构

图7 Attention-DCGAN的判别器网络结构
生成器将100维的噪声通过一个全连接层后进行维度转换(reshape)成(4, 4, 1 024)的三维张量,再先后通过两个卷积核为4×4,步幅为2的转置卷积层输出(8, 8, 512),(16, 16, 256)的张量,之后加入一次自我注意力操作,输出仍然为(16, 16, 256)。对得到的结果做卷积核为4×4,步幅为2,通道数为128的转置卷积后再加入一次自我注意力操作得到(32, 32, 128)的张量。再通过同样的转置卷积得到(64, 64, 128)的特征图后加入一次挤压激励层SEBlock。之后重复两次上述转置卷积并加入SEBlock,仅分别改变转置卷积的通道数为64和32得到(256, 256, 32)的特征图。最终经过一个卷积核为3×3,步幅为1,通道数为3的卷积层后输出(256, 256, 3)张量,经Tanh处理后即为一个生成样本。其中每个转置卷积后做batchnorm操作,再用线性门控单元(GLU)[29]做非线性化处理,对于得到的结果经最近邻插值法进行上采样得到想要的图片大小,GLU可以看作是处于激活状态下的一种简化的ReLU单元,在相同的训练时间下,可以获得比ReLU更高的精度。
判别器对输入其中的(256, 256, 3)样本用一个卷积核为3×3,步幅为1,通道数为16的卷积层转化为(256, 256, 16)的三维张量,再先后经三个卷积核为4×4,步幅为2,通道数为分别为32、64、128的卷积层后加入一次自我注意力操作和SEBlock得到(32, 32, 128)张量。然后经一个卷积核为4×4,步幅为2,通道数为256的卷积层后加入一次自我注意力操作和SEBlock得到(16, 16, 256)的特征图后再经一个卷积核为4×4,步幅为2,通道数为512的卷积层后加入一次SEBlock得到(8, 8, 512)张量,最后用一个全连接层将其展开输出一维结果。
3 实验
为评估本文方法,使用自制轨面缺陷数据集和Type-I RSDDs数据集[30]进行实验并和DCGAN进行对比。自制数据集拍摄于某厂内铁路线,包含掉块和擦伤的缺陷图片349张,制作过程中从同一水平高度拍摄,由于背景中的扣件、轨枕严重影响网络训练,统一处理为仅含轨面区域的300×130像素图片,部分图片见图8,Type-I RSDDs数据集包含大中小三种尺度的掉块缺陷图像。本方法主要适用于生成掉块和擦伤图片。实验设备为Intel(R) Core(TM) i9-10920X CPU@3.50 GHz,128 GB运行内存(RAM),NVIDIA GeForce RTX 3090 GPU,PyTorch1.8.0框架,Python3.7编译环境。

图8 部分自制数据集图片
实验中使用Adam优化器,其中β1=0.5,β2=0.999,设置学习率为0.000 2,batch_size为1,iterations为100 000。在自制数据集上生成的图像见图9、图10,在Type-I RSDDs数据集(图11)上生成的图像见图12、图13。

图9 DCGAN在自制数据集上生成的图片

图10 Attention-DCGAN在自制数据集上生成的图片

图11 部分Type-I RSDDs数据集图片

图12 DCGAN在Type-I RSDDs数据集上生成的图片

图13 Attention-DCGAN在Type-I RSDDs数据集上生成的图片
本文使用IS(inception score)[31]和FID(Fréchet inception distance)[32]来评价生成图像的质量。IS衡量生成图片的清晰度和多样性,该评分越高表示生成图像质量越好,其公式为
IS=exp(Ex~G(z)DKL(p(y|x)‖p(y)))
(12)
式中:x为生成的图像;y为生成图像输入Inception网络产生的向量;p(y|x)为生成图像x被分类成某一类的概率分布;p(y)为生成的所有图片在全体类别上的边缘分布;DKL为两分布之间的K-L散度。
FID计算真实样本和生成样本在特征空间之间的距离。首先利用Inception网络提取特征,然后使用高斯模型对特征空间进行建模,再求两个特征之间的距离,它的值越小表示生成图像质量越好,其公式为

(13)
式中:μdata、μg分别为真实样本和生成样本高斯分布的均值;∑data、∑g分别为真实样本和生成样本高斯分布的协方差。
原图与DCGAN、Attention-DCGAN在自制数据集和Type-I RSDDs数据集上的IS、FID评价得分见表1,结果表明Attention-DCGAN比DCGAN生成图片的质量更好。从主观角度来看,Attention-DCGAN相比DCGAN主要提高了缺陷分布的多样性。在小样本训练的情况下,DCGAN生成的图像中缺陷较为单一,而Attention-DCGAN生成的图像中缺陷数量不定,并创造了一些原图中没有的形状,多样性明显提高。

表1 自制数据集和Type-I RSDDs上的IS/FID评价得分
4 结论
本文结合DCGAN和自我注意力、通道注意力机制提出一种注意力深度卷积生成对抗网络(Attention-DCGAN),通过注意力机制增强了图像中的通道依赖关系和远程尺寸间的依赖关系,提高了生成轨面缺陷图像的多样性。使用深度学习进行检测任务时往往存在缺陷样本不足的问题,通过GAN进行数据扩充是常用手段,但少量的缺陷样本却难以生成丰富多样的缺陷图像,难以提高目标检测、语义分割算法的泛化能力,Attention-DCGAN为这种矛盾提供了一种解决方案,有助于深度学习在检测上的应用。实验结果表明Attention-DCGAN的性能优于DCGAN,可以用其大量扩充轨面缺陷数据。虽然本文设计的Attention-DCGAN提高了生成缺陷图片的多样性,但与真实图像比起来还是存在一定差距,因此如何生成高质量的高分辨率图像还需进一步研究。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
计算机与生活(2022年1期)2022-01-18
湖南工业大学学报(2020年6期)2020-11-27
制造技术与机床(2017年8期)2017-11-27
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
中国铁道科学(2015年5期)2015-06-21
中国铁道科学(2015年4期)2015-06-21
中国铁道科学(2014年6期)2014-06-21
铁路通信信号工程技术(2014年4期)2014-02-21
